Antes de que cada servicio genere al menos 1 Mb / s de tráfico de Internet, surge la pregunta: “¿Cómo? sobre TCP o sobre UDP? " En las áreas de aplicación, incluidas las plataformas de entrega, las preferencias y tradiciones de tomar tales decisiones ya se han desarrollado.
En teoría, si, por ejemplo, una vez que un desarrollador perezoso no intentara implementar su ML en Python (porque solo lo sabía), lo más probable es que el mundo nunca se haya sentido tan lleno de amor por el despreciable lenguaje de "codificadores súper Java". Y hoy, las debilidades de este lenguaje en el pasado contexto de aplicación le otorgan primacía incondicionalmente en el despliegue y lanzamiento de numerosos mineros A / B.
Puede comparar mucho: ARM con Intel, iOS y Android, y Mortal Kombat con injusticia. Y encuentre un espacio holivar, así que regrese al tema de entregar grandes volúmenes de contenido multiformato.
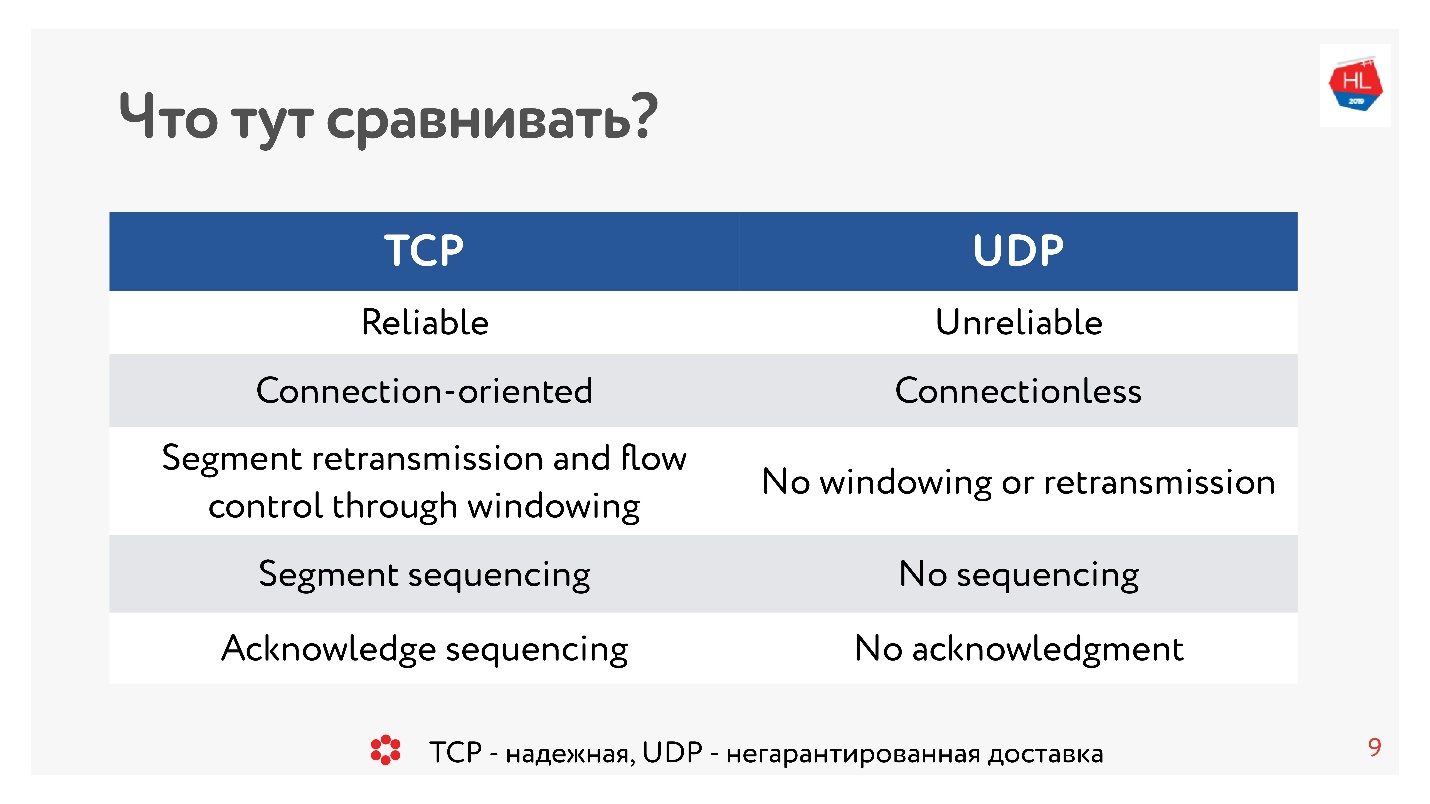
Hace diez años, todos estaban absolutamente seguros de que UDP era algo relacionado con la entrega no garantizada. Si necesita un protocolo confiable, es TCP. Y, contrariamente a la tradición en este artículo, compararemos cosas aparentemente incomparables como TCP y UDP.
 Precaución, debajo del corte 99 ilustraciones y diagramas y todo lo importante.
Precaución, debajo del corte 99 ilustraciones y diagramas y todo lo importante.La comparación la lleva a cabo el jefe de desarrollo de las plataformas Video y Tape en OK
Alexander Tobol (
alatobol ). Los servicios de Video y News Feed en la red social OK - exclusivamente sobre el contenido y su entrega a todas las plataformas de clientes existentes en cualquier condición de red mala o excelente, y la cuestión de cómo entregarlo, a través de TCP o UDP, es crucial.
TCP vs UDP. Teoría mínima
Para llegar a la comparación, necesitamos un poco de teoría básica.
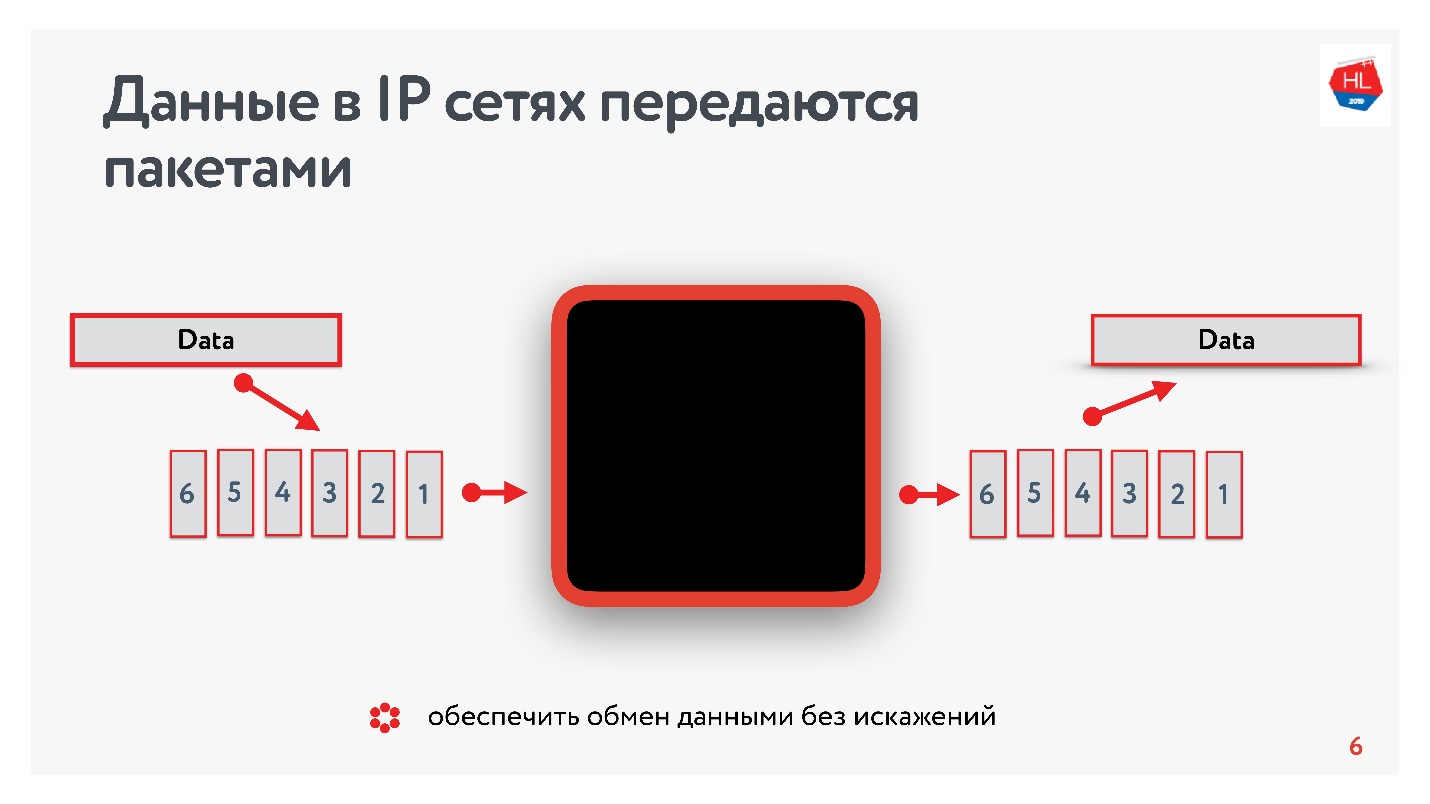
¿Qué sabemos sobre las redes IP? El flujo de datos que envía se divide en paquetes, una especie de recuadro negro entrega estos paquetes al cliente. El cliente recoge paquetes y recibe un flujo de datos. Por lo general, todo esto es transparente y no hay necesidad de pensar qué hay en los niveles inferiores.
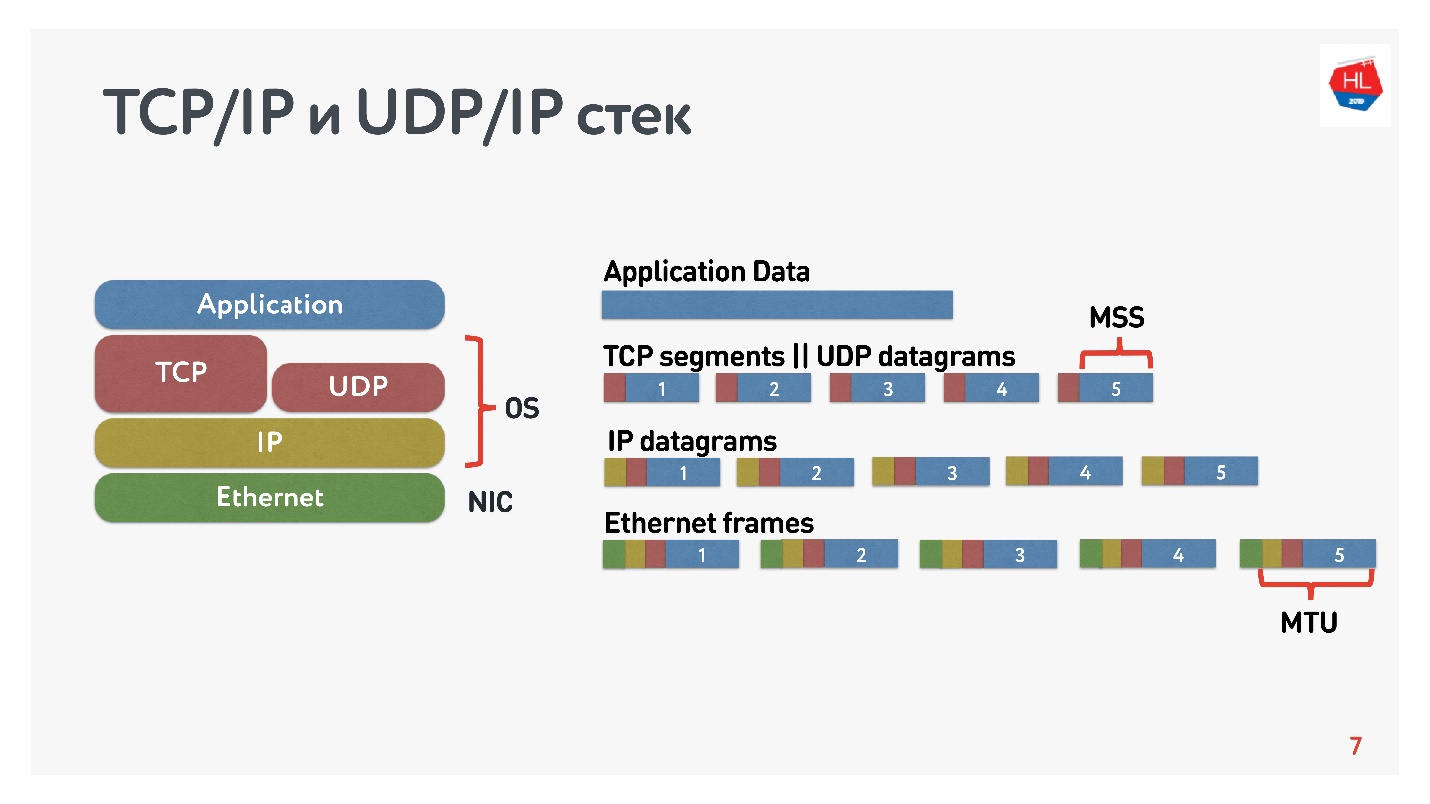
El diagrama muestra la pila TCP / IP y UDP / IP. En la parte inferior hay paquetes de Ethernet, paquetes de IP, y más a nivel del sistema operativo hay TCP y UDP. TCP y UDP en esta pila no son muy diferentes entre sí. Están encapsulados en paquetes IP y las aplicaciones pueden usarlos. Para ver las diferencias, debe buscar dentro de los paquetes TCP y UDP.
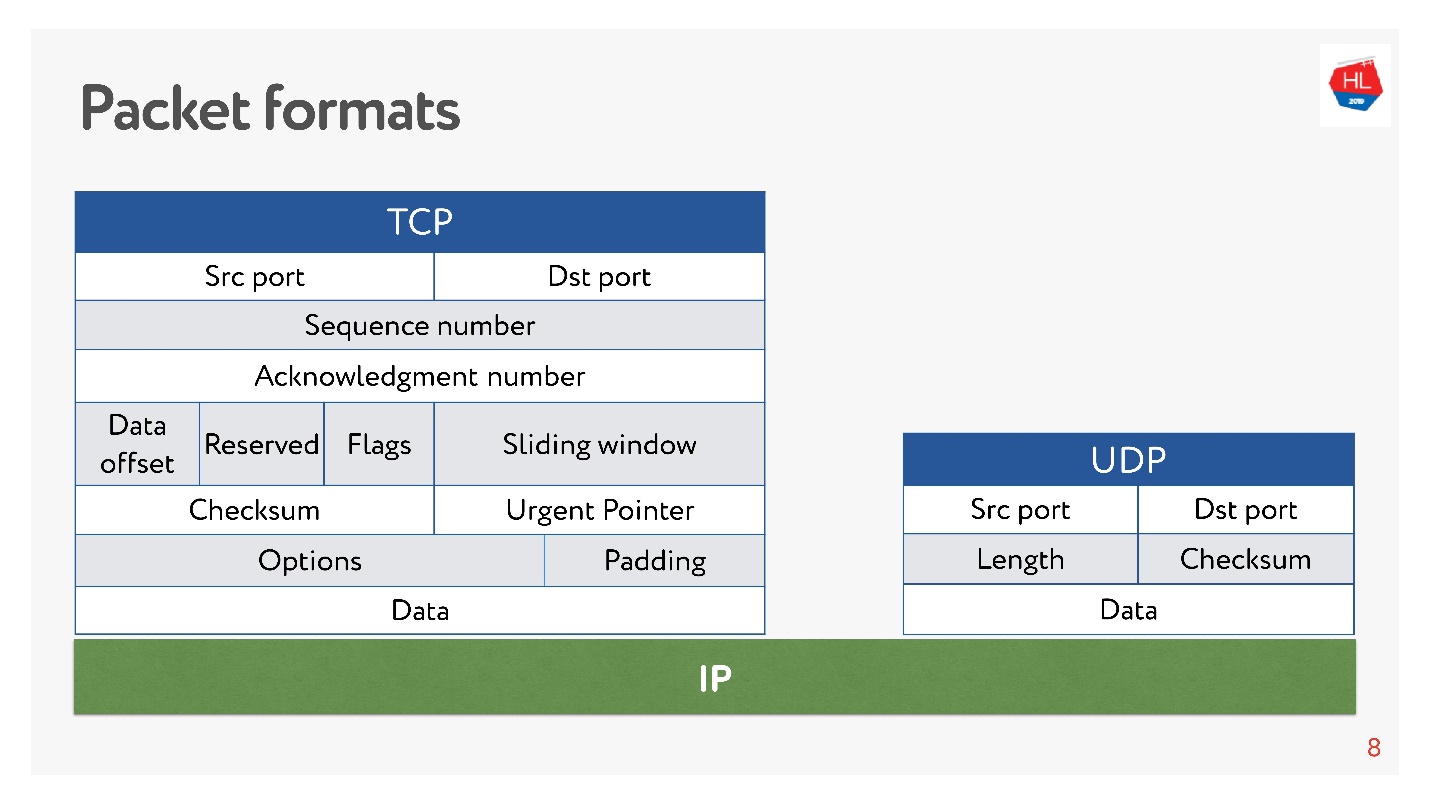
Tanto allí como hay puertos. Pero
en UDP solo hay una suma de comprobación : la longitud del paquete, este protocolo es lo más simple posible. Y en TCP, hay muchos datos que indican claramente la ventana, el reconocimiento, la secuencia, los paquetes, etc. Obviamente
TCP es más complejo .
Hablando en términos generales, TCP es un protocolo de entrega confiable, y UDP no es confiable.
Y, sin embargo, a pesar de la supuesta falta de fiabilidad de UDP, descubriremos si es posible entregar datos más rápido y más confiable que usar TCP. Intentemos mirar la red desde adentro y entender cómo funciona. En el camino, abordaremos las siguientes preguntas:
- ¿Por qué comparar TCP o qué tiene de malo?
- con qué y con qué debería comparar TCP;
- qué hizo Google y qué decisión tomó;
- qué nos espera el futuro de los protocolos de red.
Este artículo no tendrá una teoría: niveles y modelos de OSI, modelos matemáticos complejos, aunque todo se puede contar a través de ellos. Analizaremos al máximo cómo tocar la red no en teoría, sino con nuestras propias manos.
¿Por qué comparar TCP o qué tiene de malo?
TCP fue inventado en 1974, y después de 20 años, cuando fui a la escuela, compré tarjetas de Internet, borré el código y llamé a algún lado. Además, si llama de 2 noches a 7 de la mañana, entonces Internet era gratis, pero era difícil comunicarse.
Pasaron otros 20 años, y los usuarios en redes inalámbricas móviles comenzaron a prevalecer sobre los usuarios "cableados", mientras que TCP no cambió conceptualmente.
El mundo móvil ganó, aparecieron los protocolos inalámbricos y el TCP aún no cambió.
Hoy, el 80% de los usuarios utilizan Wi-Fi o una red inalámbrica 3G-4G.

En redes inalámbricas, hay:
- pérdida de paquetes: aproximadamente el 0.6% de los paquetes que enviamos se pierden en el camino;
- reordenamiento: la reorganización de paquetes en lugares, en la vida real es un fenómeno bastante raro, pero ocurre en el 0.2% de los casos;
- jitter: cuando los paquetes se envían de manera uniforme y llegan a colas con un retraso de aproximadamente 50 ms.
TCP oculta con éxito todas estas características de transferencia de datos en redes heterogéneas, y no necesita sumergirse en él.
A continuación, en el mapa, se encuentra la velocidad promedio de datos TCP en Rusia. Si quita la parte occidental, está claro que la velocidad se mide más en kilobits que en megabits.
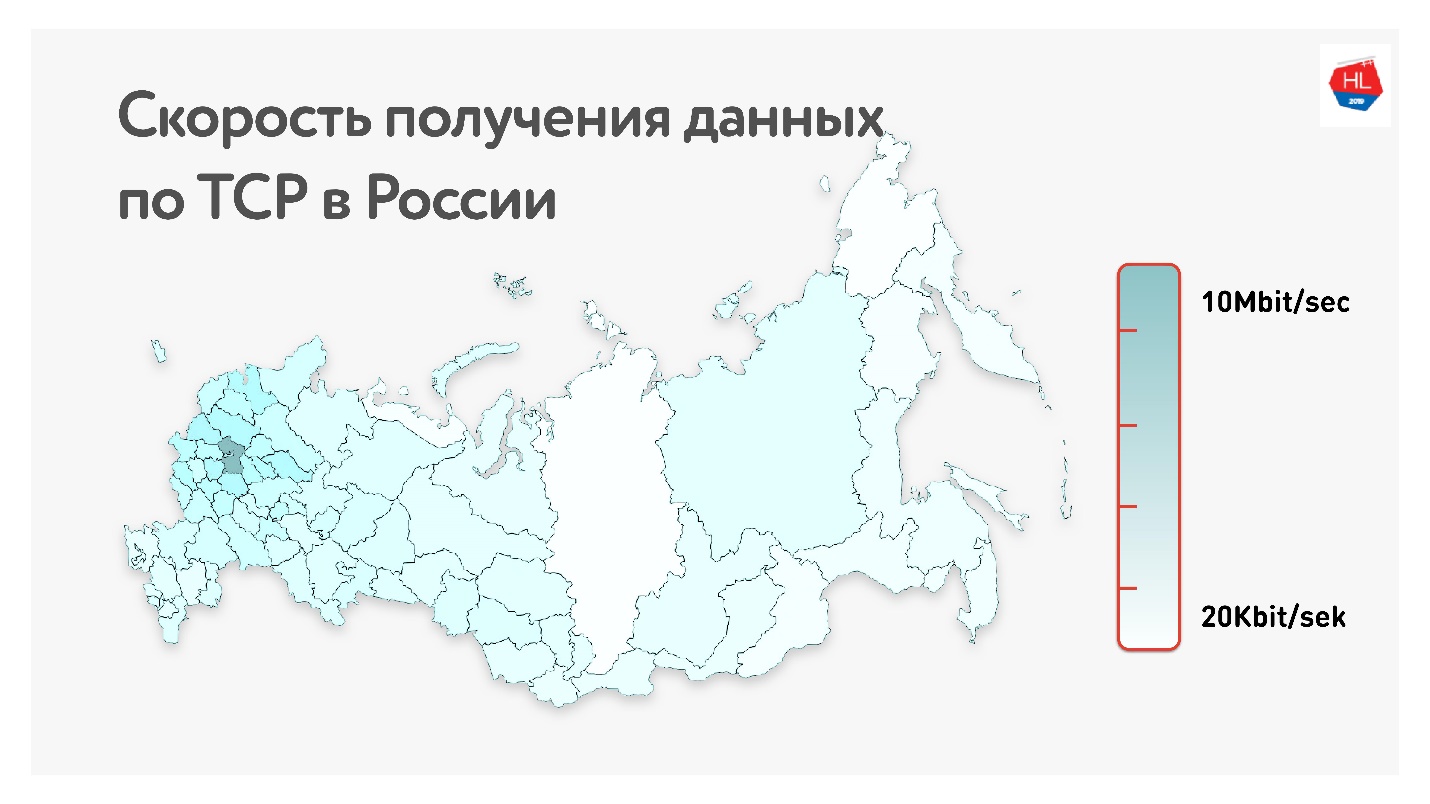
Es decir, en promedio, para nuestros usuarios (excluyendo la parte occidental de Rusia): rendimiento de 1,1 Mbps, pérdida de paquetes del 0,6%, RTT (tiempo de ida y vuelta) del orden de 200 ms.
Cómo calcular RTT
Cuando vi el promedio de 200 ms, pensé que había un error en las estadísticas y decidí medir el RTT para nuestros servidores en el MSC de una manera alternativa usando RIPE Atlas. Este es un sistema para recopilar datos sobre el estado de Internet. La sonda
RIPE Atlas está disponible de forma gratuita.
La conclusión es que lo conecta a la Internet de su hogar y recolecta "karma". Ella trabaja durante días, algunas personas cumplen con algunos de sus pedidos sobre ella. Entonces puede establecer varias tareas usted mismo. Un ejemplo de tal tarea: tomar accidentalmente 30 puntos en Internet y pedir medir RTT, es decir, ejecutar el comando ping en el sitio web Odnoklassniki.
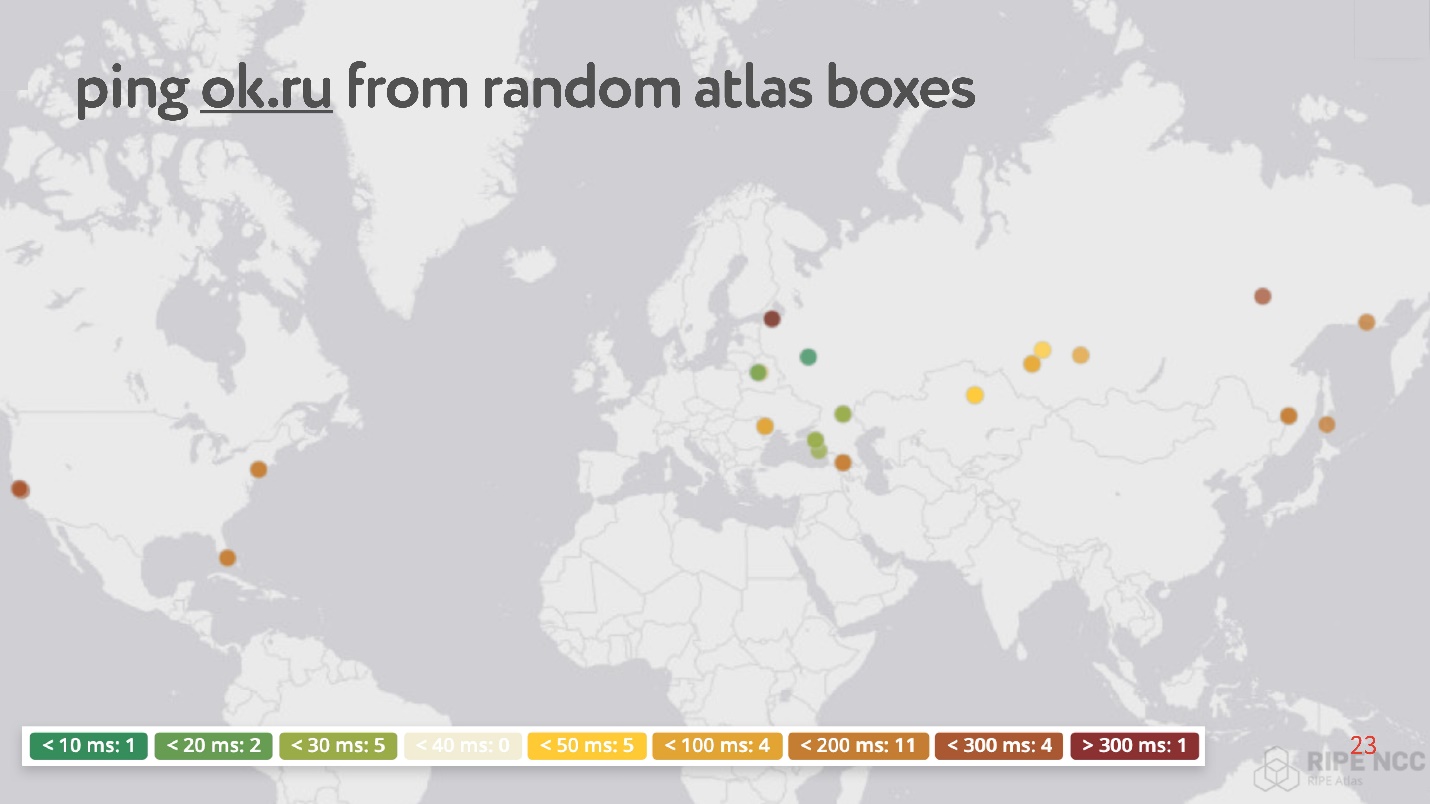
Curiosamente, entre los puntos aleatorios hay muchos que tienen ping de 200 a 300 ms.
En total,
las redes inalámbricas son populares e inestables (aunque esto último generalmente se ignora, ya que se cree que TCP puede manejar esto):
- Más del 80% de los usuarios utilizan internet inalámbrico;
- Los parámetros de las redes inalámbricas cambian dinámicamente dependiendo, por ejemplo, del hecho de que el usuario ha doblado la esquina;
- Las redes inalámbricas tienen altas tasas de pérdida de paquetes, fluctuaciones, reordenamiento;
- Canal asimétrico fijo, cambio de dirección IP.
El consumo de contenido depende de la velocidad de Internet
Esto es muy fácil de verificar: hay muchas estadísticas. Tomé
estadísticas sobre el video, que dice que cuanto mayor es la velocidad de Internet en el país, más usuarios ven el video.
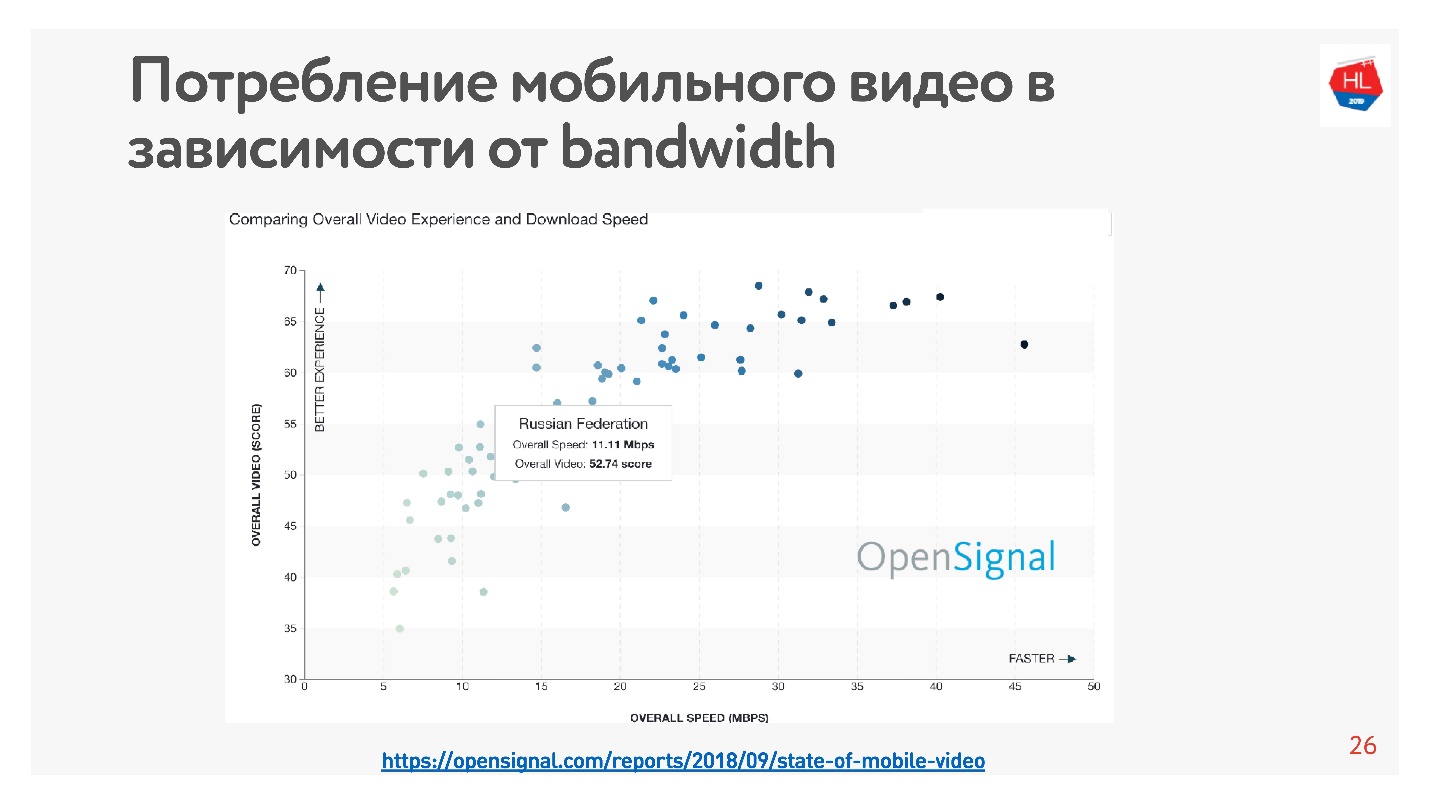
Según estas estadísticas, Rusia tiene una Internet bastante rápida, pero según nuestros datos internos, la velocidad promedio es ligeramente menor.
A favor del hecho de que la velocidad de Internet en su conjunto es insuficiente, dice que todos los creadores de grandes aplicaciones, redes sociales, servicios de video, etc., están optimizando sus servicios para trabajar en una mala red. Después de 10 Kb de datos recibidos, puede ver un mínimo de información en la cinta, y a una velocidad de 500 Kb puede ver videos.
Cómo acelerar la carga
En el proceso de desarrollo de la plataforma de video, nos dimos cuenta de que TCP no es muy efectivo en redes inalámbricas. ¿Cómo llegaste a esta conclusión?
Decidimos acelerar la descarga e hicimos el siguiente truco.
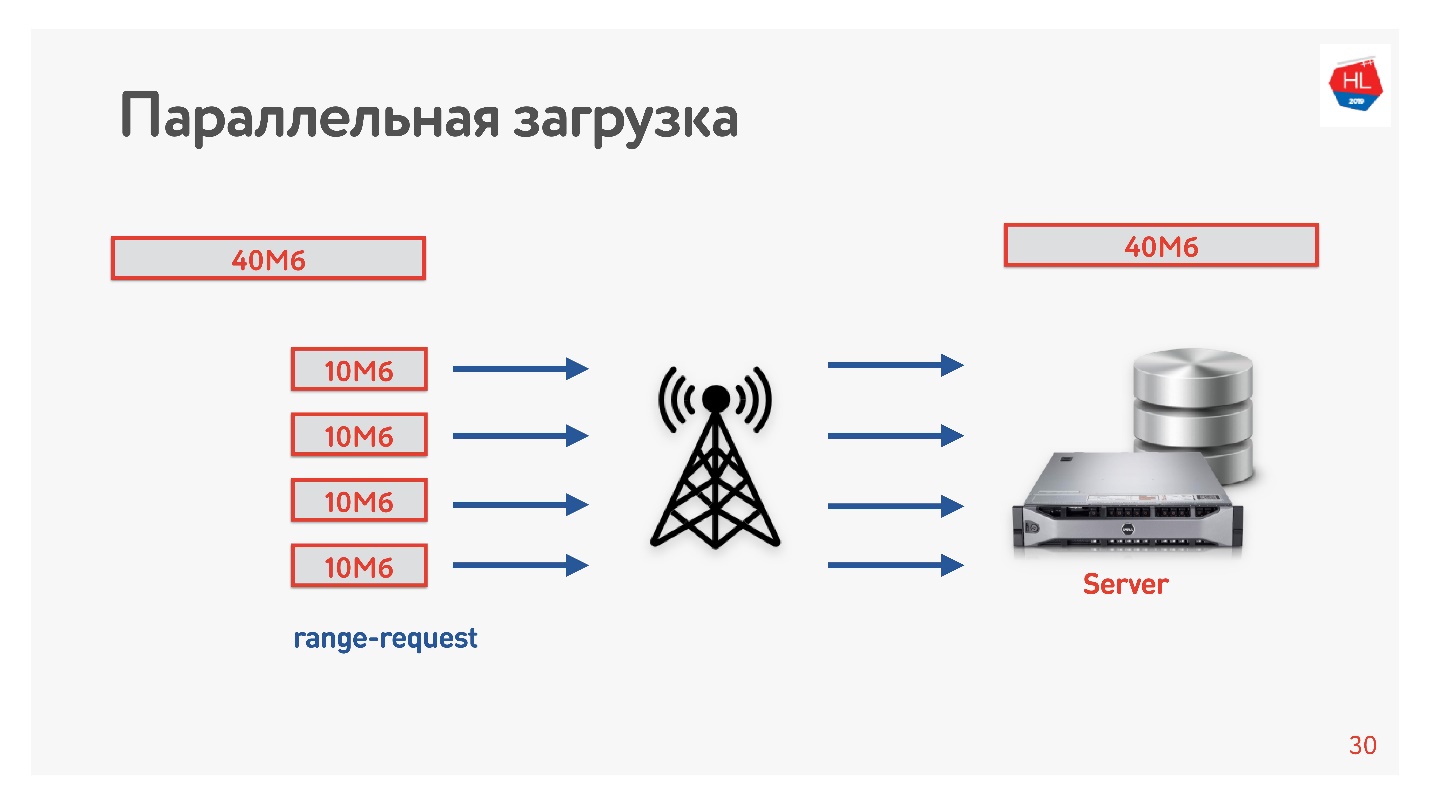
Descargamos el video del cliente al servidor en varias transmisiones, es decir, 40 MB se dividen en 4 partes de 10 MB y se cargan en paralelo. Lo iniciamos en Android y conseguimos que se cargue en paralelo más rápido que en una conexión (
demostración en el informe). ¡Lo más interesante es que cuando lanzamos descargas paralelas en producción, vimos que en algunas regiones la velocidad de descarga aumentó 3 veces!
Cuatro conexiones TCP pueden cargar datos al servidor 3 veces más rápido.
Entonces aumentamos la velocidad de descarga de video y concluimos que la descarga debe ser paralela.
TCP en redes inestables
Se puede tocar un efecto increíble con paralelismo. Es suficiente tomar un medidor de velocidad para recibir / enviar datos (por ejemplo, prueba de velocidad) y modelador de tráfico (por ejemplo, acondicionador de enlace de red, si tiene una Mac). Restringimos la red a parámetros de 1 Mbps para cargar y descargar y comenzar a aumentar la pérdida de paquetes.

La tabla muestra RTT y pérdidas. Se puede ver que en el caso de pérdida del 0%, la red se utiliza al 100%.
En la próxima iteración, aumentamos la pérdida de paquetes en un 5%, y vemos que la red se utiliza solo en un 74%. Parece correcto: con una pérdida de paquetes del 5%, se pierde el 26% de la red. Pero si también aumenta el ping, quedará
menos de la mitad del canal .
Si el canal tiene un RTT alto y una gran pérdida de paquetes, entonces una conexión TCP no utiliza completamente la red.
Otro truco muestra que si comienza a utilizar conexiones TCP paralelas (puede ejecutar varias pruebas de velocidad al mismo tiempo), puede ver el crecimiento inverso de la utilización del canal.
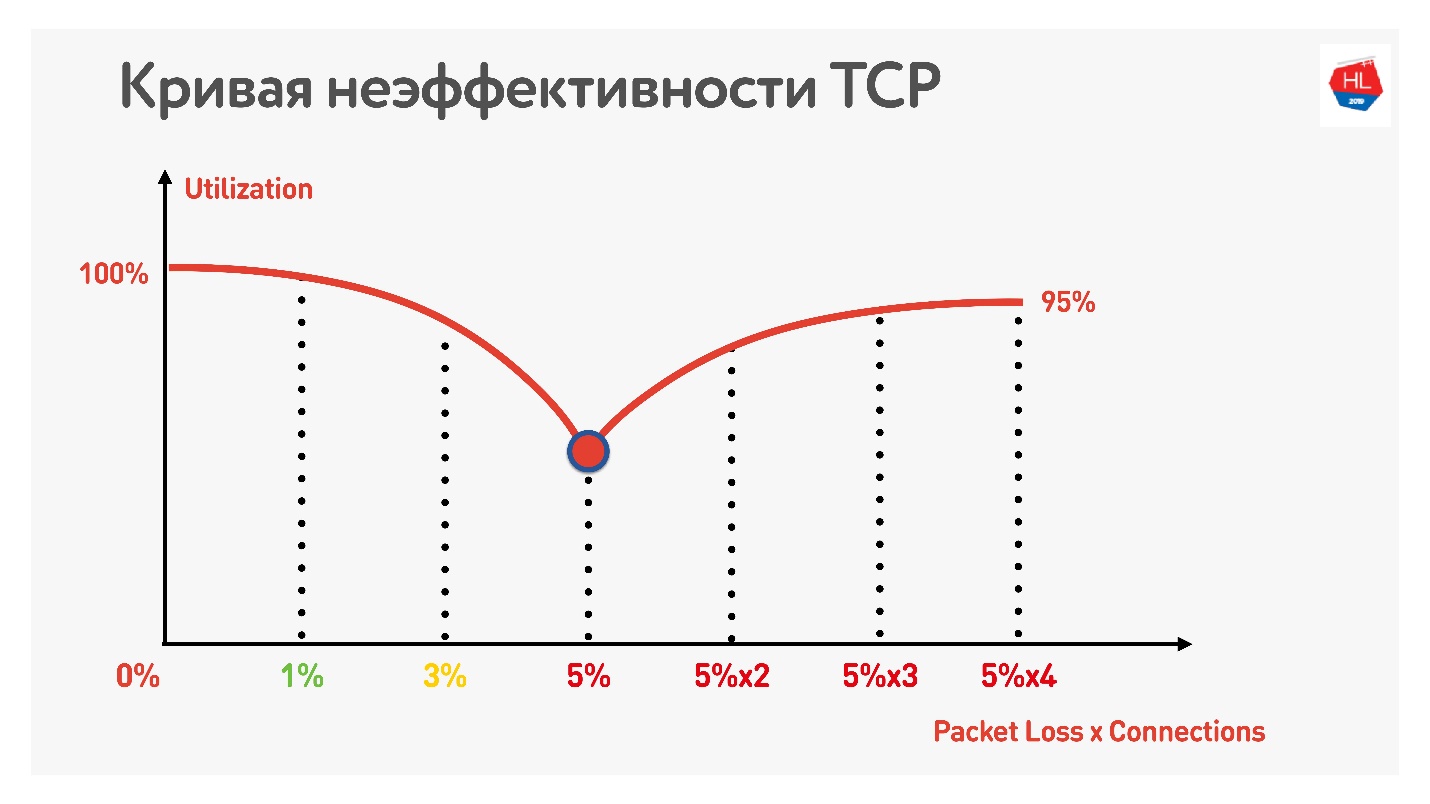
Con un aumento en el número de conexiones TCP paralelas, la utilización de la red se vuelve casi igual al rendimiento, menos el porcentaje de pérdidas.
Por lo tanto, resultó:
- Las redes móviles inalámbricas han ganado y son inestables.
- TCP no utiliza completamente el canal en redes inestables.
- El consumo de contenido depende de la velocidad de Internet: cuanto mayor es la velocidad de Internet, más usuarios ven, y amamos a nuestros usuarios y queremos que vean más.
Obviamente, debe mudarse a algún lugar y considerar alternativas al TCP.
TCP vs no TCP
¿Cómo comparar el calor? Hay dos opciones
La primera opción: en el nivel de IP hay TCP y UDP, podemos permitirnos algún otro protocolo desde arriba. Obviamente, si inicia su propio protocolo en paralelo con TCP y UDP, Firewall, Brandmauer, enrutadores y el resto del mundo involucrado en la entrega de paquetes no lo sabrán. Como resultado, tendrá que esperar durante años cuando todo el equipo se actualice y comience a funcionar con el nuevo protocolo.
La segunda opción es hacer su propio protocolo de entrega de datos confiable además de UDP no confiable. Obviamente, puede esperar mucho tiempo hasta que Linux, Android e iOS agreguen un nuevo protocolo a su kernel, por lo que debe cortar el protocolo en el espacio de usuario.
Esta solución parece interesante, la llamaremos protocolo UDP hecho a sí mismo. Para comenzar a desarrollarlo, no necesita nada especial: simplemente abra el socket UDP y envíe los datos.
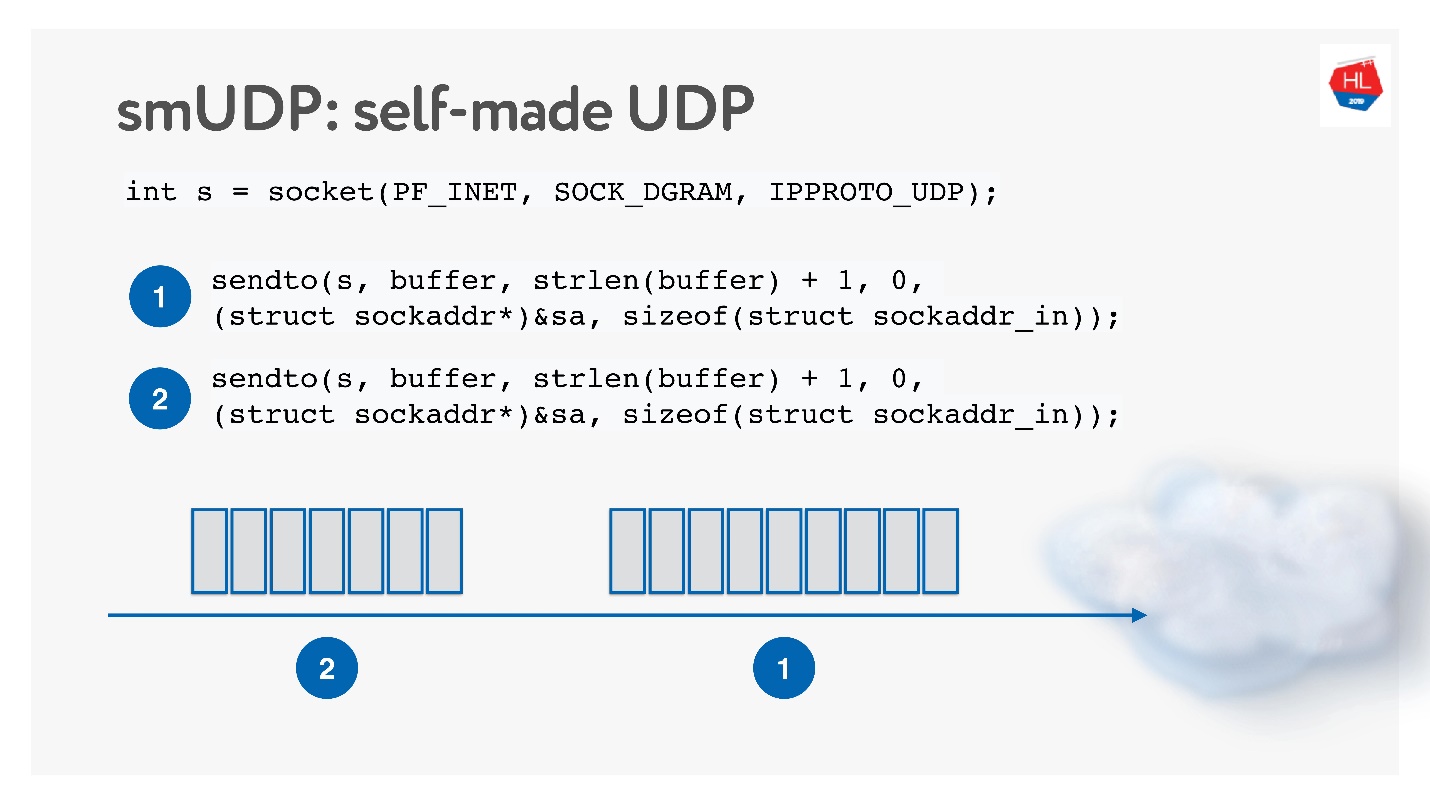
Lo desarrollaremos mientras estudiamos cómo funciona la red.
TCP vs UDP hecho a sí mismo
¿Y en qué comparar?
Las redes son diferentes:
- Con congestión, cuando hay muchos paquetes y algunos de ellos caen debido a la congestión de canales o equipos.
- Alta velocidad con gran ida y vuelta (por ejemplo, cuando el servidor está relativamente lejos).
- Extraño: cuando nada parece estar sucediendo en la red, pero los paquetes aún desaparecen simplemente porque el punto de acceso Wi-Fi está detrás de la pared.
Siempre puede tocar los perfiles de red usted mismo: seleccione uno u otro perfil en su teléfono y ejecute la Prueba de velocidad.

Además de los perfiles de red, también debe determinar el perfil de consumo de tráfico. Aquí están los que usamos:
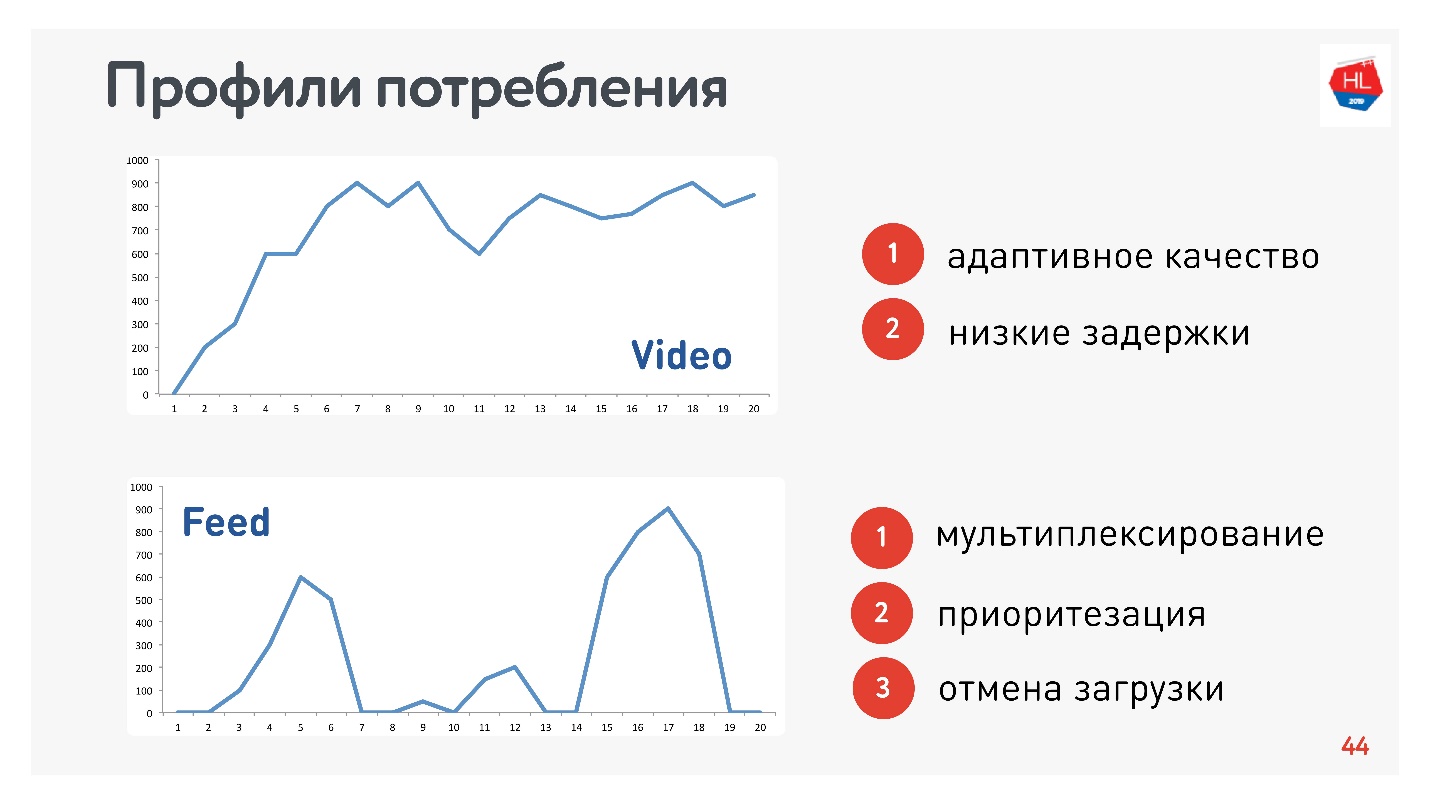
Como soy responsable del video y la transmisión, los perfiles son apropiados:
- Video de perfil, cuando se conecta y transmite este o aquel contenido. La velocidad de conexión aumenta, como en el gráfico superior. Requisitos para este protocolo: baja latencia y adaptación de velocidad de bits.
- Opción de vista de cinta: carga de datos por impulso, consultas en segundo plano, tiempo de inactividad. Requisitos para este protocolo: los datos recibidos se multiplexan y priorizan, la prioridad del contenido del usuario es mayor que los procesos en segundo plano, hay una cancelación de la descarga.
Por supuesto, debe comparar los protocolos en el HTTP más popular.
HTTP 1.1 y HTTP 2.0
La pila estándar de la década de 2000 se parecía a HTTP 1.1 sobre SSL. La pila moderna es HTTP 2.0, TLS 1.3 y todo encima de TCP.
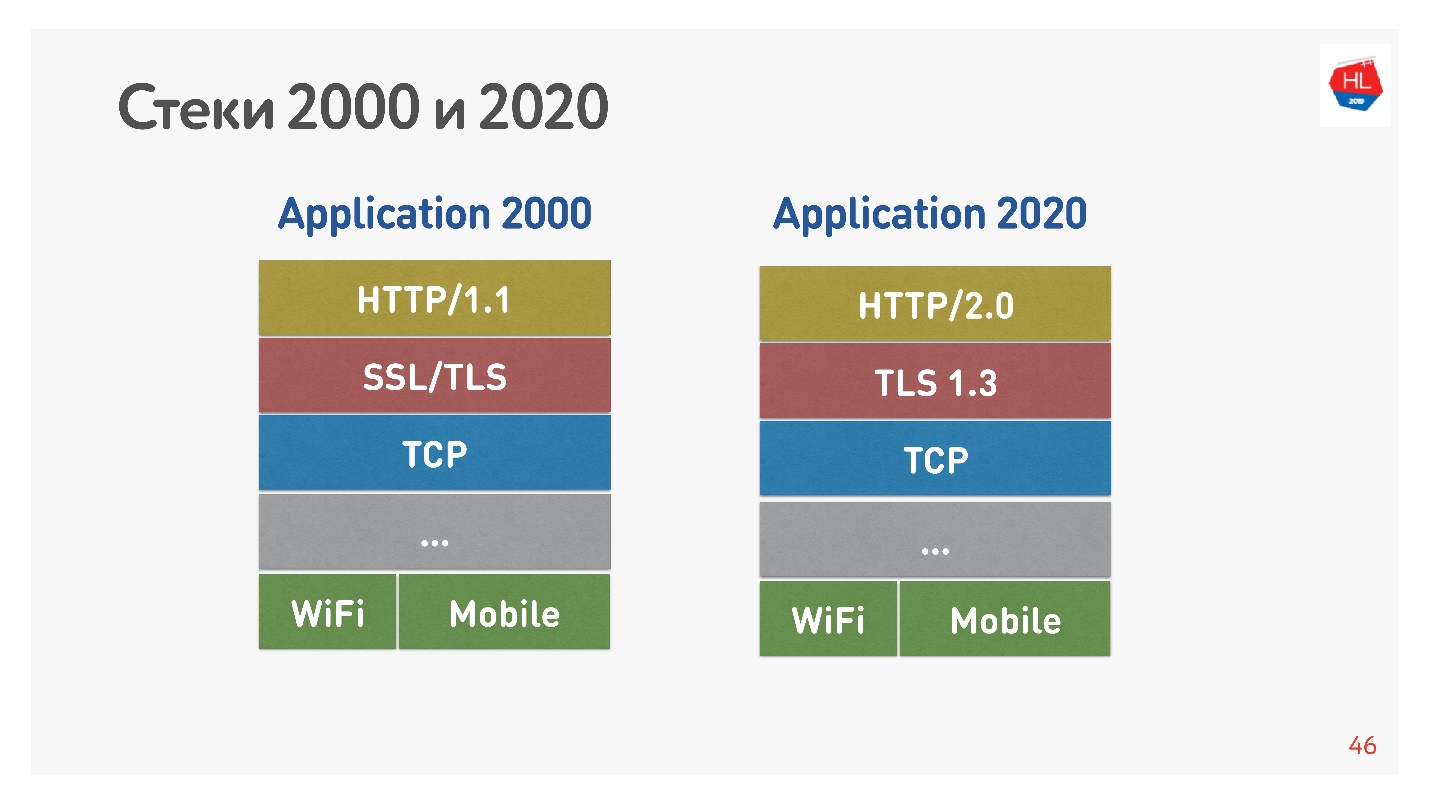
La principal diferencia es que HTTP 1.1 utiliza un conjunto limitado de conexiones en el navegador a un dominio, por lo que crean un dominio separado para imágenes, datos, etc. HTTP 2.0 ofrece una conexión multiplexada en la que se transmiten todos estos datos.
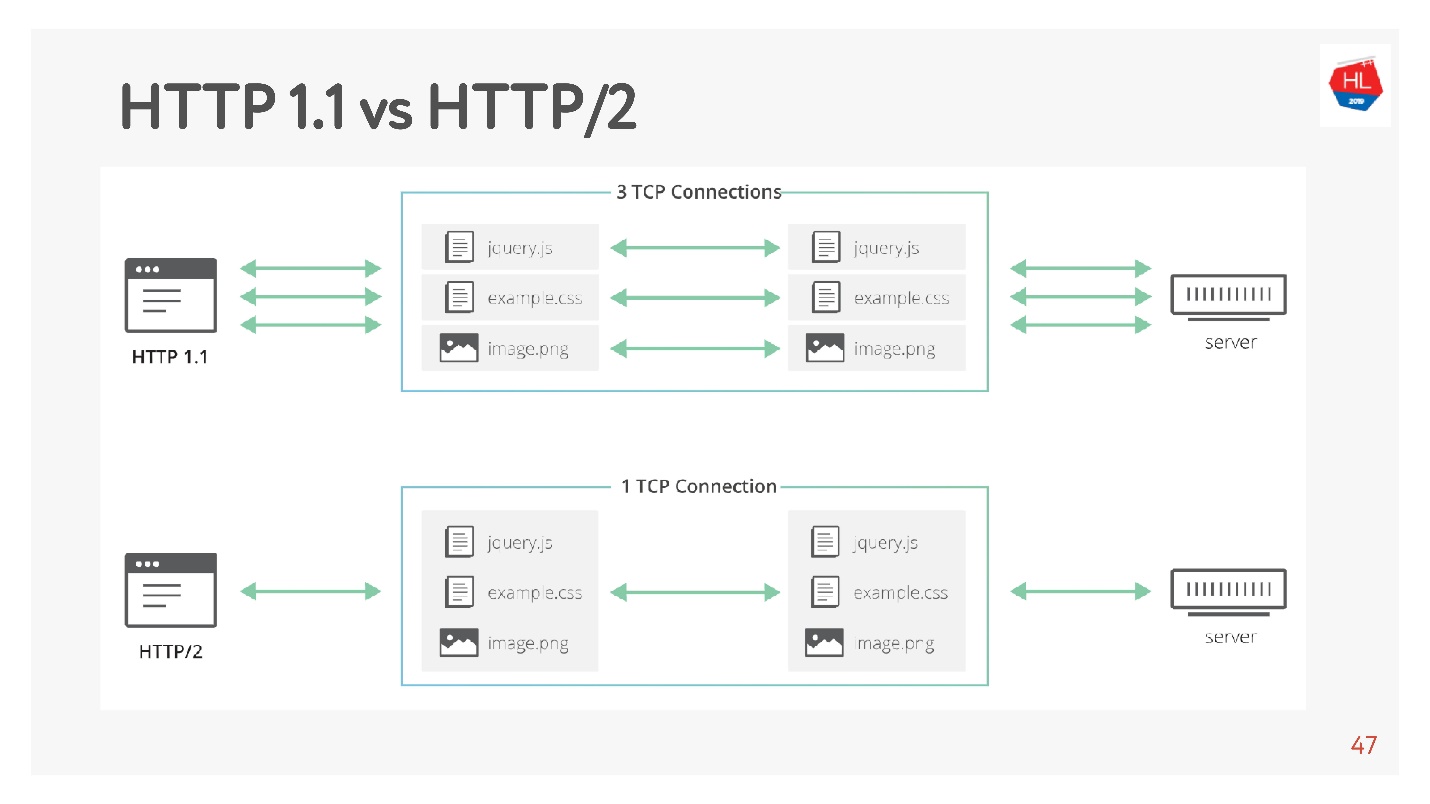
HTTP 1.1 funciona así: hacer una solicitud, obtener datos, hacer una solicitud, obtener datos.
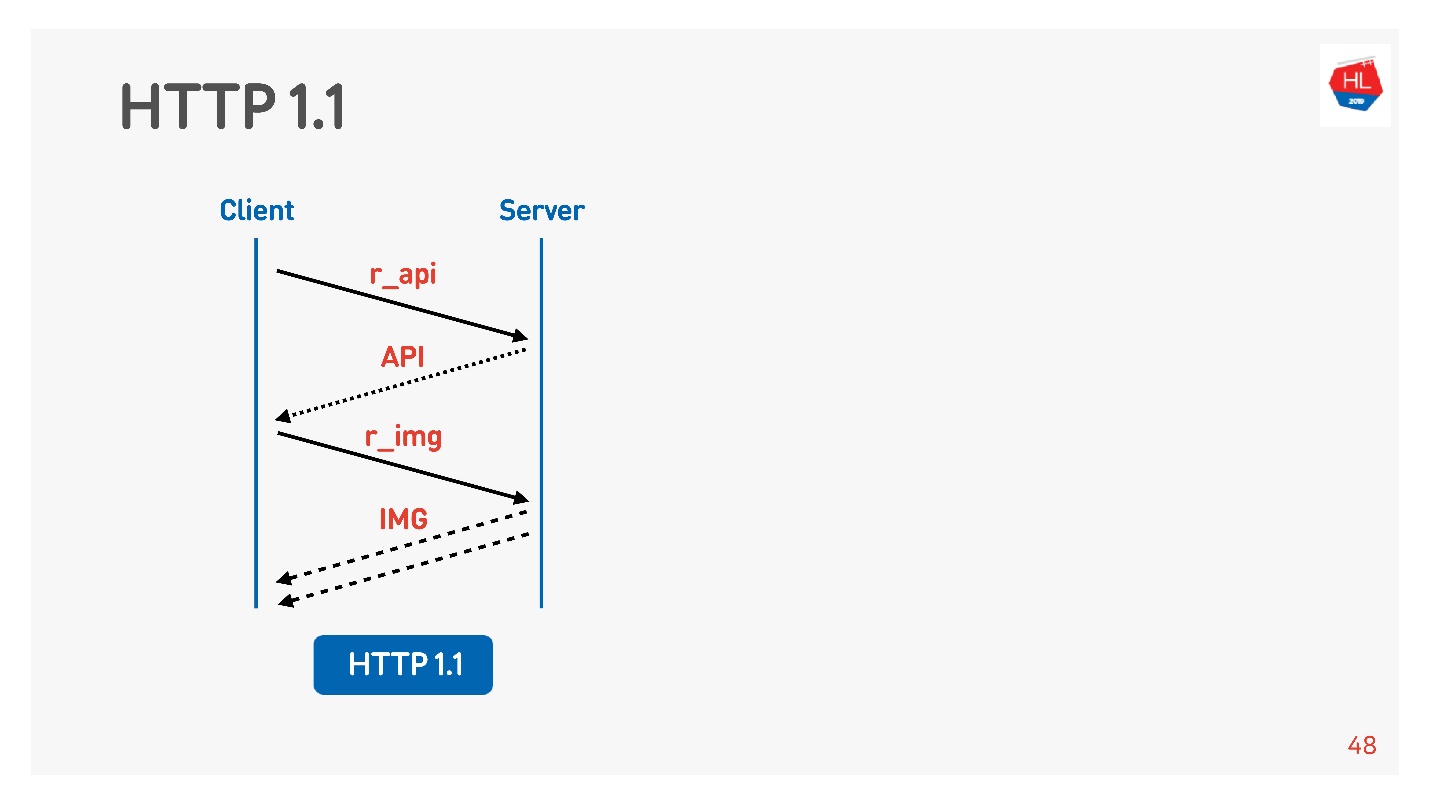
Por lo general, un navegador o una aplicación móvil lucha, es decir, una conexión para recibir imágenes, datos por API, y simultáneamente ejecuta una solicitud de una imagen, una API, un video, etc.
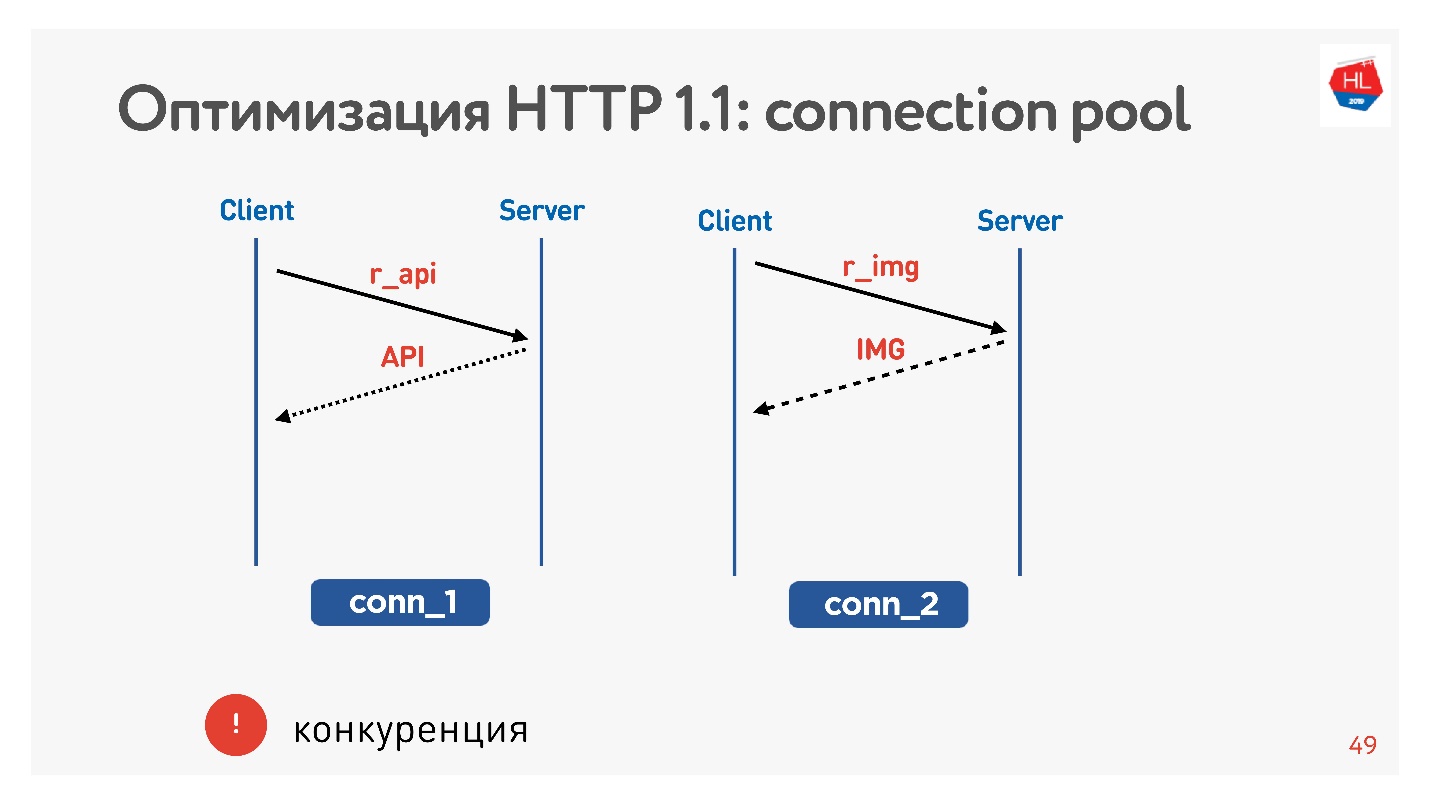
El principal problema es la competencia. No tiene control sobre las solicitudes enviadas. Usted comprende que el usuario ya no necesita la imagen que le dio la vuelta, pero no puede hacer nada.
Con HTTP 1.1, aún obtiene lo que solicitó, es difícil cancelar la descarga.
La única posibilidad de zócalo es cerrar la conexión. Luego veremos por qué esto es malo.
Diferencias en HTTP 2.0
HTTP 2.0 resuelve estos problemas:
- binario, compresión de encabezado;
- multiplexación de datos;
- priorización;
- cancelar la descarga;
- empuje del servidor
Consideremos más puntos importantes para nosotros.
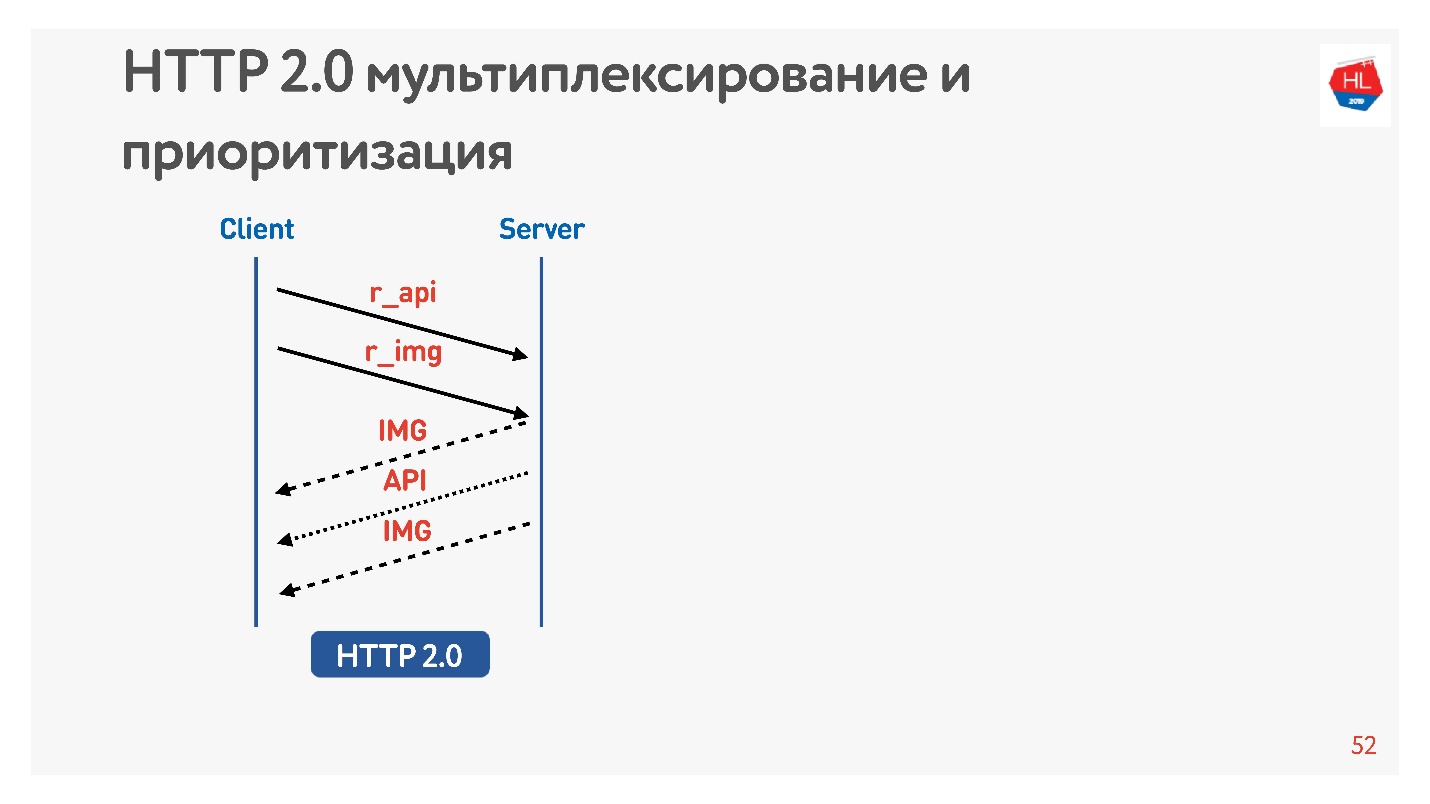
Solicite una foto y API. La imagen se da de inmediato, la API preparada después de un tiempo. Se proporcionó la API: la imagen se entregó hasta el final. Todo esto sucede de manera transparente.
El contenido de alta prioridad se descarga anteriormente.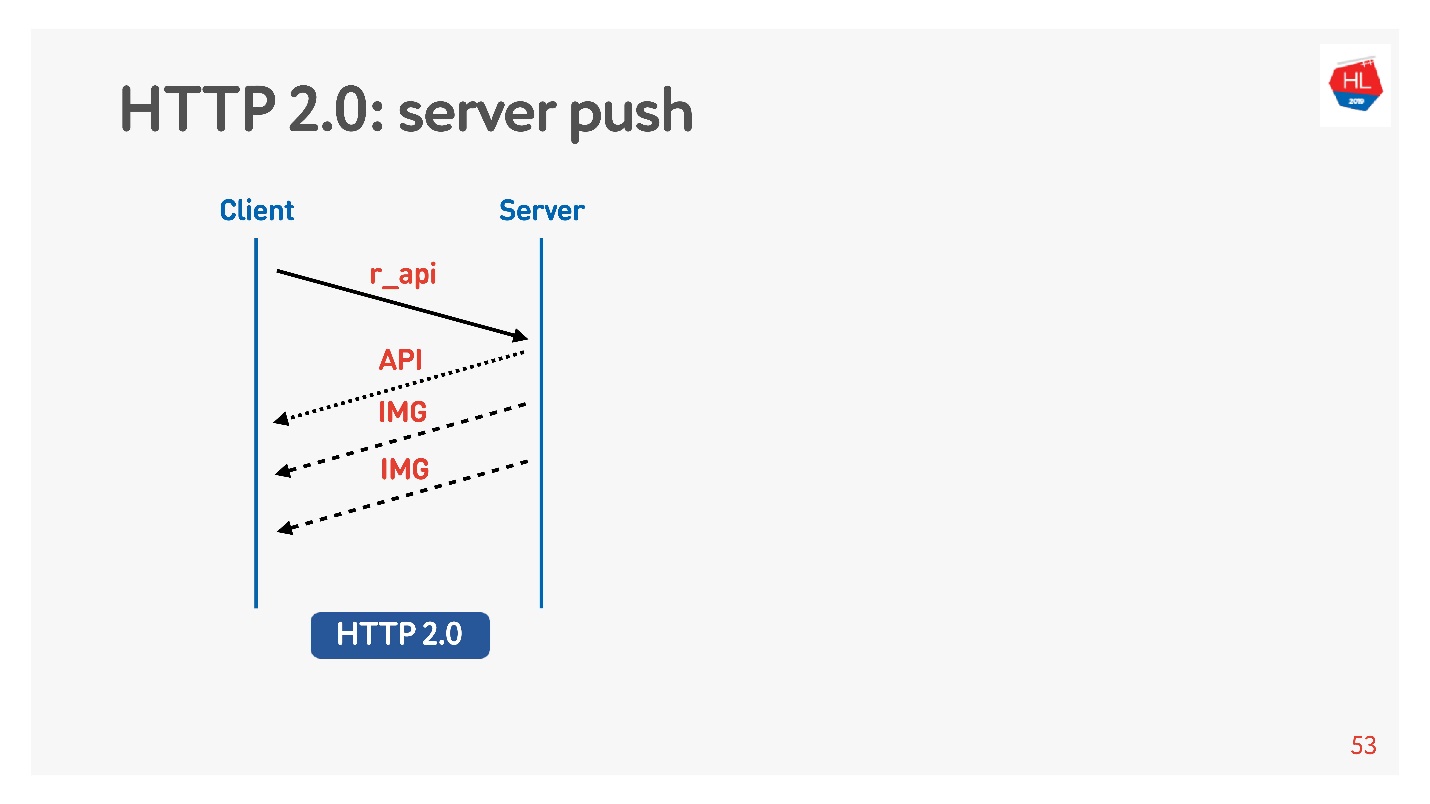 La inserción del servidor
La inserción del servidor es tal cuando solicitó algo específico como una API, pero incluso en la carga en el cliente se almacenaron en caché las imágenes que definitivamente serían necesarias para ver, por ejemplo, una cinta.
También hay un comando
Restablecer transmisión que el navegador se ejecuta solo si va entre páginas, etc. Para un cliente móvil, con su ayuda, puede negarse a recibir datos sin perder la conexión.
Por lo tanto, compararemos TCP en diferentes:
- Perfiles de red: Wi-Fi, 3G, LTE.
- Perfiles de consumo: transmisión (video), multiplexación y priorización con cancelación de la descarga (HTTP / 2) para recibir el contenido de la cinta.
Modelo sin pérdida
Comencemos la comparación con una red simple en la que solo hay dos parámetros: tiempo de ida y vuelta y ancho de banda.
RTT es ping, el tiempo de respuesta de un paquete, la recepción del acuse de recibo o el tiempo de eco de respuesta.
Para medir el
ancho de banda (
ancho de banda de la red), enviamos un paquete de paquetes y contamos el número de paquetes transmitidos en un determinado intervalo de tiempo.
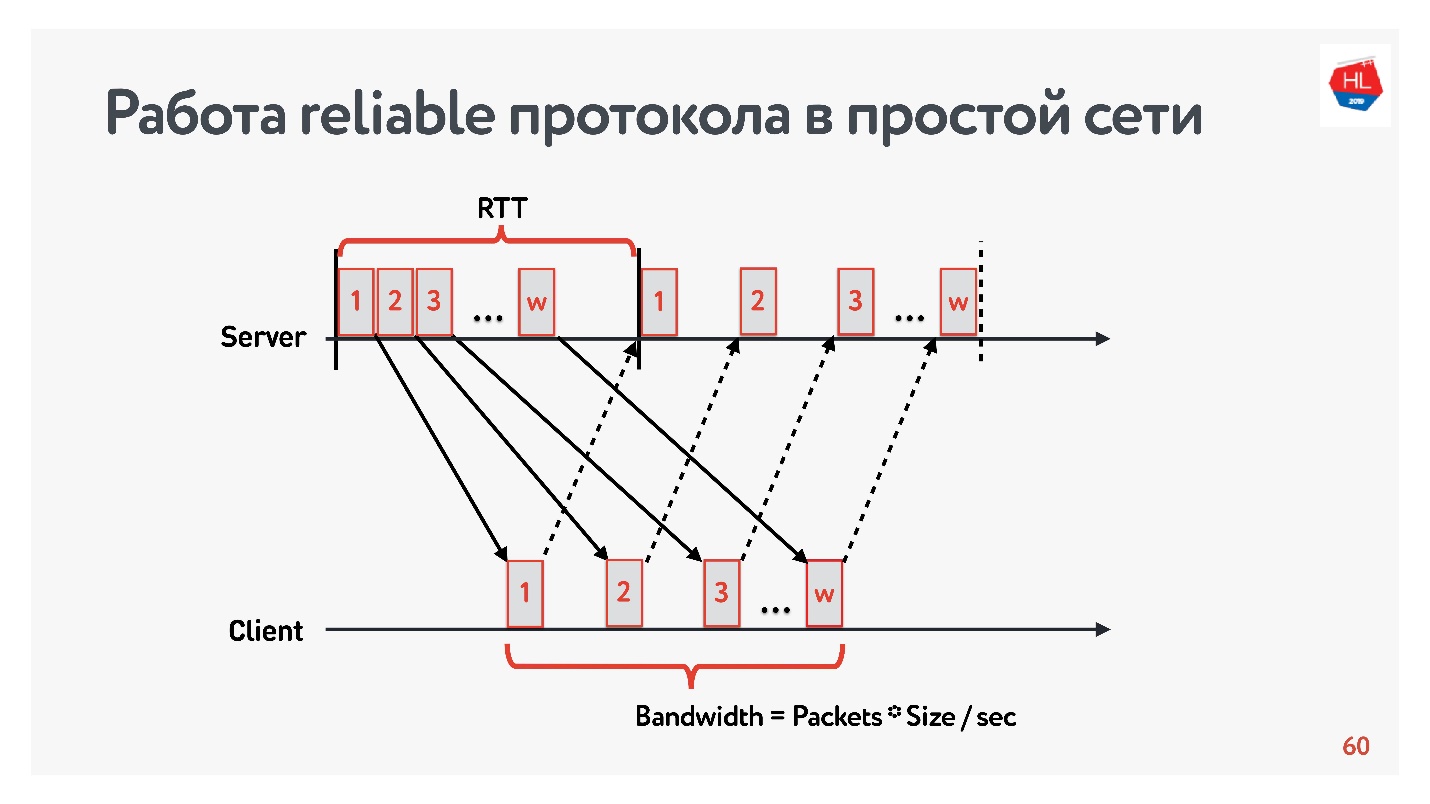
Como trabajamos con protocolos confiables, por supuesto, hay un acuse de recibo: enviamos paquetes y recibimos confirmación de recepción.
El problema de Internet lento
Al comienzo del desarrollo de nuestro servicio de video en 2013, mi amigo fue a California y decidió ver una nueva serie de su serie favorita en Odnoklassniki. Tenía un RTT de 250 ms, Wi-Fi perfecto a 400 Mbps en el campus de Google, quería ver la nueva serie en FullHD.
¿Crees que pudo ver el video? La respuesta depende de la configuración del búfer de envío / recepción en nuestros servidores.
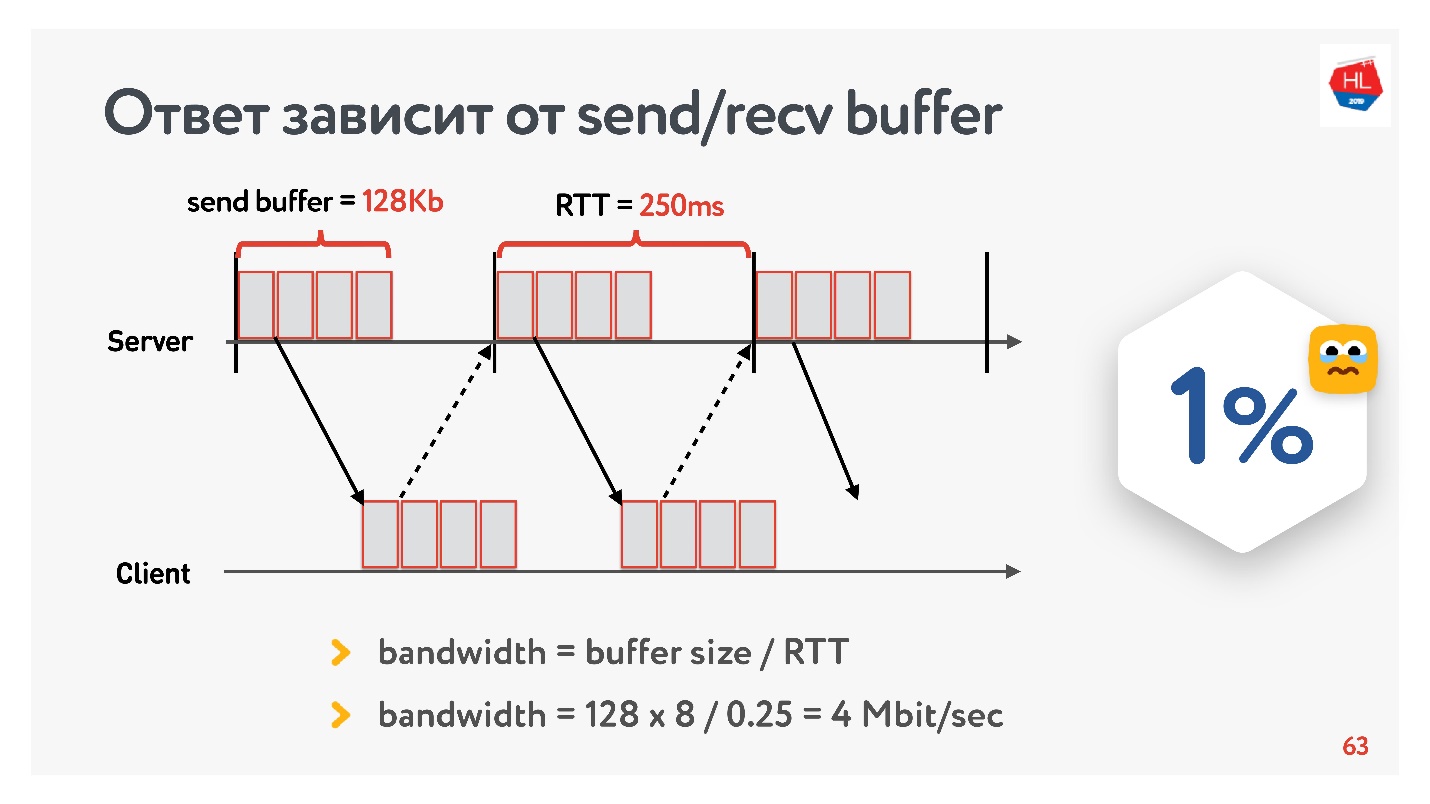
Como tenemos un protocolo con acuse de recibo, todos los datos que no recibieron una confirmación de entrega se almacenan en un búfer. Si el búfer de envío está limitado a 128 Kb, entonces estos 128 Kb son menores que para RTT, no podemos enviar. Por lo tanto, de nuestra red de 400 Mbit / s, quedan 4 Mbit / s. Esto no es suficiente para ver videos en línea en FullHD.
Luego saqué el tamaño del búfer y miré cómo la velocidad de salida de un segmento de video realmente cambia dependiendo del cambio en el tamaño del búfer. Inmediatamente haga una reserva de que el búfer de recepción se ajustó automáticamente, es decir lo que envió el servidor, el cliente siempre pudo aceptar.

