
La tercera y última parte de una serie de artículos sobre lsFusion (enlaces a la
primera y
segunda parte)
Se centrará en el modelo físico: todo lo que no está conectado con la funcionalidad del sistema, pero está asociado con su desarrollo y optimización del rendimiento, cuando hay demasiados datos.
Este artículo, como los anteriores, no es muy adecuado para la lectura entretenida, pero, a diferencia de los otros, habrá más detalles técnicos y temas "candentes" (como mecanografía o metaprogramación), además de este artículo dará una parte de las respuestas a la pregunta, ¿cómo es todo? trabaja adentro.
En este artículo, prescindiremos de una imagen (no hay una pila como esta), pero haremos una tabla de contenido, como se solicitó en artículos anteriores:
Identificación del artículo
Si el proyecto consta de varios archivos pequeños, generalmente no surgen problemas con la denominación de elementos. Todos los nombres están a la vista y son lo suficientemente fáciles como para asegurarse de que no se superpongan. Si el proyecto, por el contrario, consta de muchos módulos desarrollados por un gran número de personas diferentes, y las abstracciones en estos módulos de un dominio de dominio, los conflictos de nombres se vuelven mucho más probables. LsFusion tiene dos mecanismos para resolver estos problemas:
- Espacios de nombres: separación de un nombre en completo y corto, y la capacidad de usar solo un nombre corto al acceder a un elemento
- Escritura explícita (para ser más precisos, sobrecarga de funciones): la capacidad de nombrar propiedades (y acciones) de la misma manera, y luego, al acceder a ellas, dependiendo de las clases de argumentos, determina automáticamente a qué propiedad pertenece la llamada
Espacios de nombres
Cualquier proyecto complejo generalmente consta de una gran cantidad de elementos que deben nombrarse. Y, si los dominios de dominio se cruzan, muy a menudo es necesario usar el mismo nombre en diferentes contextos. Por ejemplo, tenemos el nombre de una clase o formulario Factura (factura), y queremos usar este nombre en varios bloques de funciones, por ejemplo: Compra (Compra), Venta (Venta), Devolución de compra (PurchaseReturn), Devolución de venta (SaleReturn). Está claro que puede llamar a clases / formularios PurchaseInvoice, SaleInvoice, etc. Pero, en primer lugar, tales nombres en sí mismos serán demasiado voluminosos. Y en segundo lugar, en un bloque funcional, las llamadas, por regla general, van a los elementos del mismo bloque funcional, lo que significa que cuando se desarrolla, por ejemplo, el bloque de función Compra a partir de una repetición constante de la palabra Compra, simplemente se ondulará en sus ojos. Para evitar que esto suceda, la plataforma tiene un concepto como un espacio de nombres. Funciona de la siguiente manera:
- cada elemento en la plataforma se crea en algún espacio de nombres
- Si se accede a otros elementos durante la creación del elemento, los elementos creados en el mismo espacio de nombres tienen prioridad
Los espacios de nombres en la versión de idioma actual se establecen para todo el módulo inmediatamente en el encabezado del módulo. Por defecto, si no se especifica un espacio de nombres, se crea implícitamente con un nombre igual al nombre del módulo. Si necesita acceder a un elemento desde un espacio de nombres no prioritario, puede hacerlo especificando el nombre completo del elemento (por ejemplo, Sale.Invoice).
Escritura explícita
Los espacios de nombres son importantes, pero no son la única forma de hacer que el código sea más corto y más legible. Además de ellos, al buscar propiedades (y acciones), también es posible tener en cuenta las clases de argumentos que se les pasan en la entrada. Entonces, por ejemplo:
Aquí, por supuesto, puede surgir la pregunta: ¿qué sucederá si el espacio de nombres de la propiedad deseada no es una prioridad, pero es más adecuado para las clases? De hecho, el algoritmo de búsqueda general es bastante complicado (su descripción completa está
aquí ) y hay muchos casos "ambiguos", por lo que en caso de incertidumbre, se recomienda especificar explícitamente espacios de nombres / clases de la propiedad deseada, o verificar dos veces en el IDE (usando Ir a la Declaración) CTRL + B) que la propiedad encontrada es exactamente lo que se quiso decir.
Además, vale la pena señalar que generalmente no es necesario escribir explícitamente en lsFusion. Las clases de parámetros pueden omitirse, y si la plataforma tiene suficiente información para encontrar la propiedad deseada, lo hará. Por otro lado, en proyectos realmente complejos, todavía se recomienda establecer clases de parámetros explícitamente, no solo desde el punto de vista de la brevedad del código, sino también desde el punto de vista de varias características adicionales, tales como: diagnóstico temprano de errores, autocompletado inteligente desde el IDE, etc. Teníamos una amplia experiencia trabajando tanto con la mecanografía implícita (los primeros 5 años) como con la explícita (tiempo restante), y debo decir que los tiempos de la mecanografía implícita ahora se recuerdan con un escalofrío (aunque puede que simplemente "no supiéramos cómo cocinarlo").
