Hola Habr! Mi nombre es Nikolai y estoy involucrado en la construcción e implementación de modelos de aprendizaje automático en Sberbank. Hoy hablaré sobre el desarrollo de un sistema de recomendación para pagos y transferencias en la aplicación en sus teléfonos inteligentes.
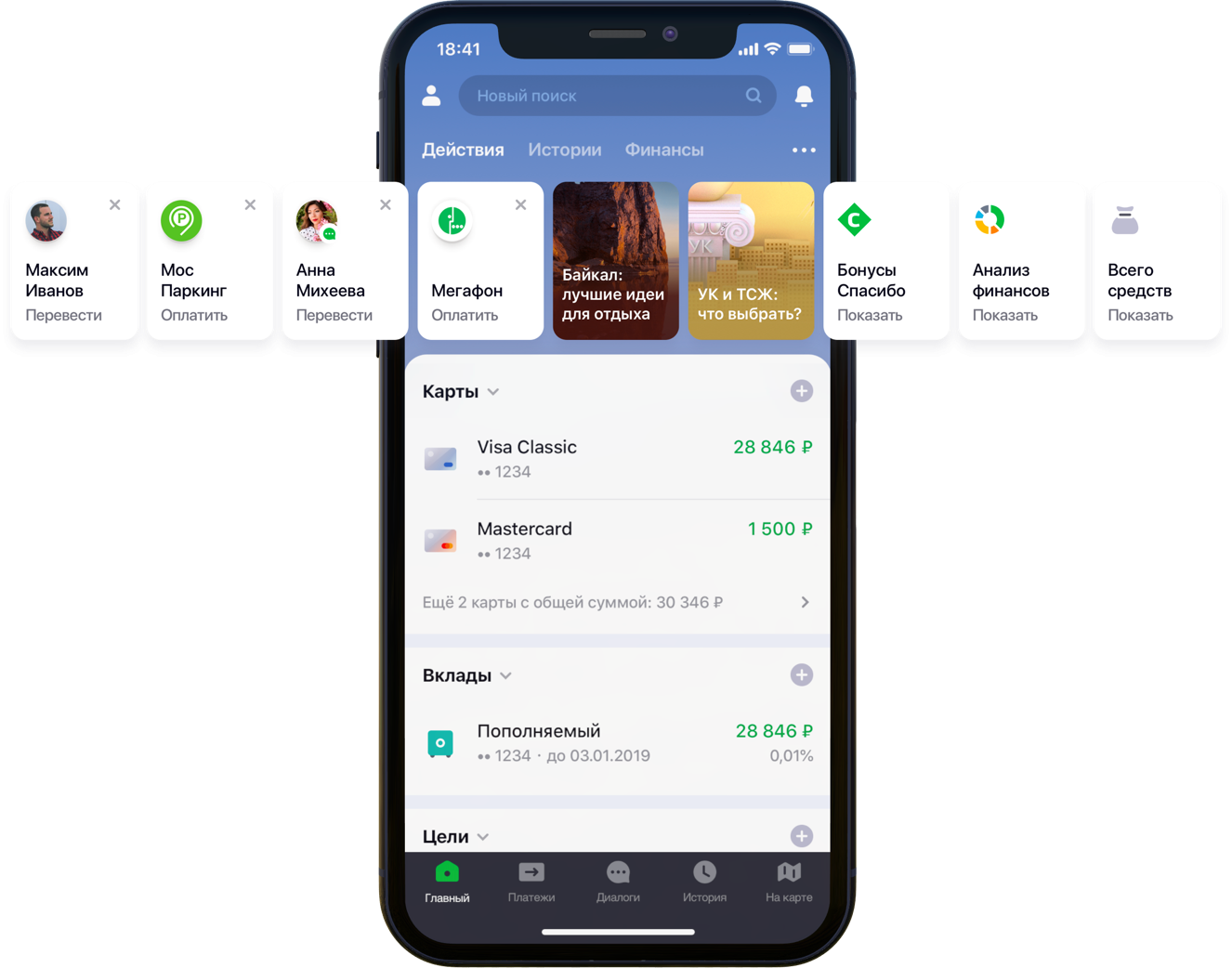 Diseño de la pantalla principal de la aplicación móvil con recomendaciones.
