Nota perev. : Presentamos a su atención detalles técnicos sobre los motivos de la reciente interrupción del servicio en la nube, atendida por los creadores de Grafana. Este es un ejemplo clásico de cómo una característica nueva y aparentemente extremadamente útil diseñada para mejorar la calidad de la infraestructura ... puede hacer mucho daño si no se prevén los numerosos matices de su aplicación en las realidades de producción. Es maravilloso cuando aparecen tales materiales que le permiten aprender no solo de sus errores. Los detalles se encuentran en la traducción de este texto del vicepresidente de producto de Grafana Labs.
El viernes 19 de julio, el servicio Hosted Prometheus en Grafana Cloud dejó de funcionar durante unos 30 minutos. Pido disculpas a todos los clientes que sufrieron el fracaso. Nuestra tarea es proporcionar las herramientas necesarias para el monitoreo, y entendemos que su inaccesibilidad complica su vida. Nos tomamos este incidente muy en serio. Esta nota explica lo que sucedió, cómo reaccionamos y qué estamos haciendo para que esto no vuelva a suceder.
Antecedentes
El servicio Prometheus alojado en la nube de Grafana se basa en
Cortex , un proyecto de CNCF para crear un servicio Prometheus multiinquilino escalable horizontalmente y altamente accesible. La arquitectura Cortex consta de un conjunto de microservicios separados, cada uno de los cuales realiza su función: replicación, almacenamiento, solicitudes, etc. Cortex se está desarrollando activamente, constantemente tiene nuevas oportunidades y mejora la productividad. Implementamos regularmente nuevas versiones de Cortex en clústeres para que los clientes puedan aprovechar estas oportunidades; afortunadamente, Cortex puede actualizarse sin tiempo de inactividad.
Para actualizaciones sin problemas, el servicio Ingester Cortex requiere una réplica adicional de Ingester durante el proceso de actualización.
( Nota : Ingester es el componente central de Cortex. Su tarea es recolectar un flujo constante de muestras, agruparlas en trozos de Prometheus y almacenarlas en una base de datos como DynamoDB, BigTable o Cassandra.) Esto permite a los Ingestores más antiguos. reenviar datos actuales a nuevos ingestadores. Vale la pena señalar que los ingestadores exigen recursos. Para su trabajo es necesario tener 4 núcleos y 15 GB de memoria por pod, es decir. El 25% de la potencia del procesador y la memoria de la máquina base en el caso de nuestros clústeres Kubernetes. En general, generalmente tenemos muchos más recursos no utilizados en un clúster que 4 núcleos y 15 GB de memoria, por lo que podemos ejecutar fácilmente estos ingestadores adicionales durante las actualizaciones.
Sin embargo, a menudo sucede que durante el funcionamiento normal ninguna de estas máquinas tiene este 25% de los recursos no reclamados. Sí, no nos esforzamos: la CPU y la memoria siempre son útiles para otros procesos. Para resolver este problema, decidimos usar las
prioridades de Kubernetes Pod . La idea es dar a los ingestadores una prioridad más alta que otros microservicios (sin estado). Cuando necesitamos ejecutar un ingesta adicional (N + 1), forzamos temporalmente otras vainas más pequeñas. Estas cápsulas se transfieren a recursos gratuitos en otras máquinas, dejando un "agujero" suficientemente grande para lanzar un ingesta adicional.
El jueves 18 de julio, lanzamos cuatro nuevos niveles de prioridad en nuestros grupos:
crítico ,
alto ,
medio y
bajo . Se probaron en un clúster interno sin tráfico de clientes durante aproximadamente una semana. Por defecto, los pods sin una prioridad dada recibieron prioridad
media ; se estableció una clase con
alta prioridad para los ingestadores.
Critical estaba reservado para el monitoreo (Prometheus, Alertmanager, node-exporter, kube-state-metrics, etc.). Nuestra configuración está abierta, y vea PR
aquí .
Accidente
El viernes 19 de julio, uno de los ingenieros lanzó un nuevo clúster Cortex dedicado para un gran cliente. La configuración para este clúster no incluía las prioridades de los nuevos pods, por lo que a todos los nuevos pods se les asignó la prioridad predeterminada:
media .
El clúster de Kubernetes no tenía suficientes recursos para el nuevo clúster Cortex, y el clúster de producción Cortex existente no se actualizó (los ingestadores se quedaron sin una
alta prioridad). Dado que los ingestadores del nuevo clúster pasaron por defecto a prioridad
media , y las vainas existentes en la producción funcionaron sin ninguna prioridad, los ingestadores del nuevo clúster expulsaron a los ingestadores del clúster de producción Cortex existente.
ReplicaSet para Ingester extruido en el clúster de producción detectó un pod extruido y creó uno nuevo para mantener un número determinado de copias. El nuevo pod se estableció en prioridad
media por defecto, y el siguiente "antiguo" Ingester en producción perdió recursos. El resultado fue
un proceso similar a una avalancha que llevó a desplazar todas las vainas de Ingester para los grupos de producción de Cortex.
Los ingestadores mantienen estado y almacenan datos de las 12 horas anteriores. Esto nos permite comprimirlos de manera más eficiente antes de escribir en el almacenamiento a largo plazo. Para hacer esto, Cortex fragmenta los datos de la serie usando una Tabla de hash distribuida (DHT), y replica cada serie a tres Ingestores usando la consistencia de quórum de estilo Dynamo. Cortex no escribe datos en Ingesters, que están deshabilitados. Por lo tanto, cuando un gran número de ingestadores abandonan DHT, Cortex no puede proporcionar una replicación suficiente de los registros y se "caen".
