
Continuamos publicando análisis de las tareas que se propusieron en el reciente campeonato. A continuación se encuentran las tareas tomadas de la ronda de calificación para especialistas en aprendizaje automático. Esta es la tercera pista de cuatro (backend, frontend, ML, analytics). Los participantes debían hacer un modelo para corregir errores tipográficos en los textos, proponer una estrategia para jugar en máquinas tragamonedas, recordar un sistema de recomendaciones de contenido y componer varios programas más.
A. Typos
Condición
(epígrafe) (de un foro)
- ¿Quién compuso estas tonterías?
- Astrofísicos. Ellos también son personas.
- Cometiste 10 errores en la palabra "periodistas".
Muchos usuarios cometen errores de tipeo, algunos por presionar teclas y otros por analfabetismo. Queremos verificar si el usuario podría tener en mente otra palabra que no sea la que escribió.
Más formalmente, suponga que se produce el siguiente modelo de error: el usuario comienza con una palabra que quiere escribir y luego comete una serie de errores. Cada error es una sustitución de alguna subcadena de la palabra por otra subcadena. Un error corresponde a reemplazar solo en una posición (es decir, si el usuario quiere cometer un solo error por la regla "abc" → "cba", entonces de la cadena "abcabc" puede obtener "cbaabc" o "abccba"). Después de cada error, el proceso se repite. La misma regla podría usarse varias veces en diferentes pasos (por ejemplo, en el ejemplo anterior, "cbacba" podría obtenerse en dos pasos).
Es necesario determinar el número mínimo de errores que un usuario podría cometer si tuviera en mente una palabra determinada y escribiera otra.
Formatos de E / S y ejemploFormato de entrada
La primera línea contiene la palabra, que, según nuestra suposición, el usuario tenía en mente (consiste en letras del alfabeto latino en minúsculas, la longitud no excede de 20).
La segunda línea contiene la palabra que realmente escribió (también consta de letras del alfabeto latino en minúsculas, la longitud no excede de 20).
La tercera línea contiene un solo número N (N <50): el número de reemplazos que describen varios errores.
Las siguientes N líneas contienen posibles reemplazos en el formato & lt secuencia de letras "correcta" y gt <espacio> <secuencia de letras "errónea">. Las secuencias no tienen más de 6 caracteres.
Formato de salida
Se requiere imprimir un número: el número mínimo de errores que el usuario podría cometer. Si este número excede 4 o es imposible obtener otro de una palabra, imprima -1.
Ejemplo
Solución
Intentemos generar de la ortografía correcta todas las palabras posibles con no más de 4 errores. En el peor de los casos, puede haber O ((L﹒N)
4 ). En las limitaciones del problema, este es un número bastante grande, por lo que debe descubrir cómo reducir la complejidad. En su lugar, puede usar el algoritmo de encuentro en el medio: genere palabras con no más de 2 errores, así como palabras de las que puede obtener una palabra escrita por el usuario, cometiendo no más de 2 errores. Tenga en cuenta que el tamaño de cada uno de estos conjuntos no excederá de 10
6 . Si el número de errores cometidos por el usuario no supera los 4, estos conjuntos se intersectarán. Del mismo modo, podemos verificar que el número de errores no exceda de 3, 2 y 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
B. Bandido de muchos brazos
Condición
Esta es una tarea interactiva.
Usted mismo no sabe cómo sucedió, pero se encontró en una sala con máquinas tragamonedas con una bolsa llena de fichas. Desafortunadamente, en la taquilla, se niegan a aceptar los tokens y decidiste probar suerte. Hay muchas máquinas tragamonedas en el pasillo que puedes jugar. Para un juego con una máquina tragamonedas, usa una ficha. En caso de ganar, la máquina le da un dólar, en caso de pérdida, nada. Cada máquina tiene una probabilidad fija de ganar (que no conoce), pero es diferente para diferentes máquinas. Después de estudiar el sitio web del fabricante de estas máquinas, descubrió que la probabilidad de ganar para cada máquina se selecciona aleatoriamente en la etapa de fabricación a partir de la
distribución beta con ciertos parámetros.
Desea maximizar sus ganancias esperadas.
Formatos de E / S y ejemploFormato de entrada
Una ejecución puede consistir en varias pruebas.