Modularidad
La modularidad es una de las propiedades más importantes del sistema, lo que permite garantizar su extensibilidad, reutilización de código, así como la interacción efectiva del equipo de desarrollo.
LsFusion proporciona modularidad con los dos mecanismos siguientes:
- Extensiones: la capacidad de expandir (cambiar) elementos del sistema después de que se crean.
- Módulos: la capacidad de agrupar algunas funciones para su posterior reutilización.
Extensiones
lsFusion admite la capacidad de extender clases y formas, así como propiedades y acciones, a través del mecanismo de polimorfismo descrito en el primer artículo.
Además, observamos que casi todos los demás diseños de plataforma (por ejemplo, navegador, diseño de formularios) son extensibles por definición, por lo tanto, no hay una lógica de extensión separada para ellos.
Módulos
Un módulo es una parte funcionalmente completa de un proyecto. En la versión actual de lsFusion, un módulo es un archivo separado que consiste en el encabezado y el cuerpo de un módulo. El título del módulo, a su vez, consiste en: el nombre del módulo, así como, si es necesario, una lista de los módulos utilizados y el nombre del espacio de nombres de este módulo. El cuerpo del módulo consta de declaraciones y / o extensiones de elementos del sistema: propiedades, acciones, restricciones, formularios, metacódigos, etc.
Típicamente, los módulos usan elementos de otros módulos para declarar sus propios / expandir elementos existentes. En consecuencia, si el módulo B usa elementos del módulo A, entonces es necesario indicar en el módulo B que depende de A.
En función de sus dependencias, todos los módulos del proyecto están organizados en un cierto orden en el que se inicializan (este orden desempeña un papel importante cuando se utiliza el mecanismo de extensión mencionado anteriormente). Se garantiza que si el módulo B depende del módulo A, entonces la inicialización del módulo A ocurrirá antes que la inicialización del módulo B. Las dependencias cíclicas entre los módulos en el proyecto no están permitidas.
Las dependencias entre módulos son transitivas. Es decir, si el módulo C depende del módulo B y el módulo B depende del módulo A, entonces se considera que el módulo C también depende del módulo A.
Cualquier módulo siempre depende automáticamente del módulo del sistema Sistema, independientemente de si se indica explícitamente o no.
Metaprogramación
La metaprogramación es un tipo de programación asociada con la escritura de código de programa, que como resultado genera otro código de programa. LsFusion utiliza los llamados metacódigos para la metaprogramación.
El metacódigo consta de:
- nombre del metacódigo
- parámetros de metacódigo
- cuerpo de un metacódigo: un bloque de código que consta de declaraciones y / o extensiones de elementos del sistema (propiedades, acciones, eventos, otros metacódigos, etc.)
En consecuencia, antes de comenzar el procesamiento principal del código, la plataforma lo prepara, reemplaza todos los usos de metacodes con los cuerpos de estos metacodes. En este caso, todos los parámetros de metacódigo utilizados en identificadores / literales de cadena se reemplazan con los argumentos pasados a este metacódigo:
Anuncio:
Uso:
Código resultante:
Además de simplemente sustituir los parámetros del metacódigo, la plataforma también le permite combinar estos parámetros con identificadores / literales de cadena existentes (o entre sí), por ejemplo:
Anuncio:
Uso:
Código resultante:
Los metacódigos son muy similares a las macros en C, pero, a diferencia de este último, no funcionan a nivel de texto (por ejemplo, no pueden pasar palabras clave en el parámetro), sino solo a nivel de identificadores / literales de cadena (esta restricción, en particular, permite analizando el cuerpo del metacódigo en el IDE).
En lsFusion, los metacódigos resuelven problemas similares a los genéricos en Java (pasando clases como parámetros) y lambda en FP (pasando funciones como parámetros), sin embargo, no lo hacen muy bien. Pero, por otro lado, lo hacen en un caso mucho más general (es decir, con la posibilidad de combinar identificadores, usar en cualquier construcción sintáctica: formas, diseños, navegador, etc.)
Tenga en cuenta que el "despliegue" de metacódigos es compatible no solo en la plataforma en sí, sino también en el IDE. Entonces, en el IDE hay un modo especial Habilitar meta, que genera el código resultante directamente en las fuentes y, por lo tanto, permite que este código generado participe en la búsqueda de usos, autocompletado, etc. En este caso, si el cuerpo del metacódigo cambia, el IDE actualiza automáticamente todos los usos de este metacódigo.
