Originalmente publiqué este artículo en el blog CodingSight .
También está disponible en ruso aquí .Este artículo contiene la segunda parte de mi discurso en la reunión de subprocesos múltiples. Puedes echar un vistazo a la primera parte
aquí y
aquí . En la primera parte, me concentré en el conjunto básico de herramientas utilizadas para iniciar un hilo o una tarea, las formas de rastrear su estado y algunas cosas interesantes adicionales como PLinq. En esta parte, solucionaré los problemas que puede encontrar en un entorno de subprocesos múltiples y algunas de las formas de resolverlos.
Contenido
Sobre los recursos compartidos
No puede escribir un programa cuyo trabajo se base en múltiples hilos sin tener recursos compartidos. Incluso si funciona en su nivel de abstracción actual, encontrará que en realidad ha compartido recursos tan pronto como baje uno o más niveles de abstracción. Aquí hay algunos ejemplos:
Ejemplo # 1:Para evitar posibles problemas, hace que los hilos funcionen con diferentes archivos, un archivo para cada hilo. Le parece que el programa no tiene recursos compartidos de ningún tipo.
Al bajar algunos niveles, se llega a saber que solo hay un disco duro, y depende del controlador o del sistema operativo encontrar una solución para los problemas con el acceso al disco duro.
Ejemplo # 2:Después de leer el
ejemplo # 1 , decidió colocar los archivos en dos máquinas remotas diferentes con hardware y sistemas operativos físicamente diferentes. También mantiene dos conexiones FTP o NFS diferentes.
Al bajar algunos niveles nuevamente, comprende que nada ha cambiado realmente y que el problema de acceso competitivo ahora se delega al controlador de la tarjeta de red o al sistema operativo de la máquina en la que se ejecuta el programa.
Ejemplo # 3:Después de tirar la mayor parte de su cabello sobre los intentos de probar que puede escribir un programa de subprocesos múltiples, decide deshacerse de los archivos por completo y mover los cálculos a dos objetos diferentes, con los enlaces a cada uno de los objetos disponibles solo para su específico hilos
Para martillar la última docena de clavos en el ataúd de esta idea: un runtime y Garbage Collector, un programador de subprocesos, físicamente una RAM unificada y un procesador todavía se consideran recursos compartidos.
Entonces, aprendimos que es imposible escribir un programa multiproceso sin recursos compartidos en todos los niveles de abstracción y en todo el alcance de la pila de tecnología. Afortunadamente, cada nivel de abstracción (como regla general) se ocupa parcial o totalmente de los problemas de acceso competitivo o simplemente lo niega de inmediato (ejemplo: cualquier marco de UI no permite trabajar con elementos de diferentes hilos). Por lo general, los problemas con los recursos compartidos aparecen en su nivel de abstracción actual. Para cuidarlos, se introduce el concepto de sincronización.
Posibles problemas en entornos de subprocesos múltiples
Podemos clasificar los errores de software en las siguientes categorías:
- El programa no produce un resultado, se bloquea o se congela.
- El programa da un resultado incorrecto.
- El programa produce un resultado correcto pero no satisface algunos requisitos no relacionados con la función: gasta demasiado tiempo o recursos.
En entornos de subprocesos múltiples, los principales problemas que provocan los errores n. ° 1 y n. ° 2 son el
punto muerto y la
condición de la carrera .
Punto muerto
El punto muerto es un bloqueo mutuo. Hay muchas variaciones de un punto muerto. El siguiente puede considerarse como el más común:
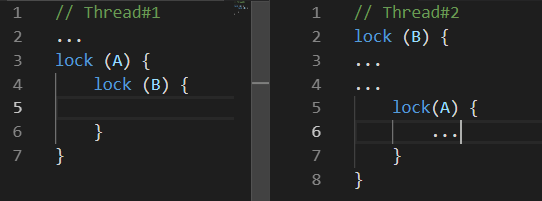
Mientras el
Hilo # 1 estaba haciendo algo, el
Hilo # 2 bloqueó el recurso
B. Algún tiempo después, el
Hilo # 1 bloqueó el recurso
A e intentaba bloquear el recurso B. desafortunadamente, esto nunca sucederá porque el
Hilo # 2 solo soltará el recurso
B después de bloquear el recurso
A.Condición de carrera
Race-Condition es una situación en la que tanto el comportamiento como los resultados de los cálculos dependen del planificador de subprocesos del entorno de ejecución
El problema es que su programa puede funcionar incorrectamente una vez en cien, o incluso en un millón.