Cada prueba comienza con el hecho de que su programa en la línea contiene dos enteros separados por un espacio: el número N es el número de fichas en su bolsa y M es el número de máquinas en el pasillo (N ≤ 10
4 , M ≤ min (N, 100) ) La siguiente línea contiene dos números reales α y β (1 ≤ α, β ≤ 10): los parámetros de la distribución beta de la probabilidad de ganar.
El protocolo de comunicación con el sistema de verificación es el siguiente: realiza exactamente N solicitudes. Para cada solicitud, imprima en una línea separada el número de la máquina que jugará (de 1 a M inclusive). Como respuesta, en una línea separada habrá "0" o "1", lo que significa, respectivamente, una pérdida y una victoria en un juego con la máquina tragamonedas solicitada.
Después de la última prueba, en lugar de los números N y M, habrá dos ceros.
Formato de salida
La tarea se considerará completada si su decisión no es mucho peor que la decisión del jurado. Si su decisión es significativamente peor que la decisión del jurado, recibirá el veredicto "respuesta incorrecta".
Se garantiza que si su decisión no es peor que la decisión del jurado, entonces la probabilidad de recibir el veredicto de "respuesta incorrecta" no excede de
10-6 .
Notas
Ejemplo de interacción:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
Solución
Este problema es bien conocido, podría resolverse de diferentes maneras. La decisión principal del jurado implementó la estrategia de
muestreo de Thompson , pero dado que el número de pasos se conocía al comienzo del programa, existen estrategias más óptimas (por ejemplo, UCB1). Además, uno podría incluso pasar con la estrategia épsilon-codiciosa: con cierta probabilidad ε jugar una máquina aleatoria y con una probabilidad (1 - ε) jugar una máquina con las mejores estadísticas de victoria.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. Alineación de oraciones
Condición
Una de las tareas más importantes para entrenar un buen modelo de traducción automática es un buen caso de oraciones paralelas. Por lo general, la fuente de ofertas paralelas son los documentos paralelos. Resulta que, a menudo, para construir un cierto corpus de oraciones paralelas, no necesita saber nada más que su longitud. En particular, puede notar que cuanto más larga sea la oración en el idioma de origen, más probablemente será traducida. Cierta dificultad radica en el hecho de que durante la traducción el número de oraciones en el texto puede cambiar: a veces dos oraciones adyacentes en la traducción se pueden combinar en una, o viceversa: una oración se puede dividir en dos. En algunos casos raros, las oraciones pueden omitirse por completo en una traducción, o una traducción puede aparecer en una traducción que no estaba en el original.
Más formalmente, suponga que el siguiente modelo generativo para recintos paralelos es verdadero. En cada paso, hacemos uno de los siguientes:
1. PararCon probabilidad p
h, finaliza
la generación de cascos.
2. [1-0] Saltar ofertasCon probabilidad p
d, atribuimos una oración al texto original. No atribuimos nada a la traducción. La longitud de la oración en el idioma original L ≥ 1 se selecciona de la distribución discreta:
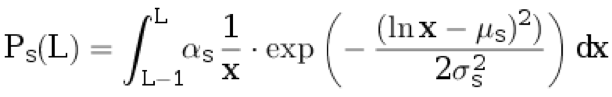
.
Aquí
μ s ,
σ s son los parámetros de distribución, y
α s es el coeficiente de normalización elegido para que

.
3. [0-1] Insertar propuestaCon probabilidad p
i asignamos una oración a la traducción. No atribuimos nada al original. La longitud de una oración en un idioma de traducción L ≥ 1 se selecciona de una distribución discreta:

.
Aquí
μ t ,
σ t son los parámetros de distribución, y
α t es el coeficiente de normalización elegido para que

.
4. TraducciónCon probabilidad (1 - p
d - p
i - p
h ) tomamos la longitud de la oración en el idioma original L
s ≥ 1 de la distribución p
s (con redondeo). A continuación, generamos la longitud de la oración en el lenguaje de traducción L
t ≥ 1 a partir de la distribución discreta condicional:
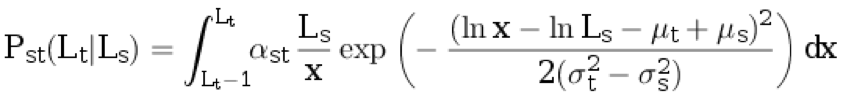
.
Aquí,
α st es el coeficiente de normalización, y los parámetros restantes se describen en los párrafos anteriores.