Diseño de la pantalla principal de la aplicación móvil con recomendaciones.Teníamos doscientas mil opciones de pago posibles, 55 millones de clientes, 5 fuentes bancarias diferentes, media columna de desarrollador y una montaña de actividad bancaria, algoritmos y todo eso, todos los colores, así como un litro de semillas aleatorias, una caja de hiperparámetros, medio litro de factores de corrección y dos docenas de bibliotecas. No es que todo esto fuera necesario en el trabajo, pero desde que comenzó a mejorar la vida de los clientes, ve a tu pasatiempo hasta el final. Debajo del corte está la historia de la batalla por UX, la formulación correcta del problema, la lucha contra la dimensionalidad de los datos, la contribución al código abierto y nuestros resultados.
Declaración del problema.
A medida que se desarrolla y amplía, la aplicación Sberbank Online está adquiriendo características útiles y funcionalidades adicionales. En particular, en la aplicación puede transferir dinero o pagar los servicios de varias organizaciones.
“Observamos cuidadosamente todas las rutas de usuario dentro de la aplicación y nos dimos cuenta de que muchas de ellas se pueden reducir significativamente. Para hacer esto, decidimos personalizar la pantalla principal en varias etapas. Primero, tratamos de eliminar de la pantalla lo que el cliente no usa, comenzando con las tarjetas bancarias. Luego pusieron de manifiesto aquellas acciones que el cliente ya había realizado anteriormente y para las cuales podría ingresar a la aplicación ahora mismo. Ahora, la lista de acciones incluye pagos a organizaciones y transferencias a contactos, luego la lista de tales acciones se ampliará ”, dijo mi colega Sergey Komarov, quien está desarrollando la funcionalidad desde el punto de vista del cliente en el equipo de Sberbank Online. Es necesario construir un modelo que llene los espacios designados en los widgets de Acciones (figura anterior) con recomendaciones personales de pagos y transferencias en lugar de reglas simples.
Solución
Nosotros en el equipo descomponemos la tarea en dos partes:
- la recomendación de la repetición de operaciones para pagar servicios o transferir fondos (bloque "Operaciones recomendadas")
- recomendación de ejemplos de solicitudes de búsqueda para el pago de servicios no utilizados anteriormente por este cliente (bloque "Ejemplos de búsqueda")
Decidimos probar la funcionalidad primero en la pestaña de búsqueda:
Diseño de pantalla de búsqueda recomendadaOperaciones recomendadas
Optimización de puntaje
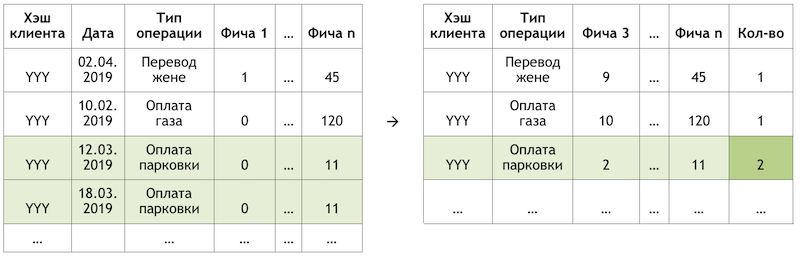
Si establecemos la subtarea como una recurrencia de operaciones, esto nos permite deshacernos del cálculo y la evaluación de billones de combinaciones de todas las operaciones posibles para todos los clientes y centrarnos en un número mucho más limitado de ellas. Si, de todo el conjunto de operaciones disponibles para nuestros clientes, el cliente hipotético con el hash YYY solo usó el pago de gas y estacionamiento, entonces evaluaremos la probabilidad de repetir solo estas operaciones para este cliente:
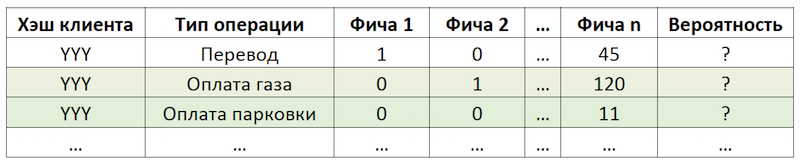 Un ejemplo de reducción de la dimensión de datos para puntuación
Un ejemplo de reducción de la dimensión de datos para puntuaciónPreparando el conjunto de datos
La muestra es una observación transaccional, enriquecida con factores de demografía del cliente, agregados financieros y diversas características de frecuencia de una operación en particular.
