La recopilación, almacenamiento, conversión y presentación de datos son los principales desafíos que enfrentan los ingenieros de datos. El departamento de Business Intelligence Badoo recibe y procesa más de 20 mil millones de eventos enviados desde dispositivos de usuario por día, o 2 TB de datos entrantes.
El estudio e interpretación de todos estos datos no siempre es una tarea trivial, a veces es necesario ir más allá de las capacidades de las bases de datos preparadas. Y si tiene el coraje y decidió hacer algo nuevo, primero debe familiarizarse con los principios de funcionamiento de las soluciones existentes.
En una palabra, desarrolladores curiosos y de mente fuerte, se aborda este artículo. En él encontrará una descripción del modelo tradicional de ejecución de consultas en bases de datos relacionales utilizando el lenguaje de demostración PigletQL como ejemplo.
Contenido
Antecedentes
Nuestro grupo de ingenieros se dedica a backends e interfaces, brindando oportunidades para el análisis e investigación de datos dentro de la empresa (por cierto, nos estamos expandiendo ). Nuestras herramientas estándar son una base de datos distribuida de docenas de servidores (Exasol) y un clúster Hadoop para cientos de máquinas (Hive y Presto).
La mayoría de las consultas a estas bases de datos son analíticas, es decir, afectan de cientos de miles a miles de millones de registros. Su ejecución lleva minutos, decenas de minutos o incluso horas, dependiendo de la solución utilizada y la complejidad de la solicitud. Con el trabajo manual del analista de usuario, dicho tiempo se considera aceptable, pero no es adecuado para la investigación interactiva a través de la interfaz de usuario.
Con el tiempo, destacamos las consultas y consultas analíticas populares, que son difíciles de establecer en términos de SQL, y desarrollamos pequeñas bases de datos especializadas para ellas. Almacenan un subconjunto de datos en un formato adecuado para algoritmos de compresión livianos (por ejemplo, streamvbyte), que le permite almacenar datos en una sola máquina durante varios días y ejecutar consultas en segundos.
Los primeros lenguajes de consulta para estos datos y sus intérpretes se implementaron en una corazonada, tuvimos que refinarlos constantemente, y cada vez tomó un tiempo inaceptablemente largo.
Los lenguajes de consulta no eran lo suficientemente flexibles, aunque no había razones obvias para limitar sus capacidades. Como resultado, recurrimos a la experiencia de los desarrolladores de intérpretes de SQL, gracias a los cuales pudimos resolver parcialmente los problemas que surgieron.