El siguiente es otro paso:
1. [2-1] Con probabilidad p
dividida s, la oración generada en el idioma original se divide en dos no vacías, de modo que el número total de palabras
aumenta exactamente en una . La probabilidad de que una oración de longitud L
s se separe en partes de longitud L
1 y L
2 (es decir, L
1 + L
2 = L
s + 1) es proporcional a P
s (L
1 ) ⋅ P
s (L
2 ).
2. [1-2] Con la probabilidad p
dividida t, la oración generada en el idioma de destino se divide en dos oraciones no vacías, de modo que el número total de palabras aumenta exactamente en una. La probabilidad de que una oración de longitud L
t se separe en partes de longitud L1 y L2 (es decir, L
1 + L
2 = L
t + 1) es proporcional a P
t (L
1 ) ⋅ P
t (L
2 ).
3. 3. [1-1] Con una probabilidad de (1 - p
dividido s - p
dividido t ), ninguno de los par de oraciones generadas decaerá.
Formatos de E / S, ejemplos y notasFormato de entrada
La primera línea del archivo contiene los parámetros de distribución: p
h , p
d , p
i , p
split s , p
split t , μ
s , σ
s , μ
t , σ
t . 0.1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s , μ
t ≤ 5.
La siguiente línea contiene los números N
sy N
t : el número de oraciones en el caso en el idioma original y en el idioma de destino, respectivamente (1 ≤ N
s , N
t ≤ 1000).
La siguiente línea contiene N
s enteros: la longitud de las oraciones en el idioma original. La siguiente línea contiene N
t enteros: la longitud de las oraciones en el idioma de destino.
La siguiente línea contiene dos números: j y k (1 ≤ j ≤ N
s , 1 ≤ k ≤ N
t ).
Formato de salida
Se requiere derivar la probabilidad de que las oraciones con los índices j y k en los textos, respectivamente, sean paralelas (es decir, que se generan en un paso del algoritmo y ninguna de ellas es el resultado de la descomposición).
Su respuesta será aceptada si el error absoluto no excede de 10 a
4 .
Ejemplo 1
Ejemplo 2
Ejemplo 3
Notas
En el primer ejemplo, la secuencia inicial de números se puede obtener de tres maneras:
• Primero, con probabilidad p
d agregue una oración al texto original, luego con probabilidad p agrego una oración a la traducción, luego con probabilidad p
h termine la generación.
La probabilidad de este evento es P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• Primero, con probabilidad p
d agregue una oración al texto original, luego con probabilidad p agrego una oración a la traducción, luego con probabilidad p
h termine la generación.
La probabilidad de este evento es igual a P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• Con probabilidad (1 - p
h - p
d - p
i ) generar dos oraciones, luego con probabilidad (1 - p
dividir s - p
dividir t ) dejar todo como está (es decir, no dividir el original o la traducción en dos oraciones ) y después de eso con probabilidad p
h terminar la generación.
La probabilidad de este evento es

.
Como resultado, la respuesta se calcula como

.
Solución
La tarea es un caso especial de alineación utilizando modelos ocultos de Markov (alineación HMM). La idea principal es que puede calcular la probabilidad de generar un par específico de documentos utilizando este modelo y
el algoritmo de reenvío : en este caso, el estado es un par de prefijos de documentos. En consecuencia, la probabilidad requerida de alineación de un par específico de oraciones paralelas puede calcularse mediante el algoritmo de
avance hacia atrás .
Código #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
D. Cinta de recomendaciones
Condición
Considere una fuente de recomendaciones para contenido heterogéneo. Mezcla objetos de varios tipos (imágenes, videos, noticias, etc.). Estos objetos generalmente están ordenados por relevancia para el usuario: cuanto más relevante (interesante) sea el objeto para el usuario, más cerca estará al principio de la lista de recomendaciones. Sin embargo, con este orden, a menudo surgen situaciones en las que varios objetos del mismo tipo aparecen en la lista de recomendaciones. Esto empeora en gran medida la variedad externa de nuestras recomendaciones y, por lo tanto, a los usuarios no les gusta. Es necesario implementar un algoritmo que, de acuerdo con la lista de recomendaciones, constituirá una nueva lista que estará libre de este problema y será más relevante.