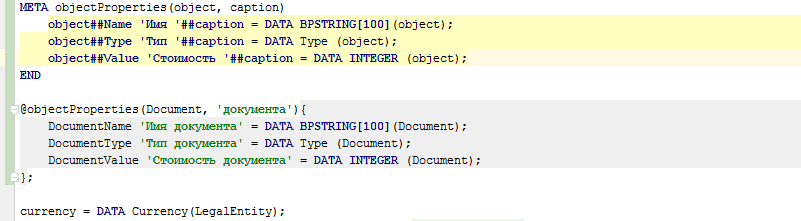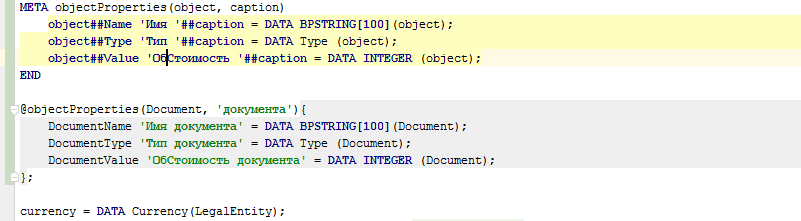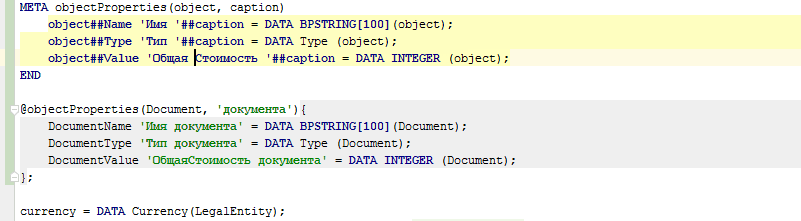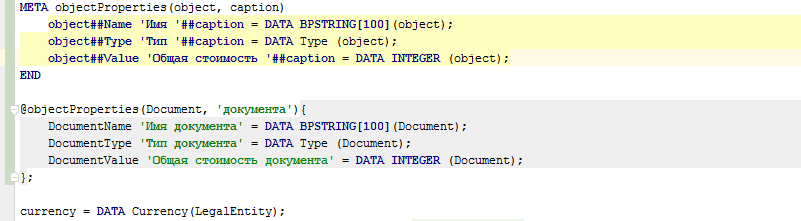
Además, los metacódigos se pueden usar no solo para la generación automática de códigos, sino también para la generación manual de códigos (como plantillas). Para hacer esto, es suficiente escribir @@ en lugar de uno @ e inmediatamente después de que la cadena de uso del metacódigo se haya ingresado por completo (hasta el punto y coma), el IDE reemplazará este uso del metacódigo con el código generado por este metacódigo:
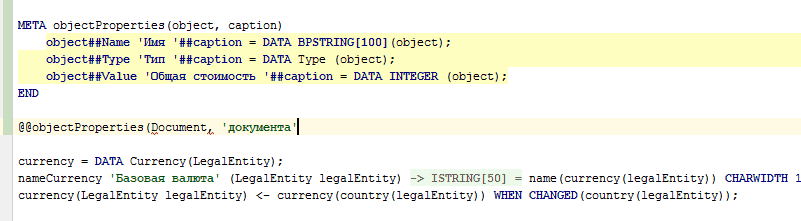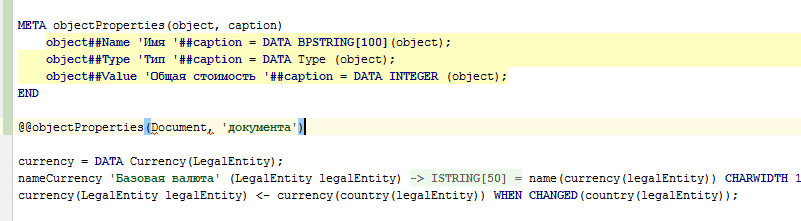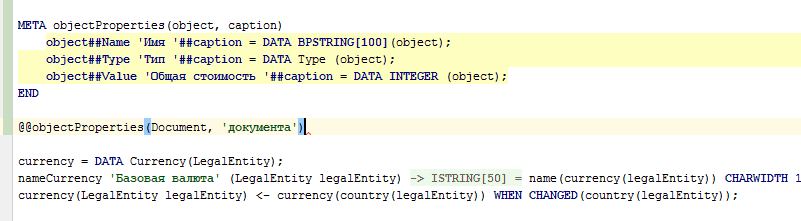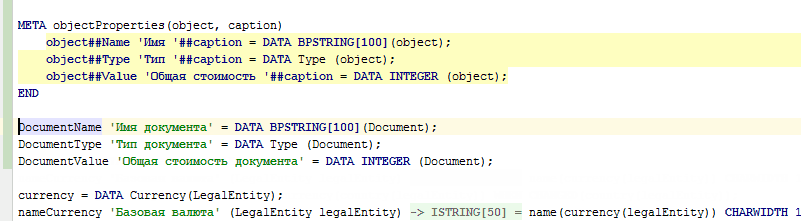
Integración
La integración incluye todo lo relacionado con la interacción del sistema lsFusion con otros sistemas. Desde el punto de vista de la dirección de esta interacción, la integración se puede dividir en:
- Accediendo al sistema lsFusion desde otro sistema.