A continuación, hablaré sobre el modelo de ejecución de consultas más común en bases de datos relacionales: Volcano. El código fuente del intérprete del dialecto SQL primitivo, PigletQL , se adjunta al artículo , por lo que todos los interesados pueden familiarizarse fácilmente con los detalles en el repositorio.
Estructura de intérprete de SQL
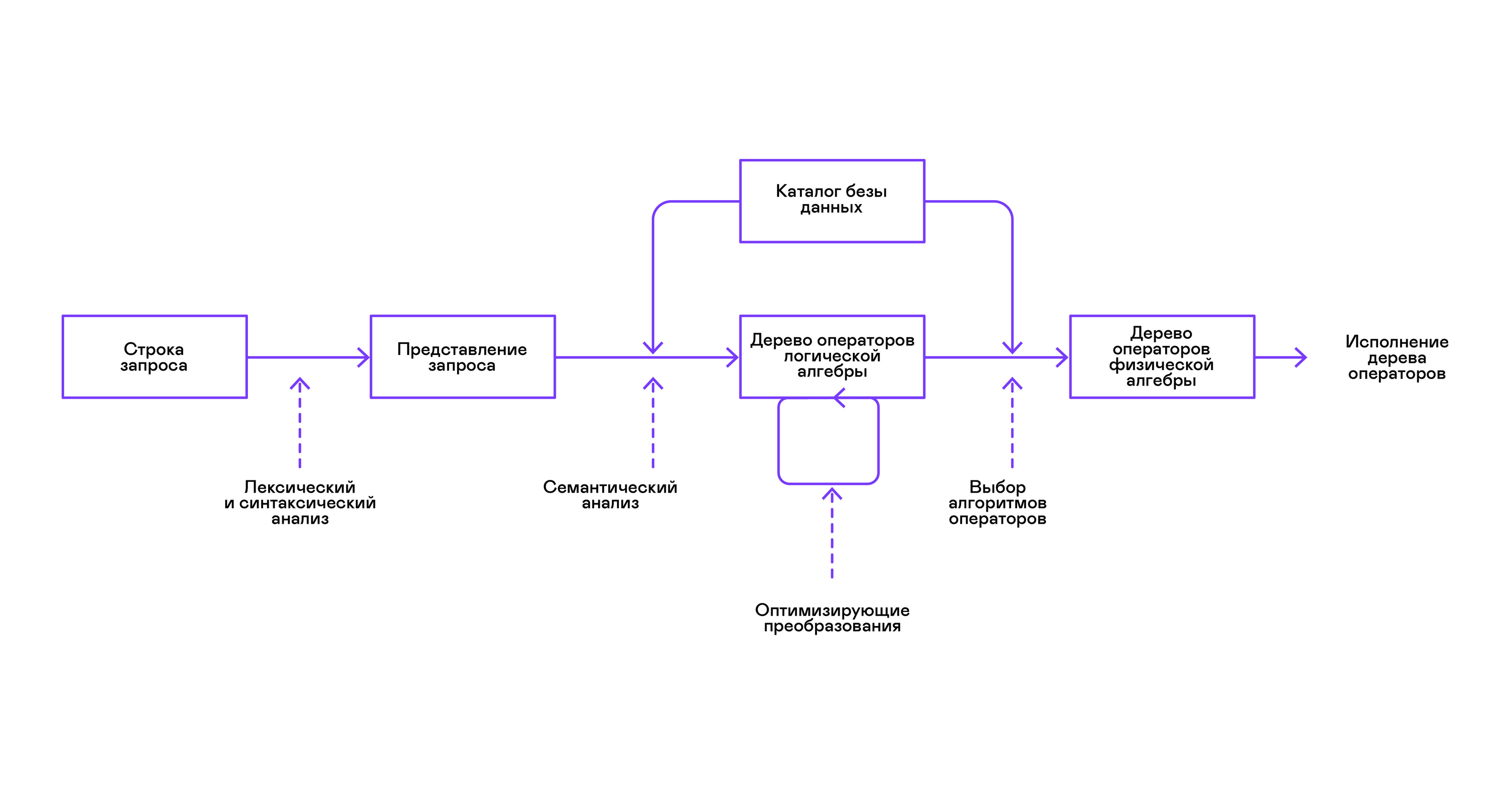
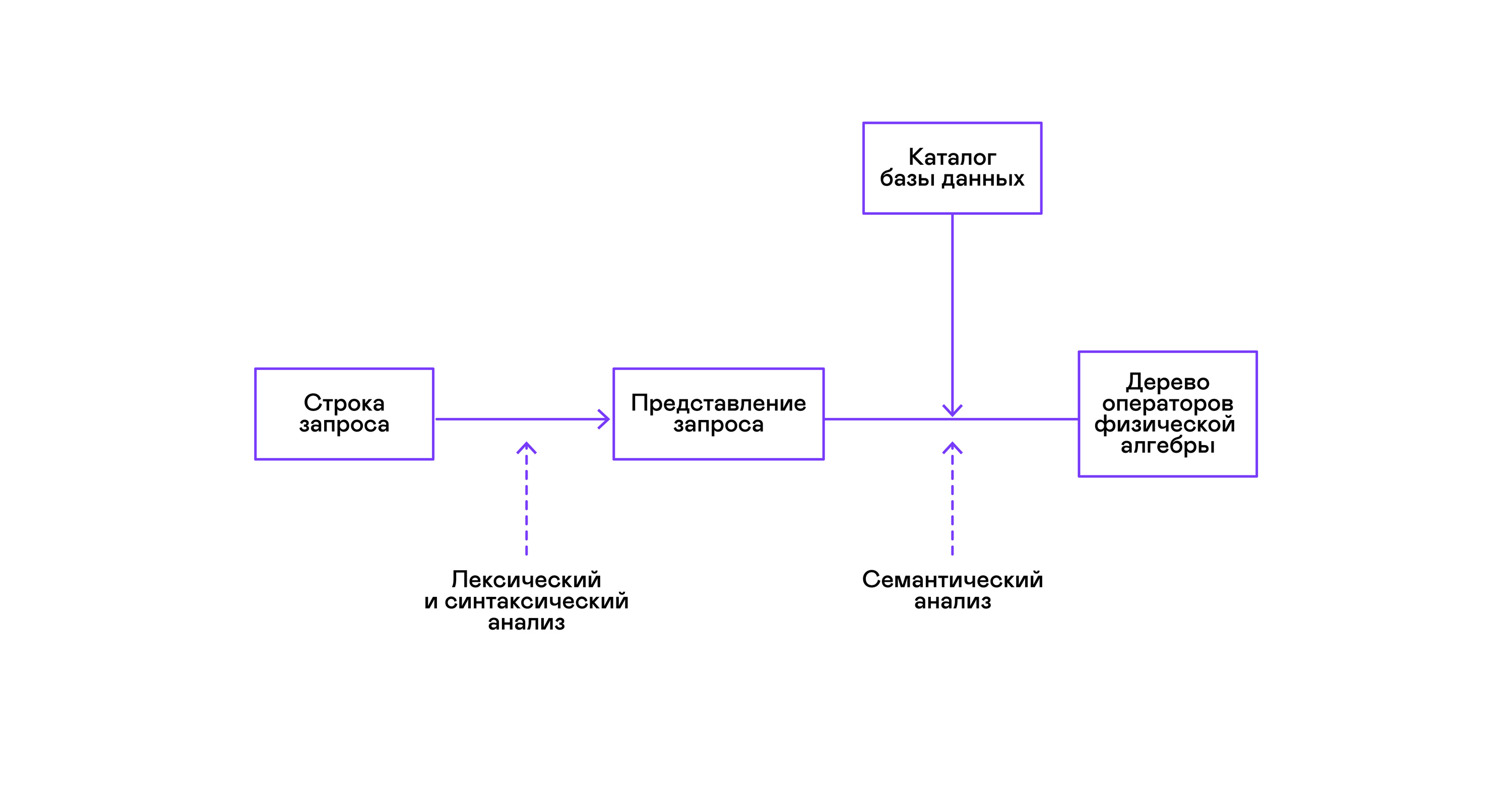
Las bases de datos más populares proporcionan una interfaz para los datos en forma de un lenguaje de consulta SQL declarativo. El analizador convierte una consulta en forma de cadena en una descripción de la consulta, similar a un árbol de sintaxis abstracta. Es posible ejecutar consultas simples ya en esta etapa, sin embargo, para optimizar las transformaciones y la ejecución posterior, esta representación es inconveniente. En las bases de datos que conozco, se presentan representaciones intermedias para estos fines.
El álgebra relacional se convirtió en un modelo para representaciones intermedias. Este es un lenguaje donde las transformaciones ( operadores ) realizadas en los datos se describen explícitamente: seleccionar un subconjunto de datos de acuerdo con un predicado, combinar datos de diferentes fuentes, etc. Además, el álgebra relacional es un álgebra en el sentido matemático, es decir, un gran número de equivalentes transformaciones Por lo tanto, es conveniente llevar a cabo transformaciones de optimización sobre una consulta en forma de un árbol de operadores de álgebra relacional.
Existen diferencias importantes entre las representaciones internas en las bases de datos y el álgebra relacional original, por lo que es más correcto llamarlo álgebra lógica .
La validación de una consulta generalmente se realiza al compilar la representación inicial de la consulta en operadores de álgebra lógica y corresponde a la etapa de análisis semántico en compiladores convencionales. El directorio de la base de datos desempeña el papel de la tabla de símbolos en las bases de datos , que almacena información sobre el esquema y los metadatos de la base de datos: tablas, columnas de tablas, índices, derechos de usuario, etc.
En comparación con los intérpretes de uso general, los intérpretes de bases de datos tienen una peculiaridad más: diferencias en el volumen de datos y metainformación sobre los datos a los que se supone que se deben realizar consultas. En las tablas o relaciones en términos de álgebra relacional, puede haber una cantidad diferente de datos, en algunas columnas ( atributos de relación) se pueden construir índices, etc. Es decir, dependiendo del esquema de la base de datos y la cantidad de datos en las tablas, la consulta debe ser realizada por diferentes algoritmos , y úselos en un orden diferente.
Para resolver este problema, se introduce otra representación intermedia: el álgebra física . Dependiendo de la disponibilidad de índices en las columnas, la cantidad de datos en las tablas y la estructura del árbol de álgebra lógica, se ofrecen diferentes formas del árbol de álgebra física, de las cuales se elige la mejor opción. Es este árbol el que se muestra a la base de datos como un plan de consulta. En los compiladores convencionales, esta etapa corresponde condicionalmente a las etapas de asignación de registros, planificación y selección de instrucciones.
El último paso en el trabajo del intérprete es directamente la ejecución del árbol de operadores de álgebra física.
Modelo de volcán y ejecución de consultas
Los intérpretes de árbol de álgebra física siempre se han utilizado en bases de datos comerciales cerradas, pero la literatura académica generalmente se refiere al optimizador experimental Volcano, desarrollado a principios de los 90.
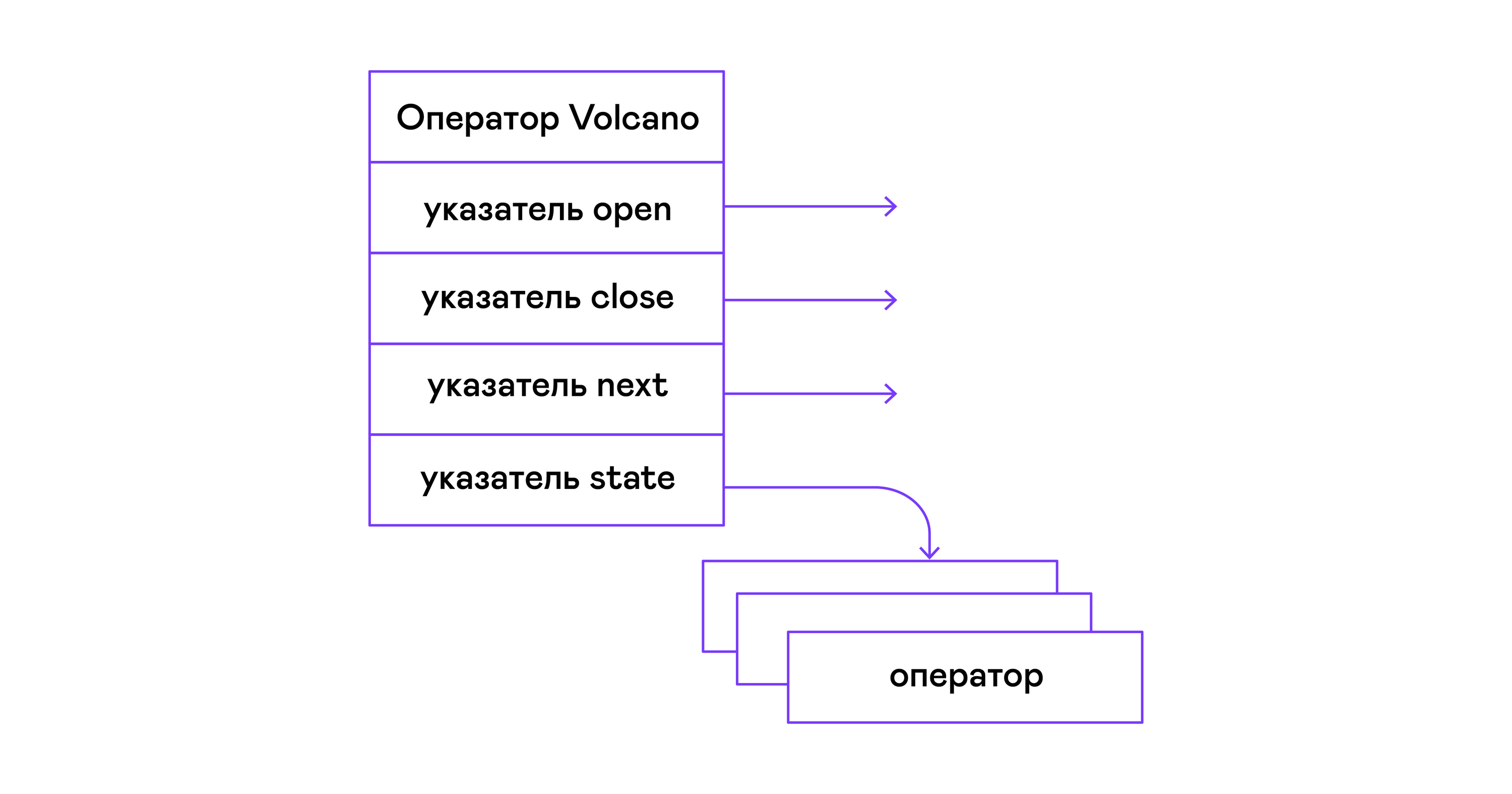
En el modelo Volcano, cada operador de un árbol de álgebra física se convierte en una estructura con tres funciones: abrir, luego, cerrar. Además de las funciones, el operador contiene un estado operativo: estado. La función abierta inicia el estado de la declaración, la siguiente función devuelve la siguiente tupla (tupla en inglés) o NULL, si no quedan tuplas, la función de cierre termina la declaración:
Los operadores se pueden anidar para formar un árbol de operadores de álgebra física. Cada operador, por lo tanto, itera sobre las tuplas de una relación existente en un medio real o una relación virtual formada al enumerar las tuplas de operadores anidados:
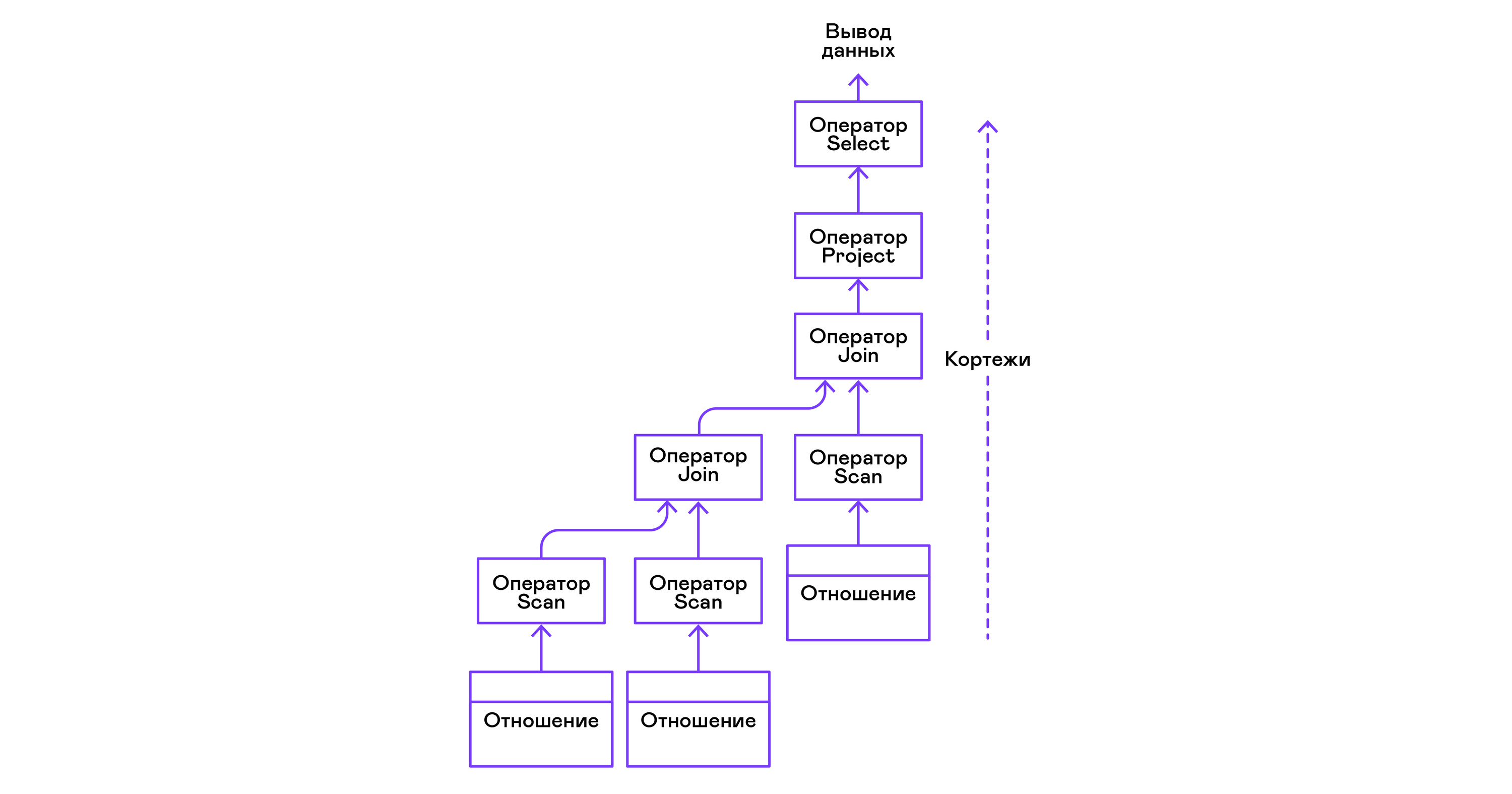
En términos de lenguajes modernos de alto nivel, el árbol de tales operadores es una cascada de iteradores.
Incluso los intérpretes de consultas industriales en DBMS relacional son repelidos del modelo Volcano, por eso lo tomé como la base del intérprete PigletQL.
PigletQL
Para demostrar el modelo, desarrollé el intérprete del lenguaje de consulta limitado PigletQL . Está escrito en C, admite la creación de tablas en el estilo de SQL, pero está limitado a un solo tipo: enteros positivos de 32 bits. Todas las tablas están en la memoria. El sistema funciona en un solo hilo y no tiene un mecanismo de transacción.
No hay optimizador en PigletQL, y las consultas SELECT se compilan directamente en el árbol de operadores de álgebra física. Las consultas restantes (CREATE TABLE e INSERT) funcionan directamente desde las vistas internas principales.
