
Hola, soy Andrey Shalnev, líder de automatización de control de calidad en el proyecto Skyeng Vimbox. A lo largo del año, el equipo y yo nos dedicamos a optimizar los procesos de prueba automática y ahora estamos muy cerca de su etapa final. Y esta es una buena razón para exhalar, revisar el trabajo atrasado y tomar algunos resultados intermedios. Para Habra, decidí hacer una selección de las diez cosas más útiles y al mismo tiempo simples que nos ayudaron a hacer frente a la tarea de optimizar las pruebas automáticas. Espero que el artículo sea útil para los equipos de control de calidad en empresas en crecimiento, donde los viejos procesos de prueba ya no pueden hacer frente a la carga, y el problema de la reorganización plantea la ventaja.
Cómo organizamos las pruebas automáticas
Vimbox usa Angular para la interfaz, por lo que escribimos pruebas en una pila bastante clásica para esta solución: Protractor + Jasmine + JS / Typecript. Durante el año, rediseñamos significativamente el conjunto de pruebas de regresión. En su forma inicial, era redundante y no muy conveniente: pruebas de varios cientos de líneas con un tiempo de paso de 5-10 minutos, con una longitud de secuencia de comandos de prueba por separado, a menudo no llega al final debido a un archivo falso. Ahora hemos dividido las pruebas en escenarios más cortos y más estables, usamos failFast para que el tiempo de ejecución sea aceptable (una prueba que se bloquea en el medio no intentará completar cada próximo paso y esperará a que se agote el tiempo). Además, nos deshicimos de las verificaciones redundantes: nos aseguramos de que una característica específica sea funcional en general, pero no intentamos verificarla en todas las variaciones posibles.
Las pruebas automáticas tienen prioridad. Un pequeño conjunto de prioridades, la prueba de aceptación del usuario (UAT), se ejecuta cada hora en el producto, después del despliegue de los proyectos principales y cuando se prueban tareas en bancos de pruebas.
El proceso en los stands se ve así: el desarrollador transfiere la tarea a las pruebas, QA la implementa en su stand y ejecuta las pruebas, tanto UAT como regresión. En UAT, tenemos alrededor de 150 casos, regresión, alrededor de 700 pruebas, se actualiza constantemente. La mayoría de los casos que son importantes y críticos, esta suite cubre aproximadamente el 80% y se ejecuta en cada iteración.
Diez trucos de la vida
Especifique explícitamente el rol de la instancia del navegador . La especificidad de las pruebas de Vimbox es que en la gran mayoría de los casos se usan dos o más instancias del navegador, ya que la lección tiene al menos dos lados: un maestro y un estudiante. Solía haber un problema: una instancia del navegador se indicaba con un número, se entendía que todos entendían que el browser1 era un maestro, y el browser2 y más allá eran estudiantes. Pero este no es siempre el caso, sucedió que el navegador del estudiante fue el primero. Además, hay pruebas en las que los estudiantes mismos son diferentes; por ejemplo, debemos asegurarnos de que no pueda ingresar accidentalmente a la lección de otra persona. Para dejar en claro a todos qué usuario se encuentra en qué instancia del navegador, comenzaron a indicar explícitamente el rol en su nombre: teacher.browser , wrongStudent.browser , wrongStudent.browser , etc. Tengo guiones de prueba más legibles.
Utilizamos funciones de flecha: () => , no function() . En primer lugar, ese registro es más corto. En segundo lugar, una sintaxis más moderna, tratamos de alejarnos de lo arcaico. Tercero, las funciones de flecha evitan problemas con this puntero desde JavaScript. La función de flecha no crea su alcance léxico , por lo que es posible hacer referencia a algo definido fuera de this . Deshágase de la clásica muleta self = this .
Utilizamos cadenas de plantilla en lugar de concatenaciones con más: `Student $ {studentName}`, y no "Student" + studentName . Intentamos usar cadenas de patrones en lugar de concatenaciones con más.
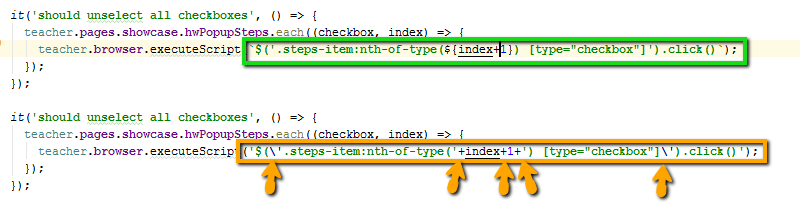
Esta es una sintaxis moderna, es más legible, ambos tipos de comillas (simple y doble) se pueden usar dentro de la cadena y no se pueden filtrar.
Usamos TypeScript . Principalmente en aras de sugerencias de entorno de desarrollo más adecuadas y navegación de código normal. Ahora, en la mayoría de los casos, en lugar de algunos consejos, es posible una transición directa al método / campo. Al mismo tiempo, cambiar a TypeScript no requirió mucha refactorización al mismo tiempo: para empezar, simplemente puede cambiar las extensiones de archivo de .js a .ts, el proyecto sigue siendo viable. Luego cambie gradualmente la sintaxis de require para Import , se mejora la navegación.
