Este artículo es una especie de clase maestra "DVC para automatizar experimentos de ML y versiones de datos", que tuvo lugar el 18 de junio en ML REPA (Machine Learning REPA:
Reproducibilidad, Experimentos y Automatización de Tuberías) en nuestro sitio bancario.
Aquí hablaré sobre las características del trabajo interno de DVC y cómo usarlo en proyectos.
Los ejemplos de código utilizados en el artículo están disponibles
aquí . El código fue probado en MacOS y Linux (Ubuntu).
Contenido
Parte 1
Parte 2
Configuración de DVC
Data Version Control es una herramienta diseñada para administrar versiones de modelos y datos en proyectos de ML. Es útil tanto en la etapa experimental como para implementar sus modelos en funcionamiento.
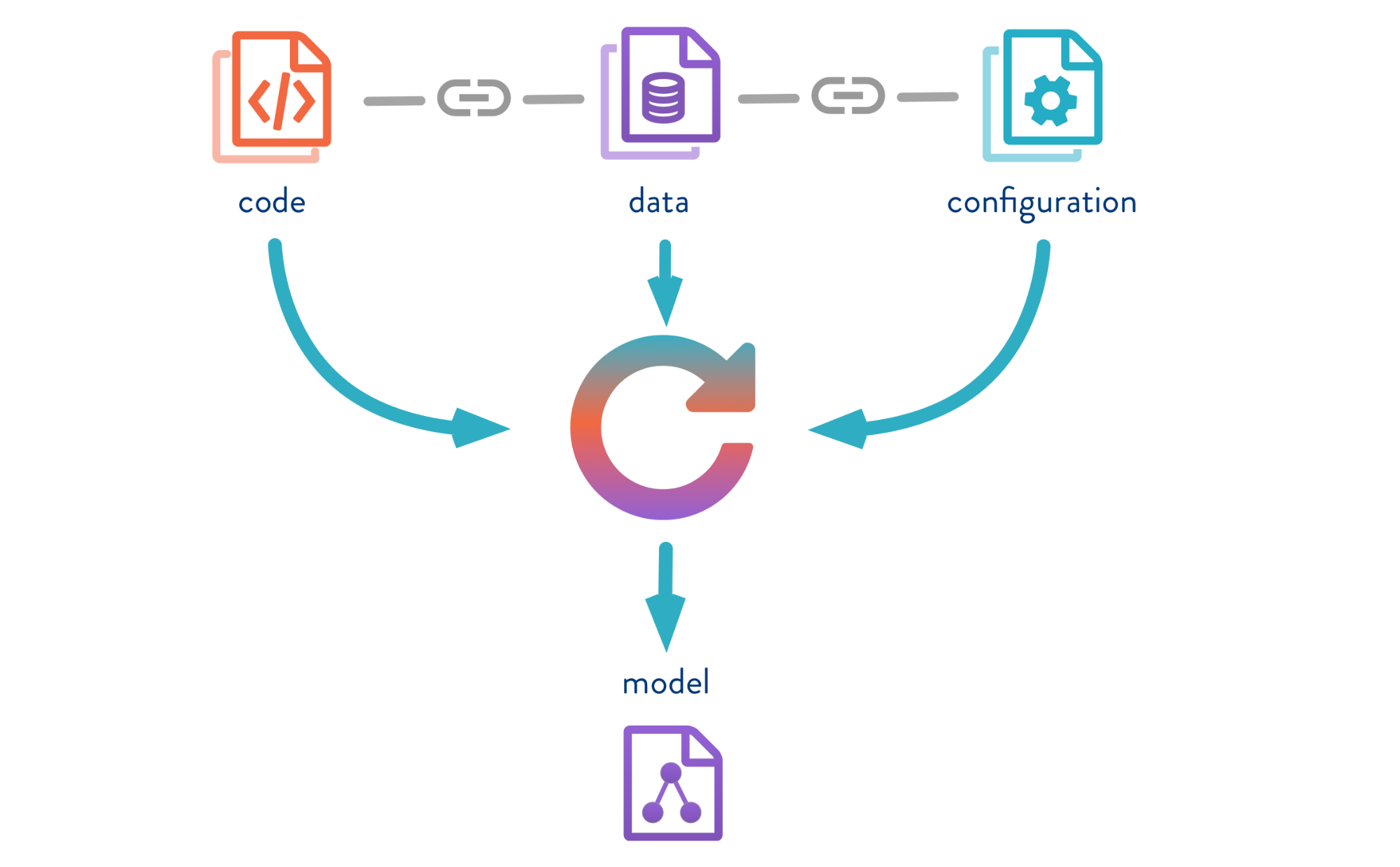
DVC le permite versionar modelos, datos y tuberías en proyectos DS.
