
Se preparó la traducción del artículo para los estudiantes del curso "MS SQL Server Developer"
Las bases de datos relacionales son una de las bases de datos más utilizadas hasta el día de hoy y, por lo tanto , se requieren habilidades de SQL para la mayoría de las publicaciones. En este artículo, con las preguntas SQL de las entrevistas, le presentaré las preguntas más frecuentes sobre SQL (Lenguaje de consulta estructurado - Lenguaje de consulta estructurado). Este artículo es una guía ideal para explorar todos los conceptos relacionados con SQL, Oracle, MS SQL Server y la base de datos MySQL.
Nuestro artículo de preguntas SQL es un recurso universal con el que puede acelerar la preparación para una entrevista. Consiste en un conjunto de 65 de las preguntas más comunes que un entrevistador puede hacer durante una entrevista. Por lo general, comienza con preguntas básicas de SQL y luego pasa a preguntas más complejas basadas en la discusión y sus respuestas. Estas preguntas de la entrevista SQL lo ayudarán a maximizar sus beneficios en varios niveles de comprensión.
¡Empecemos!
Preguntas de la entrevista SQL
Pregunta 1. ¿Cuál es la diferencia entre DELETE y TRUNCATE?
No. Pregunta 2. ¿Cuáles son los subconjuntos de SQL?
- DDL (Lenguaje de definición de datos) : le permite realizar varias operaciones con la base de datos, como CREAR (crear), ALTERAR (cambiar) y DROP (eliminar objetos).
- DML (Lenguaje de manipulación de datos) : le permite acceder y manipular datos, por ejemplo, insertar, actualizar, eliminar y recuperar datos de una base de datos.
- DCL (lenguaje de control de datos) : le permite controlar el acceso a la base de datos. Un ejemplo es GRANT (otorgar derechos), REVOKE (revocar derechos).
Pregunta 3. ¿Qué se entiende por DBMS? ¿Qué tipos de DBMS hay?
La base de datos es una recopilación de datos estructurados. Sistema de gestión de bases de datos (DBMS): software que interactúa con el usuario, las aplicaciones y la propia base de datos para recopilar y analizar datos. El DBMS permite al usuario interactuar con la base de datos. Los datos almacenados en la base de datos se pueden modificar, recuperar y eliminar. Pueden ser de cualquier tipo, como cadenas, números, imágenes, etc.
Hay dos tipos de DBMS:
- Sistema de gestión de bases de datos relacionales: los datos se almacenan en relaciones (tablas). Un ejemplo es MySQL.
- Sistema de gestión de bases de datos no relacionales: no existe un concepto de relaciones, tuplas y atributos. Un ejemplo es Mongo.
Pregunta 4. ¿Qué se entiende por tabla y campo en SQL?
Una tabla es un conjunto de datos organizado en forma de filas y columnas. Un campo es una columna en una tabla. Por ejemplo:
Tabla: Información del alumno
Campo: Stu_Id, Stu_Name, Stu_Marks
Pregunta 5. ¿Qué son las combinaciones en SQL?
El operador JOIN se usa para unir filas de dos o más tablas en función de una columna conectada entre ellas. Se utiliza para unir dos tablas u obtener datos desde allí. Hay 4 tipos de conexión en SQL, a saber:
- Unión interna
- Únete a la derecha
- Izquierda unirse
- Únete completo
Pregunta 6. ¿Cuál es la diferencia entre los tipos de datos CHAR y VARCHAR en SQL?
Tanto Char como Varchar sirven como tipos de datos de caracteres, pero varchar se usa para cadenas de caracteres de longitud variable, mientras que Char se usa para cadenas de longitud fija. Por ejemplo, char (10) solo puede almacenar 10 caracteres y no puede almacenar una cadena de ninguna otra longitud, mientras que varchar (10) puede almacenar una cadena de cualquier longitud hasta 10, es decir. por ejemplo, 6, 8 o 2.
