Los datos de series temporales o series temporales son datos que cambian con el tiempo. Las cotizaciones de divisas, la telemetría de los movimientos de transporte, las estadísticas de acceso al servidor o la carga de la CPU son datos de series temporales. Para almacenarlos se requieren herramientas específicas: bases de datos temporales. Hay docenas de herramientas, por ejemplo, InfluxDB o ClickHouse. Pero incluso las mejores soluciones de almacenamiento de series temporales tienen desventajas. Todos los almacenamientos de series temporales son de bajo nivel, adecuados solo para datos de series temporales, y ejecutar e inyectar en la pila actual es costoso y doloroso.

Pero, si tiene una pila PostgreSQL, puede olvidarse de InfluxDB y todas las demás bases de datos temporales. Instale dos extensiones, TimescaleDB y PipelineDB, y almacene, procese y analice datos de series temporales directamente en el ecosistema PostgreSQL. Sin la introducción de soluciones de terceros, sin las desventajas de los almacenamientos temporales y sin los problemas de ejecutarlos. Cuáles son estas extensiones, cuáles son sus ventajas y capacidades, le dirá a
Ivan Muratov ( binakot ) , el jefe del departamento de desarrollo de la "Primera Compañía de Monitoreo".
¿Qué son las series temporales o las series temporales?
Estos son datos sobre el proceso que se recopilan en diferentes momentos de su vida.
Por ejemplo, la ubicación del automóvil: velocidad, coordenadas, dirección o el uso de recursos en el servidor con datos sobre la carga en la CPU, RAM utilizada y espacio libre en disco.
Las series de tiempo tienen varias características.
- En una correa de fijación . Cualquier registro de serie temporal tiene un campo con una marca de tiempo en la que se registró el valor.
- Las características del proceso, que se denominan niveles de la serie : velocidad, coordenadas, datos de carga.
- Casi siempre con dichos datos funcionan en modo de solo agregar . Esto significa que los nuevos datos no reemplazan a los antiguos. Solo se eliminan los datos obsoletos.
- Las entradas no se consideran por separado entre sí . Los datos se usan solo colectivamente para ventanas de tiempo, intervalos o períodos.
Soluciones de almacenamiento populares
El gráfico que tomé de
db-engines.com muestra la popularidad de varios modelos de almacenamiento en los últimos dos años.
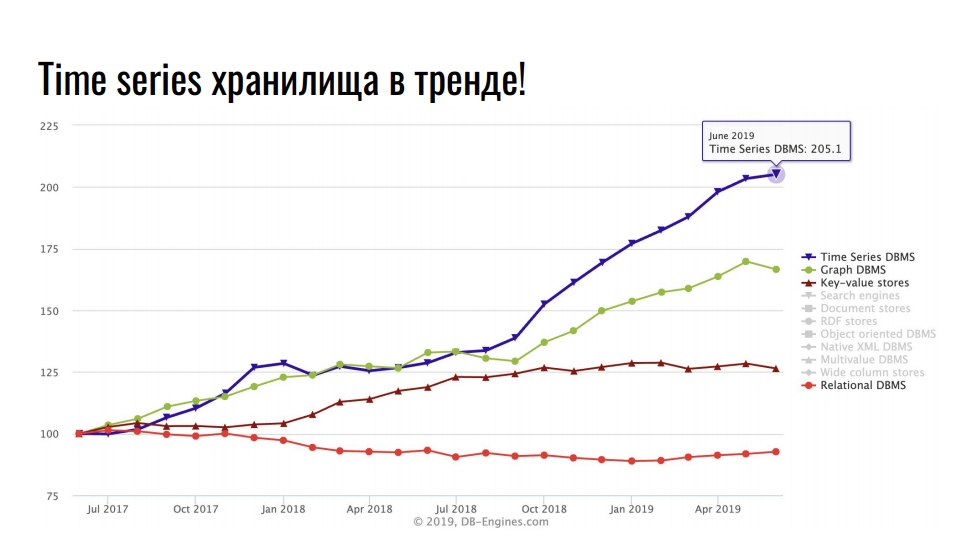
La posición de liderazgo está ocupada por almacenamientos de series de tiempo, en segundo lugar - bases de datos de gráficos, luego - bases de datos clave y relacionales. La popularidad de los repositorios especializados se asocia con un crecimiento intensivo en la integración de las tecnologías de la información: Big Data, redes sociales, IoT, monitoreo de infraestructura de alta carga. Además de los datos comerciales útiles, incluso los registros y las métricas ocupan una gran cantidad de recursos.