La fuente está
aquí .
Veamos la operación de DVC usando el ejemplo del problema de clasificación del color del iris. Para esto, se utilizará el
conjunto de datos Iris . Jupyter Notebook muestra otros
ejemplos de trabajo con DVC.
Lo que necesitas hacer:Entonces, clonamos el repositorio, creamos un entorno virtual e instalamos los paquetes necesarios. Las instrucciones de instalación y lanzamiento se encuentran en el repositorio README.
1. Clonar este repositorio
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Crear y activar entorno virtual
pip install virtualenv virtualenv venv source venv/bin/activate
3. Instalar bibliotecas de python (incluido dvc)
pip install -r requirements.txt
Para instalar DVC, use el comando
pip install dvc . Después de la instalación, debe inicializar el DVC en la carpeta del proyecto
dvc init , que generará un conjunto de carpetas para el trabajo posterior de DVC.
4. pagar una nueva rama en el repositorio de demostración (para no borrar el contenido de la rama maestra)
git checkout -b dvc-tutorial
5. Inicializar DVC
dvc init commit dvc init git commit -m "Initialize DVC"
DVC se ejecuta sobre Git, usa su infraestructura y tiene una sintaxis similar.
En el proceso, DVC crea meta archivos para describir canalizaciones y archivos versionados, que debe guardar en Git el historial de su proyecto. Por lo tanto, después de ejecutar
dvc init debe ejecutar
git commit para confirmar todas las configuraciones realizadas.
La carpeta
.dvc aparecerá en su repositorio, en la que se
.dvc cache y la
config .
El contenido de
.dvc se verá así:
./ ../ .gitignore cache/ config
Config es la configuración de DVC, y cache es la carpeta del sistema en la que DVC almacenará todos los datos y modelos que versionará.
DVC también creará un archivo
.gitignore , en el que escribirá aquellos archivos y carpetas que no necesitan ser confirmados en el repositorio. Cuando transfiere un archivo a DVC para versionar en Git, las versiones y los metadatos se guardarán, y el archivo en sí se almacenará en la memoria caché.
Ahora necesita instalar todas las dependencias y luego realizar un
checkout en la nueva rama
dvc-tutorial , en la que trabajaremos. Y descargue el conjunto de datos de Iris.
Obtener datos
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Funciones de DVC
Modelos y datos de versiones
La fuente está
aquí .
Permítame recordarle que si transfiere algunos datos bajo el control de DVC, comenzará a rastrear todos los cambios. Y podemos trabajar con estos datos de la misma manera que con Git: guarde la versión, envíela al repositorio remoto, obtenga la versión correcta de los datos, cambie y cambie entre versiones. La interfaz en DVC es muy simple.
Ingrese el comando
dvc add y especifique la ruta al archivo que necesitamos versionar. DVC creará el metarchivo iris.csv con la extensión .dvc y escribirá información al respecto en la carpeta de caché. Confirmemos estos cambios para que la información sobre el comienzo de las versiones aparezca en el historial de Git.
dvc add data/iris.csv
Dentro del archivo dvc generado, su hash se almacena con parámetros estándar.
Output : la ruta al archivo en la carpeta dvc, que agregamos bajo el control de DVC. El sistema toma los datos, los coloca en la memoria caché y crea un enlace a la memoria caché en el directorio de trabajo. Este archivo se puede agregar al historial de Git y, por lo tanto, versionarse. DVC se hace cargo de la gestión de los datos en sí. Los primeros dos caracteres del hash se usan como la carpeta dentro del caché, y los caracteres restantes se usan como el nombre del archivo creado.
