Hola a todos!
Me llamo Vitaliy Bendik. Soy el líder del equipo para el desarrollo de aplicaciones de Android en Lamoda. En 2018, hablé en el Mosdroid Aluminium con un
informe , cuya transcripción quiero compartir.

Se tratará de cómo mantenemos la estabilidad de la aplicación móvil. Esto es muy importante para nosotros, ya que nuestra audiencia móvil es de millones de usuarios. Además, en términos de la participación en los pedidos de nuestros clientes, las aplicaciones han superado durante mucho tiempo los sitios, las versiones de escritorio y móviles en total, y la plataforma iOS se ha convertido en un líder absoluto, por delante del sitio de escritorio.
En el informe diré:
- lo que entendemos por estabilidad de la aplicación;
- Sobre la arquitectura de nuestra aplicación móvil;
- sobre los procesos, prácticas y herramientas que utilizamos.
Entonces, ¿qué es una
aplicación estable para nosotros? Esta es una aplicación que no se bloquea, no se bloquea y funciona de manera predecible. Cuando digo que no cae, quiero decir que no cae en al menos el 95% -99% de los usuarios.
Arquitectura

Como habrás adivinado, esta imagen muestra una arquitectura pura, a la que intentamos adherirnos. Como capa de presentación, usamos MVP con algunas adiciones, que analizaré a continuación.
Nuestra aplicación móvil está adaptada tanto para teléfonos como para tabletas. Por lo tanto, el diseño suele ser diferente, pero consta de bloques similares o idénticos. En este sentido, tenemos una entidad como Widget. Le permite descomponer una actividad o un fragmento en bloques más pequeños que pueden reutilizarse en otras pantallas. Esto tiene sentido, ya que desde el punto de vista del código que está en el fragmento o en la actividad, rara vez es necesario distinguir entre el contexto de la interfaz de usuario que está ejecutando. Y estos fragmentos de código pueden convertirse en algunas abstracciones y reutilizarse. Este enfoque recuerda un poco a la biblioteca SoundCloud:
LightCycle .


 Página del producto Ejemplos de elementos de widget
Página del producto Ejemplos de elementos de widgetEn cuanto a la interacción del presentador con el modelo, todo es estándar aquí: el presentador interactúa con el resto de la aplicación a través de interactor, ya sean repositorios o gerentes.
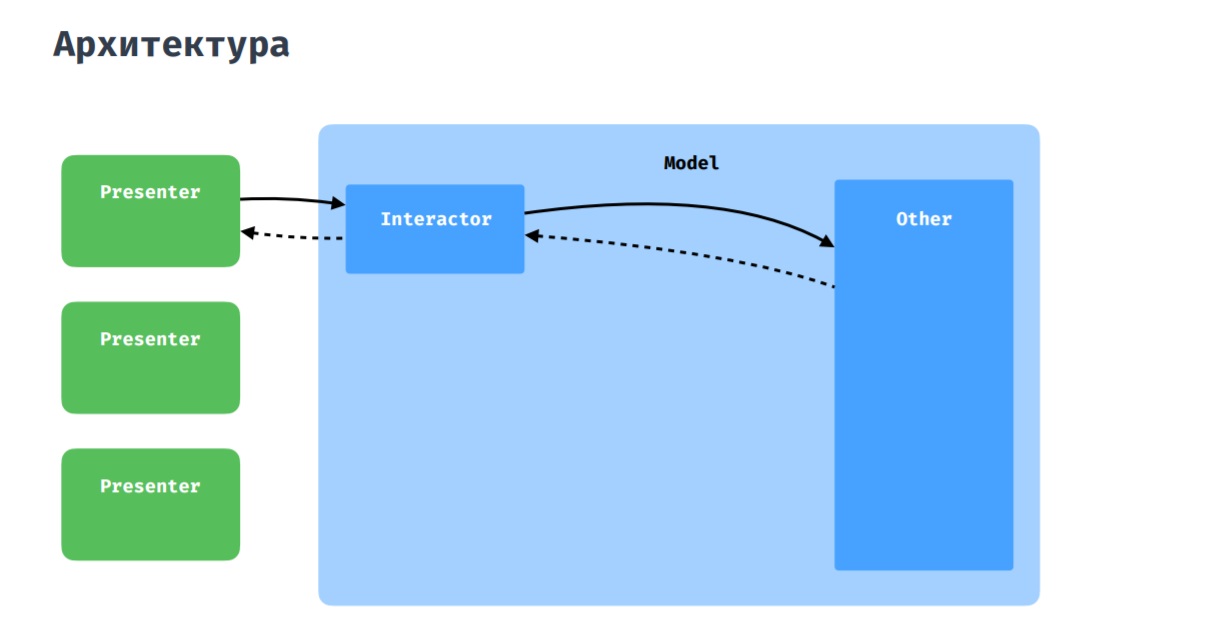
Sucede que varios presentadores necesitan comunicarse entre ellos, intercambiar datos. Para esto, tenemos un coordinador, que puede ser percibido como un interactor compartido entre varios presentadores.

