
Cuanto más rápido sea el proceso de desarrollo, más rápido se desarrolla la empresa de tecnología.
Desafortunadamente, las aplicaciones modernas funcionan en nuestra contra: nuestros sistemas deben actualizarse en tiempo real y al mismo tiempo para no molestar a nadie y no provocar tiempos de inactividad e interrupciones. La implementación en tales sistemas se convierte en una tarea compleja y requiere tuberías de entrega continua complejas incluso en equipos pequeños.
Estas tuberías generalmente tienen una aplicación estrecha, funcionan lentamente y no son confiables. Los desarrolladores primero deben crearlos manualmente y luego administrarlos, y las empresas a menudo contratan equipos completos de DevOps para esto.
La velocidad de desarrollo depende de la velocidad de estas tuberías. Para los mejores equipos, la implementación demora entre 5 y 10 minutos, pero generalmente demora mucho más, y para una implementación lleva varias horas.
En la oscuridad, tarda 50 ms. Cincuenta. Milisegundos Dark es una solución completa con un lenguaje de programación, un editor y una infraestructura diseñados específicamente para la entrega continua, y todos los aspectos de Dark, incluido el lenguaje en sí, se crean con una vista de despliegue instantáneo seguro.
¿Por qué los transportadores continuos son tan lentos?
Digamos que tenemos una aplicación web de Python y que ya hemos creado un canal de entrega continua maravilloso y moderno. Para un desarrollador que está ocupado con este proyecto todos los días, la implementación de un cambio menor se verá así:
Haciendo cambios
- Creando una nueva rama en git
- Realizar cambios detrás del interruptor de función
- Prueba de unidad para verificar cambios con y sin interruptor de función
Solicitud de piscina
- Comprometer comprometer
- Publicar cambios en un repositorio remoto en github
- Solicitud de piscina
- CI se crea automáticamente en segundo plano
- Revisión de código
- Algunas revisiones más, si es necesario
- Combinar cambios con git wizard.
CI se ejecuta en el asistente
- Establecer dependencias frontend a través de npm
- Creación y optimización de recursos HTML + CSS + JS
- Ejecutar en el extremo frontal de las pruebas unitarias y funcionales
- Instalar dependencias de Python desde PyPI
- Ejecutar en el backend de pruebas unitarias y funcionales
- Pruebas de integración en ambos extremos.
- Enviar recursos frontend a CDN
- Construyendo un contenedor para un programa Python
- Enviar un contenedor al registro
- Actualización del manifiesto de Kubernetes
Sustitución de código antiguo por nuevo
- Kubernetes lanza múltiples instancias de un nuevo contenedor
- Kubernetes está esperando que las instancias entren en funcionamiento
- Kubernetes agrega instancias al equilibrador de carga HTTP
- Kubernetes espera a que las viejas instancias dejen de usarse
- Kubernetes detiene instancias antiguas
- Kubernetes repite estas operaciones hasta que las nuevas instancias reemplacen a todas las antiguas.
Encienda el nuevo interruptor de función
- El nuevo código se incluye solo para mí, para asegurarme de que todo esté bien
- Se incluye un nuevo código para el 10% de los usuarios; se realiza un seguimiento de las métricas operativas y comerciales
- Se incluye un nuevo código para el 50% de los usuarios; se realiza un seguimiento de las métricas operativas y comerciales
- El nuevo código se incluye para el 100% de los usuarios, se realiza un seguimiento de las métricas operativas y comerciales
- Finalmente, repite todo el procedimiento para eliminar el código anterior y cambiar
El proceso depende de las herramientas, el lenguaje y el uso de arquitecturas orientadas a servicios, pero en términos generales, se ve así. No mencioné las implementaciones de migración de bases de datos porque esto requiere una planificación cuidadosa, pero a continuación describiré cómo Dark trata con esto.
Aquí hay muchos componentes, y muchos de ellos pueden ralentizarse fácilmente, bloquearse, provocar una competencia temporal o hacer caer el sistema de trabajo.
Y dado que estas tuberías casi siempre se crean para una ocasión especial, es difícil confiar en ellas. Muchas personas tienen días en los que el código no se puede implementar, porque hay problemas en el Dockerfile, uno de los docenas de servicios bloqueados o el especialista adecuado en vacaciones.