- Acceso desde el sistema lsFusion a otro sistema.
Desde el punto de vista del modelo físico, la integración se puede dividir en:
- Interacción con sistemas que se ejecutan en el "mismo entorno" que el sistema lsFusion (es decir, en la máquina virtual Java (JVM) del servidor lsFusion y / o que utilizan el mismo servidor SQL que el sistema lsFusion).
- Interacción con sistemas remotos a través de protocolos de red.
En consecuencia, los primeros sistemas se llamarán internos, el segundo, externos.
Por lo tanto, hay cuatro tipos diferentes de integración en la plataforma:
- Apelar a un sistema externo
- Apelar desde un sistema externo
- Apelar al sistema interno
- Apelación del sistema interno
Apelar a un sistema externo
El acceso a sistemas externos en lsFusion en la mayoría de los casos se implementa utilizando el operador especial EXTERNO. Este operador ejecuta el código dado en el lenguaje / en el paradigma del sistema externo dado. Además, este operador le permite transferir objetos de tipos primitivos como parámetros de dicha llamada, así como escribir los resultados de la llamada en las propiedades especificadas (sin parámetros).
Actualmente, la plataforma admite los siguientes tipos de interacciones / sistemas externos:
HTTP: realiza una solicitud http desde un servidor web.Para este tipo de interacción, debe especificar una cadena de consulta (URL), que determina simultáneamente la dirección del servidor y la solicitud que debe ejecutarse. Los parámetros se pueden transferir tanto en la línea de consulta (para acceder al parámetro, se utilizan el carácter especial $ y el número de este parámetro, a partir de 1), como en su cuerpo (BODY). Se supone que todos los parámetros no utilizados en la cadena de consulta se pasan a BODY. Si hay más de un parámetro en BODY, el tipo de contenido BODY durante la transmisión se establece en multiparte / mixto, y los parámetros se transfieren como componentes de este BODY.
Al procesar parámetros de clases de archivo (FILE, PDFFILE, etc.) en BODY, el tipo de contenido del parámetro se determina en función de la extensión del archivo (de acuerdo con la siguiente
tabla ). Si la extensión del archivo no está en esta tabla, el tipo de contenido se establece en application / <file extension>.
Si es necesario, utilizando la opción especial (HEADERS), puede configurar los encabezados de la solicitud ejecutada. Para hacer esto, debe especificar una propiedad con exactamente un parámetro de la clase de cadena en la que se almacenará el título, y el valor de la clase de cadena en la que se almacenará el valor de este encabezado.
El resultado de la solicitud http se procesa de la misma manera que sus parámetros, solo en la dirección opuesta: por ejemplo, si el tipo de contenido del resultado está presente en la siguiente
tabla o es igual a application / *, se considera que el resultado obtenido es un archivo y debe escribirse en una propiedad con el valor FILE . Los encabezados del resultado de la solicitud http se procesan por analogía con los encabezados de esta solicitud (con la única diferencia de que la opción se llama HEADERSTO, no HEADERS).
SQL: ejecutar un comando del servidor SQL.Para este tipo de interacción, se especifican la cadena de conexión y los comandos SQL que se ejecutarán. Los parámetros se pueden pasar tanto en la cadena de conexión como en el comando SQL. Para acceder al parámetro, se utilizan el carácter especial $ y el número de este parámetro (a partir de 1).
Los parámetros de las clases de archivo (FILE, PDFFILE, etc.) solo se pueden usar en el comando SQL. Además, si alguno de los parámetros durante la ejecución es un archivo TABLE (TABLEFILE o FILE con la extensión de tabla), este parámetro también se considera una tabla en este caso:
- antes de ejecutar el comando SQL, el valor de cada parámetro se carga en el servidor en una tabla temporal
- al sustituir parámetros, no se sustituye el valor del parámetro en sí, sino el nombre de la tabla temporal creada
Los resultados de la ejecución son: para consultas DML - números iguales al número de registros procesados, para consultas SELECT - archivos en formato TABLE (ARCHIVO con la extensión de tabla) que contienen los resultados de estas consultas. El orden de estos resultados coincide con el orden de ejecución de las consultas correspondientes en el comando SQL.
LSF: una llamada a la acción de otro servidor lsFusion.Para este tipo de interacción, se establece la cadena de conexión al servidor lsFusion (o su servidor web, si corresponde), la acción a realizar, así como una lista de propiedades (sin parámetros), en cuyos valores se escribirán los resultados de la llamada. Los parámetros a transferir deben coincidir en número y clase con los parámetros de la acción que se realiza.
El método de establecer la acción en este tipo de interacción es totalmente consistente con el método de establecer la acción cuando se accede desde un sistema externo (sobre este tipo de acceso en la siguiente sección).
