
Hace dos años, Sundar Pichai, jefe de Google, dijo que la compañía de mobile-first se convierte primero en AI y se enfoca en el aprendizaje automático. Un año después, se lanzó el Kit de aprendizaje automático, un conjunto de herramientas con las que puedes usar ML de manera efectiva en iOS y Android.
Se habla mucho sobre el Kit ML en los Estados Unidos, pero casi no hay información en ruso. Y dado que lo usamos para algunas tareas en Yandex.Money, decidí compartir mi experiencia y mostrar con ejemplos cómo usarlo para hacer cosas interesantes.
Mi nombre es Yura. El año pasado estuve trabajando en el equipo Yandex.Money en una billetera móvil. Hablaremos sobre el aprendizaje automático en dispositivos móviles.
Nota Equipo editorial: esta publicación es un recuento del informe de Yuri Chechetkin "Desde el móvil primero hasta la IA primero" del Yandex.Money metap Android Paranoid .
¿Qué es el Kit ML?
Este es el SDK móvil de Google que facilita el uso del aprendizaje automático en dispositivos Android e iOS. No es necesario ser un experto en ML o en inteligencia artificial, porque en unas pocas líneas de código puede implementar cosas muy complejas. Además, no es necesario saber cómo funcionan las redes neuronales o la optimización del modelo.
¿Qué puede hacer el Kit ML?
Las características básicas son bastante amplias. Por ejemplo, puede reconocer texto, caras, buscar y rastrear objetos, crear etiquetas para imágenes y sus propios modelos de clasificación, escanear códigos de barras y etiquetas QR.
Ya utilizamos el reconocimiento de código QR en la aplicación Yandex.Money.
También hay un kit ML
- Reconocimiento de hito;
- Definición del idioma en el que se escribe el texto;
- Traducción de textos en el dispositivo;
- Respuesta rápida a una carta o mensaje.
Además de una gran cantidad de métodos listos para usar, hay soporte para modelos personalizados, lo que prácticamente ofrece infinitas posibilidades, por ejemplo, puede colorear fotografías en blanco y negro y hacerlas colorear.
Es importante que no necesite utilizar ningún servicio, API o back-end para esto. Todo se puede hacer directamente en el dispositivo, por lo que no cargamos el tráfico de usuarios, no obtenemos un montón de errores relacionados con la red, no tenemos que procesar un montón de casos, por ejemplo, falta de Internet, pérdida de conexión, etc. Además, en el dispositivo funciona mucho más rápido que a través de una red.

Reconocimiento de texto
Tarea: dada una fotografía, debe hacer que el texto circule en un rectángulo.
Comenzamos con la dependencia en Gradle. Es suficiente para conectar una dependencia, y estamos listos para trabajar.
dependencies {
Vale la pena especificar metadatos que indiquen que el modelo se descargará al dispositivo mientras se descarga la aplicación desde Play Market. Si no hace esto y accede a la API sin un modelo, obtendremos un error y el modelo deberá descargarse en segundo plano. Si necesita usar varios modelos, es recomendable especificarlos separados por comas. En nuestro ejemplo, usamos el modelo OCR, y el nombre del resto se puede encontrar en la documentación .
<application ...> ... <meta-data android:name="com.google.firebase.ml.vision.DEPENDENCIES" android:value="ocr" /> <!-- To use multiple models: android:value="ocr,model2,model3" --> </application>
Después de la configuración del proyecto, debe establecer los valores de entrada. ML Kit funciona con el tipo FirebaseVisionImage, tenemos cinco métodos, cuya firma escribí a continuación. Convierten los tipos habituales de Android y Java en los tipos de ML Kit, con los que es conveniente trabajar.
fun fromMediaImage(image: Image, rotation: Int): FirebaseVisionImage fun fromBitmap(bitmap: Bitmap): FirebaseVisionImage fun fromFilePath(context: Context, uri: Uri): FirebaseVisionImage fun fromByteBuffer( byteBuffer: ByteBuffer, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage fun fromByteArray( bytes: ByteArray, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage
Preste atención a los dos últimos: funcionan con una matriz de bytes y con un búfer de bytes, y necesitamos especificar metadatos para que ML Kit comprenda cómo manejarlo todo. Los metadatos, de hecho, describen el formato, en este caso, el ancho y la altura, el formato predeterminado, IMAGE_FORMAT_NV21 y la rotación.