La variable objetivo en este caso es binaria y refleja el hecho del evento el día siguiente al día en que se calculan los factores. Por lo tanto, moviendo iterativamente el día de cálculo de los factores y estableciendo la bandera de la variable objetivo, multiplicamos y marcamos las mismas operaciones y las marcamos de manera diferente dependiendo de la posición con respecto a este día.
Esquema de observaciónCalculando el corte el 17/03/2019 para el cliente "YYY", obtenemos dos observaciones:
Un ejemplo de las observaciones para un conjunto de datos."Característica 1" puede significar, por ejemplo, el saldo de todas las tarjetas del cliente, "Característica 2" - la presencia de este tipo de operación en la última semana.
Tomamos las mismas transacciones, pero formamos observaciones para capacitación en una fecha diferente:
Esquema de observaciónObtendremos observaciones para un conjunto de datos con otros valores de ambas características y la variable objetivo:
 Un ejemplo de las observaciones para un conjunto de datos.
Un ejemplo de las observaciones para un conjunto de datos.En los ejemplos anteriores, para mayor claridad, se proporcionan los valores reales de los factores, pero de hecho, los valores se procesan mediante un algoritmo automático: los resultados de la
conversión de WOE se introducen en la entrada del modelo. Le permite llevar las variables a una relación monotónica con la variable objetivo y al mismo tiempo eliminar los efectos de los valores atípicos. Por ejemplo, tenemos el factor "Número de tarjetas" y alguna distribución de la variable objetivo:
 Ejemplo de conversión de WOE
Ejemplo de conversión de WOELa transformación de WOE nos permite transformar una dependencia no lineal en al menos una dependencia monotónica. Cada valor del factor analizado se asocia con su propio valor WOE y, por lo tanto, se forma un nuevo factor, y el original se elimina del conjunto de datos:
 El efecto de la transformación WOE en la relación con la variable objetivo
El efecto de la transformación WOE en la relación con la variable objetivoEl diccionario para convertir valores variables a WOE se guarda y se usa más tarde para la puntuación. Es decir, si necesitamos calcular las probabilidades para mañana, creamos un conjunto de datos como en las tablas con ejemplos de observaciones anteriores, convertimos las variables necesarias en WOE con el código guardado y aplicamos el modelo en estos datos.
Entrenamiento
La elección del método era estrictamente limitada: interpretabilidad. Por lo tanto, para cumplir con los plazos, se decidió posponer las explicaciones usando el mismo
SHAP en la segunda mitad del problema y probar métodos relativamente simples: regresión y neuronas superficiales. La herramienta fue SAS Miner, un software para preprocesar, analizar y construir modelos en varios datos en una forma interactiva, lo que ahorra mucho tiempo en la escritura de código.
 Interfaz SAS Miner
Interfaz SAS MinerEvaluación de calidad
La comparación de la métrica GINI en una muestra fuera de tiempo mostró que la red neuronal se adapta mejor a la tarea:
Tabla comparativa de modelos de calidad y reglas de frecuencia.El modelo tiene dos puntos de salida. Las recomendaciones en forma de tarjetas de widgets en la pantalla principal incluyen operaciones cuyo pronóstico está por encima de cierto umbral (ver la primera imagen en la publicación). El borde se selecciona en función de un equilibrio de calidad y cobertura, que en dicha arquitectura es la mitad de todas las operaciones realizadas. Las 4 operaciones principales se envían al bloque de "operaciones recomendadas" de la pantalla de búsqueda (vea la segunda imagen).
Buscar ejemplos
Pasando a la segunda parte de la tarea, volvemos al problema de una gran cantidad de posibles opciones de pago para los servicios de proveedores que deben evaluarse y clasificarse dentro de cada cliente: billones de pares. Además de esto, tenemos datos implícitos, es decir, no hay información sobre la evaluación de los pagos realizados, o por qué el cliente no realizó ningún pago. Por lo tanto, para empezar, se decidió probar varios métodos para expandir la matriz de pagos de clientes a proveedores: ALS y FM.