Las cosas pueden empeorar cuando surgen problemas de tres en tres. Por ejemplo, el comportamiento específico del planificador de subprocesos puede conducir a un punto muerto mutuo.
Además de estos dos problemas que conducen a errores explícitos, también están los problemas que, si no conducen a resultados de cálculo incorrectos, aún pueden hacer que el programa tome mucho más tiempo o recursos para producir el resultado deseado. Dos de estos problemas son
Busy Wait y
Thread Starvation .
Ocupado-espera
La espera ocupada es un problema que ocurre cuando el programa gasta los recursos del procesador en espera en lugar de en cálculo.
Por lo general, este problema tiene el siguiente aspecto:
while(!hasSomethingHappened) ;
Este es un ejemplo de un código extremadamente pobre, ya que ocupa completamente un núcleo de su procesador sin hacer realmente nada productivo. Dicho código solo puede justificarse cuando es de importancia crítica procesar rápidamente un cambio de un valor en un hilo diferente. Y por "rápidamente" quiero decir que no puedes esperar ni siquiera unos pocos nanosegundos. En todos los demás casos, es decir, en todos los casos que pueda tener una mente razonable, es mucho más conveniente usar las variaciones de ResetEvent y sus versiones Slim. Hablaremos de ellos un poco más tarde.
Probablemente, algunos lectores sugerirían resolver el problema de que un núcleo esté completamente ocupado con la espera agregando Thread.Sleep (1) (o algo similar) en el ciclo. Si bien resolverá este problema, se creará uno nuevo: el tiempo que se tarda en reaccionar a los cambios ahora será de 0,5 ms en promedio. Por un lado, no es tanto, pero por otro lado, este valor es catastróficamente más alto de lo que podemos lograr mediante el uso de primitivas de sincronización de la familia ResetEvent.