val metadata = FirebaseVisionImageMetadata.Builder() .setWidth(480) .setHeight(360) .setFormat(FirebaseVisionImageMetadata.IMAGE_FORMAT_NV21) .setRotation(rotation) .build() val image = FirebaseVisionImage.fromByteBuffer(buffer, metadata)
Cuando se recopilan los datos de entrada, cree un detector que reconozca el texto.
Hay dos tipos de detectores, en el dispositivo y en la nube, se crean literalmente en una línea. Vale la pena señalar que el detector en el dispositivo solo funciona con inglés. El detector de nubes admite más de 20 idiomas; deben especificarse en el método setLanguageHints especial.
El número de idiomas admitidos es más de 20, todos están en el sitio web oficial. En nuestro ejemplo, solo inglés y ruso.
Después de tener una entrada y un detector, simplemente llame al método processImage en este detector. Obtenemos el resultado en forma de una tarea, en la que colgamos dos devoluciones de llamada: por éxito y por error. La expresión estándar llega a un error, y el tipo FirebaseVisionText llega al éxito de onSuccessListener.
val result: Task<FirebaseVisionText> = detector.processImage(image) .addOnSuccessListener { result: FirebaseVisionText ->
¿Cómo trabajar con el tipo FirebaseVisionText?
Consiste en bloques de texto (TextBlock), los que a su vez consisten en líneas (Línea) y líneas de elementos (Elemento). Están anidados el uno en el otro.
Además, cada una de estas clases tiene cinco métodos que devuelven datos diferentes sobre el objeto. Un rectángulo es el área donde se encuentra el texto, la confianza es la precisión del texto reconocido, los puntos de esquina son los puntos de esquina en el sentido de las agujas del reloj, comenzando desde la esquina superior izquierda, los idiomas reconocidos y el texto mismo.
FirebaseVisionText contains a list of FirebaseVisionText.TextBlock which contains a list of FirebaseVisionText.Line which is composed of a list of FirebaseVisionText.Element. fun getBoundingBox(): Rect
¿Para qué es esto?
Podemos reconocer tanto el texto completo de la imagen como sus párrafos individuales, piezas, líneas o solo palabras. Y como ejemplo, podemos iterar, en cada etapa tomar un texto, tomar los bordes de este texto y dibujar. Muy comodo
Tenemos la intención de utilizar esta herramienta en nuestra aplicación para reconocer tarjetas bancarias, cuyas etiquetas se encuentran no estándar. No todas las bibliotecas de reconocimiento de tarjetas funcionan bien, y para tarjetas personalizadas, el Kit ML sería muy útil. Como hay poco texto, es muy fácil procesarlo de esta manera.
Reconocimiento de objetos en la foto.
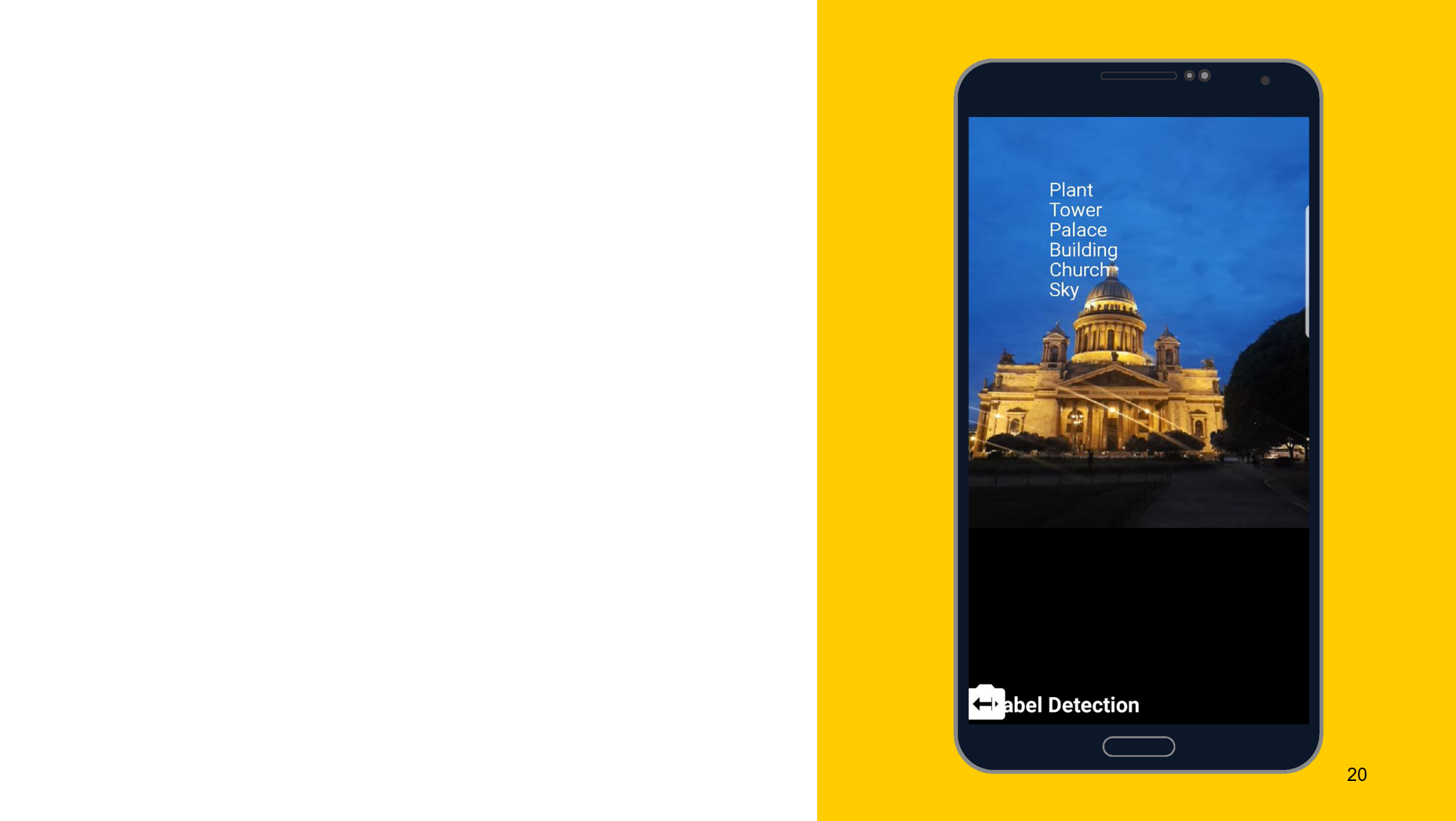
Usando la siguiente herramienta como ejemplo, me gustaría mostrar que el principio de funcionamiento es aproximadamente el mismo. En este caso, reconocimiento de lo que se representa en el objeto. También creamos dos detectores, uno en el dispositivo y el otro en la nube, podemos especificar la precisión mínima como parámetros. El valor predeterminado es 0.5, indicado 0.7, y listo para funcionar. También obtenemos el resultado en forma de FirebaseImageLabel, esta es una lista de etiquetas, cada una de las cuales contiene una identificación, descripción y precisión.
Harold ocultando la felicidad

Puede intentar comprender qué tan bien Harold oculta el dolor y si es feliz al mismo tiempo. Utilizamos una herramienta de reconocimiento facial, que, además de reconocer los rasgos faciales, puede decir qué tan feliz es una persona. Al final resultó que, Harold está 93% feliz. O esconde muy bien el dolor.

De fácil a fácil, pero un poco más complicado. Modelos a medida.
Tarea: clasificación de lo que se representa en la foto.
Tomé una foto de la computadora portátil y reconocí el módem, la computadora de escritorio y el teclado. Suena como la verdad. Hay mil clasificadores, y él toma tres de ellos que mejor describen esta foto.

Al trabajar con modelos personalizados, también podemos trabajar con ellos tanto en el dispositivo como a través de la nube.