Peor aún, muchos de estos pasos no hacen nada en absoluto. Los necesitábamos antes cuando implementamos el código de inmediato para los usuarios, pero ahora tenemos conmutadores para el nuevo código, y estos procesos están divididos. Como resultado, el paso en el que se implementa el código (el antiguo se reemplaza por el nuevo) ahora se ha convertido en un riesgo adicional.
Por supuesto, esta es una tubería muy reflexiva. El equipo que lo creó se tomó el tiempo y el dinero para implementarlo rápidamente. Por lo general, las canalizaciones de implementación son mucho más lentas y poco confiables.
Implementación de entrega continua en la oscuridad
La entrega continua es tan importante para Dark que fijamos nuestra vista a tiempo en menos de un segundo. Recorrimos todos los pasos de la tubería para eliminar todo lo innecesario, y recordamos el resto. Así es como eliminamos los pasos.
Jessie Frazelle acuñó la nueva palabra deployless en la conferencia Future of Software Development en Reykjavik
Inmediatamente decidimos que Dark se basaría en el concepto de "sin despliegue" (gracias a Jesse Frazel por el neologismo). Sin implementación significa que cualquier código se implementa instantáneamente y está listo para usarse en producción. Por supuesto, no vamos a perder un código defectuoso o incompleto (describiré los principios de seguridad a continuación).
En la demostración de Dark, a menudo nos preguntaban cómo logramos acelerar la implementación. Pregunta extraña La gente probablemente piense que hemos encontrado algún tipo de supertecnología que compara el código, lo compila, lo empaqueta en un contenedor, lanza una máquina virtual, lanza un contenedor en uno frío y cosas así, y todo esto en 50 ms. Esto es casi imposible. Pero hemos creado un motor de despliegue especial, que no necesita todo esto.
Dark lanza intérpretes en la nube. Suponga que escribe código en una función o controlador para HTTP o eventos. Enviamos diff al árbol de sintaxis abstracta (la implementación del código utilizado internamente por nuestro editor y servidores) a nuestros servidores, y luego ejecutamos este código cuando se reciben solicitudes. Por lo tanto, la implementación se ve como un registro modesto en la base de datos: instantánea y primaria. La implementación es muy rápida porque incluye lo mínimo.
En el futuro, planeamos hacer un compilador de infraestructura de Dark, que creará y ejecutará la infraestructura ideal para un alto rendimiento y confiabilidad de las aplicaciones. La implementación instantánea, por supuesto, no va a ninguna parte.
Despliegue seguro
Editor estructurado
El código en Dark está escrito en el editor Dark. El editor estructurado no comete errores de sintaxis. De hecho, Dark ni siquiera tiene un analizador. A medida que escribe, trabajamos directamente con el Árbol de sintaxis abstracta (AST) como Paredit , Sketch-n-Sketch , Tofu , Prune y MPS .
Cualquier código incompleto en Dark tiene una semántica de ejecución válida, al igual que los agujeros escritos en Hazel . Por ejemplo, si cambia una llamada de función, mantenemos la función anterior hasta que se pueda utilizar la nueva.
Cada programa en Dark tiene su propio significado, por lo que un código incompleto no interfiere con el trabajo terminado.
Modos de edición
Escribes código en Dark en dos casos. Primero: escribe un código nuevo y es el único usuario. Por ejemplo, está en el REPL, y otros usuarios nunca tendrán acceso a él, o es una nueva ruta HTTP a la que no se refiere en ningún lado. Puede trabajar aquí sin precauciones, y ahora está trabajando aproximadamente en el entorno de desarrollo.
Segunda situación: el código ya está en uso. Si el tráfico pasa por el código (funciones, controladores de eventos, bases de datos, tipo), se debe tener cuidado. Para hacer esto, bloqueamos todo el código usado y requerimos el uso de herramientas más estructuradas para editarlo. A continuación, hablaré sobre las herramientas estructurales: conmutadores de funciones para HTTP y controladores de eventos, una potente plataforma de migración para bases de datos y un nuevo método de control de versiones para funciones y tipos.
Interruptores de función
Una forma de eliminar la complejidad adicional en Dark es solucionar varios problemas con una solución. Los conmutadores de funciones realizan muchas tareas diferentes: reemplazar el entorno de desarrollo local, las ramas de git, implementar código y, por supuesto, la versión tradicional lenta y controlada de código nuevo.
La creación y el despliegue de un cambio de función se realiza en nuestro editor en una sola operación. Crea un espacio vacío para el nuevo código y proporciona controles de acceso para el antiguo y el nuevo código, así como botones y comandos para la transición gradual al nuevo código o su exclusión.
Los conmutadores de función están integrados en el lenguaje oscuro, e incluso los conmutadores incompletos realizan su tarea: si no se cumple la condición del conmutador, se ejecutará el código bloqueado anterior.
Entorno de desarrollo
Los interruptores de función reemplazan el entorno de desarrollo local. Hoy en día, es difícil para los equipos asegurarse de que todos usen las mismas versiones de herramientas y bibliotecas (formateadores de código, linters, gestores de paquetes, compiladores, preprocesadores, herramientas de prueba, etc.) Con Dark, no necesita instalar dependencias localmente, controlar la instalación local de Docker o tomar otras medidas para garantizar al menos una apariencia de igualdad entre el entorno de desarrollo y la producción. Dado que tal igualdad sigue siendo imposible , ni siquiera pretendemos que nos estamos esforzando por lograrla.
En lugar de crear un entorno local clonado, los conmutadores en Dark crean un nuevo entorno limitado en producción que reemplaza el entorno de desarrollo. En el futuro, también planeamos crear un entorno limitado para otras partes de la aplicación (por ejemplo, clones de bases de datos instantáneos), aunque por ahora esto no parece tan importante.
Ramas y despliegues
Ahora hay varias formas de ingresar código nuevo en los sistemas: ramas git, la fase de implementación y los conmutadores de funciones. Resuelven un problema en diferentes partes del flujo de trabajo: git - en las etapas previas a la implementación, implementación - en el momento de la transición del código antiguo al nuevo, y los conmutadores de función - para la liberación controlada de código nuevo.
La forma más efectiva es cambiar de función (al mismo tiempo, la más fácil de entender y usar). Con ellos, puedes abandonar por completo los otros dos métodos. Es especialmente útil eliminar la implementación: si usamos interruptores de función para incluir el código de todos modos, el paso de transferir los servidores al nuevo código solo crea riesgos innecesarios.
Git es difícil de usar, especialmente para principiantes, y realmente lo limita, pero tiene ramas convenientes. Alisamos muchos de los defectos de git. Dark se edita en tiempo real y ofrece la capacidad de trabajar juntos al estilo de Google Docs, de modo que no tiene que enviar el código y con menos frecuencia puede realizar la reubicación y la fusión.
Los conmutadores de funciones respaldan la implementación segura. Junto con las implementaciones instantáneas, le permiten probar rápidamente conceptos en pequeños fragmentos con un bajo riesgo, en lugar de aplicar un cambio importante que puede hacer caer el sistema.
Versionado
Para cambiar las funciones y los tipos, usamos versiones. Si desea cambiar una función, Dark crea una nueva versión de esta función. Luego puede invocar esta versión utilizando el conmutador en el controlador de eventos o HTTP. (Si esta función es profunda en el gráfico de llamadas, se crea una nueva versión de cada función en el proceso. Puede parecer que es demasiado, pero las funciones no interfieren si no las usa, por lo que ni siquiera lo notará).
Por las mismas razones, estamos versionando tipos. Hablamos sobre nuestro sistema de tipos en detalle en una publicación anterior .
Al versionar funciones y tipos, puede realizar cambios en la aplicación gradualmente. Puede verificar que cada controlador individual funcione con la nueva versión, no necesita hacer todos los cambios de forma inmediata en las aplicaciones (pero tenemos herramientas para hacerlo rápidamente si lo desea).
Esto es mucho más seguro que desplegar todo de una vez, como lo es ahora.
Nuevas versiones de paquetes y biblioteca estándar
Cuando actualiza un paquete en Dark, no reemplazamos inmediatamente el uso de cada función o tipo en toda la base de código. Esto no es seguro. El código continúa usando la misma versión que usó, y usted actualiza el uso de funciones y tipos a una nueva versión para cada caso individual usando los interruptores.

Una captura de pantalla de una parte de un proceso automático en Dark que muestra dos versiones de la función Dict :: get. Dict :: get_v0 devolvió el tipo Any (que rechazamos), y Dict :: get_v1 devolvió el tipo Option.
A menudo ofrecemos una nueva función en la biblioteca estándar y excluimos versiones anteriores. Los usuarios con versiones antiguas en el código conservarán el acceso a ellos, pero los nuevos usuarios no podrán obtenerlos. Vamos a proporcionar herramientas para transferir usuarios de versiones antiguas a versiones nuevas en 1 paso, y nuevamente usando interruptores de función.