Pila
- Escribimos todo el código nuevo en Kotlin , y usamos Moxy como la implementación MVP.
- Como DI usamos Dagger2 .
- Para trabajar con la red - Reequipamiento .
- Para trabajar con imágenes - Glide .
- Agregamos bloqueos a New Relic .
- También usamos Lottie .
- En este momento, estamos utilizando activamente Corotinas Kotlin .
Proceso de desarrollo
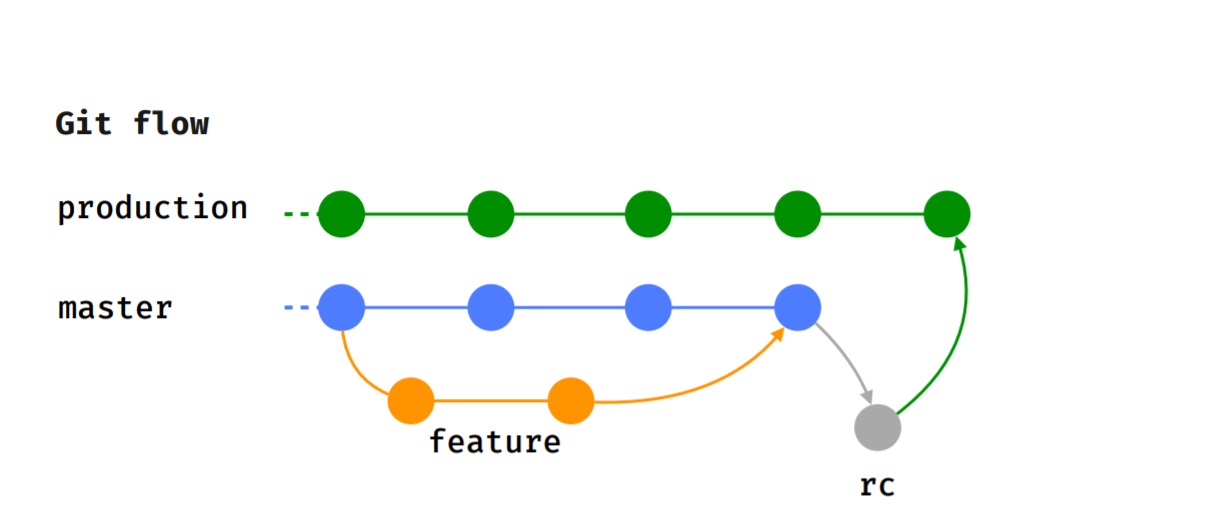
Nos adherimos al flujo de Git, es decir, cada característica se implementa en una rama de características separada, que, después de una revisión del código, se envía para su prueba.
Después de que el probador completó con éxito la prueba, y decidimos sobre la versión a la que irá esta característica, se fusiona con el maestro.