Ejemplo de sesión de usuario en PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
Léxico y analizador
PigletQL es un lenguaje muy simple, y su implementación no fue necesaria en las etapas del análisis léxico y de análisis.
El analizador léxico está escrito a mano. Se crea un objeto analizador ( scanner_t ) a partir de la cadena de consulta, que entrega tokens uno por uno:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
El análisis se realiza utilizando el método de descenso recursivo. Primero, se crea el objeto parser_t , que, después de haber recibido el analizador léxico (scanner_t), llena el objeto query_t con información sobre la solicitud:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
El resultado del análisis en query_t es uno de los tres tipos de consulta admitidos por PigletQL:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
El tipo de consulta más complejo en PigletQL es SELECT. Corresponde a la estructura de datos query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
La estructura contiene una descripción de la consulta (un conjunto de atributos solicitados por el usuario), una lista de fuentes de datos: relaciones, un conjunto de predicados que filtran tuplas e información sobre el atributo utilizado para ordenar los resultados.
Analizador semántico
La fase de análisis semántico en SQL regular implica verificar la existencia de las tablas enumeradas, las columnas en las tablas y la comprobación de tipos en las expresiones de consulta. Para las comprobaciones relacionadas con tablas y columnas, se utiliza el directorio de la base de datos, donde se almacena toda la información sobre la estructura de datos.
No hay expresiones complejas en PigletQL, por lo que la verificación de consultas se reduce a la verificación de metadatos del catálogo de tablas y columnas. Las consultas SELECT, por ejemplo, son validadas por la función validate_select . Lo traeré en forma abreviada:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
Si la solicitud es válida, el siguiente paso es compilar el árbol de análisis en un árbol de operador.
Compilación de consultas en una vista intermedia
En los intérpretes de SQL completos, generalmente hay dos representaciones intermedias: álgebra lógica y física.
Un simple intérprete de PigletQL realiza consultas CREATE TABLE e INSERT directamente desde sus árboles de análisis, es decir, las estructuras query_create_table_t y query_insert_t . Las consultas SELECT más complejas se compilan en una única representación intermedia, que será ejecutada por el intérprete.