Si trabajamos a través de la nube, debe ir a Firebase Console, a la pestaña ML Kit y tocar personalizado, donde podemos cargar nuestro modelo en TensorFlow Lite, porque ML Kit funciona con modelos con esta resolución. Si lo usamos en un dispositivo, simplemente podemos poner el modelo en cualquier parte del proyecto como un activo.
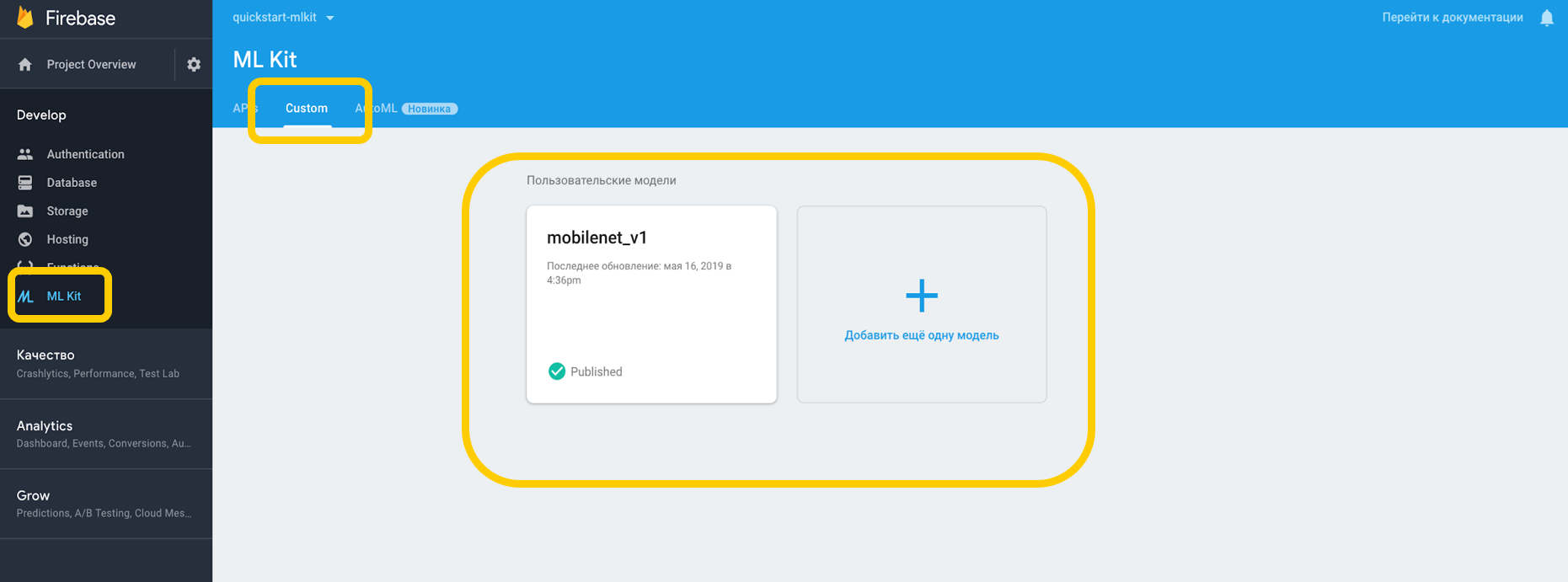
Señalamos la dependencia del intérprete, que puede trabajar con modelos personalizados, y no nos olvidemos del permiso para trabajar con Internet.
<uses-permission android:name="android.permission.INTERNET" /> dependencies {
Para aquellos modelos que están en el dispositivo, debe indicar en Gradle que el modelo no debe comprimirse, ya que puede distorsionarse.
android {
Cuando hemos configurado todo en nuestro entorno, debemos establecer condiciones especiales, que incluyen, por ejemplo, el uso de Wi-Fi, también requieren carga y requieren que el dispositivo inactivo esté disponible con Android N; estas condiciones indican que el teléfono se está cargando o está en modo de espera.