ALS
ALS (Alternating Least Squares) o Alternating Least Squares - en el filtrado colaborativo, uno de los métodos para resolver el problema de factorización de la matriz de interacción. Presentaremos nuestros datos transaccionales sobre el pago de servicios en forma de matriz en la que las columnas son identificadores únicos de todos los servicios de los proveedores, y las filas son clientes únicos. En las celdas colocamos el número de operaciones de clientes específicos con proveedores específicos durante un cierto período de tiempo:
 Principio de descomposición de la matriz
Principio de descomposición de la matrizEl significado del método es que creamos dos de esas matrices de dimensión inferior, cuya multiplicación da el resultado más cercano a la matriz grande original en las celdas rellenas. El modelo aprende a crear una descripción factorial oculta para clientes y proveedores. Se utilizó una implementación del método en la biblioteca
implícita . El entrenamiento se lleva a cabo de acuerdo con el siguiente algoritmo:
- Se inicializan las matrices de clientes y proveedores con factores ocultos. Su número es el hiperparámetro del modelo.
- La matriz de factores ocultos de los proveedores es fija y se considera la derivada de la función de pérdida para la corrección de la matriz del cliente. El autor utilizó un método interesante de gradientes conjugados , que le permite acelerar mucho este paso.
- El paso anterior se repite de manera similar para la matriz de factores ocultos de los clientes.
- Los pasos 2-3 se alternan hasta que el algoritmo converge.
Preparación
Los datos transaccionales se transformaron en una matriz de interacciones con un grado de dispersión de ~ 99% con gran desigualdad entre los proveedores. Para separar los datos en muestras de tren y validación, enmascaramos al azar la proporción de celdas llenas:
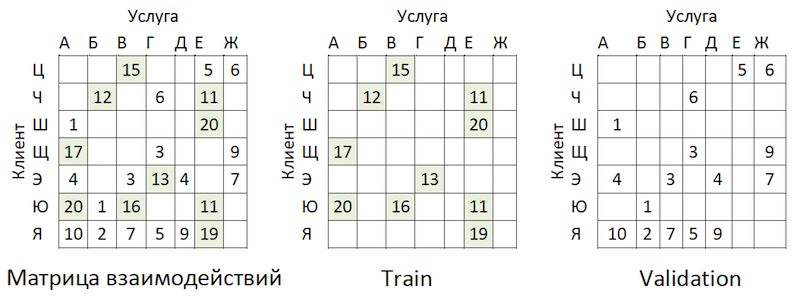 Ejemplo de intercambio de datos
Ejemplo de intercambio de datosLas transacciones se tomaron como una prueba para el período de tiempo posterior a la capacitación y se presentaron en una matriz del mismo formato: resultó fuera de tiempo.
Entrenamiento
El modelo tiene varios hiperparámetros que se pueden ajustar para mejorar la calidad:
- Alfa es el coeficiente por el cual se pondera la matriz, ajustando el grado de confianza ( C_iu ) de que el servicio dado es realmente "querido" por el cliente.
- El número de factores en las matrices ocultas de clientes y proveedores es el número de columnas y filas, respectivamente.
- Coeficiente de regularización L2 λ.
- El número de iteraciones del método.
Utilizamos la biblioteca de
hiperopt , que nos permite evaluar el efecto de los hiperparámetros en la métrica de calidad utilizando el método
TPE y seleccionar su valor óptimo. El algoritmo comienza con un arranque en frío y realiza varias evaluaciones de la métrica de calidad según los valores de los hiperparámetros analizados. Luego, en esencia, trata de seleccionar un conjunto de valores de hiperparámetros que sea más probable que proporcione un buen valor para la métrica de calidad. Los resultados se guardan en un diccionario desde el que puede construir un gráfico y evaluar visualmente el resultado del optimizador (el azul es mejor):
El gráfico de la dependencia de la métrica de calidad en la combinación de hiperparámetros.El gráfico muestra que los valores de los hiperparámetros afectan fuertemente la calidad del modelo. Como es necesario aplicar rangos para cada uno de ellos a la entrada del método, el gráfico puede determinar aún más si tiene sentido expandir el espacio de valores o no. Por ejemplo, en nuestra tarea está claro que tiene sentido probar valores grandes para la cantidad de factores. En el futuro, esto realmente mejoró el modelo.
Evaluación de calidad métrica y complejidad
¿Cómo evaluar la calidad del modelo? Una de las métricas más utilizadas para los sistemas de recomendación donde el pedido es importante es
MAP @ k o Precisión media promedio en K. Esta métrica estima la precisión del modelo en las recomendaciones K teniendo en cuenta el orden de los artículos en la lista de estas recomendaciones en promedio para todos los clientes.