Pregunta 7. ¿Qué es una clave primaria?

- Una clave primaria es una columna o conjunto de columnas que identifica de forma exclusiva cada fila de una tabla.
- Identifica de forma exclusiva una fila en una tabla
- Valores nulos no permitidos
_Ejemplo: en la tabla Student Stu, la clave principal es.
Pregunta 8. ¿Qué son las restricciones?
Las restricciones se utilizan para indicar restricciones en el tipo de datos de una tabla. Se pueden especificar al crear o modificar una tabla. Restricciones de ejemplo:
- NO NULO
- VERIFICAR
- PREDETERMINADO
- ÚNICO
- CLAVE PRIMARIA
- CLAVE EXTRANJERA
Pregunta 9. ¿Cuál es la diferencia entre SQL y MySQL?
SQL es el lenguaje de consulta estructurado estándar basado en el idioma inglés, mientras que MySQL es un sistema de administración de bases de datos. SQL es un lenguaje de base de datos relacional que se utiliza para acceder y administrar datos, MySQL es un DBMS relacional (sistema de administración de bases de datos), así como SQL Server, Informix, etc.
Pregunta 10. ¿Qué es una clave única?
- Identifica de forma exclusiva una fila en una tabla.
- Se permiten muchas claves únicas en una tabla.
- Se permiten valores NULL ( nota de traducción: depende del DBMS; en SQL Server, NULL solo se puede agregar una vez en un campo con CLAVE ÚNICA ).
Pregunta 11. ¿Qué es una clave foránea?
- Una clave externa mantiene la integridad referencial al proporcionar un enlace entre los datos en dos tablas.
- La clave foránea en la tabla secundaria se refiere a la clave primaria en la tabla primaria.
- Una restricción de clave externa impide acciones que rompen las relaciones entre las tablas primaria y secundaria.
Pregunta 12. ¿Qué se entiende por integridad de datos?
La integridad de los datos determina la precisión y la consistencia de los datos almacenados en la base de datos. También define restricciones de integridad para hacer cumplir las reglas comerciales de los datos cuando se ingresan en una aplicación o base de datos.
Pregunta 13. ¿Cuál es la diferencia entre los índices agrupados y no agrupados en SQL?
- Diferencias entre los índices agrupados y no agrupados en SQL:
Un índice agrupado se usa para recuperar datos de una base de datos de manera fácil y rápida, mientras que la lectura de un índice no agrupado es relativamente más lenta. - Un índice agrupado cambia la forma en que se almacenan los registros en la base de datos: clasifica las filas por la columna que se establece como índice agrupado, mientras que en un índice no agrupado no cambia el método de almacenamiento, sino que crea un objeto separado dentro de la tabla que apunta a las filas de la tabla original durante la búsqueda.
- Una tabla puede tener solo un índice agrupado, mientras que puede tener muchos índices no agrupados.
Pregunta 14. Escriba una consulta SQL para mostrar la fecha actual.
SQL tiene una función incorporada GetDate () que ayuda a devolver la fecha y hora actual.
Pregunta 15. Enumere los tipos de conexiones
Existen varios tipos de combinaciones que se utilizan para extraer datos entre tablas. Básicamente, se dividen en cuatro tipos, a saber:
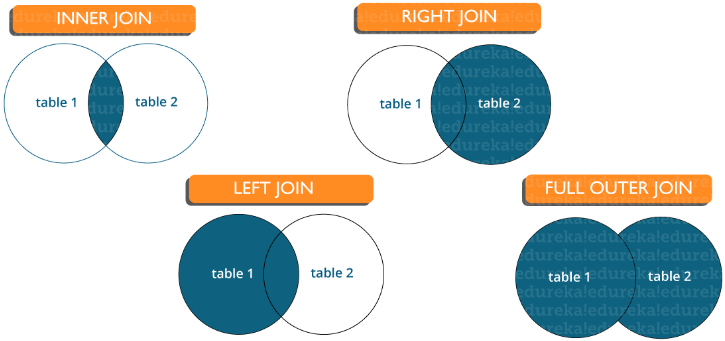
Unión interna : en MySQL, el tipo más común. Se utiliza para devolver todas las filas de varias tablas para las que se cumple la condición de unión.