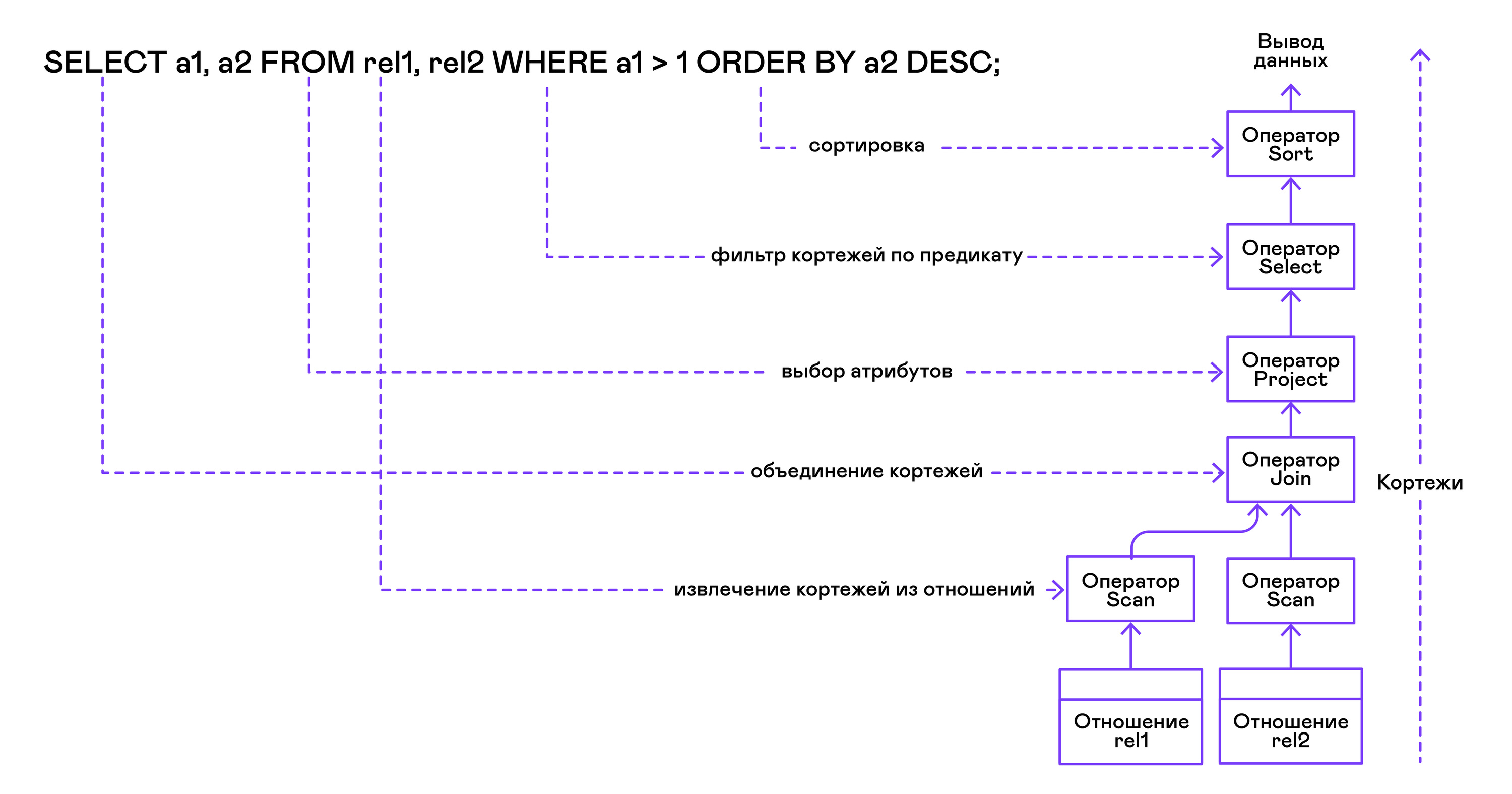
El árbol del operador se construye desde las hojas hasta la raíz en la siguiente secuencia:
A partir de la parte derecha de la consulta ("... DESDE relación1, relación2, ..."), se obtienen los nombres de las relaciones deseadas, para cada una de las cuales se crea una instrucción de exploración.
Al extraer las tuplas de las relaciones, los operadores de exploración se combinan en un árbol binario izquierdo a través del operador de unión.
La declaración del proyecto selecciona los atributos solicitados por el usuario ("SELECT attr1, attr2, ...").
Si se especifica algún predicado ("... DONDE a = 1 Y b> 10 ..."), la instrucción de selección se agrega al árbol de arriba.
Si se especifica el método para ordenar el resultado ("... ORDER BY attr1 DESC"), el operador de clasificación se agrega a la parte superior del árbol.
Compilación en código PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
Después de que se forma el árbol, las transformaciones de optimización generalmente se llevan a cabo, pero PigletQL inmediatamente pasa a la etapa de ejecución de la representación intermedia.
Ejecución de una presentación provisional.
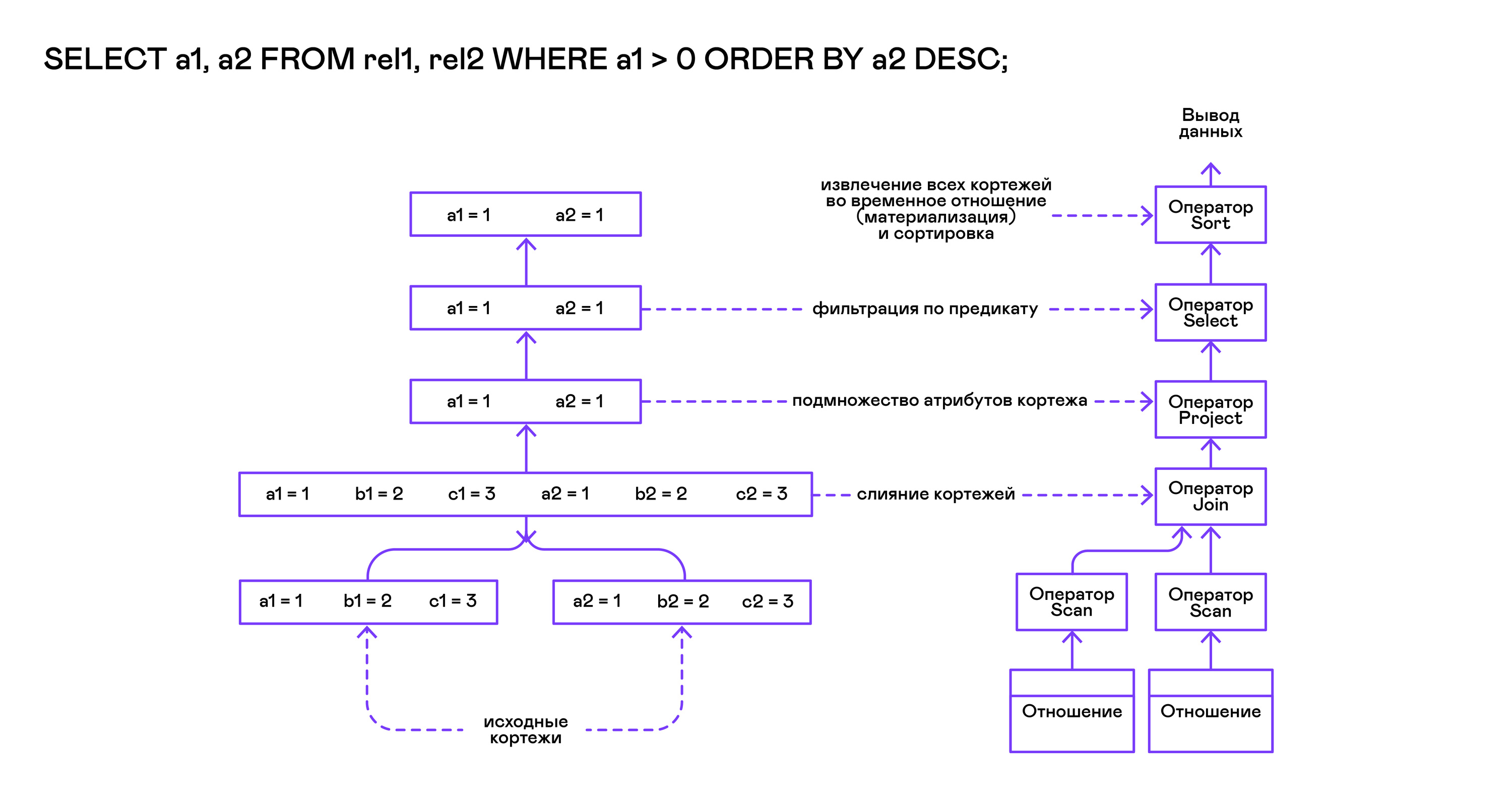
El modelo Volcano implica una interfaz para trabajar con operadores a través de tres operaciones comunes de apertura / siguiente / cierre. En esencia, cada declaración de Volcano es un iterador del que las tuplas se "extraen" una por una, por lo que este enfoque de ejecución también se denomina modelo de extracción.
Cada uno de estos iteradores puede invocar las mismas funciones que los iteradores anidados, crear tablas temporales con resultados intermedios y convertir las tuplas entrantes.
Ejecutando consultas SELECT en PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
La solicitud se compila primero mediante la función compile_select, que devuelve la raíz del árbol del operador, después de lo cual se invocan las mismas funciones de apertura / siguiente / cierre en el operador raíz. Cada llamada al siguiente devuelve la siguiente tupla o NULL. En el último caso, esto significa que se han extraído todas las tuplas y se debe llamar a la función de iterador cerrado.
Las tuplas resultantes son recalculadas y enviadas por la tabla a la secuencia de salida estándar.
Operadores
Lo más interesante de PigletQL es el árbol de operadores. Mostraré el dispositivo de algunos de ellos.