Cuando llega el momento de la liberación (saldremos cada 2 semanas), se asigna la rama rc, donde se realizan las pruebas de humo, se ejecutan los casos de prueba. Después de eso, la función se fusiona con la rama de producción y se publica en Google Play Beta.
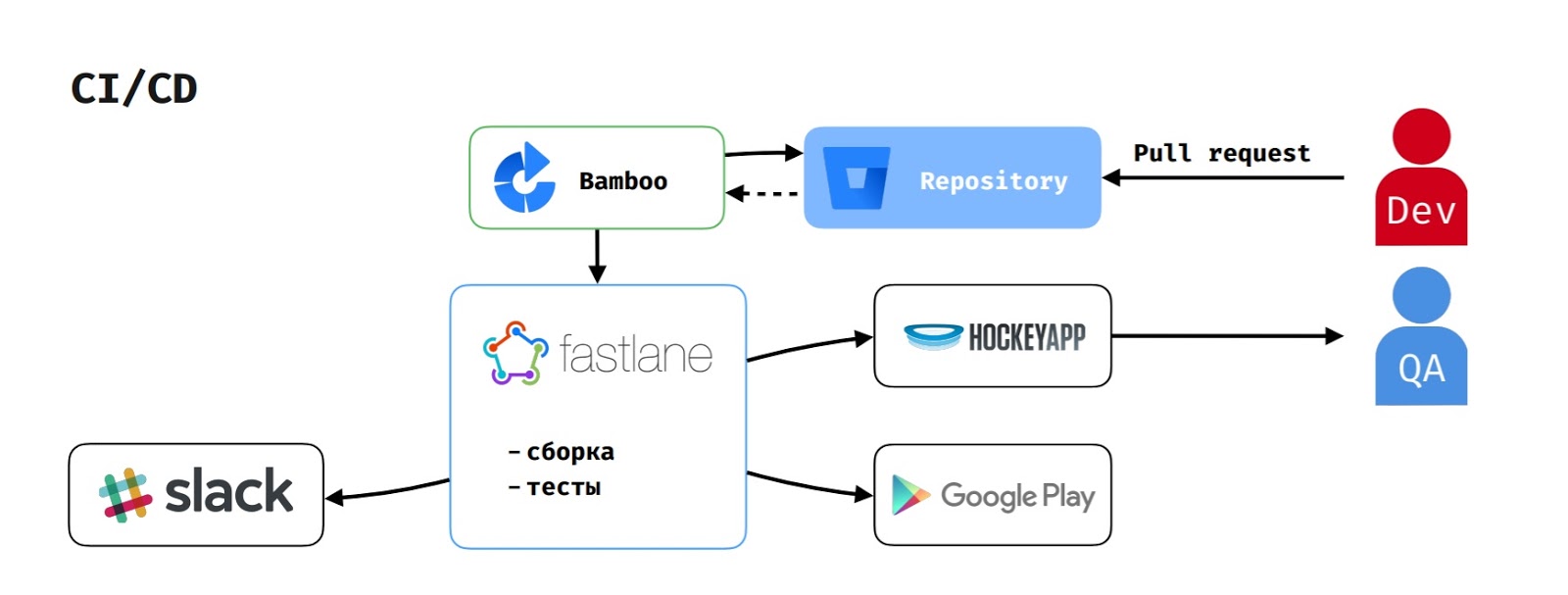
En cuanto a CI / CD, dado que usamos la pila Atlassian, Bamboo actúa como un servidor de compilación.
Cuando un desarrollador crea una solicitud de extracción, la tarea de compilación comienza en Bamboo. Extrae el código del repositorio, ejecuta el script en fastlane, que recopila la aplicación, ejecuta las pruebas e informa esto a Slack.
Si el probador inició el ensamblaje para probar la función, entonces apk también se carga en HockeyApp.
Para publicar el lanzamiento en Google Play Beta, el administrador de entrega inicia la tarea correspondiente en Bamboo, que ejecuta el mismo flujo, pero también carga la versión en Google Play Beta.
