Imagine una situación típica en el primer año: leyó
sobre el algoritmo Dinits , lo implementó, pero no funcionó y no sabe por qué. La solución estándar es comenzar a depurar en pasos, cada vez que dibuja el estado actual del gráfico en una hoja de papel, pero esto es terriblemente inconveniente. Intenté corregir la situación como parte de un proyecto semestral sobre Ingeniería de Software, y en una publicación le contaré cómo terminé con un complemento para Visual Studio. Puede descargarlo
aquí , el código fuente y la documentación se pueden encontrar
aquí . Aquí hay una captura de pantalla del gráfico obtenido para el algoritmo Dinits.
Sobre mi
Mi nombre es Olga, me gradué del tercer año de la dirección de "Matemática Aplicada y Ciencias de la Computación" en el St. Petersburg HSE con un título en Ingeniería de Software. Antes de ingresar a la universidad, no estaba involucrado en la programación.
Investigación: requisitos
En nuestra facultad practicamos trabajos de investigación semestrales. Por lo general, esto sucede así: al comienzo del semestre, se realiza una presentación de trabajos de investigación: representantes de diferentes empresas ofrecen diversos proyectos. Luego, los estudiantes eligen sus proyectos favoritos, los supervisores eligen a sus estudiantes favoritos, y así sucesivamente. Al final, cada estudiante encuentra un proyecto para sí mismo.
Pero hay otra manera: puede encontrar independientemente un supervisor y un proyecto, y luego convencer al curador de que este proyecto realmente puede ser una I + D completa. Para hacer esto, pruebe que:
- Vas a hacer algo nuevo. Por supuesto, el proyecto puede tener análogos, pero su opción debería tener algunas ventajas sobre ellos.
- La tarea debería ser bastante difícil, es decir, el trabajo allí debería ser por un semestre, y no por un día. Al mismo tiempo, es necesario que el proyecto se haya realizado realmente en un semestre.
- Su proyecto debería ser útil para el mundo. Es decir, cuando se le pregunta por qué esto es necesario, no debe responder: "Bueno, necesito hacer algún tipo de investigación".
Elegí el segundo camino. Lo primero que hice después de acordar con el supervisor fue encontrar el tema del proyecto. La lista de ideas incluyó: el verificador de estilo de código para Lua, un depurador que le permite calcular expresiones en partes, y una herramienta para olimpiadas / entrenamiento de programación, que le permite visualizar lo que está sucediendo en el código. Es decir, un visualizador para estructuras de datos arbitrarias combinadas con un depurador. Por ejemplo, una persona escribe un
árbol cartesiano , y en el proceso se dibujan vértices, bordes, el vértice actual, etc. Al final, decidí detenerme en esta opción.
Plan de trabajo del proyecto
Mi trabajo en el proyecto consistió en las siguientes etapas:
- Se requirió el estudio del área temática para comprender si este problema ya se había resuelto (entonces el tema del proyecto tendría que cambiarse), cuáles son sus análogos, cuáles son sus ventajas y desventajas, lo que podría tener en cuenta en mi trabajo.
- Definir la funcionalidad específica que poseerá la herramienta creada. El tema del proyecto se planteó de manera bastante abstracta, y esto fue necesario para garantizar que la tarea sea bastante complicada, pero al mismo tiempo se puede completar en un semestre.
- Se requería crear una interfaz de usuario prototipo para demostrar cómo se puede usar la herramienta creada. Agregó aún más especificidad que un conjunto de características descritas por palabras.
- Elección de dependencias : debe comprender cómo se organizará todo desde el punto de vista del desarrollador y decidir las herramientas que se utilizarán en el proceso de escritura del código.
- Crear un prototipo (prueba de concepto) , es decir, un ejemplo mínimo en el que la mayoría estaría codificado. Con este ejemplo, tuve que lidiar con todas las herramientas que iba a utilizar, y también aprender a resolver todas las dificultades que surgieron en el camino, para que la versión final ya estuviera escrita "limpiamente".
- Trabajar en la parte de contenido , es decir, el desarrollo y la implementación de la lógica de la herramienta.
- Se requiere la protección del proyecto para poder hablar rápidamente sobre el trabajo realizado y dar la oportunidad de evaluarlo a todos, incluso a las personas que no hurgan en el tema. Es un entrenamiento antes de la graduación. Al mismo tiempo, un proyecto bien hecho no garantiza que el informe resulte bueno, ya que requiere otras habilidades, por ejemplo, la capacidad de hablar al público.
Siempre llevé a cabo la planificación con mi supervisor. También siempre se nos ocurrió y discutimos todas las ideas que surgieron en el camino. Además, el supervisor me dio consejos sobre el código y me ayudó con la gestión del tiempo. Acerca de todos los problemas técnicos (errores incomprensibles, etc.) También siempre informaba, pero casi siempre me las arreglaba para resolverlos.
Investigación del tema
Para empezar, nuestro liderazgo debería haber estado convencido de que este tema merece ser mi trabajo de investigación. Y para comenzar desde el primer punto: la búsqueda de análogos.
Al final resultó que, hay muchos análogos. Pero la mayoría de ellos fueron diseñados para la visualización de la memoria. Es decir, habrían hecho un gran trabajo con la visualización del árbol cartesiano, pero no pueden entender que el
montón en la matriz no se debe dibujar como una matriz, sino como un árbol. Estos incluían
gdbgui , un
depurador de visualización de datos , un complemento para Eclipse
jGRASP y un complemento para Visual Studio
Data Structures Visualizer . Este último también se creó para los problemas de programación de olimpiadas, pero solo pudo visualizar estructuras de datos en punteros.
Hubo algunas herramientas más:
Algojammer para python (y queríamos ventajas, como el lenguaje más popular entre olympiadniki) y la herramienta
Lens desarrollada en 1994. Este último, a juzgar por la descripción, hizo casi lo que necesitaba, pero, desafortunadamente, fue creado bajo Sun OS 4.1.3 (un sistema operativo de 1992). Entonces, a pesar de la disponibilidad de códigos fuente, se decidió no perder el tiempo en esta dudosa arqueología.