Desafortunadamente, una operación de evaluación de calidad incluso en una muestra tomó varias horas. Después de arremangarnos, comenzamos a perfilar la función mean_average_pecision_at_k () con la biblioteca line_profiler. La tarea se complicó aún más por el hecho de que la función usaba código cython y tenía que
tenerse en cuenta correctamente, de lo contrario las estadísticas necesarias simplemente no se recopilaron. Como resultado, nuevamente enfrentamos el problema de la dimensionalidad de nuestros datos. Para calcular esta métrica, debe obtener algunas estimaciones de cada servicio de todas las posibles para cada cliente y seleccionar las recomendaciones personales de K principales clasificándolas de la matriz resultante. Incluso teniendo en cuenta el uso de la clasificación parcial de numpy.argpartition () con O (n) complejidad, la clasificación de las calificaciones resultó ser el paso más largo que estira la calificación de calidad a lo largo del reloj. Como numpy.argpartition () no utilizó todos los núcleos de nuestro servidor, se decidió mejorar el algoritmo reescribiendo esta parte en C ++ y OpenMP a través de cython. Un algoritmo brevemente nuevo es el siguiente:
- Los clientes cortan los datos en lotes.
- Se inicializan una matriz vacía y punteros a la memoria.
- Las cadenas de lotes por punteros se ordenan de dos maneras: por la función partial_sort y luego se ordenan por la biblioteca de algoritmos de C ++.
- Los resultados se escriben en las celdas de la matriz vacía en paralelo.
- Los datos se devuelven en python.
Esto nos permitió acelerar el cálculo de recomendaciones varias veces. La revisión se ha
agregado al repositorio oficial.
Análisis de resultados OOT
Y ahora es el momento de evaluar la calidad del modelo. ¿Por qué necesitamos un muestreo fuera de tiempo? Si observamos la distribución de operaciones por proveedores, veremos la siguiente imagen:
Distribución de la popularidad de los proveedores de servicios.Hay un desequilibrio. Esto lleva al hecho de que el modelo está tratando de recomendar servicios populares. De vuelta a la imagen de arriba:
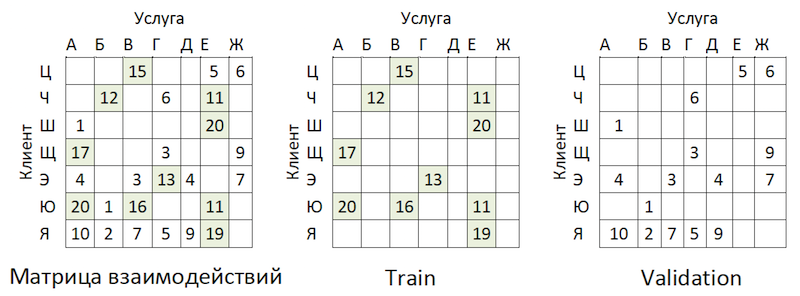
El problema es que si verifica la precisión del modelo enmascarando la misma matriz, como se recomienda en casi todas partes, entonces para la mayoría de los clientes (ejemplos marginales: "W", "E" e "I") la calidad de los pronósticos de validación (vamos a pretender que ella no participó en la selección de hiperparámetros) será alta si estos son los proveedores más populares. Como resultado, tenemos una falsa confianza en la solidez del modelo. Por lo tanto, actuamos de la siguiente manera:
- Estimaciones formadas de proveedores por modelo.
- Los pares existentes de servicio al cliente se excluyeron de las clasificaciones (consulte la figura a continuación) y las matrices OOT.
- Formado a partir de las calificaciones restantes de las principales recomendaciones de K y calificado MAP @ k en el OOT restante.
 La lógica de preparar la matriz para generar pronósticos
La lógica de preparar la matriz para generar pronósticosComo línea de base, compilamos una lista de proveedores, ordenada por popularidad, y la multiplicamos por todos los clientes, excluyendo nuevamente los pares existentes de servicio al cliente. Resultó ser triste y nada de lo que esperábamos y vimos en las muestras de validación del tren:
Tabla comparativa de calidad de referencia y modeloBasta! Tenemos factores de cliente y parámetros de proveedores. Tenemos máquinas de factorización.