var conditionsBuilder: FirebaseModelDownloadConditions.Builder = FirebaseModelDownloadConditions.Builder().requireWifi() if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) {
Cuando creamos un modelo remoto, establecemos las condiciones de inicialización y actualización, así como el indicador de si nuestro modelo debe actualizarse. El nombre del modelo debe coincidir con el que especificamos en la consola de Firebase. Cuando creamos el modelo remoto, debemos registrarlo en Firebase Model Manager.
val cloudSource: FirebaseRemoteModel = FirebaseRemoteModel.Builder("my_cloud_model") .enableModelUpdates(true) .setInitialDownloadConditions(conditions) .setUpdatesDownloadConditions(conditions) .build() FirebaseModelManager.getInstance().registerRemoteModel(cloudSource)
Hacemos los mismos pasos para el modelo local, especificamos su nombre, la ruta al modelo y lo registramos en Firebase Model Manager.
val localSource: FirebaseLocalModel = FirebaseLocalModel.Builder("my_local_model") .setAssetFilePath("my_model.tflite") .build() FirebaseModelManager.getInstance().registerLocalModel(localSource)
Después de eso, debe crear esas opciones donde especificamos los nombres de nuestros modelos, instalamos el modelo remoto, instalamos el modelo local y creamos un intérprete con estas opciones. Podemos especificar un modelo remoto o solo uno local, y el intérprete comprenderá con quién trabajar.
val options: FirebaseModelOptions = FirebaseModelOptions.Builder() .setRemoteModelName("my_cloud_model") .setLocalModelName("my_local_model") .build() val interpreter = FirebaseModelInterpreter.getInstance(options)
ML Kit no sabe nada sobre el formato de los datos de entrada y salida de los modelos personalizados, por lo que debe especificarlos.
Los datos de entrada son una matriz multidimensional, donde 1 es el número de imágenes, 224x224 es la resolución y 3 es una imagen RGB de tres canales. Bueno, el tipo de datos es bytes.
val input = intArrayOf(1, 224, 224, 3)
Los valores de salida son 1000 clasificadores. Establecemos el formato de los valores de entrada y salida en bytes con las matrices multidimensionales especificadas. Además de bytes, float, long, int también están disponibles.
Ahora establecemos los valores de entrada. Tomamos Bitmap, lo comprimimos a 224 por 224, lo convertimos a ByteBuffer y creamos valores de entrada usando FirebaseModelInput usando un generador especial.
val bitmap = Bitmap.createScaledBitmap(yourInputImage, 224, 224, true) val imgData = convertBitmapToByteBuffer(bitmap) val inputs: FirebaseModelInputs = FirebaseModelInputs.Builder() .add(imageData) .build()
Y ahora, cuando hay un intérprete, el formato de los valores de entrada y salida y los propios valores de entrada, podemos ejecutar la solicitud utilizando el método de ejecución. Transferimos todo lo anterior como parámetros, y como resultado obtenemos FirebaseModelOutput, que contiene un genérico del tipo que especificamos. En este caso, se trataba de una matriz de bytes, después de lo cual podemos comenzar a procesar. Este es exactamente el millar de clasificadores que solicitamos, y mostramos, por ejemplo, los 3 más adecuados.
interpreter.run(inputs, inputOutputOptions) .addOnSuccessListener { result: FirebaseModelOutputs -> val labelProbArray = result.getOutput<Array<ByteArray>>(0)
Implementación de un día
Todo es bastante fácil de implementar, y el reconocimiento de objetos con herramientas integradas se puede realizar en solo un día. La herramienta está disponible en iOS y Android, además, puede usar el mismo modelo TensorFlow para ambas plataformas.
Además, hay toneladas de métodos disponibles listos para usar que pueden cubrir muchos casos. La mayoría de las API están disponibles en el dispositivo, es decir, el reconocimiento funcionará incluso sin Internet.
Y lo más importante: soporte para modelos personalizados que se pueden usar como desee para cualquier tarea.
Enlaces utiles
Documentación del kit ML
Proyecto de demostración del kit Github ML
Aprendizaje automático para dispositivos móviles con Firebase (Google I / O'19)
Machine Learning SDK para desarrolladores móviles (Google I / O'18)
Creación de un escáner de tarjeta de crédito con Firebase ML Kit (Medium.com)