Entonces, después de algunas investigaciones, se descubrió que Tula, que haría exactamente lo que queríamos, y al mismo tiempo trabajaría en máquinas modernas, aún no está en la naturaleza.
Definición de funcionalidad
El segundo paso fue demostrar que esta tarea es bastante complicada, pero factible. Para hacer esto, era necesario proponer algo más específico que "Quiero una imagen hermosa, y que todo se aclare de inmediato".
En este proyecto, decidimos concentrarnos en visualizar solo gráficos: hay muchos algoritmos en gráficos que se pueden implementar de diferentes maneras, e incluso si se reducen, la tarea aún no es trivial.
También es más o menos obvio que la herramienta debe integrarse de alguna manera con el depurador. Necesitamos poder ver los valores de las variables y expresiones, y dibujar una imagen final de estos valores.
Después de eso, fue necesario encontrar un cierto lenguaje que nos permita construir un gráfico de acuerdo con el estado actual del programa de la manera que queramos. Además del gráfico en sí, era necesario proporcionar la capacidad de cambiar el color de los vértices y bordes, agregarles etiquetas arbitrarias y cambiar otras propiedades. En consecuencia, la primera idea fue:
- Determine qué tenemos vértices, por ejemplo, números de 0 a n.
- Determine la presencia de un borde entre los vértices utilizando la condición booleana. En este caso, los bordes son de diferentes tipos, y cada tipo tiene su propio conjunto de propiedades.
- Además, podemos definir propiedades de vértice como el color, también usando la condición booleana.
- Siga los pasos con el depurador: se calculan todas las expresiones, se verifican todas las condiciones y, según esto, se dibuja un gráfico.
Prototipos de interfaz de usuario
Dibujé el prototipo de la interfaz de usuario en
NinjaMock . Esto fue necesario para comprender mejor cómo se verá la interfaz desde el punto de vista del usuario y qué acciones necesitará realizar. Si hubiera problemas con el prototipo, entenderíamos que hay algunas inconsistencias lógicas, y esta idea debería descartarse. Por fidelidad, tomé algunos algoritmos. La siguiente imagen muestra ejemplos de cómo imaginé la configuración de visualización
DFS y
el algoritmo Floyd .
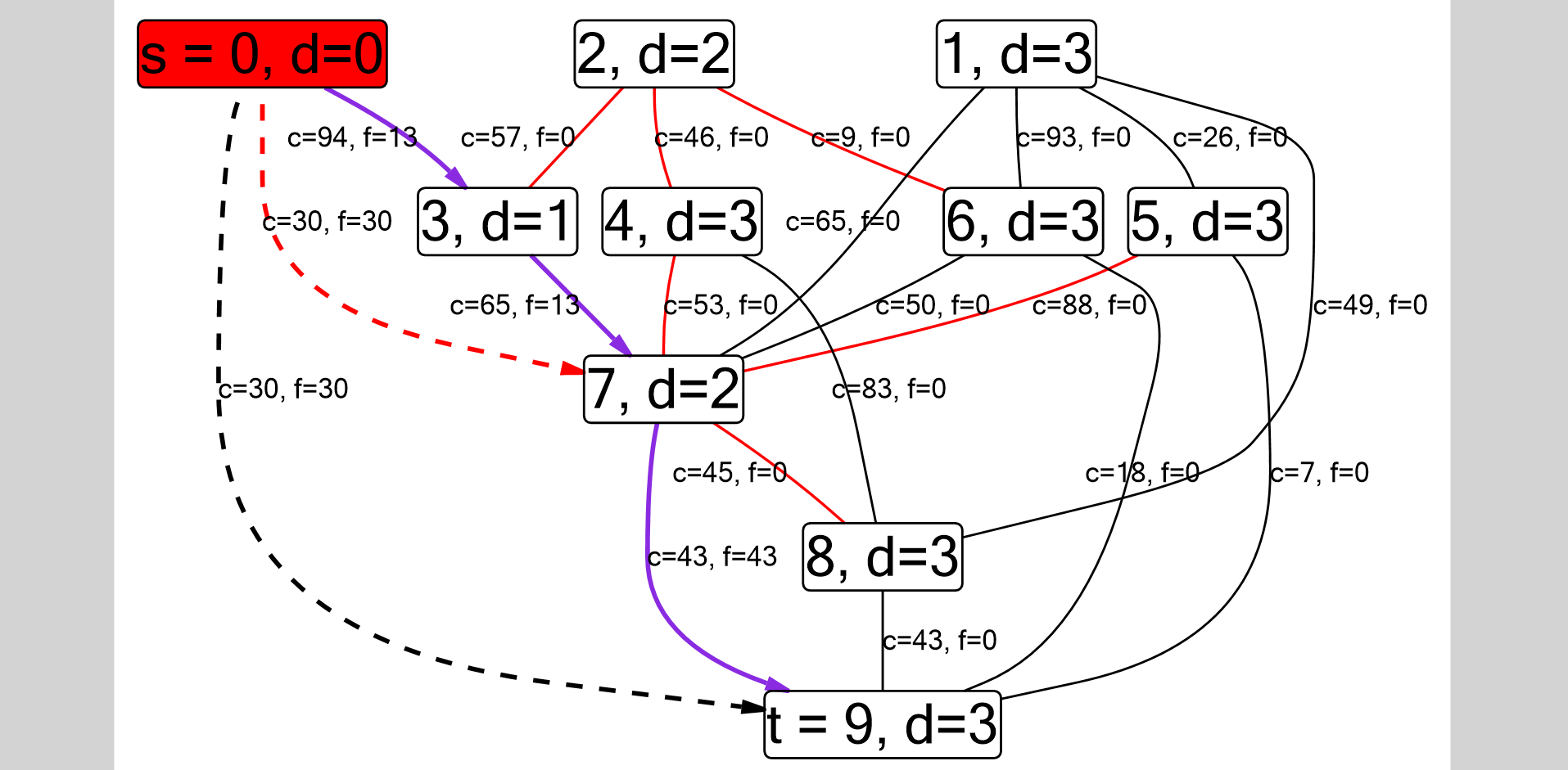
 Como me imaginaba la configuración de DFS. El gráfico se almacena como una lista de adyacencia, por lo que el borde entre los vértices i y j está determinado por la condición
Como me imaginaba la configuración de DFS. El gráfico se almacena como una lista de adyacencia, por lo que el borde entre los vértices i y j está determinado por la condición g[i].find() != g[i].end() (de hecho, para no duplicar los bordes, debemos verificar que i <= j ) La ruta DFS se muestra por separado: p[j] == i . Estos bordes estarán orientados.
