La primera tarea a la que se enfrentan con mayor frecuencia los desarrolladores que comienzan a programar en JavaScript es cómo registrar eventos en el registro de la
console.log utilizando el método
console.log . En la búsqueda de información sobre la depuración del código JavaScript, encontrará cientos de artículos de blog, así como instrucciones sobre StackOverflow, que le aconsejan que "simplemente" envíe datos a la consola a través del método
console.log . Esta es una práctica tan común que tuve que introducir reglas para el control de calidad del código, como
no-console , para no dejar entradas de registro aleatorias en el código de producción. Pero, ¿qué sucede si necesita registrar específicamente un evento para proporcionar información adicional?
Este artículo analiza varias situaciones en las que necesita mantener registros; Muestra la diferencia entre los métodos
console.log y
console.error en Node.js y muestra cómo pasar la función de registro a las bibliotecas sin sobrecargar la consola del usuario.

Fundamentos teóricos de trabajar con Node.js
Los métodos
console.log y
console.error se pueden usar tanto en el navegador como en Node.js. Sin embargo, al usar Node.js, hay una cosa importante para recordar. Si crea el siguiente código en Node.js usando un archivo llamado
index.js ,

y luego ejecutarlo en la terminal usando el
node index.js , luego los resultados de la ejecución del comando se ubicarán uno encima del otro:

A pesar de que parecen similares, el sistema los procesa de manera diferente. Si mira la sección sobre el funcionamiento de la
console en la
documentación de Node.js , resulta que
console.log imprime el resultado a través de
stdout , y
console.error imprime a través de
stderr .
Cada proceso puede funcionar con tres flujos (
stream ) de forma predeterminada:
stdin ,
stdout y
stderr . La secuencia
stdin procesa la entrada para un proceso, por ejemplo, clics de botón o salida redirigida (más sobre esto a continuación). El flujo de salida estándar
stdout es para la salida de datos de la aplicación. Finalmente, el flujo de error estándar
stderr está diseñado para mostrar mensajes de error. Si necesita averiguar para qué
stderr y cuándo usarlo, lea
este artículo .
En resumen, se puede usar para usar los operadores de redirección (
> ) y de canalización (
| ) para trabajar con errores e información de diagnóstico por separado de los resultados reales de la aplicación. Si el operador
> permite redirigir la salida del resultado del comando a un archivo, entonces usando el operador
2> puede redirigir la salida de la secuencia de error
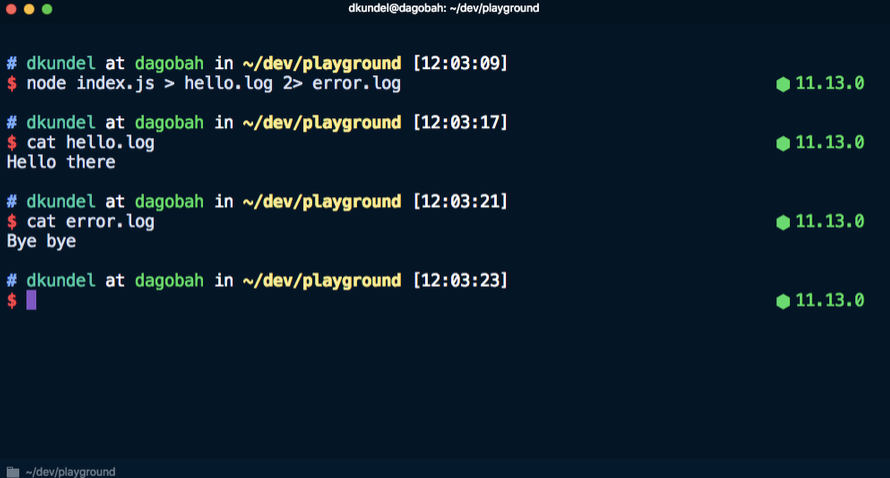
stderr a un archivo. Por ejemplo, este comando envía
Hello al archivo
hello.log y
Bye bye al archivo
error.log .

¿Cuándo necesito escribir eventos en el registro?
Ahora que hemos revisado los aspectos técnicos que subyacen en el registro, pasemos a varios escenarios en los que necesita registrar eventos. Por lo general, estos escenarios se dividen en una de varias categorías:
Este artículo solo trata los últimos tres escenarios basados en Node.js.
Registro para aplicaciones de servidor
Existen varios motivos para registrar eventos que ocurren en el servidor. Por ejemplo, el registro de solicitudes entrantes le permite obtener estadísticas sobre la frecuencia con la que los usuarios encuentran errores 404, cuál podría ser la razón de esto o qué aplicación de cliente de
User-Agent se está utilizando. También puede averiguar la hora en que ocurrió el error y su causa.
Para experimentar con el material proporcionado en esta parte del artículo, debe crear un nuevo catálogo para el proyecto. En el directorio del proyecto, cree
index.js para el código que se utilizará y ejecute los siguientes comandos para iniciar el proyecto e instalar
express :