 Automatización de tuberías ML
Automatización de tuberías MLAdemás del control de versión de datos, podemos crear tuberías (tuberías): cadenas de cálculos entre las que se definen las dependencias. Aquí está la tubería estándar para la capacitación y evaluación de clasificadores:
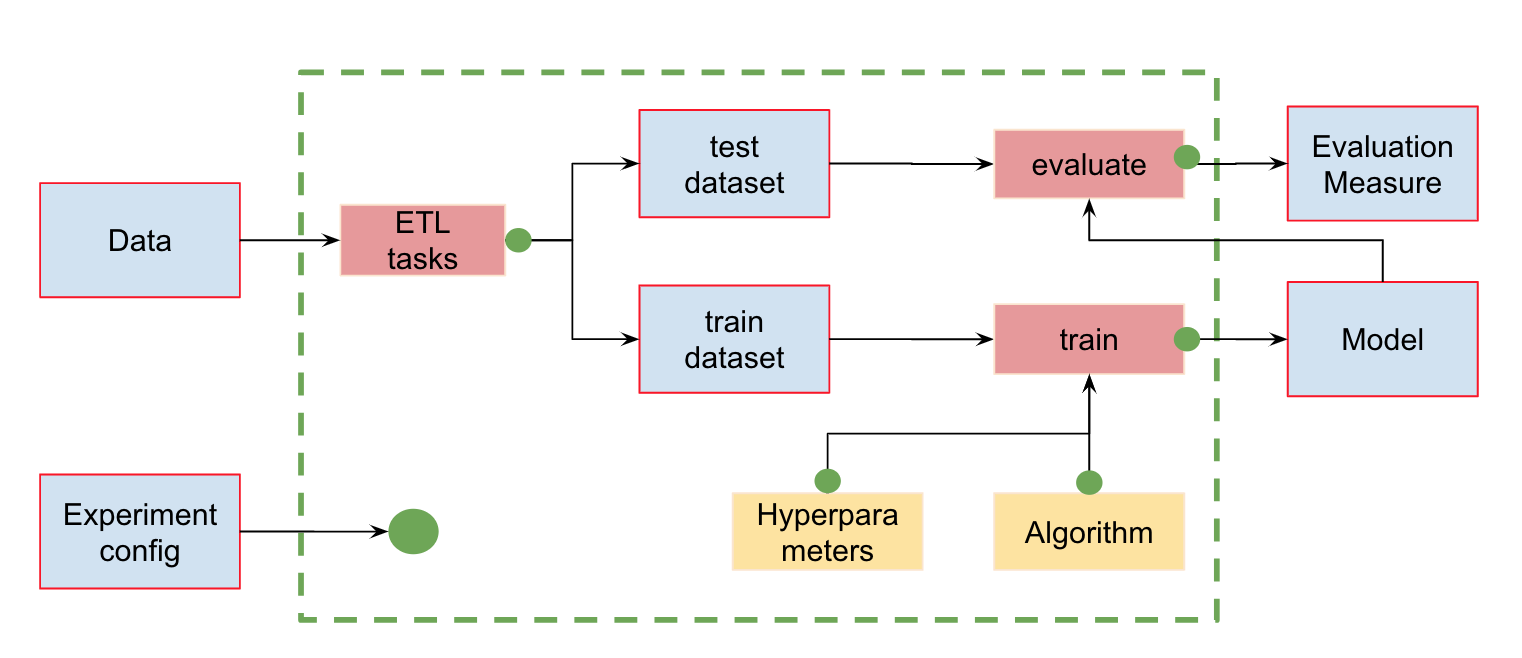
En la entrada, tenemos datos que deben ser preprocesados, divididos en entrenar y probar, calcular las características y solo luego entrenar el modelo y evaluarlo. Esta tubería se puede dividir en piezas separadas. Por ejemplo, para distinguir la etapa de carga y preprocesamiento de datos, división de datos, evaluación, etc., y conexión de estas cadenas.
Para hacer esto, el DVC tiene un maravilloso
dvc run , en el que pasamos ciertos parámetros y especificamos el módulo de Python que necesitamos ejecutar.
Ahora, por ejemplo, la fase de lanzamiento del cálculo de signos. Primero, veamos el contenido del módulo featureization.py:
import pandas as pd def get_features(dataset): features = dataset.copy()
Este código toma el conjunto de datos, calcula las características y las guarda en iris_featurized.csv. Dejamos el cálculo de signos adicionales a la siguiente etapa.
Para crear una tubería, debe ejecutar el comando para cada etapa del cálculo.
dvc run .

Primero, en el comando
dvc run , especifique el nombre del metarchivo stage_feature_extraction.dvc, en el que el DVC escribirá los metadatos necesarios sobre la etapa de cálculo. Mediante el argumento
-d , especificamos las dependencias necesarias: el módulo featureization.py y el archivo de datos iris.csv. También especificamos el archivo iris_featurized.csv, en el que se guardan los signos, y el comando de lanzamiento python src / featurization.py.