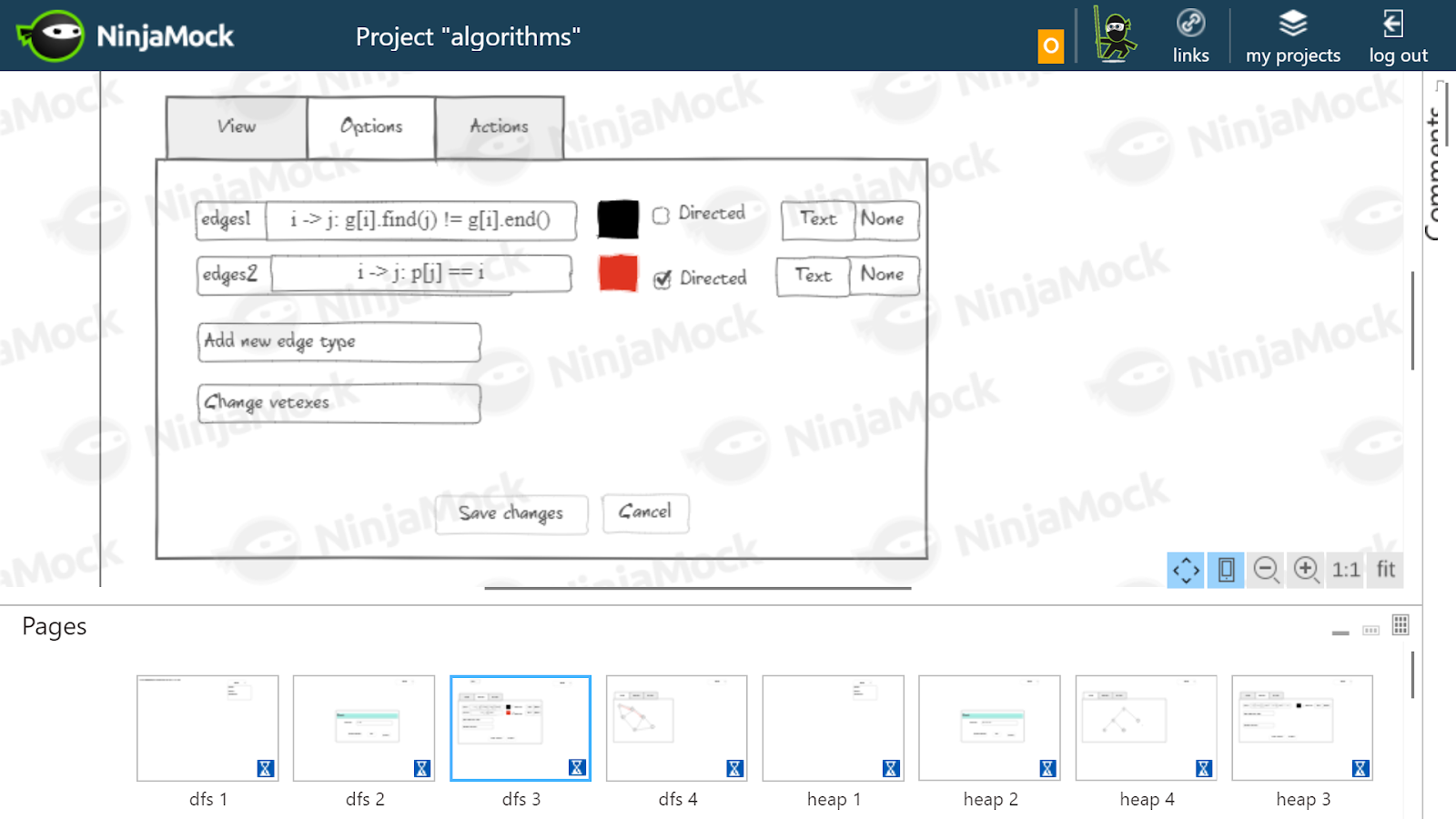
Supuse que para el algoritmo de Floyd, sería necesario dibujar en negro los bordes reales almacenados en la matriz c , y gris, las rutas más cortas encontradas en esta etapa, almacenadas en la matriz d . Para cada borde y camino más corto, se escribe su peso.Selección de dependencia
Para el siguiente paso, era necesario entender cómo hacer todo esto. En primer lugar, se requería la integración con un depurador. Lo primero que viene a la mente cuando la palabra "depurador" es gdb, pero luego tendría que crear toda la interfaz gráfica desde cero, lo que es realmente difícil para un estudiante en un semestre. La segunda idea obvia es hacer un complemento para algún entorno de desarrollo existente. Como opciones, consideré QTCreator, CLion y Visual Studio.
La opción CLion se descartó casi de inmediato, porque, en primer lugar, ha cerrado el código fuente y, en segundo lugar, todo está muy mal con la documentación (y nadie necesita dificultades adicionales). QTCreator, a diferencia de Visual Studio, es multiplataforma y de código abierto, y por lo tanto, al principio decidimos detenernos en él.