Practicas Aplicadas
Compilación previa al lanzamientoInicialmente, teníamos dos tipos de ensamblaje, como muchos:
Compilación de depuración en la que se deshabilitaron ProGuard y SSL Pinning.
Versión de lanzamiento en la que se incluyeron ProGuard y SSL Pinning.
El proceso se veía así: el desarrollador termina el trabajo en la función y la da para probar. El probador recopila el ensamblaje de depuración, prueba los casos de prueba en él y verifica la corrección de los análisis enviados por la aplicación. Si todo está bien, entonces él envía la tarea a Listo para liberar, y ella espera el momento en que comencemos a recoger el lanzamiento.
Cuando llega el momento del lanzamiento de la aplicación, el desarrollador fusiona todas las tareas en maestra, selecciona la rama rc y le otorga QA para la prueba de humo. El control de calidad recopila el conjunto de liberación y comienza a ejecutar pruebas. Pero hay momentos en que algo sale mal. Los problemas generalmente ocurren debido a ProGuard. Por supuesto, se solucionan rápidamente, pero esto puede retrasar el lanzamiento o retrasarlo por algún tiempo.
Por esta razón, creamos una compilación previa al lanzamiento en la que ProGuard está activado y SSL Pinning está desactivado. Esto permite a los evaluadores verificar la exactitud de los análisis enviados (esta fue la razón por la cual los evaluadores no crearon inicialmente la versión de lanzamiento).
Ahora, los QA están creando una versión preliminar. Esto les da la oportunidad de probar análisis y enfrentar problemas causados por ProGuard lo antes posible.
Especificación primeroEste es un enfoque en el que la especificación es primaria. Cuando desarrollamos una nueva característica y requiere un backend, primero se crea una especificación y luego, en base a ella, el desarrollo de la característica comienza tanto desde el backend como desde los clientes. Todos los cambios pasan por la especificación, y solo entonces los cambios se realizan en el servidor y los clientes. Esta especificación también genera documentación de Swagger sobre métodos API.
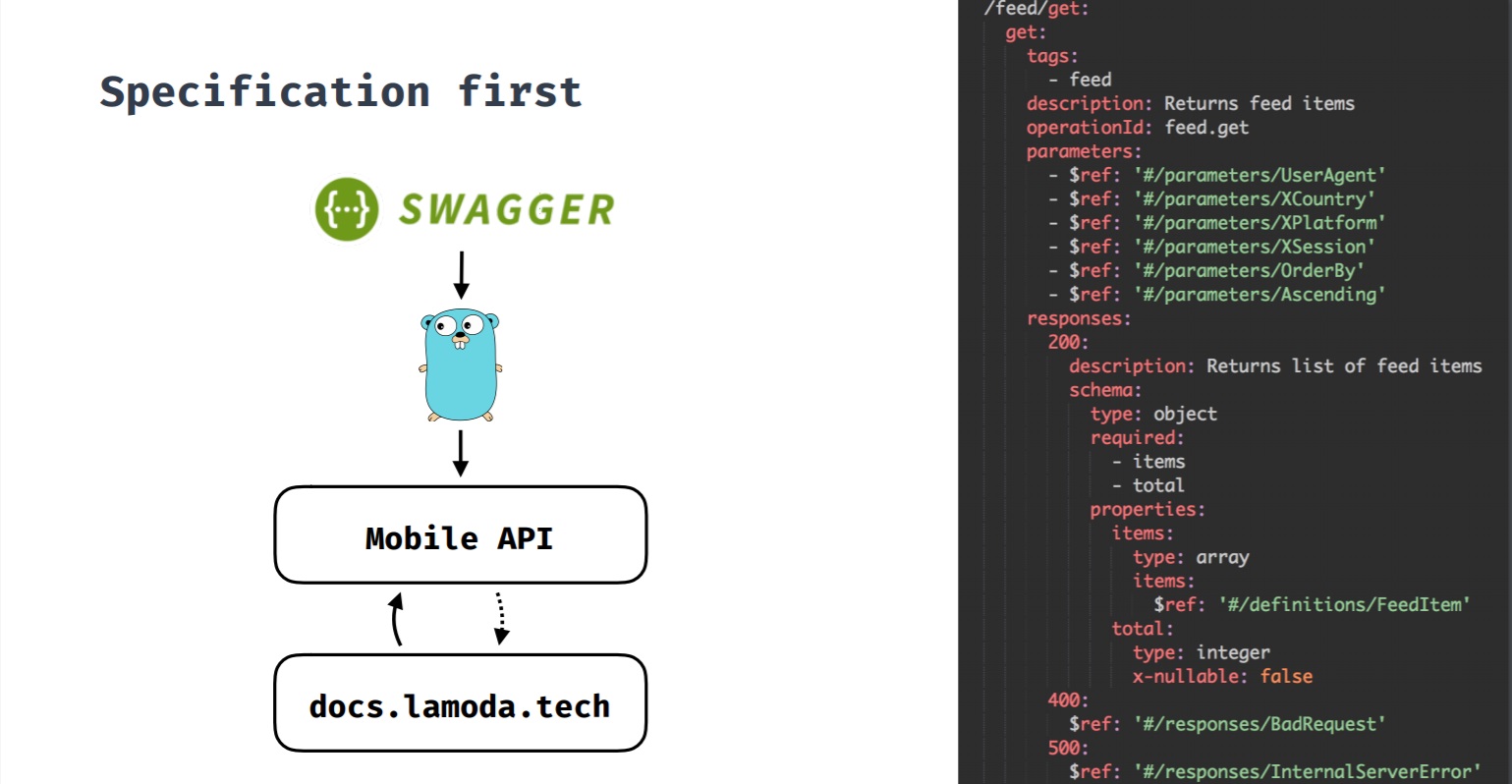