Hilo de hambre
Thread Starvation es un problema con el programa que tiene demasiados hilos que operan simultáneamente. Aquí, estamos hablando específicamente de los hilos ocupados con el cálculo en lugar de esperar una respuesta de algún IO. Con este problema, perdemos los posibles beneficios de rendimiento que vienen junto con los subprocesos porque el procesador pasa mucho tiempo cambiando de contexto.
Puede encontrar estos problemas utilizando varios perfiladores. La siguiente es una captura de pantalla del
generador de perfiles
dotTrace que funciona en el modo Línea de tiempo
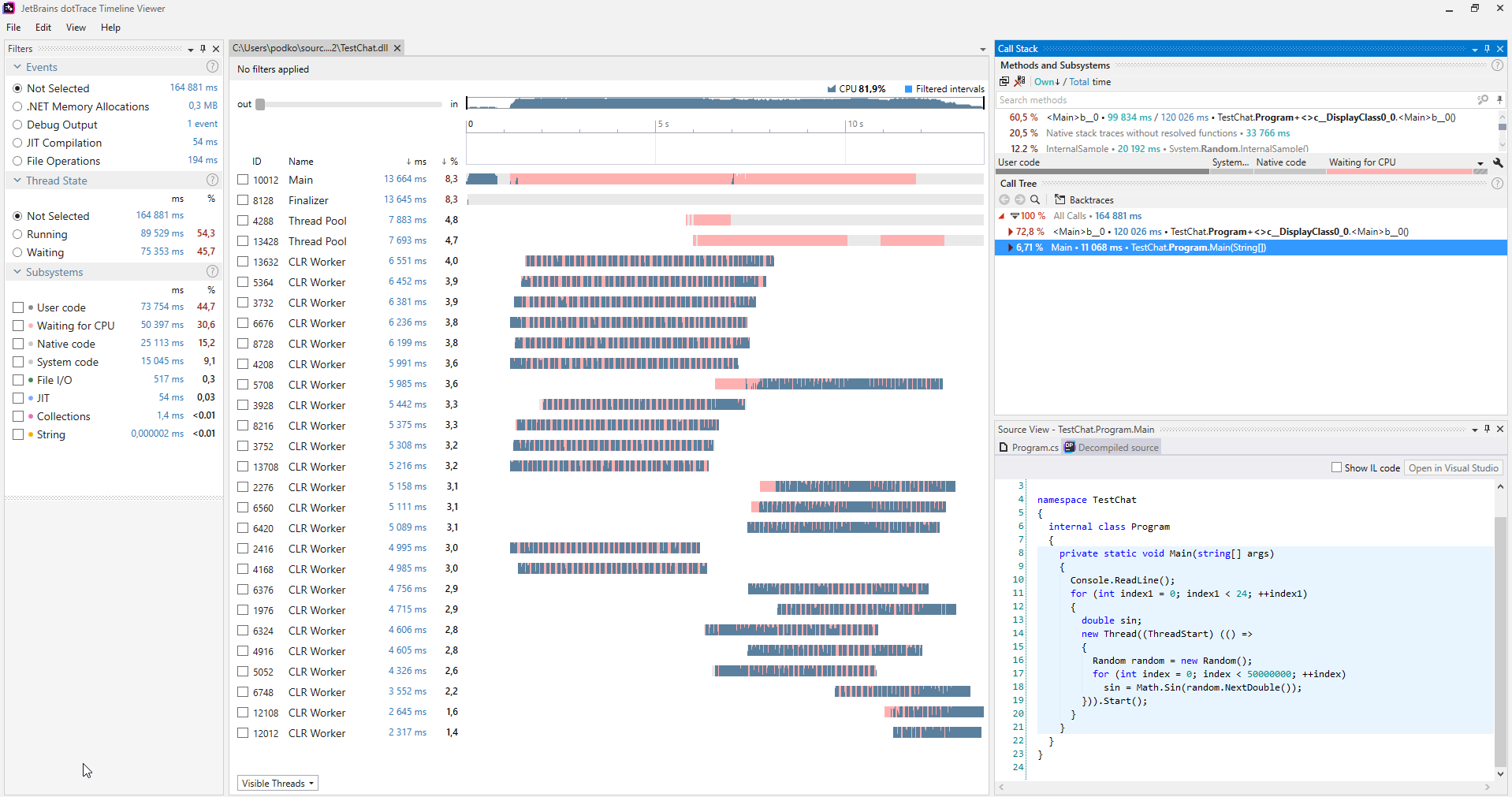 (haga clic para agrandar).
(haga clic para agrandar).Por lo general, los programas que no sufren el hambre del hilo no tienen secciones rosadas en los gráficos que representan los hilos. Además, en la categoría Subsistemas, podemos ver que el programa estaba esperando CPU el 30.6% del tiempo.
Cuando se diagnostica un problema de este tipo, puede solucionarlo de manera bastante simple: ha comenzado demasiados hilos a la vez, así que solo comience menos hilos.
Métodos de sincronización
Enclavado
Este es probablemente el método de sincronización más ligero. Interlocked es un conjunto de operaciones atómicas simples. Cuando se ejecuta una operación atómica, no puede pasar nada. En .NET, Interlocked está representado por la clase estática del mismo nombre con una selección de métodos, cada uno de ellos implementando una operación atómica.