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
El DVC creará un metarchivo y hará un seguimiento de los cambios en el módulo Python y el archivo iris.csv.
Si se producen cambios en ellos, el DVC reiniciará este paso de cálculo en la tubería.
El archivo stage_feature_extraction.dvc resultante contendrá su hash, comando de inicio, dependencias y salida (hay parámetros adicionales para ellos que se pueden encontrar en los metadatos).
Ahora debe guardar este archivo en el historial de confirmaciones de Git. Por lo tanto, podemos crear una nueva rama e insertarla en el repositorio de Git. Puede comprometerse con una historia de Git ya sea creando cada etapa individualmente o todas las etapas a la vez.
Cuando construimos una cadena de este tipo para todo nuestro experimento, el DVC crea un gráfico de cálculo (DAG), por el cual puede comenzar a contar toda la tubería o alguna parte. Los hashes de la salida de una etapa van a las entradas de otra. Según ellos, DVC rastrea las dependencias y crea un gráfico de cálculos. Si cambió el código en algún lugar de split_dataset.py, el DVC no cargará los datos y posiblemente recalculará los signos, pero reiniciará esta etapa y las etapas posteriores de capacitación y evaluación.
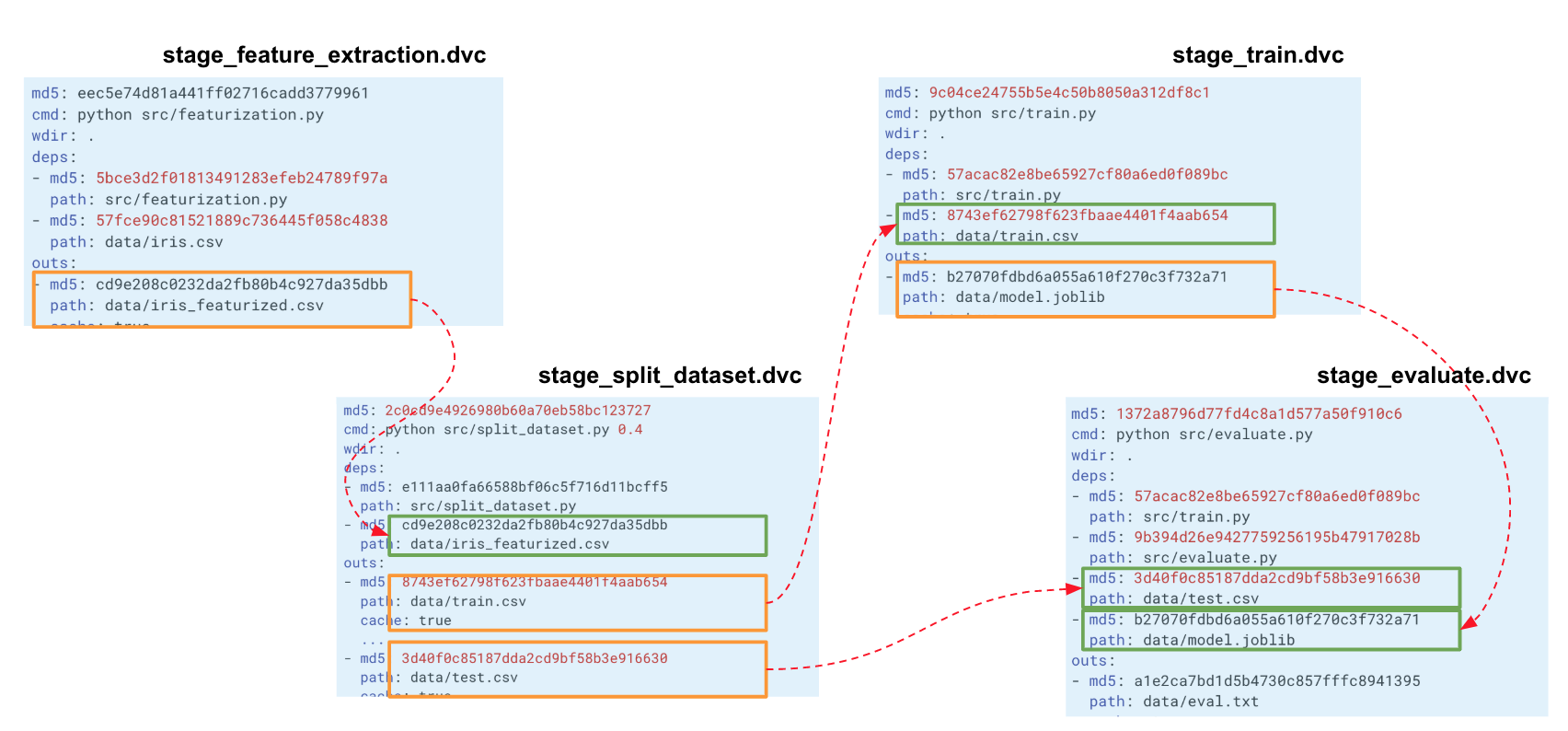 Seguimiento de métricas
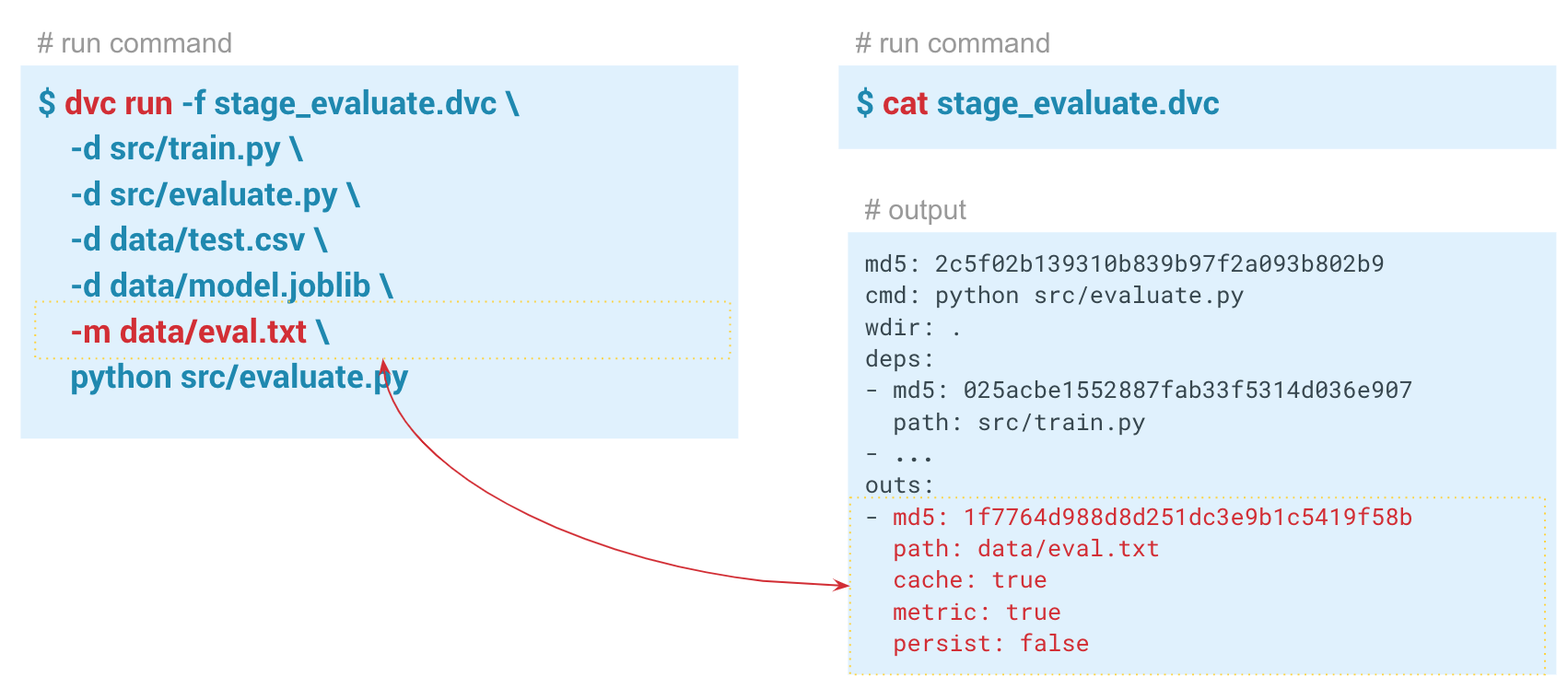
Seguimiento de métricasUsando el
dvc metrics show , puede mostrar las métricas del lanzamiento actual, la rama en la que estamos ubicados. Y si pasamos la opción
-a , el DVC mostrará todas las métricas que están en el historial de Git. Para que DVC comience a rastrear métricas, al crear el paso de evaluación, pasamos el parámetro
-m través de data / eval.txt. El módulo Evaluation.py escribe métricas en este archivo, en este caso
f1 y
confusion metrics . En la carpeta de salida en el archivo dvc de este paso, el
cache y las
metrics establecen en verdadero. Es decir, el comando dvc metrics show mostrará el contenido del archivo eval.txt en la consola. Además, utilizando los argumentos de este comando, puede mostrar solo
f1_score o solo
confusion_matrix .
