Como sabe, los índices juegan un papel importante en el DBMS, proporcionando una búsqueda rápida de los registros necesarios. Por lo tanto, es muy importante atenderlos de manera oportuna. Se ha escrito una gran cantidad de material sobre análisis y optimización, incluso en Internet. Por ejemplo, se realizó una revisión reciente de este tema en
esta publicación .
Hay muchas soluciones pagas y gratuitas para esto. Por ejemplo, hay una
solución llave en mano basada en un método de optimización de índice adaptativo.
A continuación, considere la utilidad gratuita
SQLIndexManager , creada por
AlanDenton .
La diferencia técnica principal entre SQLIndexManager y varios otros análogos es hecha por el autor
aquí y
aquí .
En el mismo artículo, analizamos el proyecto y las posibilidades de usar esta solución de software.
Discuta esta utilidad
aquí .
Con el tiempo, la mayoría de los comentarios y errores han sido corregidos.
Entonces, ahora pasemos a la utilidad SQLIndexManager.
La aplicación está escrita en C # .NET Framework 4.5 en Visual Studio 2017 y usa DevExpress para formularios:
y se ve así:
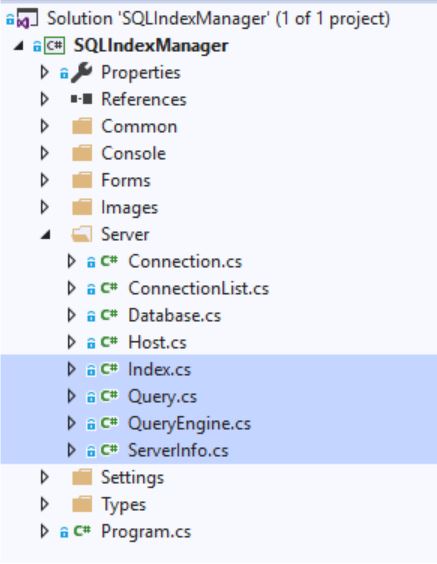
Todas las solicitudes se generan en los siguientes archivos:
- Indice
- Consulta
- Queryengine
- ServerInfo
Al conectarse a la base de datos y enviar solicitudes al DBMS, la aplicación se firma de la siguiente manera:
ApplicationName=”SQLIndexManager”
Cuando se inicia la aplicación, se abre una ventana modal para agregar una conexión:
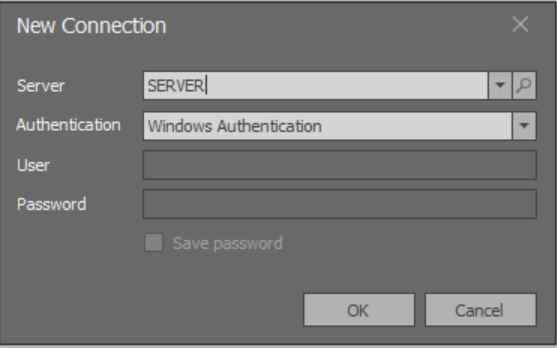
Aquí la carga de la lista completa de todas las instancias de MS SQL Server disponibles en redes locales todavía no funciona.
También puede agregar una conexión con el botón situado más a la izquierda en el menú principal:
A continuación, se lanzarán las siguientes consultas DBMS:
Obtención de información DBMS SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
Obtener una lista de bases de datos disponibles con sus breves propiedades SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
Después de ejecutar los scripts anteriores, aparece una ventana que contiene información breve sobre las bases de datos de la instancia seleccionada de MS SQL Server:
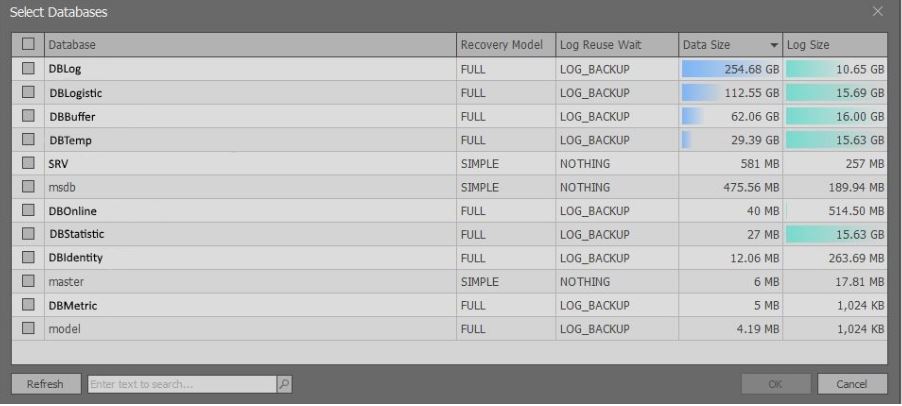
Vale la pena señalar que la información extendida se muestra en función de los derechos. Si hay
sysadmin , puede seleccionar datos de la
vista sys.master_files . Si no existen tales derechos, se devuelven menos datos para no ralentizar la solicitud.