Dark también brinda una oportunidad única: una vez que ejecutamos su código de trabajo, podemos probar las nuevas versiones nosotros mismos, comparando el resultado de las solicitudes nuevas y antiguas para informarle sobre los cambios. Como resultado, las actualizaciones de paquetes, que a menudo se realizan a ciegas (o requieren pruebas de seguridad rigurosas), presentan muchos menos riesgos y pueden ocurrir automáticamente.
Nuevas versiones oscuras
La transición de Python 2 a Python 3 se ha prolongado durante una década y sigue siendo un problema. Una vez que creamos Dark para la entrega continua, estos cambios de idioma deben considerarse.
Cuando hacemos pequeños cambios en el idioma, creamos una nueva versión de Dark. El código antiguo permanece en la versión anterior de Dark, y el nuevo código se usa en la nueva versión. Para cambiar a la nueva versión de Dark, puede usar los interruptores o versiones de funciones.
Esto es especialmente útil teniendo en cuenta que Dark ha aparecido recientemente. Muchos cambios en el idioma o la biblioteca pueden fallar. La versión gradual del lenguaje nos permite hacer actualizaciones menores, es decir, no podemos apurarnos y posponer muchas decisiones sobre el idioma hasta que tengamos más usuarios y, por lo tanto, más información.
Migraciones de bases de datos
Existe una fórmula estándar para la migración segura de la base de datos:
- Reescribe el código para admitir formatos nuevos y antiguos
- Convierta todos los datos a un nuevo formato
- Eliminar acceso a datos antiguos
Como resultado, la migración de la base de datos se retrasa y requiere muchos recursos. Y estamos acumulando esquemas obsoletos, porque incluso las tareas simples, como corregir el nombre de una tabla o columna, no valen la pena.
Dark tiene una plataforma de migración de base de datos efectiva que (esperamos) simplificará tanto el proceso que ya no le tendrá miedo. Todos los almacenes de datos en Dark (pares clave-valor o tablas hash persistentes) son de tipo. Para migrar un almacén de datos, simplemente asigne un nuevo tipo y una función de reversión y reversión para convertir valores entre los dos tipos.
El acceso a los almacenes de datos en Dark es a través de nombres de variables versionadas. Por ejemplo, el almacén de datos de los usuarios inicialmente se llamaría Users-v0. Cuando se crea una nueva versión con un tipo diferente, el nombre cambia a Users-v1. Si los datos se guardan a través de Users-v0, y usted accede a ellos a través de Users-v1, se aplica la función roll-over. Si los datos se guardan a través de Users-v1, y usted accede a ellos a través de Users-v0, se utiliza la función de reversión.
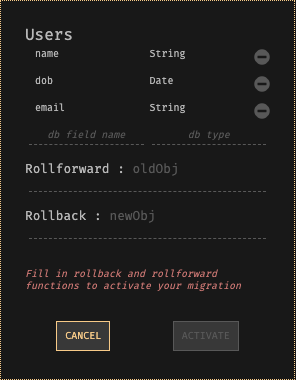
Pantalla de migración de base de datos con nombres de campo para la antigua base de datos, expresiones de reversión y reversión e instrucciones para habilitar la migración.
Use los conmutadores de función para enrutar llamadas a Users-v0 a Users-v1. Puede hacer este único controlador HTTP a la vez para reducir los riesgos, y los conmutadores también funcionan para usuarios individuales para que pueda verificar que todo funcione como se esperaba. Cuando Users-v0 no se deja, Dark convierte todos los datos restantes en segundo plano del formato anterior al nuevo. Ni siquiera lo notarás.
Prueba
Dark es un lenguaje de programación funcional con escritura estática y valores inmutables; por lo tanto, su superficie de prueba es significativamente más pequeña en comparación con los lenguajes orientados a objetos con escritura dinámica. Pero aún necesitas probar.
En Dark, el editor ejecuta automáticamente pruebas unitarias en segundo plano para el código editable y, de forma predeterminada, ejecuta estas pruebas para todos los interruptores de función. En el futuro, queremos usar los tipos estáticos para eliminar automáticamente el código para encontrar errores.