Los operadores tienen una interfaz común y consisten en punteros a la función abrir / siguiente / cerrar y una función adicional destruir destruir, que libera los recursos de todo el árbol de operadores a la vez:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
Además de las funciones, el operador puede contener un estado interno arbitrario (puntero de estado).
A continuación analizaré el dispositivo de dos operadores interesantes: el escaneo más simple y la creación de un tipo de relación intermedia.
Declaración de escaneo
La declaración que inicia cualquier consulta es scan. Él solo pasa por todas las tuplas de la relación. El estado interno de exploración es un puntero a la relación desde donde se recuperarán las tuplas, el índice de la próxima tupla en la relación y una estructura de enlace a la tupla actual que se pasa al usuario:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
Para crear el estado de una instrucción de escaneo, necesita una relación de origen; todo lo demás (punteros a las funciones correspondientes) ya se conoce:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
Operaciones de apertura / cierre en el caso de enlaces de restablecimiento de escaneo al primer elemento de la relación:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
La siguiente llamada devuelve la siguiente tupla, o NULL si no hay más tuplas en la relación:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
Ordenar declaración
La instrucción sort produce tuplas en el orden especificado por el usuario. Para hacer esto, cree una relación temporal con las tuplas obtenidas de operadores anidados y ordénela.
El estado interno del operador:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
La clasificación se realiza de acuerdo con los atributos especificados en la solicitud (sort_attr_name y sort_order) a lo largo de la relación de tiempo (tmp_relation). Todo esto sucede cuando se llama a la función abierta:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
El operador temporal tmp_relation_scan_op realiza la enumeración de los elementos de la relación temporal:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
La relación temporal se desasigna en la función de cierre:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
Aquí puede ver claramente por qué las operaciones de clasificación en columnas sin índices pueden llevar tanto tiempo.
Ejemplos de trabajo
Daré algunos ejemplos de consultas PigletQL y los árboles correspondientes de álgebra física.
