Mi nombre es Oleg Ermakov, trabajo en el equipo de desarrollo de backend de la aplicación Yandex.Taxi. Es costumbre para nosotros realizar stand-ups diarios donde cada uno de nosotros habla sobre las tareas realizadas durante el día. Así es como sucede ...
Los nombres de los empleados pueden cambiar, ¡pero las tareas son bastante reales!A las 12:45, todo el equipo se reúne en la sala de reuniones. La primera palabra es tomada por Ivan, un desarrollador en prácticas.
Ivan:
Trabajé en la tarea de mostrar todas las opciones posibles para las cantidades que el pasajero podría dar al conductor a un costo conocido del viaje. La tarea es bastante conocida: se llama "Cambio de monedas". Teniendo en cuenta los detalles, agregó varias optimizaciones al algoritmo. Ayer presenté la solicitud de la piscina para la revisión, pero desde entonces he estado corrigiendo los comentarios.
Por la sonrisa de satisfacción de Anna, quedó claro qué comentarios corrige Ivan.
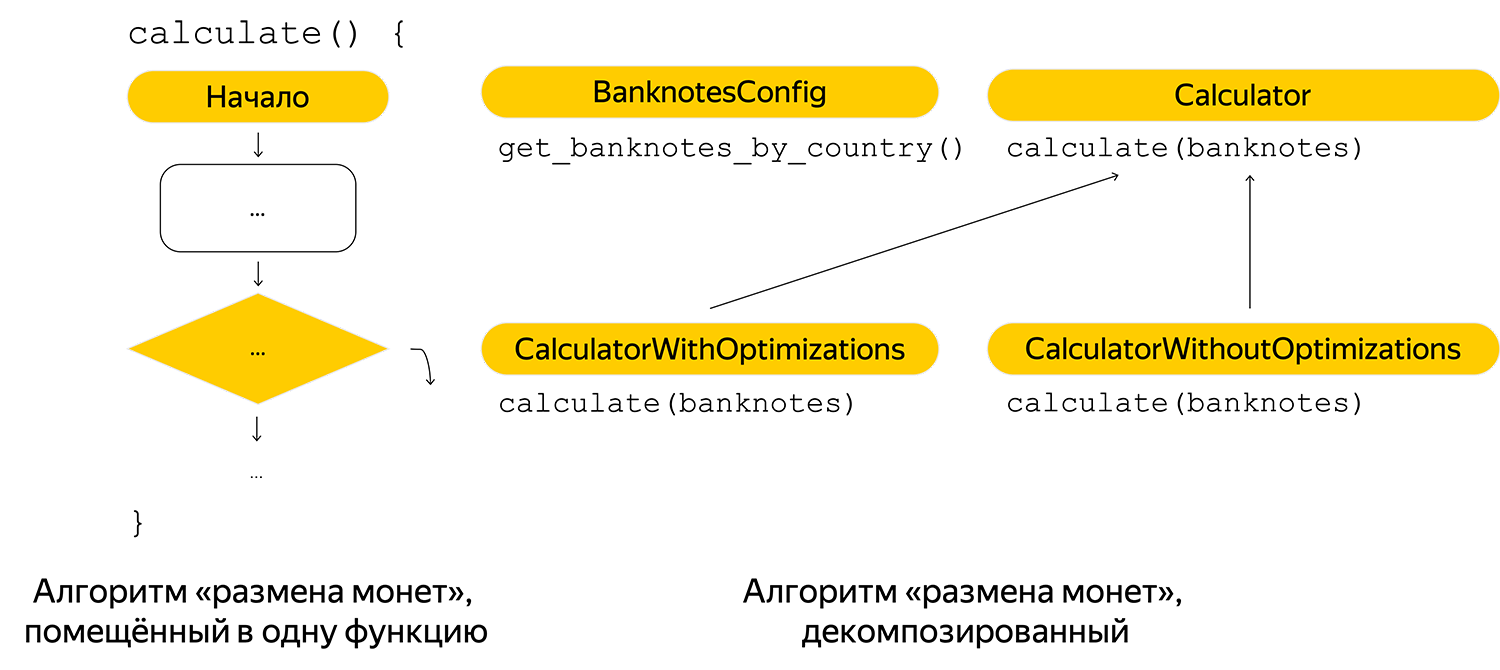
En primer lugar, realizó la descomposición mínima del algoritmo y estaba recibiendo billetes de forma inteligente. En la primera implementación, los posibles billetes se registraron en el código, por lo tanto, se sacaron a la configuración por país.