Configuramos un servidor con middleware, que registrará cada solicitud en la consola utilizando el método
console.log . Ponemos las siguientes líneas en el archivo
index.js :
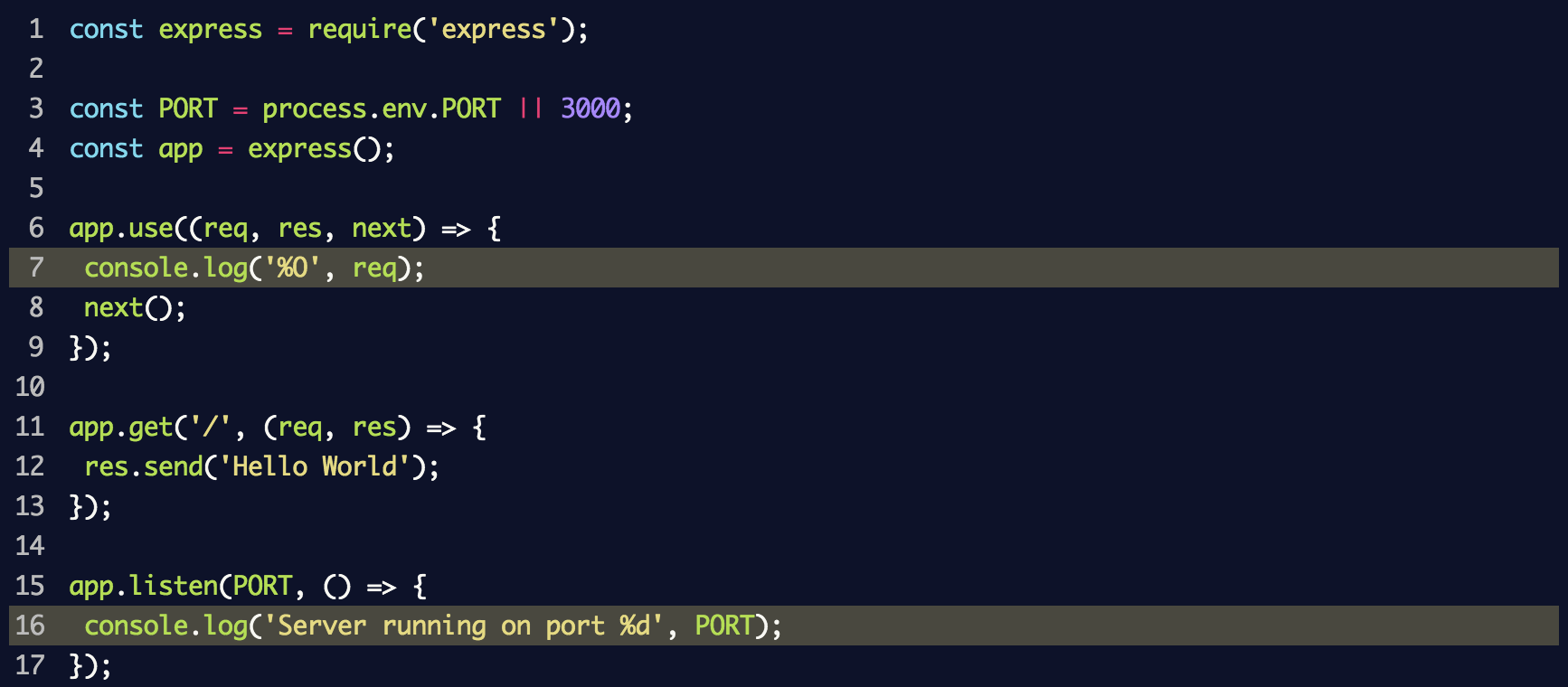
Esto usa
console.log('%O', req) para registrar todo el objeto en el registro. Desde el punto de vista de la estructura interna, el método
util.forma usa
util.forma t, que, además de
%O admite otros marcadores de posición. Se puede encontrar información sobre ellos en la
documentación de Node.js.Al ejecutar el
node index.js para iniciar el servidor y cambiar a
localhost : 3000, la consola muestra mucha información innecesaria:
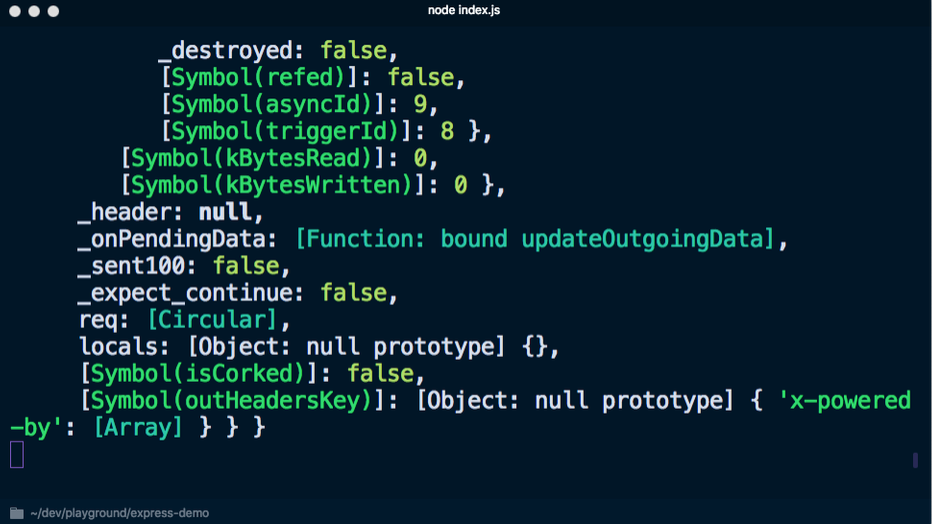
Si en su lugar usa
console.log('%s', req) para no mostrar el objeto por completo, no obtendrá mucha información:
Puede escribir su propia función de registro, que generará solo los datos necesarios, pero primero debe decidir qué información se necesita. A pesar de que el enfoque generalmente está en el contenido del mensaje, en realidad a menudo es necesario obtener información adicional, que incluye:
- marca de tiempo - para saber cuándo ocurrieron los eventos;
- nombre de la computadora / servidor: si se está ejecutando un sistema distribuido;
- identificador de proceso: si se ejecutan varios procesos de Nodo utilizando, por ejemplo,
pm2 ; - mensaje: un mensaje real con cierto contenido;
- seguimiento de pila: si se registra un error;
- Variables / información adicional.
Además, dado que, en cualquier caso, todo se envía a las secuencias
stdout y
stderr , es necesario mantener un diario en diferentes niveles, así como configurar y filtrar las entradas de diario según el nivel.
Esto se puede lograr obteniendo acceso a diferentes partes del
process y escribiendo varias líneas de código en JavaScript. Sin embargo, Node.js es notable porque ya tiene un ecosistema
npm y varias bibliotecas que se pueden usar para estos fines. Estos incluyen:
pinowinston ;- roarr
- bunyan (esta biblioteca no se ha actualizado durante dos años).
A menudo se prefiere el pino porque es rápido y tiene su propio ecosistema. Veamos cómo
pino puede ayudar con el registro. Otra ventaja de esta biblioteca es el paquete
express-pino-logger , que le permite registrar solicitudes.
Instale
pino y
express-pino-logger :