Detección y eliminación.
Las nuevas notificaciones de Prometheus basadas en el "
error basado en el
presupuesto " (
los detalles basados en el
presupuesto de error aparecerán en un artículo futuro) comenzaron a sonar una alarma 4 minutos después del inicio del apagado. Durante los siguientes cinco minutos más o menos, diagnosticamos y creamos el clúster Kubernetes subyacente para acomodar los clústeres de producción nuevos y existentes.
Cinco minutos más tarde, los antiguos ingestadores registraron con éxito sus datos, y los nuevos comenzaron, y los grupos de Cortex volvieron a estar disponibles.
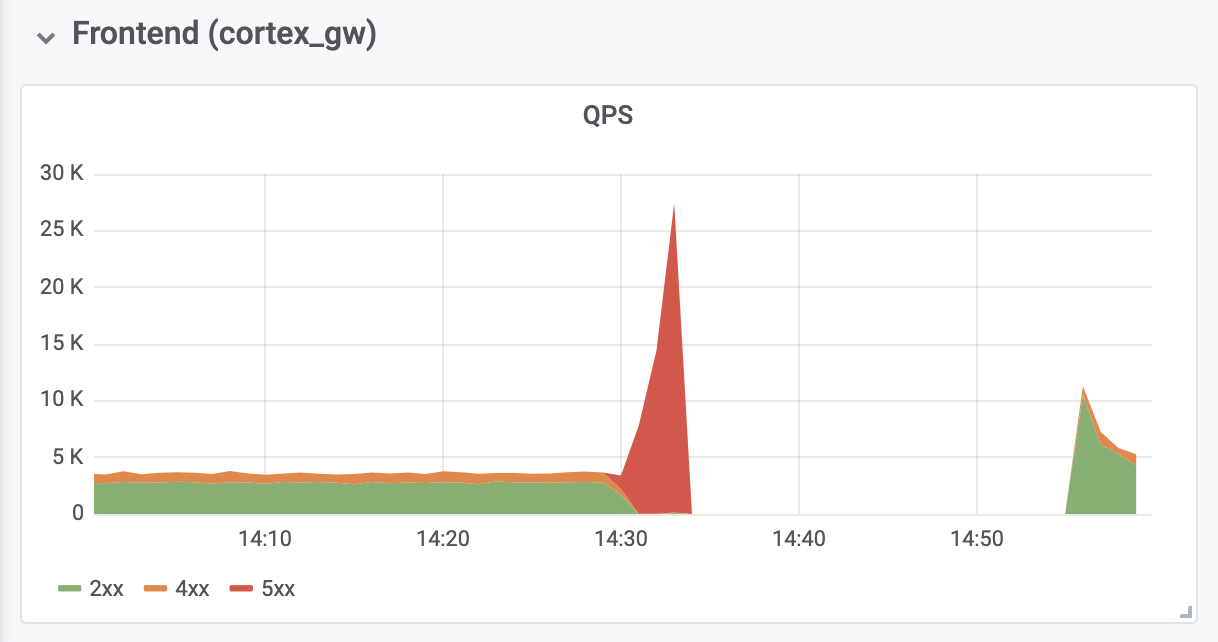
Tomó otros 10 minutos diagnosticar y corregir los errores de falta de memoria (OOM) de los servidores proxy de autenticación inversa ubicados frente a Cortex. Los errores de OOM fueron causados por un aumento de diez veces en QPS (como creemos, debido a solicitudes excesivamente agresivas de los servidores del cliente Prometheus).
Las consecuencias
El tiempo de inactividad total fue de 26 minutos. No se perdieron datos. Los ingestadores han cargado con éxito todos los datos en memoria al almacenamiento a largo plazo. Durante un apagado, los servidores del cliente Prometheus guardaron las entradas
remotas en el búfer utilizando la
nueva API remote_write basada en
WAL (creada por
Callum Styan de Grafana Labs) y repitieron las entradas fallidas después de la falla.
 Operaciones de escritura de clúster de producción
Operaciones de escritura de clúster de producciónConclusiones
Es importante aprender de este incidente y tomar las medidas necesarias para evitar una recurrencia.
Mirando hacia atrás, debemos admitir que no debemos establecer la prioridad
media predeterminada, hasta que todos los ingestadores en producción reciban una
alta prioridad. Además, deberían haberse ocupado de su
alta prioridad por adelantado. Ahora todo está arreglado. Esperamos que nuestra experiencia ayude a otras organizaciones a considerar el uso de prioridades de pod en Kubernetes.
Agregaremos un nivel adicional de control sobre la implementación de cualquier objeto adicional cuyas configuraciones sean globales para el clúster. En adelante, tales cambios serán evaluados por más personas. Además, la modificación que condujo a la falla se consideró demasiado insignificante para un documento de proyecto separado; solo se discutió en el tema de GitHub. De ahora en adelante, todos los cambios de configuración estarán acompañados por la documentación adecuada del proyecto.
Finalmente, automatizamos el cambio de tamaño del proxy de autenticación inversa para evitar OOM durante la congestión, de lo que hemos sido testigos, y analizamos la configuración predeterminada de Prometheus asociada con la reversión y el escalado para evitar problemas similares en el futuro.
El fracaso experimentado también tuvo algunas consecuencias positivas: después de recibir los recursos necesarios, Cortex se recuperó automáticamente sin ninguna intervención adicional. También
adquirimos una valiosa experiencia con
Grafana Loki , nuestro nuevo sistema de agregación de registros, que ayudó a garantizar que todos los ingestadores se comportaron correctamente durante y después del bloqueo.
PD del traductor
Lea también en nuestro blog: