Este es un resumen en inglés de dos artículos absolutamente sobresalientes escritos por
Vitaliy Malkin de "Informzashita" cuyo equipo, True0xA3, se convirtió en los ganadores de la prestigiosa competencia de sombrero negro The Standoff durante
Positive Hack Days 9 en mayo de 2019.
Vitaliy ha publicado tres artículos detallados sobre Habr, dos de los cuales se dedicaron a la descripción de las estrategias que el equipo True0xA3 utilizó antes y durante la competencia para asegurar a este equipo el título de los ganadores. Sentí que lo único que les faltaba a esos dos artículos era un resumen en inglés para que una audiencia más amplia de lectores pudiera disfrutarlos. Entonces, a continuación se muestra el resumen de dos artículos de
Vitaliy Malkin , junto con imágenes que Vitaliy publicó para aclarar sus puntos. Vitaliy me ha autorizado a hacer la traducción y publicarla.
PARTE I. Preparándose para la batalla.
El artículo original está aquí.I. Objetivos iniciales
El equipo constaba de 16 pentesters verdaderos y 4 internos, armados con 6 servidores y nuestra propia estación CUDA, además de la voluntad de llegar a la distancia.
Los preparativos activos comenzaron 8 días antes del comienzo de The Standoff. Este fue nuestro tercer intento de ganar The Standoff, por lo que algunos de nosotros tuvimos la experiencia suficiente para saber lo que había que hacer. Desde el principio, hemos discutido las siguientes prioridades para el equipo:
- Coordinación fluida entre los miembros del equipo.
- Colección de frutas bajas
- Explotación de vulnerabilidades no típicas para nosotros, como los sistemas de control de procesos automatizados (APCS), los sistemas de control distribuido (DCS), IoT, GSM
- Establecer nuestra propia infraestructura y equipo con anticipación
- Desarrollar alguna estrategia para la persistencia y el endurecimiento.
Coordinación
Esta es la debilidad de todos los novatos en el Standoff: las tareas no se distribuyen de manera efectiva; varias personas están trabajando en la misma tarea; no está claro qué tareas ya se han completado; los resultados de una tarea no se envían a los miembros apropiados del equipo, etc. Cuanto más grande es el equipo, menos efectiva es la coordinación entre los miembros del equipo. Lo que es más importante, debe haber al menos una persona que comprenda la imagen completa desde el punto de vista de la infraestructura y que pueda reunir múltiples vulnerabilidades en un vector de ataque enfocado.
Este año utilizamos la plataforma de colaboración Discord. Es similar al chat IRC pero con características adicionales como carga de archivos y llamadas de voz. Para cada objetivo en el mapa Standoff, creamos un canal separado en el que se recopilarían todos los datos. De esta forma, un nuevo miembro del equipo asignado a una tarea podría ver fácilmente toda la información que ya se ha recopilado para esta tarea, los resultados de las implementaciones, etc. Todos los canales de información tenían un límite de 1 mensaje por minuto para evitar inundaciones. Cada objeto en el Standoff tenía su propio espacio de chat dedicado.
Cada miembro del equipo recibió un alcance de trabajo claramente definido. Para mejorar la coordinación, se asignó una persona para tomar decisiones finales sobre todas las tareas. Esto nos impidió entrar en largas discusiones y desacuerdos durante la competencia.
Recolectando frutas bajas
Creo que el factor más importante en el juego resultó ser la capacidad de gestionar múltiples proyectos y priorizar adecuadamente los objetivos. En el juego del año pasado, pudimos tomar el control de una oficina y quedarnos allí simplemente porque usamos vulnerabilidades bien conocidas. Este año decidimos hacer una lista de tales vulnerabilidades con anticipación y organizar nuestro conocimiento:
ms17-010; ms08-67; SMBCRY LibSSH RCE; HP DATA Protector; HP iLo; ipmi Instalación inteligente de Cisco Java RMI JDWP; JBOSS; drupalgeddon2; weblogic desangrado concha ibm websphere iis-webdav; servicios; vnc; ftp-anon; NFS smb-null; TomcatLuego creamos 2 servicios, verificador y penetrador, que automatizaron las pruebas de vulnerabilidades y el despliegue de exploits y metasploits disponibles públicamente. Los servicios utilizaron los resultados de nmap para acelerar nuestro trabajo.