Para darse cuenta del horror final de las operaciones no atómicas, intente escribir un programa que lance 10 hilos, cada uno de los cuales incremente la misma variable un millón de veces. Cuando terminen con su trabajo, muestre el valor de esta variable. Desafortunadamente, será muy diferente de 10 millones. Además, será diferente cada vez que ejecute el programa. Esto sucede porque incluso una operación tan simple como el incremento no es atómica, e incluye la extracción del valor de la memoria, el cálculo del nuevo valor y volver a escribirlo en la memoria. Por lo tanto, dos hilos pueden realizar cualquiera de estas operaciones y se perderá un incremento en este caso.
La clase Interlocked proporciona los métodos de Incremento / Decremento, y no es difícil adivinar lo que se supone que deben hacer. Son realmente útiles si procesa datos en varios hilos y calcula algo. Dicho código funcionará mucho más rápido que el bloqueo clásico. Si utilizamos Interlocked en la situación descrita en el párrafo anterior, el programa produciría de manera confiable un valor de 10 millones en cualquier escenario.
La función del método CompareExchange no es tan obvia. Sin embargo, su existencia permite la implementación de muchos algoritmos interesantes. Lo más importante, los de la familia sin cerradura.
public static int CompareExchange (ref int location1, int value, int comparand);
Este método toma tres valores. El primero se pasa a través de una referencia y es el valor que se cambiará al segundo si location1 es igual a comparand cuando se realiza la comparación. Se devolverá el valor original de location1. Esto suena complicado, por lo que es más fácil escribir un fragmento de código que realice las mismas operaciones que CompareExchange:
var original = location1; if (location1 == comparand) location1 = value; return original;
La única diferencia es que la clase Interlocked implementa esto de una manera atómica. Entonces, si escribimos este código nosotros mismos, podríamos enfrentar un escenario en el que la condición location1 == comparand ya se ha cumplido. Pero cuando se ejecuta la instrucción location1 = value, un subproceso diferente ya ha cambiado el valor de location1, por lo que se perderá.
Podemos encontrar un buen ejemplo de cómo se puede usar este método en el código que genera el compilador para cualquier evento de C #.
Escribamos una clase simple con un evento llamado MyEvent:
class MyClass { public event EventHandler MyEvent; }
Ahora, construyamos el proyecto en la configuración de lanzamiento y abramos la construcción a través de
dotPeek con la opción "Mostrar código generado por el compilador" habilitada:
[CompilerGenerated] private EventHandler MyEvent; public event EventHandler MyEvent { [CompilerGenerated] add { EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler; eventHandler = Interlocked.CompareExchange<EventHandler>(ref this.MyEvent, (EventHandler) Delegate.Combine((Delegate) comparand, (Delegate) value), comparand); } while (eventHandler != comparand); } [CompilerGenerated] remove {
Aquí, podemos ver que el compilador ha generado un algoritmo bastante complejo detrás de escena. Este algoritmo nos impide perder una suscripción al evento en el que algunos subprocesos se suscriben simultáneamente a este evento. Elaboremos el método de agregar teniendo en cuenta lo que hace el método CompareExchange detrás de escena:
EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler;
Esto es mucho más manejable, pero probablemente aún requiera una explicación. Así es como describiría el algoritmo:
Si MyEvent sigue siendo el mismo que en el momento en que comenzamos a ejecutar Delegate.Combine, configúrelo en lo que Delegate.Combine devuelve. Si no es el caso, intente nuevamente hasta que funcione.De esta manera, las suscripciones nunca se perderán. Tendrá que resolver un problema similar si desea implementar una matriz dinámica, segura para subprocesos y sin bloqueo. Si de repente varios subprocesos comienzan a agregar elementos a esa matriz, es importante que todos esos elementos se agreguen con éxito.