Unión izquierda : en MySQL se utiliza para devolver todas las filas de la tabla izquierda (primera) y solo las filas coincidentes de la tabla derecha (segunda) para las que se cumple la condición de unión.
Unión derecha : en MySQL se usa para devolver todas las filas de la tabla derecha (segunda) y solo las filas coincidentes de la tabla izquierda (primera) para las que se cumple la condición de unión.
Unión completa : devuelve todos los registros para los que hay una coincidencia en cualquiera de las tablas. Por lo tanto, devuelve todas las filas de la tabla izquierda y todas las filas de la tabla derecha.
Pregunta 16. ¿Qué quiere decir con desnormalización?
La desnormalización es una técnica que se utiliza para convertir de formas normales más altas a más bajas. Ayuda a los desarrolladores de bases de datos a mejorar el rendimiento de toda la infraestructura al introducir redundancia en la tabla. Agrega datos redundantes a la tabla, dadas las frecuentes consultas a la base de datos que combinan datos de diferentes tablas en una sola tabla.
Pregunta 17. ¿Qué son las entidades y las relaciones?
Entidades: una persona, lugar u objeto en el mundo real, cuyos datos se pueden almacenar en una base de datos. Las tablas almacenan datos que representan un tipo de entidad. Por ejemplo, una base de datos bancaria tiene una tabla de clientes para almacenar la información del cliente. La tabla de clientes almacena esta información como un conjunto de atributos (columnas en la tabla) para cada cliente.
Relaciones: relaciones o relaciones entre entidades que de alguna manera están relacionadas entre sí. Por ejemplo, el nombre de un cliente está asociado con un número de cuenta de cliente e información de contacto, que puede estar en la misma tabla. También puede haber relaciones entre tablas individuales (por ejemplo, cliente a cuentas).
Pregunta 18. ¿Qué es un índice?
Los índices se refieren a un método de ajuste de rendimiento que le permite recuperar registros de una tabla más rápido. El índice crea una estructura separada para el campo indexado y, por lo tanto, permite una recuperación de datos más rápida.
Pregunta 19. Describa los diferentes tipos de índices.
Hay tres tipos de índices, a saber:
- Índice único: este índice evita que el campo tenga valores duplicados si la columna se indexa de forma exclusiva. Si se define una clave primaria, se puede aplicar automáticamente un índice único.
- Índice agrupado: este índice cambia el orden físico de la tabla y las búsquedas en función de los valores clave. Cada tabla solo puede tener un índice agrupado.
- Índice no agrupado: no cambia el orden físico de la tabla y mantiene el orden lógico de los datos. Cada tabla puede tener muchos índices no agrupados.
Pregunta 20. ¿Qué es la normalización y cuáles son sus ventajas?
La normalización es el proceso de organización de datos, cuyo propósito es evitar la duplicación y la redundancia. Algunos de los beneficios:
- Mejor organización de base de datos
- Más mesas con pequeñas filas.
- Acceso efectivo a datos
- Mayor flexibilidad para consultas.
- Búsqueda rápida de información
- Más fácil de implementar seguridad de datos
- Permite una fácil modificación
- Reduce datos redundantes y duplicados
- Base de datos más compacta
- Garantiza la coherencia de los datos después de los cambios.
Pregunta 21. ¿Cuál es la diferencia entre DROP y TRUNCATE?
El comando DROP elimina la tabla en sí, y no puede ejecutar los comandos Rollback, mientras que el comando TRUNCATE elimina todas las filas de la tabla ( nota de traducción: en SQL Server, Rollback normalmente funcionará y retrocederá DROP ).
Pregunta 22. Explique los diferentes tipos de normalización.