Soluciones de almacenamiento populares para datos de series temporales
El gráfico muestra soluciones especializadas para almacenar datos de series temporales. La escala es logarítmica.
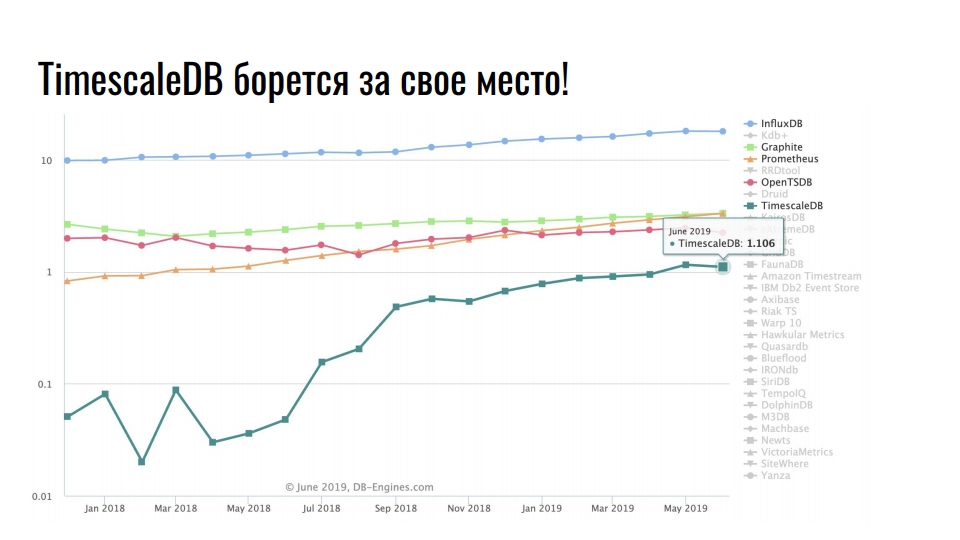
Líder estable InfluxDB. Todos los que han encontrado datos de series de tiempo han escuchado sobre este producto. Pero el gráfico muestra un aumento de diez veces en TimescaleDB: una extensión del DBMS relacional está luchando por un lugar bajo el sol entre los productos que se desarrollaron originalmente en la serie temporal.
PostgreSQL no es solo una buena base de datos, sino también una plataforma extensible para desarrollar soluciones especializadas.
Postgres, Postgis y TimescaleDB
The First Monitoring Company monitorea el movimiento de vehículos utilizando satélites. Rastreamos 20,000 vehículos y almacenamos datos de movimiento durante dos años. En total, tenemos 10 TB de datos de telemetría actuales. En promedio, cada vehículo envía 5 registros de telemetría por minuto mientras conduce. Los datos se envían a través de equipos de navegación a nuestros servidores telemáticos. Reciben 500 paquetes de navegación por segundo.
Hace algún tiempo, decidimos actualizar globalmente la infraestructura y pasar de un monolito a microservicios. Llamamos al nuevo sistema Waliot, y ya está en producción: el 90% de todos los vehículos se transfieren a él.
Mucho ha cambiado en la infraestructura, pero el enlace central se ha mantenido sin cambios: esta es la base de datos PostgreSQL. Ahora estamos trabajando en la versión 10 y nos estamos preparando para pasar a 11. Además de PostgreSQL, como almacenamiento principal, utilizamos PostGIS para la informática geoespacial en la pila y TimescaleDB para almacenar una gran variedad de datos de series temporales.