Explotación de vulnerabilidades no típicas para nosotros
No teníamos mucha experiencia con el análisis de vulnerabilidades de los Sistemas Automatizados de Control de Procesos (APCS). Aproximadamente 8 días antes del enfrentamiento comenzamos a profundizar en el tema. La situación con IoT y GSM era aún peor. Nunca tuvimos experiencia con estos sistemas fuera de los enfrentamientos anteriores.
Por lo tanto, en la etapa de preparación, seleccionamos a 2 personas para estudiar Sistemas de Control Automático de Procesos (APCS) y 2 más para estudiar GSM e IoT. El primer equipo en una semana creó una lista de enfoques típicos para la integración de los sistemas SCADA y estudió en detalle los videos de la infraestructura del año anterior dentro del Standoff. También descargaron aproximadamente 200 GB de varios HMI, controladores y otro software relacionado con los controladores. El equipo de IoT preparó algo de hardware y leyó todos los artículos disponibles sobre GSM. Esperábamos que fuera suficiente (alerta de spoiler: ¡no fue así!)
Conseguir nuestra propia infraestructura y equipos configurados
Como teníamos un equipo bastante grande, decidimos que necesitaríamos equipo adicional. Esto es lo que llevamos con nosotros:
- Servidor CUDA
- Laptop de respaldo
- Router wifi
- Interruptor
- Variedad de cables de red
- WiFi Alfa
- Patitos de goma
El año pasado entendimos la importancia del uso de servidores CUDA durante la piratería de un par de apretones de manos. Es importante tener en cuenta que este año, así como en años anteriores, todos los equipos rojos estaban detrás de un NAT, por lo que no pudimos usar conexiones inversas desde DMZ. Sin embargo, asumimos que todos los hosts que no sean los Sistemas de Control Automático de Procesos (APCS) tendrían una conexión a Internet. Con esto en mente, decidimos activar 3 servidores de escucha disponibles en Internet. Para facilitar el pivote, utilizamos nuestro propio servidor OpenVPN con cliente a cliente activado. Desafortunadamente, la creación automatizada de canales no fue posible, por lo tanto, durante 12 horas de 28, uno de los miembros del equipo se dedicó solo a administrar los canales.
Desarrollar alguna estrategia para la persistencia y el endurecimiento.
Nuestra experiencia previa con el enfrentamiento ya nos enseñó que no era suficiente con hacerse cargo de un servidor. Era igual de importante evitar que otros equipos también se establecieran. Por lo tanto, pasamos mucho tiempo en la RAT (Herramienta de administración remota) con nuevas firmas y scripts para fortalecer los sistemas Windows. Utilizamos una RAT estándar pero cambiamos ligeramente el método de ofuscación. Las reglas presentaron una mayor dificultad. En general, desarrollamos la siguiente lista de scripts:
- Cerrar los puertos SMB (bloque de mensajes del servidor) y RPC (llamada a procedimiento remoto)
- Mover RDP (protocolo de escritorio remoto) a puertos no estándar
- Desactivar el cifrado reversible, las cuentas de invitados y otros problemas típicos de la línea de base de seguridad
Para los sistemas Linux, desarrollamos un guión de inicio especial que cerró todos los puertos, movió SSH a un puerto no estándar y creó claves públicas para el acceso del equipo a SSH
II Briefing
El 17 de mayo, 5 días antes del enfrentamiento, los organizadores proporcionaron la información para los equipos rojos. Proporcionaron mucha información que afectó nuestra preparación. Publicaron el mapa de la red, que nos permitió dividir la red en zonas y asignar responsabilidades para cada zona a un miembro del equipo. La información más importante que proporcionaron los organizadores fue que APCS sería accesible solo desde un segmento de la red, y ese segmento no está protegido. Además, reveló que se otorgarán los puntos más altos para el APCS y para las oficinas aseguradas. También dijeron que recompensarían la capacidad de los equipos rojos de noquearse entre sí.