Después de eso, actualizamos el archivo
index.js para usar el registrador de eventos y el middleware:
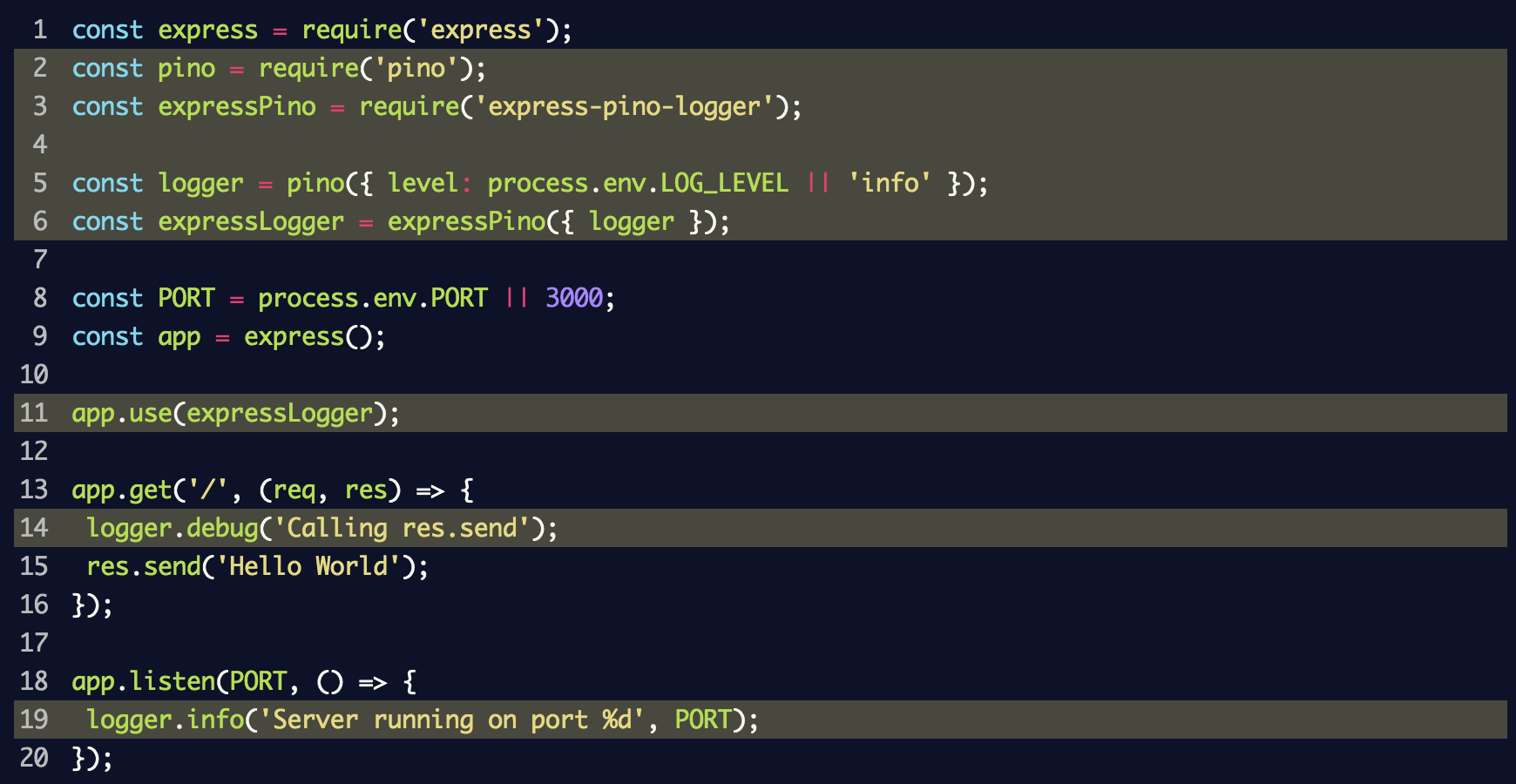
En este fragmento, creamos una instancia del
logger eventos para
pino y se lo pasamos a
express-pino-logger para crear un nuevo software de registro de eventos multiplataforma con el que puede llamar a
app.use . Además,
console.log reemplazado en
logger.info por
logger.info y
logger.debug agregado a la ruta para mostrar diferentes niveles del registro.
Si reinicia el servidor ejecutando repetidamente el
node index.js , obtendrá un resultado diferente en la salida, en el que cada línea / línea se generará en formato JSON. Nuevamente, vaya a
localhost : 3000 para ver otra nueva línea en formato JSON.
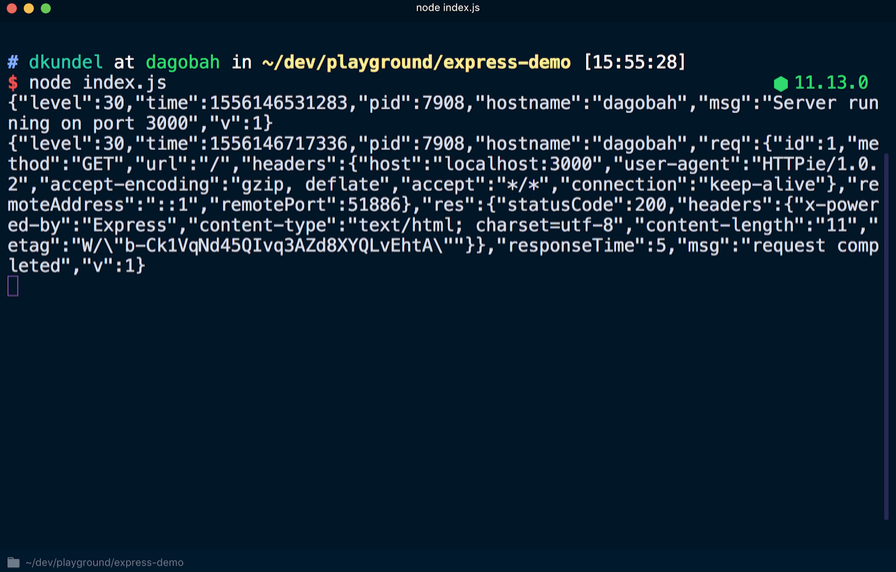
Entre los datos en formato JSON, puede encontrar la información mencionada anteriormente, como una marca de tiempo. También tenga en cuenta que el mensaje
logger.debug no se mostró. Para hacerlo visible, debe cambiar el nivel de registro predeterminado. Después de crear una instancia del registro de eventos del registrador, se estableció el valor
process.env.LOG_LEVEL . Esto significa que puede cambiar el valor o aceptar el valor de
info predeterminado.
LOG_LEVEL=debug node index.js ejecutar
LOG_LEVEL=debug node index.js , cambiamos el nivel de registro.
Antes de hacer esto, es necesario resolver el problema del formato de salida, que no es muy conveniente para la percepción en este momento. Este paso es intencional. De acuerdo con la filosofía
pino , por razones de rendimiento, es necesario transferir el procesamiento de entradas de diario a un proceso separado, pasando la salida (utilizando el operador
| ). El proceso implica traducir el resultado a un formato más conveniente para la percepción humana, o subirlo a la nube. Esta tarea se realiza mediante herramientas de transferencia llamadas
transports . Consulte la
documentación del kit de herramientas de transports y vea por qué los errores de
pino no se
stderr través de
stderr .
Para ver una versión más legible de la revista, use la herramienta
pino-pretty . Ejecutar en la terminal:

Todas las entradas de registro se transfieren mediante
| a disposición de
pino-pretty , debido a que la salida se "borra", que contendrá solo información importante que se muestra en diferentes colores. Si consulta
localhost : 3000 nuevamente, debería aparecer un mensaje de
debug depuración.
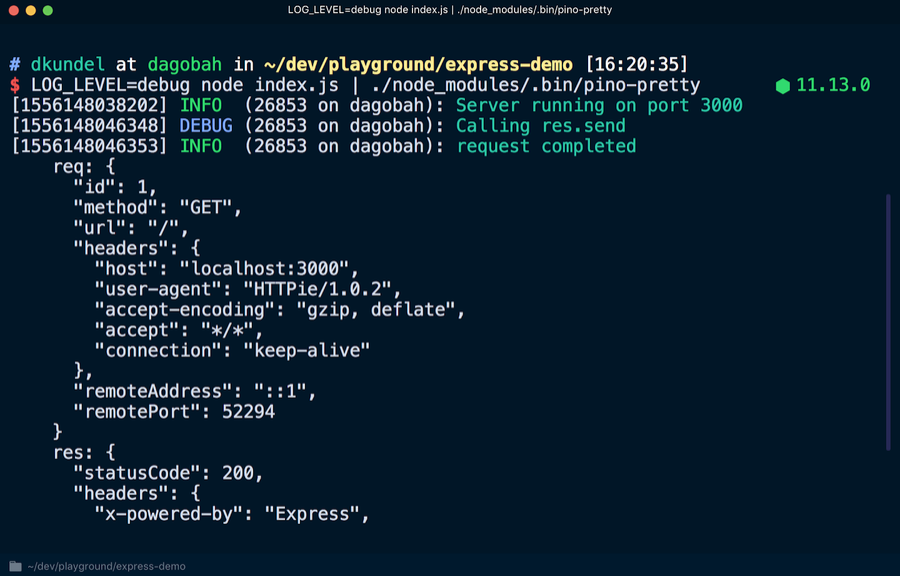
Para hacer que las entradas del diario sean más legibles o convertirlas, existen muchas herramientas de transmisión. Incluso se pueden mostrar usando emojis con
pino-colada . Estas herramientas serán útiles para el desarrollo local. Cuando el servidor está en producción, puede ser necesario transferir datos de registro usando
otra herramienta , escribirlos en el disco usando
> para su posterior procesamiento, o hacer dos operaciones al mismo tiempo usando un comando específico, por ejemplo
tee .
El
documento también habla sobre la rotación de archivos de registro, el filtrado y la escritura de datos de registro en otros archivos.
Diario de la biblioteca
Al explorar formas de organizar eficientemente el registro para las aplicaciones del servidor, puede usar la misma tecnología para sus propias bibliotecas.
El problema es que, en el caso de la biblioteca, es posible que deba mantener un registro con fines de depuración sin cargar la aplicación cliente. Por el contrario, el cliente debería poder activar el registro si es necesario depurarlo. De manera predeterminada, la biblioteca no debe registrar la salida, lo que le otorga al usuario este derecho.
Un buen ejemplo de esto es el marco
express . Muchos procesos tienen lugar en la estructura interna del marco
express , lo que puede causar interés en estudiarlo más profundamente durante la depuración de la aplicación. La
documentación del marco express dice que puede agregar
DEBUG=express:* al comienzo del comando de la siguiente manera:

Si aplica este comando a una aplicación existente, puede ver una gran cantidad de resultados adicionales que ayudarán con la depuración:
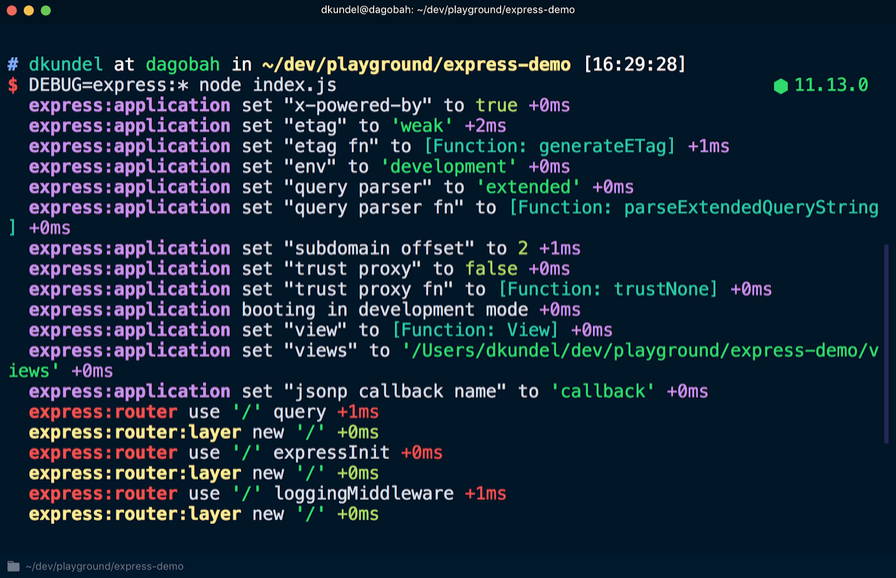
Esta información no se puede ver a menos que el registro de depuración esté activado. Hay un paquete de
debug para esto. Se puede usar para escribir mensajes en el "espacio de nombres", y si el usuario de la biblioteca incluye este espacio de nombres o un comodín que coincida con su
variable de entorno DEBUG , se mostrarán los mensajes. Primero necesita instalar la biblioteca de
debug :

