El artículo proporciona código para generar informes periódicos sobre el estado de las unidades de almacenamiento EMC VNX con enfoques alternativos e historial de creación.
Traté de escribir código con los comentarios más detallados y un archivo. Solo sustituya sus contraseñas. También se indica el formato de los datos de origen, por lo que me alegrará si alguien intenta aplicarlo en casa.
Antecedentes
Puede omitir si no es interesante de dónde provienen las "patas".
Contamos con un centro de datos. No hay sistemas de almacenamiento muy frescos. Hay muchos sistemas de almacenamiento, fallas de disco también. Varias veces a la semana, las personas van al centro de datos y cambian las unidades en el sistema de almacenamiento. La decisión de reemplazar discos se toma después de una alarma del sistema " Reemplazo de disco recomendado ".
Nada fuera de lo común.

Pero recientemente, los LUN individuales recopilados en estos sistemas de almacenamiento y presentados al entorno virtual comenzaron a degradarse gravemente. Después de hablar con el soporte técnico del proveedor, quedó claro que los discos ya deberían cambiarse no solo cuando aparece el mensaje de alarma anterior, sino también cuando aparece una gran cantidad de otros mensajes de que el sistema no considera errores críticos.
La monitorización SNMP de estos sistemas de almacenamiento no es compatible. Debe usar un software propietario costoso (no lo tenemos) o la utilidad de consola NaviSECCli , que debe estar conectada a cada controlador (hay dos) de cada sistema de almacenamiento, pero esto no era muy deseable.
Se decidió automatizar la recopilación de registros y buscar errores en ellos. Y la decisión de reemplazar los discos debe dejarse a los ingenieros responsables en función de los resultados del análisis del informe.
Primeros pasos
Inicialmente, uno de mis colegas escribió el código de PowerShell que hizo lo siguiente:
- Tomó una tabla de entrada que contenía las direcciones IP de los controladores de almacenamiento;
- el ciclo fue a las direcciones IP de los controladores A , luego a las direcciones IP de los controladores B ;
- en el proceso, además los entrevisté para números de serie de discos;
- procesó todas las líneas de los registros y filtró el contenido de los mensajes buscados;
- creó un objeto PowerShell y en sus propiedades analizó los datos necesarios de las líneas obtenidas anteriormente;
- fusionó todos los objetos resultantes en una tabla que se emitió en forma de csv.
El código está abajo. Inmediatamente haga una reserva de que está trabajando, pero hemos introducido una solución alternativa.
Fuente de PowerShellcd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
Todo estaba bien, todo lo que quedaba era agregar un "brillo" en forma de envío automático de una carta a los colegas interesados y un formato mínimo del csv resultante. Pero (!) Todo este problema funcionó durante mucho tiempo. Los datos de un mes, por ejemplo, se recopilaron aproximadamente 45 minutos , lo que no fue muy adecuado, porque además de los informes regulares, quería hacer un análisis para el año en curso, y esto sería mucho tiempo. Pero "rechazar - oferta". Ellos comenzaron a pensar.