¿Por qué PostgreSQL?
¿Por qué estamos tratando de usar una base de datos relacional para almacenar series de tiempo, en lugar de
soluciones especializadas de
ClickHouse para este tipo de datos? Debido a los antecedentes de la experiencia acumulada y las impresiones de trabajar con PostgreSQL, no queremos utilizar una solución desconocida como almacenamiento principal.
Cambiar a una nueva solución es un riesgo.
Existen muchas soluciones especializadas para almacenar y procesar datos de series temporales. La documentación no siempre es suficiente, y una gran selección de soluciones no siempre es buena. Parece que los desarrolladores de cada nuevo producto quieren escribir todo desde cero, porque algo no era agradable en la solución anterior. Para comprender lo que no le gustó exactamente, debe buscar información, analizar y comparar. Una gran variedad de
tops ,
clasificaciones y
comparaciones son bastante atemorizantes en lugar de motivar a probar algo. Tendrá que pasar mucho tiempo para probar todas las soluciones usted mismo. No podemos permitirnos adaptar solo una solución durante varios meses. Esta es una tarea difícil, y el tiempo dedicado nunca valdrá la pena. Por lo tanto, hemos elegido extensiones para PostgreSQL.
Durante la fase de desarrollo de la infraestructura de Waliot, consideramos que InfluxDB es el principal repositorio de telemetría. Pero cuando me encontré con TimescaleDB y ejecuté pruebas en él, no hubo preguntas sobre la elección. PostgreSQL con la extensión TimescaleDB le permite usar otras extensiones en el mismo almacenamiento PostGIS o PipelineDB. No necesitamos extraer datos, transformar, realizar análisis y transferirlos a través de la red. Todo se encuentra en un servidor o en un sistema agrupado; no es necesario arrastrar los datos. Todos los cálculos se realizan al mismo nivel.
Recientemente,
Nikolay Samokhvalov , el autor de la cuenta postgresmen,
publicó un enlace a un artículo interesante sobre el uso de SQL para el procesamiento de datos en streaming. Cinco de los seis autores del artículo participan en el desarrollo de varios productos de Apache y trabajan con el procesamiento continuo. Por lo tanto, el artículo menciona Apache Spark, Apache Flink, Apache Beam, Apache Calcite y KSQL de Confluent.
Pero no es interesante el artículo en sí, sino el
tema en Hacker News , en el que se discute. El autor del tema escribe que, basándose en el artículo, implementó casi todas las ideas basadas en PostgreSQL 11. Utilizó extensiones CitusDB para escalado y fragmentación horizontal, PipelineDB para computación de flujo y vistas materializadas, TimescaleDB para almacenar datos de series temporales y seccionamiento. También usa varios envoltorios de datos extranjeros.
Una mezcla loca de PostgreSQL y sus extensiones confirma una vez más que PostgreSQL no es solo un DBMS, es una plataforma.
Y cuando se entregue el almacenamiento conectable ... ¡Uf!
Irónicamente, al investigar las soluciones, encontramos
Outflux , el desarrollo del equipo TimescaleDB, que publicaron el 1 de abril. ¿Qué crees que hace ella? Esta es una utilidad para migrar de InfluxDB a TimescaleDB en un comando ...
Postgres bombo!
¡No subestimes el poder del bombo! A menudo bromeamos diciendo que "el desarrollo está impulsado por el bombo", porque influye en nuestra percepción de los componentes de infraestructura y ajuste. En
HighLoad ++, discutimos mucho sobre PostgreSQL, ClickHouse, Tarantool, estos son desarrollos exagerados. Simplemente no diga que no afecta sus preferencias y la elección de soluciones para la infraestructura ... Por supuesto, este no es el factor principal, pero ¿tiene algún efecto?
He estado trabajando con PostgreSQL durante 5 años. Me gusta esta solución Resuelve casi todas mis tareas con una explosión. Cada vez que algo salía mal con esta base, mis manos torcidas tenían la culpa. Por lo tanto, la elección estaba predeterminada.