Sin embargo, resultó que QTCreator está mal adaptado para la extensión usando complementos. El primer paso para crear un complemento para QTCreator es construir desde la fuente. Me llevó una semana y media. Al final, envié dos informes de errores (
aquí y
allá ) con respecto al proceso de ensamblaje. Sí, ese es el esfuerzo realizado en la construcción de QTCreator solo para descubrir que el depurador en QTCreator no tiene una API pública. Regresé a otra opción, a saber, Visual Studio.
Y resultó ser la decisión correcta: Visual Studio no solo tiene una gran API, sino también una excelente documentación para ello. La
_debugger.GetExpression(...).Value expresiones
_debugger.GetExpression(...).Value simplificó llamando a
_debugger.GetExpression(...).Value . Visual Studio también proporciona la capacidad de iterar sobre los marcos y evaluar la expresión en el contexto de cualquiera de ellos. Para hacer esto, cambie la propiedad
CurrentStackFrame a la requerida. También puede realizar un seguimiento de las actualizaciones del concurso de depurador para volver a dibujar la imagen al cambiar.
Por supuesto, no se suponía que estaría involucrado en la visualización de gráficos desde cero; hay muchas bibliotecas especiales para esto. El más famoso de ellos es
Graphviz , y planeamos usarlo al principio. Pero para un complemento para Visual Studio, sería más lógico usar la biblioteca para C #, ya que iba a escribir en él. Busqué en Google un poco y encontré la biblioteca
MSAGL : tenía toda la funcionalidad requerida y tenía una interfaz simple e intuitiva.
Prueba de concepto
Ahora, teniendo un mecanismo para calcular expresiones arbitrarias por un lado y una biblioteca para visualizar gráficos por el otro, era necesario hacer un prototipo. El primer prototipo se hizo para DFS, luego se tomaron como ejemplo el
algoritmo Dinits,
el algoritmo Kuhn , la
búsqueda de componentes doblemente conectados , el árbol cartesiano y el
SNM . Tomé mis implementaciones anteriores de estos algoritmos del primer al segundo año, creé un nuevo complemento, dibujé un gráfico correspondiente a esta tarea (todos los nombres de variables estaban codificados). Aquí hay un ejemplo de un gráfico que obtuve para el algoritmo Kuhn:
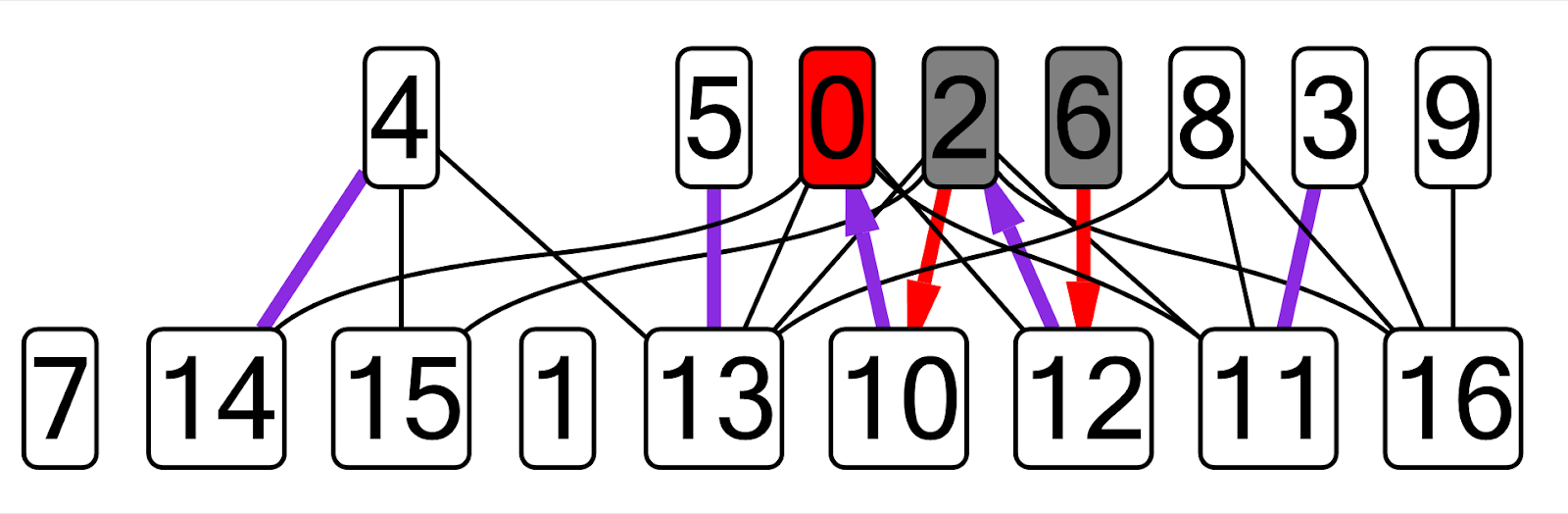 En este gráfico, los bordes coincidentes actuales se muestran en morado, el vértice dfs actual se muestra en rojo, los vértices visitados son grises, los bordes de una cadena alterna que no corresponde a la coincidencia se muestran en rojo.
En este gráfico, los bordes coincidentes actuales se muestran en morado, el vértice dfs actual se muestra en rojo, los vértices visitados son grises, los bordes de una cadena alterna que no corresponde a la coincidencia se muestran en rojo.Considere que está permitido modificar ligeramente el código del algoritmo para que sea más fácil de visualizar. Por ejemplo, en el caso del árbol cartesiano, resultó que es más fácil agregar todos los nodos creados a un vector que omitir el árbol dentro del complemento.
Un descubrimiento desagradable fue que el depurador en Visual Studio no admite métodos y funciones de llamada desde el STL. Esto significaba que no era posible verificar la presencia de un elemento en el contenedor usando
std::find , como se suponía originalmente. Este problema puede resolverse creando una función definida por el usuario o duplicando la propiedad "el elemento está contenido en el contenedor" en una matriz booleana.
En mis complementos de prueba, sucedió algo como lo siguiente (si el gráfico se almacenó como una lista de adyacencia):
- Primero viene el ciclo
for de 0 a _debugger.GetExpression("n").Value , que agregó todos los vértices al gráfico, cada uno con su propio número.
