El título de este artículo puede parecer un poco extraño. De hecho: si trabaja en el campo de la ciencia de datos en 2019, ya está en demanda. La demanda de especialistas en este campo está creciendo constantemente: en el momento de escribir este artículo, se publicaron 144.527 vacantes con la palabra clave "Ciencia de datos" en LinkedIn.
Sin embargo, definitivamente vale la pena seguir las últimas noticias y tendencias en la industria. Para ayudarlo con esto, el equipo de
CV Compiler y yo analizamos varios cientos de trabajos de Data Science en junio de 2019 y determinamos qué habilidades los empleadores esperan más de los candidatos.
Habilidades de ciencia de datos más buscadas en 2019
Este gráfico muestra las habilidades que los empleadores mencionan con mayor frecuencia en los trabajos de Data Science en 2019:
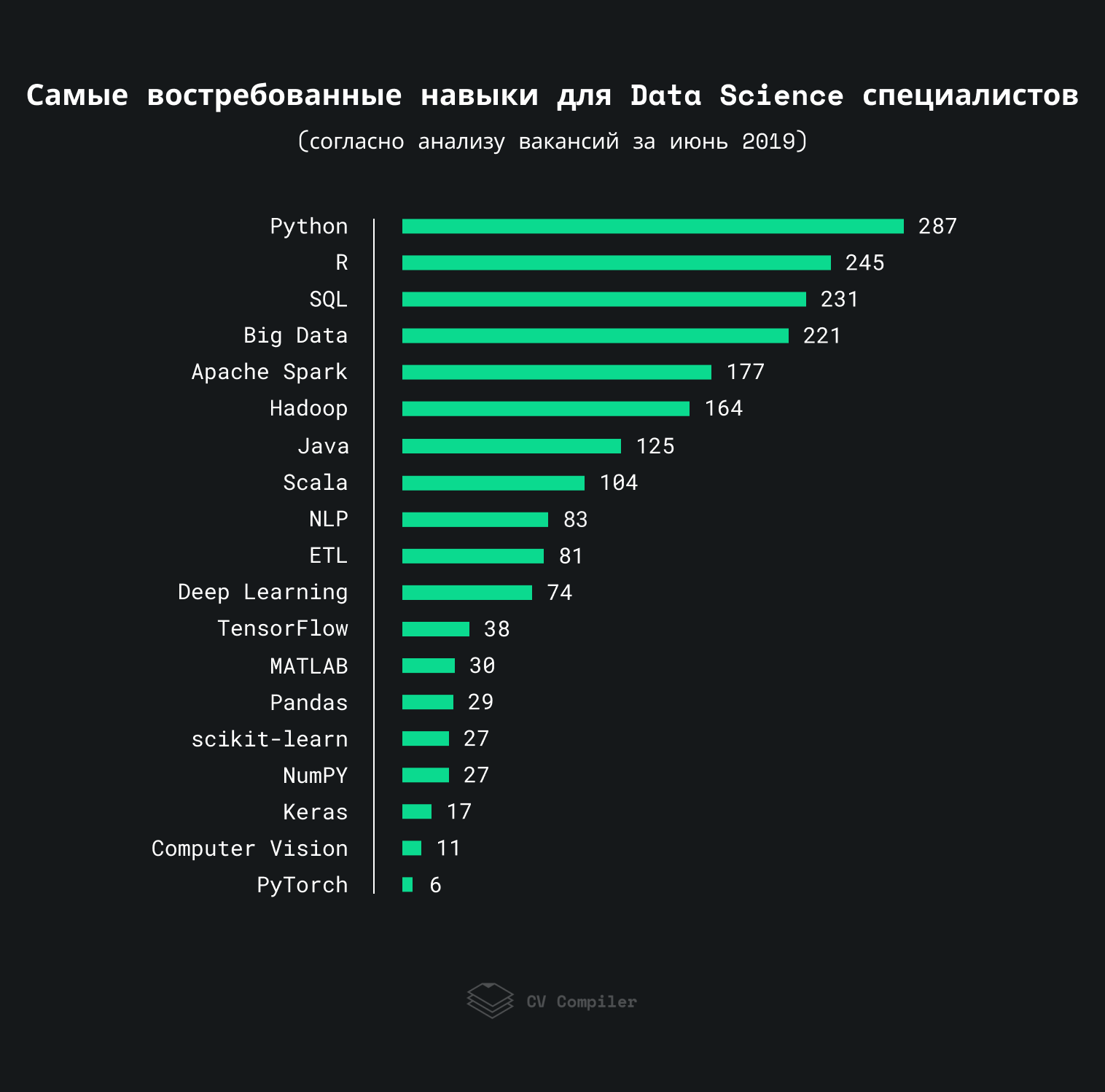
Analizamos aproximadamente 300 trabajos con StackOverflow, AngelList y recursos similares. Algunos términos podrían repetirse más de una vez dentro de la misma vacante.
Importante: Esta calificación demuestra las preferencias de los empleadores en lugar de especialistas en el campo de la ciencia de datos.
Tendencias clave en ciencia de datos
Obviamente, Data Science no es principalmente frameworks y bibliotecas, sino conocimiento fundamental. Sin embargo, todavía vale la pena mencionar algunas tendencias y tecnologías.
Big data
Según
la investigación de mercado de Big Data en 2018 , el uso de Big Data en las empresas aumentó del 17% en 2015 al 59% en 2018. En consecuencia, la popularidad de las herramientas para trabajar con big data ha aumentado. Si no tiene en cuenta Apache Spark y Hadoop (hablaremos de este último con más detalle), las herramientas más populares son
MapReduce (36) y
Redshift (29).