Por defecto, este tipo de interacción se implementa usando el protocolo HTTP usando las interfaces apropiadas para acceder a / desde un sistema externo.
En el caso de que necesite acceder al sistema utilizando un protocolo diferente al anterior, siempre puede hacerlo creando una acción en Java e implementando esta llamada allí (pero más sobre eso más adelante en la sección "Acceso a sistemas internos")
Apelar desde un sistema externo
La plataforma permite que los sistemas externos accedan al sistema desarrollado en lsFusion utilizando el protocolo de red HTTP. La interfaz de esta interacción es llamar a alguna acción con los parámetros dados y, si es necesario, devolver los valores de algunas propiedades (sin parámetros) como resultados. Se supone que todos los objetos de parámetros y resultados son objetos de tipos primitivos.
La acción llamada se puede establecer de tres maneras:
- / exec? action = <nombre de acción>: establece el nombre de la acción llamada.
- / eval? script = <code>: establece el código en lsFusion. Se supone que en este código hay una declaración de una acción con el nombre ejecutado, es esta acción la que se llamará. Si no se especifica el parámetro de script, se supone que el código se pasa como el primer parámetro BODY.
- / eval / action? script = <código de acción>: establece el código de acción en lsFusion. Para acceder a los parámetros, puede usar el carácter especial $ y el número de parámetro (a partir de 1).
En el segundo y tercer caso, si no se especifica el parámetro de secuencia de comandos, se supone que el primer parámetro BODY pasa el código.
El procesamiento de parámetros y resultados es simétrico para acceder a sistemas externos utilizando el protocolo HTTP (con la única diferencia de que los parámetros se procesan como resultados y, por el contrario, los resultados se procesan como parámetros), por lo que no nos repetiremos mucho.
Por ejemplo, si tenemos una acción:
Luego puede acceder a él utilizando una solicitud POST que:
- URL: http: // server_address / exec? Action = importOrder & p = 123 & p = 2019-01-01
- BODY - archivo json con cadenas de consulta
Ejemplo de llamada de Python import json import requests from requests_toolbelt.multipart import decoder lsfCode = ("run(INTEGER no, DATE date, FILE detail) {\n" " NEW o = FOrder {\n" " no(o) <- no;\n" " date(o) <- date;\n" " LOCAL detailId = INTEGER (INTEGER);\n" " LOCAL detailQuantity = INTEGER (INTEGER);\n" " IMPORT JSON FROM detail TO detailId, detailQuantity;\n" " FOR imported(INTEGER i) DO {\n" " NEW od = FOrderDetail {\n" " id(od) <- detailId(i);\n" " quantity(od) <- detailQuantity(i);\n" " price(od) <- 5;\n" " order(od) <- o;\n" " }\n" " }\n" " APPLY;\n" " EXPORT JSON FROM price = price(FOrderDetail od), id = id(od) WHERE order(od) == o;\n" " EXPORT FROM orderPrice(o), exportFile();\n" " }\n" "}") order_no = 354 order_date = '10.10.2017' order_details = [dict(id=1, quantity=10), dict(id=2, quantity=15), dict(id=5, quantity=4), dict(id=10, quantity=18), dict(id=11, quantity=1), dict(id=12, quantity=3)] order_json = json.dumps(order_details) url = 'http://localhost:7651/eval' payload = {'script': lsfCode, 'no': str(order_no), 'date': order_date, 'detail': ('order.json', order_json, 'text/json')} response = requests.post(url, files=payload) multipart_data = decoder.MultipartDecoder.from_response(response) sum_part, json_part = multipart_data.parts sum = int(sum_part.text) data = json.loads(json_part.text)
Apelar al sistema interno
Hay dos tipos de interacción interna:
Interoperabilidad JavaEste tipo de interacción le permite llamar al código Java dentro del servidor JVM lsFusion. Para hacer esto, debes:
- asegúrese de que la clase Java compilada sea accesible en el classpath del servidor de aplicaciones. También es necesario que esta clase herede lsfusion.server.physics.dev.integration.internal.to.InternalAction.
Ejemplo de clase Java import lsfusion.server.data.sql.exception.SQLHandledException; import lsfusion.server.language.ScriptingErrorLog; import lsfusion.server.language.ScriptingLogicsModule; import lsfusion.server.logics.action.controller.context.ExecutionContext; import lsfusion.server.logics.classes.ValueClass; import lsfusion.server.logics.property.classes.ClassPropertyInterface; import lsfusion.server.physics.dev.integration.internal.to.InternalAction; import java.math.BigInteger; import java.sql.SQLException; public class CalculateGCD extends InternalAction { public CalculateGCD(ScriptingLogicsModule LM, ValueClass... classes) { super(LM, classes); } @Override protected void executeInternal(ExecutionContext<ClassPropertyInterface> context) throws SQLException, SQLHandledException { BigInteger b1 = BigInteger.valueOf((Integer)getParam(0, context)); BigInteger b2 = BigInteger.valueOf((Integer)getParam(1, context)); BigInteger gcd = b1.gcd(b2); try { findProperty("gcd[]").change(gcd.intValue(), context); } catch (ScriptingErrorLog.SemanticErrorException ignored) { } } }
- registrar una acción utilizando el operador especial de llamadas internas (INTERNO)
- Se puede invocar una acción registrada, como cualquier otra, utilizando el operador de llamada. En este caso, se ejecutará el método executeInternal (lsfusion.server.logics.action.controller.context.ExecutionContext) de la clase Java especificada.