Comentarios agregados para el futuro, para que cualquier lector pueda descubrir rápidamente el algoritmo:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Bueno, por supuesto, pasé el resto del tiempo cubriendo todo el código con pruebas.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [
Además de las pruebas habituales que se ejecutan en cada compilación del proyecto, escribió una prueba que utiliza un algoritmo sin optimizaciones (considérelo un fracaso completo). El resultado de este algoritmo para cada factura de los primeros 10 mil casos colocados en un archivo y se ejecutó por separado en el algoritmo con optimizaciones para asegurarse de que realmente funciona correctamente.
Tomemos un momento para distraernos de la situación y resumir los resultados locales de todo lo que Ivan dice. Al escribir código, el objetivo principal es garantizar su rendimiento. Para lograr este objetivo, debe completar las siguientes tareas:
- Descomponga la lógica empresarial en fragmentos atómicos. La legibilidad es complicada cuando se visualiza un lienzo de código escrito en una función.
- Agregue comentarios a las partes "particularmente complejas" del código. Nuestro equipo tiene el siguiente enfoque: si le hacen una pregunta sobre la implementación de la revisión del código (le piden que explique el algoritmo), entonces debe agregar un comentario. Mejor aún, piense de antemano y agréguelo usted mismo.
- Escriba pruebas que cubran las ramas principales de la ejecución del algoritmo. Las pruebas no son solo un método para verificar el estado del código. Todavía sirven como ejemplo de uso de su módulo.
Por desgracia, incluso los especialistas con muchos años de experiencia no siempre utilizan estos enfoques en su trabajo. En
la escuela de desarrollo de backend que estamos haciendo ahora, los estudiantes obtendrán habilidades prácticas para escribir códigos arquitectónicos de alta calidad. Nuestro otro objetivo es difundir las prácticas de cobertura de prueba para el proyecto.
Pero volvamos al stand-up. Después de Ivan, Anna habla.
Anna:
Estoy desarrollando un microservicio para devolver imágenes de promoción. Como recordará, el servicio inicialmente proporcionó stubs de datos estáticos. Luego, los evaluadores me pidieron que los personalizara, y los puse en la configuración, y ahora estoy haciendo una implementación "honesta" con la devolución de datos de la base de datos (PostgreSQL 10.9). La descomposición establecida al principio me ayudó mucho, en cuyo marco la interfaz para recibir datos en la lógica empresarial no cambia, y cada nueva fuente (ya sea una configuración, una base de datos o un microservicio externo) solo implementa su propia lógica.

Revisé el sistema escrito bajo carga, las pruebas mostraron que el mango comienza a frenar bruscamente cuando vamos a la base de datos. Según explican, vi que el índice no se usa. Hasta que descubrí cómo solucionarlo.
Vadim
¿Y qué tipo de solicitud?
Anya
Dos condiciones bajo OR:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
La explicación de la consulta mostró que no utiliza uno de los índices para los atributos attr1 de table_2 y attr2 de table_1.
Vadim
Frente a un comportamiento similar en MySQL, el problema está precisamente en la condición de OR, debido a que solo se usa un índice, digamos attr2. Y la segunda condición usa la exploración seq: un pase completo a través de la tabla. La solicitud se puede dividir en dos solicitudes independientes. Como opción, divida y congele el resultado de la consulta en el lado del backend. Pero luego debe pensar en envolver estas dos solicitudes en una transacción, o combinarlas usando UNION, de hecho, en el lado base:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Anya
Gracias, lo intentaré ^ _ ^
Para resumir de nuevo:
- Casi todas las tareas de desarrollo de productos están relacionadas con la obtención de registros de fuentes externas (servicios o bases de datos). Debe abordar cuidadosamente el tema de la descomposición de las clases que descargan datos. Las clases diseñadas adecuadamente le permitirán escribir pruebas y modificar fuentes de datos sin problemas.
- Para trabajar de manera efectiva con la base de datos, debe conocer las características de la ejecución de consultas, por ejemplo, comprender explicar.