Monitor.Enter, Monitor.Exit, lock
Estas construcciones se utilizan para la sincronización de subprocesos con mayor frecuencia. Implementan el concepto de una sección crítica: es decir, el código escrito entre las llamadas de Monitor.Enter y Monitor.Exit solo puede ejecutarse en un recurso en un punto del tiempo por un solo hilo. El operador de bloqueo sirve como sintaxis-azúcar alrededor de las llamadas de entrada / salida envueltas en try-finally. Una calidad agradable de la sección crítica en .NET es que admite reentrada. Esto significa que el siguiente código puede ejecutarse sin problemas reales:
lock(a) { lock (a) { ... } }
Es poco probable que alguien escriba de esta manera exacta, pero si distribuye este código entre algunos métodos a través de la profundidad de la pila de llamadas, esta función puede ahorrarle algunos IF. Para que este truco funcione, los desarrolladores de .NET tuvieron que agregar una limitación: solo puede usar instancias de tipos de referencia como un objeto de sincronización, y se agregan unos pocos bytes a cada objeto donde se escribirá el identificador de hilo.
Esta peculiaridad del proceso de trabajo de la sección crítica en C # impone una limitación interesante sobre el operador de bloqueo: no puede usar el operador de espera dentro del operador de bloqueo. Al principio, esto me sorprendió, ya que se puede compilar una construcción similar de Monitor de entrada y salida. Cual es el trato? Es importante volver a leer el párrafo anterior y aplicar algunos conocimientos sobre cómo funciona async / await: el código después de waitit no se ejecutará en el mismo hilo que el código antes de wait. Esto depende del contexto de sincronización y de si se llama o no al método ConfigureAwait. A partir de esto, se deduce que Monitor.Exit puede ejecutarse en un subproceso diferente que Monitor.Enter, lo que conducirá a que se produzca SynchronizationLockException. Si no me cree, intente ejecutar el siguiente código en una aplicación de consola: generará una
excepción SynchronizationLockException :
var syncObject = new Object(); Monitor.Enter(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId); await Task.Delay(1000); Monitor.Exit(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
Vale la pena señalar que, en una aplicación WinForms o WPF, este código funcionará correctamente si lo llama desde el hilo principal, ya que habrá un contexto de sincronización que implementa el retorno a UI-Thread después de la llamada en espera. En cualquier caso, es mejor no jugar con secciones críticas en el contexto de un código que contiene el operador de espera. En tales ejemplos, es mejor usar primitivas de sincronización que veremos más adelante.
Si bien estamos en el tema de las secciones críticas en .NET, es importante mencionar una peculiaridad más de cómo se implementan. Una sección crítica en .NET funciona en dos modos: spin-wait y core-wait. Podemos representar el algoritmo spin-wait como el siguiente pseudocódigo:
while(!TryEnter(syncObject)) ;
Esta optimización está dirigida a capturar una sección crítica lo más rápido posible en un corto período de tiempo sobre la base de que, incluso si el recurso está actualmente ocupado, se lanzará muy pronto. Si esto no sucede en un corto período de tiempo, el subproceso cambiará a esperar en el modo central, lo que lleva tiempo, al igual que volver de esperar. Los desarrolladores de .NET han optimizado el escenario de bloques cortos tanto como sea posible. Desafortunadamente, si muchos subprocesos comienzan a tirar de la sección crítica entre ellos, puede provocar una carga repentina y alta en la CPU.
SpinLock, SpinWait
Después de haber mencionado el algoritmo de espera cíclico (spin-wait), vale la pena hablar sobre las estructuras SpinLock y SpinWait de BCL. Debe usarlos si hay razones para suponer que siempre será posible obtener un bloqueo muy rápidamente. Por otro lado, no debería pensar realmente en ellos hasta que los resultados de la generación de perfiles muestren que el cuello de botella de su programa se debe al uso de otras primitivas de sincronización.
Monitor.Wait, Monitor.Pulse [Todos]
Deberíamos mirar estos dos métodos uno al lado del otro. Con su ayuda, puede implementar varios escenarios Productor-Consumidor.
Productor-Consumidor es un patrón de diseño multiproceso / multiproceso que implica uno o más hilos / procesos que producen datos y uno o más procesos / hilos que procesan estos datos. Por lo general, se usa una colección compartida.