Una receta TCP obvia: si transmite datos de alta velocidad a largas distancias, debe aumentar el búfer de envío.
Todo parece estar bien. Puede ir al servicio fast.com, que mide la velocidad de su Internet a los servidores de Netflix. Desde la oficina obtuve una velocidad de 210 Mbps. Y luego, a través de net shaper, configuré las condiciones de la tarea y fui a este sitio nuevamente. Magia: obtuve 4 Mbps exactamente.
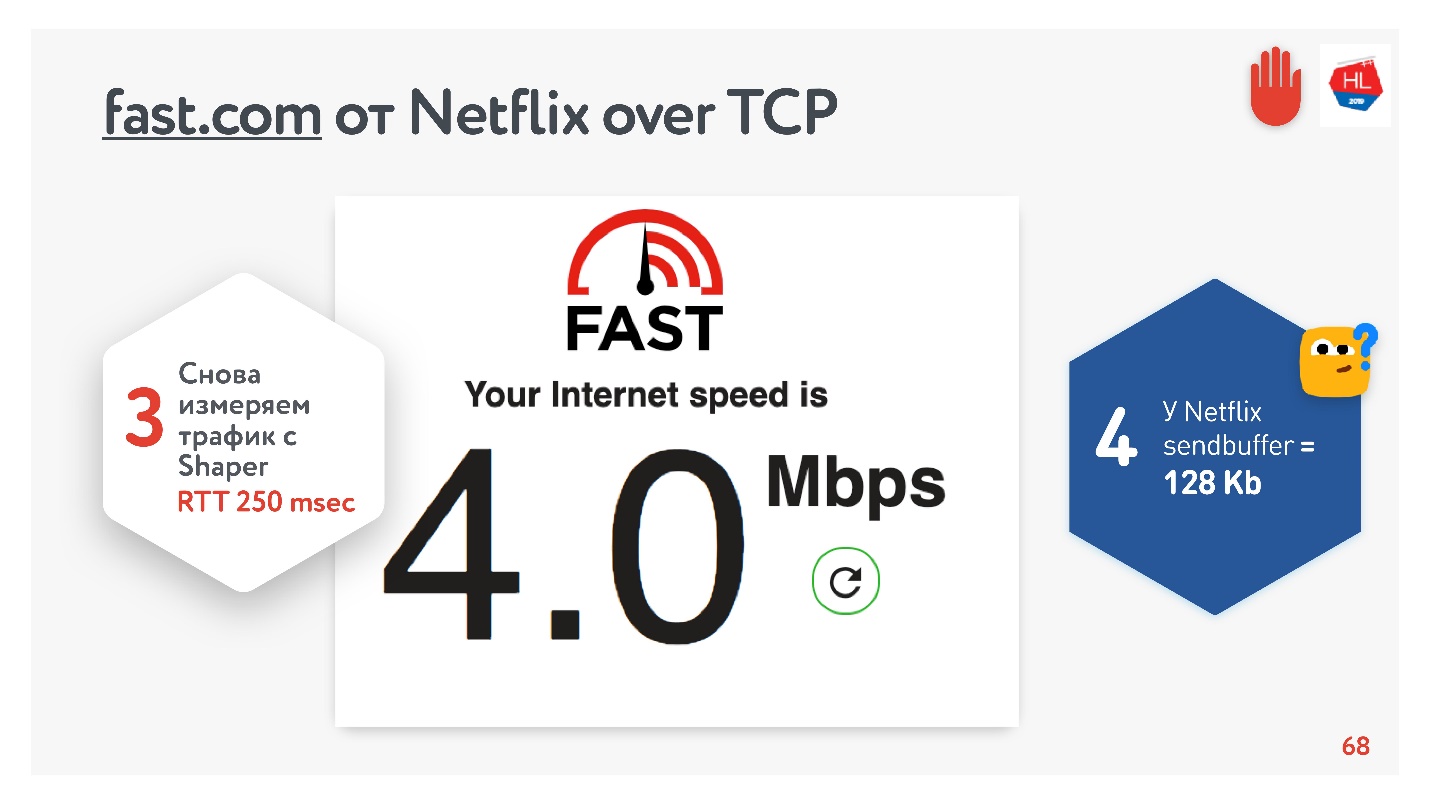
No importa cómo lo gire, Netflix no logró obtener un búfer de más de 128 KB.
Tampón
Para determinar el tamaño óptimo del búfer, debe comprender qué son los paquetes sobre la marcha.
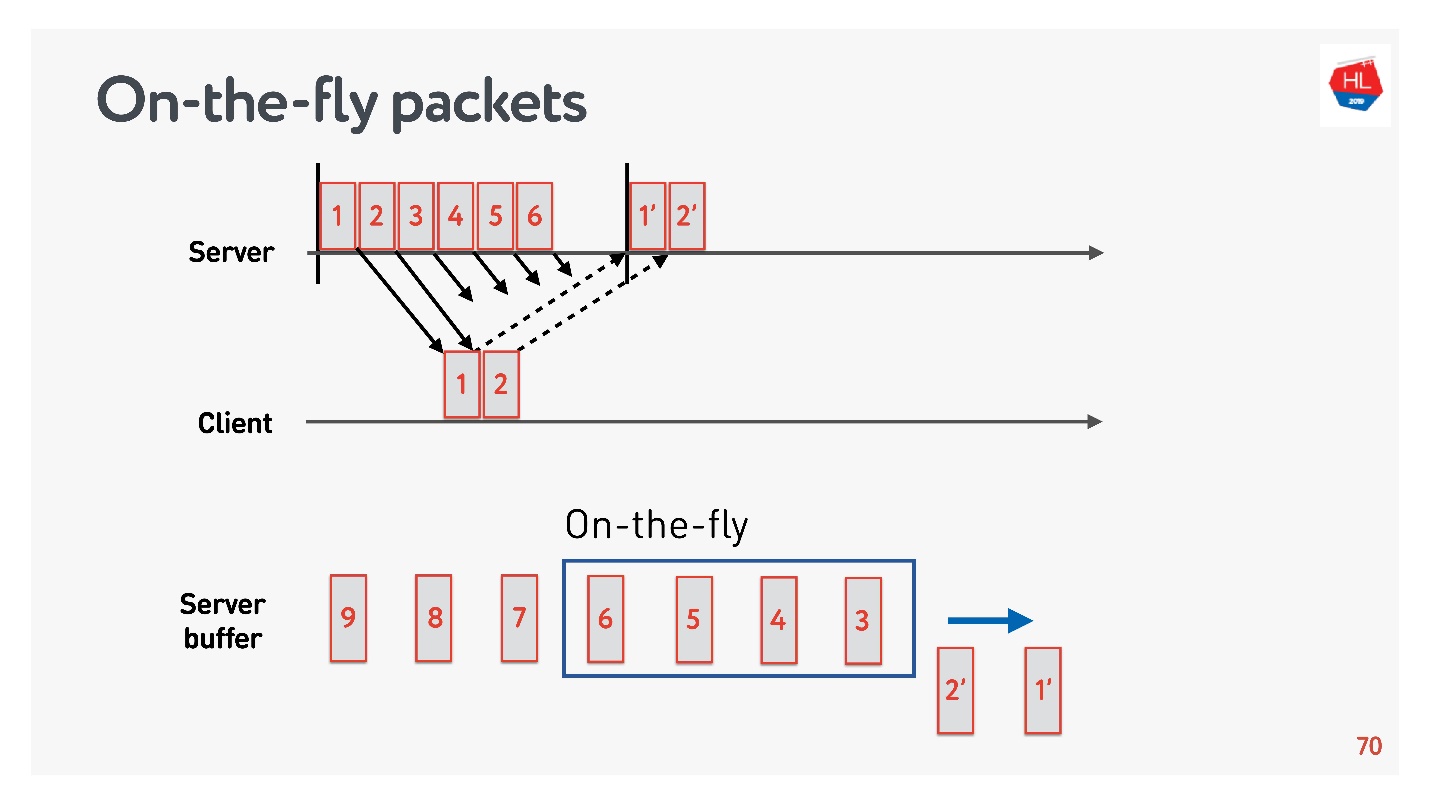
Hay un estado de red:
- los paquetes 1 y 2 ya se han enviado, se ha recibido una confirmación para ellos;
- se enviaron los paquetes 3, 4, 5, 6, pero se desconoce el resultado de la entrega (paquetes sobre la marcha);
- otros paquetes están en la cola.
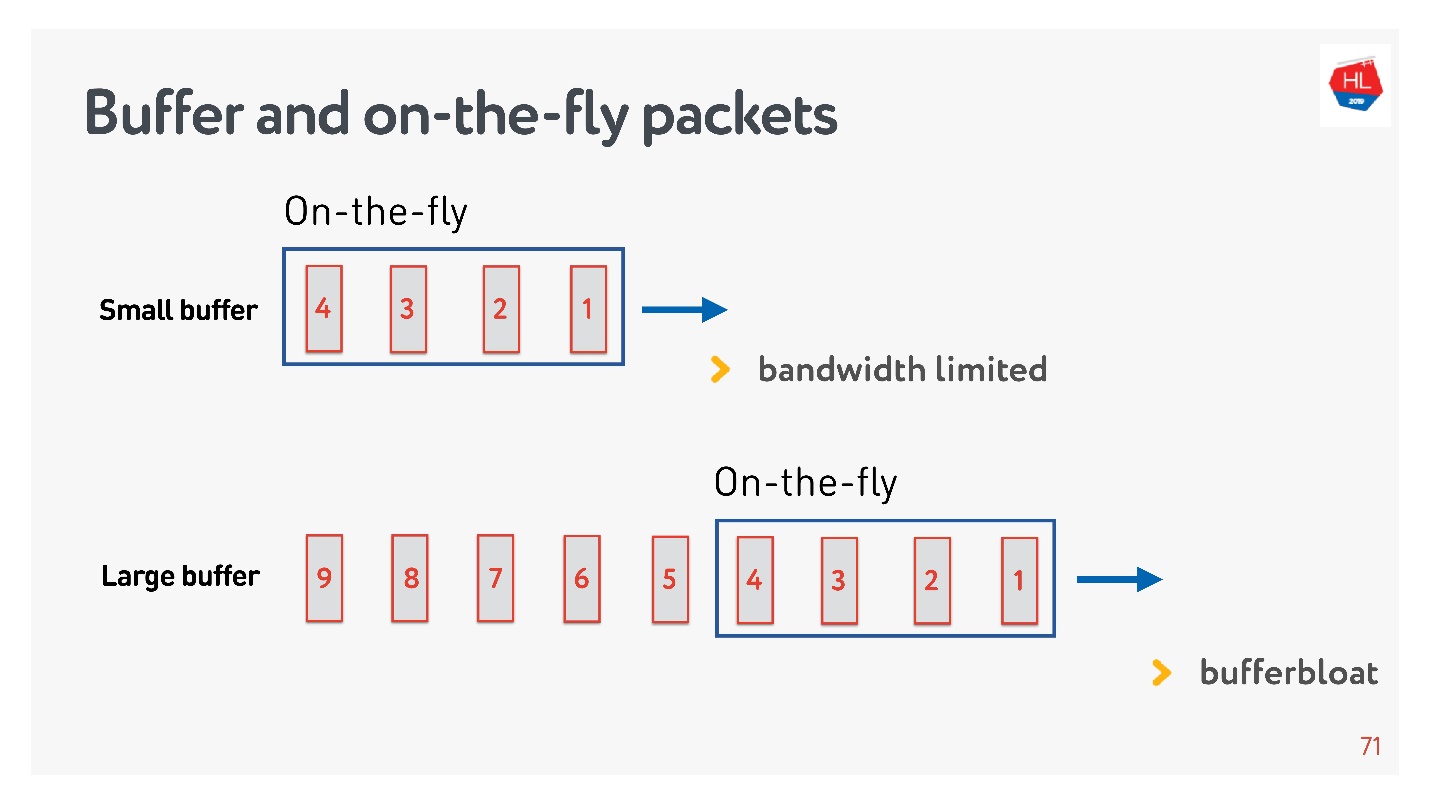
Si el número de paquetes en la marcha es igual al tamaño del búfer, entonces no es lo suficientemente grande. En este caso, la red está muriendo de hambre, no totalmente utilizada.
La situación inversa es posible: el búfer es demasiado grande. En este caso, el búfer se hincha. ¿Por qué es esto malo?

Si hablamos de multiplexación de datos y enviamos varias solicitudes al mismo tiempo, por ejemplo, imágenes en la misma conexión y API, entonces, cuando toda la enorme imagen de megabytes entró en el búfer, e intentamos rellenar también la API de alta prioridad, el búfer se hincha. Tienes que esperar mucho tiempo cuando la imagen desaparece.
Una solución simple es ajustar automáticamente el tamaño del búfer. Ahora está disponible en muchos clientes y funciona de esta manera.
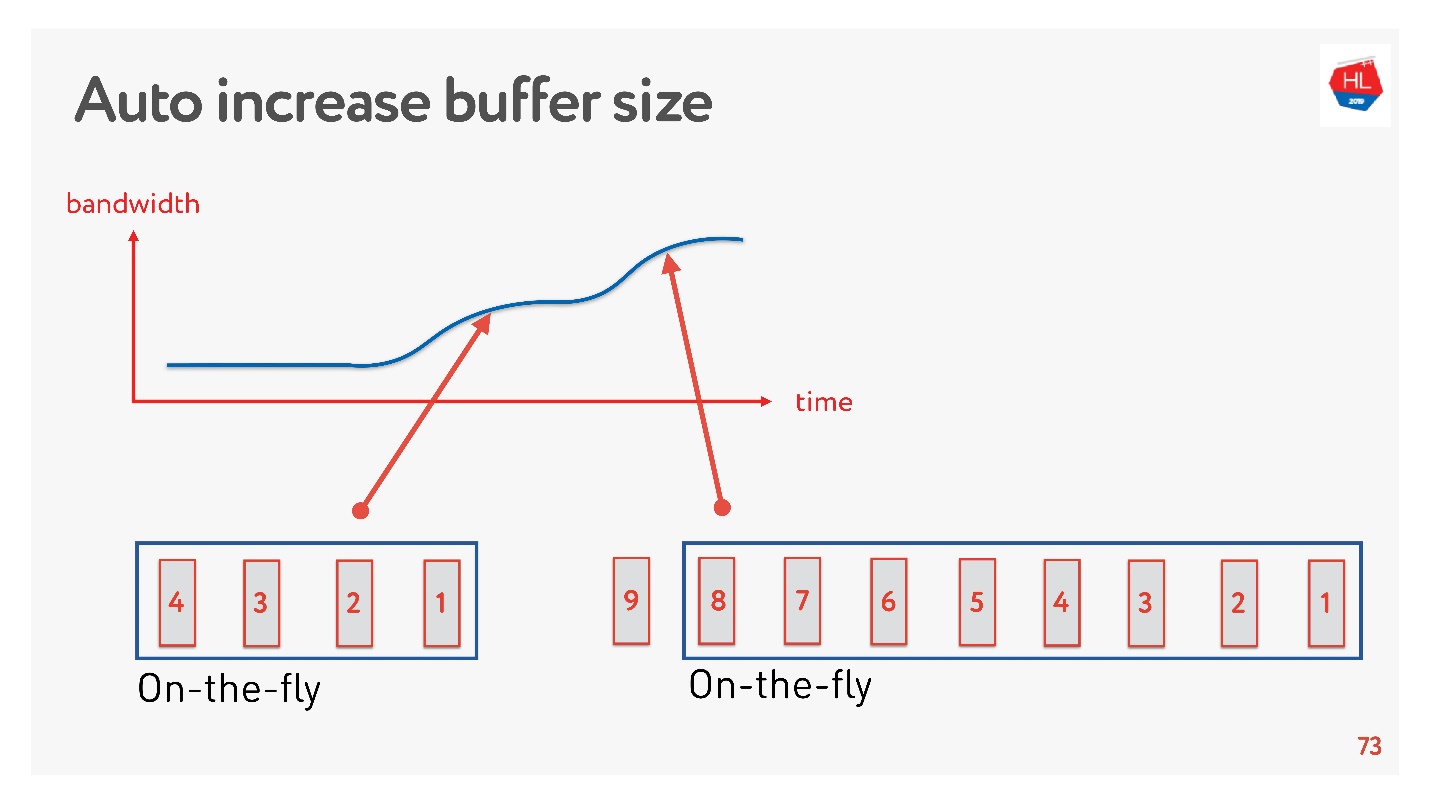
Si se pueden enviar muchos paquetes ahora, el búfer está aumentando, la transferencia de datos se está acelerando, el tamaño del búfer está creciendo, todo parece ser genial.
Pero hay un problema. Si el búfer ha aumentado, no se puede reducir tan fácilmente. Esta es una tarea más difícil. Si la velocidad disminuye, se produce la misma hinchazón del búfer. El búfer es bastante grande y está lleno, debemos esperar hasta que todos los datos se envíen al cliente.
Si escribimos nuestro propio protocolo UDP, entonces todo es muy simple: tenemos acceso al búfer.
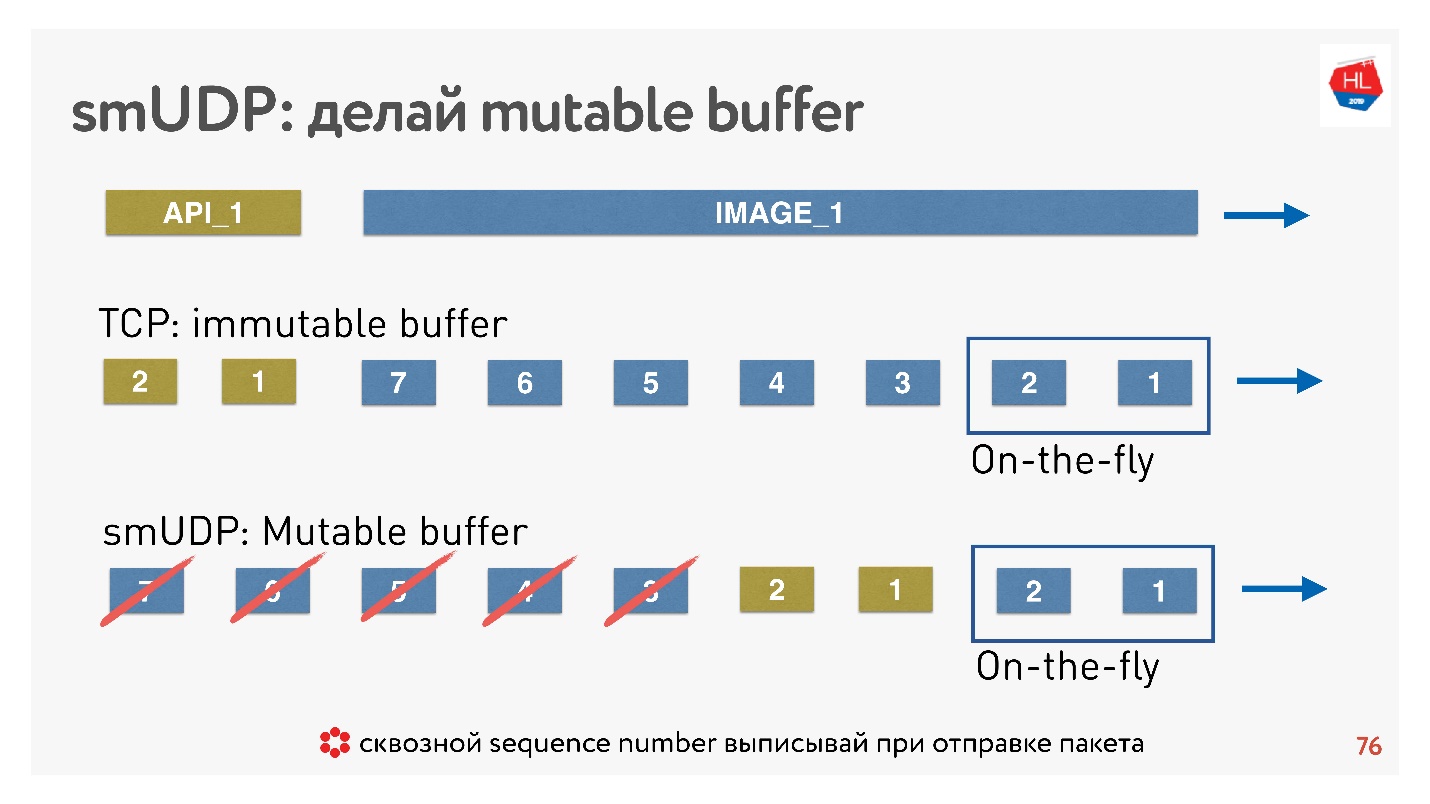
Si TCP en tales situaciones simplemente agrega datos hasta el final, y no puede hacer nada, entonces en un protocolo hecho a mano puede colocar datos, por ejemplo, hacia adelante, inmediatamente después de los paquetes sobre la marcha.
Y si viene cancelar, y el cliente dice que esta imagen ya no es necesaria, necesita los datos de la API, desplazó el contenido aún más, puede tirar todo esto del búfer y enviar la deseada.
¿Cómo se hace esto? Se sabe que para restaurar paquetes, gestionar la entrega, recibir acuses de recibo, necesita algún número de secuencia de paquetes. Sequence_id estamos escritos solo para paquetes sobre la marcha, es decir, lo emitimos solo cuando enviamos paquetes. Todo lo demás en el búfer se puede mover como queramos hasta que los paquetes desaparezcan.
Conclusión: el búfer TCP debe estar configurado correctamente, recuperar el equilibrio para no colindarse con la red y no inflar el búfer. Para su propio protocolo UDP, todo es simple: esto se puede controlar.
Modelo de red con pérdida
Pasamos a un nivel superior, la red se vuelve un poco más complicada, aparece la pérdida de paquetes. Para redes móviles, esta es una situación común. Algunos de los paquetes enviados no llegan al cliente. El algoritmo de recuperación de retransmisión estándar funciona más o menos así:
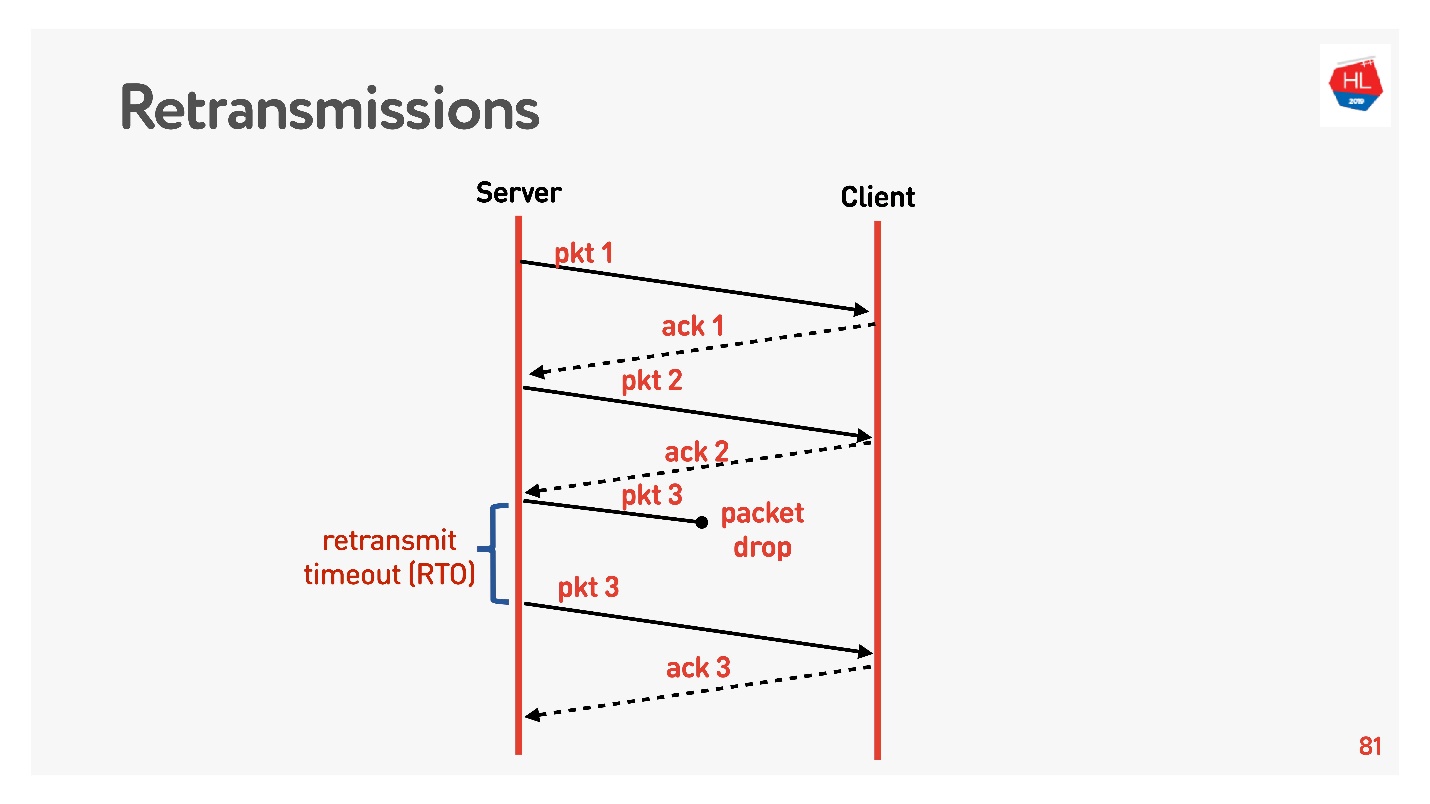
Envía paquetes, por cada paquete recibe acuse de recibo. Retransmit timeout (RTO) RTT , .
TCP, 5% , 50%.
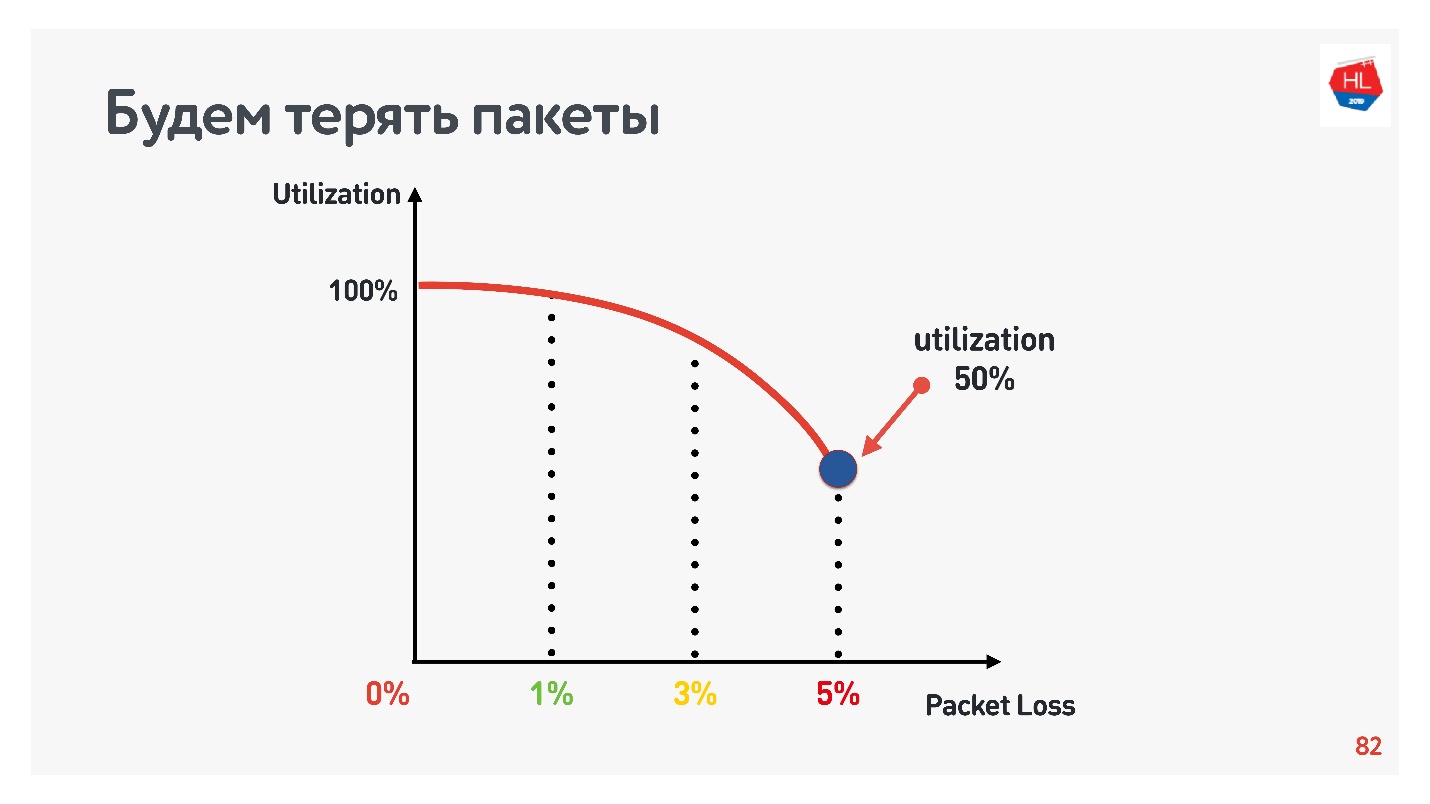
retransmit, , . , , Congestion control.
Congestion control
flow control, .
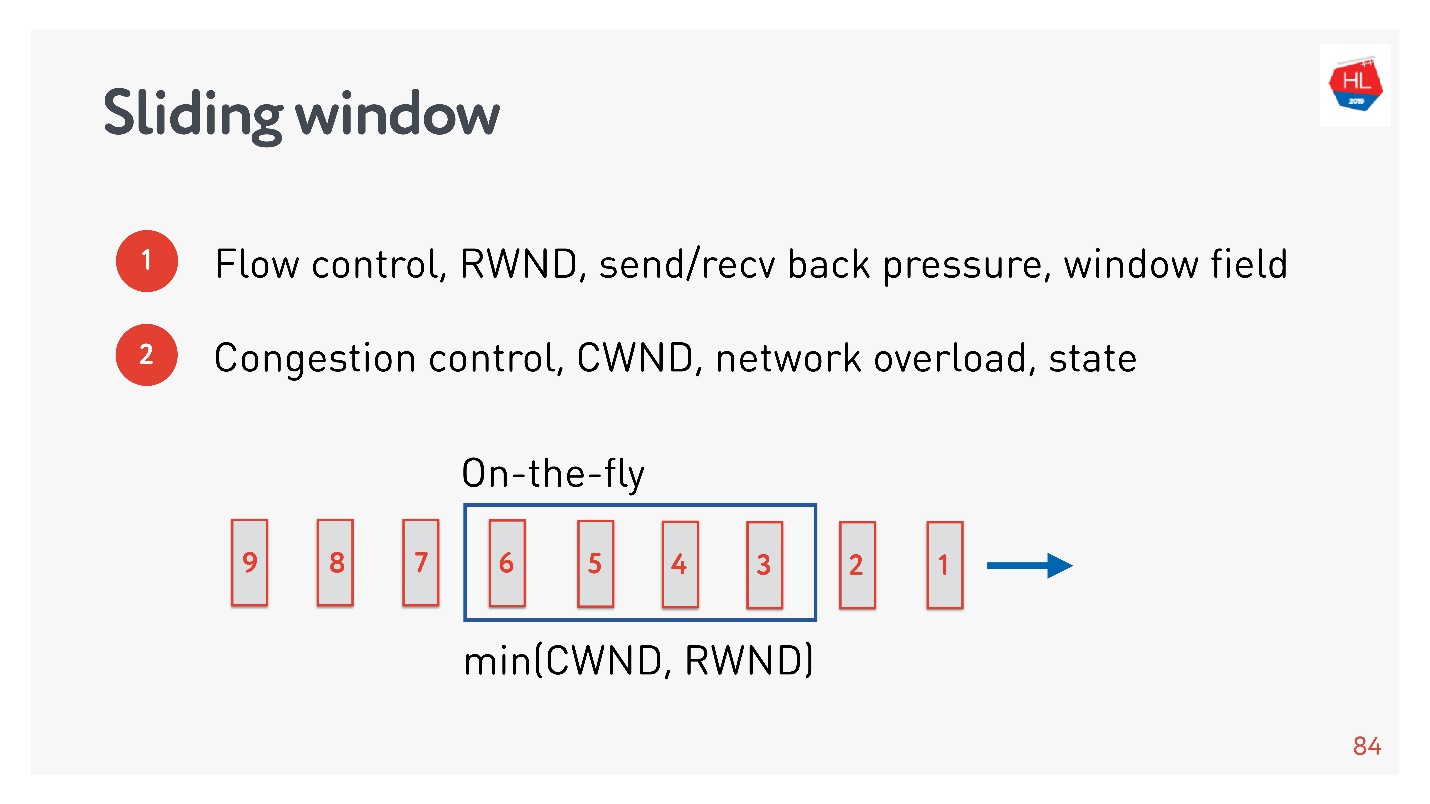
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
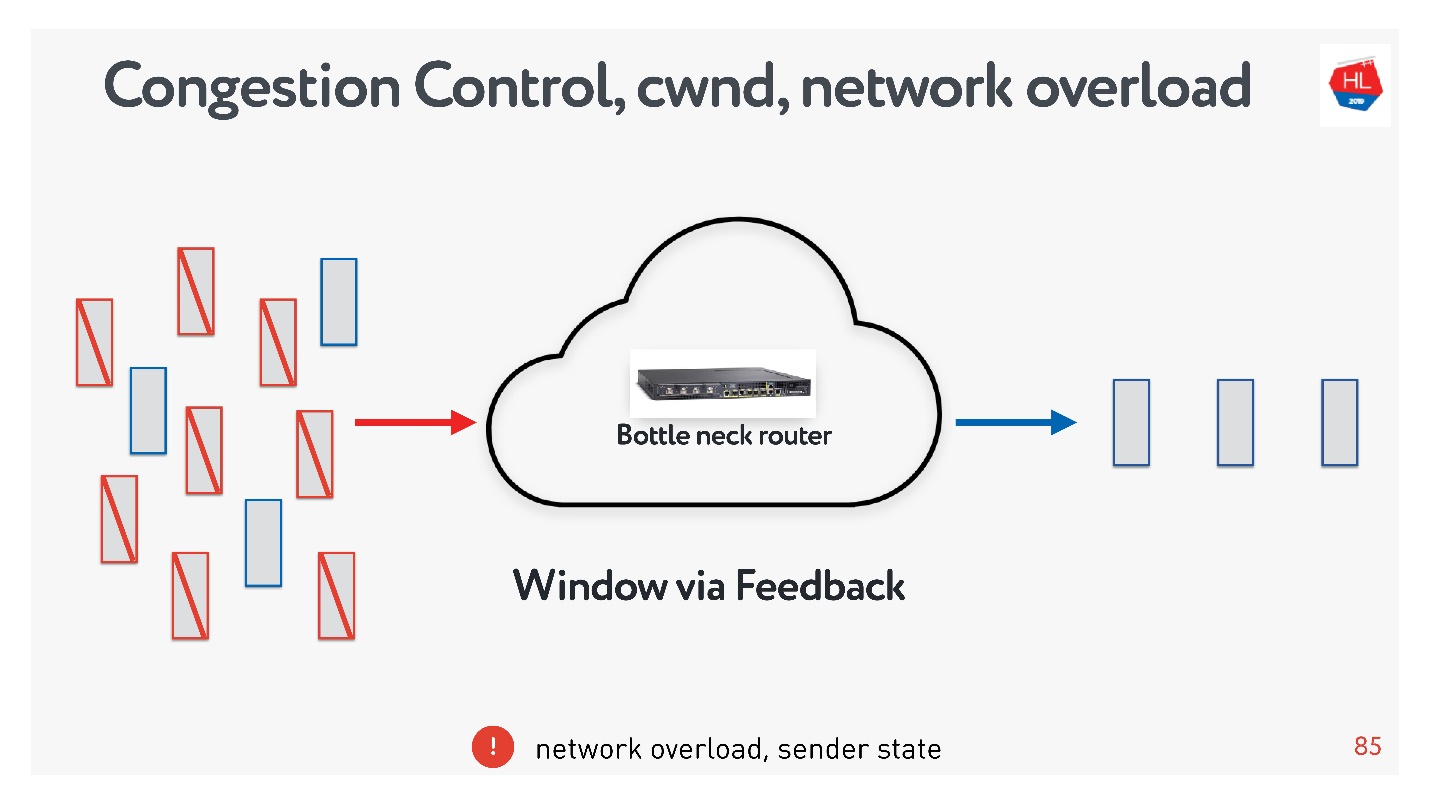
, : , , , . , congestion control.
TCP window.
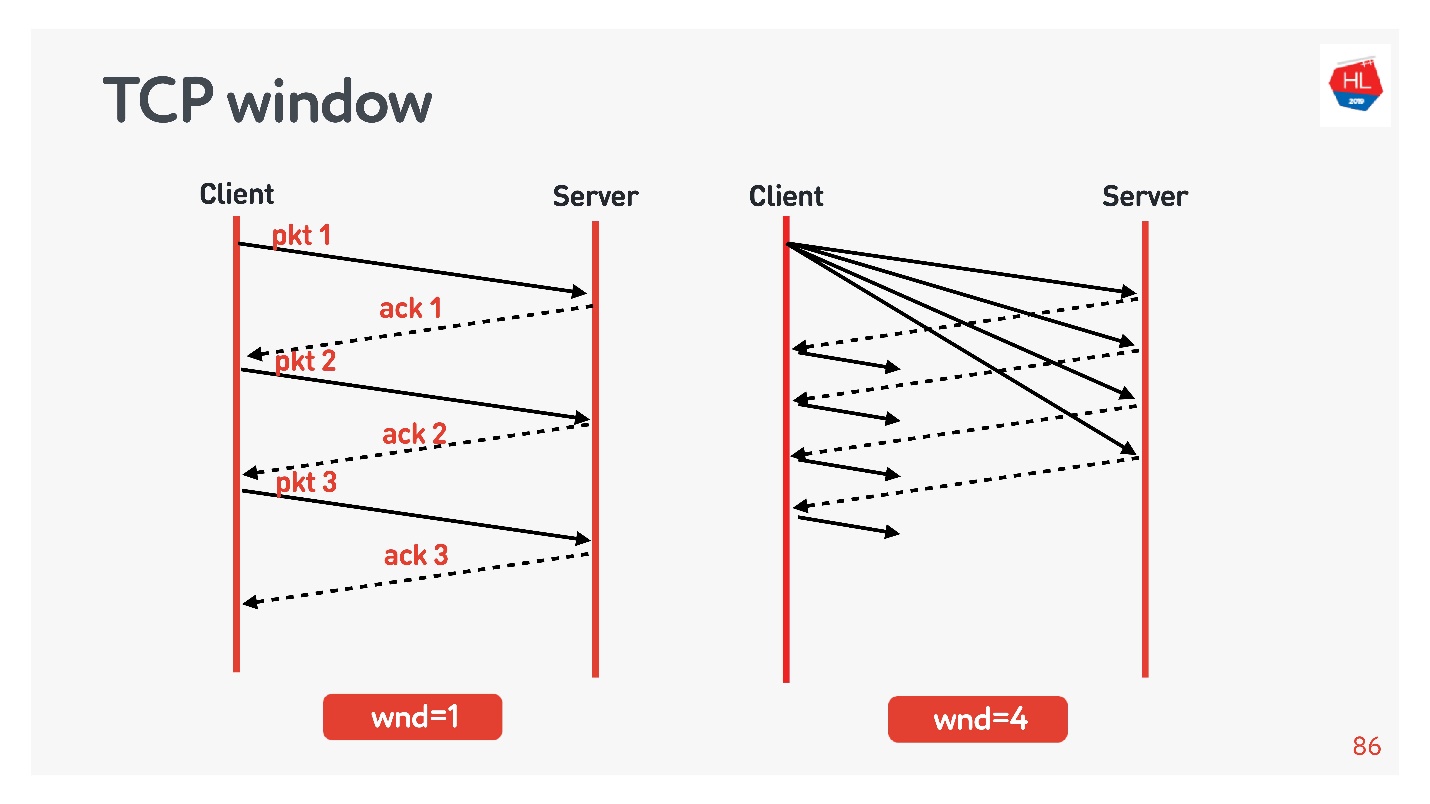
flow control congestion control, .
Ejemplos:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
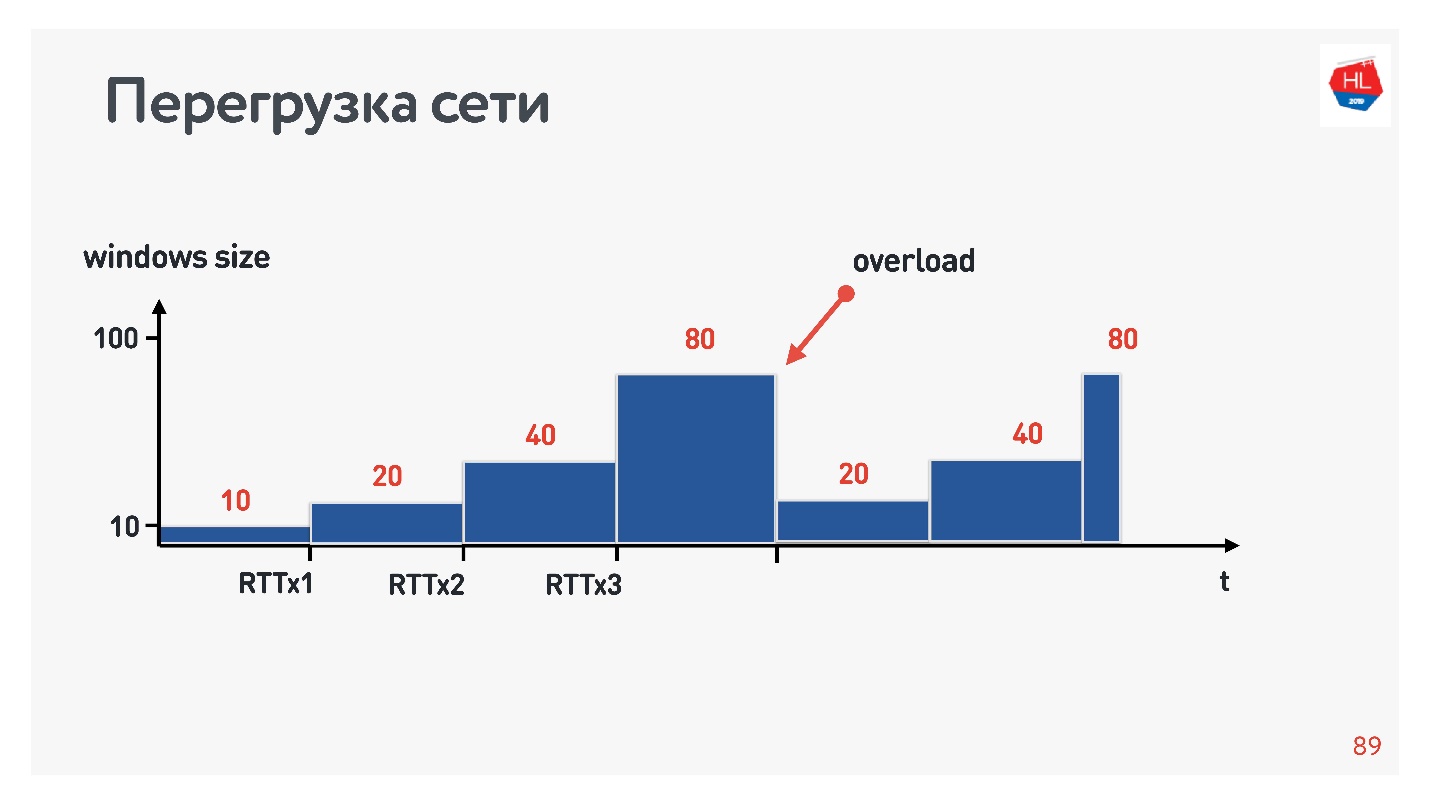
, , .
?
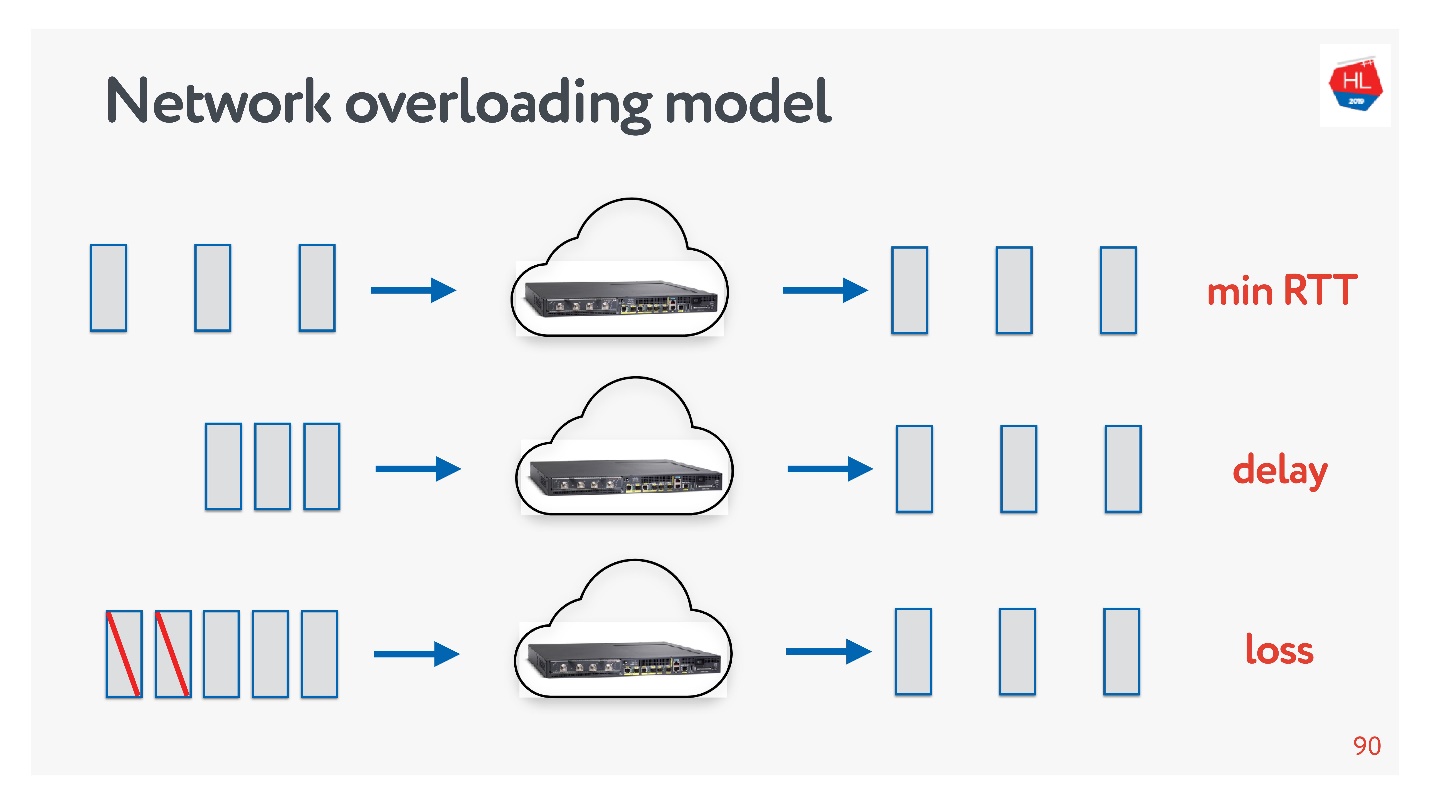
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
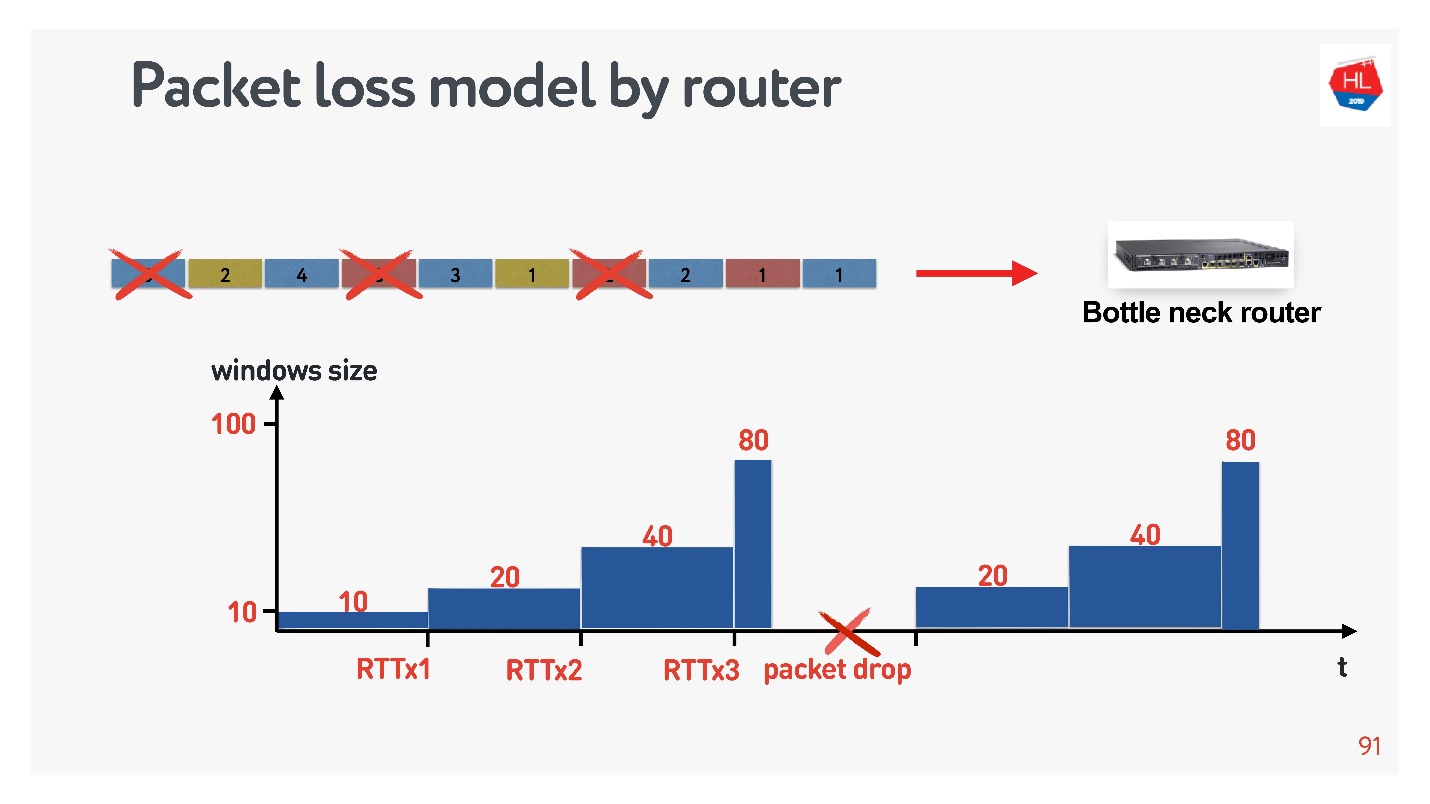
, , . : , .. , . congestion control, TCP window, , .
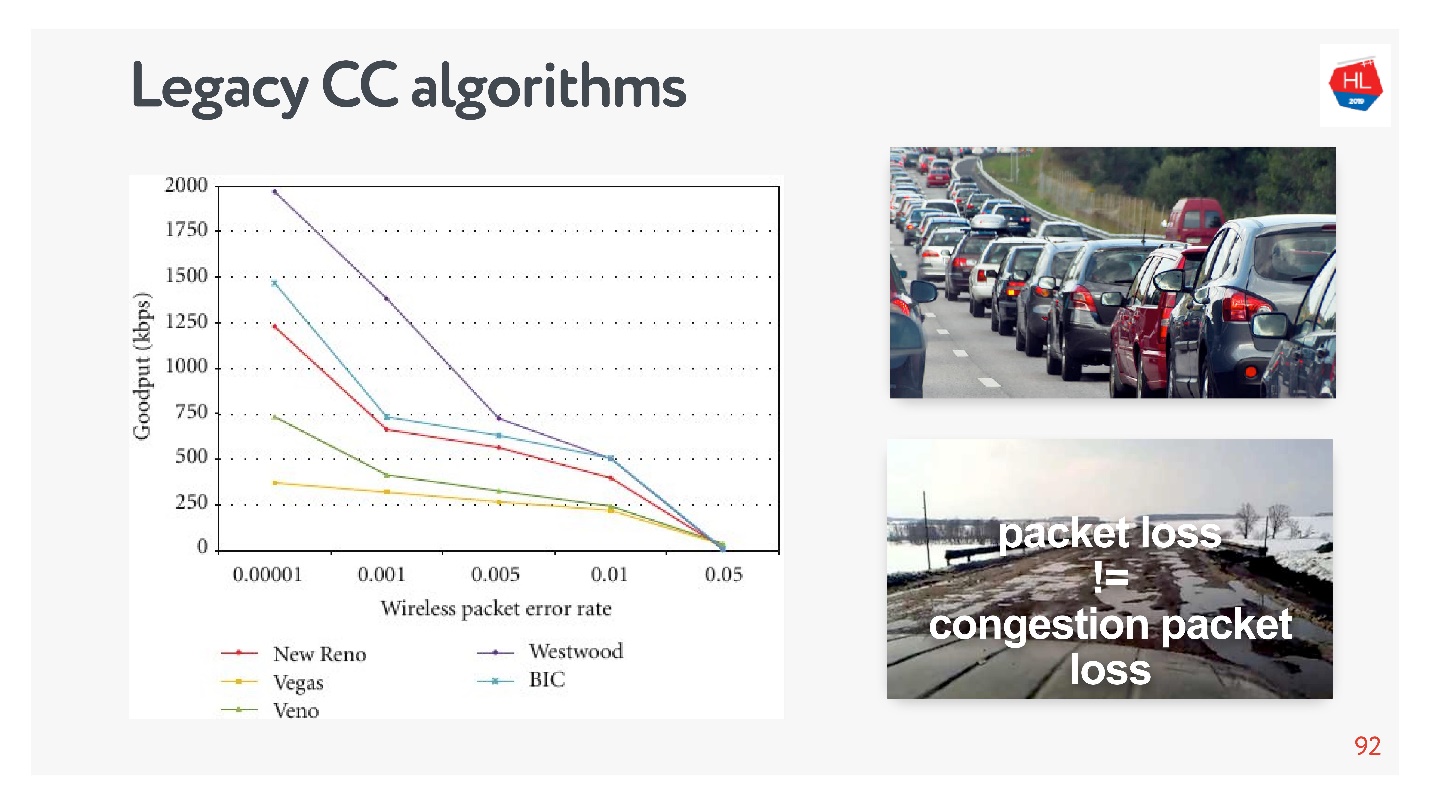
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
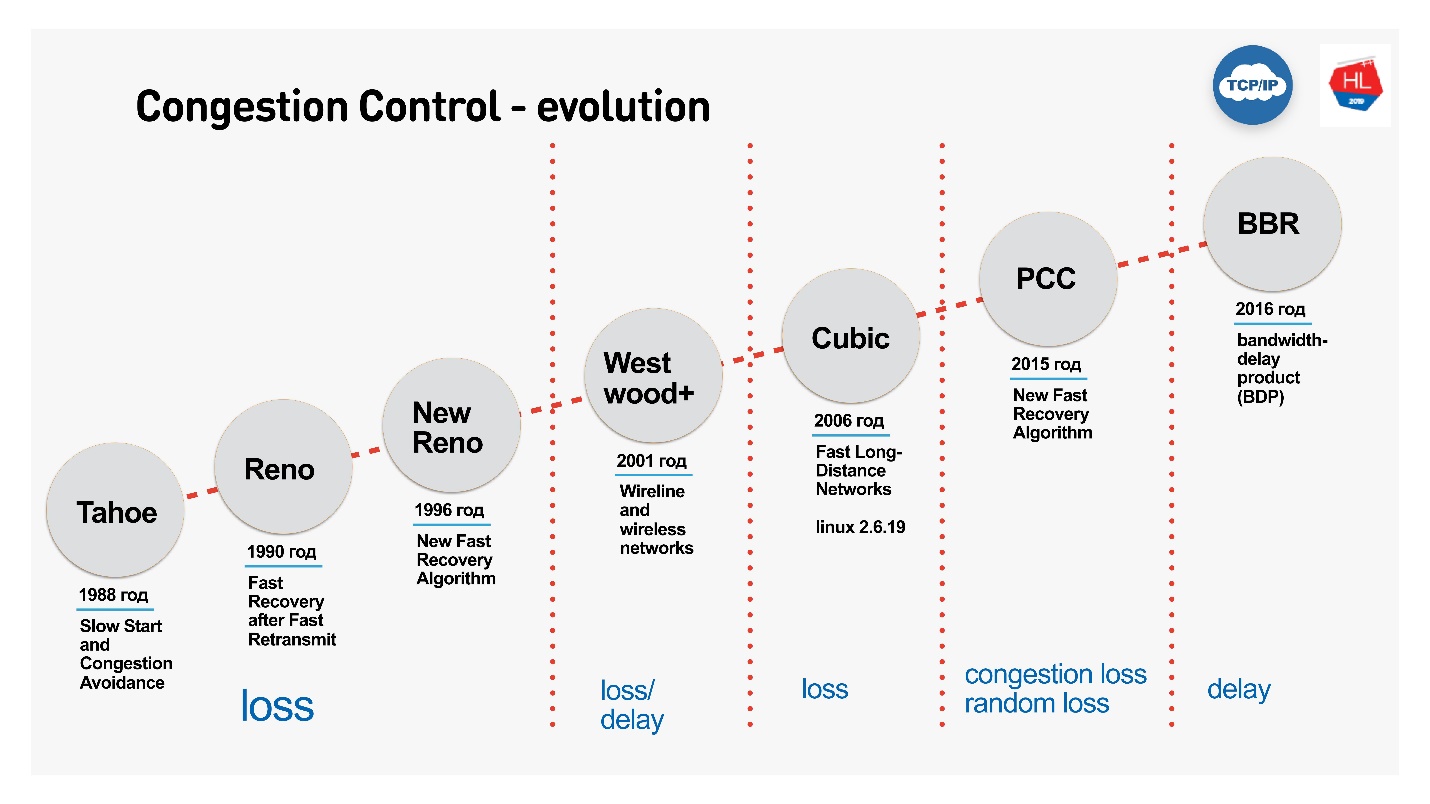
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
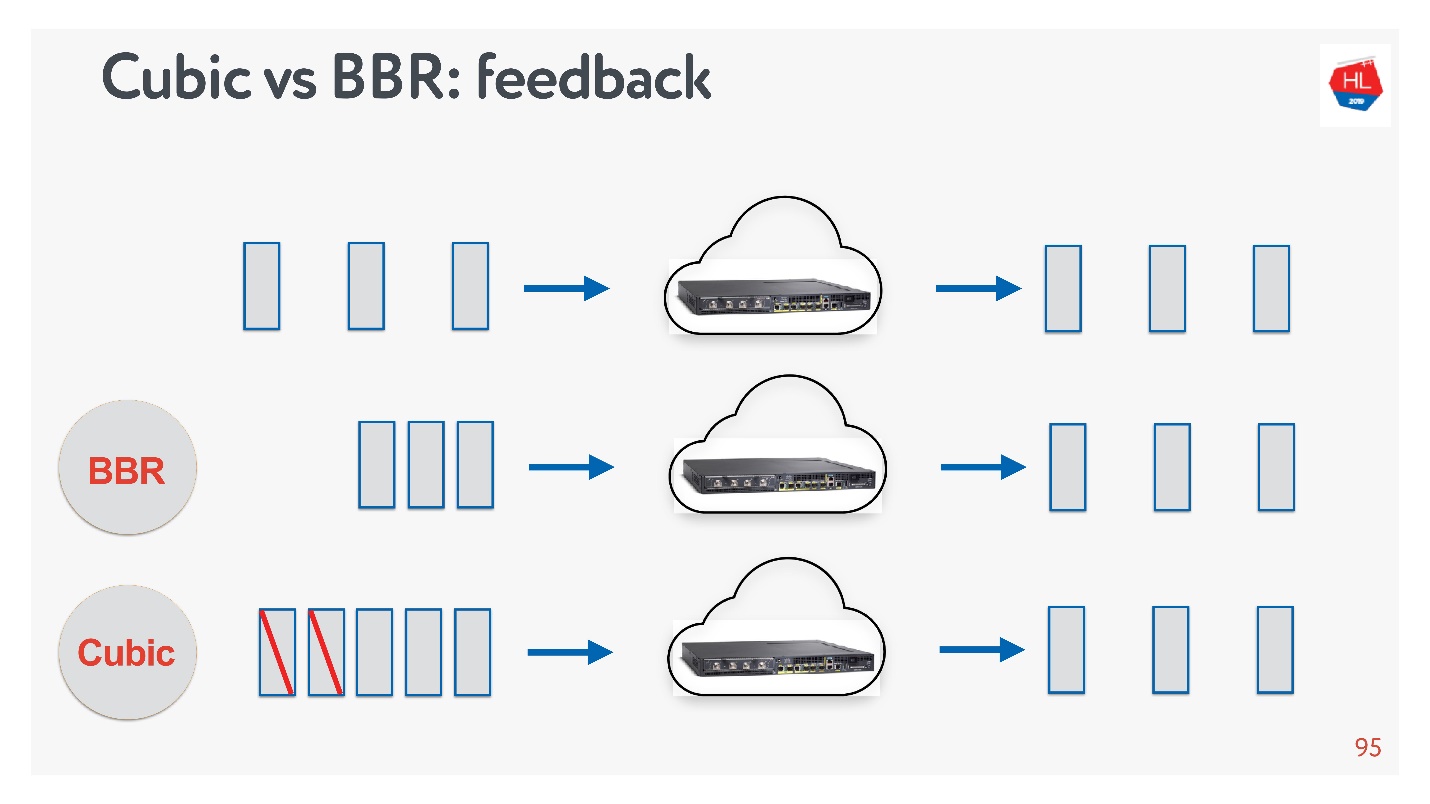
, — acknowledgement . :
A continuación se muestra un gráfico del retraso versus el tiempo de conexión, que muestra lo que sucede en diferentes controles de congestión.
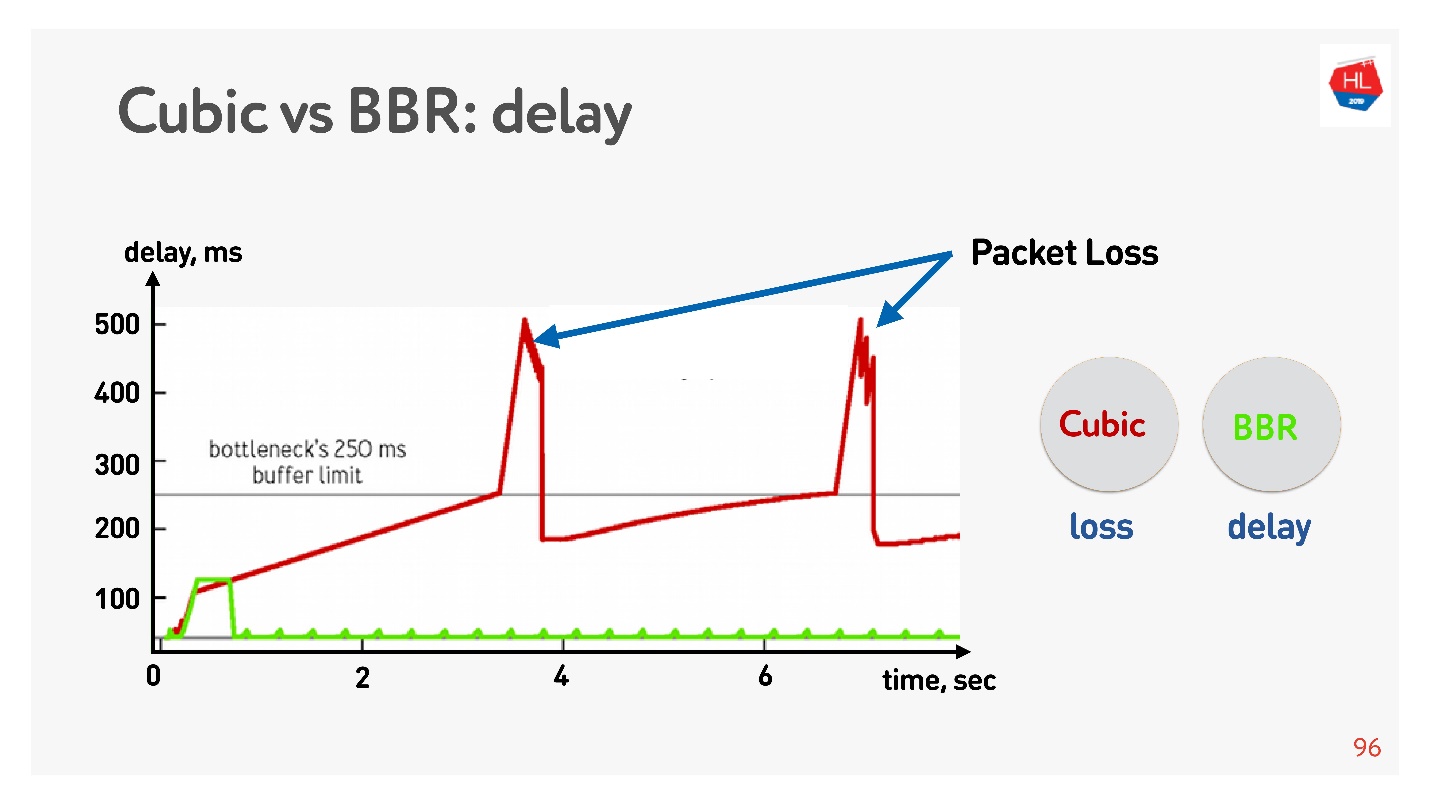
El BBR primero detecta el tiempo de ida y vuelta, envía más y más paquetes, luego se da cuenta de que el búfer está obstruido y entra en el modo de operación con un retraso mínimo.
Cubic funciona de forma agresiva: desborda todo el búfer, y cuando el búfer se desborda y se produce la pérdida de paquetes, cubic reduce la ventana.
Parece que, con la ayuda de BBR, sería posible resolver todos los problemas, pero hay una
inquietud en las redes: los paquetes a veces se retrasan, a veces se agrupan en paquetes. Los envías con cierta frecuencia y vienen en grupos. Peor aún, cuando recibes acuses de recibo de estos paquetes, y también de alguna manera "fluctúan".
Como prometí que todo podría ser tocado con las manos, entonces hacemos ping, por ejemplo, el sitio
HighLoad ++ , observamos el ping y consideramos la fluctuación entre paquetes.
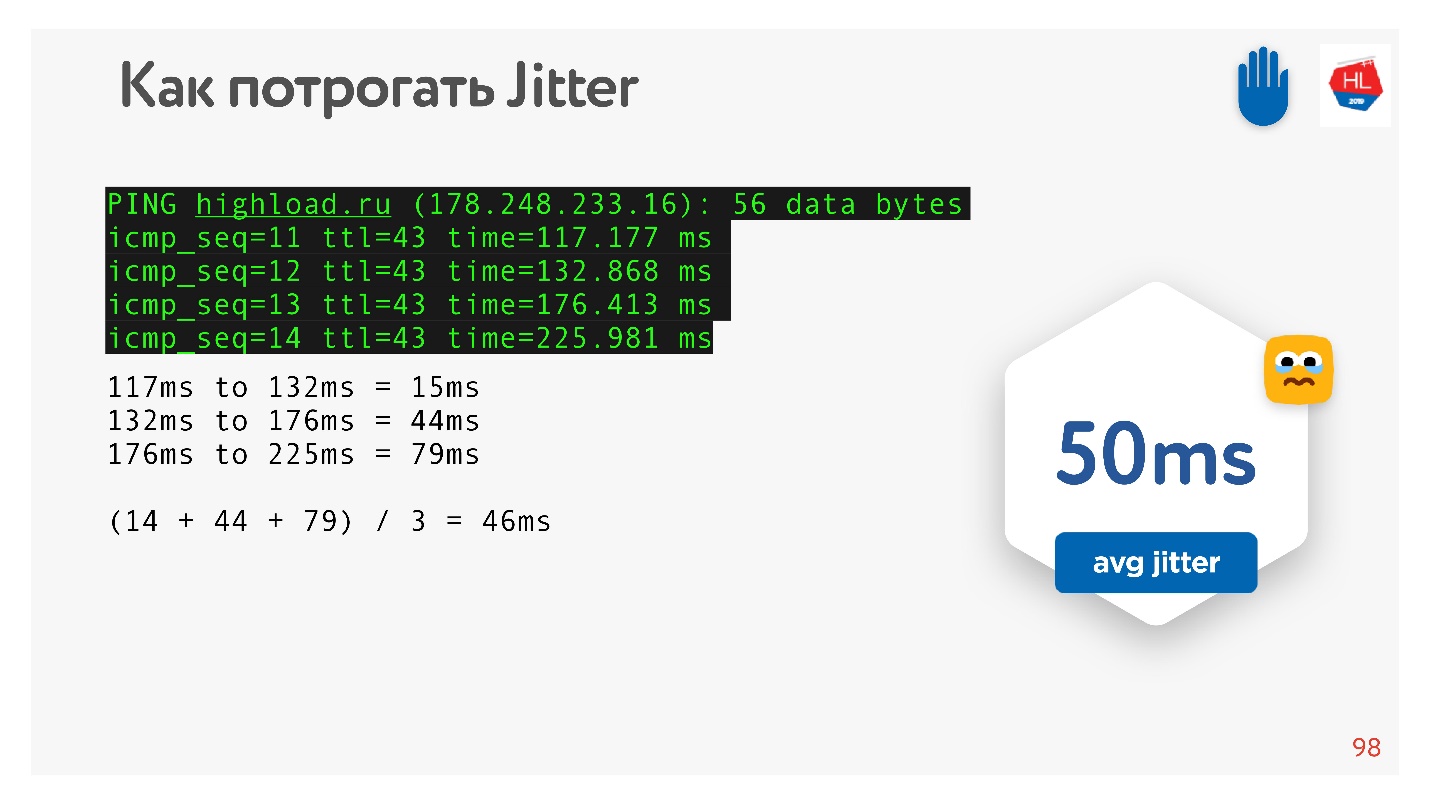
Se puede ver que los paquetes son desiguales, la fluctuación promedio es de aproximadamente 50 ms. Naturalmente, BBR puede estar equivocado.
BBR es bueno porque distingue entre: pérdida de congestión real, pérdida de paquetes debido a desbordamientos del búfer del dispositivo y pérdida aleatoria debido a una red inalámbrica deficiente. Pero no funciona bien en caso de nerviosismo elevado. ¿Cómo puedo ayudarlo?
Cómo mejorar el control de la congestión
De hecho, TCP no tiene suficiente información como reconocimiento, solo tiene los paquetes que vio. También hay un reconocimiento selectivo, que dice qué paquetes están confirmados y cuáles aún no han llegado. Pero esta información no es suficiente.
Si tiene la oportunidad de inflar el reconocimiento, aún puede ahorrar todo el tiempo, no solo enviando estos paquetes, sino también llegando al cliente. Eso es, de hecho, en el servidor para recopilar el cliente de jitter.
¿Por qué es generalmente efectivo inflar el reconocimiento? Porque las redes móviles son asimétricas. Por ejemplo, generalmente con 3G o LTE, el 70% del ancho de banda se asigna para descargar datos y el 30% para cargar. El transmisor cambia: cargar - descargar, cargar - descargar, y no lo afecta de ninguna manera. Si no descarga nada, entonces simplemente está inactivo. Por lo tanto, si tiene ideas interesantes, aumente el reconocimiento, no sea tímido; esto no es un problema.
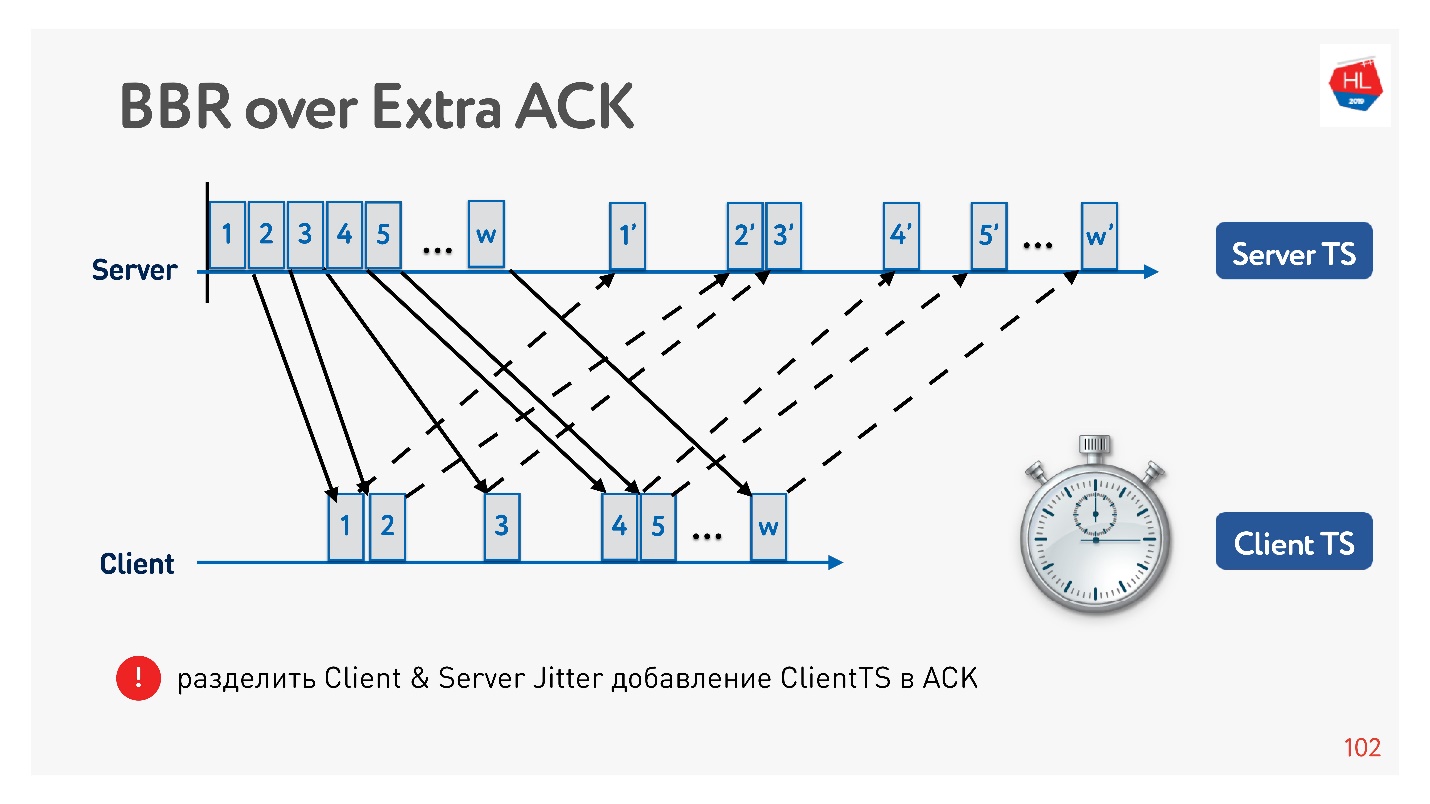
Un ejemplo de cómo puede usar un acuse de recibo para dividir el jitter en envío y el jitter para recibir, y rastrearlos por separado. Luego nos volvemos más flexibles y entendemos cuándo ocurrió la pérdida de congestión y cuándo ocurrió la pérdida aleatoria. Por ejemplo, puede comprender la cantidad de fluctuación en cada dirección y configurar con mayor precisión la ventana.