Obviamente, debe optimizar el código y habilitar la computación paralela. En PowerShell , no tuvimos éxito en más de 5 subprocesos simultáneos utilizando el flujo de trabajo , y todavía no hemos "fumado" métodos alternativos. Entonces se decidió tratar de cambiar la lógica del script a R. La utilidad NaviSECCli , que puede ejecutarse desde debajo de R , hace la encuesta de almacenamiento en el código fuente, por lo que la solución es bastante adecuada.
Se dice un par de dias - hecho!
Decidimos que en la salida me gustaría recibir un boletín diario que contenga la cantidad total de errores en el texto de la carta, algún tipo de cronograma para la cantidad de accidentes (para que haya algo que mostrar a la gerencia) y también un archivo adjunto en forma de una tabla xlsx. Determinamos que en la tabla quiero tener 3 pestañas:
- Datos de accidentes durante 3 días por disco y tipo de accidente
- Una pestaña similar, pero durante 30 días.
- Datos sin procesar (si alguien quiere ejecutarlos en Excel)
Algoritmo de secuencia de comandos
1. Descargue desde csv los datos disponibles en los controladores;
2. ejecutar un ciclo de computación paralela para todos los controladores con una búsqueda de registros de los mensajes de alarma requeridos;
3. combinar los resultados en un marco de datos;
4. hacer procesamiento de datos y conversión;
5. generar documento xlsx;
6. formamos el horario que guardamos en png;
7. formar una carta que contenga los datos recopilados;
8. enviar una carta.
Veamos los puntos del algoritmo.
1. Descargue los datos disponibles en los controladores de csv
Formato de tabla de origen con parámetros VNX Para recopilar información de emergencia, debe conectarse en serie a ambos controladores ( columnas newA y newB ) utilizando el software especializado EMC : NaviCLI con ciertas teclas.
Por conveniencia, formateamos la tabla resultante después de cargarla para que las direcciones IP de ambos controladores estén en la misma columna, de modo que pueda hacer un ciclo a lo largo de la lista, y no dos consecutivos. Hacemos esto usando la función de recopilación . Los problemas de trabajar con formatos de datos "verticales" u "horizontales" están muy bien descritos en la documentación oficial de la biblioteca tidyverse . Puedes leerlo aquí .
Leemos los datos usando la función read_csv2 , también determinamos manualmente los tipos de columnas a través del parámetro adicional col_types . Esta es una buena práctica, ya que En gran medida acelera la carga. En nuestro caso, esto no es tan importante, porque El csv original contiene menos de 100 líneas, pero nos acostumbramos a escribir correctamente.
En la salida, obtenemos dicho marco de datos (las nuevas columnas son cntName y cntIP ):
2-3. Realizamos un ciclo de cómputos paralelos para todos los controladores con una búsqueda de registros de los mensajes de alarma requeridos. Combina los resultados en un marco de datos
El siguiente es el más interesante. Computación paralela .
En R hay varias opciones (más bien, incluso muchas) para la computación paralela. Me gustó más el enlace de las bibliotecas foreach y doParallel . Puede leer sobre ellos y otras opciones de computación paralela en R aquí .
En resumen, tomamos solo 3 pasos :
Paso 1 Registrar núcleos Esmeralda pura CPU para trabajar en computación paralela a través de registerDoParallel (en nuestro caso, primero detectamos el número de núcleos en el caso)
Registrar núcleos de CPU numCores <- detectCores() registerDoParallel(numCores)
Paso 2 Comenzamos el ciclo a través de foreach (no olvide especificar el operador % dopar% para que el ciclo se ejecute en paralelo e indique, a través del parámetro .combine, la forma en que recopilaremos el resultado). En nuestro caso .combine = rbind , porque en la salida de cada bucle tendremos un marco de datos .
Código de recuperación de la tabla de errores Paso 3 Limpiamos el clúster de paralelismo creado a través de stopImplicitCluster ()
Un poco más de detalle sobre cómo obtener una tabla legible del texto de error sin formato
En forma de texto, los errores son los siguientes:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
Aquí tenemos valores separados por un espacio que, a primera vista, incluso en csv se insertará normalmente. Pero no es tan simple. La complejidad de analizar aquí es que:
- la fecha y la hora también están separadas por un espacio (el más pequeño de los males);
- el texto del error consta de "palabras", es decir también separados por un espacio;
- por alguna razón no hay espacio entre el número de disco y el código de error (que está entre paréntesis).
En general, un paraíso para los amantes de las expresiones regulares :)

No me detendré en el análisis, porque es cuestión de gustos, pero aclararé que el texto del error tuvo que separarse, ya que los valores ubicados entre el paréntesis de cierre del número de error y el corchete de apertura de algún otro valor. En un bucle, esta es la variable de errores .
También es un punto interesante que, para la conveniencia de formar el marco de datos final, nosotros, que queremos recorrer las direcciones IP de los controladores, establecemos la secuencia no a través de la columna con las direcciones IP de los controladores (es decir, i = VNX_ip $ cntIP ), sino a través del número de línea (es decir, e. i = 1: nrow (VNX_ip) ). Esto nos permite agregar el número de clúster y el nombre de almacenamiento a través de las llamadas VNX_ip $ cl [i] y VNX_ip $ Name [i], respectivamente, al crear un marco de datos con errores ya analizados. Sin esto, las uniones tendrían que hacerse, lo que sería más lento y peor leído en el código.
Al final, obtenemos un marco de datos (para ser sincero, luego tibble , pero la diferencia está más allá del alcance del artículo), que contiene todos los datos que necesitamos. Es decir en qué sistema de almacenamiento, en qué disco, cuándo ocurrió el error.
Vista final Marco de datos Lo más inteligente es que el ciclo completo de sondeo paralelo de todos los sistemas de almacenamiento no lleva 30 minutos, sino 30 segundos .
Gracias a Dios que este no es el caso cuando 30 segundos son demasiado rápidos.

Vale la pena aclarar que el código de PowerShell también recopiló los números de serie de los discos de todos los sistemas de almacenamiento en un ciclo, y al momento de reescribir el código en R, estos datos eran redundantes. Por lo tanto, la comparación del tiempo de ejecución no es del todo honesta, pero sigue siendo impresionante.
La conversión de datos para documentos xlsx se redujo al filtrado de la tabla de origen en los últimos 3 días, así como en el último mes y la conversión de las columnas con los nombres de error al formato "horizontal", de modo que cada tipo de error estaba en una columna separada. Se escribió una función separada para esto (para no duplicar los mismos pasos 2 veces)
Función de filtrado de origen myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
Para mostrar los tipos de errores en una columna separada, la función de propagación se aplicó con la tecla adicional fill = 0 , con la cual los valores faltantes se completaron con 0 . Sin esta clave, si algún día no hubiera algún tipo de error, la columna correspondiente tendría valores de NA .
Además, en la función quería mantener la capacidad de pasar el nombre de la columna para ordenar como variable, pero al mismo tiempo tener valores predeterminados para esta variable. Para esto, se utiliza la peculiar sintaxis dplyr , sobre la cual puede leer más aquí .
En nuestro caso, al definir los parámetros de una función, establecemos uno de ellos en el valor predeterminado y lo citamos ( orderColname = quo (Soft_Media_Error) ), y luego, cuando se llama, ¡pone caracteres delante de él ! para organizar (desc (!! orderColname)) .
La aparición de la tabla con errores para el mes. Analicé la formación del documento xlsx en el artículo sobre informes sobre el estado de la VM , por lo que no me detendré en detalle. Todo el código se da al final del artículo.