Ambos métodos solo pueden ser llamados por un hilo que actualmente tiene un bloque. El método Wait liberará el bloque y se congelará hasta que otro hilo llame a Pulse.
Como demostración de esto, escribí un pequeño ejemplo:
object syncObject = new object(); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
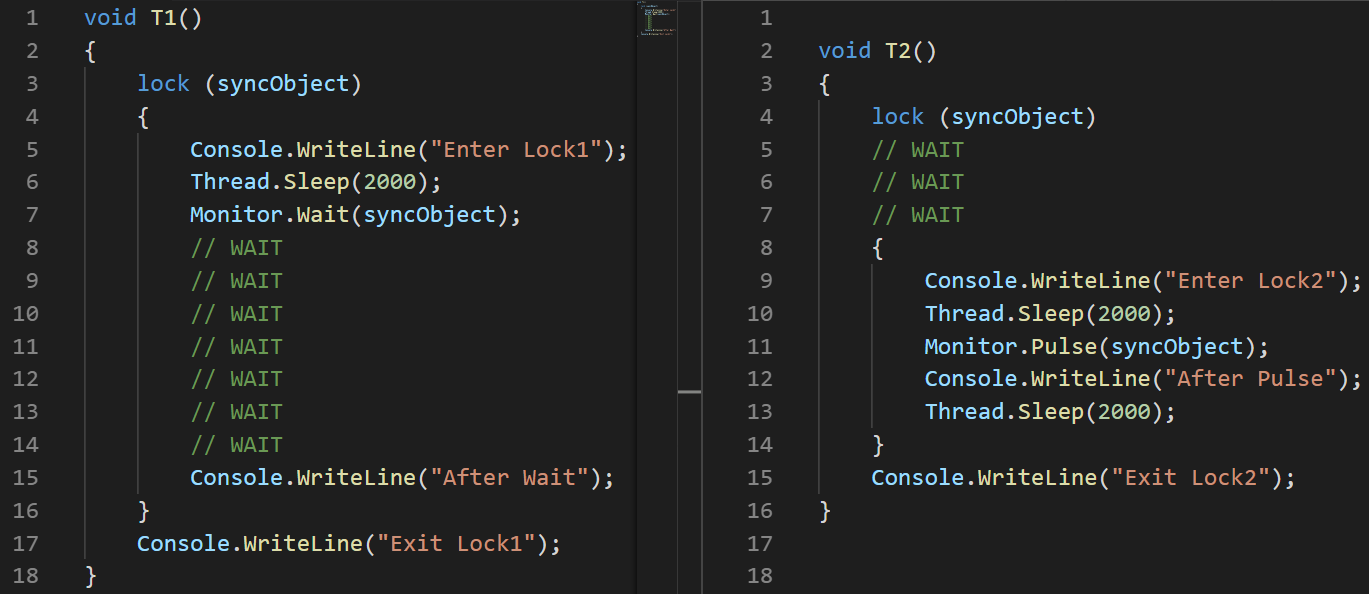 (Usé una imagen en lugar de texto aquí para mostrar con precisión el orden de ejecución de la instrucción)Explicación:
(Usé una imagen en lugar de texto aquí para mostrar con precisión el orden de ejecución de la instrucción)Explicación: establecí una latencia de 100 ms al iniciar el segundo subproceso para garantizar específicamente que se ejecutará más tarde.
- T1: Línea # 2 se inicia el hilo
- T1: Línea # 3 el hilo entra en una sección crítica
- T1: Línea # 6 el hilo se va a dormir
- T2: Línea # 3 se inicia el hilo
- T2: línea # 4 se congela y espera la sección crítica
- T1: Línea # 7, deja ir la sección crítica y se congela mientras espera que salga Pulse
- T2: Línea # 8 ingresa a la sección crítica
- T2: Línea # 11 señala T1 con la ayuda de Pulse
- T2: Línea # 14 sale de la sección crítica. T1 no puede continuar su ejecución antes de que esto suceda.