Interacción SQLEste tipo de interacción le permite acceder a los objetos / construcciones de sintaxis del servidor SQL utilizado por el sistema desarrollado lsFusion. Para implementar este tipo de interacción en la plataforma, se utiliza un operador especial: FORMULA. Este operador le permite crear una propiedad que evalúa alguna fórmula en el lenguaje SQL. La fórmula se establece en forma de una cadena dentro de la cual se utilizan el carácter especial $ y el número de este parámetro para acceder al parámetro (a partir de 1). En consecuencia, el número de parámetros de la propiedad obtenida será igual al máximo de los números de los parámetros utilizados.
Se recomienda usar este operador solo en los casos en que el problema no se pueda resolver con la ayuda de otros operadores, y también si se garantiza que los servidores SQL específicos se pueden usar, o las construcciones de sintaxis utilizadas cumplen con uno de los últimos estándares SQL.
Apelación del sistema interno
Todo es simétrico al atractivo del sistema interno. Hay dos tipos de interacción:
Interoperabilidad JavaDentro del marco de este tipo de interacción, el sistema interno puede acceder directamente a los elementos Java del sistema lsFusion (como los objetos Java normales). Por lo tanto, puede realizar las mismas operaciones que usar protocolos de red, pero al mismo tiempo evitar una sobrecarga significativa de dicha interacción (por ejemplo, serialización de parámetros / deserialización del resultado, etc.). Además, este método de comunicación es mucho más conveniente y eficiente si la interacción es muy cercana (es decir, durante la ejecución de una operación, se requiere un contacto constante en ambas direcciones, desde el sistema lsFusion a otro sistema y viceversa) y / o requiere acceso a nodos de plataforma específicos.
Para acceder a los elementos Java de un sistema lsFusion directamente, primero debe obtener un enlace a algún objeto que tenga interfaces para encontrar estos elementos Java. Esto generalmente se hace de una de dos maneras:- Si inicialmente la llamada proviene del sistema lsFusion (a través del mecanismo descrito anteriormente), entonces, como "objeto de búsqueda", puede usar el objeto de acción "a través del cual" pasa esta llamada (la clase de esta acción debe heredarse de lsfusion.server.physics.dev.integration. internal.to.InternalAction, que, a su vez, tiene todas las interfaces necesarias).
- Si el objeto desde cuyo método es necesario acceder al sistema lsFusion es un bean Spring, entonces se puede obtener un enlace al objeto de lógica de negocios usando la inyección de dependencia (el bean se llama businessLogics, respectivamente).
Ejemplo de clase Java import lsfusion.server.data.sql.exception.SQLHandledException; import lsfusion.server.data.value.DataObject; import lsfusion.server.language.ScriptingErrorLog; import lsfusion.server.language.ScriptingLogicsModule; import lsfusion.server.logics.action.controller.context.ExecutionContext; import lsfusion.server.logics.classes.ValueClass; import lsfusion.server.logics.property.classes.ClassPropertyInterface; import lsfusion.server.physics.dev.integration.internal.to.InternalAction; import java.math.BigInteger; import java.sql.SQLException; public class CalculateGCDObject extends InternalAction { public CalculateGCDObject(ScriptingLogicsModule LM, ValueClass... classes) { super(LM, classes); } @Override protected void executeInternal(ExecutionContext<ClassPropertyInterface> context) throws SQLException, SQLHandledException { try { DataObject calculation = (DataObject)getParamValue(0, context); BigInteger a = BigInteger.valueOf((Integer)findProperty("a").read(context, calculation)); BigInteger b = BigInteger.valueOf((Integer)findProperty("b").read(context, calculation)); BigInteger gcd = a.gcd(b); findProperty("gcd[Calculation]").change(gcd.intValue(), context, calculation); } catch (ScriptingErrorLog.SemanticErrorException ignored) { } } }
Lossistemas de interacción SQL que tienen acceso al servidor SQL del sistema lsFusion (uno de esos sistemas, por ejemplo, es el propio servidor SQL), pueden acceder directamente a las tablas y campos creados por el sistema lsFusion utilizando las herramientas del servidor SQL. Debe tenerse en cuenta que si la lectura de datos es relativamente segura (a excepción de la posible eliminación / modificación de tablas y sus campos), no se desencadenará ningún evento cuando se escriban los datos (y, en consecuencia, todos los elementos que los usan: restricciones, agregaciones, etc. n.), y tampoco se volverán a contar las materializaciones. Por lo tanto, no se recomienda escribir datos directamente en las tablas del sistema lsFusion y, si es necesario, es importante tener en cuenta todas las características anteriores.Tenga en cuenta que dicha interacción directa (pero solo para lectura) es especialmente conveniente para la integración con varios sistemas OLAP, donde todo el proceso debe ocurrir con una sobrecarga mínima.La migracion