Interpretamos que esto significa lo siguiente: "Quien capture el bigbrogroup probablemente ganará el juego". Esto se debe a que nuestra experiencia previa nos ha enseñado que no importa cómo los organizadores penalicen la pérdida de servicio, los equipos azules matarán a los servidores vulnerables si no pueden parcharlos lo suficientemente rápido. Esto se debe a que sus respectivas compañías están mucho más preocupadas por la publicidad de un sistema totalmente pirateado que por algunos puntos perdidos en un juego. Nuestra suposición era correcta, como veremos pronto.
Por lo tanto, decidimos dividir el equipo en 4 partes:
I. Bigbrogroup . Decidimos priorizar esta tarea por encima de todas las demás, por lo que pusimos a nuestros pentesters más experimentados en ese grupo. Este mini equipo tenía 5 personas y su objetivo principal era hacerse cargo del dominio y evitar que otros equipos obtuvieran acceso al APCS.
II Redes inalámbricas . Este equipo fue responsable de mirar Wifi, rastrear nuevos WAP, capturar los apretones de manos y forzarlos. También fueron responsables de GSP, pero su objetivo principal era evitar que otros equipos se hicieran cargo de Wifi
III. Redes desprotegidas . Este equipo pasó las primeras 4 horas probando todas las redes desprotegidas y analizando vulnerabilidades. Entendimos que en las primeras 4 horas no podría pasar nada de interés en los segmentos protegidos, al menos nada que los equipos azules no pudieran eliminar, por lo tanto, decidimos pasar esas primeras horas protegiendo las redes desprotegidas, donde las cosas podrían cambiar. Y resultó que fue un buen enfoque.
IV. Grupo de escáneres . Los equipos azules nos dijeron de antemano que la topología de la red cambiará constantemente, por lo que dedicamos 2 personas a escanear la red y detectar cambios. La automatización de este proceso resultó ser difícil ya que teníamos múltiples redes con múltiples configuraciones. Por ejemplo, en la primera hora, nuestro nmap funcionó en modo T3, pero al mediodía apenas funcionaba en modo T1.
Otro vector importante fue la lista de software y tecnologías que los organizadores proporcionaron durante la sesión informativa. Creamos un grupo de competencia para cada una de las tecnologías que podría evaluar rápidamente las vulnerabilidades típicas. Para algunos servicios, encontramos vulnerabilidades conocidas pero no pudimos encontrar ninguna vulnerabilidad publicada. Este fue, por ejemplo, un caso con Redis Post-explotación RCE. Estábamos bastante seguros de que esta vulnerabilidad estaría presente en la infraestructura de Standoff, por lo tanto, decidimos escribir nuestro propio exploit de 1 día. Por supuesto, no pudimos escribir el exploit completo, pero en general reunimos 5 exploits inéditos que estábamos listos para implementar.
Desafortunadamente, no pudimos investigar todas las tecnologías, pero resultó no ser tan crítico. Como examinamos los de mayor prioridad, resultó ser suficiente. También preparamos la lista de controladores para APCS, que también investigamos en detalle.
Durante la fase de preparación, reunimos varias herramientas para la conexión subrepticia a la red APCS. Por ejemplo, preparamos una versión barata de una piña usando una frambuesa. Se conectaría a la red Ethernet de la producción y, a través de GSM, al servicio de control. Luego podríamos configurar remotamente una conexión Ethernet y luego transmitirla a través de un módulo wifi incorporado. Desafortunadamente, durante el juego, los organizadores dejaron en claro que la conexión física con el APCS estaría prohibida, por lo tanto, no pudimos usar el módulo.
Encontramos bastante información sobre el trabajo del banco, las cuentas en el extranjero y el antifraude. Sin embargo, también descubrimos que el banco no tenía tanto dinero, así que decidimos no pasar tiempo preparándonos para ese objeto, y solo jugarlo de oído durante el juego.
En resumen, trabajamos bastante durante la fase de preparación. Me gustaría señalar que, además del beneficio obvio de ser los ganadores de la competencia Standoff, obtuvimos beneficios menos notables pero no menos importantes, como
- Tomamos un descanso de las minucias cotidianas del trabajo y probamos algo que siempre habíamos esperado hacer.
- Esta fue nuestra primera experiencia en la que todo el equipo de pentesting estaba trabajando en una sola tarea, por lo que el efecto de creación de equipo fue muy notable.
- Mucha de la información que reunimos durante la preparación del juego que podemos usar para nuestros proyectos de pentesting de la vida real, hemos aumentado nuestro nivel de competencia y creado nuevas herramientas listas para usar
Mirando hacia atrás, me doy cuenta de que nuestra victoria en el enfrentamiento probablemente se aseguró mucho antes de que comenzara el juego, durante la etapa de preparación. Ahora, lo que realmente ocurrió durante el enfrentamiento se describirá en la Parte II de esta serie
Parte II. Ganar el enfrentamiento. Compartiendo los salvavidas
El artículo original está aquí.De Vitaliy Malkin, el jefe del equipo rojo de la compañía InformZachita y el capitán del equipo True0xA3. True0xA3 ganó una de las competiciones de sombreros blancos más prestigiosas de Rusia: el Standoff en PHDays 2019.
Día uno
9:45 MSKEl día comenzó recibiendo los resultados de MassScan. Comenzamos enumerando todos los hosts con 445 puertos abiertos, y exactamente a las 10 am implementamos el verificador para el metasploit MS17-010. Según nuestro plan, nuestro objetivo principal era capturar el controlador de dominio del dominio bigbrogroup, por lo tanto, 2 personas de nuestro equipo se dedicaron solo a eso. A continuación verá las tareas iniciales para cada grupo.
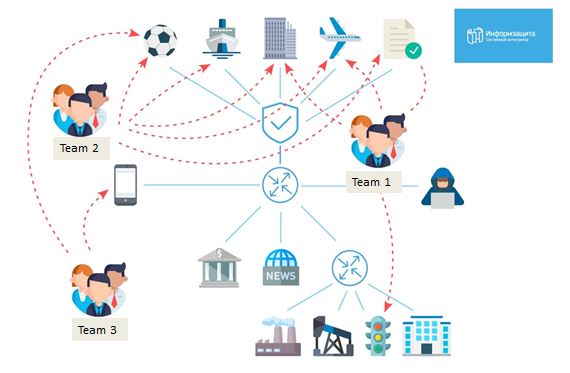
Como puede ver, intentamos penetrar en todas las oficinas del juego, y el hecho de que teníamos 20 personas estaba haciendo una gran diferencia.
10:15Uno de los miembros del equipo de Team1 encuentra un host en el dominio bigbrogroup.phd que es vulnerable a MS17-010. Desplegamos el exploit con mucha prisa. Hace un par de años tuvimos la situación en la que pudimos llevar el shell meterpreter (ataque de phishing que llevaba el código de ejecución remoto) a un objetivo importante, pero nos expulsaron en 10 segundos. Este año estuvimos más preparados. Asumimos el host, cerramos el puerto SMB y cambiamos el RDP al puerto 50002. Prestamos mucha atención al proceso de persistencia en el dominio, por lo tanto, creamos algunas cuentas de administrador local e implementamos nuestras propias Herramientas de administración remota (RAT) . Solo después de eso pasamos a la siguiente tarea
10:25Continuamos revisando los resultados de la información que recopilamos del anfitrión. Además del acceso a la red interna y la conexión al controlador de dominio, también encontramos el token del administrador de dominio. Antes de entusiasmarnos demasiado, verificamos si el token sigue siendo válido. Y luego nos regocijamos. El primer dominio ha caído. El tiempo total empleado es de 27 min 52 segundos
Media hora después de la hora de inicio, visitamos el portal del jugador para comprender las reglas para entregar banderas y recibir puntos. Vemos la lista estándar: los inicios de sesión de administrador de dominio, los administradores locales, los administradores de intercambio y algunos otros administradores. Desde el dominio, descargamos ntds.dit y al mismo tiempo preparamos nuestra estación CUDA. Luego descubrimos que el cifrado reversible es esto en el dominio, por lo que ahora podemos obtener todas las contraseñas que necesitamos. Para comprender qué contraseñas necesitamos, formamos un equipo de 2 personas que comienzan a analizar la estructura del AD y sus grupos. 5 minutos después entregan los resultados. Entregamos nuestras banderas y esperamos. Ya era hora de obtener nuestra Primera Sangre, al menos para aumentar la moral del equipo si nada más. Pero nada Nos llevó una hora tratar de entender que el corrector funciona así:
- Es automatizado
- Tiene un formato muy inflexible.
- Si pasa sus banderas al cheque y no recibió una respuesta en unos segundos, entonces su formato no coincide con el formato del verificador
Finalmente, descubrimos el formato correcto y alrededor de las 11 de la mañana tenemos nuestra Primera Sangre. ¡Uf!
11:15El equipo 1 se está dividiendo en dos equipos secundarios. El subteam 1 continúa fortaleciendo el dominio: obtienen krbtgt, endurecen la línea de base, cambian las contraseñas de los servicios de directorio. Los organizadores de Standoff nos dijeron durante la sesión informativa que los primeros en el dominio pueden jugar como quieran. Así que cambiamos las contraseñas de administrador para que, incluso si alguien entra y logra echarnos, no podrán obtener los inicios de sesión para entregar sus banderas por puntos.
El equipo 2 continúa investigando la estructura del dominio y encuentra otra bandera. En el escritorio del CFO, encuentran un informe financiero. Desafortunadamente, está comprimido y protegido con contraseña. Entonces, encendemos la estación CUDA. Convertimos el zip en un hash y lo enviamos a hashcat.
El Equipo 2 continúa encontrando servicios interesantes con RCE (ejecución remota de código) y comienza a buscarlos. Uno de ellos es un servicio de monitoreo para el dominio cf-media construido sobre la base de Nagios. Otro es el administrador de horarios para una compañía de envío creada en torno a una tecnología extraña que nunca antes habíamos visto. También hay algunos servicios interesantes, como los convertidores DOC a DPF.
El segundo equipo del Equipo 1 para ese momento ya comenzó a trabajar en el banco y encontró una base de datos interesante en MongoDB, que contiene, entre muchas otras cosas, el nombre de nuestro equipo y otros equipos, y sus saldos. Cambiamos el saldo de nuestro equipo a 50 millones y seguimos adelante.
2 p.m.La suerte nos ha dejado. En primer lugar, los dos servicios para los que teníamos RCE en los segmentos protegidos dejaron de estar disponibles. El equipo azul simplemente los apagó. Por supuesto, nos quejamos a los organizadores por violaciones a las reglas, pero sin efecto. ¡En el enfrentamiento no hay procesos comerciales que proteger! En segundo lugar, no podemos encontrar una lista de clientes. Sospechamos que está oculto en algún lugar en las profundidades de 1C, pero no tenemos bases de datos ni archivos de configuración. Callejón sin salida.
Estamos tratando de configurar el canal VPN entre nuestros servidores remotos y los Sistemas de Control Automático de Procesos (APCS). Por alguna extraña razón, no lo hacemos en el controlador de dominio de bigbrogroup, y la conexión entre las interfaces se rompe. Ahora el controlador de dominio no es accesible. La parte del equipo responsable del acceso al dominio casi sufre un ataque al corazón. La tensión entre los miembros del equipo crece, comienzan las huellas digitales.
Entonces nos damos cuenta de que el controlador de dominio es accesible, pero la conexión VPN es inestable. Retrocedemos cuidadosamente en nuestros pasos, a través de RDP apagamos la VPN, y listo, el controlador de dominio es accesible nuevamente. El equipo exhala colectivamente. Al final, configuramos la VPN desde otro servidor. El controlador de dominio está siendo maltratado y mimado. Todos los equipos competidores todavía tienen 0 puntos, y esto es tranquilizador.
16:50Los organizadores finalmente publican un minero. Usando psexec lo configuramos en todos los puntos finales que controlamos. Esto trae un poco de flujo constante de ingresos.
El equipo 2 todavía está trabajando en la vulnerabilidad de Nagios. Tienen la versión con la vulnerabilidad.
<= 5.5.6 CVE-2018-15710 CVE-2018-15708. Hay un exploit público disponible, pero necesita una conexión inversa para descargar el shell web. Como estamos detrás del NAT, tenemos que reescribir el exploit y dividirlo en dos partes. La primera parte obliga a Nagios a conectarse a nuestro servidor remoto a través de Internet, y la segunda parte, ubicada en el servidor, le da a Nagios el shell web. Esto nos da acceso a través del proxy al dominio cf-media. Pero la conexión es inestable y difícil de usar, por lo que decidimos vender el exploit por los dólares de BugBounty, al mismo tiempo que tratamos de elevar nuestro acceso a la raíz.
18:07Aquí vienen las "sorpresas" prometidas por los organizadores. Anuncian que BigBroGroup acaba de comprar CF-media. No estamos terriblemente sorprendidos. Durante nuestra investigación del dominio bigbrogroup, notamos las relaciones de confianza entre los dominios bigbrogroup y cf-media.
En el momento en que se anunció la adquisición de los medios CF, aún no teníamos conexión a su red. Pero después del anuncio, apareció el acceso. Esto nos salvó de girar nuestras ruedas tratando de pivotar desde Nagios. Las credenciales de Bigbrogroup funcionan en el dominio cf-media, pero los usuarios no tienen privilegios. Todavía no se encuentran vulnerabilidades fácilmente explotables, pero somos bastante optimistas de que algo aparecerá.
18:30De repente, nos expulsan del dominio de bigbrogroup. Por quien? Como? ¡Parece que el equipo TSARKA es el culpable! Están cambiando la contraseña de administrador, pero tenemos otras 4 cuentas de administrador en las reservas. Cambiamos la contraseña de administrador de dominio nuevamente, restablecemos todas las contraseñas. ¡Pero minutos después nos echan de nuevo! En ese momento exacto, encontramos un vector para el dominio cf-media. En uno de sus servidores, el nombre de usuario y la contraseña coinciden con los que encontramos anteriormente en el dominio bigbrogroup. ¡Oh, contraseña reutilizada! ¿Qué haríamos sin ti? Ahora solo necesitamos un hash. Usamos hashkiller y obtenemos la contraseña P @ ssw0rd. Siguiendo adelante.
19:00La lucha por el control del bidbrogroup se está convirtiendo en un problema grave. TSARKA ha cambiado la contraseña a krbtgt dos veces, perdemos todas las cuentas de administrador ... ¿qué sigue? Callejón sin salida?
19:30Finalmente obtenemos los privilegios de administrador de dominio en cf-media y comenzamos a activar nuestras banderas. A pesar de que se supone que este es un dominio seguro, vemos encriptación reversible. Entonces, ahora tenemos los inicios de sesión y las contraseñas, y procedemos a través de los mismos pasos que con el bigbrogroup. Creamos administradores adicionales, fortalecemos nuestro punto de apoyo, fortalecemos la línea de base, cambiamos las contraseñas, creamos una conexión VPN. Encontramos un segundo informe financiero, también como un zip protegido. Verificamos con el equipo responsable del primer informe. Lo han logrado, pero los organizadores no lo aceptarán. Resulta que tenía que ser entregado como un 7zip protegido. Por lo tanto, ¡ni siquiera tuvimos que usarlo en bruto! 3 horas de trabajo por nada.
Entregamos ambos informes como archivos 7zip protegidos. Nuestro saldo total hasta ahora es de 1 millón de puntos, y TSARKA tiene 125,000, y están comenzando a entregar sus banderas del dominio de bigbrogroup. Nos damos cuenta de que debemos evitar que entreguen sus banderas, pero ¿cómo?
19:30¡Encontramos una solución! Todavía tenemos las credenciales de los administradores locales. Iniciamos sesión, tomamos el ticket y simplemente apagamos el controlador de dominio. El controlador se está apagando. Cerramos todos los puertos del servidor excepto RDP y cambiamos las contraseñas de todos nuestros administradores locales. Ahora estamos en nuestro pequeño espacio y ellos están en el suyo. ¡Ojalá la conexión VPN se mantuviera estable! El equipo exhala colectivamente.
Mientras tanto, configuramos mineros en todos los puntos finales en el dominio cf-media. TSARKA está por delante de nosotros en el volumen general, pero no estamos muy lejos y tenemos más caballos de fuerza.
Noche
Aquí puedes ver los cambios que hicimos en el equipo durante la noche.

Algunos de los miembros del equipo tienen que irse a pasar la noche. A medianoche, tenemos 9 personas. La productividad cae a casi cero. Cada hora nos levantamos para mojarnos la cara con agua y salir para tomar aire, solo para sacudirnos la somnolencia.
Ahora, por fin, estamos llegando a los Sistemas Automatizados de Control de Procesos (APCS)
02.00Las últimas horas han sido muy desalentadoras. Hemos encontrado varios vectores, pero ya están cerrados. No podemos decir si estaban cerrados para empezar o si TSARKA ya ha estado aquí. Estudiando lentamente el APCS, encontramos un controlador NetBus vulnerable. Usamos un módulo metasploit que no entendemos completamente cómo funciona. De repente, las luces de la ciudad se apagan. Los organizadores anuncian que contarán esto si podemos volver a encender la luz. En ese momento, nuestra VPN se cae. ¡El servidor que administra la VPN fue asumido por TSARKA! Parece que estábamos discutiendo el APCS demasiado fuerte y lograron hacerse cargo.
03.30Incluso los más dedicados de nosotros están empezando a quedarse dormidos. Solo 7 siguen trabajando. De repente, sin ninguna explicación, la VPN vuelve a encenderse. ¡Repetimos rápidamente el truco con las luces de la ciudad, y vemos que nuestro saldo aumenta en 200,000 puntos!
Una parte del equipo todavía está buscando vectores adicionales, mientras que otra está trabajando en el APCS. Allí encontramos dos vulnerabilidades adicionales. Uno de ellos podemos explotar. Pero el resultado del exploit podría ser una reescritura del firmware del microcontrolador. Discutimos esto con los organizadores y decidimos que esperaremos a que el resto de nuestro equipo se una a nosotros por la mañana y luego decidamos colectivamente qué hacer.
05:30Nuestra VPN funciona aproximadamente 10 minutos cada hora, y luego se desconecta nuevamente. Dentro de ese tiempo, tratamos de trabajar. Pero la productividad es cercana a cero. Finalmente, decidimos tomar una hora cada una para tomar una siesta. Alerta de spoiler: ¡mala idea!
5 personas siguen trabajando en el APCS.
Mañana
Por la mañana, de repente nos damos cuenta de que estamos por delante de otros equipos en casi 1 millón de puntos. TSARKA pudo entregar dos banderas de APCS, además de varias banderas del proveedor de telecomunicaciones y bigbrogroup. Además, tienen mineros trabajando, y deben tener algunas criptomonedas que aún no han entregado. Estimamos que tenían un mínimo de 200-300 mil puntos más en criptografía. Esto es desconcertante. Tenemos la sensación de que podrían tener algunas banderas más que están reteniendo estratégicamente hasta las últimas horas. Pero nuestro equipo vuelve a estar en línea. La prueba de sonido de la mañana en la arena principal es un poco molesta pero ahuyenta el sueño.