- Luego hay dos
_debugger.GetExpression($"g[{i}].size()").Value for anidados, el primero para i - de 0 a n , el segundo para j - de 0 a _debugger.GetExpression($"g[{i}].size()").Value , y el borde {i, _debugger.GetExpression($"g[{i}][{j}]").Value} .
- Si es necesario, se agregó información adicional a las etiquetas de los vértices y bordes. Por ejemplo, el valor de la matriz
d , que es responsable de la distancia al vértice seleccionado.
- Si el algoritmo se basaba en dfs, entonces un bucle atravesaba todos los cuadros y todos los vértices de la pila (
stackFrame.FunctionName.Equals("dfs") && stackFrame.Arguments.Item(1) == v ) se resaltaban en gris.
- Luego, para cada
i de 0 a n , que denota los números de los vértices, se verificaron algunas condiciones y, si se cumplieron, algunas propiedades cambiaron en el vértice, a menudo el color.
En ese momento, escribí el código "según sea necesario", sin tratar de elaborar un esquema general para todos los algoritmos, o escribir el código al menos de una manera hermosa. La creación de cada nuevo complemento comenzó con la copia y pegado del anterior.
Configuración gráfica
Después de la investigación, fue necesario elaborar un esquema general que pudiera aplicarse a todos los algoritmos. Lo primero que se introdujo fueron los índices para los vértices y los bordes. Cada índice tiene un nombre único y termina el rango, calculado usando
_debugger.GetExpression . Para acceder al valor del índice, use su nombre rodeado de __ (es decir, __x__). Las expresiones con lugares para sustituir valores de índice, así como el nombre de la función actual (__CURRENT_FUNCTION__) y los valores de sus argumentos (__ARG1__, __ARG2__, ...), se denominan plantillas.
Los índices se sustituyen por cada vértice o borde, y después de eso se calcula en el depurador. Se usaron plantillas para filtrar algunos valores de índice (si el gráfico se almacena como la matriz de adyacencia
c , entonces los índices serán a y b de 0 a n, y la plantilla para la validación es
c[__a__][__b__] ). Los límites del rango de índice también son plantillas, ya que pueden contener índices anteriores.
Un gráfico puede tener diferentes tipos de vértices y aristas. Por ejemplo, en el caso de buscar la coincidencia máxima en un gráfico bipartito, cada fracción se puede indexar por separado. Por lo tanto, se introdujo el concepto de familia para vértices y bordes. Para cada familia, la indexación y todas las propiedades se determinan de forma independiente. En este caso, los bordes pueden conectar vértices de diferentes familias.
Puede asignar propiedades específicas a una familia de vértices o aristas que se aplicarán selectivamente a los elementos de la familia. La propiedad se aplica si se cumple la condición. La condición consiste en una plantilla que se evalúa como
true o
false , y una expresión regular para el nombre de la función. La condición se verifica solo para el marco de vidrio actual o para todos los marcos de vidrio (y luego se considera cumplido si se cumple al menos para uno).
Las propiedades son muy diversas. Para vértices: etiqueta, color de relleno, color de borde, ancho de borde, forma, estilo de borde (por ejemplo, línea de puntos). Para bordes: etiqueta, color, ancho, estilo, orientación (puede especificar dos flechas, de principio a fin o viceversa; en este caso, puede haber dos flechas al mismo tiempo).
Es importante que cada vez que se dibuje el gráfico desde cero, y el estado anterior no se tenga en cuenta de ninguna manera. Esto puede ser un problema si el gráfico cambia dinámicamente durante el algoritmo: los vértices y los bordes pueden cambiar drásticamente su posición, y luego es difícil entender lo que está sucediendo.
Una descripción detallada de la configuración del gráfico se puede encontrar
aquí .
Interfaz de usuario
Con la interfaz, decidí no molestarme mucho. La ventana principal con la configuración (
ToolWindow ) contiene textarea para la
configuración serializada en JSON y una lista de familias de vértices y bordes. Cada familia tiene su propia ventana con configuraciones, y cada propiedad de la familia tiene una ventana más (se obtienen tres niveles de anidamiento). El gráfico en sí se dibuja en una ventana separada. No funcionó ponerlo en ToolWindow, así que envié un
informe de error a los desarrolladores de MSAGL, pero respondieron que este no era el caso de uso objetivo.
Se envió
otro informe de error a Visual Studio, ya que TextBoxes a veces colgaba en las ventanas de configuración adicionales.
Plugin
Para configurar el gráfico, el complemento tiene una interfaz de usuario y la capacidad de (des) serializar la configuración en JSON. El esquema general de interacción de todos los componentes es el siguiente:
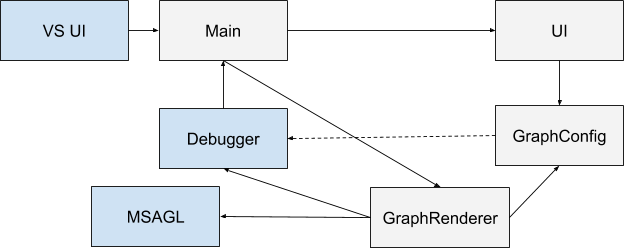
Azul muestra los componentes que existían originalmente, gris, que creé. Cuando se inicia Visual Studio, la extensión se inicializa (aquí el componente principal se designa como Principal). El usuario tiene la oportunidad de especificar la configuración a través de la interfaz. Cada vez que se cambia el contexto del depurador, se notifica al componente principal. Si se define la configuración y se ejecuta el programa que se está depurando, se inicia GraphRenderer. Recibe una entrada de configuración y, con la ayuda de un depurador, crea un gráfico en él, que luego se muestra en una ventana especial.