En la práctica, a menudo surgen situaciones en las que, por diversos motivos, es necesario cambiar los nombres de los elementos existentes del sistema. Si el elemento a renombrar no está asociado con ningún dato primario, esto puede hacerse sin ningún gesto innecesario. Pero si este elemento es una propiedad o clase primaria, entonces un cambio de nombre "silencioso" conducirá al hecho de que los datos de esta propiedad o clase primaria simplemente desaparecerán. Para evitar esto, el desarrollador puede crear un archivo especial de migración migration.script, colocarlo en el classpath del servidor e indicar en él cómo los nombres de los elementos antiguos corresponden a los nuevos nombres. Todo funciona de la siguiente manera:La migración consiste en bloques que describen los cambios realizados en la versión especificada de la estructura de la base de datos. Al iniciar el servidor, se aplican todos los cambios del archivo de migración que tienen una versión superior a la versión almacenada en la base de datos. Los cambios se aplican de acuerdo con la versión, desde una versión más pequeña a una más grande. Si la estructura de la base de datos se cambia con éxito, la versión máxima de todos los bloques aplicados se escribe en la base de datos como la actual. La sintaxis para la descripción de cada bloque es la siguiente: V< > { 1 ... N }
Los cambios, a su vez, son de los siguientes tipos:Para la migración de datos de usuario, solo los primeros tres tipos de cambios son relevantes (cambios en propiedades primarias, clases, objetos estáticos). Se necesitan los cuatro tipos de cambios restantes:- para la migración de metadatos (políticas de seguridad, configuración de tablas, etc.)
- para optimizar la migración de los datos del usuario (para no volver a calcular las agregaciones y no transferir datos entre las tablas una vez más).
En consecuencia, si no se necesita la migración de metadatos o no hay muchos datos, se pueden omitir dichos cambios en el script de migración.Vale la pena señalar que, por lo general, la mayor parte del trabajo en la generación de scripts de migración se realiza utilizando el IDE. Por lo tanto, al cambiar el nombre de la mayoría de los elementos, puede especificar la casilla de verificación especial Cambiar el archivo de migración (habilitado de forma predeterminada), y el IDE generará automáticamente todos los scripts necesarios.Internacionalizacion
En la práctica, a veces surge una situación en la que es necesario poder usar una aplicación en diferentes idiomas. Esta tarea generalmente se reduce a localizar todos los datos de cadena que ve el usuario, a saber: mensajes de texto, encabezados de propiedad, acciones, formularios, etc. Todos estos datos en lsFusion se configuran utilizando literales de cadena (cadenas entre comillas simples, por ejemplo 'abc'), respectivamente, su localización se realiza de la siguiente manera:- en lugar del texto a localizar, la cadena identifica los datos de la cadena, encerrados entre llaves (por ejemplo, '{button.cancel}').
- cuando esta cadena se envía al cliente en el servidor, busca todos los identificadores encontrados en la cadena, luego busca cada uno de ellos en todos los archivos de proyecto de ResourceBundle en la configuración regional deseada (es decir, la configuración regional del cliente), y cuando se encuentra la opción correcta, el identificador entre paréntesis se reemplaza con el texto correspondiente.
ServerResourceBundle.properties: scheduler.script.scheduled.task.detail=Script scheduler.constraint.script.and.action=In the scheduler task property and script cannot be selected at the same time scheduler.form.scheduled.task=Tasks
ServerResourceBundle_ru.properties scheduler.script.scheduled.task.detail= scheduler.constraint.script.and.action= scheduler.form.scheduled.task=
Optimizar el rendimiento de grandes proyectos de datos
Si el sistema es pequeño y hay relativamente pocos datos, por lo general, funciona de manera bastante eficiente sin ninguna optimización adicional. Si la lógica se vuelve bastante complicada y la cantidad de datos aumenta significativamente, a veces tiene sentido decirle a la plataforma la mejor manera de almacenar y procesar todos estos datos.La plataforma tiene dos mecanismos principales para trabajar con datos: propiedades y acciones. El primero es responsable de almacenar y calcular datos, el segundo es transferir el sistema de un estado a otro. Y si el trabajo de las acciones puede optimizarse de manera bastante limitada (incluso debido al efecto del efecto secundario), entonces para las propiedades hay un conjunto completo de características que le permiten reducir el tiempo de respuesta de operaciones específicas y aumentar el rendimiento general del sistema:- . ( , ), , , .