FM
Máquinas de factorización (máquina de factorización): un algoritmo de aprendizaje con un maestro, diseñado para encontrar relaciones entre factores que describen entidades interactuantes, que se presentan en forma de matrices dispersas. Utilizamos la implementación FM de la biblioteca
LightFM .
Formato de datos
Además de la matriz de interacción normalizada, el
método utiliza dos conjuntos de datos adicionales con factores para clientes y para servicios de proveedores en forma de matrices codificadas en caliente conectadas a unidades individuales:
 La lógica de preparar la matriz para generar pronósticos
La lógica de preparar la matriz para generar pronósticosEvaluación de calidad
La calidad del modelo FM en nuestros datos resultó ser inferior a ALS:
Tabla comparativa de modelos de calidad y línea de base.Cambiar la arquitectura del modelo: impulsar
Se decidió venir desde el otro lado. Recordando la distribución de la popularidad de los servicios, identificamos 300 de ellos, transacciones en las que cubre el 80% de todas las operaciones, y capacitamos a un clasificador en ellas. Aquí, los datos representan agregados de transacciones de clientes enriquecidos con características de clientes:
 Esquema de agregación de transacciones
Esquema de agregación de transacciones¿Por qué solo del lado del cliente, preguntas? Porque en este caso, para preparar recomendaciones, será suficiente para nosotros tener una línea por cliente. Al aplicarle el modelo, obtenemos el vector de salida de las probabilidades para todas las clases, de las cuales es fácil elegir las recomendaciones de K principales. Si agregamos las características de los servicios del proveedor al conjunto de capacitación, en la etapa de aplicación del modelo nos veremos obligados a preparar 300 líneas para cada cliente, una para cada servicio del proveedor con características que las describan, o construir otro modelo para clasificar previamente a los candidatos que califican. .
Agregar características a los clientes de ALS no aumentó nuestros datos, ya que ya tomamos en cuenta la actividad transaccional, por ejemplo, en secciones del MCC o categorías en el estilo de "jugador" o "teatro". En este formato, logramos buenos resultados:
Tabla comparativa de modelos de calidad y línea de base.Filtro regional
A pesar de la alta calidad del modelo, un problema más permanece en este enfoque. Dado que la arquitectura de los datos y el modelo no implica el uso de características de los servicios de los proveedores, el modelo no tiene en cuenta la geografía y puede recomendar que las personas paguen por el servicio de un proveedor local de otra región. Para minimizar este riesgo, hemos desarrollado un pequeño filtro para cortar las opciones antes de entrar en recomendaciones. Se arroja un fleur fácil de recursión en el algoritmo:
- Recopilamos información sobre la región del cliente a partir de perfiles bancarios y otras fuentes internas.
- Seleccionamos las principales regiones de presencia para cada proveedor.
- Aclaramos / completamos la información sobre la región del cliente por las regiones de los proveedores que utiliza.
Después de estas manipulaciones, utilizando
el índice Herfindahl, separamos los proveedores regionales, que están representados en un conjunto limitado de regiones, de los federales:
Separación de proveedores por presencia en las regiones.Formamos una máscara con proveedores regionales aceptables para los clientes y excluimos artículos innecesarios de las predicciones del modelo antes de crear una lista de recomendaciones.
Conclusión
Hemos desarrollado dos modelos que juntos forman un conjunto completo de recomendaciones sobre pagos y transferencias. Fue posible reducir la ruta del cliente para la mitad de las operaciones recurrentes a un solo clic. En los planes futuros para mejorar el modelo de "operaciones recomendadas" utilizando datos de retroalimentación (las tarjetas se pueden ocultar, etc.), lo que reducirá el umbral para seleccionar recomendaciones y aumentará la cobertura. También está previsto ampliar la cobertura de los pagos recomendados en el modelo de "ejemplos de búsqueda" y desarrollar un algoritmo para la optimización de la puntuación.
Hemos recorrido el camino espinoso de construir un sistema de recomendación de pagos y transferencias. En el camino, obtuvimos golpes y ganamos experiencia en la descomposición y simplificación de tales tareas, evaluando correctamente dichos sistemas, aplicabilidad de métodos, trabajo óptimo con grandes volúmenes de datos, y expandimos significativamente nuestra comprensión de los detalles de tales tareas. En el camino, logré contribuir al código abierto, que nosotros mismos usamos. Le deseo tareas interesantes, líneas de base realistas y un solo F1. Gracias por su atencion!