Divida los Objetos de página grandes en subclases para facilitar el mantenimiento de dichos objetos. Nuestra mayor lección de Objeto de página alcanzó cuatro mil líneas de código, fue difícil hojearla, recuerda lo que comenzó, lo que no. Ahora el código más largo es de aproximadamente 1300 líneas. Podemos decir que al hacerlo nos deshicimos de la gran clase antipatrón. Además, eliminaron comentarios innecesarios y trabajaron en la conveniencia y la comprensión de los nombres de los métodos: en la mayoría de los casos, si el método se nombra de acuerdo con la convención clara para todos, simplemente no es necesario un comentario que explique su trabajo.
Ejecutamos la UAT en paralelo en varios subprocesos para facilitar el trabajo con la UAT en el producto. El hecho es que con nosotros dicha prueba se ejecuta una vez por hora y se ejecuta en un hilo durante 15 minutos. Si ocurre un archivo en él, se reiniciará y al final funcionará durante media hora. Durante una implementación, esto puede ser un problema porque la cola se retrasa. El resultado de usar el paralelo es 2-3 minutos en el UAT (o 6 con un reinicio). La cola se mueve más rápido, la información sobre el problema o que el archivo resultó ser falso llega más rápido.
Regularmente ejecutamos UAT y regresión en bancos de prueba . Cada uno de nuestros probadores manuales tiene su propio servidor. Solíamos ejecutar pruebas de regresión en prod después de que el probador manual encontrara una parte significativa de los errores; de hecho, simplemente lo verificamos. Ahora ejecutamos pruebas automáticas en cada iteración de la prueba manual de la tarea, que, en primer lugar, facilita el trabajo de un probador manual (no necesita perforar lo que es automáticamente), y en segundo lugar, acorta el ciclo de retroalimentación. Si el desarrollador ha roto algo, lo sabrá media hora después de implementar la tarea, y no al día siguiente. Además, en el banco de pruebas puede hacer muchas cosas que no son deseables en la producción: cambiar el número de versión del producto, eliminar / agregar contenido de prueba, editar sin miedo la base de datos para preparar la situación de prueba, etc.
Eliminar archivos vacíos . Intentamos mantener la coherencia entre la estructura de directorios en las pruebas automáticas y en Testrail. Pero al mismo tiempo, en algún momento nos encontramos con un problema: en Testrail hay una gran cantidad de casos con baja prioridad (solo alrededor de 9000+ casos), porque Se utiliza como base de conocimiento del proyecto. Al mismo tiempo, solo alrededor de mil de los casos más importantes están cubiertos con autotest. Si logramos una coincidencia perfecta, obtenemos una gran cantidad de archivos y directorios no utilizados. Esto complica la navegación del proyecto y dificulta la comprensión de lo que realmente se está probando. Como resultado, solo quedaron las carpetas y archivos necesarios, el resto se eliminó.
Arreglamos los errores encontrados . La tarea principal de las pruebas automáticas no es encontrar errores, sino asegurarse rápidamente de que no están allí, por lo que rara vez se detecta algo. La fijación resuelve dos problemas: en primer lugar, vemos estadísticas donde los problemas persisten con mayor frecuencia y cuáles, y en segundo lugar, nos deshacemos de la sensación de que estamos haciendo algo mal. Cuando las pruebas no encuentran nada, surge la pregunta: ¿estamos haciendo todo bien, tal vez nuestras pruebas no sirvan? Y luego hay una tableta que muestra que cuando pudieron atrapar: más de 60 errores por año. Al mismo tiempo, el significado de ejecutar pruebas en servidores de prueba y prod se hizo evidente. El lanzamiento frecuente en el producto, cada hora, ayuda a detectar problemas de infraestructura (un servicio externo no está disponible, nuestro servidor se apagó), el lanzamiento antes de las pruebas manuales detecta averías introducidas por el nuevo código.
Se implementaron los atributos data-qa-id , por ejemplo, [data-qa-id="btn-login"] . Propósito: selectores más estables. Acordamos con el equipo de desarrollo que si cambia la implementación de algunos elementos, si ven el atributo data-qa-id allí, entonces entienden que esto es para las pruebas automáticas, no lo cambian y lo transfieren con precisión. Este atributo tiene un nombre lógico, que en sí mismo puede determinar de qué es responsable el elemento. Además, no dependemos de la implementación específica del elemento: qué identificación ordinaria depende de él, qué clase, etiqueta, diferencial, enlace depende de él. Se volvió más tranquilo: los selectores se rompen con menos frecuencia, en algunos casos se puede mostrar información adicional con este atributo. Por ejemplo, necesita el nombre de un paso en una lección. Si recurre al nombre del paso a través de XPath, el selector puede resultar largo, multinivel y de baja lectura, y si trabaja con la plantilla html en el código Angular, puede mostrar el mismo nombre en un atributo comprensible corto, evitando el XPath largo.
¡Comparte tus trucos y pensamientos en los comentarios!