TimescaleDB VS PipelineDB
Pasemos a las extensiones TimescaleDB y PipelineDB. ¿Qué dicen sus creadores sobre las extensiones?
TimescaleDB es una base de datos de series de tiempo de código abierto que está optimizada para una inserción rápida y consultas complejas.
PipelineDB es una extensión de alto rendimiento diseñada para ejecutar consultas SQL continuas
para datos de series temporales .
Además de trabajar con datos de series temporales, tienen una historia similar. Timescale se fundó en 2015 y Pipeline en 2013. Las primeras versiones de trabajo aparecieron en 2017 y 2015, respectivamente. Los equipos tardaron dos años en liberar la funcionalidad mínima. Los lanzamientos de producción de ambas extensiones tuvieron lugar en octubre pasado con una diferencia de una semana. Aparentemente, apurados uno tras otro.
GitHub tiene un montón de estrellas y tenedores, que, como de costumbre, no son un solo compromiso. Así es como funciona el Código Abierto, no hay nada que hacer. Pero hay muchas estrellas,
TimescaleDB tiene más que
PipelineDB , e incluso más que PostgreSQL.
Las extensiones parecen ser similares, pero se posicionan de manera diferente.
TimescaleDB afirma haber insertado millones de registros por segundo y almacenado cientos de miles de millones de filas y decenas de terabytes de datos. La extensión es más rápida que InfluxDB, Cassandra, MongoDB o Vangre PostgreSQL. Admite replicación de transmisión y herramientas de copia de seguridad. TimescaleDB es una extensión, no una bifurcación de PostgreSQL.
PipelineDB solo almacena el resultado de los cálculos de transmisión, sin la necesidad de almacenar datos sin procesar para sus cálculos. La extensión es capaz de agregación continua sobre flujos de datos en tiempo real, combinándose con tablas convencionales para cálculos en el contexto de un dominio de dominio. PipelineDB es una extensión, no una bifurcación, pero inicialmente era una bifurcación.
Timescaledb
Ahora en detalle sobre las extensiones. Comencemos con TimescaleDB. He estado trabajando con él por casi 2 años. Arrastrado a producción antes de la versión de lanzamiento. Veamos ejemplos de cómo aplicarlo.
Almacenamiento para métricas de infraestructura . Tenemos métricas de consumo de recursos de contenedor Docker, tiempo de confirmación de métricas, identificador de contenedor y campos de consumo de recursos, por ejemplo, memoria libre. Necesitamos mostrar estadísticas para todos los contenedores con una cantidad promedio de ventanas de memoria libre durante 10 segundos. La consulta que ve resuelve este problema y TimescaleDB se puede utilizar como repositorio de métricas de infraestructura.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
Para cálculos Necesitamos calcular la cantidad de camiones que dejaron Krasnodar y su tonelaje total por días.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
También utiliza funciones de la extensión PostGIS para calcular el transporte que salió de la ciudad, en lugar de simplemente moverse en ella.
Monitoreo de la tasa de cambio . El tercer ejemplo es sobre las criptomonedas. La solicitud le permite mostrar cómo ha cambiado el precio de Ethereum en relación con Bitcoin y el dólar estadounidense en las últimas 2 semanas por día.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
Todo esto es igual de claro y conveniente para nosotros SQL.
¿Qué tiene de bueno TimescaleDB?
¿Por qué no usar las herramientas integradas de partición de tablas? ¿Y por qué molestarse en romper las mesas? La respuesta obvia es la
velocidad de inserción en tales bases de datos . El gráfico muestra las mediciones reales de la tasa de inserción del número de filas por segundo entre la tabla de vainilla regular PostgreSQL 10 sin seccionamiento y el hiperestable TimescaleDB.