Ejemplos
Como resultado, creé una herramienta que le permite visualizar algoritmos gráficos y requiere pequeños cambios en el código. Ha sido probado en ocho tareas diferentes. Aquí hay algunas fotos resultantes:
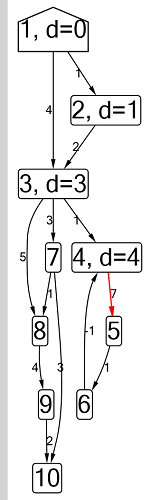 Algoritmo de Ford-Bellman : el vértice en el que contamos los caminos más cortos está indicado por una casa, la distancia más corta actual encontrada para los vértices es d, y el borde a lo largo del cual pasa la relajación es rojo.
Algoritmo de Ford-Bellman : el vértice en el que contamos los caminos más cortos está indicado por una casa, la distancia más corta actual encontrada para los vértices es d, y el borde a lo largo del cual pasa la relajación es rojo.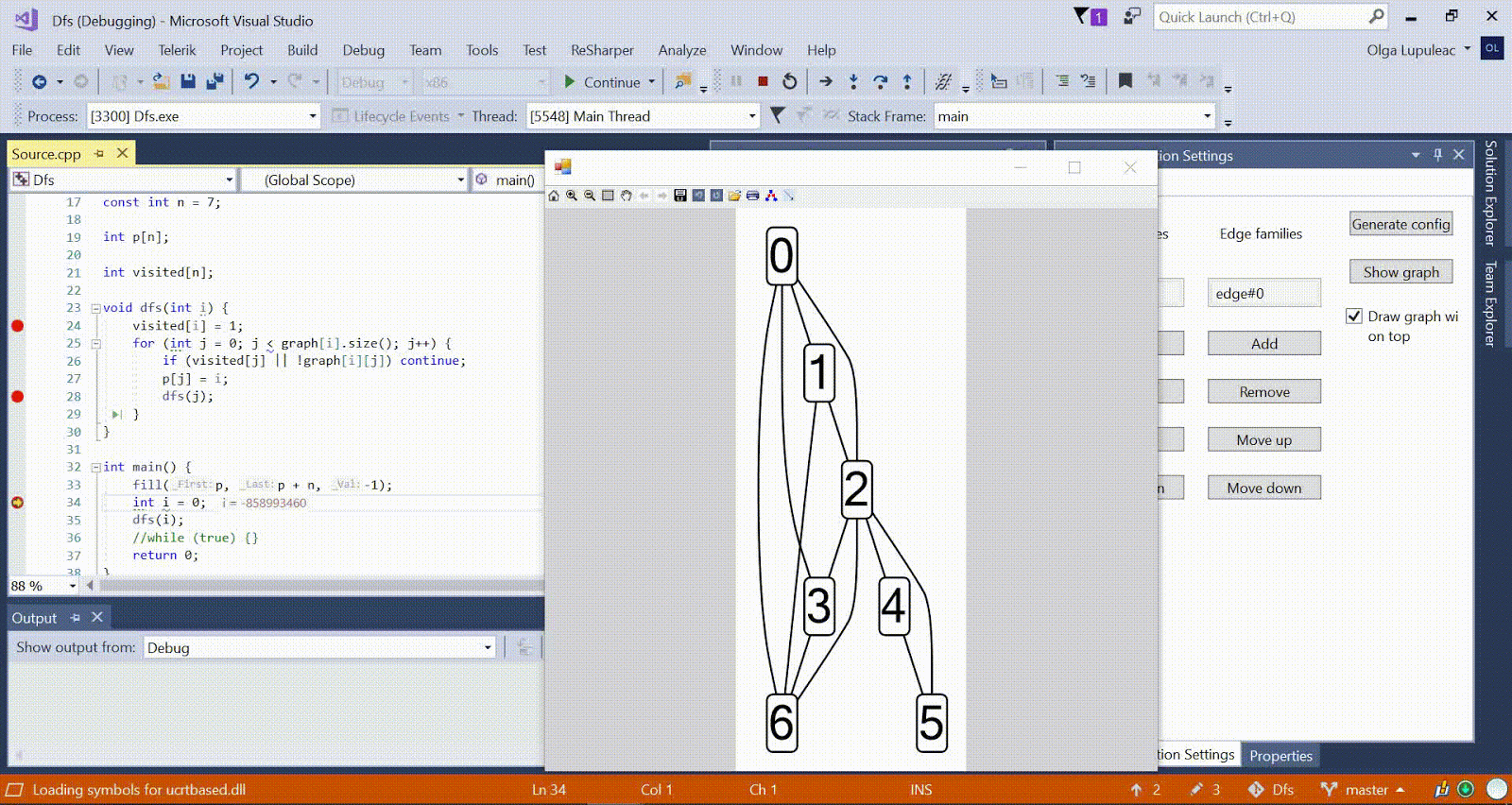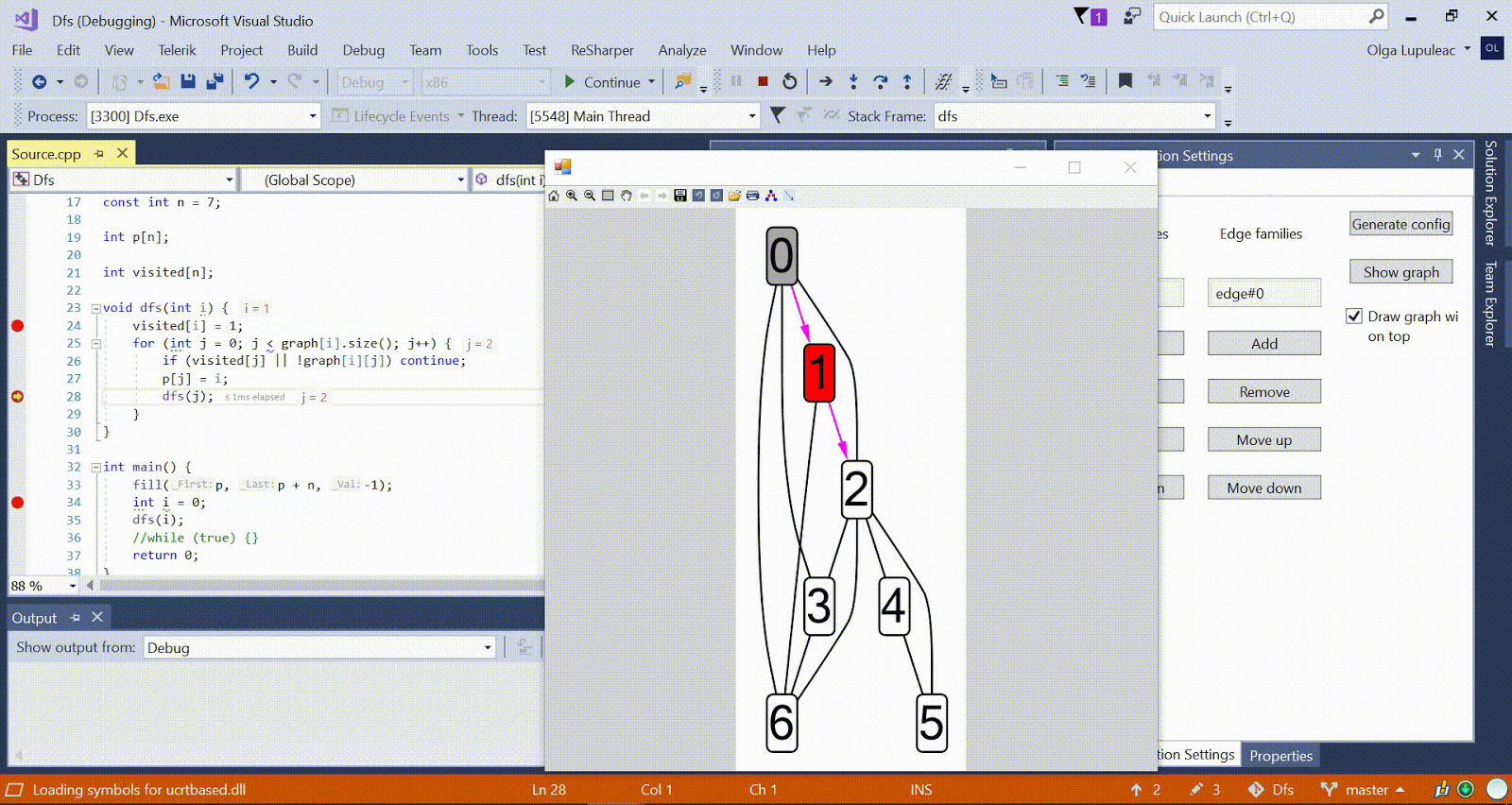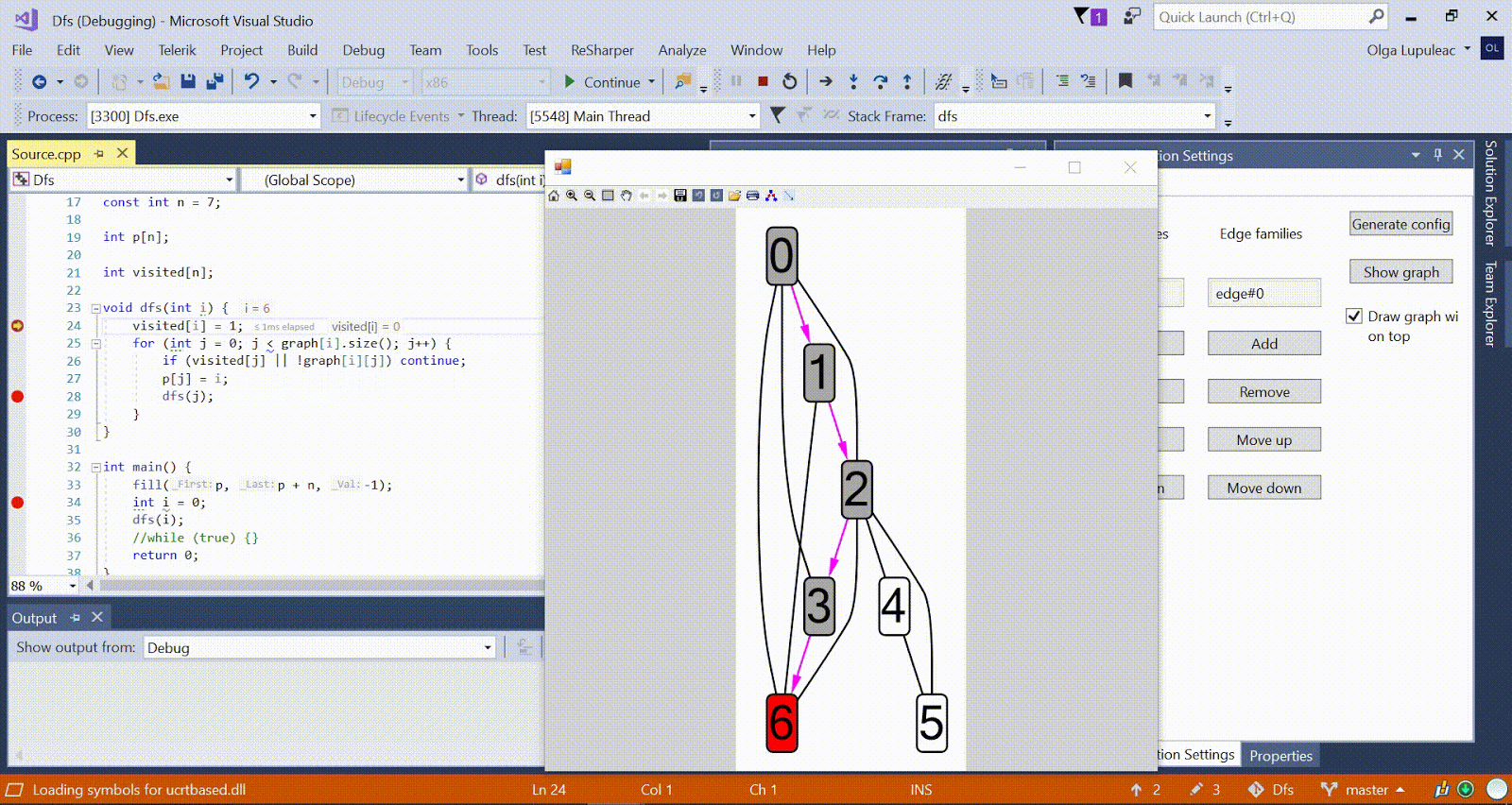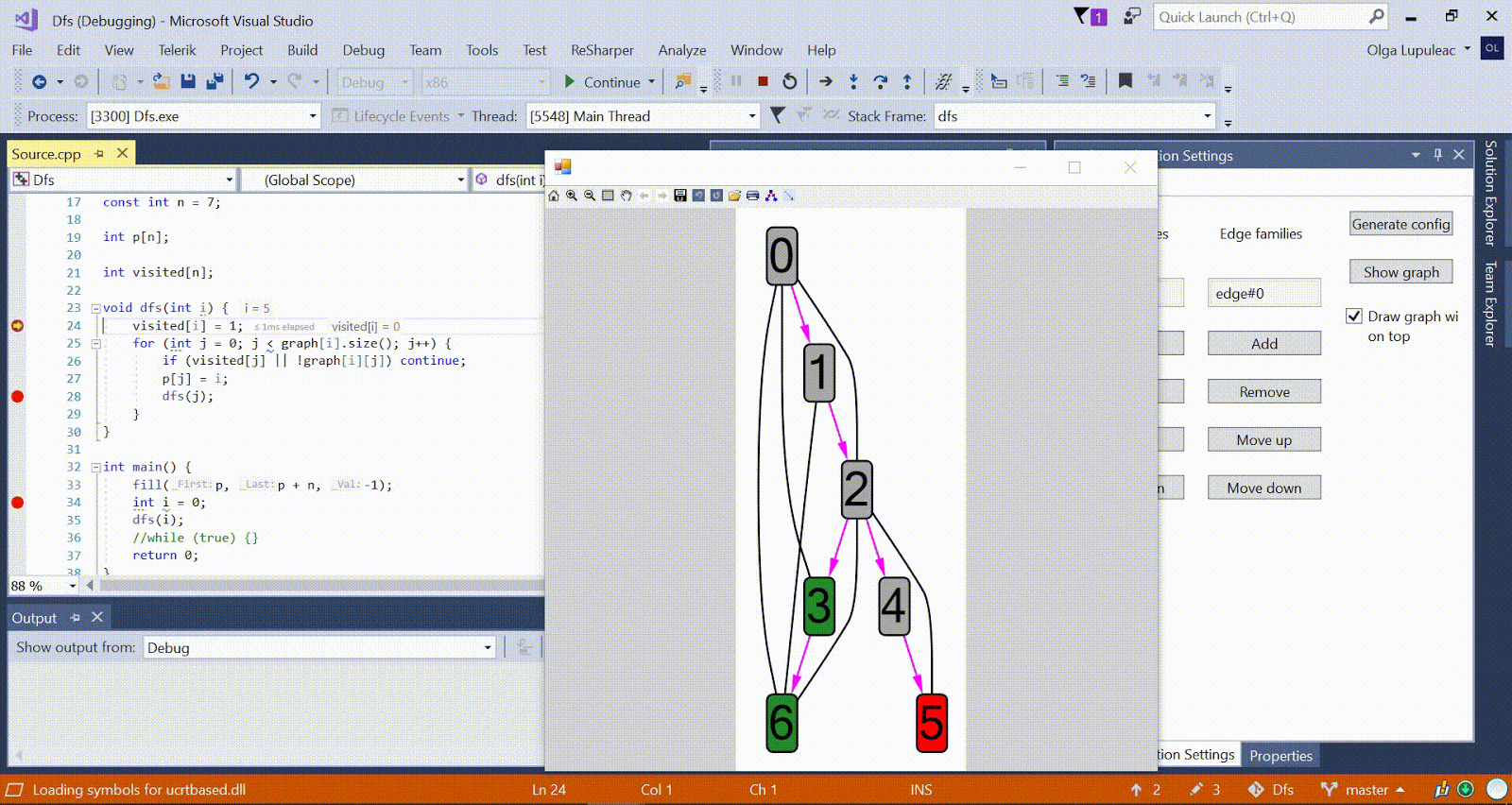 Animación con DFS: el vértice actual se muestra en rojo, los vértices en la pila son grises y los otros vértices visitados son verdes. Costillas de frambuesa indican la dirección de la derivación.
Animación con DFS: el vértice actual se muestra en rojo, los vértices en la pila son grises y los otros vértices visitados son verdes. Costillas de frambuesa indican la dirección de la derivación.Más algoritmos de muestra están disponibles
aquí.Protección NIR
Para proteger el trabajo de investigación, se requiere que los estudiantes cuenten en siete minutos sobre su trabajo durante un semestre. Al mismo tiempo, independientemente de si el tema se propuso como parte de la presentación del trabajo de investigación o si el estudiante lo encontró por su cuenta, debe poder responder para justificar por qué el tema del proyecto cumple los requisitos descritos al principio. Por lo general, un informe está estructurado de la siguiente manera: primero hay motivación, luego una revisión de los análogos, se dice por qué no nos convienen, luego se formulan las metas y objetivos, y luego cada una de las tareas se describe cómo se resolvió. Al final hay una diapositiva con los resultados, que una vez más dice que el objetivo se ha logrado y que todas las tareas están resueltas.
Como ya había decidido la motivación y la revisión de los análogos en la etapa inicial, solo necesitaba recopilar toda la información y comprimirla en siete minutos. Al final, tuve éxito, la defensa fue sin problemas, me dieron el puntaje máximo para la investigación.
Referencias