Inicialmente, teníamos una API cuyos clientes no eran solo aplicaciones móviles. Los métodos API no eran consistentes entre sí, lo que a menudo dificultaba los cambios.
También a menudo encontré casos divertidos. Por ejemplo, cuando el método devuelve una lista de marcas, en el caso de que haya varias, devuelve una matriz, y si solo hubo una marca, devuelve un objeto.

O, en ausencia de marcas, se devolvió nulo o, en general, 4 caracteres nulos
(no JSON). En este caso, la aplicación fue difícil.

Por lo tanto, con el tiempo, llegamos a la conclusión de que las aplicaciones móviles requieren su propia API, que tendría en cuenta sus detalles y asociaría la aplicación móvil con un conjunto de sistemas internos de Lamoda con los que tiene que interactuar.

Al mismo tiempo, decidimos probar el primer enfoque de Especificación (especificación Swagger). Cuando un desarrollador comienza a trabajar en alguna característica que necesita un backend, realiza una solicitud de extracción con un contrato de característica. Luego, todas las partes interesadas de iOS, Android y equipos de backend se agregan a esta solicitud de extracción. Cuando todos están satisfechos con el contrato del nuevo método API, la solicitud de extracción se vierte en la rama del backend y los desarrolladores del backend comienzan a desarrollar funciones. Los clientes también comienzan a desarrollar características, porque el contrato ahora está arreglado y puedes confiar en él y, si es necesario, hacer moki.
Alternar funcionesLa empresa tiene su propia herramienta de desarrollo A / B, que le permite implementar experimentos y alternar funciones. Al alternar funciones, cerramos la funcionalidad no crítica para el usuario, que, si es necesario, se puede desactivar. Por ejemplo, si algo salió mal o si necesitamos reducir la carga en el backend (como opción, en el "Viernes Negro").
Las funciones de alternancia también nos permiten probar bibliotecas para poder ver si otra biblioteca resolverá mejor nuestro problema y se comportará de manera más estable. Si no, entonces siempre podemos retroceder a nuestra biblioteca anterior.