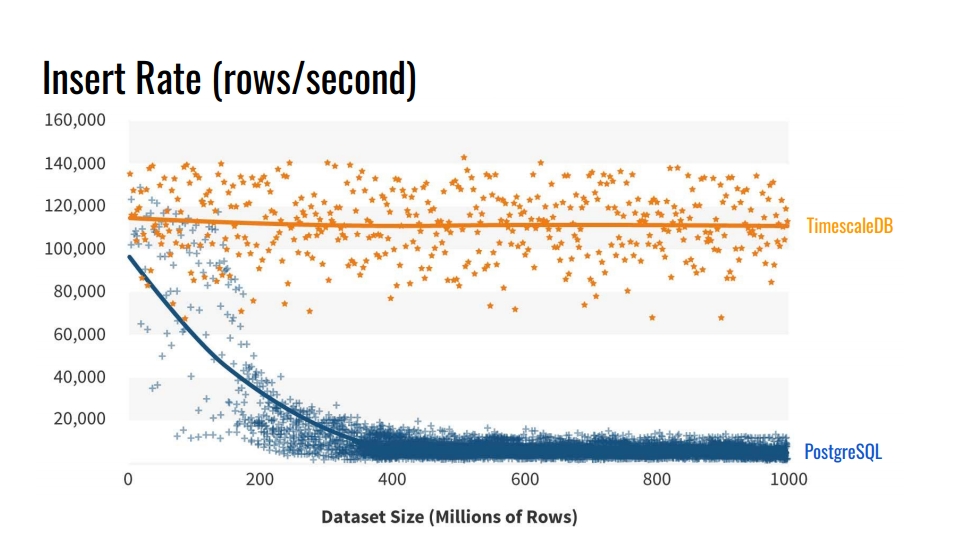
Este punto de referencia escribe mil millones de líneas en una máquina, simulando un escenario para recopilar métricas de la infraestructura. El registro contiene tiempo, el identificador del componente de infraestructura y 10 métricas. El punto de referencia se ejecutó en Azure VM con 8 núcleos y 28 gigabytes de RAM, así como unidades SSD de red. La inserción se realizó en lotes de 10 mil registros.
¿De dónde viene esa degradación del rendimiento de PostgreSQL? Porque cuando inserta, también necesita actualizar los índices de la tabla. Cuando no caben en el caché, comenzamos a cargar discos. La partición resuelve este problema si los índices de la sección en la que insertamos los datos se colocan en la RAM.
Veamos el siguiente cuadro. Esto compara el sistema de particionamiento declarativo integrado en PostgreSQL 10 y la hipertabla TimescaleDB. En el eje horizontal, el número de secciones.
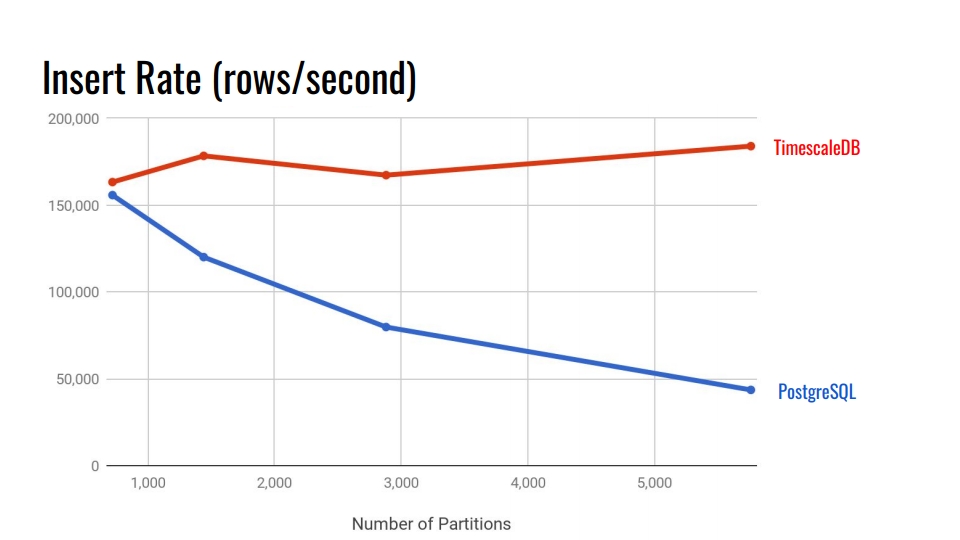
En TimescaleDB, la degradación es insignificante con secciones crecientes. Los desarrolladores de extensiones afirman que les está yendo bien con 10,000 secciones en una sola instancia de PostgreSQL.