Estas son características importantes que aumentan la legibilidad del informe:
- Pestañas firmadas (por defecto, la más interesante está abierta);
- Nombres de columna resaltados
- Formateo automático de todas las columnas para que todo el texto sea legible sin tener que expandir las columnas.
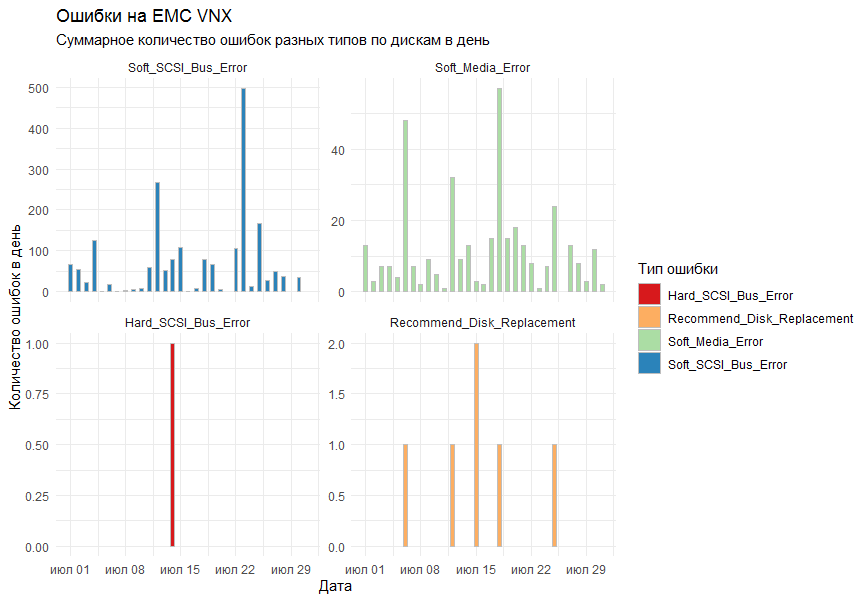
En el gráfico, quería obtener el número total de errores por día para todos los sistemas de almacenamiento por tipo. Como herramienta de dibujo, se decidió utilizar la biblioteca estándar ggplot2 .
La primera versión del gráfico mostró todos los errores en un gráfico y se veía así:

Los colegas dijeron que resultó ilegible.
¿Qué iban a entender?
Se tomaron en cuenta las observaciones y se agregó la función facet_grid a las columnas estándar ( geom_bar ) para dividir el resultado en gráficos separados por tipo de error.
El resultado final fue adecuado para todos.

Preparación de datos, gráficos, guardar en archivo De lo interesante en la formación del horario.
Quería que los gráficos estuvieran en cierto orden. Para hacer esto, el parámetro de formación de filas en facet_grid tuvo que transferirse como un factor, o más bien incluso como un factor ordenado . Factor es un formato de datos tan astuto en R, que es un conjunto de valores (en nuestro caso, cadenas, es decir, caracteres ), y el conjunto de estos valores está estrictamente definido (llamados niveles de factor), e incluso estos niveles están ordenados. Suena complicado, pero todo encaja si dices que los nombres de los meses son un gran ejemplo de un factor ordenado. Es decir sabemos qué nombres pueden tener los meses, y también sabemos (bueno, espero) que primero llegue enero, luego febrero, luego marzo, etc. Es sobre el mismo principio que creamos un factor.
La formación y el envío de cartas, así como la formación de tareas en el programador de Windows también se consideró en el artículo sobre informes sobre el estado de VM . Simplemente ponemos algunas variables en el texto y lo formateamos más o menos claramente. No olvides el archivo adjunto.
La forma final de la carta. Conclusiones
Una vez más, R demostró ser una herramienta universal para realizar tareas cotidianas y visualizar sus resultados. Y con la computación paralela habilitada, esta herramienta también se vuelve rápida.
La práctica también ha demostrado que PowerShell es extremadamente lento para analizar registros y traducirlos a un formato legible.
Muchas gracias a todos los que leyeron tantas cartas hasta el final.
Código de aplicación completo
Código de aplicación R completo - : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3