En los grandes sistemas en la nube, el problema del equilibrio automático o el equilibrio de la carga en los recursos informáticos es especialmente grave. Tionics también se ocupó de este problema (el desarrollador y operador de servicios en la nube, somos parte del grupo de empresas Rostelecom).
Y, dado que nuestra plataforma de desarrollo principal es Openstack, y nosotros, como todas las personas, somos perezosos, se decidió elegir algún tipo de módulo listo para usar que ya es parte de la plataforma. Nuestra elección recayó en Watcher, que decidimos usar para nuestras necesidades.

Primero, tratemos con términos y definiciones.
Términos y definiciones
Una meta es un resultado final legible, observable y medible para el ser humano que debe lograrse. Para lograr cada objetivo, hay una o más estrategias. Una estrategia es una implementación de un algoritmo que puede encontrar una solución para un propósito determinado.
Una acción es una tarea elemental que cambia el estado actual de un recurso administrado de destino de un clúster OpenStack, como: migrar una máquina virtual (migración), cambiar el estado de la potencia de un nodo (change_node_power_state), cambiar el estado de un servicio de nova (change_nova_service_state), cambiar un sabor (cambiar el tamaño) , registrando un mensaje NOP (nop), la ausencia de acciones durante un cierto período de tiempo: pausa (suspensión), transferencia de disco (volume_migrate).
Plan de acción (Plan de acción) : una secuencia específica de acciones llevadas a cabo en un orden específico para lograr un objetivo específico. El plan de acción también contiene un desempeño global estimado con un conjunto de indicadores de desempeño. El plan de acción es generado por Watcher durante una auditoría exitosa, como resultado de lo cual la estrategia utilizada encuentra una solución para lograr el objetivo. Un plan de acción consiste en una lista de acciones secuenciales.
La auditoría es una solicitud de optimización de clúster. La optimización se realiza para lograr un objetivo en un grupo determinado. Para cada auditoría exitosa, Watcher genera un plan de acción.
Audit Scope es un conjunto de recursos dentro del cual se realiza una auditoría (zona (s) de disponibilidad, agregadores de nodos, nodos informáticos individuales o nodos de almacenamiento, etc.). Se define un alcance de auditoría en cada plantilla. Si no se especifica el alcance de la auditoría, se audita todo el clúster.
Plantilla de auditoría : un conjunto de configuraciones guardadas para iniciar una auditoría. Se necesitan plantillas para ejecutar auditorías con la misma configuración varias veces. La plantilla debe contener necesariamente el propósito de la auditoría; si no se indican las estrategias, se seleccionan las estrategias existentes más adecuadas.
Un clúster es un conjunto de máquinas físicas que proporcionan recursos informáticos, de almacenamiento y de red y son administrados por el mismo nodo de control OpenStack.
El modelo de datos del clúster (CDM) es una representación lógica del estado actual y la topología de los recursos administrados por el clúster.
Indicador de eficiencia (indicador de eficacia) : un indicador que indica cómo se implementa la solución creada con esta estrategia. Los indicadores de desempeño son específicos de un objetivo particular y se usan comúnmente para calcular la efectividad global de un plan de acción final.
La especificación de eficacia es un conjunto de características específicas asociadas con cada objetivo, que define varios indicadores de rendimiento que la estrategia que garantiza el logro del objetivo correspondiente debe proporcionar en su decisión. De hecho, cada solución propuesta por la estrategia se verificará para el cumplimiento de la especificación antes de calcular su efectividad global.
Un "motor de puntuación" es un archivo ejecutable que tiene datos de entrada claramente definidos, datos de salida claramente definidos y realiza una tarea puramente matemática. Por lo tanto, el cálculo no depende del entorno en el que se realiza: dará el mismo resultado en cualquier lugar.
Watcher Planner es parte del motor de decisiones de Watcher. Este módulo acepta el conjunto de acciones generadas por la estrategia y crea un plan de flujo de trabajo que define cómo planificar estas diversas acciones a tiempo y para cada acción, cuáles son los requisitos previos.
Metas y estrategias del observador
Meta ficticia : una meta de reserva que se utiliza con fines de prueba.
Estrategias relacionadas: estrategia ficticia, estrategia ficticia utilizando motores de puntuación de muestra y estrategia ficticia con cambio de tamaño. La estrategia ficticia es una estrategia ficticia utilizada para las pruebas de integración a través de Tempest. Esta estrategia no proporciona ninguna optimización útil; su único propósito es usar las pruebas de Tempest.