En PostgreSQL, la implementación nativa se degrada significativamente después de 3.000. En general, la partición declarativa en PostgreSQL es un gran paso adelante, pero solo funciona bien para tablas con menos carga. Por ejemplo, para bienes, compradores y otras entidades de dominio que ingresan al sistema de manera no tan intensa como las métricas.
En las versiones 11 y 12 de PostgreSQL, aparecerá el soporte de particionamiento nativo y puede intentar ejecutar pruebas comparativas para datos de series temporales con nuevas versiones. Pero, me parece que TimescaleDB es aún mejor. Todos los puntos de referencia de TimescaleDB se pueden encontrar en su
github y probar.
Características clave
Espero que ya tenga interés en la extensión. Repasemos las características principales de TimescaleDB para consolidar este sentimiento.
Particionamiento a través de hipertables . TimescaleDB utiliza el término "hipertable" para las tablas a las que se ha aplicado la función create_hypertable (). Después de eso, la tabla se convertirá en el padre de todas las secciones heredadas: fragmentos. La tabla principal en sí no contendrá ningún dato, pero será un punto de entrada para todas las consultas y una plantilla al crear automáticamente nuevas secciones. Todas las secciones se almacenan no en el esquema principal de sus datos, sino en un esquema especial. Esto es conveniente porque no vemos miles de estas secciones en el esquema de datos.
La extensión está integrada en el planificador y el ejecutor de consultas . A través de enlaces especiales en PostgreSQL, TimescaleDB comprende cuándo accede a un hipertable. TimescaleDB analiza la consulta y redirige las consultas solo a las secciones necesarias en función de las condiciones especificadas en la propia llamada SQL. Esto le permite paralelizar el trabajo con secciones durante la extracción de una cantidad significativa de datos.
La extensión no impone restricciones en SQL . Puede utilizar libremente uniones, agregados, funciones de ventana, CTE e índices adicionales. Si vio la lista de restricciones para el sistema de particionamiento incorporado, esto debería complacerle.
Funciones útiles adicionales específicas para datos de series temporales:
- "Time_bucket" - "date_trun" de una persona sana;
- histogramas: completar los intervalos perdidos utilizando la interpolación o el último valor conocido;
- Trabajador en segundo plano: servicios que le permiten realizar operaciones en segundo plano: limpieza de secciones antiguas, reorganización.
TimescaleDB le permite permanecer en el poderoso ecosistema PostgreSQL . Esta extensión no rompe PostgreSQL, por lo tanto, todas las soluciones de alta disponibilidad, sistemas de respaldo y herramientas de monitoreo continuarán funcionando. TimescaleDB es amigo de Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
Grafana ya tiene soporte nativo para TimescaleDB como fuente de datos. Grafana entiende de inmediato que PostscreSQL tiene TimescaleDB. El generador de consultas en Grafana en los paneles comprende funciones adicionales de TimescaleDB, como "time_bucket", "first", "last". Puede crear gráficos directamente desde la base de datos relacional con estas funciones de series de tiempo sin consultas gigantes.
Prometheus tiene un adaptador que le permite combinar datos de él y usar TimescaleDB como un almacén de datos confiable. Use un adaptador para no almacenar datos en Prometheus durante años.
También hay un
complemento Telegraf . La solución le permite eliminar completamente Prometheus. Los datos de infraestructura se transfieren inmediatamente a TimescaleDB y se leen a través de Telegraf.
Licencias y noticias
No hace mucho tiempo, la compañía cambió a un nuevo modelo de licencia. La mayor parte del código tiene licencia de Apache 2.0. Una pequeña porción es de uso gratuito, pero tiene licencia bajo TSL.
