Hola Habr
En la
primera parte , se consideró NVIDIA Jetson Nano: una placa con el factor de forma Raspberry Pi centrada en la informática de rendimiento con la GPU. Es hora de probar el tablero para lo que fue creado, para cálculos orientados a la inteligencia artificial.

Considere cómo se realizan las diferentes tareas en el tablero, como clasificar imágenes o reconocer a los peatones o las focas (sin ellas). Para todas las pruebas, el código fuente se puede ejecutar en el escritorio, Jetson Nano o Raspberry Pi. Para aquellos que estén interesados, continúe bajo el corte.
Hay dos formas de usar este tablero. El primero es ejecutar marcos estándar como Keras y Tensorflow. Funcionará en principio, lo hará, pero como ya se vio en la primera parte, Jetson Nano, por supuesto, es inferior a una tarjeta de video de escritorio o portátil de pleno derecho. El usuario tendrá que asumir la tarea de optimizar el modelo. La segunda forma es tomar clases preparadas que vienen con la pizarra. Es más simple y funciona "fuera de la caja", el inconveniente es que todos los detalles de implementación están ocultos en una medida mucho mayor, además, tendrá que estudiar y usar sdk personalizado, que, además de estos paneles, no será útil en ningún otro lugar. Sin embargo, veremos las dos formas, comencemos con la primera.
Clasificación de la imagen
Considere el problema del reconocimiento de imágenes. Para hacer esto, utilizaremos el modelo ResNet50 suministrado con Keras (este modelo fue el ganador del desafío ImageNet Challenge en 2015). Para usarlo, basta con unas pocas líneas de código.
import tensorflow as tf import numpy as np import time IMAGE_SIZE = 224 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) resnet = tf.keras.applications.ResNet50(input_shape=IMG_SHAPE) img = tf.contrib.keras.preprocessing.image.load_img('cat.png', target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_data = tf.contrib.keras.preprocessing.image.img_to_array(img) x = tf.contrib.keras.applications.resnet50.preprocess_input(np.expand_dims(img_data, axis=0)) probabilities = resnet.predict(x) print(tf.contrib.keras.applications.resnet50.decode_predictions(probabilities, top=5)) print("dT", time.time() - t_start)
Ni siquiera comencé a eliminar el código debajo del spoiler, porque El es muy pequeño. Como puede ver, la imagen primero se redimensiona a 224x224 (este es el formato de red de entrada), al final, la función de predicción hace todo el trabajo.
Tomamos una foto del gato y ejecutamos el programa.