En este ejemplo, obtuvimos estos resultados:
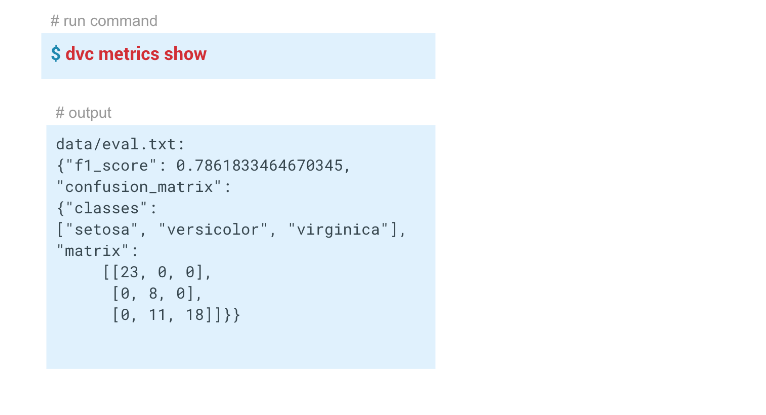 Reproducibilidad de tubería
Reproducibilidad de tuberíaQuienes han trabajado con este conjunto de datos saben que es muy difícil construir un buen modelo sobre él.
Ahora tenemos una tubería creada usando DVC. El sistema rastrea el historial de datos y el modelo, puede reiniciarse total o parcialmente y puede mostrar métricas. Hemos completado toda la automatización necesaria.
Teníamos un modelo con f1 = 0,78. Queremos mejorarlo cambiando algunos parámetros. Para hacer esto, reinicie toda la tubería, idealmente, con un solo comando. Además, si está trabajando en un equipo, es posible que desee transmitir el modelo y el código a sus colegas para que puedan seguir trabajando en ellos.
El
dvc repro permite reiniciar tuberías o etapas individuales (en este caso, debe especificar la etapa reproducida después del comando).
dvc repro stage_evaluate , la etapa intentará reiniciar toda la tubería. Pero si hacemos esto en el estado actual, el DVC no verá ningún cambio y no se reiniciará. Y si cambiamos algo, él encontrará el cambio y reiniciará la tubería a partir de ese momento.
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
En este caso, el DVC no vio ningún cambio en las dependencias de la etapa stage_evaluate y se negó a reiniciar. Y si especificamos la opción
-f , reiniciará todos los pasos preliminares y mostrará una advertencia de que elimina las versiones anteriores de los datos de los que estaba rastreando. Cada vez que el DVC reinicia la etapa, elimina el caché anterior, en realidad lo sobrescribe para no duplicar datos. En el momento en que se inicia el archivo DVC, se verificará su hash y, si ha cambiado, la tubería se reiniciará y sobrescribirá toda la salida que tiene esta tubería. Si desea evitar esto, primero debe ejecutar una versión específica de los datos en algún repositorio remoto.
La capacidad de reiniciar tuberías y rastrear las dependencias de cada etapa le permite experimentar con modelos más rápido.
Por ejemplo, puede cambiar las características ('descomentar' las líneas para calcular las características en
featurization.py ). DVC verá estos cambios y reiniciará toda la tubería.