Cree un nuevo archivo llamado
random-id.j s que simule la biblioteca y coloque el siguiente código:
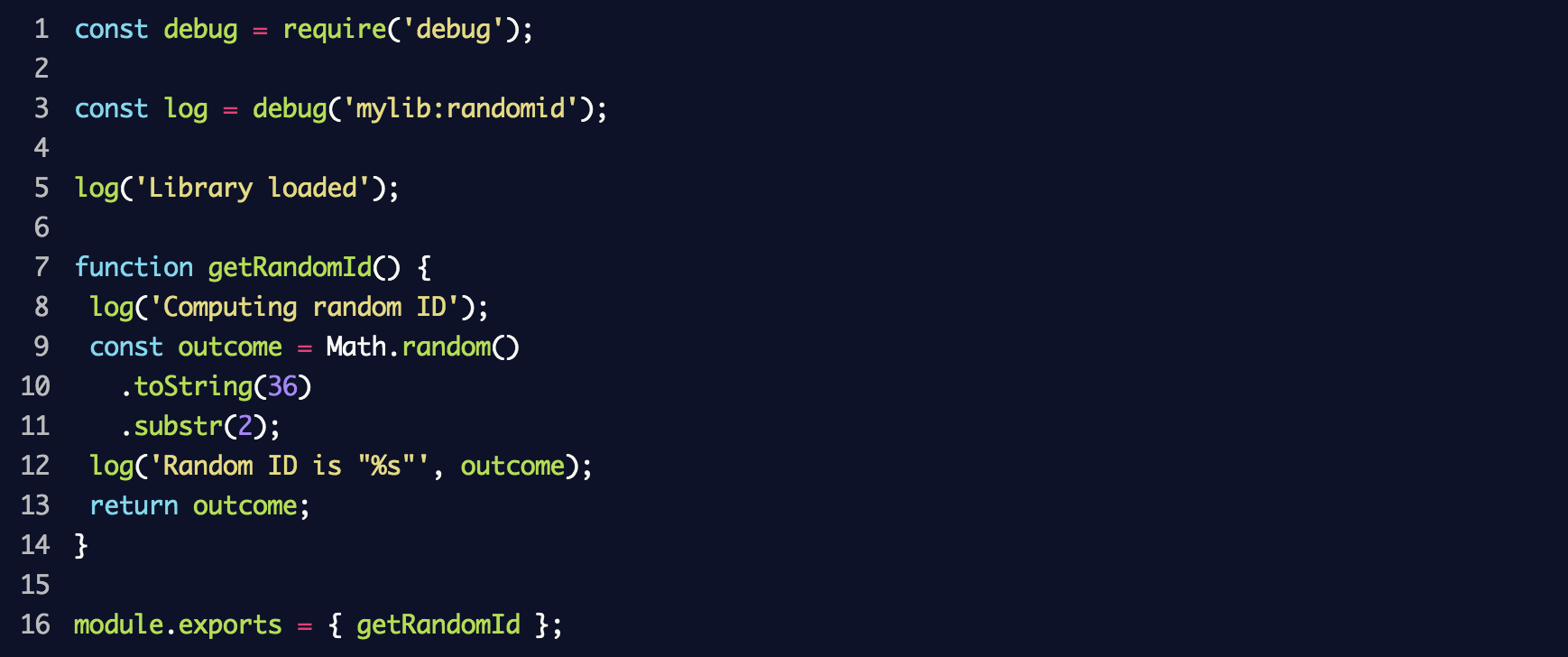
Como resultado, se creará un nuevo registrador de eventos de
debug con el
mylib:randomid , en el que se registrarán dos mensajes. Lo usamos en
index.js de la sección anterior:
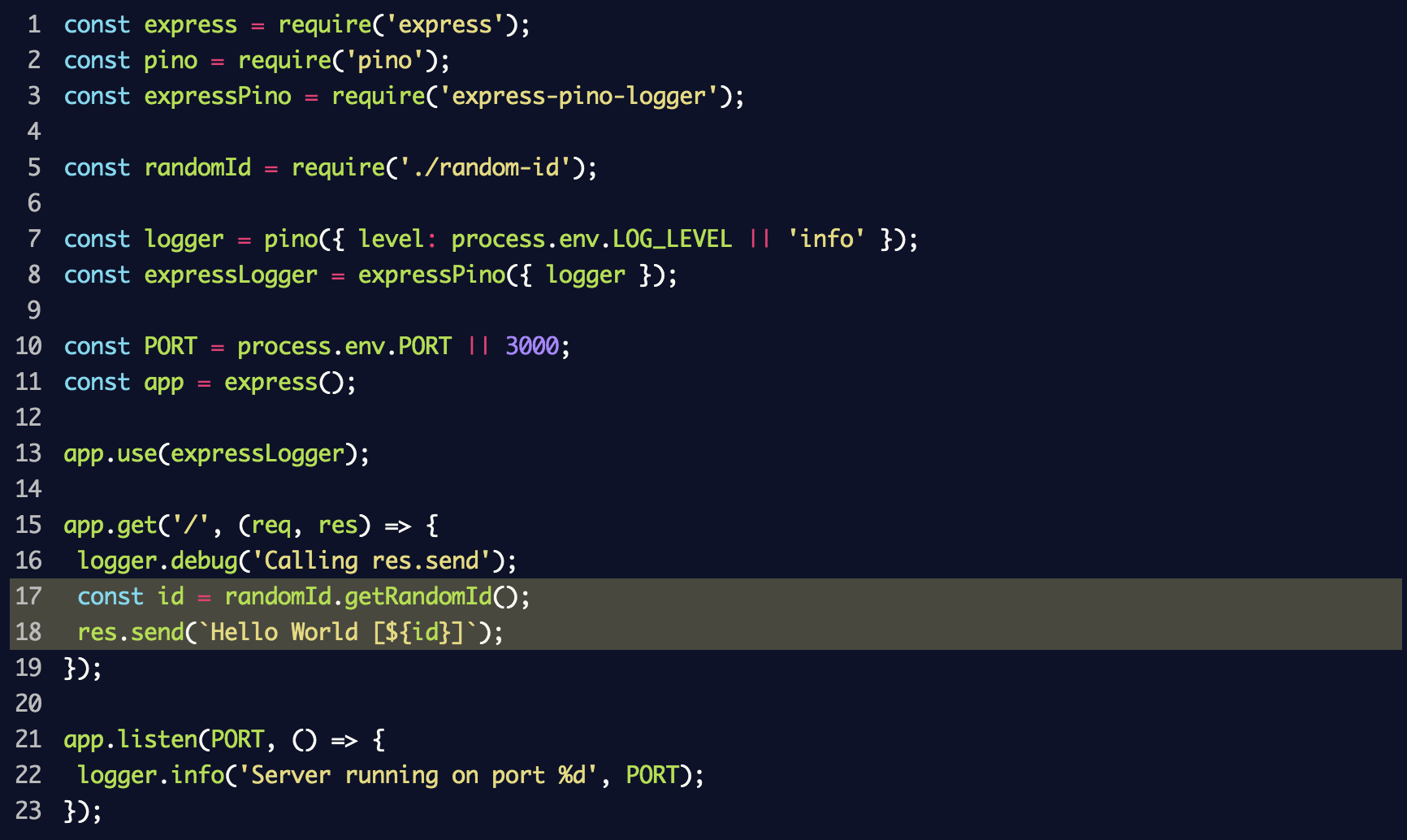
Si inicia el servidor nuevamente, agregando
DEBUG=mylib:randomid node index.js esta vez, se mostrarán las entradas del registro de depuración para nuestra "biblioteca":
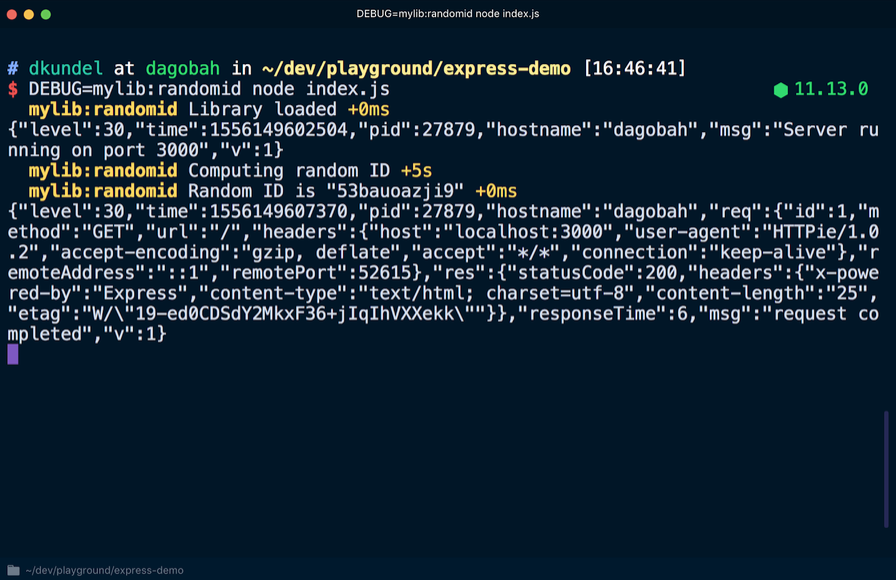
Si los usuarios de la biblioteca desean poner información de depuración en las entradas de registro de
pino , pueden usar una biblioteca llamada
pino-debug creada por el comando
pino para formatear estas entradas correctamente.
Instala la biblioteca:

Antes de usar la
debug por primera vez, se debe inicializar
pino-debug . La forma más fácil de hacer esto es usar los
indicadores -r o --require para solicitar un módulo antes de ejecutar el script. Reiniciamos el servidor usando el comando (siempre que
pino-colada instalado
pino-colada ):

Como resultado, las entradas del registro de depuración de la biblioteca aparecerán igual que en el registro de la aplicación:
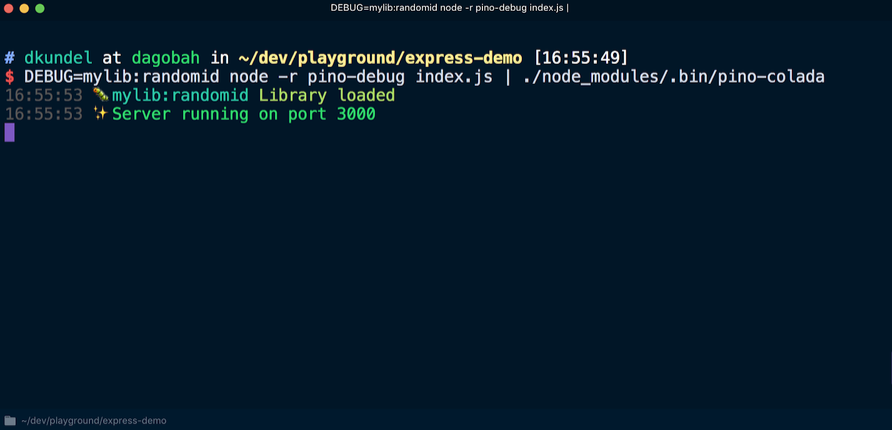
Salida de la interfaz de línea de comando (CLI)
El último caso que trata este artículo es el registro de la interfaz de línea de comandos. Preferiblemente, el registro que registra eventos relacionados con la lógica del programa se mantiene separado del registro para registrar datos de la interfaz de línea de comandos. Para registrar cualquier evento relacionado con la lógica del programa, debe usar una biblioteca específica, por ejemplo,
debug . En este caso, puede reutilizar la lógica del programa sin limitarse a un escenario utilizando la interfaz de línea de comandos.
Al crear una interfaz de línea de comando usando Node.js , puede agregar varios colores, bloques de valores variables o herramientas de formato para darle a la interfaz un aspecto visualmente atractivo. Sin embargo, debe tener en cuenta varios escenarios.
Según uno de ellos, la interfaz se puede utilizar en el contexto de un sistema de integración continua (CI), en cuyo caso es mejor abandonar el formato de color y la presentación de resultados visualmente sobrecargada. Algunos sistemas de integración continua tienen establecido el indicador
CI . Puede verificar que está en un sistema de integración continua utilizando el paquete
is-ci , que admite varios de estos sistemas.
Algunas bibliotecas, como la
chalk , definen sistemas de integración continua y anulan la salida de texto en color a la consola. Veamos como funciona.
Instale
chalk con el comando npm
install chalk y cree un archivo llamado
cli.js Ponga las siguientes líneas en el archivo:

Ahora, si ejecuta este script usando el
node cli.js , los resultados se presentarán con diferentes colores:
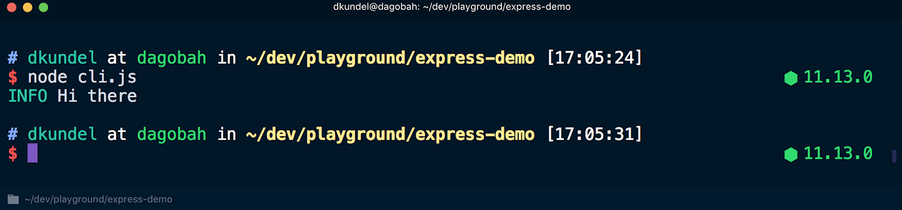
Pero si ejecuta el script usando
CI=true node cli.js , el formato de color de los textos se cancelará:
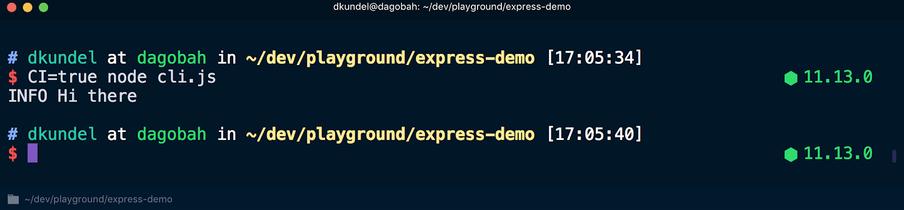
En otro escenario que vale la pena recordar,
stdout ejecuta en modo terminal, es decir los datos se envían al terminal. En este caso, los resultados se pueden mostrar muy bien con
boxen . De lo contrario, lo más probable es que la salida se redirija a un archivo o a otro lugar.
Puede comprobar el funcionamiento de las secuencias
stdin ,
stdout o
stderr en modo terminal mirando el atributo
isTTY de la secuencia correspondiente. Por ejemplo,
process.stdout.isTTY .
TTY significa "teletipo" y en este caso está diseñado específicamente para el terminal.
Los valores pueden variar para cada uno de los tres subprocesos, dependiendo de cómo se iniciaron los procesos Node.js. Se puede encontrar información detallada sobre esto en la
documentación de Node.js, en la sección "Entrada / salida de procesos" .
Veamos cómo el valor de
process.stdout.isTTY varía en diferentes situaciones.
cli.js archivo
cli.js para verificarlo:

Ahora ejecute el
node cli.js en el terminal y vea la palabra
true , después de lo cual el mensaje se muestra en letra de color:

Después de eso, volvemos a ejecutar el comando, pero redirigimos la salida a un archivo y luego vemos el contenido:

Esta vez, la palabra
undefined apareció en la terminal, seguida de un mensaje que se muestra en una fuente incolora, ya que la secuencia
stdout redirigió fuera del modo terminal. Aquí la
chalk utiliza la herramienta de
supports-color , que desde el punto de vista de la estructura interna verifica el
isTTY secuencia correspondiente.
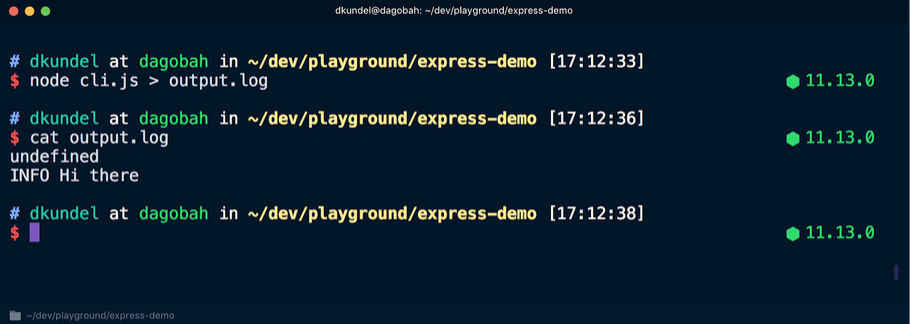
Las herramientas como la
chalk hacen estas cosas por su cuenta. Sin embargo, al desarrollar una interfaz de línea de comandos, siempre debe estar atento a las situaciones en las que la interfaz funciona en un sistema de integración continua o la salida se redirige. Estas herramientas lo ayudan a usar la interfaz de línea de comandos en un nivel superior. Por ejemplo, los datos en el terminal se pueden organizar de una manera más estructurada, y si
isTTY undefined está
undefined , cambie a una forma más simple de análisis.
Conclusión
Comenzar a usar JavaScript e ingresar la primera línea en el registro de la consola usando
console.log bastante simple. Pero antes de implementar el código en producción, debe considerar varios aspectos del uso del registro. Este artículo es solo una introducción a los diversos métodos y soluciones utilizados en la organización del registro de eventos. No contiene todo lo que necesita saber. Por lo tanto, se recomienda prestar atención a los proyectos exitosos de código abierto y monitorear cómo resolvieron el problema de registro y qué herramientas se utilizan. Y ahora intente iniciar sesión sin generar datos en la consola.
Si conoce otras herramientas que vale la pena mencionar, escríbalas en los comentarios.