Qué control de congestión elegir
Los compañeros de clase son una gran red con mucho tráfico diferente: video, API, imágenes. Y hay estadísticas sobre qué control de congestión es mejor elegir.
BBR siempre es efectivo para video porque reduce los retrasos. En otros casos, Cubic generalmente se usa, es bueno para fotografías. Pero hay otras opciones.

Hay docenas de diferentes opciones de control de congestión. Para elegir el mejor, puede recopilar estadísticas sobre el cliente y probar uno u otro control de congestión para diferentes tipos de perfiles de carga.
Por ejemplo, este es el efecto de iniciar BBR en un video.
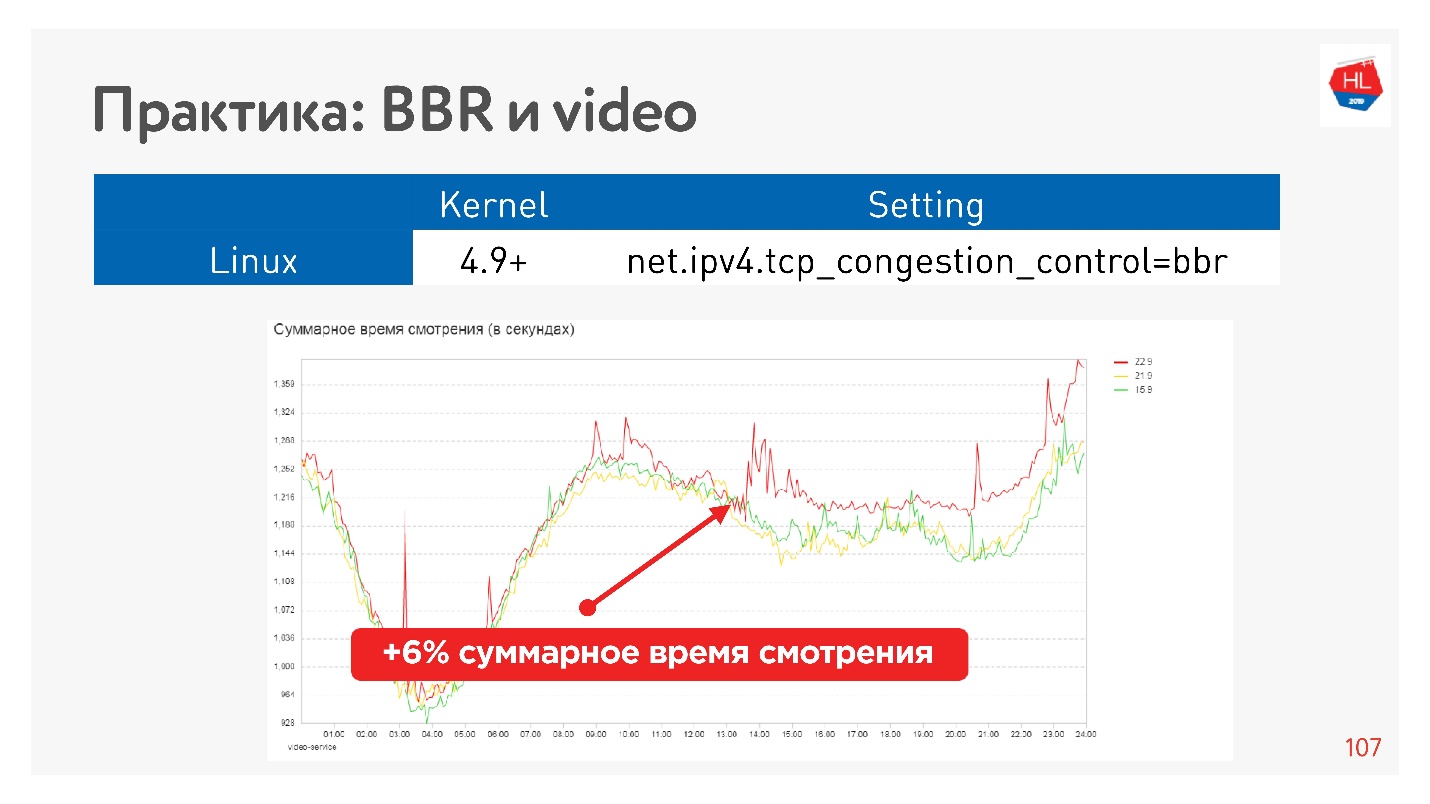
Logramos aumentar seriamente la profundidad de visualización. Google dice que tienen aproximadamente un 10% menos de almacenamiento en búfer en el reproductor cuando usan BBR.
Genial, pero ¿qué pasa con nuestros clientes?

Los clientes son un poco lentos, todos tienen Cubic y no puedes influenciarlo. Pero está bien, a veces puedes paralelizar datos, y será bueno.
Conclusiones sobre el control de congestión:- BBR siempre es bueno para el video.
- En otros casos, si usamos nuestro propio protocolo UDP, puede llevar el control de congestión con usted.
- Desde el punto de vista de TCP, solo puede usar el control de congestión, que está en el núcleo. Si desea implementar su control de congestión en el núcleo, debe cumplir con la especificación TCP. Es imposible inflar el reconocimiento, realizar cambios, porque simplemente no están en el cliente.
Si crea su protocolo UDP, tiene mucha más libertad en términos de control de congestión.
Multiplexación y priorización
Esta es una nueva tendencia, todos lo están haciendo ahora. Que problemas hay Si usamos TCP, seguramente todos (o casi todos) conocen la situación de bloqueo de cabecera.
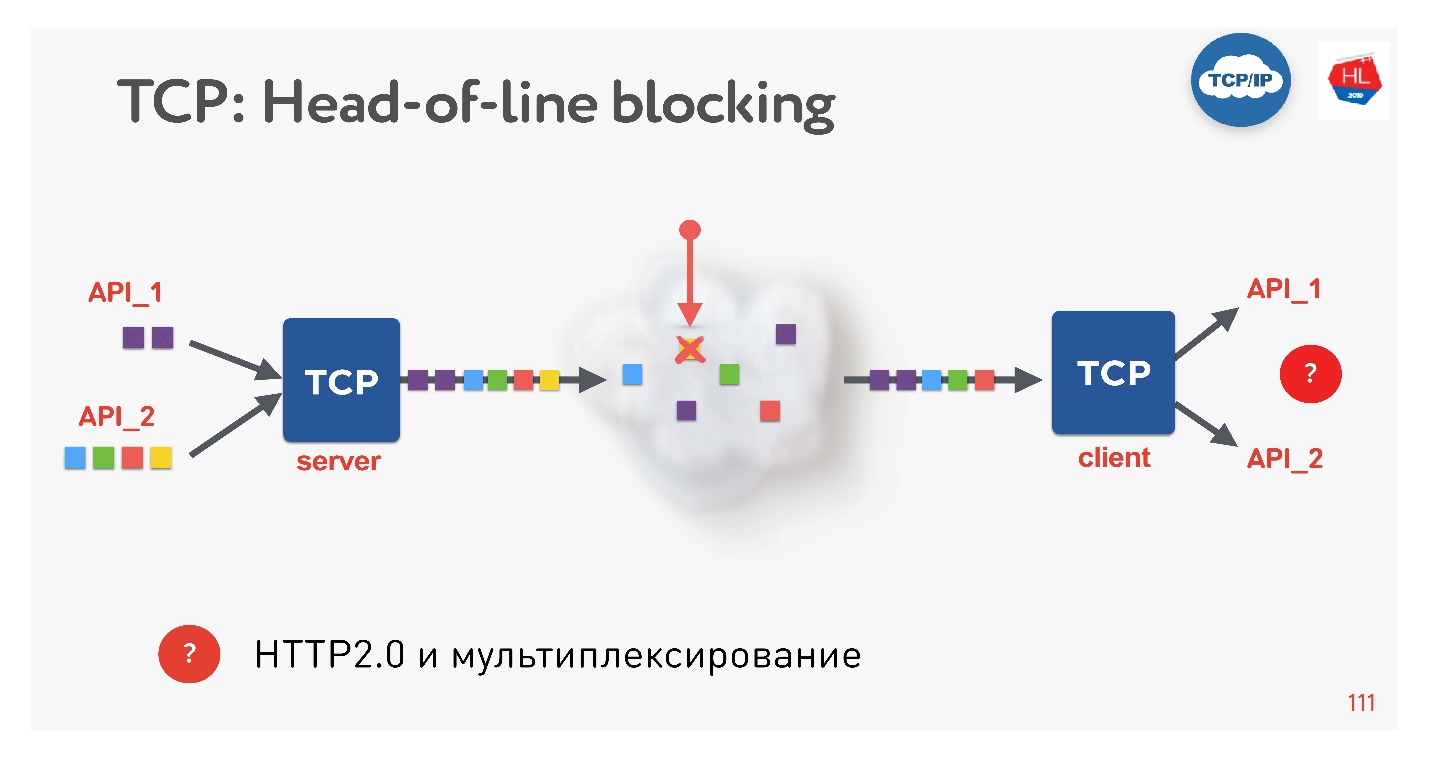
Hay varias solicitudes que se multiplexan en una sola conexión TCP. Los enviamos a la red, pero faltaba algún paquete. Una conexión TCP retransmitirá este paquete; se retransmitirá en un tiempo cercano a RTT o más. En este momento, no podremos obtener nada, aunque el búfer TCP contiene datos de otra solicitud que está completamente listo para ser recogido.
Resulta que la multiplexación a través de TCP, si usa HTTP 2.0, no siempre es efectiva en redes defectuosas.
El siguiente problema es la hinchazón del búfer.

Cuando se envía una imagen al cliente, el búfer aumenta. Lo enviamos durante mucho tiempo, y luego aparece una solicitud de API, y de ninguna manera se puede priorizar. En tales casos, la priorización de TCP no funciona.
Por lo tanto, si se produce una pérdida de paquetes, se produce un bloqueo de cabecera de línea y cuando el cliente tiene una tasa de bits variable (y esto sucede a menudo con clientes móviles), aparece el efecto de bloqueo de búfer. Como resultado, ni la multiplexación, ni la priorización, ni la inserción del servidor, ni todo lo demás funciona, porque tenemos búferes o el cliente espera algo.
Si hacemos nuestra propia multiplexación, entonces podemos poner varios datos allí.
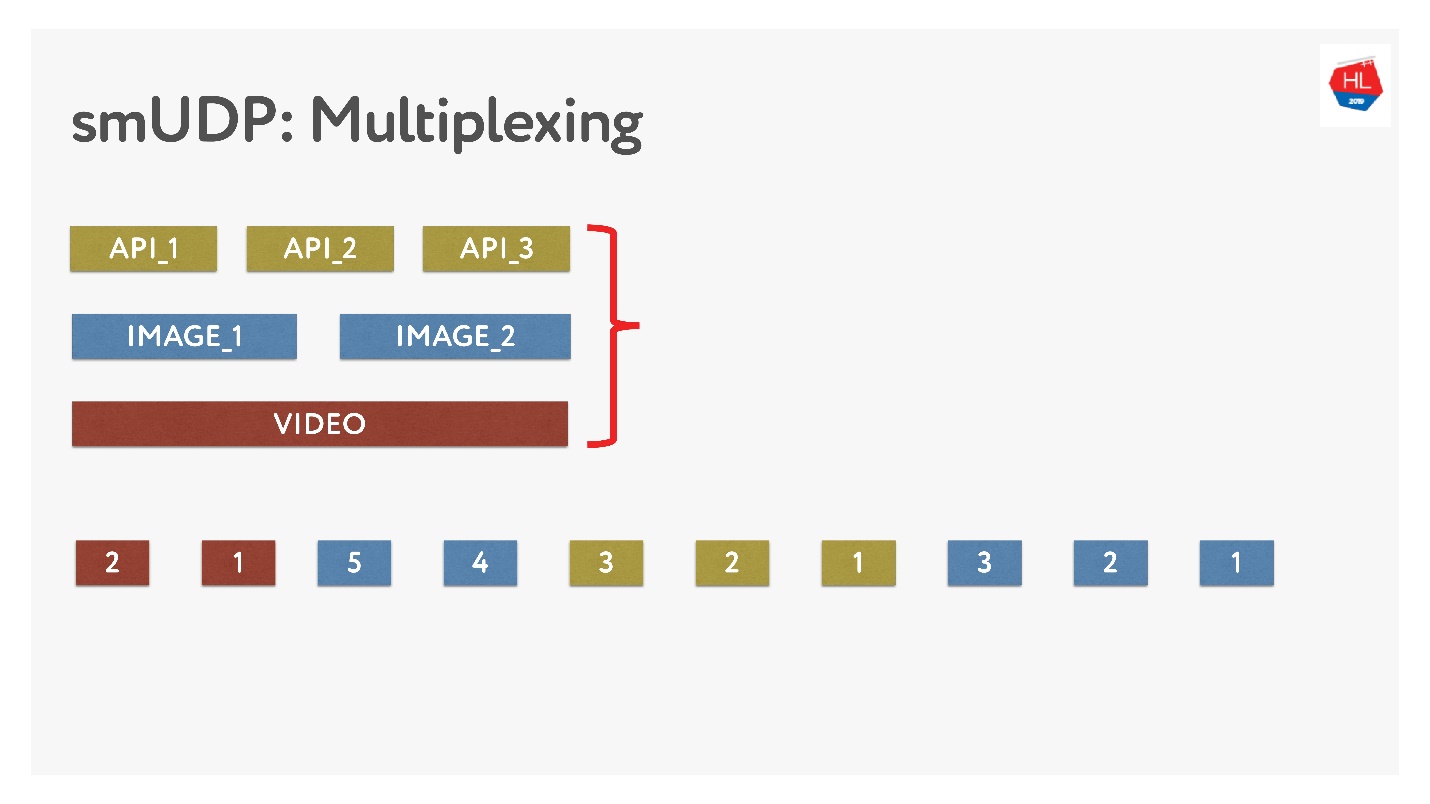
Esto no es difícil, solo agregue paquetes con números al búfer. Sobre la marcha: no toque lo que ya se ha enviado, pero lo que aún no se ha enviado se puede reorganizar. Se ve así.
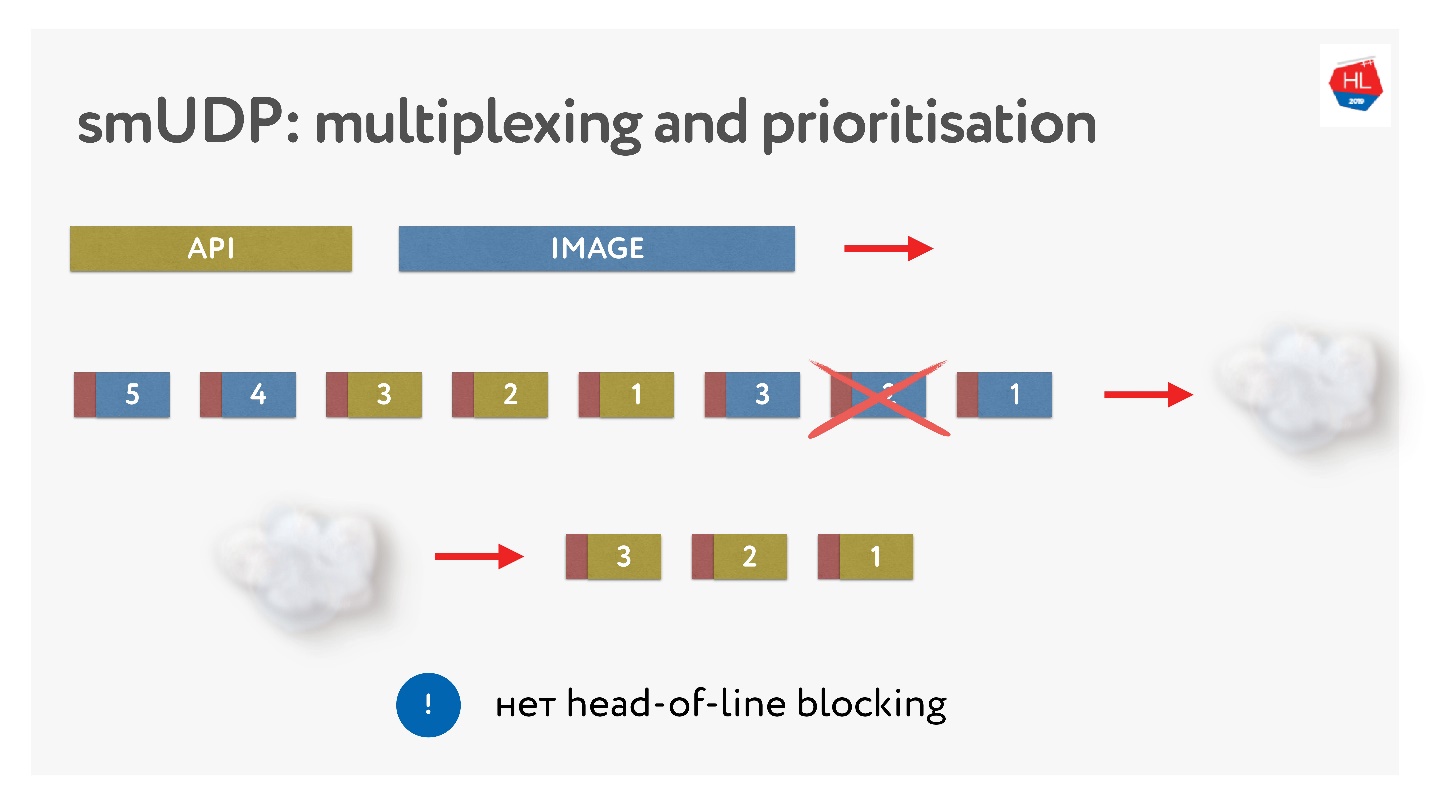
Enviaron imágenes, las dividieron en paquetes, recibieron una solicitud de API prioritaria: la insertaron y enviaron la imagen. Incluso si falta un paquete, podemos obtener una solicitud de API preparada desde el búfer, es de alta prioridad y llegará rápidamente al cliente. En TCP, por definición, la transferencia de datos de transmisión no es posible.
Establecer una conexión
Si perfilamos nuestra aplicación, veremos que la mayoría de las veces la red está inactiva al inicio de la aplicación, porque la conexión se establece primero antes de la API, luego obtenemos los datos, luego se establece la conexión antes de las imágenes, se descargan estos datos, etc. Esto siempre sucede: la red es utilizada por picos.