- T1: Línea # 15 sale de esperar
- T1: línea # 16 sale de la sección crítica
Hay una observación importante en MSDN con respecto al uso de los métodos Pulse / Wait: Monitor no almacena la información de estado, lo que significa que llamar al método Pulse antes del método Wait puede llevar a un punto muerto. Si tal caso es posible, es mejor usar una de las clases de la familia ResetEvent.El ejemplo anterior muestra claramente cómo funcionan los métodos Wait / Pulse de la clase Monitor, pero aún deja algunas preguntas sobre los casos en los que deberíamos usarlos. Un buen ejemplo es
esta implementación de BlockingQueue <T>. Por otro lado, la implementación de BlockingCollection <T> de System.Collections.Concurrent usa SemaphoreSlim para la sincronización.
ReaderWriterLockSlim
Me encanta esta primitiva de sincronización, y está representada por la clase del mismo nombre del sistema. Creo que muchos programas funcionarían mucho mejor si sus desarrolladores usaran esta clase en lugar del bloqueo estándar.
Idea: muchos hilos pueden leer, y el único puede escribir. Cuando un hilo quiere escribir, no se pueden iniciar nuevas lecturas; estarán esperando la escritura hasta el final. También existe el concepto actualizable de bloqueo de lectura. Puede usarlo cuando, durante el proceso de lectura, comprenda que es necesario escribir algo: tal bloqueo se transformará en un bloqueo de escritura en una operación atómica.
En el espacio de nombres System.Threading, también está la clase ReadWriteLock, pero se recomienda no usarla para un nuevo desarrollo. La versión Slim ayudará a evitar casos que conducen a puntos muertos y permite capturar rápidamente un bloque, ya que admite la sincronización en el modo de espera de giro antes de pasar al modo central.
Si no conocía esta clase antes de leer este artículo, creo que ya ha recordado muchos ejemplos del código recientemente escrito en el que este enfoque de bloques permitió que el programa funcionara de manera efectiva.
La interfaz de la clase ReaderWriterLockSlim es simple y fácil de entender, pero no es tan cómoda de usar:
var @lock = new ReaderWriterLockSlim(); @lock.EnterReadLock(); try {
Por lo general, me gusta envolverlo en una clase, esto lo hace mucho más práctico.
Idea: crear métodos Read / WriteLock que devuelvan un objeto junto con el método Dispose. Luego puede acceder a ellos en Uso, y probablemente no diferirá demasiado del bloqueo estándar cuando se trata de la cantidad de líneas. class RWLock : IDisposable { public struct WriteLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public WriteLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterWriteLock(); } public void Dispose() => @lock.ExitWriteLock(); } public struct ReadLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public ReadLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterReadLock(); } public void Dispose() => @lock.ExitReadLock(); } private readonly ReaderWriterLockSlim @lock = new ReaderWriterLockSlim(); public ReadLockToken ReadLock() => new ReadLockToken(@lock); public WriteLockToken WriteLock() => new WriteLockToken(@lock); public void Dispose() => @lock.Dispose(); }
Esto nos permite escribir lo siguiente más adelante en el código:
var rwLock = new RWLock();
La familia ResetEvent
Incluyo las siguientes clases en esta familia: ManualResetEvent, ManualResetEventSlim y AutoResetEvent.
La clase ManualResetEvent, su versión Slim y la clase AutoResetEvent pueden existir en dos estados:
- Sin señalización: en este estado, todos los subprocesos que han llamado a WaitOne se congelan hasta que el evento cambia a un estado señalado.
- Señalizado: en este estado, se liberan todos los hilos previamente congelados en una llamada WaitOne. Todas las nuevas llamadas WaitOne en un evento señalado se realizan de manera relativamente instantánea.
AutoResetEvent difiere de ManualResetEvent en que cambia automáticamente al estado no señalado después de liberar
exactamente un subproceso . Si se congelan algunos subprocesos mientras se espera AutoResetEvent, al llamar a Set solo se liberará un subproceso aleatorio, a diferencia de ManualResetEvent que libera todos los subprocesos.