Guardar datos en un repositorio remoto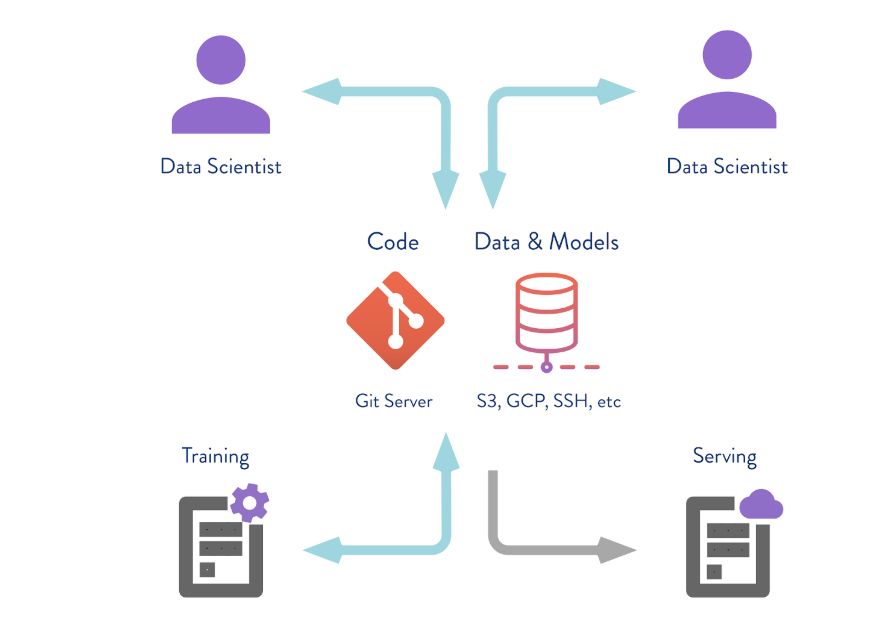
DVC puede funcionar no solo con el almacenamiento de la versión local. Si ejecuta el
dvc push , el DVC enviará la versión actual del modelo y los datos a un repositorio de repositorio remoto preconfigurado. Si entonces su colega hace el
git clone su repositorio y
dvc pull , obtendrá la versión de los datos y modelos destinados a esta rama. Lo principal es que todos tengan acceso a este repositorio.
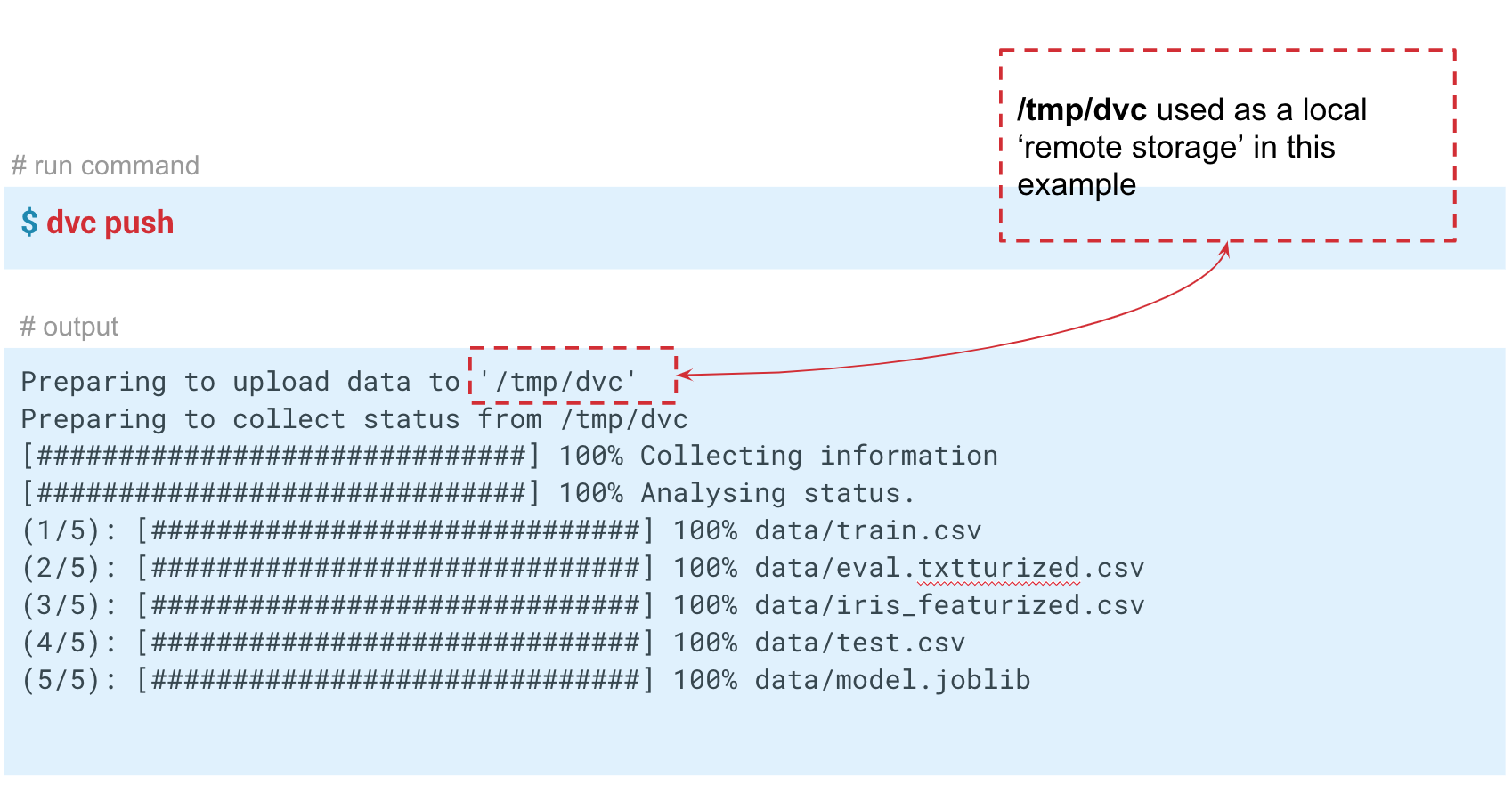
En este caso, simulamos el almacenamiento "remoto" en la carpeta temp / dvc. Aproximadamente de la misma manera, el almacenamiento remoto se crea en la nube. Comete este cambio para que permanezca en la historia de Git. Ahora podemos hacer un
dvc push para enviar datos a este almacenamiento, y su colega simplemente hace
dvc pull para obtenerlos.
Entonces , examinamos tres situaciones en las que DVC y la funcionalidad básica son útiles:
- Datos y modelos de versiones . Si no necesita tuberías y repositorios remotos, puede versionar los datos para un proyecto específico, trabajando en la máquina local. DVC le permite trabajar rápidamente con datos en decenas de gigabytes.
- Intercambio de datos y modelos entre equipos . Puede usar soluciones en la nube para almacenar datos. Esta es una opción conveniente si tiene un equipo distribuido o si hay restricciones en el tamaño de los archivos enviados por correo. Además, esta técnica se puede utilizar en situaciones en las que se envían un cuaderno, pero no se inician.