Para lidiar con esto, veamos cómo se establece la conexión.
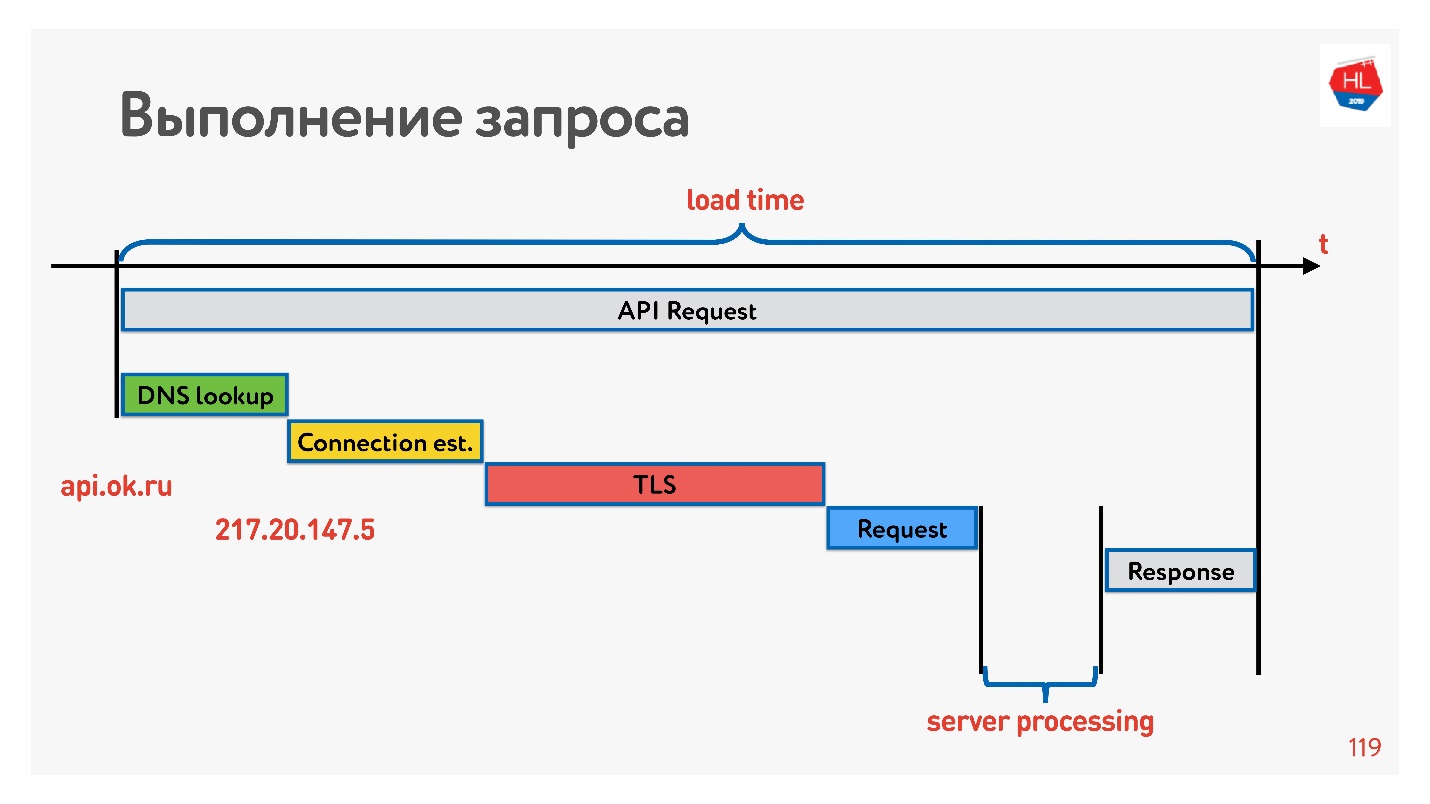
El primero es resolver DNS: no podemos hacer nada con esto. Luego, establezca una conexión TCP, establezca una conexión segura, luego ejecute la solicitud y reciba una respuesta. Lo más interesante es que parte del trabajo que realiza el servidor cuando responde a una solicitud generalmente toma menos tiempo que establecer una conexión.
Ahora está muy de moda medir números de latencia para memoria, para discos, para otra cosa. Puede medirlos para una red 3G, 4G y ver cuánto tiempo lleva, en el peor de los casos, establecer una conexión TCP con TLS.
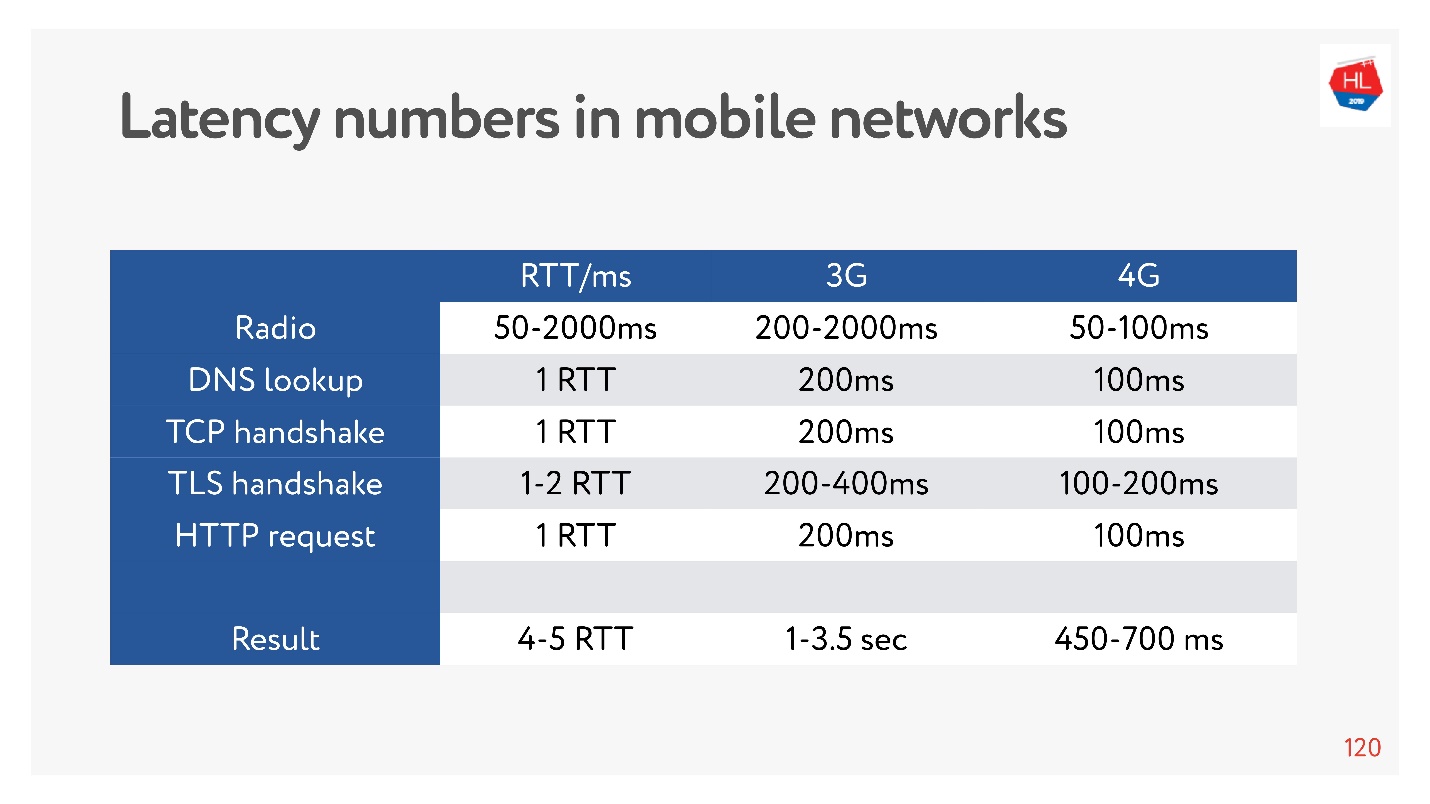
¡Y pueden ser segundos! Incluso en 4G hasta 700 ms también es significativo. Pero TCP no podría vivir tan fácilmente todo este tiempo.
La conexión se basa en el algoritmo básico de
protocolo de enlace TCP de 3 vías . Haga syn, syn + ack, luego corrija la solicitud más tarde (a la izquierda en el diagrama).
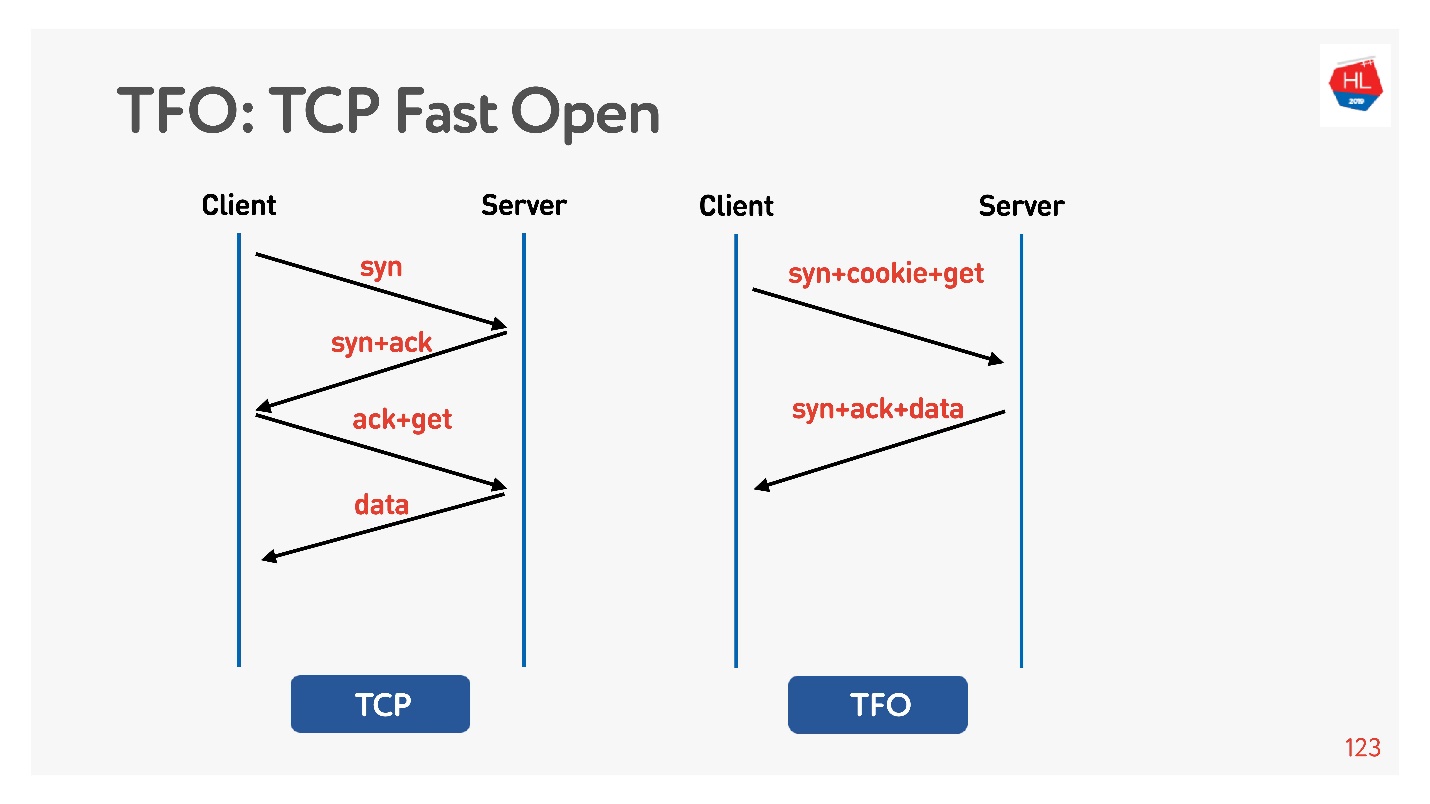
Hay
TCP Fast Open (derecha). Si ya ha conectado con este servidor, hay una cookie, puede enviar su solicitud de inmediato para RTT cero. Para usar esto, debe crear un socket, hacer que sendto () sea el primer dato, decir que quiere FASTOPEN.

Nginx puede hacer todo esto: solo enciéndalo, todo funcionará (o enciéndalo en el núcleo).
TLS
Vamos a comprobar que TLS es malo.
Configuré net shaper a 200 ms nuevamente, pinqué google.com y vi que RTT = 220 es mi RTT + RTT shaper. Luego hice una solicitud a través de HTTP y HTTPS. Descubrí que a través de HTTP es posible obtener una respuesta durante RTT, es decir, TFO funciona para Google desde mi computadora. Para HTTPS, esto tomó más tiempo.

Esta es una sobrecarga TLS tan común que requiere mensajería para establecer una conexión segura.
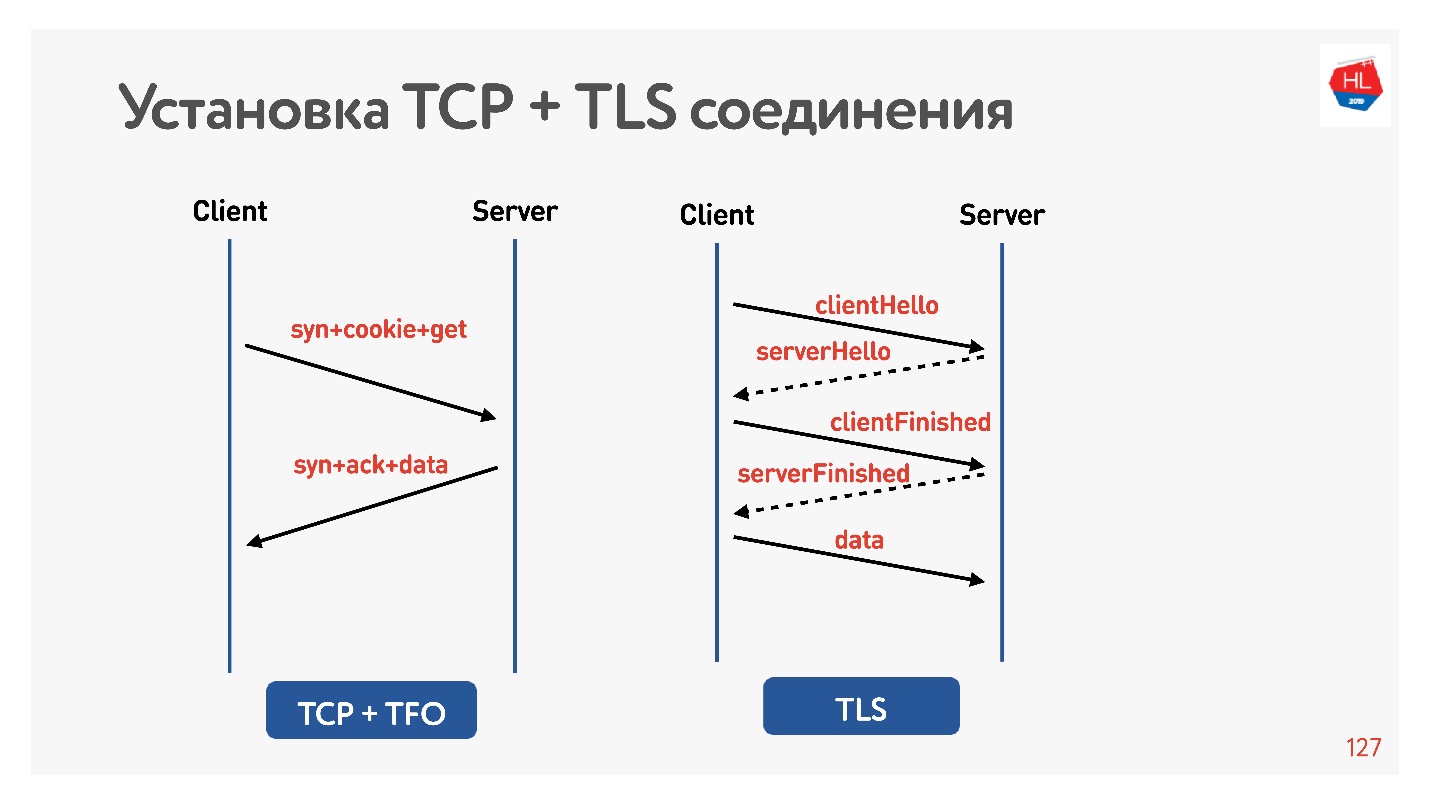
Para hacer esto, pensaron por nosotros, agregaron TLS 1.3. También es fácil de incluir en nginx.
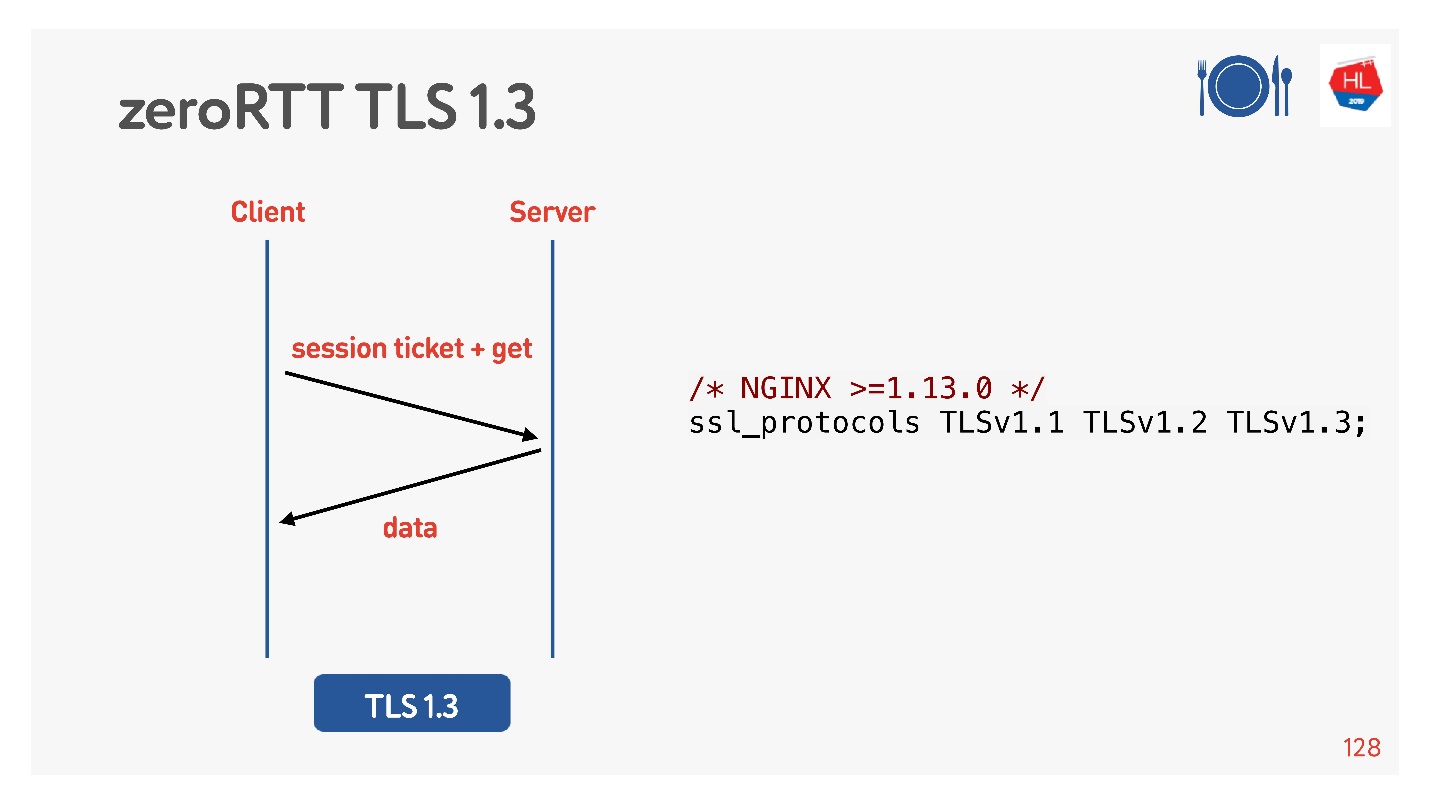
Todo parece funcionar. Pero veamos qué hay en nuestros clientes móviles que aprovechan todo esto.
¿Qué pasa con los clientes?
TCP Fast Open es algo genial. Según las estadísticas
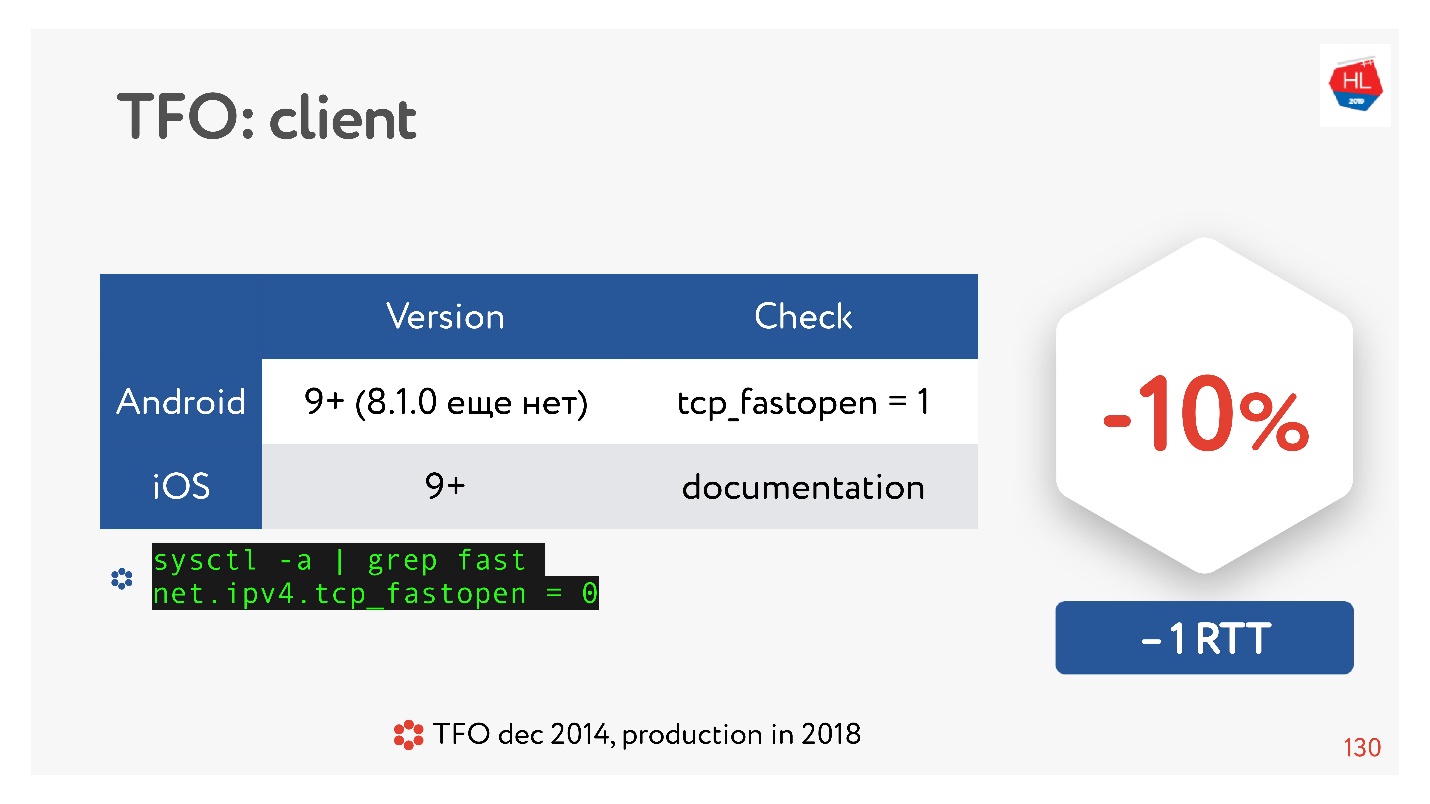
Hay muchos artículos que dicen que se garantiza que establecer una conexión pasará un 10% más rápido. Pero en Android 8.1.0 (vi varios dispositivos) nadie tiene TFO. En Android 9, vi TFO en el emulador, pero no en dispositivos reales. IOS está un poco mejor. Aquí puedes verlo:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
¿Por qué sucedió esto? TCP Fast Open se propuso en 2014, ahora ya es un estándar, es compatible con Linux y todo es genial. Pero existe un problema tal que el apretón de manos TFO comenzó a desmoronarse en algunas redes. Esto se debe a que algunos proveedores (o algunos dispositivos) están acostumbrados a inspeccionar TCP, hacer sus optimizaciones, y no esperaban que el protocolo de enlace TFO estuviera allí. Por lo tanto, su implementación tomó mucho tiempo, y hasta ahora, los clientes móviles no lo incluyen por defecto, al menos Android.
Con TLS 1.3, que nos promete que la configuración de la conexión RTT cero es aún mejor. No encontré ningún dispositivo Android en el que funcionara. Por lo tanto, Facebook creó la biblioteca
Fizz . Hace un par de meses, estuvo disponible en código abierto, puede arrastrarlo con usted y usar TLS 1.3. Resulta que incluso la seguridad necesita ser arrastrada, nada aparece en el núcleo de esto.
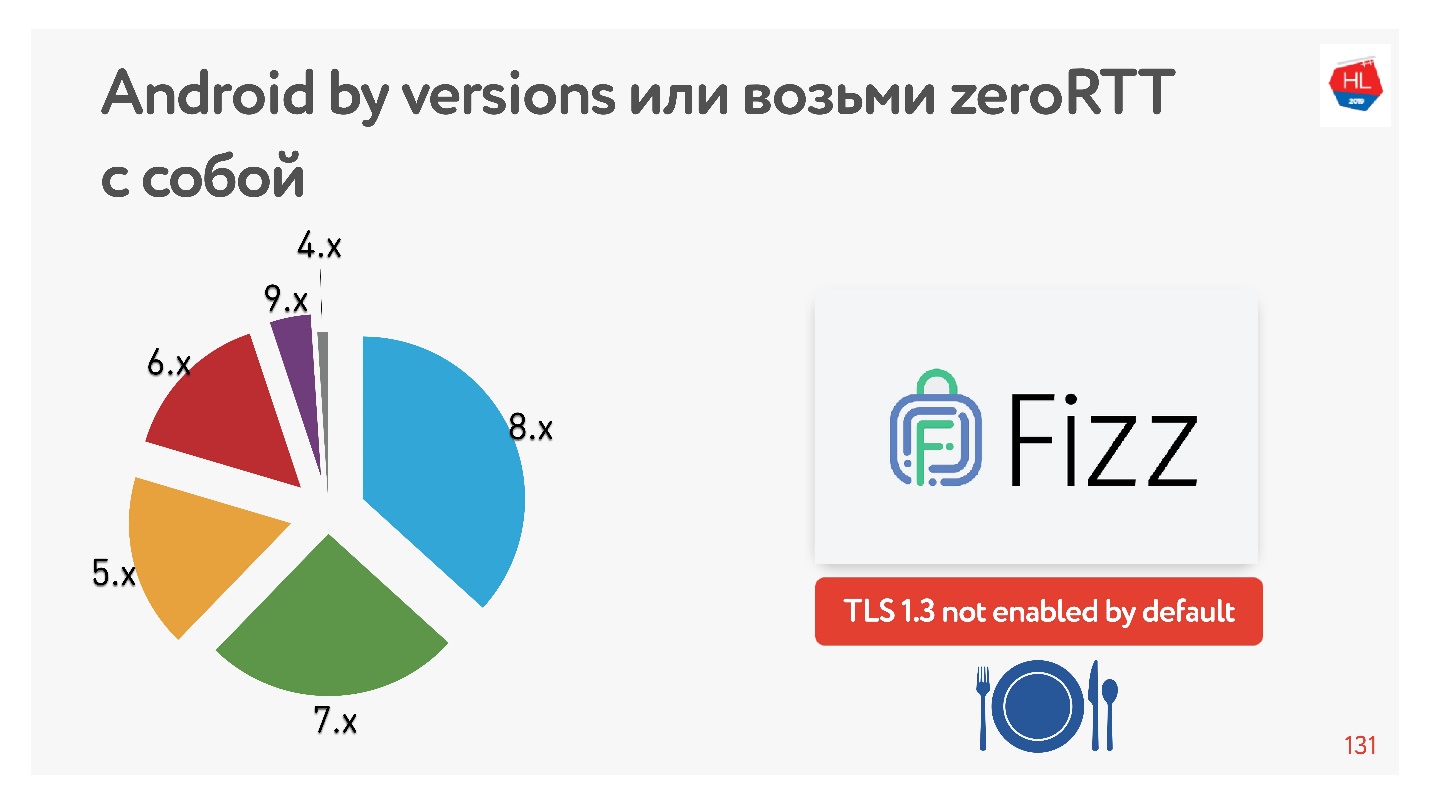
El diagrama muestra el uso de varias versiones de Android por parte de nuestros clientes móviles. V 9.x es bastante, donde puede aparecer TFO, y TLS1.3 no se encuentra en ningún otro lugar.
Conclusiones sobre el establecimiento de una conexión:- TFO no está disponible para el 95% de los dispositivos.
- TLS1.3 necesita ser traído consigo mismo.
- Si necesita repetir esto en UDP, transfiera todo esto a UDP y repita.
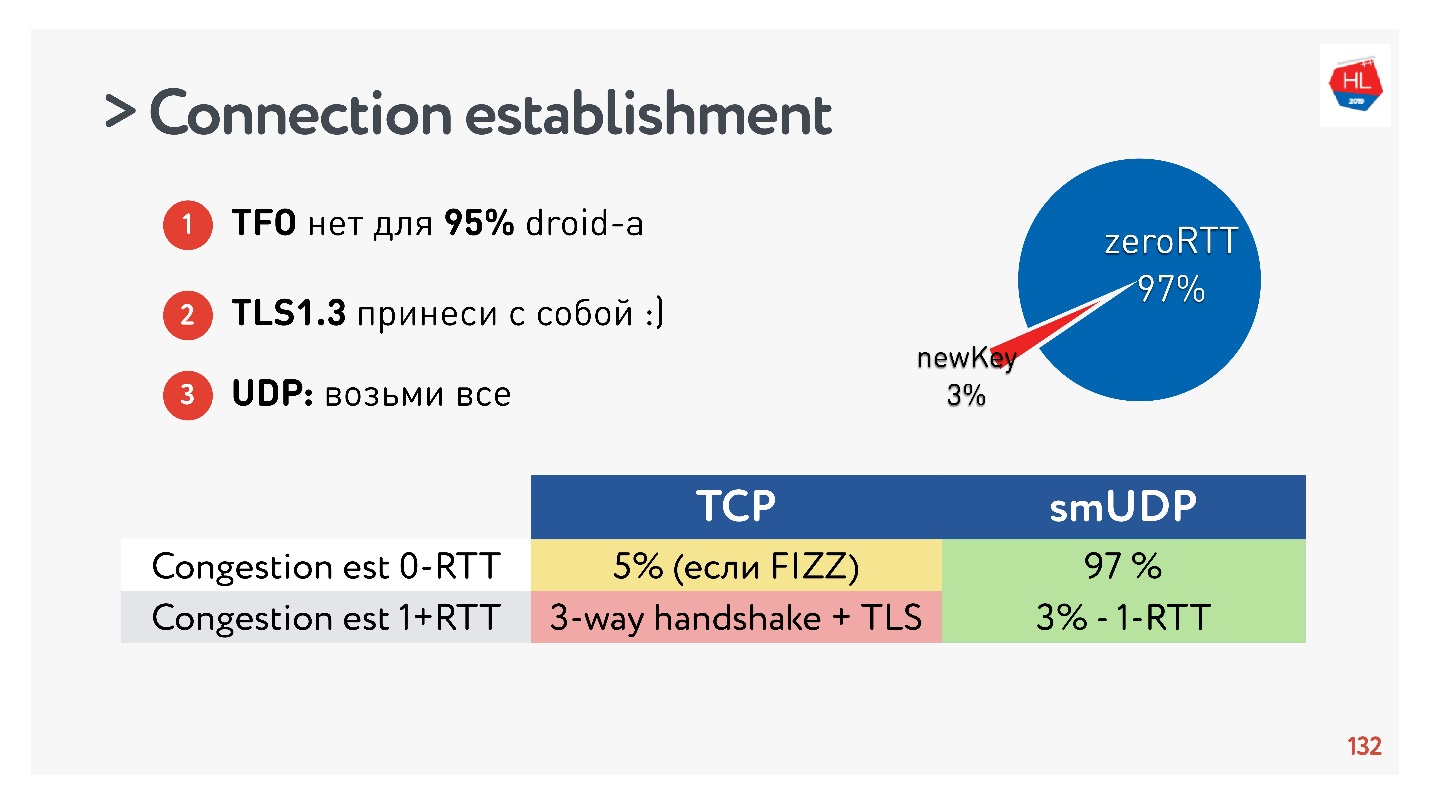
Resultó que el 97% de las conexiones creadas usan la clave existente, es decir, el 97% se crea para cero RTT, y solo el 3% son nuevas. La clave se almacena en el dispositivo durante algún tiempo.
TCP no puede presumir de ello. En un máximo del 5% de los casos, si hace todo bien, podrá obtener el verdadero RTT cero del que todo el mundo está hablando ahora.
Cambio de dirección IP
A menudo, cuando sales de casa, tu teléfono cambia de Wi-Fi a 4G.
TCP funciona así: la dirección IP ha cambiado, la conexión ha fallado.
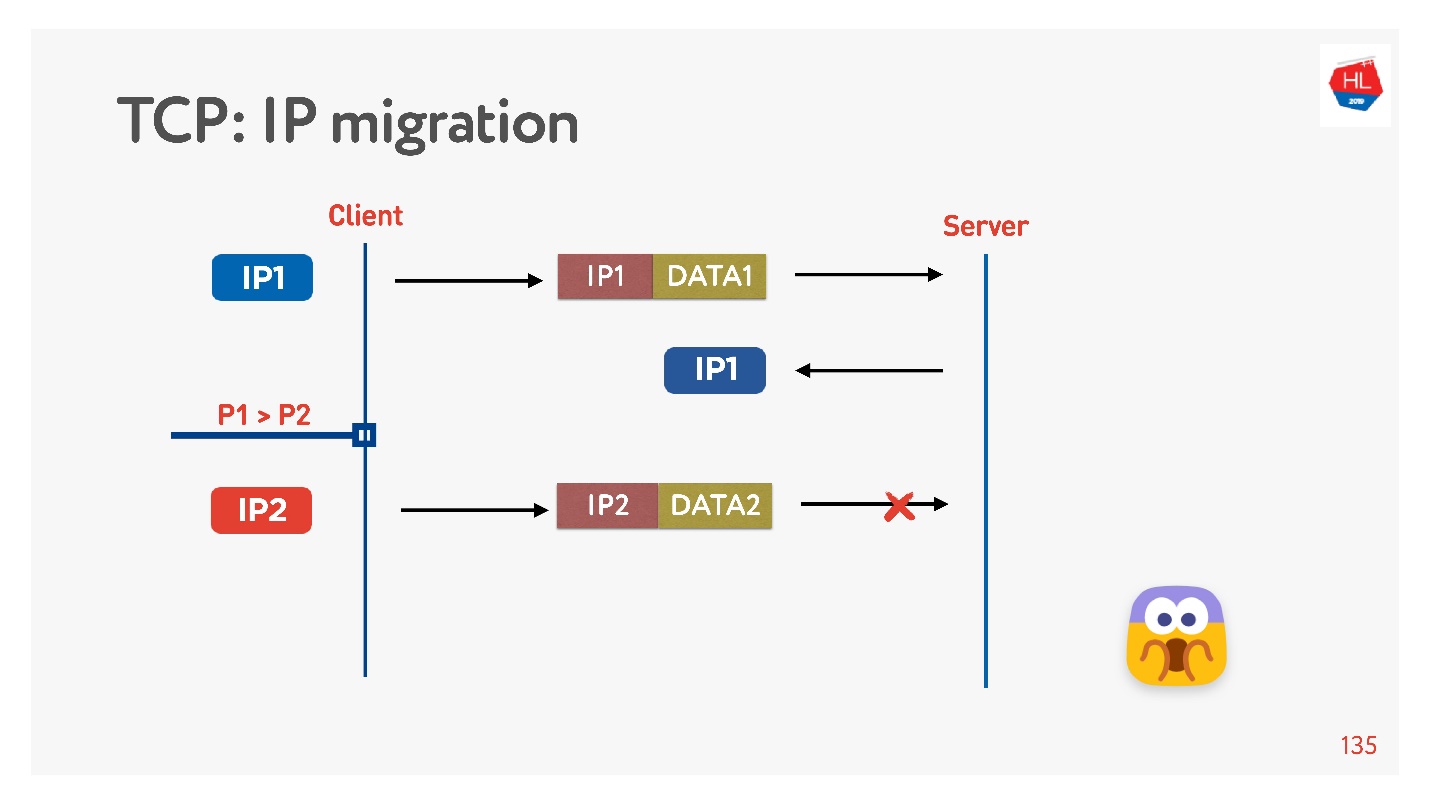
Si escribe su protocolo UDP, es muy simple, al implementar una ID de conexión (CUID) en cada paquete, puede identificarlo, incluso si proviene de una dirección IP diferente.