Veamos un ejemplo de cómo funciona AutoResetEvent:
AutoResetEvent evt = new AutoResetEvent(false); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
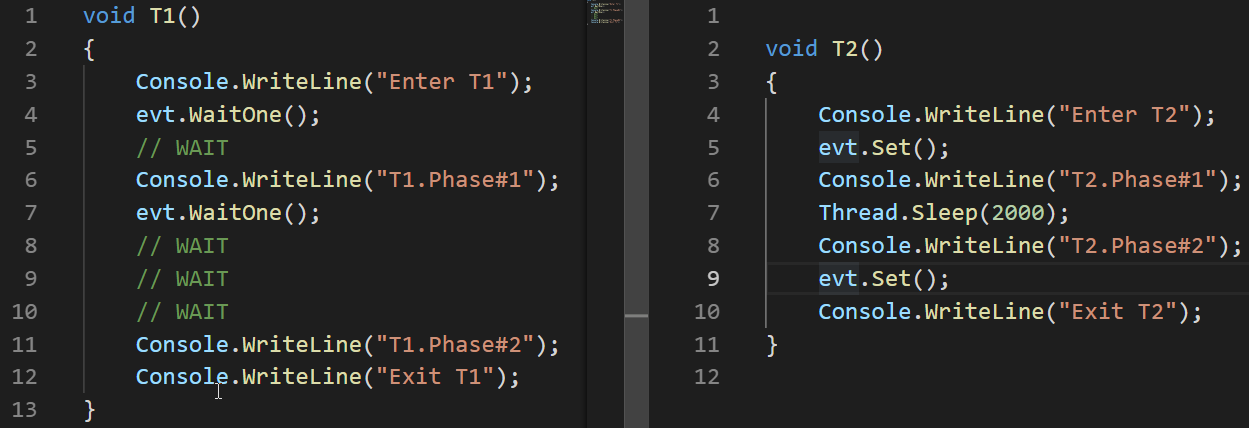
En estos ejemplos, podemos ver que el evento cambia al estado no señalado automáticamente solo después de liberar el hilo que se congeló en una llamada WaitOne.
A diferencia de ReaderWriterLock, ManualResetEvent no se considera obsoleto incluso después de que apareció su versión Slim. Esta versión Slim de la clase puede ser efectiva para esperas cortas como sucede en el modo Spin-Wait; La versión estándar es buena para largas esperas.
Además de las clases ManualResetEvent y AutoResetEvent, también está la clase CountdownEvent. Esta clase es muy útil para implementar algoritmos que combinan resultados juntos después de una sección paralela. Este enfoque se conoce como
fork-join . Hay un gran
artículo dedicado a esta clase, por lo que no lo describiré en detalle aquí.
Conclusiones
- Cuando se trabaja con subprocesos, hay dos problemas que pueden conducir a resultados incorrectos o incluso a la ausencia de resultados: condición de carrera y punto muerto.
- Los problemas que pueden hacer que el programa gaste más tiempo o recursos son el hambre de hilos y la espera ocupada.
- .NET proporciona muchas formas de sincronizar hilos.
- Hay dos modos de espera en bloque: Spin Wait y Core Wait. Algunas primitivas de sincronización de hilos en .NET usan ambas.
- Interlocked es un conjunto de operaciones atómicas que se pueden usar para implementar algoritmos sin bloqueo. Es la primitiva de sincronización más rápida.
- Los operadores de bloqueo y monitor de entrada / salida implementan el concepto de una sección crítica, un fragmento de código que solo puede ser ejecutado por un hilo en un punto de tiempo.
- Los métodos Monitor.Pulse / Wait son útiles para implementar escenarios Productor-Consumidor.
- ReaderWriterLockSlim puede ser más útil que los casos de bloqueo estándar cuando se espera una lectura paralela.
- La familia de clases ResetEvent puede ser útil para la sincronización de subprocesos.