Hadoop
A pesar de la popularidad de Spark y el almacenamiento en la nube, la
era de Hadoop aún no ha terminado. Por lo tanto, algunas compañías esperan que los candidatos conozcan
Apache Pig (30),
HBase (32) y tecnologías similares.
HDFS (20) también se encuentra en algunos trabajos.
Procesamiento de datos en tiempo real.
Dado el uso ubicuo de varios sensores y dispositivos móviles, así como la popularidad de
IoT (18), las compañías están tratando de aprender cómo procesar datos en tiempo real. Por lo tanto, las plataformas de subprocesos como
Apache Flink (21) son populares entre los empleadores.
Ingeniería de características y ajuste de hiperparámetros
La preparación de datos y la selección de parámetros del modelo es una parte importante del trabajo de cualquier especialista en el campo de la ciencia de datos. Por lo tanto, el término
Minería de datos (128) es bastante popular entre los empleadores. Algunas compañías también prestan atención al
ajuste de hiperparámetros (21) (un término como
Feature Engineering tampoco debe olvidarse ). La selección de los parámetros óptimos para el modelo es importante, porque el rendimiento general del modelo depende del éxito de esta operación.
Visualización de datos
La capacidad de procesar correctamente los datos y mostrar los patrones necesarios es importante. Sin embargo,
la visualización de datos (55) es una habilidad igualmente importante. Debe poder presentar los resultados de su trabajo en un formato que sea comprensible para cualquier miembro del equipo o cliente. En términos de herramientas de visualización de datos, los empleadores prefieren
Tableau (54).
Tendencias generales
En las vacantes, también encontramos términos como
AWS (86),
Docker (36) y
Kubernetes (24). Se puede concluir que las tendencias generales del campo del desarrollo de software han migrado lentamente al campo de la ciencia de datos.
Opinión experta
Esta lista de tecnologías realmente refleja el estado real de las cosas en el mundo de la ciencia de datos. Sin embargo, no hay cosas menos importantes que escribir código. Esta es la capacidad de interpretar correctamente los resultados de su trabajo, así como visualizarlos y presentarlos en una forma comprensible. Todo depende de la audiencia: si habla de sus logros a los candidatos de ciencias, habla su idioma, pero si presenta los resultados al cliente, a él no le importará el código, solo el resultado que ha logrado.
Carla Gentry
Científico de datos, propietario de
la solución analíticaLinkedIn |
TwitterEste gráfico muestra las tendencias actuales en el campo de la ciencia de datos, pero es bastante difícil predecir el futuro basado en él. Me inclino a creer que la popularidad de R disminuirá (como la popularidad de MATLAB), mientras que la popularidad de Python solo crecerá. Hadoop y Big Data también aparecieron en la lista por inercia: Hadoop desaparecerá pronto (ya nadie está invirtiendo seriamente en esta tecnología), y Big Data ha dejado de ser una tendencia creciente. El futuro de Scala no está del todo claro: Google oficialmente admite Kotlin, que es mucho más fácil de aprender. También soy escéptico sobre el futuro de TensorFlow: la comunidad científica prefiere PyTorch, y la influencia de la comunidad científica en el campo de la ciencia de datos es mucho mayor que en todas las demás áreas. (Esta es mi opinión personal, que puede no coincidir con la opinión de Gartner).
Andrey Burkov,
Director de Machine Learning en Gartner,
autor del
Libro de Aprendizaje Automático de Cien Páginas .
LinkedInPyTorch es la fuerza impulsora detrás del aprendizaje reforzado, así como un marco sólido para la ejecución de código paralelo en múltiples GPU (que no es el caso con TensorFlow). PyTorch también ayuda a construir gráficos dinámicos que son efectivos cuando se trabaja con redes neuronales recurrentes. TensorFlow funciona con gráficos estáticos y es más difícil de estudiar, pero es utilizado por más desarrolladores e investigadores. Sin embargo, PyTorch está más cerca de Python en términos de código de depuración y bibliotecas para la visualización de datos (matplotlib, seaborn). La mayoría de las herramientas de depuración de código Python se pueden usar para depurar código PyTorch. TensorFlow también tiene su propia herramienta de depuración: tfdbg.
Ganapati Pulipaka,
Científico jefe de datos en Accenture,
Ganador del premio Top 50 Tech Leader.
LinkedIn |
TwitterEn mi opinión, el trabajo y la carrera en Data Science no son lo mismo. Para trabajar, necesitará el conjunto de habilidades anterior, pero para construir una carrera exitosa en Data Science, la habilidad más importante es la capacidad de aprender. Data Science es un campo voluble y tendrá que aprender a dominar las nuevas tecnologías, herramientas y enfoques para mantenerse al día. Plantea constantemente nuevos desafíos y trata de no "contentarte con poco".
Lon Riesberg
Fundador / Curador de
Data Elixir ,
ex-nasa
Twitter |
LinkedInLa ciencia de datos es un campo complejo y de rápido desarrollo en el que el conocimiento fundamental es tan importante como la experiencia con ciertas herramientas. Esperamos que este artículo lo ayude a determinar qué habilidades se necesitan para convertirse en un especialista más solicitado en el campo de la Ciencia de Datos en 2019. ¡Buena suerte!
Este artículo fue escrito por el equipo de CV Compiler , una herramienta para mejorar los currículums para la ciencia de datos y otros profesionales de TI.