Estrategia ficticia con motores de puntuación de muestra: la estrategia es similar a la anterior, solo difiere en el uso de la muestra del "motor de evaluación", que cuenta con métodos de aprendizaje automático.
Estrategia ficticia con cambio de tamaño: la estrategia es similar a la anterior, solo difiere en el uso de cambiar el sabor (migración y cambio de tamaño).
No se usa en producción.
Ahorro de energía : minimice el consumo de energía. Estrategia para este objetivo Ahorrar energía La estrategia junto con la VM Workload Consolidation Strategy (Server Consolidation) es capaz de realizar funciones de administración dinámica de energía (DPM), que ahorran energía al consolidar dinámicamente las cargas de trabajo incluso durante períodos de baja carga de recursos: las máquinas virtuales se transfieren a menos nodos , y los nodos innecesarios se desconectan. Después de la consolidación, la estrategia ofrece la decisión de encender / apagar los nodos de acuerdo con los parámetros dados: "min_free_hosts_num" - el número de nodos incluidos gratis que están esperando carga, y "free_used_percent" - el porcentaje de nodos incluidos gratis al número de nodos ocupados por las máquinas. Para que la estrategia
funcione, Ironic debe estar
encendido y configurado para funcionar con encendido / apagado en los nodos.Opciones de estrategia
Debe haber al menos dos nodos en la nube. El método utilizado es cambiar el estado de energía del nodo (change_node_power_state).
La estrategia no requiere la recopilación de métricas.Consolidación del servidor: minimice el número de nodos de proceso (consolidación). Tiene dos estrategias: Consolidación básica del servidor fuera de línea y Estrategia de consolidación de carga de trabajo de VM.
La estrategia de consolidación de servidor fuera de línea básica minimiza el número total de servidores utilizados y también minimiza el número de migraciones.
La estrategia básica requiere las siguientes métricas:
Parámetros de la estrategia: migración_intentos: el número de combinaciones para buscar posibles candidatos para el cierre (predeterminado, 0, sin restricciones), período - intervalo de tiempo en segundos para obtener la agregación estática del origen de datos métricos (700 por defecto).
Métodos utilizados: migración, cambio de estado del servicio nova (change_nova_service_state).
La estrategia de consolidación de carga de trabajo de VM se basa en el algoritmo heurístico de primer ajuste, que se enfoca en la carga de CPU medida y trata de minimizar los nodos que tienen mucha o muy poca carga, teniendo en cuenta las limitaciones de capacidad de recursos. Esta estrategia proporciona una solución que conduce a un uso más eficiente de los recursos del clúster utilizando los siguientes cuatro pasos:
- Fase de descarga: procesamiento de recursos utilizados en exceso;
- Fase de consolidación: procesamiento de recursos subutilizados;
- Optimización de la solución: reducción del número de migraciones;
- Deshabilitar nodos informáticos no utilizados.
La estrategia requiere las siguientes métricas:
Las siguientes métricas son opcionales, pero mejoran la precisión de la estrategia si está disponible:
Parámetros de estrategia: período - intervalo de tiempo en segundos para obtener la agregación estática del origen de datos métricos (3600 por defecto).
Utiliza los mismos métodos que la estrategia anterior. Más detalles
aquí .
Equilibrio de la carga de trabajo : equilibre la carga de trabajo entre nodos de proceso. El objetivo tiene tres estrategias: estrategia de migración de equilibrio de carga de trabajo, estabilización de la carga de trabajo, estrategia de equilibrio de capacidad de almacenamiento.
Workload Balance Migration Strategy lanza migraciones de máquinas virtuales basadas en la carga de trabajo de las máquinas virtuales host. La decisión de transferir se toma siempre que el% de utilización de CPU o RAM del nodo exceda el umbral especificado. En este caso, la máquina virtual movida debería acercar el nodo a la carga de trabajo promedio de todos los nodos.
Requisitos
- Uso de procesadores físicos;
- Al menos dos nodos de computación física;
- El componente de Ceilometer instalado y configurado es el cómputo de agente de ceilometer que trabaja en cada nodo informático y la API de Ceilometer, además de recopilar las siguientes métricas:
Opciones de estrategia:
El método utilizado es la migración.