Hay una versión Enterprise con licencia comercial. No se preocupe, no todas las cosas buenas en la versión Enterprise. Básicamente, hay automatización, como la eliminación automática de fragmentos obsoletos que se puede hacer a través de un simple "cron" y cosas similares.
Ahora la compañía está trabajando activamente en una solución de clúster. Quizás caiga en la versión Enterprise. También hay una versión en la nube para nuevas empresas que desean ingresar al mercado antes de que los inversores se queden sin dinero.
De las noticias:
- un millón de descargas en el último año y medio;
- Inversión de $ 31 millones;
- Colaboración activa con MS Azure con respecto a las soluciones de IoT.
Para resumir
TimescaleDB está diseñado para almacenar datos de series temporales. Este es un poderoso sistema de particionamiento con restricciones mínimas en comparación con los nativos en PostgreSQL.
Desafortunadamente, la extensión aún no tiene una versión multinodo. Si desea un multimaestro o un fragmento, debe jugar, por ejemplo, con CitusDB. Si quieres una replicación lógica, te dolerá. Pero siempre duele con ella.
Pipelinedb
Ahora hablemos de la segunda extensión. Desafortunadamente, no pudimos probarlo adecuadamente en la batalla. Ahora está pasando por la etapa de adaptación en nuestro sistema. Es cierto, hay un problema del que hablaré más cerca del final.
Como en el caso anterior, comenzamos con ejemplos reales. Es más fácil comprender los beneficios de la extensión y la motivación para usarla.
Colección de estadísticas . Imagine que recopilamos estadísticas sobre las visitas a nuestro sitio web. Necesitamos análisis de las páginas más populares, la cantidad de usuarios únicos y alguna idea de demoras en los recursos. Todo esto debe actualizarse en tiempo real. Pero no queremos tocar la tabla de datos cada vez y generar una consulta, o actualizar la vista en la parte superior de la tabla.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
El procesamiento de transmisión y la extensión PipelineDB vienen al rescate. La extensión agrega la abstracción CONTINUES VIEW. En la versión rusa, esto puede sonar como una "presentación continua". Esta vista se actualiza automáticamente cuando se inserta en la tabla con los registros de visitas, mientras que solo se basa en datos nuevos, sin leerlos ya registrados de antemano.
Flujo de datos . PipelineDB no se limita solo al nuevo tipo de vista. Supongamos que realizamos pruebas A / B y recopilamos análisis en tiempo real sobre la efectividad de una nueva solución de negocios. Pero no queremos almacenar los datos sobre las acciones del usuario. Solo nos interesa el resultado: qué grupo tiene la mayor conversión.
Para evitar el almacenamiento directo de datos sin procesar para la informática de transmisión, necesitamos una abstracción como las
transmisiones: transmisión de datos . PipelineDB presenta esta característica. Puede crear transmisiones como tablas normales. Debajo del capó, será "TABLA EXTRANJERA" basada en la cola ZeroMQ, que la extensión utiliza imperceptiblemente de nosotros. Los datos entran en la cola interna de ZeroMQ y desencadenan una actualización de la vista continua.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
Luego creamos una "VISTA CONTINUA" basada en datos de una secuencia creada previamente. Cuando los datos llegan a la secuencia, la vista se actualizará en función de estos datos. Después de eso, los datos simplemente se descartarán, no se guardarán en ningún lugar y no ocuparán espacio en disco. Esto le permite crear análisis sobre una cantidad casi ilimitada de datos, cargarlos en el flujo de datos de PipelineDB y leer el resultado del cálculo desde una vista continua.
Streaming de computación Después de haber creado el flujo de datos y la vista continua, podemos trabajar con la informática de flujo. Se ve así.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
El primer "SELECCIONAR" le da al grupo "ab" y el número de visitantes únicos. El segundo - da la relación entre los grupos - conversión. Eso es todo prueba A / B en cinco llamadas SQL en una base de datos relacional.