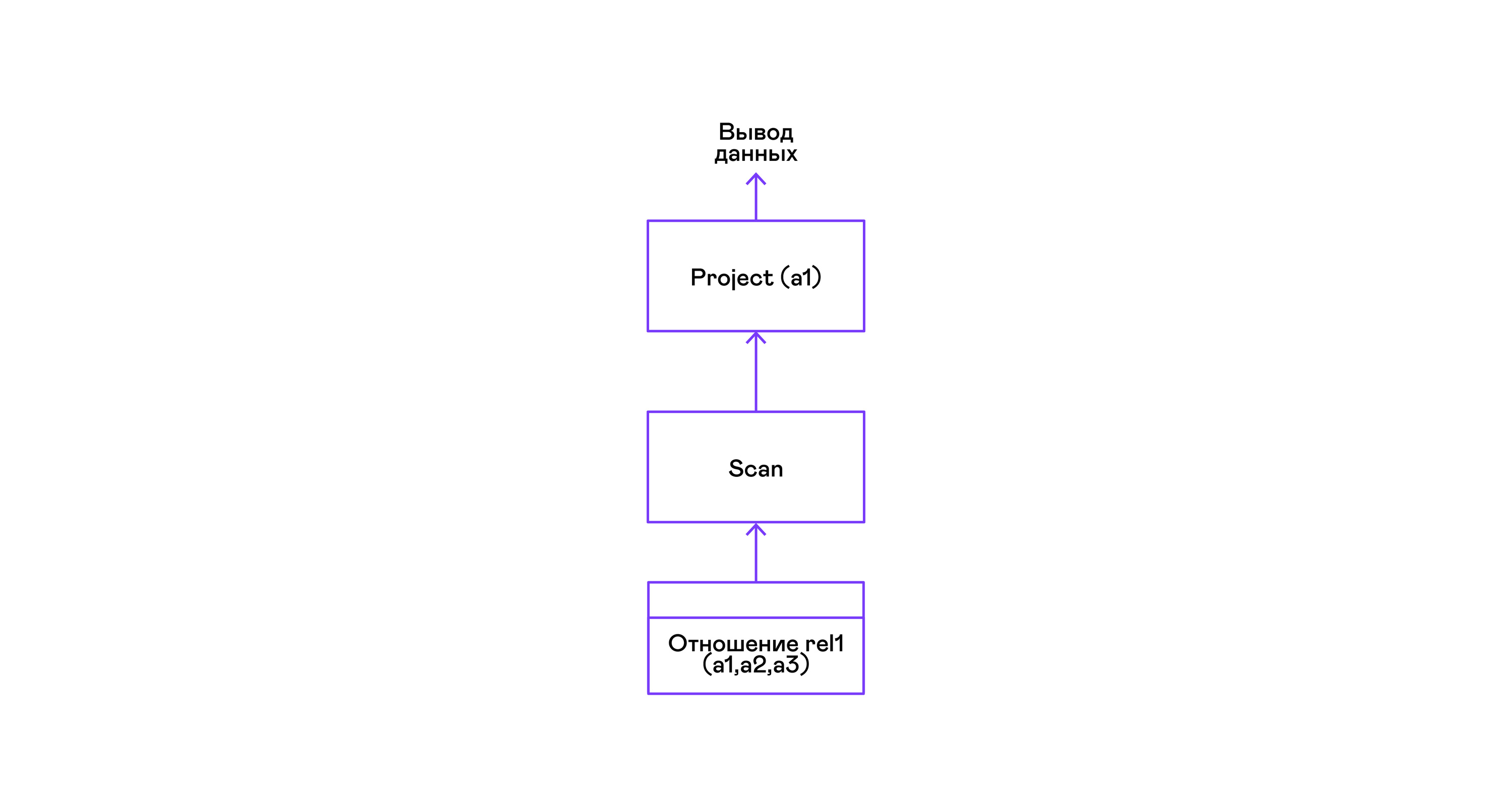
El ejemplo más simple donde se seleccionan todas las tuplas de una relación:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
Para las consultas más simples, solo se utilizan las tuplas de recuperación de la relación de escaneo y se selecciona el único atributo del proyecto de las tuplas:
Elegir tuplas con un predicado:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
Los predicados se expresan mediante la instrucción select:
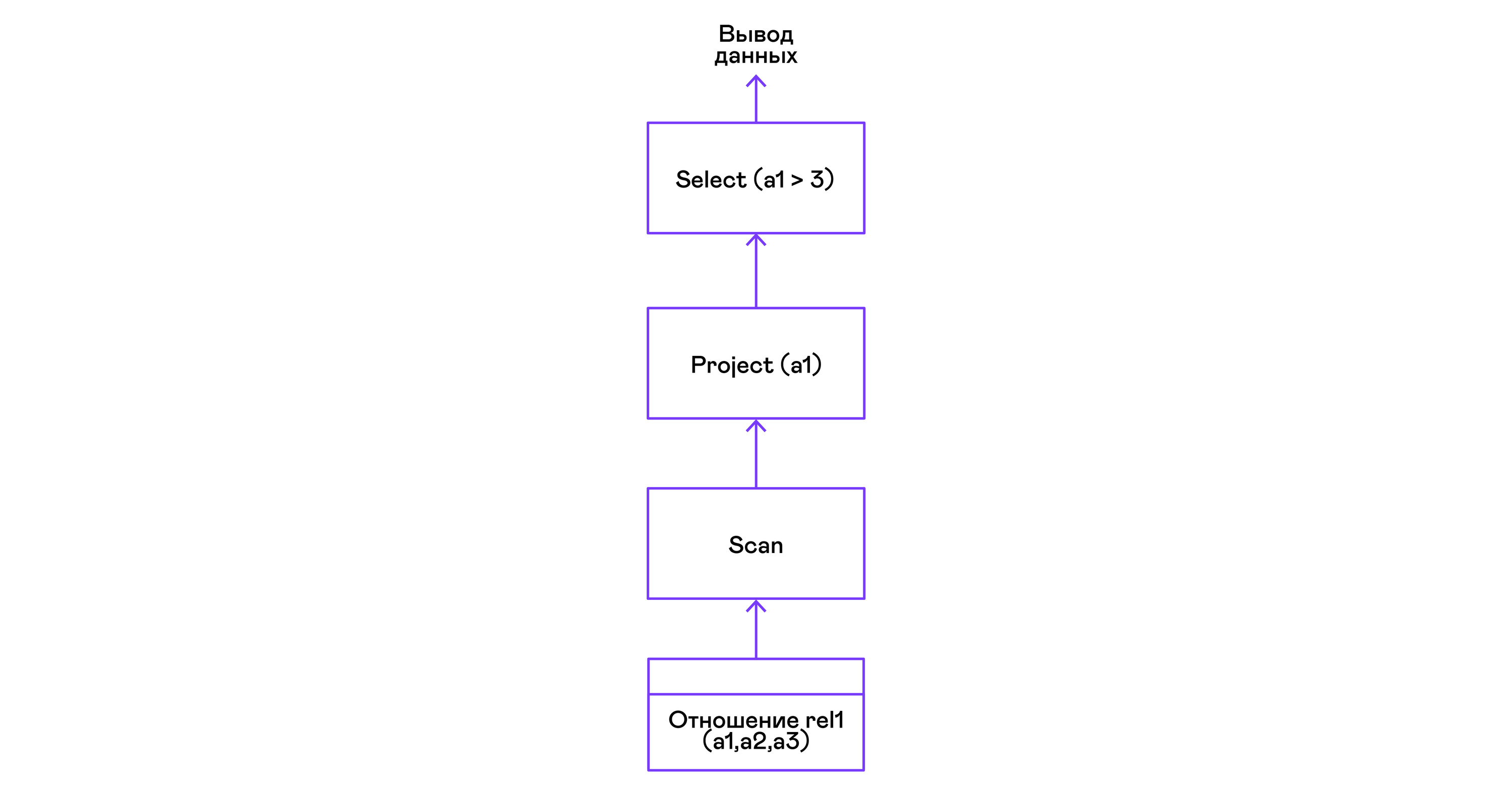
Selección de tuplas con clasificación:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
El operador de clasificación de escaneo en la llamada abierta crea ( materializa ) una relación temporal, coloca todas las tuplas entrantes allí y clasifica el conjunto. Después de eso, en las próximas llamadas, infiere tuplas de la relación temporal en el orden especificado por el usuario:

Combinando tuplas de dos relaciones con un predicado:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
El operador de unión en PigletQL no utiliza ningún algoritmo complejo, sino que simplemente forma un producto cartesiano a partir de los conjuntos de tuplas de los subárboles izquierdo y derecho. Esto es muy ineficiente, pero para un intérprete de demostración lo hará:
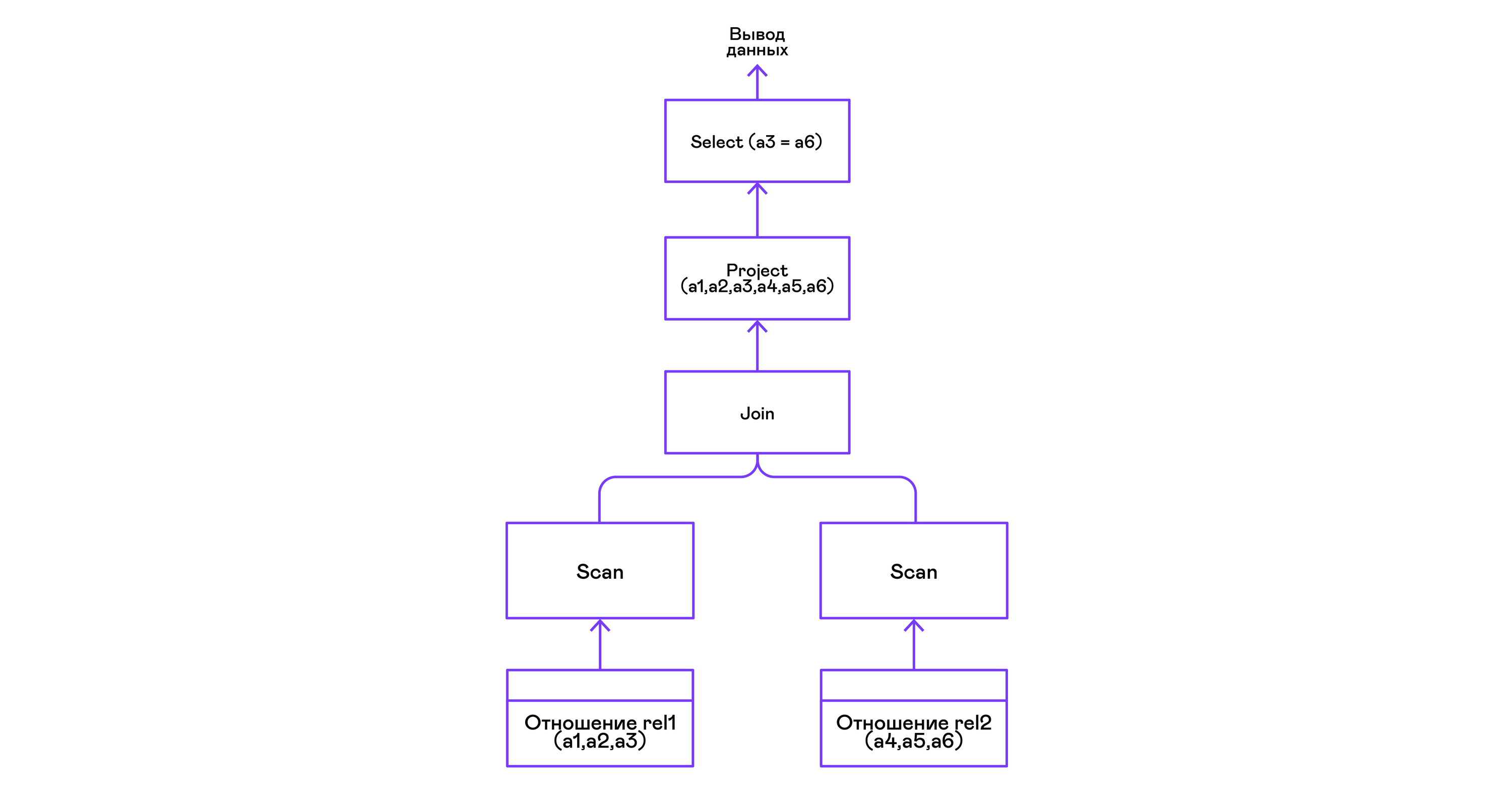
Conclusiones
En conclusión, noto que si está haciendo un intérprete de un lenguaje similar al SQL, entonces probablemente debería tomar cualquiera de las muchas bases de datos relacionales disponibles. Se han invertido miles de años-persona en optimizadores modernos e intérpretes de consultas de bases de datos populares, y lleva años desarrollar incluso las bases de datos de propósito general más simples.