Hay muchos niveles consecutivos de normalización. Estas son las llamadas formas normales. Cada forma normal posterior incluye la anterior. Las tres primeras formas normales suelen ser suficientes.
- Primera forma normal (1NF) : no hay grupos duplicados en filas
- La segunda forma normal (2NF) : cada valor de columna sin clave (de soporte) depende de la clave primaria completa
- Tercera forma normal (3NF) : cada valor no clave depende solo de la clave primaria y no depende de otro valor no clave de la columna
Pregunta 23. ¿Cuál es la propiedad ACID en la base de datos?
ACID significa atomicidad, consistencia, aislamiento, durabilidad. Se utiliza para proporcionar un procesamiento confiable de transacciones de datos en un sistema de base de datos.
Atomicidad Asegura que la transacción se complete por completo o falle, donde la transacción representa una única operación de datos lógicos. Esto significa que si una parte de cualquier transacción falla, la transacción completa falla y el estado de la base de datos permanece sin cambios.
Coherencia Asegura que los datos deben cumplir con todas las reglas de validación. En pocas palabras, puede decir que su transacción nunca dejará su base de datos en un estado no válido.
Aislamiento El objetivo principal del aislamiento es controlar el mecanismo de los cambios de datos paralelos.
Longevidad La durabilidad implica que si se confirmó la transacción (COMMIT), los cambios que ocurrieron dentro de la transacción se conservarán independientemente de lo que se interponga en su camino (por ejemplo, pérdida de energía, fallas o errores de cualquier tipo).
Pregunta 24. ¿Qué quiere decir con un "disparador" en SQL?
Un disparador en SQL es un tipo especial de procedimiento almacenado que está diseñado para ejecutarse automáticamente cuando o después de los cambios de datos. Esto le permite ejecutar un paquete de código cuando se realiza una inserción, actualización o cualquier otra consulta en una tabla específica.
Pregunta 25. ¿Qué declaraciones están disponibles en SQL?
Hay tres tipos de declaraciones disponibles en SQL, a saber:
- Operadores aritméticos
- Operadores lógicos
- Operadores de comparación
Pregunta 26. ¿Los valores NULL coinciden con cero o espacio?
NULL no es cero o espacio en absoluto. Un valor NULL representa un valor que no está disponible, desconocido, asignado o no aplicable, mientras que cero es un número y el espacio es un carácter.
Pregunta 27. ¿Cuál es la diferencia entre una unión cruzada y una unión natural?
Una unión cruzada crea un producto cruzado o cartesiano de dos tablas, mientras que una unión natural se basa en todas las columnas que tienen el mismo nombre y tipos de datos en ambas tablas.
Pregunta 28. ¿Qué es una subconsulta en SQL?
Una subconsulta es una consulta dentro de otra consulta que define una consulta para recuperar datos o información de una base de datos. En una subconsulta, la consulta externa se denomina consulta principal, mientras que la consulta interna se denomina subconsulta. Las subconsultas siempre se ejecutan primero, y el resultado de la subconsulta se pasa a la consulta principal. Se puede anidar en SELECT, UPDATE o cualquier otra consulta. Una subconsulta también puede usar cualquier operador de comparación, como>, <o =.
Pregunta 29. ¿Cuáles son los tipos de subconsultas?
Hay dos tipos de subconsultas, a saber: correlacionadas y no correlacionadas.
- Subconsulta correlacionada: esta es una consulta que selecciona datos de una tabla con un enlace a una consulta externa. No se considera una consulta independiente porque se refiere a otra tabla o columna en la tabla.
- Subconsulta no correlacionada: esta consulta es una consulta independiente en la que la salida de la subconsulta se sustituye por la consulta principal.
Pregunta 30. ¿Enumera las formas de obtener el número de registros en la tabla?
Para contar el número de registros en una tabla, puede usar los siguientes comandos:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Publicaremos otras 35 preguntas con respuestas en la siguiente parte ... ¡Sigue las noticias!