- Organización del trabajo en equipo dentro de un servidor grande . El equipo puede trabajar con la versión local de Big Data, por ejemplo, varias decenas o cientos de gigabytes, para que no los copie de un lado a otro, sino que use un almacenamiento remoto que enviará y guardará solo versiones críticas de modelos o datos.
Parte 2
¿Cómo implementar DVC en tus proyectos?Para garantizar la reproducibilidad del proyecto, se deben cumplir ciertos requisitos.
Aquí están los principales:
- todas las tuberías están automatizadas;
- control de parámetros de lanzamiento de cada etapa de cálculos;
- control de versiones de código, datos y modelos;
- control ambiental;
- La documentación.
Si se hace todo esto, es más probable que el proyecto sea reproducible. DVC le permite cumplir los primeros 3 requisitos de esta lista.
Al intentar implementar DVC en su empresa, puede encontrar reticencias: “¿Por qué necesitamos esto? Tenemos un cuaderno Jupyter ". Quizás algunos de sus colegas solo trabajan con Jupyter Notebook, y es mucho más difícil para ellos escribir tales canalizaciones y códigos en el IDE. En este caso, puede realizar una implementación paso a paso.
- La forma más fácil de comenzar es versionando el código y los modelos.
Y luego pasar a automatizar las tuberías. - Primero automatice los pasos que a menudo se reinician y cambian,
y luego toda la tubería.
Si tiene un nuevo proyecto y un par de entusiastas en un equipo, entonces es mejor usar DVC de inmediato. Entonces, por ejemplo, ¡resultó en nuestro equipo! Cuando comencé un nuevo proyecto, mis colegas me apoyaron y comenzamos a usar DVC por nuestra cuenta. Luego comenzaron a compartir con otros colegas y equipos. Alguien recogió nuestro compromiso. Hoy, DVC todavía no es una herramienta generalmente aceptada en nuestro banco, pero se usa en varios proyectos.