Está claro que debe asegurarse de que tiene la clave correcta, todo está descifrado, etc. Pero, en principio, puede comenzar a responder a esta dirección, no habrá problemas con esto.
En TCP, la migración de IP es algo imposible.
Si crea su UDP y llegó al mismo servidor, debe hacer un poco de magia, incluir el CID en cada paquete y podrá utilizar la conexión establecida al cambiar la dirección IP.
Reutilización de conexión
Todo el mundo dice que debes reutilizar las conexiones porque las conexiones son muy caras.

Pero hay dificultades en la reutilización de compuestos.
Lo más probable es que mucha gente recuerde (si no, entonces vea
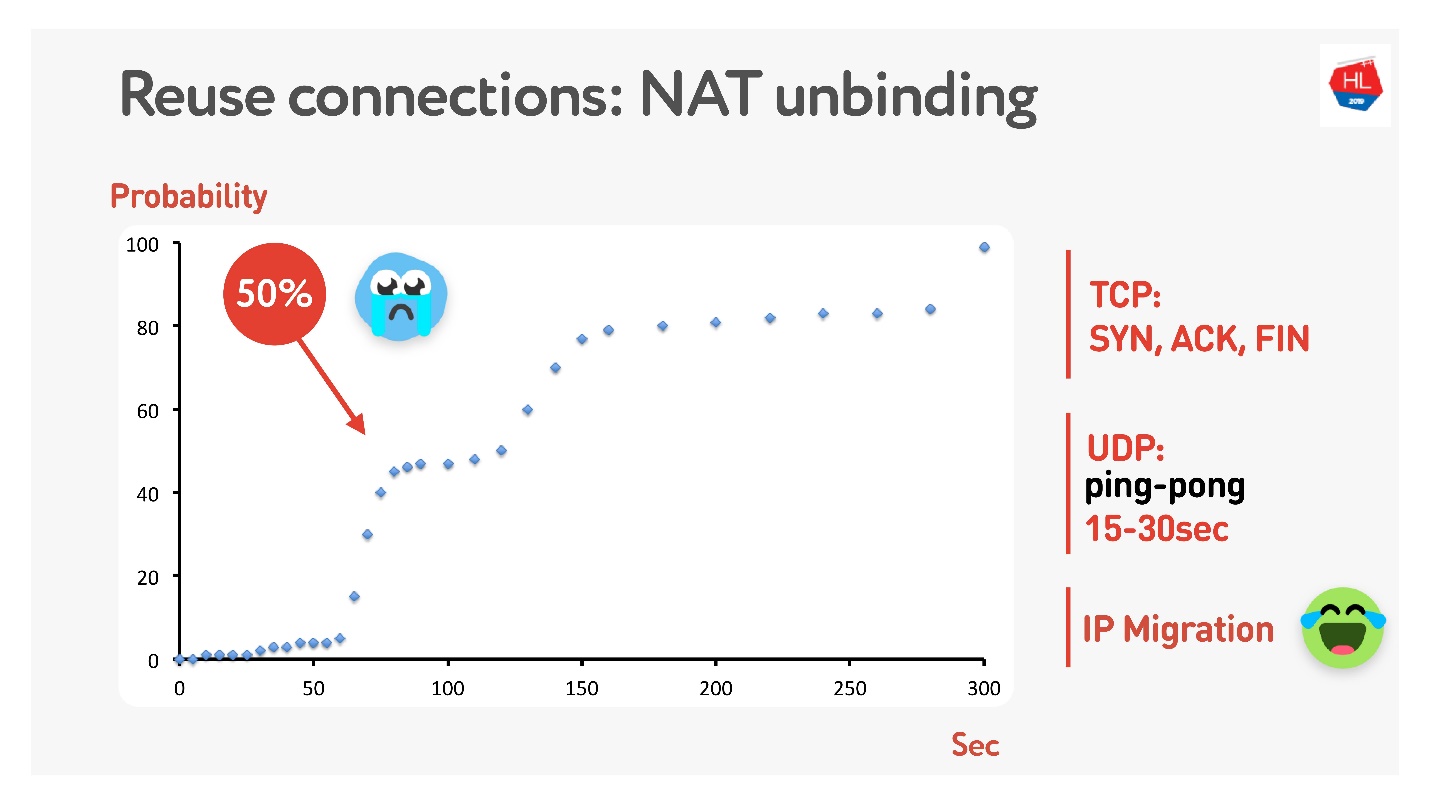
aquí ) que no todos tienen direcciones públicas, pero hay NAT, que generalmente almacena mapas durante algún tiempo en el enrutador doméstico. Para TCP, está claro cuánto almacenar, pero para UDP no está claro. NAT opera en un tiempo de espera, si mide cuidadosamente este tiempo de espera, obtenemos que en aproximadamente 15-30 segundos más del 50% de las conexiones comenzarán a fallar.
Está bien, haremos un paquete de ping-pong durante 15 s. Para los casos en que la conexión aún está interrumpida, existe la migración de IP, que a bajo costo le permite cambiar el puerto en el enrutador.
Estimulación de paquetes
Esto es algo muy importante si está haciendo su protocolo UDP.

Si es muy simple, cuanto más tiempo envíe paquetes continuamente a la red, mayor será la probabilidad de pérdida de paquetes. Si filtra los paquetes, la pérdida de paquetes será menor.
Hay muchas teorías diferentes sobre cómo funciona esto, pero me gusta esta.
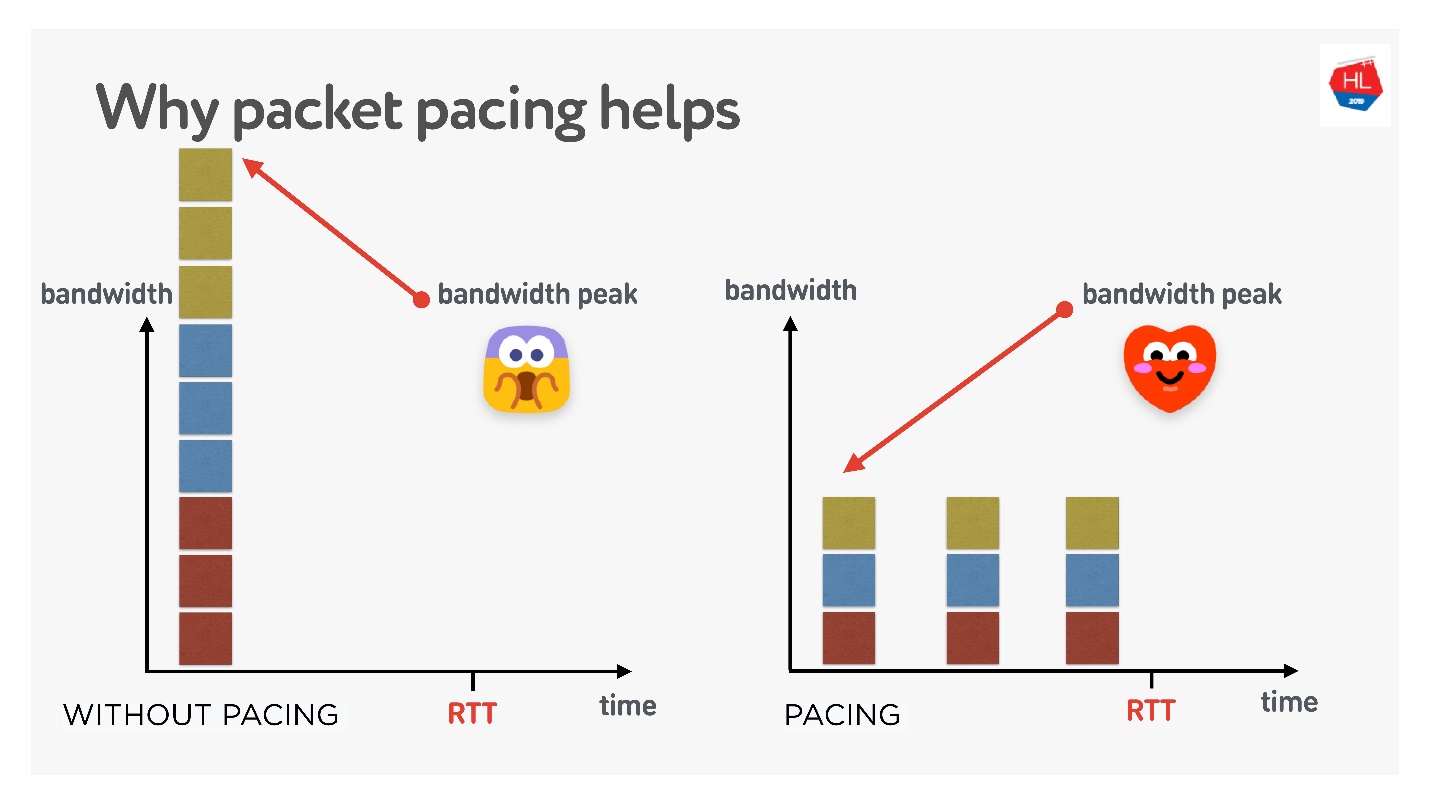
Hay 3 conexiones que se crean a la vez. Tiene la llamada ventana inicial: 10 paquetes creados al mismo tiempo. Por supuesto, el ancho de banda podría no ser suficiente en este momento. Pero si los distribuye cuidadosamente, sepárelos, entonces todo estará bien, como en la figura correcta.
Por lo tanto, si establece una velocidad uniforme para enviar paquetes, reduzca su volumen, entonces la probabilidad de que haya un desbordamiento del búfer de una sola vez se reduce. Esto no está probado, pero en teoría resulta así.

Cuando necesite cortar paquetes (marque el ritmo):
- Cuando creas una ventana.
- Cuando amplía la ventana, por ejemplo, se recomienda agregar tantos paquetes como se puedan enviar para RTT / 2. Esto no degradará el tiempo de entrega, pero reducirá la pérdida de paquetes.
- En el caso de pérdida de congestión, para reducir la ventana, debe untar los paquetes aún más. 4/5 RTT es una figura empíricamente seleccionada.
MTU
Al escribir su protocolo UDP, asegúrese de recordar acerca de MTU. MTU es el tamaño de los datos que puede reenviar.
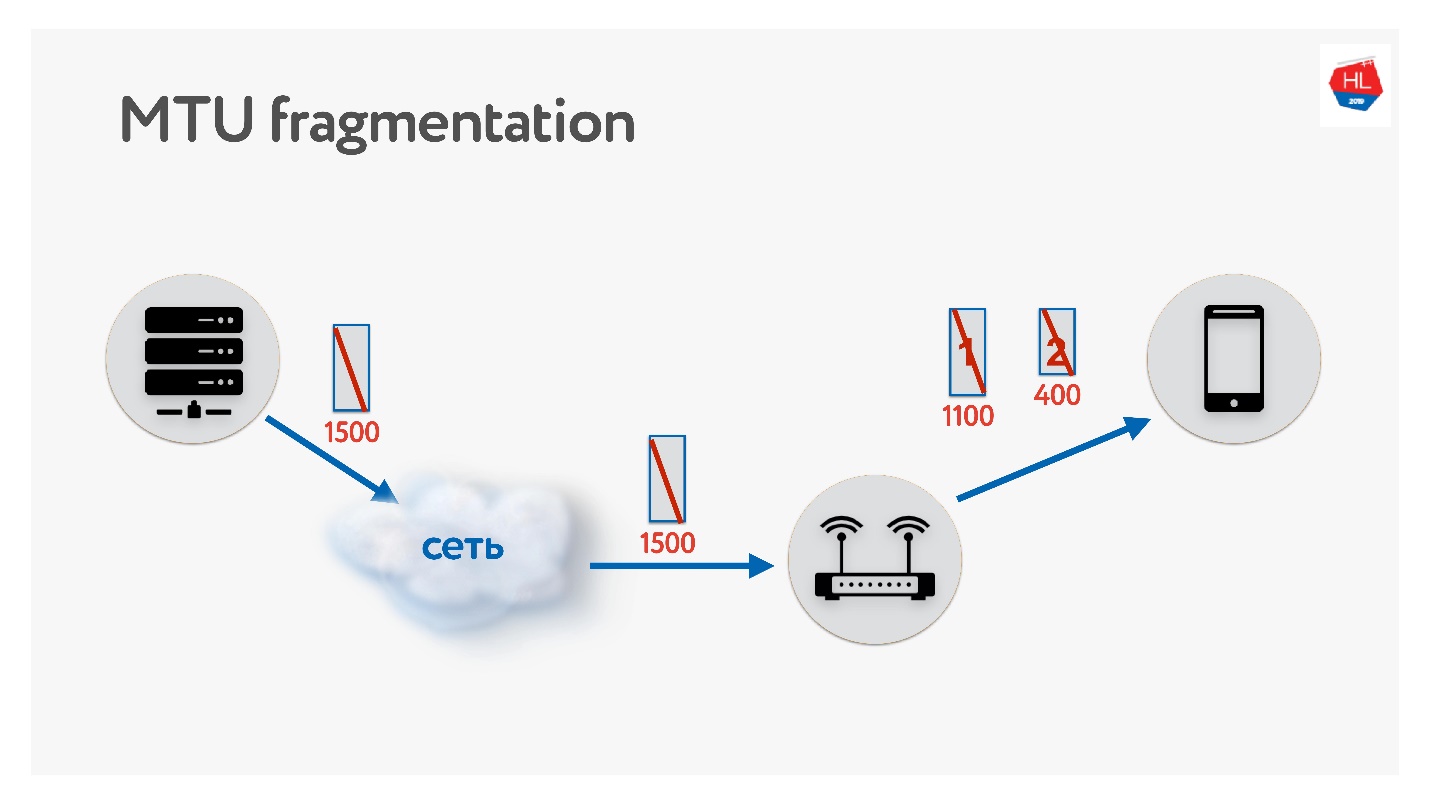
Enviamos paquetes desde el servidor al cliente, por ejemplo, con un tamaño de 1500. Si hay un enrutador en la ruta que no admite este tamaño de MTU, lo fragmentará. El único problema de fragmentación es que si se pierde un paquete, ambos se perderán y todo esto tendrá que retransmitirse. Por lo tanto, TCP tiene un algoritmo para determinar MTU - PMTU.

Cada enrutador mira el MTU de su interfaz, lo envía a un cliente, el otro lo envía a su cliente, todos saben cuántas MTU tienen en el cliente. Luego, la bandera prohíbe la fragmentación y se envían paquetes de tamaño MTU. Si en este momento alguien dentro de la red se da cuenta de que tiene menos MTU, entonces a través de ICMP dirá: "Lo siento, el paquete se perdió porque se necesita fragmentación" e indicará el tamaño de la MTU. Cambiaremos este tamaño y continuaremos enviando. En el peor de los casos, nuestra pequeña sobrecarga es RTT / 2. Esto está en TCP.
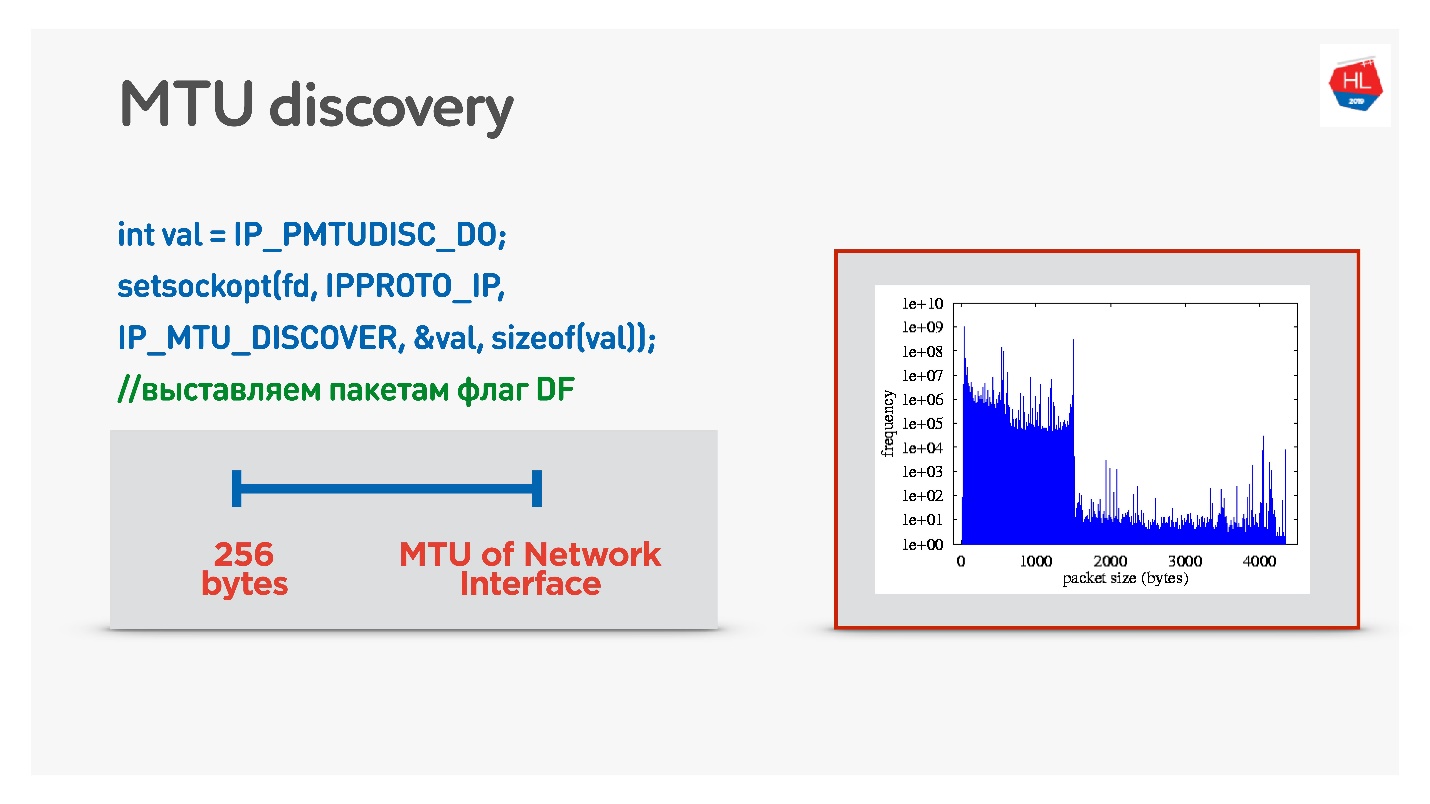
Si en UDP no desea molestarse con ICMP, puede hacer lo siguiente: permitir la fragmentación al enviar datos normales. Es decir, para enviar paquetes fragmentados, déjelos trabajar. Y en paralelo para comenzar un proceso que prohíba la fragmentación, una búsqueda binaria seleccionará la MTU óptima, a la que luego iremos. Esto no es del todo efectivo, porque al principio la MTU parecerá calentarse.
Una opción más complicada es mirar la distribución de MTU entre clientes móviles.

Desde todos los clientes, enviamos paquetes de varios tamaños con la prohibición de la fragmentación. Es decir, si el paquete no alcanza, caerá y la MTU más pequeña debería alcanzar el 100%. Pero hay una pequeña pérdida de paquetes, por lo que hay dos diapositivas en el gráfico:
- 1350 bytes: en lugar del 98%, recibimos el 95% de entrega de inmediato.
- 1500 bytes - MTU, después de lo cual ya el 80% de los clientes no recibirán dichos paquetes.
De hecho, podemos decir esto: descuidamos el 1-2% de nuestros clientes, les dejamos vivir en paquetes fragmentados. Pero comenzaremos de inmediato con lo que necesitamos: esto es a partir de 1350.
Corrección de errores (SACK, NACK, FEC)
Si está haciendo su protocolo, debe corregir los errores. Si falta el paquete (esto es normal para las redes inalámbricas), debe restaurarse.
En el caso más simple (más detalles
aquí ), hay un relé a través de Retransmit Time Out (RTO). Si falta el paquete, espere el tiempo de retransmisión y envíelo nuevamente.
El siguiente algoritmo es la
retransmisión rápida . Todos estos son algoritmos TCP, pero se pueden portar fácilmente a UDP.
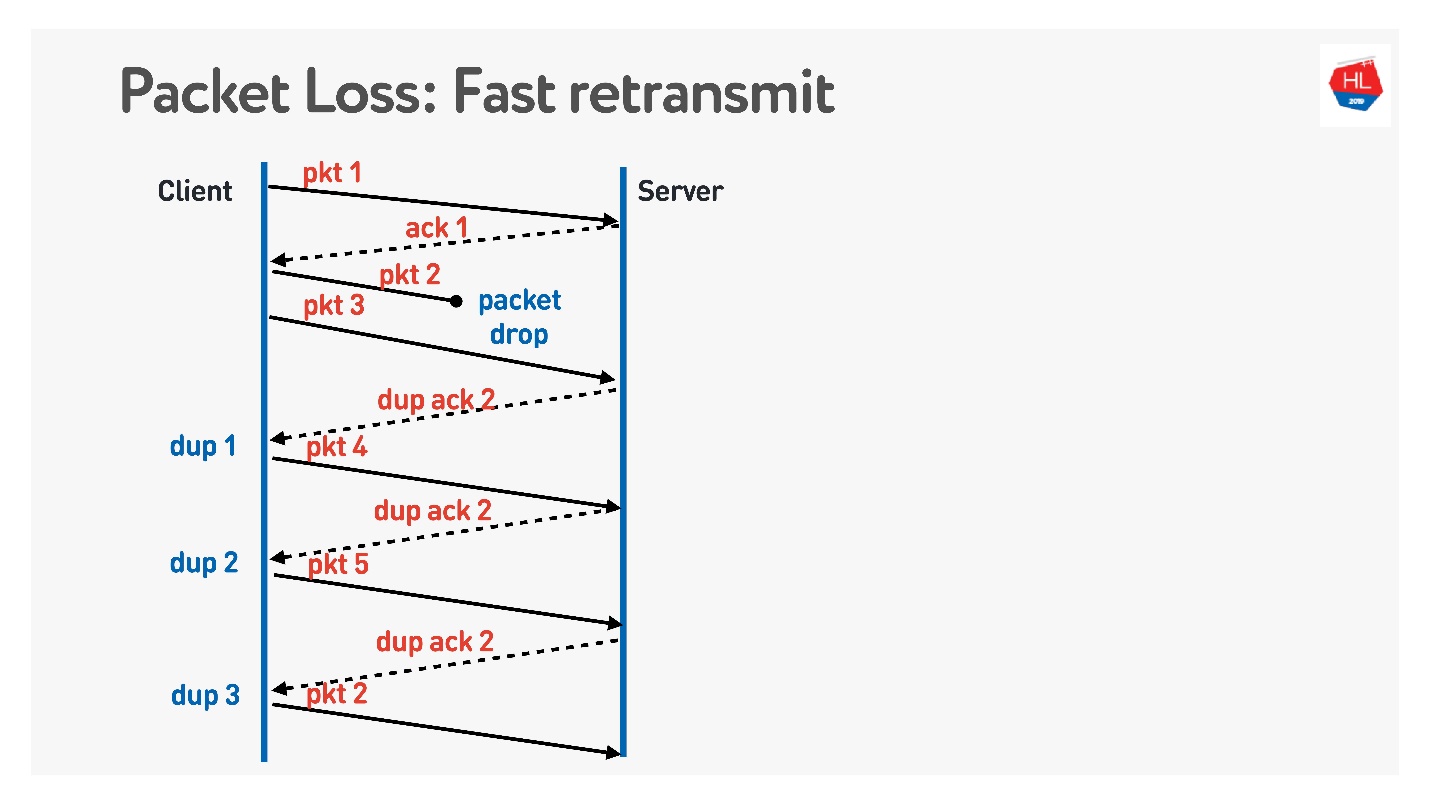
Cuando el paquete se va, continuamos enviando, hay una transmisión de otros paquetes. En este momento, el servidor dice que recibió el siguiente paquete, pero que no había ninguno anterior. Para hacer esto, realiza un reconocimiento complicado, que es igual al número de paquete + 1, y establece el indicador de reconocimiento duplicado. Él envía estos duplicados así, y en el tercero generalmente entendemos que el paquete ha desaparecido y lo enviamos nuevamente.
Lo que más quieres hacer con clase, lo que no está en TCP y lo que proponen hacer en UDP es la
corrección de errores de reenvío .

Parece que si sabemos que los paquetes pueden perderse, podemos tomar un conjunto de paquetes, agregarle un paquete XOR y solucionar el problema sin retransmisiones adicionales inmediatamente en el cliente al recibir datos. Pero hay un problema si varios paquetes desaparecen. Parece que se puede resolver a través de la protección de paridad, Reed-Solomon, etc.
Lo intentamos de esta manera, resultó que, de hecho, los paquetes desaparecen en paquetes.
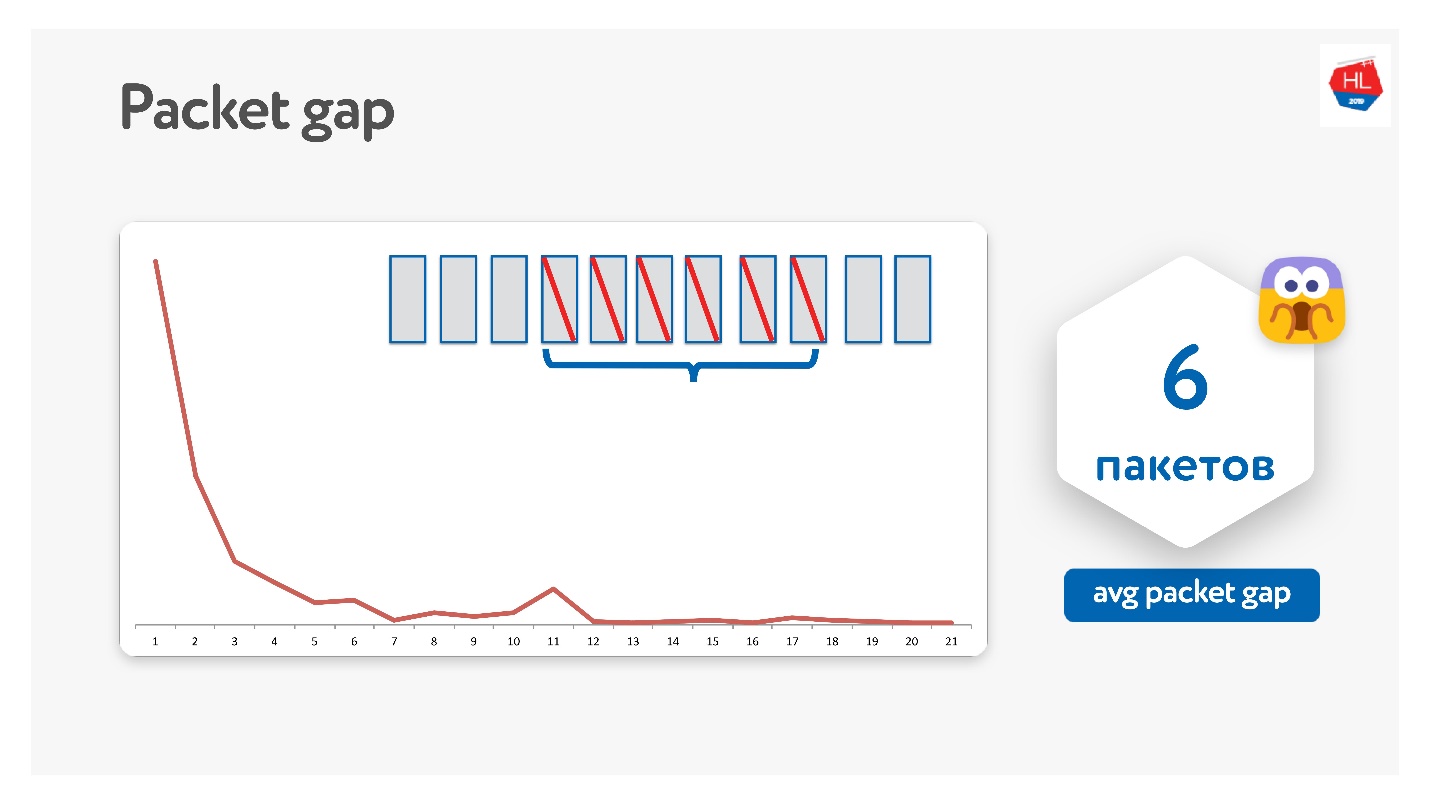
El intervalo de paquetes promedio resultó ser 6. Este es un intervalo de paquetes muy inconveniente: necesita muchos códigos de corrección de errores. Al mismo tiempo, hay algún tipo de pico a las 11: no sé por qué, pero los paquetes a veces desaparecen en paquetes de 11. Debido a esta brecha de paquetes, esto no funciona.
Google también intentó esto, todos sueñan con FEC, pero hasta ahora nadie ha trabajado.
Hay otra opción cuando FEC puede ayudar.

Además de retransmitir a través de Retransmit Time Out, Fast Retransmit, también hay una
sonda de pérdida de cola . Esto es así cuando envía datos, y la cola se ha ido. Es decir, envió parte de los datos, envió el quinto paquete, ya llegó. Luego, los paquetes comenzaron a desaparecer, por ejemplo, porque la red falló. Los paquetes desaparecen, desaparecen, y recibió un acuse de recibo solo para el quinto paquete.
Para comprender si se han alcanzado estos datos, después de un tiempo comienza a hacer TLP (sonda de pérdida de cola), pregunte si se recibe el final. El hecho es que la transferencia de datos ha finalizado y no está enviando nada, entonces la retransmisión rápida no funcionará. Para solucionar esto, haga un TLP.
Puede agregar FEC a TLP. Puede ver todos los paquetes que no llegaron, contar la paridad en ellos y enviar TLP con algún paquete de paridad.
Todo esto es genial, parece funcionar. Pero hay tal problema.
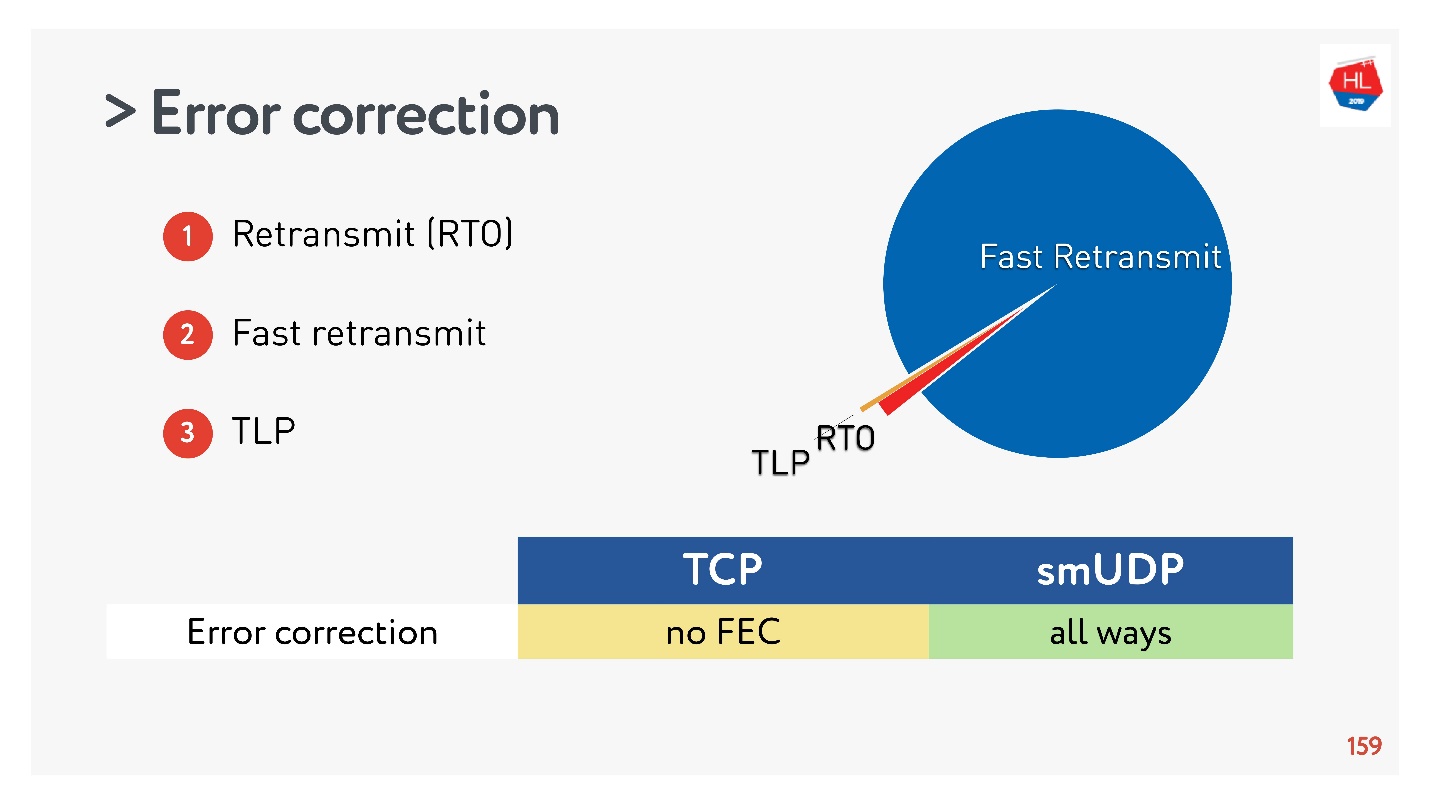
Recopilamos estadísticas, y resultó que el 98% de los errores se reparan a través de la retransmisión rápida. El resto se repara mediante Retransmit Time Out, y menos del 1% a través de TLP. Si arregla algo más FEC, será menos del 0.5%.
TCP no es compatible con FEC. En UDP no es difícil hacer esto, pero en el caso general, los algoritmos de recuperación TCP estándar son suficientes.
Rendimiento
Sería posible no dañar el rendimiento al comparar TCP con UDP.
TCP es un protocolo muy antiguo con muchas optimizaciones diferentes, por ejemplo, LSO (descarga de segmento grande) y zerocopy. Ahora para UDP no está disponible. Por lo tanto, el rendimiento UDP es solo del 20% en relación con el TCP de los mismos servidores. Pero ya hay soluciones listas para
usar (
UDP GSO ,
zerocopy ) que permiten a Linux soportar esto.
El principal problema que soporta la optimización para zerocopy y LSO es que se pierde el ritmo.