Monitoreo real del usuarioReal User Monitoring le permite medir el rendimiento de la aplicación desde la perspectiva de un usuario. Por ejemplo, un cliente hizo clic en un artículo en un catálogo. ¿Cuánto tiempo tendrá que esperar antes de ver el resultado de su acción, es decir, verá una tarjeta de producto con fotos?
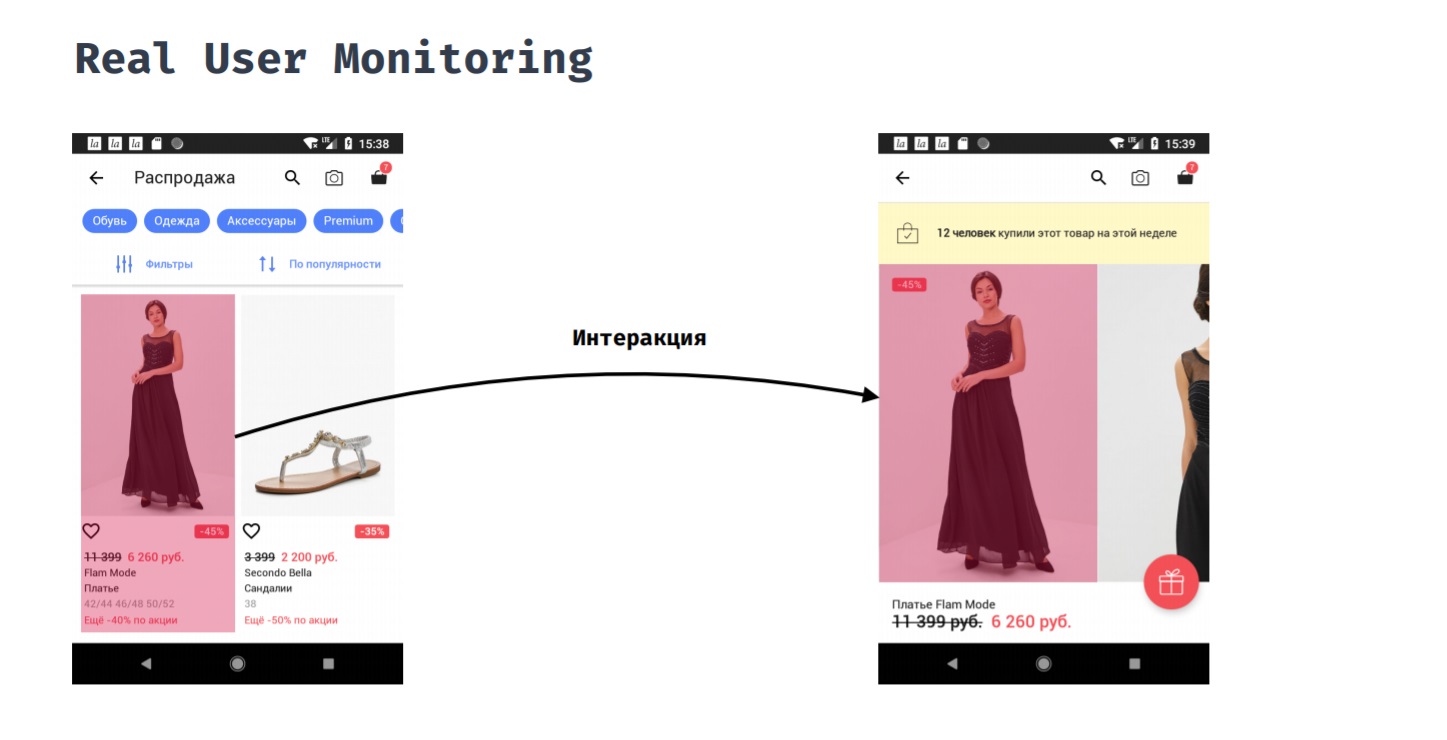
Esto no se puede hacer automáticamente, porque el punto de inicio y el punto final de esta medición deben establecerse manualmente. Solo el desarrollador comprende cuándo se puede suponer que el usuario está listo para interactuar con la nueva pantalla. En el proceso de esta interacción, podemos estar interesados en cosas como:
1. consumo de memoria;
2. consumo de CPU;
3. lo que sucedió en la transmisión principal;
4. lo que se cargó desde la red;
5. lo que sucedió en otros hilos.