Todavía estamos trabajando para intentar entrar en el APCS, pero la esperanza está disminuyendo. La diferencia en los puntos entre el primer y el segundo equipo y el resto de los equipos es gigantesca. Nos preocupa que los organizadores decidan lanzar algunas "sorpresas" más para sacudir las cosas.
Después de una conferencia de prensa conjunta con TSARKA en la arena principal, decidimos cambiar nuestra estrategia de "obtener más banderas" para "evitar que TSARKA entregue más banderas".
En uno de nuestros servidores, activamos Cain & Abel y redirigimos todo el tráfico a nuestro servidor. Encontramos algunas VPN de Kazajstán y las matamos. Luego decidimos eliminar todo el tráfico en todas partes, por lo que creamos un firewall local en el canal VPN para eliminar todo el tráfico dentro de la red APCS. ¡Así es como proteges un APCS! Los organizadores ahora se quejan de que perdieron la conexión con el APCS. Abrimos el acceso a sus direcciones IP (NO es así como protege el APCS).
12:47Teníamos razón al preocuparnos de que los organizadores intentaran sacudir las cosas. De la nada, hay un volcado de datos que contiene 4 inicios de sesión para cada dominio. Movilizamos a todo el equipo.
Objetivos:
Equipo 1 : asume de inmediato todos los segmentos protegidos.
Equipo 2 : use Outlook Web Access para cambiar todas las contraseñas a los inicios de sesión.
Algunos equipos azules, que perciben mucha actividad, simplemente apagan la VPN. Otros son más engañosos y cambian el idioma del sistema al chino. Técnicamente, el servicio aún está activo. Pero, por supuesto, en la práctica, no es utilizable (organizadores, ¡presten atención!). A través de VPN podemos conectarnos a 3 de las redes. En uno de ellos, solo duramos 1 minuto antes de ser expulsados.
 12:52
12:52Localizamos un servidor saludable con la vulnerabilidad MS17-010 (¿supuestamente un segmento protegido?). Lo explotamos rápidamente, sin encontrar resistencia. Obtenemos el hash del administrador de dominio y a través de Pth accedemos al controlador de dominio. ¿Y adivina qué encontramos allí? Encriptación reversible!
Quien estaba protegiendo ese segmento no ha hecho su tarea. Recopilamos todas las banderas, excepto la parte relacionada con 1C. Existe una buena posibilidad de que lo consigamos si pasamos otros 30-40 minutos allí, pero decidimos simplemente apagar el controlador de dominio saludable. ¿Quién necesita competencia?
13:20Entregamos nuestras banderas. Ahora tenemos 2,900,000 puntos, más algunas recompensas de errores pendientes. TSARKA tiene un poco más de 1 millón. Entregan su criptomoneda y obtienen otros 200,000. Ahora estamos bastante seguros de que no podrán ponerse al día, sería casi imposible.
13:55La gente viene y nos felicita. Todavía estamos preocupados por alguna sorpresa de los organizadores, ¡pero parece que realmente estamos siendo anunciados como los ganadores!
Esta es la crónica de las 28 horas de True0xA3. Por supuesto, me salí mucho. Por ejemplo, las conferencias de prensa en la arena, la tortura que fueron el Wifi y el GSM, la interacción con los reporteros ... pero espero haber capturado los momentos más interesantes.
Esta fue una de las experiencias más elevadas para nuestro equipo, y espero haber podido darte al menos un poco de idea de cómo se siente la atmósfera del Standoff, y para motivarte a que intentes participar también. !
A continuación, publicaré la última parte de esta serie, donde analizaré nuestros errores y las formas de corregirlos en el futuro. Porque aprender sobre los errores de otra persona es el mejor tipo de aprendizaje, ¿verdad?