Tiempo de comercialización o lo que mató a TCP
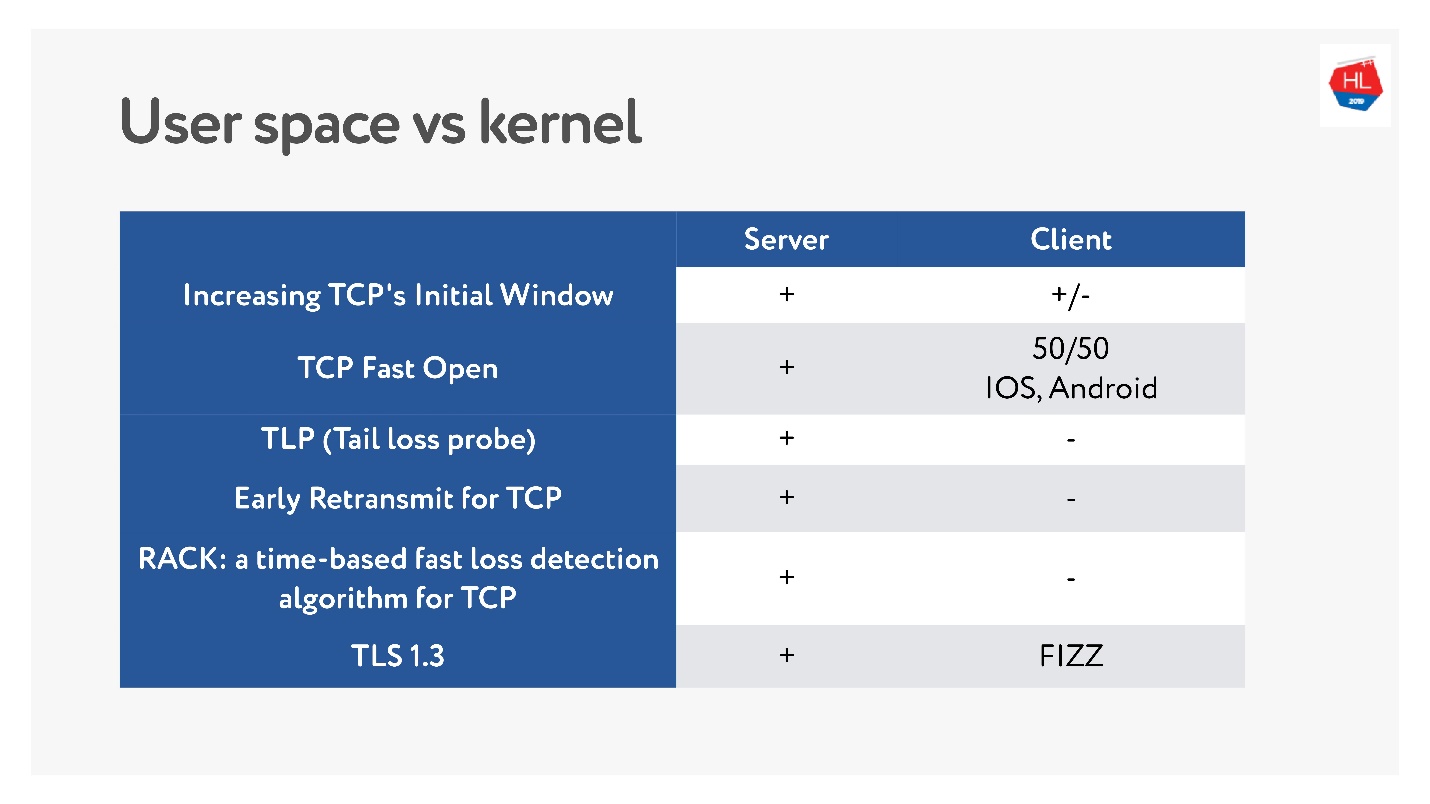
Recientemente, cuando las redes inalámbricas móviles se hicieron populares, aparecieron muchos estándares TCP diferentes: TLP, TFO, nuevo control de congestión, RACK, BBR y más.

Pero el problema principal es que muchos de ellos no se están implementando, porque se dice que TCP está osificado. En muchos casos, los operadores miran los paquetes TCP y esperan ver lo que esperan. Por lo tanto, es muy difícil cambiar.
Además, los clientes móviles se actualizan durante mucho tiempo y no podemos entregar estas actualizaciones. Si observa cuáles son las últimas actualizaciones recientes disponibles en el cliente y qué hay en el servidor, puede decir que no hay casi nada en el cliente.
Por lo tanto, la decisión de escribir un protocolo en el espacio del usuario, al menos mientras acumule todas estas características, no parece tan mala.

Con TCP, las funciones han estado funcionando durante años. Para su protocolo UDP, puede actualizar la versión literalmente en una actualización del cliente y el servidor. Pero deberá agregar la negociación de la versión.
TCP vs UDP hecho a sí mismo. Pelea final
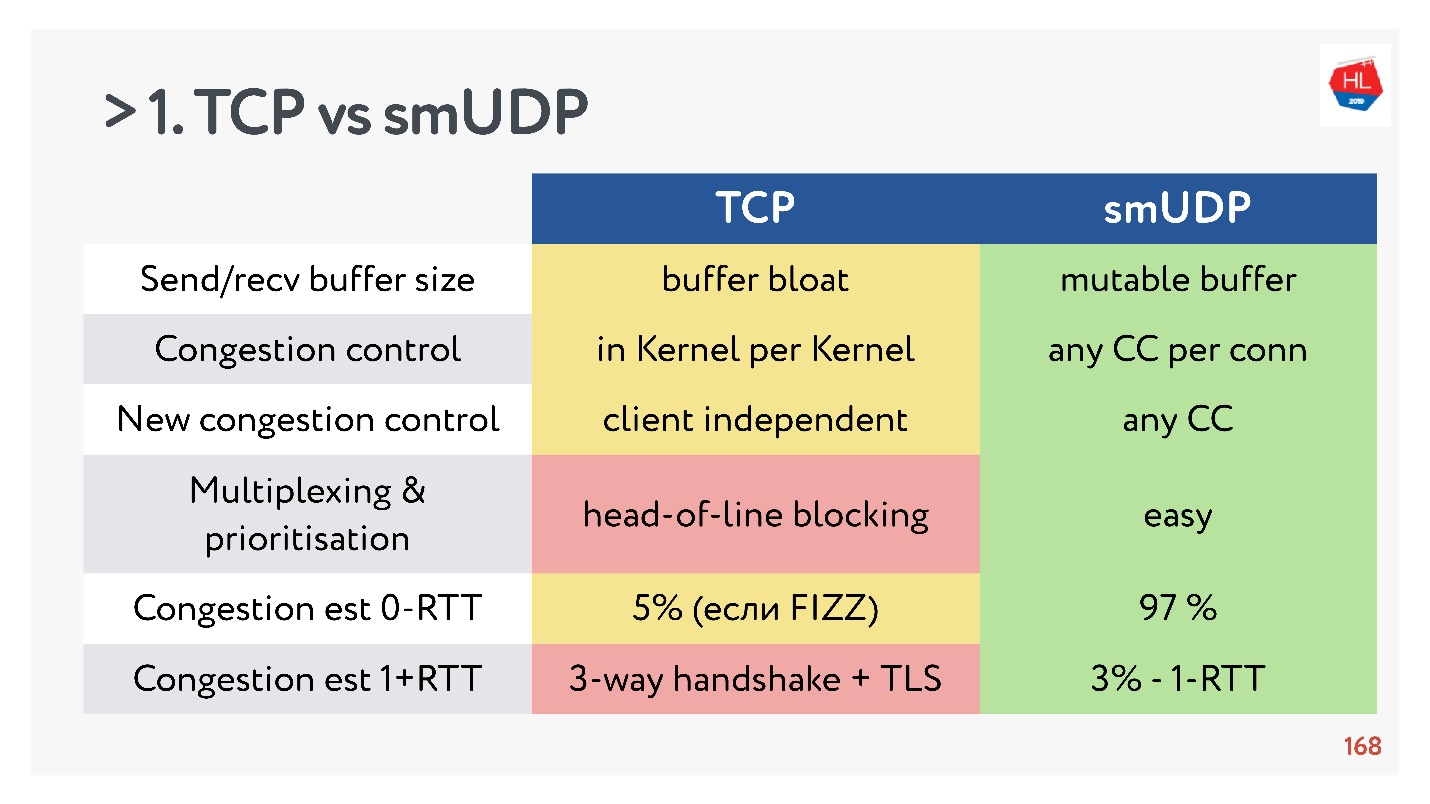
- Búfer de envío / recepción: se puede hacer un búfer mutable para su protocolo, habrá problemas con el búfer hinchado con TCP.
- Control de congestión que puede utilizar existente. En UDP son cualquiera.
- El nuevo control de congestión es difícil de agregar a TCP, porque necesita modificar el reconocimiento, no puede hacerlo en el cliente.
- La multiplexación es un tema crítico. El bloqueo de encabezado de línea ocurre, cuando pierde un paquete, no puede multiplexar a TCP. Por lo tanto, HTTP2.0 sobre TCP no debería dar un aumento serio.
- Los casos en que puede obtener una configuración de conexión para 0-RTT en TCP son extremadamente raros, del orden del 5% y del orden del 97% para UDP de fabricación propia.

- La migración de IP no es una característica tan importante, pero en el caso de suscripciones complejas y el estado de almacenamiento en el servidor, definitivamente es necesaria, pero no se implementa en TCP.
- La desvinculación de Nat no está a favor de UDP. En este caso, UDP a menudo necesita hacer paquetes de ping-pong.
- El ritmo de paquetes en UDP es simple, aunque no hay optimización, en TCP esta opción no funciona.
- MTU y corrección de errores son comparables.
- La velocidad de TCP, por supuesto, es más rápida que UDP ahora, si está distribuyendo una tonelada de tráfico. Pero luego algunas optimizaciones tardan mucho en entregarse.
Si recopila todo lo más importante, entonces UDP, más probablemente, tiene más ventajas que desventajas.
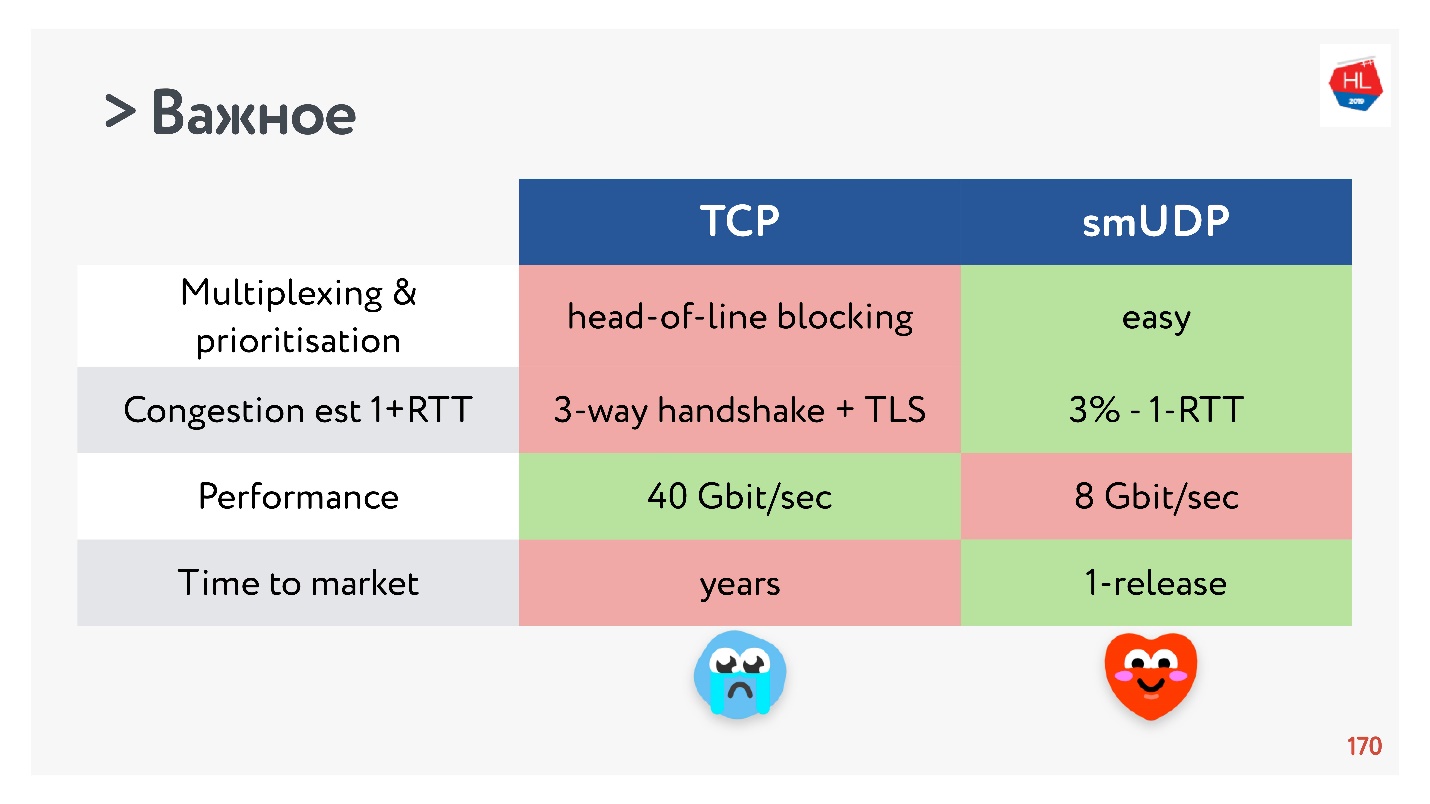 ¡Elige UDP!
¡Elige UDP!Probar UDP hecho a sí mismo en usuarios
Hemos creado un banco de pruebas.
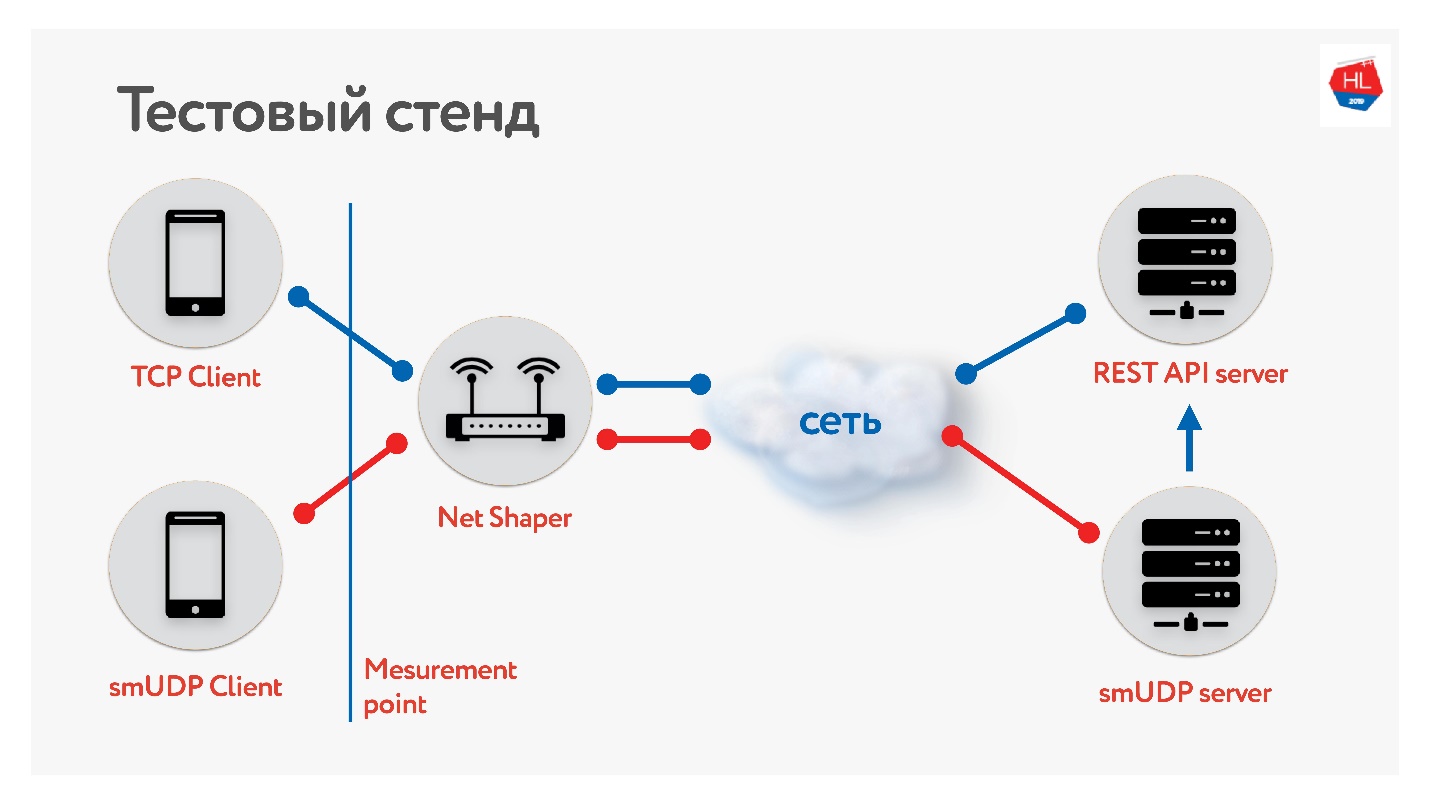
Hay un cliente en TCP y UDP. Normalizamos el tráfico a través de Net Shaper, enviado a Internet y al servidor. Un servicio REST API, el segundo con UDP. Y UDP va a la misma API REST dentro del mismo centro de datos para verificar los datos. Recopilamos diferentes perfiles de nuestros clientes móviles y
lanzamos la prueba .

Al medir el promedio sobre el portal, vimos que pudimos reducir el tiempo de llamar a la API en un 10%, las imágenes en un 7%. La actividad de los usuarios creció solo un 1%, pero no nos rendimos, creemos que será mejor.

En términos de cargas, ahora tenemos alrededor de 10 millones de usuarios en nuestro UDP hecho a sí mismo, tráfico de hasta 80 Gb / s, 6 millones de paquetes por segundo y 20 servidores sirven para esto.
Lista de verificación UDP
Si va a escribir su protocolo, necesita una lista de verificación:
- Ritmo
- Descubrimiento de MTU.
- Se requieren correcciones de errores .
- Control de flujo y control de congestión.
- Opcionalmente, puede admitir la migración de IP, TLP es fácil.
Recuerde que los canales son asimétricos, y mientras recibe datos del servidor, su carga puede estar inactiva, intente usarla.
QUIC
Sería deshonesto decir que Google no lo hizo.

Hay un protocolo QUIC que Google implementó bajo HTTP 2.0, que admite casi lo mismo.
¿Por qué QUIC no es tan rápido?
Cuando salió QUIC, se odiaba mucho el hecho de que Google dice que todo funciona más rápido y "lo medí en casa en una computadora, funciona más lento".

Este
artículo tiene un montón de imágenes y medidas.
Bueno, resulta que hicimos todo esto en vano, ¿la gente nos midió? Hay mediciones reales en el hogar, incluso con ejemplos de código.

De hecho, no habrá mejoras hasta que paralelice las solicitudes, trabaje en redes reales y hasta que las pérdidas de paquetes se dividan en pérdida de congestión y pérdida aleatoria. Necesitamos una emulación real de una red real.
Pero hay un aspecto positivo, dicen, QUIC no es ni mejor ni peor. Por lo tanto, en redes perfectas, QUIC funciona bien.
El futuro
Google recientemente nombró HTTP 2.0 sobre QUIC HTTP 3, para no confundirlo, porque HTTP 2.0 podría estar sobre TCP y QUIC. Ahora es HTTP 3.
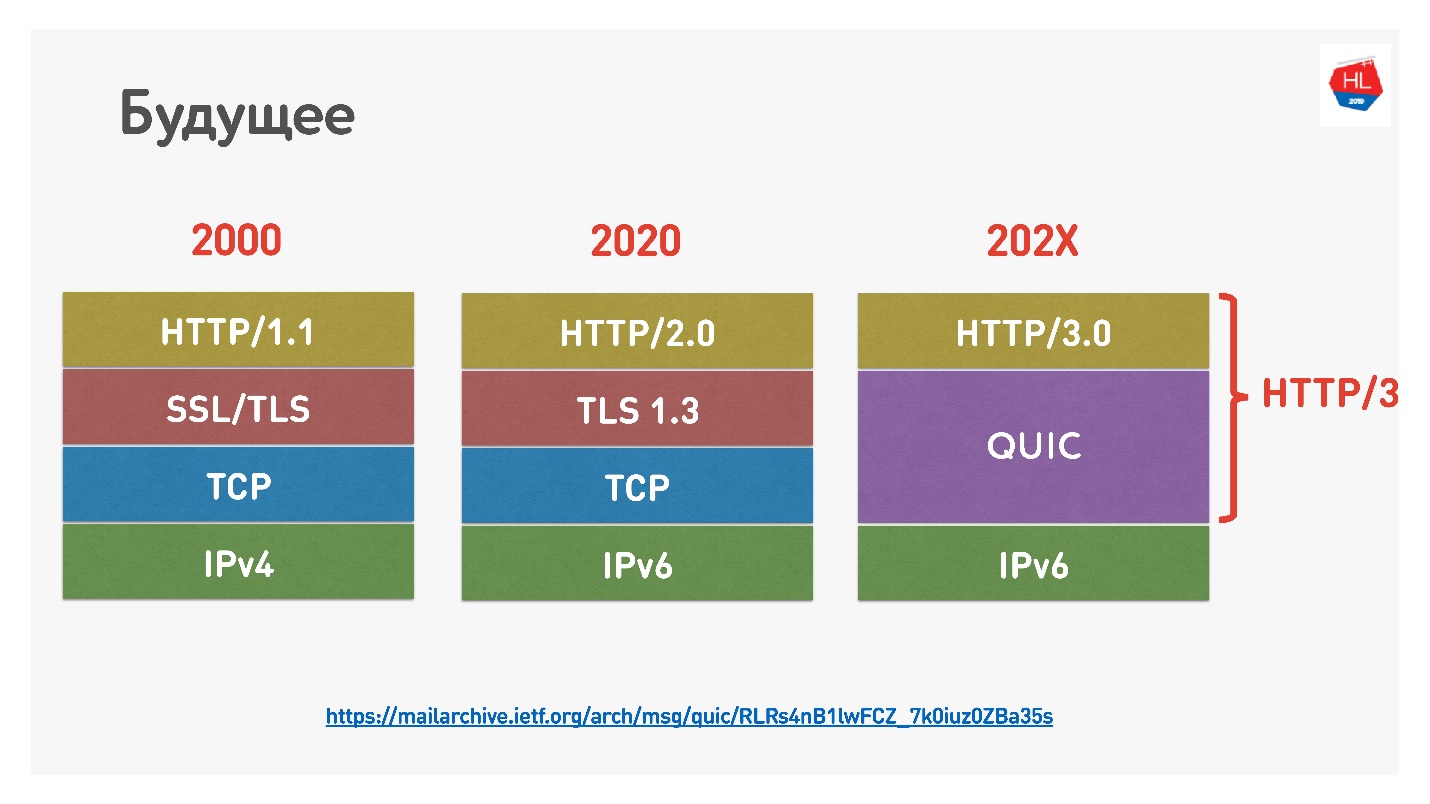
También hubo
Google QUIC , esto es QUIC, que se implementa en Chrome, e iQUIC, un QUIC estandarizado. El QUIC estandarizado no se implementó en ninguna parte, los servidores iQUIC estándar no se dieron la mano con Google QUIC. Ahora prometen resolver este problema, y pronto estará disponible.
QUIC está en todas partes
Si todavía no cree que TCP está muerto, le diré que cuando usa Chrome, Android y pronto iOS, y va a google, youtube, etc., entonces usa QUIC y UDP (
prueba de enlace ).
QUIC ahora es:
- 1.9% de todos los sitios web;
- 12% de todo el tráfico;
- 30% del tráfico de video en redes móviles.
¿Cómo verificar que usas QUIC si no crees? Abrir en Chrome Wireshark. Estaba buscando iQUIC, no lo he encontrado en ningún lado, pero sucede GQUIC.
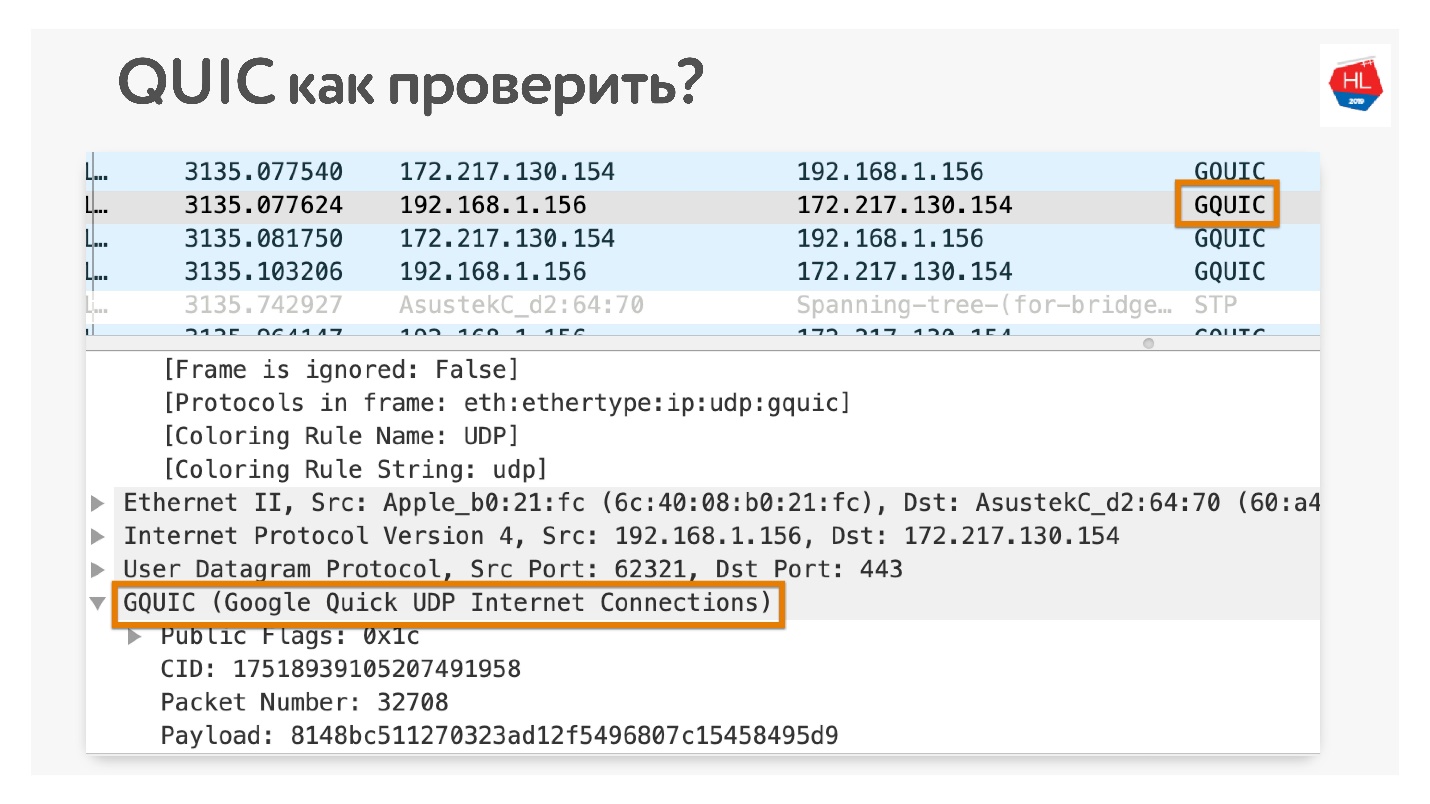
También puede conectarse en línea en su navegador y también ver qué GQUIC está allí.

Un poco mas de futuro
Multipath nos espera pronto.
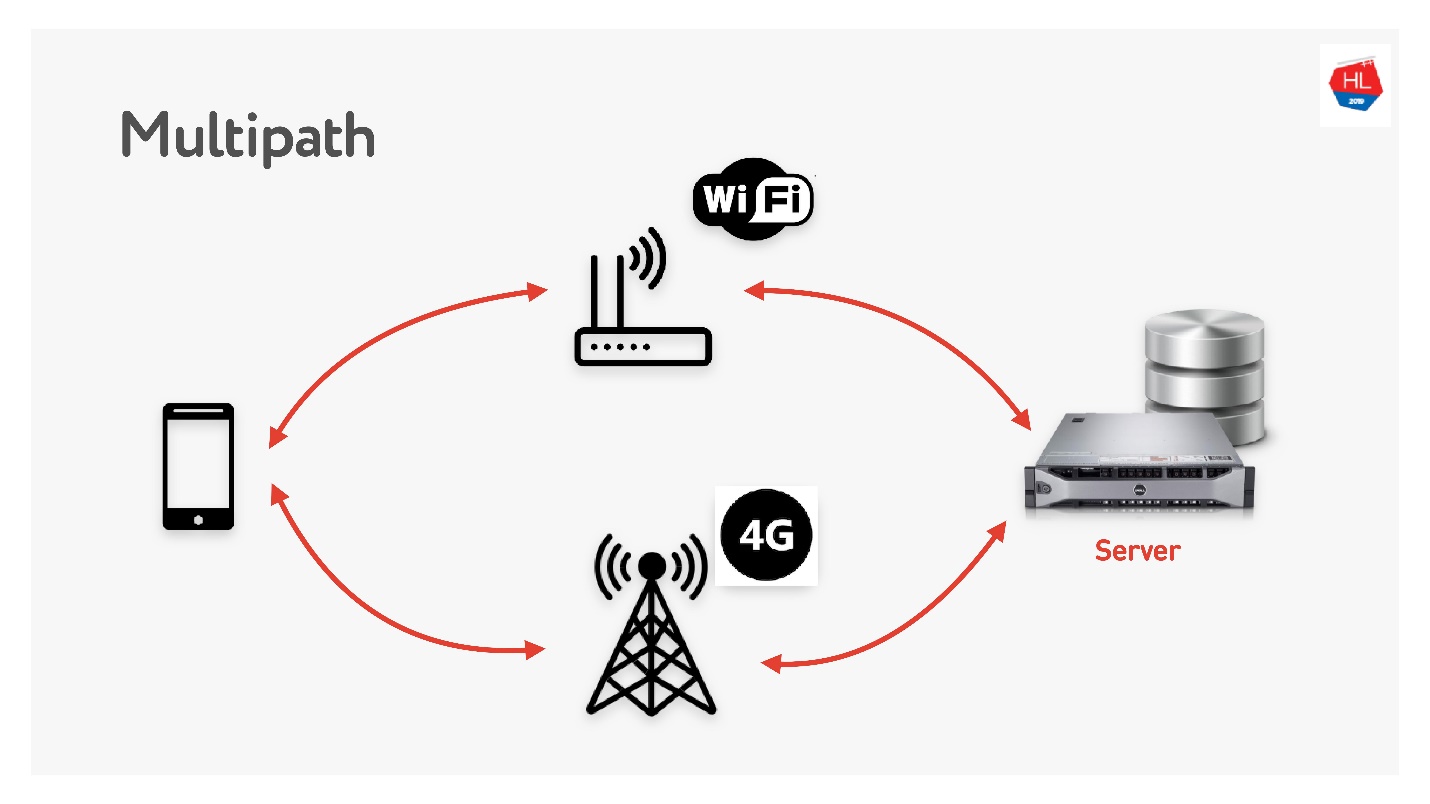
Cuando tiene un cliente móvil que tiene Wi-Fi y 3G, puede usar ambos canales. Multipath TCP ahora está en desarrollo y estará disponible pronto en el kernel de Linux. Obviamente, no llegará a los clientes pronto, creo que se puede hacer en UDP mucho más rápido.
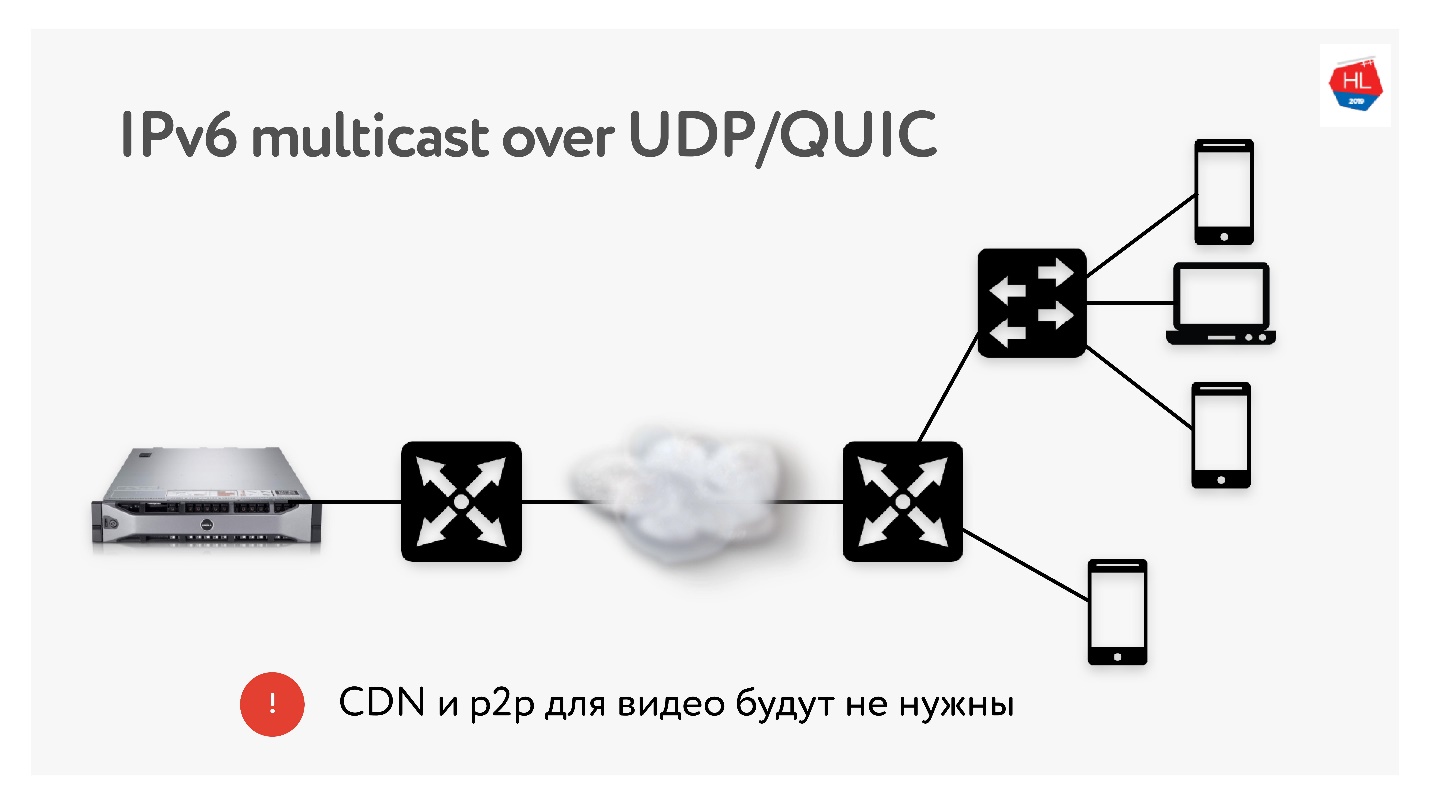
Dado que realizamos muchas traducciones de 3 TB cada una, a menudo utilizamos tecnologías como la distribución de CDN y p2p, cuando se necesita entregar el mismo contenido a muchos usuarios de todo el mundo.
En IPv6 hay multidifusión con UDP, lo que permitirá entregar paquetes a varios usuarios suscritos a la vez. Por lo tanto, creo que las tecnologías CDN y p2p no serán necesarias en el futuro cercano si entregamos todo el contenido mediante multidifusión a IPv6.
Conclusiones
Espero que entiendas:
- Cómo funciona realmente la red, y que TCP se puede repetir sobre UDP y hacerlo mejor.
- Ese TCP no es tan malo si lo configura correctamente, pero realmente se rindió y casi ya no se está desarrollando.
- No confíes en los que odian UDP que dicen que no trabajarán en el espacio del usuario. Todos estos problemas pueden resolverse. Pruébalo, este es el futuro cercano.
- Si no lo cree, puede y debe tocar la red con las manos. Mostré cómo se puede verificar casi todo.
¿Leíste todo y descubriste qué sigue?
- Configure el protocolo (TCP, UDP, no importa) para la situación (perfil de red + perfil de carga).
- Use las recetas TCP que le dije: TFO, búfer de envío / recepción, TLS1.3, CC ...
- Haga sus protocolos UDP si tiene los recursos.
- Si ha hecho su UDP, verifique en la lista de verificación UDP que ha hecho todo lo que necesita. Olvidando cualquier tontería como el ritmo, no funcionará.
Si no tiene los recursos, prepare su infraestructura para QUIC. Tarde o temprano él vendrá a ti.
Estamos determinando el futuro. Decidimos qué protocolos usar. Si desea usar QUIC, úselo, si desea su UDP o permanecer en TCP, decida el futuro usted mismo.
Enlaces utiles
Hasta el 7 de septiembre, aún puede enviar una solicitud para Moscow HighLoad ++ y compartir cómo prepara sus servicios para grandes cargas. Pero el programa ya se está llenando gradualmente, desde Odnoklassniki se han recibido informes sobre la nueva arquitectura de la gráfica de amigos, sobre la optimización del servicio de regalos para grandes cargas y sobre qué hacer si ha optimizado todo y los datos no llegan al usuario lo suficientemente rápido.