Además, Dark ejecuta su infraestructura en producción, y esto abre nuevas posibilidades. Guardamos automáticamente las solicitudes HTTP en la infraestructura oscura (por ahora guardamos todas las solicitudes, pero luego queremos cambiar a la búsqueda). Probamos un nuevo código en ellos y realizamos pruebas unitarias, y si lo desea, puede convertir fácilmente consultas interesantes en pruebas unitarias.
De lo que nos deshacemos
Como no tenemos una implementación, pero hay conmutadores de funciones, aproximadamente el 60% de la tubería de implementación permanece por la borda. No necesitamos sucursales de git o solicitudes de agrupación, creación de recursos y contenedores de back-end, envío de recursos y contenedores a registros o pasos de implementación en Kubernetes.
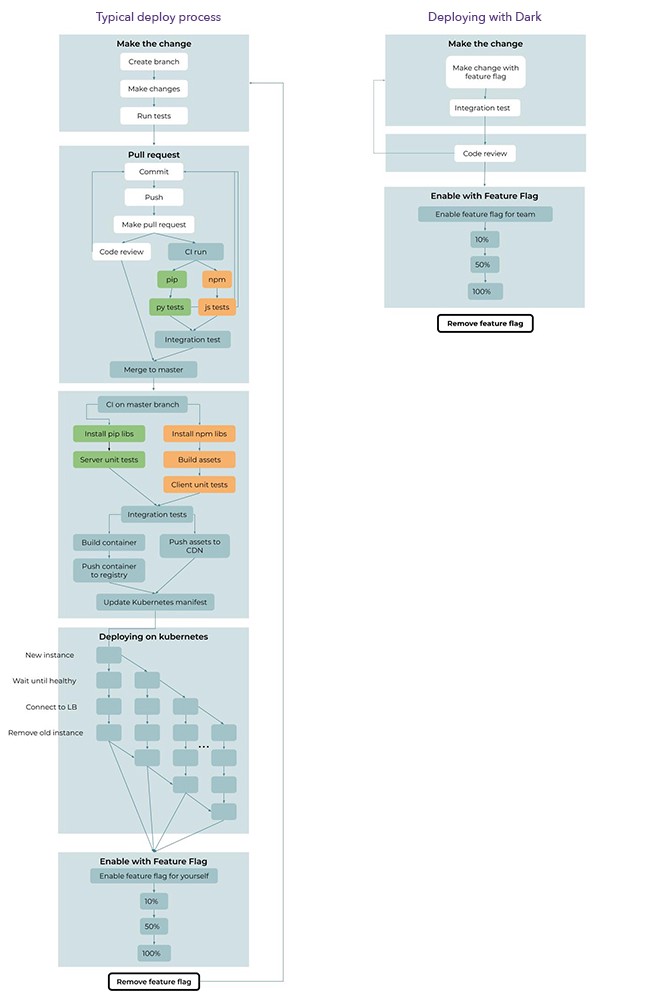
Comparación de la tubería de entrega continua estándar (izquierda) y el suministro continuo de Dark (derecha). En Dark, la entrega consta de 6 pasos y un ciclo, mientras que la versión tradicional incluye 35 pasos y 3 ciclos.
En Dark, solo hay 6 pasos y 1 ciclo en la implementación (pasos que se repiten varias veces), mientras que la tubería de suministro continuo moderno consta de 35 pasos y 3 ciclos. En Dark, las pruebas se ejecutan automáticamente y ni siquiera lo ves; las dependencias se instalan automáticamente; todo lo relacionado con git o github ya no es necesario; No es necesario recolectar, probar y enviar contenedores Docker; La implementación de Kubernetes ya no es necesaria.
Incluso los pasos restantes en Dark se han vuelto más fáciles. Dado que los conmutadores de funciones se pueden controlar en una sola acción, no tiene que pasar por todo el proceso de implementación por segunda vez para eliminar el código anterior.
Simplificamos la entrega de código tanto como sea posible, reduciendo el tiempo y los riesgos de la entrega continua. También simplificamos enormemente las actualizaciones de paquetes, las migraciones de bases de datos, las pruebas, el control de versiones, la instalación de dependencias, la igualdad entre el entorno de desarrollo y la producción, y las actualizaciones de versiones de idiomas rápidas y seguras.
Respondo preguntas sobre esto en HackerNews .
Para obtener más información sobre el dispositivo Dark, lea el artículo de Dark , síganos en Twitter (o en mí ) o regístrese en una versión beta y reciba notificaciones de las siguientes publicaciones . Si vienes a StrangeLoop en septiembre, ven a nuestro lanzamiento .