- . , , .
- . / , . «» .
Casi cualquier propiedad agregada en la plataforma se puede materializar. En este caso, la propiedad se almacenará en la base de datos de forma constante y automática cuando se modifiquen los datos de los que depende esta propiedad. Además, al leer los valores de dicha propiedad materializada, estos valores se leerán directamente de la base de datos, como si la propiedad fuera primaria (y no se calculara cada vez). En consecuencia, todas las propiedades primarias se materializan por definición.Una propiedad se puede materializar si y solo para ella hay un número finito de conjuntos de objetos para los cuales el valor de esta propiedad no es NULL.Generalmente, el tema de la materialización se examinó con suficiente detalle en un artículo reciente. sobre el equilibrio de la escritura y la lectura en bases de datos, por lo que, en mi opinión, hacer hincapié en ello en detalle aquí no tiene mucho sentido.Índices
La creación de un índice por propiedad le permite almacenar en la base de datos todos los valores de esta propiedad de manera ordenada. En consecuencia, el índice se actualiza cada vez que cambia el valor de la propiedad indexada. Gracias al índice, si, por ejemplo, el filtrado por propiedad indexada está en progreso, puede encontrar rápidamente los objetos necesarios, en lugar de ver todos los objetos existentes en el sistema.Solo se pueden indexar las propiedades materializadas (de la sección anterior).También se puede construir un índice en varias propiedades a la vez (esto es efectivo si, por ejemplo, el filtrado se realiza inmediatamente en estas varias propiedades). Además, los parámetros de propiedad se pueden incluir en dicho índice compuesto. Si las propiedades especificadas se almacenan en tablas diferentes, un intento de generar el índice dará como resultado el error correspondiente.Mesas
LsFusion utiliza una base de datos relacional para almacenar y calcular valores de propiedad. Todas las propiedades primarias, así como todas las propiedades agregadas que están marcadas como materializadas, se almacenan en los campos de las tablas de la base de datos. Para cada tabla, hay un conjunto de campos clave con los nombres key0, key1, ..., keyN, en los que se almacenan los valores de los objetos (por ejemplo, para clases personalizadas, los identificadores de estos objetos). Todos los demás campos almacenan valores de propiedad de tal manera que en el campo correspondiente de cada fila se encuentra el valor de propiedad para los objetos de los campos clave.Al crear una tabla, debe especificar una lista de clases de objetos que serán las claves de esta tabla.Para cada propiedad, puede especificar en qué tabla debe almacenarse. En este caso, el número de claves de tabla debe coincidir con el número de parámetros de propiedad, y las clases de parámetros deben coincidir con las clases de clave de esta tabla. Si la tabla en la que se va a almacenar no se establece explícitamente para la propiedad, la propiedad se colocará automáticamente en la tabla "más cercana" existente en el sistema (es decir, el número de claves que coincide con el número de parámetros de propiedad, y cuyas clases de claves son más cercanas a las clases de parámetros )Los nombres de las tablas y campos en los que se almacenan las propiedades en el DBMS se forman de acuerdo con la política de nomenclatura especificada. Actualmente, la plataforma admite tres políticas de nomenclatura estándar.Si es necesario, para cada propiedad, el desarrollador puede especificar explícitamente el nombre del campo en el que se almacenará esta propiedad. Además, es posible crear su propia política para nombrar campos de propiedad si lo anterior por alguna razón no es adecuado.Al elegir una política de nomenclatura, es importante tener en cuenta que el uso de una política de nomenclatura de propiedad demasiado corta, si el número de propiedades materializadas es lo suficientemente grande, puede complicar en gran medida la nomenclatura de estas propiedades (por lo que es único), o, en consecuencia, conducir a la necesidad de nombrar explícitamente Los campos en los que se almacenarán estas propiedades.Conclusión
Como dijeron en una famosa película animada: "construimos, construimos y finalmente construimos". Por supuesto, puede ser un poco superficial, pero creo que puede descubrir las características básicas del lenguaje / plataforma lsFusion para estos tres artículos. Es hora de pasar a la parte más interesante: comparar con otras tecnologías.Como lo demostró la experiencia y el formato del Habr, hacer esto de manera más efectiva no jugando solo, sino en un campo extranjero. Es decir, no pasar de las oportunidades, sino de los problemas y, en consecuencia, no hablar de sus ventajas, sino de las desventajas de las tecnologías alternativas, y en su propia terminología. Este enfoque generalmente se percibe mucho mejor en los mercados conservadores y, en mi opinión, dicho mercado es el mercado para el desarrollo de sistemas de información, en cualquier caso, en el espacio postsoviético.Muy pronto habrá varios artículos más al estilo de: "¿Por qué no ...?", Y estoy seguro de que serán mucho más interesantes que estos tutoriales muy aburridos.