Esto nos da la oportunidad de solucionar problemas si surgen, porque queda claro que en realidad tomó la mayor parte del tiempo y que podemos optimizarlo para que la aplicación responda mejor al usuario.
Reembolso de deuda técnica
Antes de implementar la nueva versión, corregimos los bloqueos que ocurrieron en la versión anterior. No se trata de bloqueos críticos, ya que esto definitivamente requeriría revisiones, sino de bloqueos que no ocurren con demasiada frecuencia, no afectan los indicadores comerciales, pero son desagradables para los usuarios.
Después del lanzamiento de la versión, la implementamos por porcentaje, monitoreamos los indicadores críticos y respondemos a los incidentes si ocurren. Para el rodamiento por fases, utilizamos la consola Google Play. El balanceo se realiza de la siguiente manera: desplegado en un 5%, monitoreamos el indicador; si todo está en orden, entonces continúa. Si sucedió algo, haga una revisión y despliéguela ya. A continuación, hacemos una rotación del 10%, 20% y 50%.
¿Qué lugares críticos estamos
monitoreando ?
- Solicitudes de red, incluso de bibliotecas de terceros: errores, tiempo de respuesta, carga.
- La caida.
- Excepciones manejadas, las llamadas "excepciones procesadas". Estas son excepciones que podrían haber ocurrido si no las hubiéramos envuelto en try-catch. Esto permite que la aplicación no se caiga si se produce una excepción en la funcionalidad no crítica para el usuario. Por ejemplo, es malo caer debido a los análisis. Sin embargo, es importante que los productos comprendan que una función mejora o empeora la conversión. El uso de excepciones manejadas nos permite responder y solucionar estos problemas.
Las herramientas
- Herramienta A / B
- NuevoRelic RPM
- NewRelic Insights.
La herramienta A / B es un mecanismo para realizar experimentos y un mecanismo para hacer rodar variables, las mismas funciones de alternancia. Este es un desarrollo interno, por lo que está bien integrado en muchos sistemas: en aplicaciones móviles, en el sitio, en el back-end. Le permite transmitir la configuración de alternancia de funciones no en una solicitud separada detrás de ella, sino en los encabezados de las respuestas a las solicitudes que hace la aplicación.
Esto nos da la oportunidad:
- Implemente experimentos en la oficina cuando queramos probar alguna característica dentro de nuestra oficina.
- Implemente un experimento, así como alternar funciones para un usuario específico.
El sistema es independiente de factores externos. Si utilizamos una herramienta de terceros, en algún momento podría bloquearse (hola, Roskomnadzor) o algo podría salir mal. Para nosotros, esto sería crítico, porque en ese caso no podríamos cambiar rápidamente la función de alternancia. Y dado que este es nuestro propio desarrollo, no tenemos ese problema.
NewRelic es una herramienta que le permite monitorear muchos indicadores diferentes en tiempo real. De la variedad de características de New Relic, utilizamos, por ejemplo, instrumentación automática de código. Es lo que nos permite monitorear las solicitudes de red no solo a nuestro backend, sino también a todo el resto (incluso de bibliotecas de terceros). NewRelic admite un cierto conjunto de clientes estándar para trabajar con la red. También le permite recopilar información:
1. sobre el consumo de memoria;
2. sobre el consumo de CPU;
3. sobre operaciones relacionadas con JSON;
4. sobre operaciones relacionadas con SQlite.
