
En los últimos años, las bases de datos de series temporales han evolucionado de algo curioso (altamente especializado en sistemas de monitoreo abiertos (y vinculados a soluciones específicas) o proyectos de Big Data) en un "bien de consumo". En el territorio de la Federación de Rusia, se debe dar un agradecimiento especial a Yandex y ClickHouse por esto. Hasta este punto, si necesitaba guardar una gran cantidad de datos de series temporales, tenía que aceptar la necesidad de levantar una pila monstruosa de Hadoop y acompañarla, o comunicarse con protocolos específicos de cada sistema.
Puede parecer que en 2019, un artículo sobre qué TSDB debería usarse consistirá en una sola oración: "solo use ClickHouse". Pero ... hay matices.
De hecho, ClickHouse se está desarrollando activamente, la base de usuarios está creciendo y el soporte es muy activo, pero ¿nos hemos convertido en rehenes del éxito público de ClickHouse, que ha eclipsado otras soluciones posiblemente más efectivas y confiables?
A principios del año pasado, comenzamos a procesar nuestro propio sistema de monitoreo, durante el cual surgió la cuestión de elegir la base adecuada para el almacenamiento de datos. Quiero contar sobre la historia de esta elección aquí.
Declaración del problema.
En primer lugar, el prefacio necesario. ¿Por qué necesitamos nuestro propio sistema de monitoreo y cómo se organizó?
Comenzamos a proporcionar servicios de soporte en 2008, y en 2010 quedó claro que era difícil agregar datos sobre los procesos que ocurren en la infraestructura del cliente con las soluciones que existían en ese momento (estamos hablando de que Dios me perdone, Cacti, Zabbix y los principiantes). Grafito).
Nuestros principales requisitos fueron:
- soporte (en ese momento - docenas, y en el futuro - cientos) de clientes dentro del mismo sistema y al mismo tiempo la presencia de un sistema centralizado de gestión de alertas;
- flexibilidad en la gestión del sistema de alertas (escalada de alertas entre asistentes, contabilidad de horarios, base de conocimiento);
- la posibilidad de detallar en profundidad los gráficos (Zabbix en ese momento dibujaba gráficos en forma de imágenes);
- almacenamiento a largo plazo de una gran cantidad de datos (un año o más) y la capacidad de seleccionarlos rápidamente.
En este artículo, estamos interesados en el último punto.
Hablando de almacenamiento, los requisitos fueron los siguientes:
- el sistema debería funcionar rápidamente;
- es deseable que el sistema tenga una interfaz SQL;
- el sistema debe ser estable y tener una base activa de usuarios y soporte (una vez que nos encontramos con la necesidad de soportar sistemas como MemcacheDB, que dejamos de desarrollar, o el almacenamiento distribuido de MooseFS, cuyo rastreador de errores se realizó en chino: repitiendo esta historia para nuestro proyecto) no quería);
- Correspondencia al teorema del CAP: Consistencia (necesaria): los datos deben ser relevantes, no queremos que el sistema de gestión de notificaciones no reciba nuevos datos y envíe alertas sobre la no llegada de datos para todos los proyectos; Partition Tolerance (necesario): no queremos obtener sistemas Split Brain; Disponibilidad (no crítica, en el caso de una réplica activa): podemos cambiar al sistema de respaldo nosotros mismos en caso de accidente, con un código.
Curiosamente, en ese momento MySQL era la solución perfecta para nosotros. Nuestra estructura de datos era extremadamente simple: identificación del servidor, identificación del contador, marca de tiempo y valor; El muestreo rápido de los datos calientes fue proporcionado por un gran grupo de búferes, y el SSD proporcionó el muestreo de datos históricos.
Por lo tanto, logramos una muestra de datos nuevos de dos semanas, con detalles de hasta 200 segundos antes de que los datos se procesaran por completo y vivieran en este sistema durante bastante tiempo.
Mientras tanto, el tiempo pasó y la cantidad de datos creció. Para 2016, los volúmenes de datos alcanzaron decenas de terabytes, lo que en términos de almacenamiento SSD arrendado fue un gasto significativo.
En este punto, las bases de datos en columnas se estaban extendiendo activamente, lo que comenzamos a pensar activamente: en las bases de datos en columnas, los datos se almacenan, como puede entender, en columnas, y si observa nuestros datos, es fácil ver una gran cantidad de tomas que podrían ser Si usa una base de datos de columnas, comprima con compresión.
Sin embargo, el sistema clave para el trabajo de la compañía continuó funcionando de manera estable, y no quería experimentar con la transición a otra cosa.
En 2017, en la conferencia Percona Live en San José, probablemente la primera vez que los desarrolladores de Clickhouse se anunciaron. A primera vista, el sistema estaba listo para la producción (bueno, Yandex.Metrica es una producción dura), el soporte fue rápido y simple y, lo más importante, la operación fue simple. Desde 2018, hemos comenzado el proceso de transición. Pero para ese entonces había muchos sistemas TSDB “adultos” y probados en el tiempo, y decidimos asignar un tiempo considerable y comparar alternativas para asegurarnos de que no hubiera soluciones alternativas de Clickhouse, de acuerdo con nuestros requisitos.
Además de los requisitos de almacenamiento ya indicados, aparecieron nuevos:
- el nuevo sistema debería proporcionar al menos el mismo rendimiento que MySQL, con la misma cantidad de hierro;
- el almacenamiento del nuevo sistema debería ocupar significativamente menos espacio;
- DBMS aún debería ser fácil de administrar;
- Quería minimizar la aplicación al cambiar el DBMS.
¿Qué sistemas comenzamos a considerar?
Apache Hive / Apache ImpalaAntigua pila de Hadoop maltratada. De hecho, esta es una interfaz SQL construida sobre el almacenamiento de datos en formatos nativos en HDFS.
Pros
- Con una operación estable, es muy fácil escalar los datos.
- Existen soluciones de columna para el almacenamiento de datos (menos espacio).
- Ejecución muy rápida de tareas paralelas en presencia de recursos.
Contras
- Este es un Hadoop, y es difícil de operar. Si no estamos listos para tomar una solución lista para usar en la nube (y no estamos listos para el costo), los administradores tendrán que ensamblar y apoyar toda la pila, pero realmente no quiero esto.
- Los datos se agregan realmente rápido .
Sin embargo:

La velocidad se logra al escalar el número de servidores informáticos. En pocas palabras, si somos una gran empresa dedicada al análisis y los negocios, es de suma importancia agregar la información lo más rápido posible (incluso a costa de utilizar una gran cantidad de recursos informáticos); esta puede ser nuestra elección. Pero no estábamos listos para multiplicar el parque de hierro para acelerar las tareas.
Druida / pinotYa hay mucho más sobre TSDB específicamente, pero de nuevo: Hadoop-stack.
Hay un
gran artículo que compara los pros y los contras de Druid y Pinot en comparación con ClickHouse .
En pocas palabras: Druid / Pinot se ven mejor que Clickhouse en casos donde:
- Usted tiene una naturaleza heterogénea de los datos (en nuestro caso, solo registramos series de tiempo de métricas del servidor y, de hecho, esta es una tabla. Pero puede haber otros casos: series temporales de equipos, series temporales económicas, etc., cada una con su propia estructura, que debe ser agregado y procesado).
- Además, hay muchos de estos datos.
- Las tablas y los datos con series temporales aparecen y desaparecen (es decir, se introdujo algún tipo de conjunto de datos, se analizó y eliminó).
- No existe un criterio claro por el cual los datos se puedan particionar.
En casos opuestos, ClickHouse se muestra mejor, y este es nuestro caso.
Clickhouse- Tipo SQL.
- Fácil de manejar
- La gente dice que funciona.
Cae en la lista de prueba.
InfluxdbAlternativa extranjera a ClickHouse. De las desventajas: la alta disponibilidad solo está presente en la versión comercial, pero debe compararse.
Cae en la lista de prueba.
CassandraPor un lado, sabemos que se utiliza para almacenar series de tiempo métricas en sistemas de monitoreo como, por ejemplo,
SignalFX u OkMeter. Sin embargo, hay detalles.
Cassandra no es una base de datos de columnas en el sentido habitual. Se parece más a una letra minúscula, pero cada fila puede tener un número diferente de columnas, por lo que es fácil organizar una representación de columna. En este sentido, está claro que con un límite de 2 mil millones de columnas, puede almacenar algunos datos en las columnas (sí, la misma serie de tiempo). Por ejemplo, en MySQL hay un límite en 4096 columnas y es fácil tropezar con un error con el código 1117 si intenta hacer lo mismo.
El motor Cassandra se centra en almacenar grandes cantidades de datos en un sistema distribuido sin un asistente, y en el teorema CAP anterior, Cassandra trata más sobre AP, es decir, sobre accesibilidad de datos y resistencia a la partición. Por lo tanto, esta herramienta puede ser excelente si solo necesita escribir en esta base de datos y rara vez leerla. Y aquí es lógico usar Cassandra como un almacenamiento "frío". Es decir, como un lugar confiable a largo plazo para almacenar grandes cantidades de datos históricos que rara vez se requieren, pero que se pueden obtener si es necesario. Sin embargo, en aras de la integridad, lo probaremos. Pero, como dije antes, no hay ningún deseo de reescribir activamente el código para la solución de base de datos seleccionada, por lo que lo probaremos de forma algo limitada, sin adaptar la estructura de la base de datos a los detalles de Cassandra.
PrometeoBueno, y por interés, decidimos probar el rendimiento de la tienda Prometheus, solo para comprender si somos más rápidos que las soluciones actuales o más lentos y cuánto.
Metodología y Resultados de la Prueba
Entonces, probamos 5 bases de datos en las siguientes 6 configuraciones: ClickHouse (1 nodo), ClickHouse (tabla distribuida de 3 nodos), InfluxDB, Mysql 8, Cassandra (3 nodos) y Prometheus. El plan de prueba es el siguiente:
- complete los datos históricos de la semana (840 millones de valores por día; 208 mil métricas);
- generar una carga de grabación (se consideraron 6 modos de carga, ver más abajo);
- Paralelamente a la grabación, periódicamente hacemos muestras, emulando las solicitudes de un usuario que trabaja con gráficos. Para no complicar demasiado las cosas, seleccionamos datos por 10 métricas (igual de ellas en el gráfico de la CPU) por semana.
Cargamos emulando el comportamiento de nuestro agente de supervisión, que envía valores a cada métrica cada 15 segundos. En este caso, estamos interesados en variar:
- número total de métricas en las que se escriben los datos;
- intervalo de envío de valores en una métrica;
- tamaño del lote
Sobre el tamaño del lote. Dado que no se recomienda que casi todas nuestras bases experimentales se carguen con inserciones individuales, necesitaremos un relé, que recolecte las métricas entrantes y las agrupe tanto como sea posible y las escriba en la base con un paquete insertado.
Además, para comprender mejor cómo interpretar los datos recibidos más tarde, imagine que no solo estamos enviando un montón de métricas, sino que las métricas están organizadas en servidores: 125 métricas por servidor. Aquí, el servidor es solo una entidad virtual, solo para entender que, por ejemplo, 10,000 métricas corresponden a aproximadamente 80 servidores.
Y así, teniendo en cuenta todo esto, nuestros 6 modos de carga de grabación de la base:
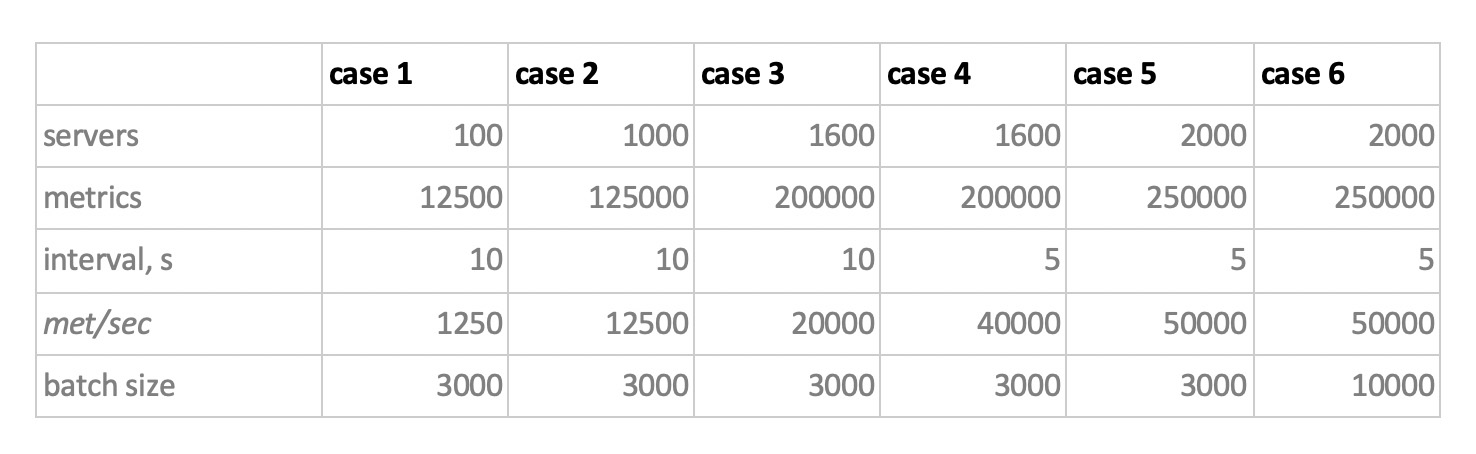
Hay dos puntos En primer lugar, para cassandra tales tamaños de lotes resultaron ser demasiado grandes, allí utilizamos valores de 50 o 100. Y en segundo lugar, ya que el prometeus funciona estrictamente en modo pull, es decir. él camina y recopila datos de fuentes métricas (e incluso la puerta de acceso, a pesar del nombre, no cambia fundamentalmente la situación), las cargas correspondientes se implementaron utilizando una combinación de configuraciones estáticas.
Los resultados de la prueba son los siguientes:
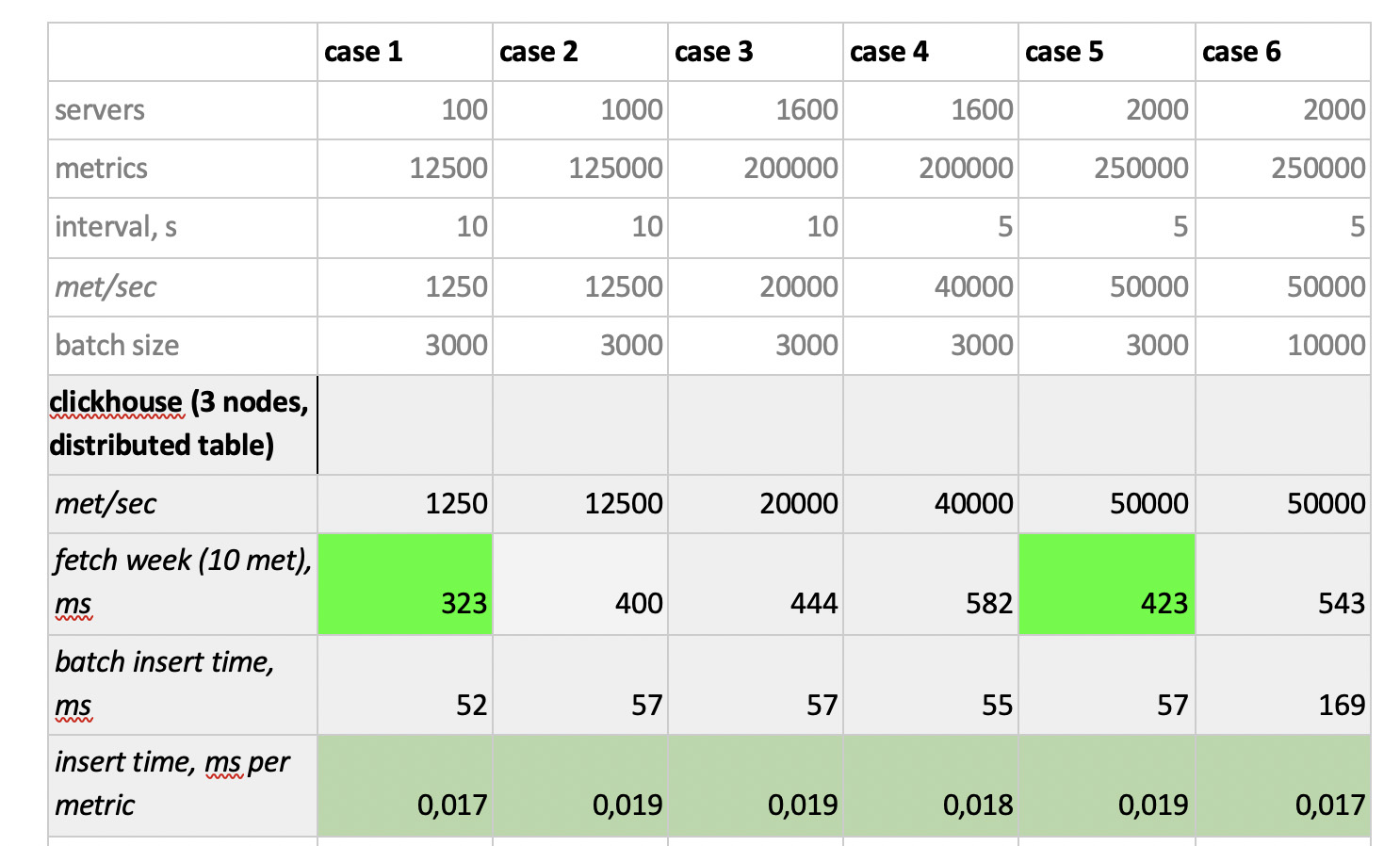
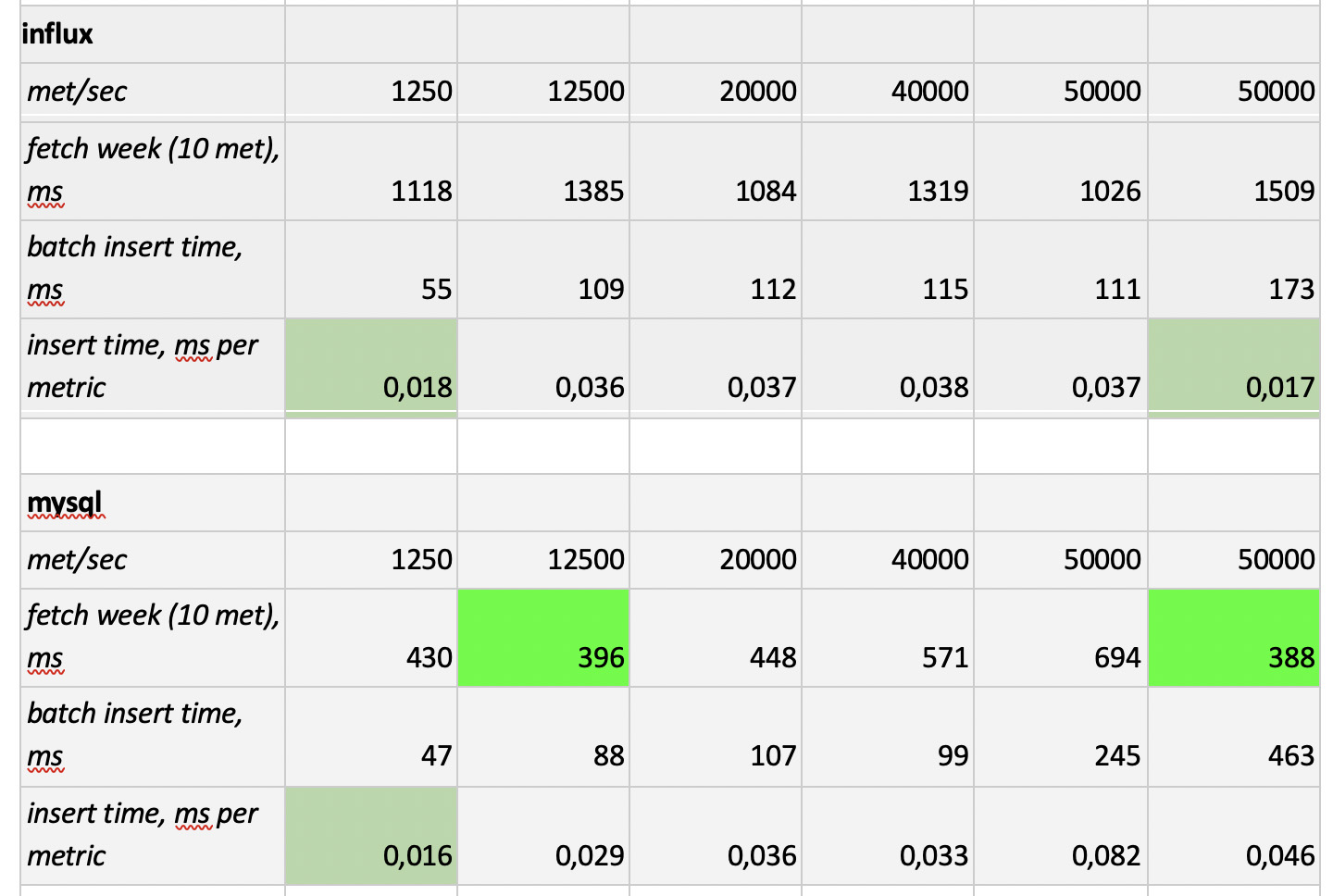
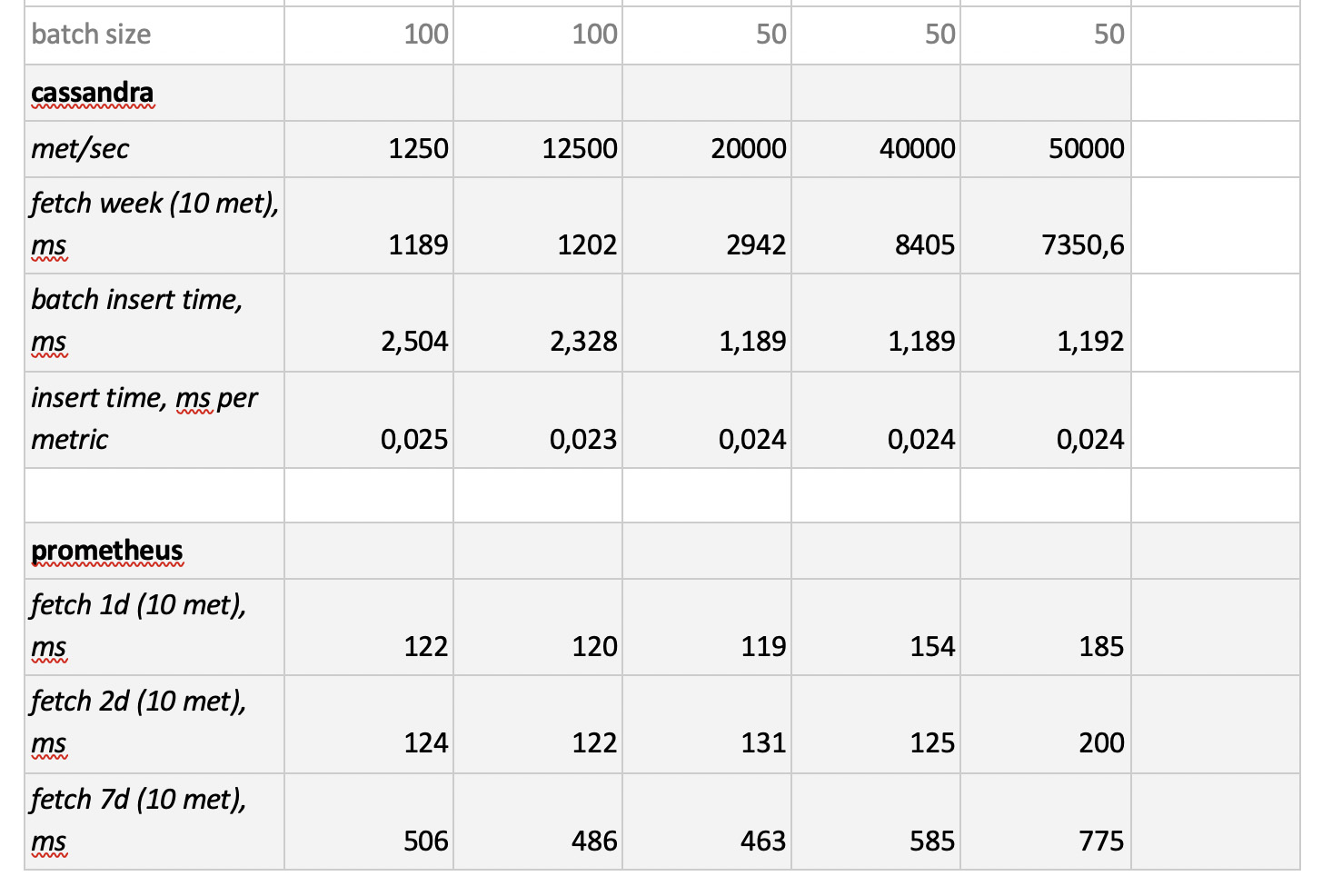 Lo que vale la pena señalar
Lo que vale la pena señalar : muestras fantásticamente rápidas de Prometheus, muestras terriblemente lentas de Cassandra, muestras inaceptablemente lentas de InfluxDB; ClickHouse ganó en términos de velocidad de grabación, y Prometheus no participa en la competencia, porque se inserta dentro de sí mismo y no medimos nada.
Como resultado : ClickHouse e InfluxDB se mostraron lo mejor de todo, pero un clúster de Influx solo se puede construir sobre la base de la versión Enterprise, que cuesta dinero, y ClickHouse no cuesta nada y se fabrica en Rusia. Es lógico que en EE. UU. La elección sea probablemente a favor de inInfluxDB, y en nuestro caso es a favor de ClickHouse.