Estabilización de la carga de trabajo: una estrategia dirigida a estabilizar la carga de trabajo mediante la migración en vivo. La estrategia se basa en el algoritmo de desviación estándar y determina si hay congestión en el clúster y responde a él al activar una migración de máquina para estabilizar el clúster.
Requisitos
- Uso de procesadores físicos;
- Al menos dos nodos de computación física;
- El componente de Ceilometer instalado y configurado es el cómputo de agente de ceilometer que trabaja en cada nodo informático y la API de Ceilometer, además de recopilar las siguientes métricas:
Estrategia de equilibrio de capacidad de almacenamiento (una estrategia implementada desde Queens): la estrategia transfiere discos según la carga de los grupos de Cinder. La decisión de transferencia se toma cada vez que la utilización del grupo excede el umbral especificado. Un disco móvil debería acercar el grupo a la carga promedio de todos los grupos de Cinder.
Requerimientos y limitaciones
- Al menos dos piscinas de ceniza;
- Posibilidad de migrar discos.
- Cluster de colector de modelo de datos.
Opciones de estrategia:
El método utilizado es la migración del disco (volume_migrate).
Vecino ruidoso: identifique y migre un "vecino ruidoso": una máquina virtual de baja prioridad que afecta negativamente el rendimiento de una máquina virtual de alta prioridad desde el punto de vista de IPC, utilizando en exceso el caché de último nivel. Estrategia propia: Vecino ruidoso (el parámetro de estrategia utilizado es cache_threshold (el valor predeterminado es 35), la migración comienza cuando el rendimiento cae al valor especificado. Para que la estrategia funcione, las
métricas incluidas de
LLC (caché de último nivel), el último servidor Intel con soporte CMT y también recopilación de las siguientes métricas:
Modelo de datos del clúster (predeterminado): recopilador del modelo de datos del clúster Nova. El método aplicado es la migración.
El trabajo para este propósito a través de Dashboard no está completamente implementado en Queens.
Optimización térmica : optimiza las condiciones de temperatura. La temperatura de salida (aire de escape) es uno de los sistemas importantes de telemetría térmica para medir el estado de la carga térmica / de trabajo del servidor. Para este propósito, hay una estrategia: la estrategia basada en la temperatura de salida, que toma decisiones sobre la transferencia de cargas de trabajo a nodos con condiciones de temperatura favorables (la temperatura más baja a la salida) cuando la temperatura en la salida de los hosts originales alcanza un umbral personalizado.
Para que la estrategia funcione, necesita un servidor con Intel Power Node Manager
3.0 instalado
o posterior , además de recopilar las siguientes métricas:
Opciones de estrategia:
El método utilizado es la migración.
Optimización del flujo de aire : optimice el modo de ventilación. Estrategia propia: flujo de aire uniforme mediante migración en vivo. La estrategia comienza la migración de la máquina virtual siempre que el flujo de aire del ventilador del servidor excede el umbral especificado.
Para trabajar, la estrategia requiere:
- Hardware: nodos informáticos <con soporte NodeManager 3.0;
- Al menos dos nodos de cálculo;
- Los componentes ceilometer-agent-compute y Ceilometer API instalados y configurados en cada nodo informático pueden informar con éxito métricas como el flujo de aire, la potencia del sistema y la temperatura de entrada:
Para que la estrategia funcione, necesita un servidor con Intel Power Node Manager 3.0 o posterior instalado y configurado.
Limitaciones: El concepto no está destinado a la producción.
Se propone utilizar este algoritmo con auditorías continuas, ya que solo se planea migrar una máquina virtual por iteración.
Las migraciones en vivo son posibles.
Opciones de estrategia:
El método utilizado es la migración.
Mantenimiento de hardware - mantenimiento de hardware. Una estrategia relacionada con este objetivo es la migración de zona. La estrategia es una herramienta para una migración eficiente automática y mínima de máquinas virtuales y discos en caso de mantenimiento de hardware. La estrategia construye un plan de acción de acuerdo con los pesos: un conjunto de acciones que tiene más peso se planificará por delante de los demás. Hay dos opciones de configuración: pesos de acción (action_weights) y paralelización.
Limitaciones: es necesario ajustar los pesos de las acciones y la paralelización.
Opciones de estrategia:
Elementos de una matriz de nodos informáticos:
Elementos de una matriz de nodos de almacenamiento:
Elementos de objetos prioritarios:
Métodos utilizados: migración de máquinas virtuales, migración de discos.