Además, utilizamos NewRelic para recopilar informes de fallas, para recopilar excepciones manejadas y para las interacciones de los usuarios: esta es exactamente la misma
Monitoreo real de usuarios . Lo hemos implementado a través del mecanismo de interacciones del usuario NewRelic.
¿Pero qué hay de la estabilidad?
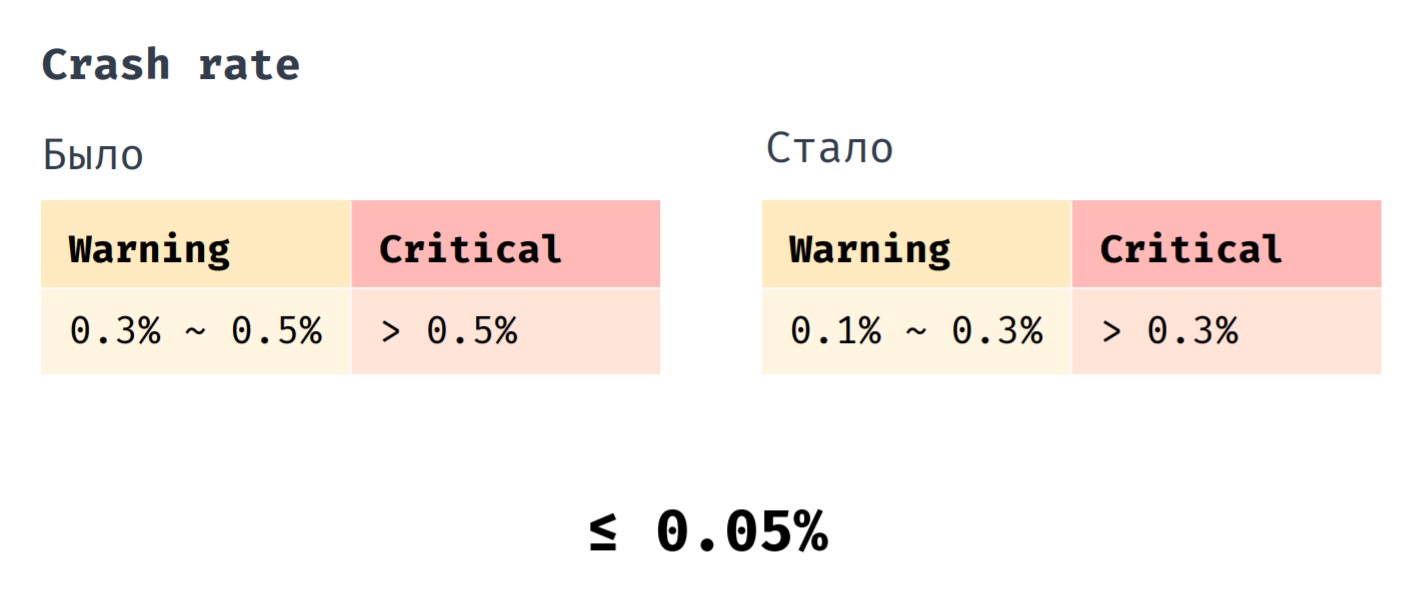
Tenemos un indicador como la tasa de choque. Anteriormente, implementamos la revisión cuando su indicador estaba en el rango de 0.3% a 0.5%. Es absolutamente crítico si su valor se convierte en más de 0.5%. Ahora implementamos la revisión cuando la tasa de bloqueo está en el rango de 0.1% a 0.3%. Un valor crítico es más del 0.3% y, si antes la tasa de caída promedio de nuestra aplicación era 0.1%, ahora es 0.05%.
En conclusión, me gustaría enumerar las prácticas más importantes que nos ayudan a mantener la estabilidad de la aplicación. Probamos la aplicación lo más cerca posible de la versión de producción, cerramos la funcionalidad acrítica de los cambios de características, así como también monitoreamos y respondemos a los indicadores que son importantes para nosotros.