Aquí debe seleccionar la base de datos de interés y hacer clic en el botón "Aceptar".
A continuación, se ejecutará el siguiente script para cada base de datos seleccionada para analizar el estado de los índices:
Análisis de estado del índice declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
Como puede ver en las consultas, a menudo se usan tablas temporales. Esto se hace para que no haya recompilación, y en el caso de un esquema grande, el plan podría generarse en paralelo al insertar datos, ya que la inserción con variables de tabla es posible en una sola secuencia.
Después de ejecutar el script anterior, aparecerá una ventana con la tabla de índice:

Aquí también puede mostrar otra información detallada, como:
- una base de datos
- número de secciones
- fecha y hora de la última llamada
- compresión
- grupo de archivos
etc.
Las columnas en sí se pueden personalizar:
En las celdas de la columna Fix, puede elegir qué acción se realizará durante la optimización. Además, cuando se completa el escaneo, la acción predeterminada se selecciona en función de la configuración seleccionada:
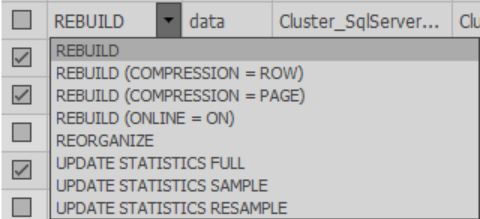
Debe seleccionar los índices deseados para el procesamiento.
Usando el menú principal, puede guardar el script (el mismo botón inicia el proceso de optimización del índice):
guarde la tabla en diferentes formatos (el mismo botón le permite abrir configuraciones detalladas para el análisis y la optimización de índices):

Además, la información se puede actualizar haciendo clic en el tercer botón a la izquierda en el menú principal junto a la lupa.
Un botón con una lupa le permite seleccionar la base de datos deseada para su consideración.
Actualmente no hay un sistema de ayuda completo. Por lo tanto, presionando el "?" simplemente provocará la aparición de una ventana modal que contiene información básica sobre el producto de software:
Además de todo lo anterior, el menú principal tiene una barra de búsqueda:

Al iniciar el proceso de optimización de índice:

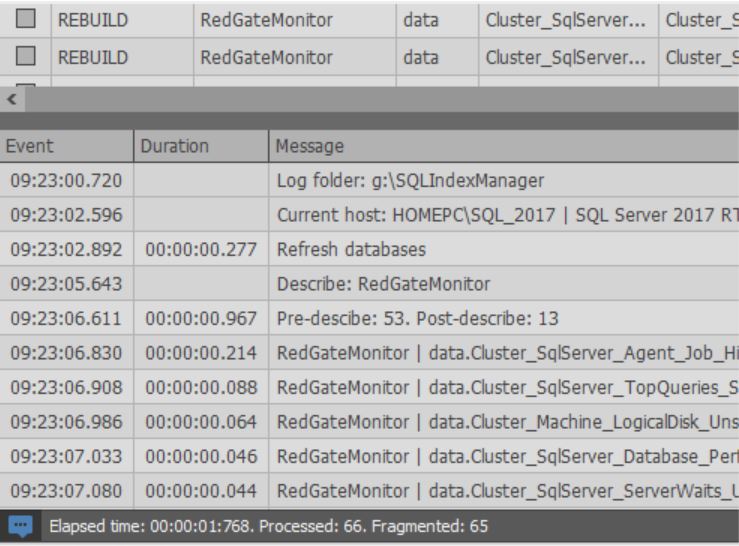
También en la parte inferior de la ventana puede ver el registro de las acciones realizadas:
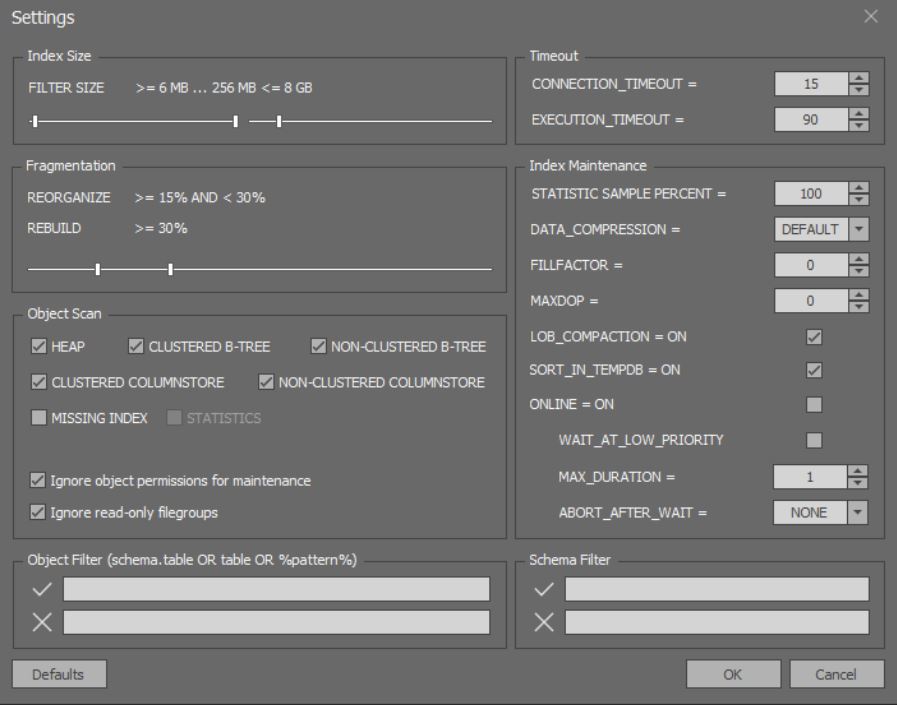
En la ventana de análisis detallado y optimización de índices, puede configurar opciones más sutiles:
 Sugerencias para la aplicación:
Sugerencias para la aplicación:- Permitir la actualización selectiva de estadísticas no solo para índices sino también de diferentes maneras (actualización total o parcial)
- hacen posible no solo seleccionar la base de datos, sino también diferentes servidores (esto es muy conveniente cuando hay muchas instancias de MS SQL Server)
- Para una mayor flexibilidad de uso, se propone ajustar los comandos en las bibliotecas y enviarlos a los comandos de PowerShell, como se hace, por ejemplo, aquí: dbatools.io/commands
- Permitir guardar y cambiar la configuración personal tanto para toda la aplicación como, si es necesario, para cada instancia de MS SQL Server y cada base de datos
- de las cláusulas 2 y 4 sigue el deseo de crear grupos en bases de datos y grupos en instancias de MS SQL Server, para las cuales la configuración es la misma
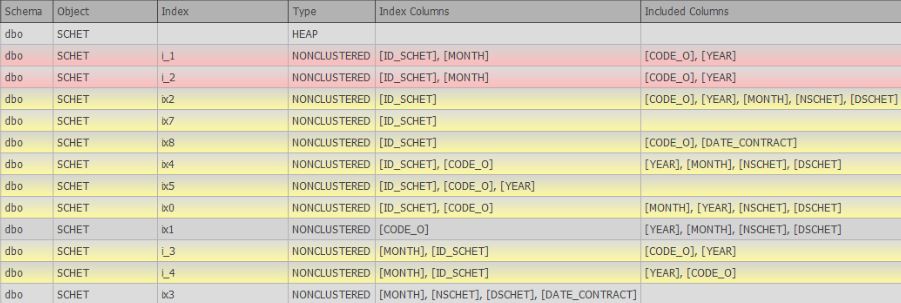
- buscar índices duplicados (completos e incompletos, que difieren ligeramente o solo difieren en las columnas incluidas)
- Dado que SQLIndexManager se usa solo para MS SQL Server DBMS, debe reflejar esto en el nombre, por ejemplo, de la siguiente manera: SQLIndexManager para MS SQL Server
- Elimine todas las partes de la aplicación de la GUI en módulos separados y vuelva a escribirlas en .NET Core 2.1
Al momento de escribir este artículo, el artículo 6 de los deseos se está desarrollando activamente y ya existe apoyo en forma de búsqueda de duplicados completos y similares:
Fuentes