Sin clasificar es un objetivo de apoyo utilizado para facilitar el desarrollo de una estrategia. No contiene especificaciones y puede usarse cuando la estrategia aún no está conectada con un objetivo existente. Este objetivo también se puede utilizar como una etapa de transición. Una estrategia relacionada es el Actuador.
Crea un nuevo objetivo
Watcher Decision Engine tiene una interfaz de complemento de "objetivo externo" que le permite integrar un objetivo externo que puede lograrse mediante la estrategia.
Antes de crear un nuevo objetivo, debe asegurarse de que ninguno de los objetivos existentes satisfaga sus necesidades.
Crea un nuevo complemento
Para crear un nuevo objetivo, debe: extender la clase objetivo, implementar el método de clase
get_name () para devolver un identificador único para el nuevo objetivo que desea crear. Este identificador único debe coincidir con el nombre del punto de entrada que declare más adelante.
A continuación, debe implementar el método de clase
get_display_name () para devolver el nombre para mostrar traducido del destino que desea crear (no use la variable para devolver la cadena traducida para que la herramienta de traducción pueda recopilarla automáticamente).
Implemente el método de clase
get_translatable_display_name () para devolver la clave de traducción (en realidad, el nombre para mostrar en inglés) de su nuevo destino. El valor de retorno debe coincidir con la cadena traducida a get_display_name ().
Implemente su método
get_efficacy_specification () para devolver la especificación de rendimiento para su propósito. El método get_efficacy_specification () devuelve la instancia Unclassified () proporcionada por Watcher. Esta especificación de rendimiento es útil en el proceso de desarrollo de su objetivo porque cumple con la especificación vacía.
→
Más detalles aquíObservador de Arquitectura (más información
aquí ).
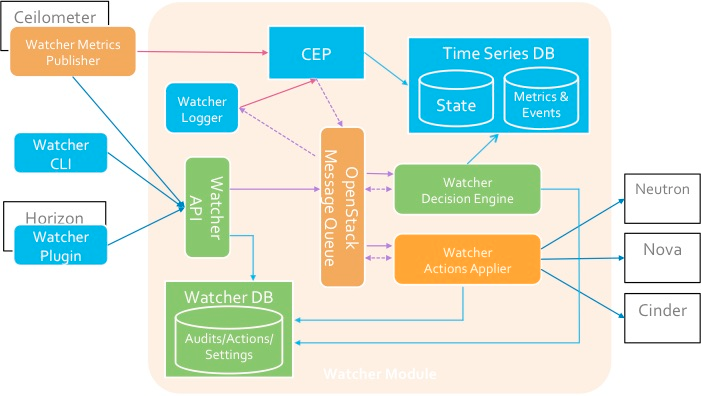
Componentes
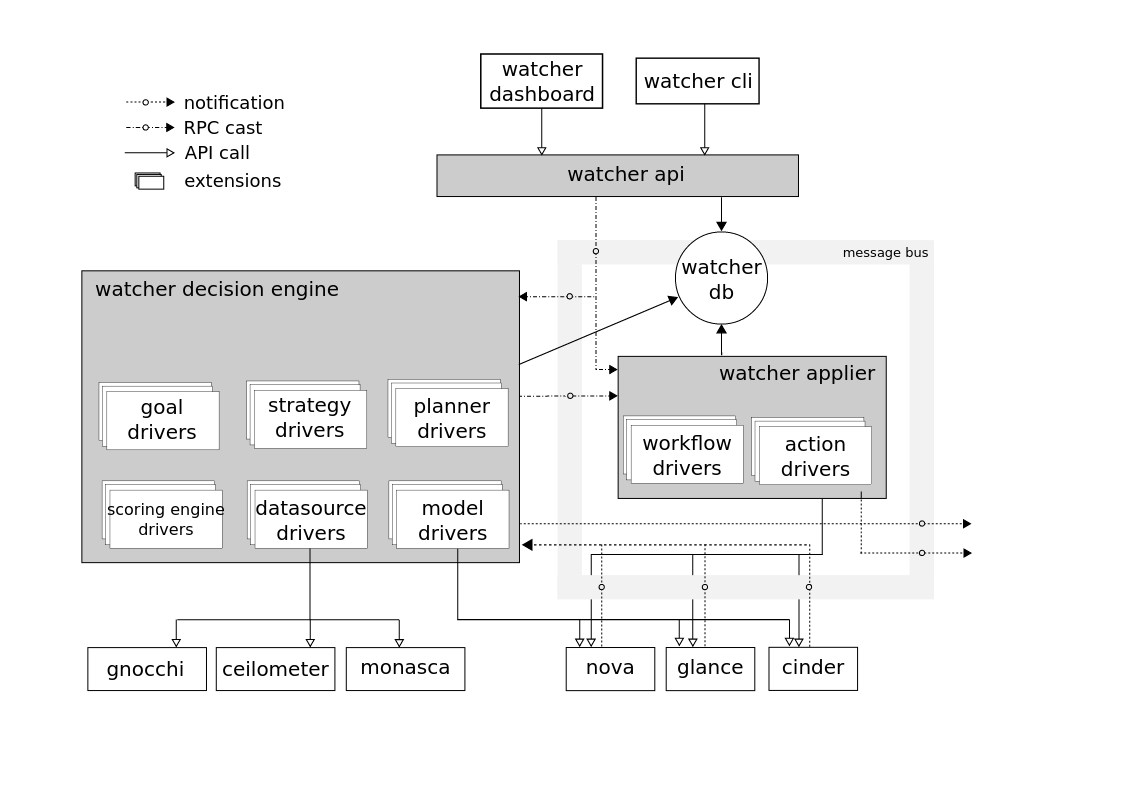 Watcher API
Watcher API : un componente que implementa la API REST proporcionada por Watcher. Mecanismos de interacción: CLI, complemento Horizon, Python SDK.
Watcher DB : base de datos de vigilantes.
Watcher Applier : un componente que implementa la implementación del plan de acción creado por el componente Watcher Decision Engine.