Sea una lista inicial de recomendaciones a = [a
0 , a
1 , ..., a
n - 1 ] de longitud n> 0. Un objeto con número i tiene tipo con número b
i b {0, ..., m - 1}. Además, un objeto bajo el número i tiene relevancia r (a
i ) = 2
−i . Considere la lista que se obtiene de la inicial eligiendo un subconjunto de objetos y su permutación: x = [a
i 0 , a
i 1 , ..., a
i k - 1 ] de longitud k (0 ≤ k ≤ n). Una lista se llama admisible si no coinciden dos objetos consecutivos en ella, es decir, b
i j ≠ b
i j + 1 para todo j = 0, ..., k - 2. La relevancia de la lista se calcula mediante la fórmula.
. Necesita encontrar la lista de relevancia máxima entre todas las válidas.
Formatos de E / S y ejemplosFormato de entrada
En la primera línea, los números n y m se escriben con un espacio (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). Las siguientes n líneas contienen los números b
i para i = 0, ..., n - 1 (0 ≤ b
i ≤ m - 1).
Formato de salida
Escriba, con un espacio, el número de objetos en la lista final: i
0 , i
1 , ..., i
k - 1 .
Ejemplo 1
Ejemplo 2
Ejemplo 3
Solución
Utilizando cálculos matemáticos simples, se puede demostrar que el problema se puede resolver mediante un enfoque "codicioso", es decir, en la lista óptima de recomendaciones, cada elemento tiene el objeto más relevante de todos los que son válidos al mismo comienzo de la lista. La implementación de este enfoque es simple: tomamos objetos en una fila y los agregamos a la respuesta, si es posible. Cuando se encuentra un objeto no válido (cuyo tipo coincide con el tipo del anterior), lo ponemos a un lado en una cola separada, desde la cual lo insertamos en la respuesta lo antes posible. Tenga en cuenta que en todo momento, todos los objetos en esta cola tendrán un tipo coincidente. Al final, varios objetos pueden permanecer en la cola, ya no se incluirán en la respuesta.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. Clusterización de secuencias de caracteres.
Hay un alfabeto finito A = {a
1 , a
2 , ..., a
K - 1 , a
K = S}, a
i ∈ {a, b, ..., z}, S es el final de la línea.
Considere el siguiente método para generar cadenas aleatorias sobre el alfabeto A:
1. El primer carácter x
1 es una variable aleatoria con la distribución P (x
1 = a
i ) = q
i (se sabe que q
K = 0).
2. Cada siguiente carácter se genera en base al anterior de acuerdo con la distribución condicional P (x
i = a
j || x
i - 1 = a
l ) = p
jl .
3. Si x
i = S, la generación se detiene y el resultado es x
1 x
2 ... x
i - 1 .
Se da el conjunto de líneas generadas a partir de una mezcla de dos modelos descritos con diferentes parámetros. Es necesario que cada fila proporcione el índice de la cadena a partir de la cual se generó.
Formatos de E / S, ejemplo y notasFormato de entrada
La primera línea contiene dos números 1000 ≤ N ≤ 2000 y 3 ≤ K ≤ 27: el número de líneas y el tamaño del alfabeto, respectivamente.
La segunda línea contiene una línea que consta de K - 1 letras minúsculas diferentes del alfabeto latino, que indican los primeros elementos K - 1 del alfabeto.
Cada una de las siguientes N líneas se genera de acuerdo con el algoritmo descrito en la condición.
Formato de salida
N líneas, la línea i-ésima contiene el número de clúster (0/1) para la secuencia en la línea i + 1-th del archivo de entrada. La coincidencia con la respuesta verdadera debe ser al menos del 80%.
Ejemplo
Notas
Nota para la prueba de la condición: en ella se generan las primeras 50 líneas de la distribución
P (x
i = a | x
i - 1 = a) = 0.5, P (x
i = S | x
i - 1 = a) = 0.5, P (x
1 = a) = 1; segundo 50 - de distribución
P (x
i = b | x
i - 1 = b) = 0.5, P (x
i = S | x
i - 1 = b) = 0.5, P (x
1 = b) = 1.
Solución
El problema se resuelve utilizando el
algoritmo EM : se supone que la muestra presentada se genera a partir de una mezcla de dos cadenas de Markov cuyos parámetros se restauran durante las iteraciones. Se realiza una restricción del 80% de las respuestas correctas para que la corrección de la solución no se vea afectada por ejemplos que tienen una alta probabilidad en ambas cadenas. Por lo tanto, estos ejemplos, cuando se restauran correctamente, se pueden asignar a una cadena que es incorrecta en términos de la respuesta generada.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.