Trabajar con información y organizar flujos de datos es una parte integral de las tareas de cualquier desarrollador de back-end. La escuela introducirá la arquitectura de la interacción de servicios (y fuentes de datos). Los estudiantes aprenderán a trabajar con bases de datos arquitectónicamente y en términos de operación: migración de datos y pruebas.
El último en hablar es Vadim.
Vadim
Estuve de servicio durante una semana, resolví la secuencia de incidentes. Un error ridículo en el código tomó mucho tiempo: no había registros a pedido en el producto, aunque su creación estaba escrita en el código.
Por el triste silencio de todos los presentes, está claro: todos de alguna manera ya enfrentaron el problema .
Para obtener todos los registros como parte de la solicitud, se utiliza request_id, que se incluye en todos los registros de la siguiente forma:
log_extra es un diccionario con metainformación de la solicitud, cuyas claves y valores se escribirán en el registro. Sin pasar log_extra a la función de registro, el registro no se asociará con todos los demás registros, ya que no tendrá request_id.
Tuve que corregir el error en el servicio, volver a implementarlo y solo entonces lidiar con el incidente. Esta no es la primera vez que esto ha sucedido. Para evitar que esto vuelva a ocurrir, intenté solucionar el problema globalmente y eliminar log_extra.
Primero escribí un contenedor sobre la ejecución estándar de la solicitud:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
Era necesario decidir cómo almacenar log_extra en una sola solicitud. Había dos opciones. El primero es cambiar task_factory para eventloop de asyncio:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task
La segunda opción es "impulsar" la transición a Python 3.7 a través del comando de infraestructura para usar contextvars :
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Bueno y más, era necesario reenviar almacenado en el contexto de log_extra en logger.
class LogExtraFactory(logging.LogRecord):
Resumen:
- En Yandex.Taxi (y en todas partes en Yandex), asyncio se usa activamente. Es importante no solo poder usarlo, sino también comprender su estructura interna.
- Desarrolle el hábito de leer los registros de cambios de todas las versiones nuevas del lenguaje, piense en cómo puede facilitarle la vida a usted y a sus colegas con la ayuda de innovaciones.
- Cuando trabaje con bibliotecas estándar, no tenga miedo de rastrear su código fuente y comprender su dispositivo. Esta es una habilidad muy útil que le permitirá comprender mejor el funcionamiento del módulo y abrir nuevas posibilidades en la implementación de funciones.
Los maestros de la escuela secundaria comieron más de una
libra de sal y llenaron muchos conos en la operación asincrónica de los servicios. Les informarán a los estudiantes sobre las características de la operación asincrónica de Python, tanto a nivel práctico como en el análisis de componentes internos de paquetes.
Libros y enlaces
Aprender Python puede ayudarte:
- Tres libros: Python Cookbook , Diving Into Python 3 y Python Tricks .
- Conferencias en video de los pilares de la industria de TI, como Raymond Hettinger y David Beasley. De las conferencias en video de la primera, se puede distinguir el informe "Más allá de PEP 8 - Mejores prácticas para un hermoso código inteligible". Beasley le aconseja ver una actuación sobre asyncio.
Para obtener un mayor nivel de comprensión de la arquitectura, lea los libros:
- "Aplicaciones altamente cargadas" . Aquí, los problemas de interacción con los datos se describen en detalle (codificación de datos, trabajo con datos distribuidos, replicación, particionamiento, transacciones, etc.).
- “Microservicios. Desarrollo y refactorización de patrones " . El libro muestra los enfoques básicos de la arquitectura de microservicios, describe las deficiencias y problemas que uno tiene que enfrentar al cambiar de un monolito a microservicios. No hay casi nada en la publicación sobre ellos, pero aún así te aconsejo que leas este libro. Comenzará a comprender las tendencias en la construcción de arquitecturas y aprenderá las prácticas básicas de descomposición de código.
Otra de las habilidades más importantes que puedes desarrollar infinitamente en ti mismo es leer el código de otra persona. Si de repente te das cuenta de que rara vez lees el código de otra persona, te aconsejo que desarrolles el hábito de ver regularmente nuevos
repositorios populares.
El stand-up terminó, todos se pusieron a trabajar.