Watcher Decision Engine es un componente responsable de calcular un conjunto de posibles acciones de optimización para cumplir un objetivo de auditoría. Si no se especifica una estrategia, el componente selecciona independientemente la más adecuada.Watcher Metrics Publisher es un componente que recopila y calcula algunas métricas o eventos y los publica en el punto final de CEP. La funcionalidad de la característica también puede ser proporcionada por el editor de Ceilometer.Motor de procesamiento de eventos complejos (CEP)- motor para el procesamiento de eventos complejos. Por razones de rendimiento, puede haber varias instancias del motor CEP ejecutándose al mismo tiempo, cada una de las cuales maneja un tipo específico de métrica / evento. En el sistema Watcher, CEP lanza dos tipos de acciones: - escribe los eventos / métricas correspondientes en la base de datos de series temporales; - envíe eventos relevantes al componente Watcher Decision Engine cuando este evento pueda afectar el resultado de la estrategia de optimización actual, ya que el clúster Openstack no es un sistema estático.La interacción de los componentes se lleva a cabo de acuerdo con el protocolo AMQP.→ Configuración de WatcherEsquema de interacción con Watcher

Resultados de la prueba de vigilante
- Optimization — Action plans 500 ( Queens, ), , , .
- Action details , ( Queens, ).
- Dummy () , .
- Unclassified , .
- Workload Balancing ( Storage Capacity balance) , . .
- Workload Balancing ( Workload Balance Migration Strategy) , .
- Workload Balancing ( Workload Stabilization Strategy) .
- Noisy Neighbor , .
- Hardware maintenance , ( , ).
- nova.conf ( default compute_monitors = cpu.virt_driver) .
- Server Consolidation ( Basic) .
- Server Consolidation ( VM workload consolidation) . . , , .
- Watcher ( — Optimization, - ):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Saving Energy . , - Ironic, baremetal service.
- Thermal Optimization . , Server Consolidation ( VM workload consolidation) ( )
- Las auditorías para la optimización del flujo de aire fallan.
También se encuentran los siguientes errores de finalización de auditoría. Rastreo en decision-engine.log logs (el estado del clúster no está definido).→ Discusión del error aquíConclusión
El resultado de nuestra investigación de dos meses fue la conclusión inequívoca de que para obtener un sistema de equilibrio de carga en pleno funcionamiento, tendremos que trabajar estrechamente para finalizar las herramientas para la plataforma Openstack.Watcher ha demostrado ser un producto serio y de rápido desarrollo con un enorme potencial, para el uso completo del cual se requerirá mucho trabajo serio.Pero más sobre eso en los próximos artículos del ciclo.