Resultados:
[[('n02123045', 'tabby', 0.765179), ('n02123159', 'tiger_cat', 0.19059166), ('n02124075', 'Egyptian_cat', 0.013605555), ('n04493381', 'tub', 0.0025916891), ('n04553703', 'washbasin', 0.0021566998)]]
Una vez más, molesto por su conocimiento del inglés (me pregunto cuántas personas no nativas saben lo que es "atigrado"), verifiqué la salida con el diccionario, sí, todo funciona.
El tiempo de ejecución del código de la PC fue de
0.5 s para cálculos en la CPU y 2 s (!) Para cálculos en la GPU. A juzgar por el registro, el problema está en el modelo o en Tensorflow, pero cuando se inicia, el código intenta asignar mucha memoria, obteniendo varias advertencias de la forma "Allocator (GPU_0_bfc) se quedó sin memoria tratando de asignar 2.13GiB con freed_by_count = 0." . Esta es una advertencia y no un error, el código funciona, pero es mucho más lento de lo que debería.
En Jetson Nano, todavía es más lento:
2.8c en la CPU y
18.8c en la GPU, mientras que la salida se ve así:
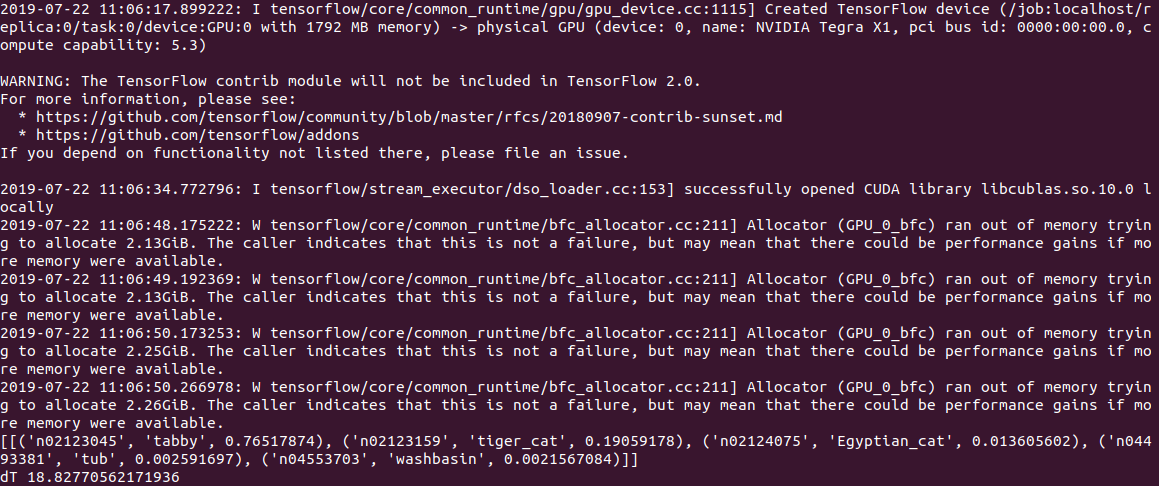
En general, incluso 3s por imagen, esto aún no es en tiempo real. Establecer la opción gpu_options.allow_growth recomendada en el desbordamiento de la pila no ayuda, si alguien conoce otra forma, escriba los comentarios.
Editar : como se sugiere en los comentarios, el primer inicio de tensorflow siempre lleva mucho tiempo, y es incorrecto medir el tiempo usándolo. De hecho, al procesar el segundo archivo y los posteriores, los resultados son mucho mejores: 0.6s sin una GPU y 0.2s con una GPU. En el escritorio, la velocidad es, sin embargo, 2.0s y 0.05s, respectivamente.
Una característica conveniente de ResNet50 es que, al principio, bombea todo el modelo al disco (aproximadamente 100 MB), luego el código funciona de manera completamente autónoma, sin registro ni SMS. Lo cual es especialmente bueno, dado que la mayoría de los servicios modernos de IA funcionan solo en el servidor, y sin Internet el dispositivo se convierte en una "calabaza".
Gatos vs perros
Considere el siguiente problema. Usando Keras, crearemos una red neuronal que pueda distinguir entre gatos y perros. Será una red neuronal convolucional (CNN - Red neuronal convolucional), tomaremos el diseño de red de
esta publicación. Ya se incluye un conjunto de imágenes de entrenamiento de gatos y perros en el paquete tensorflow_datasets, por lo que no tendrá que fotografiarlos usted mismo.
Cargamos un conjunto de imágenes y lo dividimos en tres bloques: capacitación, verificación y prueba. "Normalizamos" cada imagen, llevando los colores al rango 0..1.
import tensorflow as tf from tensorflow.keras import layers import tensorflow_datasets as tfds from keras.preprocessing import image import numpy as np import time IMAGE_SIZE = 64 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) splits = tfds.Split.TRAIN.subsplit(weighted=(80, 10, 10)) (cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True) label_names = info.features['label'].int2str def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0
Escribimos la función de generar una red neuronal convolucional.
def custom_model():
Ahora podemos ejecutar capacitación en red en nuestro kit "gato-perro". La capacitación lleva mucho tiempo (20 minutos en la GPU y 1-2 horas en la CPU), por lo que al final guardamos el modelo en un archivo.
tl_model = custom_model() t_start = time.time() tl_model.fit(train_batch, steps_per_epoch=8000, epochs=2, validation_data=validation_batch, validation_steps=10, callbacks=None) print("Training done, dT:", time.time() - t_start) print(tl_model.summary()) validation_steps = 20 loss0, accuracy0 = tl_model.evaluate(validation_batch, steps=validation_steps) print("Loss: {:.2f}".format(loss0)) print("Accuracy: {:.2f}".format(accuracy0)) tl_model.save("dog_cat_model.h5")
Por cierto, el intento de iniciar el entrenamiento directamente en el Jetson Nano falló: después de 5 minutos, el tablero se sobrecalentó y se colgó. Para los cálculos intensivos en recursos, se requiere un refrigerador para la placa, aunque en general, no tiene sentido hacer tales tareas directamente en Jetson Nano: el modelo se puede entrenar en una PC y el archivo guardado terminado se puede usar en Nano.
Aquí surgió otro obstáculo: la biblioteca de la versión 14 de tensowflow se instaló en la PC, y la última versión para Jetson Nano hasta ahora es 13. Y el modelo guardado en la versión 14 no se leyó en el 13, tuve que instalar las mismas versiones usando pip.
Finalmente, podemos cargar el modelo desde un archivo y usarlo para reconocer imágenes.
def predict_model(model, image_file): img = image.load_img(image_file, target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_arr = np.expand_dims(img, axis=0) result = model.predict_classes(img_arr) print("Result: {}, dT: {}".format(label_names(result[0][0]), time.time() - t_start)) model = tf.keras.models.load_model('dog_cat_model.h5') predict_model(model, "cat.png") predict_model(model, "dog1.png") predict_model(model, "dog2.png")
La foto del gato se usó de la misma manera, pero para la prueba del "perro" se usaron 2 imágenes:

El primero adivinó correctamente, y el segundo al principio tuvo errores y la red neuronal pensó que era un gato, tuve que aumentar el número de iteraciones de entrenamiento. Sin embargo, probablemente habría cometido un error la primera vez;)
El tiempo de ejecución en Jetson Nano resultó ser bastante pequeño: la primera foto se procesó en 0.3s, pero todas las siguientes fueron mucho más rápidas, aparentemente los datos se almacenan en la memoria caché.
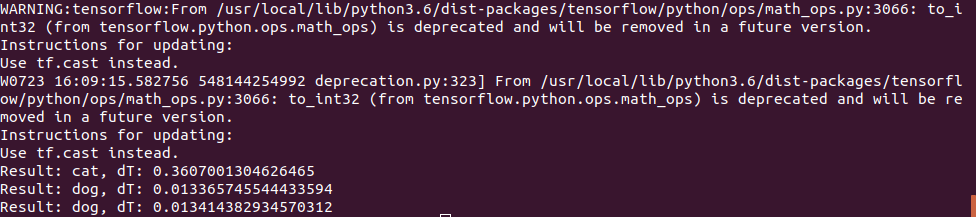
En general, podemos suponer que en redes neuronales tan simples la velocidad de la placa es suficiente incluso sin optimizaciones, 100 fps es un valor suficiente incluso para video en tiempo real.
Conclusión
Como puede ver, incluso los modelos estándar de Keras y Tensorflow se pueden usar en Nano, aunque con un éxito variable: algo funciona, algo no. Sin embargo, los resultados se pueden mejorar, las instrucciones para optimizar el modelo y reducir el tamaño de la memoria se pueden leer
aquí .
Pero afortunadamente para nosotros, los fabricantes ya lo han hecho por nosotros. Si los lectores aún tienen interés, la parte final estará dedicada a
las bibliotecas preparadas y optimizadas para trabajar con Jetson Nano.