El lenguaje de demostración PigletQL imita el trabajo del intérprete de SQL, pero en realidad usamos solo elementos individuales de la arquitectura Volcano y solo para esos (¡raros!) Tipos de consultas que son difíciles de expresar en el marco del modelo relacional.
Sin embargo, repito: incluso un conocimiento superficial de la arquitectura de tales intérpretes es útil en los casos en que es necesario trabajar de manera flexible con los flujos de datos.
Literatura
Si está interesado en los temas básicos del desarrollo de la base de datos, entonces los libros son mejores que la "Implementación del sistema de base de datos" (Garcia-Molina H., Ullman JD, Widom J., 2000), no encontrará.
Su único inconveniente es una orientación teórica. Personalmente, me gusta cuando se adjuntan al material ejemplos concretos de código o incluso un proyecto de demostración. Para esto, puede consultar el libro "Diseño e implementación de bases de datos" (Sciore E., 2008), que proporciona el código completo para una base de datos relacional en Java.
Las bases de datos relacionales más populares todavía usan variaciones sobre el tema de Volcano. La publicación original está escrita en un lenguaje muy accesible y se puede encontrar fácilmente en Google Scholar: "Volcano: un sistema de evaluación de consultas extensible y paralelo" (Graefe G., 1994).
Aunque los intérpretes de SQL han cambiado bastante en detalle en las últimas décadas, la estructura muy general de estos sistemas no ha cambiado durante mucho tiempo. Puede hacerse una idea en un artículo de revisión del mismo autor, "Técnicas de evaluación de consultas para grandes bases de datos" (Graefe G. 1993).