La vista se actualiza dinámicamente. No puede esperar el procesamiento de toda la matriz de datos, sino leer los resultados intermedios que ya se han procesado. Las vistas se leen de la misma manera que PostgreSQL normal. También puede combinar una vista con tablas o incluso otras vistas. No hay restricciones
Topología
Kafka recibe telemetría, el tema en Kafka envía estos datos a PostgreSQL y los agregamos más. Por ejemplo, combinamos con alguna tabla ordinaria y redirigimos los datos a la secuencia. Además, provoca la actualización de la presentación continua correspondiente, desde la cual los clientes de la base de datos ya pueden leer los datos terminados.
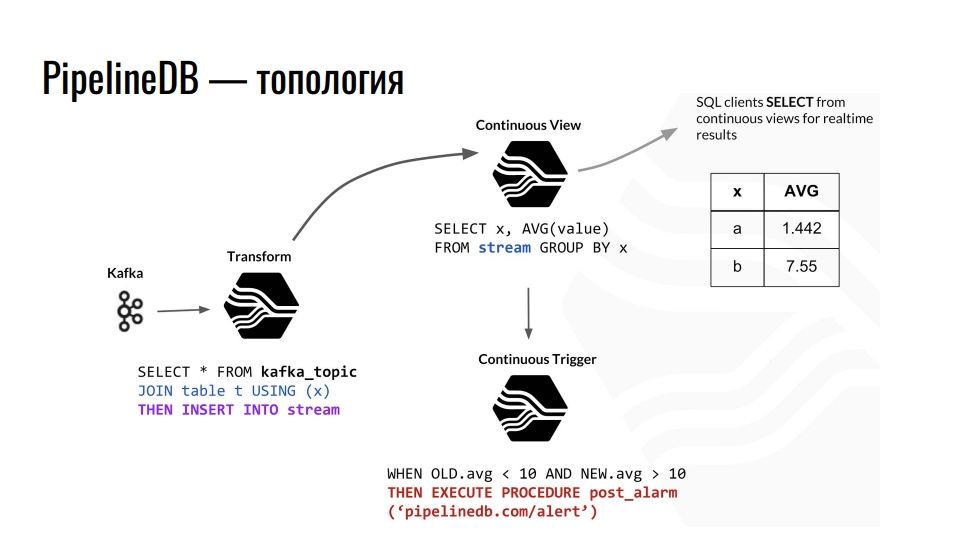 Un ejemplo de la topología de los componentes PipelineDB dentro de PostgreSQL. El circuito está tomado de una presentación de Derek Nelson.
Un ejemplo de la topología de los componentes PipelineDB dentro de PostgreSQL. El circuito está tomado de una presentación de Derek Nelson.Además de las transmisiones y las vistas, la extensión también proporciona una abstracción de "transformadores": convertidores o mutadores. Esta vista, pero apuntaba a convertir el flujo de datos entrantes en una salida modificada. Con estos mutadores, puede cambiar la presentación de los datos o filtrarlos. Desde el mutador, todo cae en la vista VISTA CONTINUA. Ya hacemos consultas para negocios en él. Cualquier persona familiarizada con la programación funcional debe entender la idea.
En PipelineDB podemos colgar un disparador en nuestras vistas y realizar acciones, por ejemplo, "alerta". Con todos estos cálculos, nunca almacenamos los datos sin procesar nosotros mismos, en base a los cuales todos los calculamos. Estos pueden ser terabytes, que cargamos secuencialmente a un servidor con un disco de cien gigabytes. Después de todo, solo estamos interesados en el resultado de los cálculos.
Características clave
La extensión PipelineDB es más difícil de aprender que TimescaleDB. En TimescaleDB, creamos una tabla, le decimos que es hiperactiva y disfrutamos la vida usando varias funciones adicionales que ofrece la extensión.
PipelineDB resuelve el problema de la informática en streaming en bases de datos relacionales . La tarea de procesar el procesamiento de datos es más complicada que la partición en términos de integración y uso. Sin embargo, no todos tienen grandes datos y miles de millones de filas. ¿Por qué complicar la infraestructura si hay PipelineDB? La extensión proporciona sus propias implementaciones de representaciones, flujos, convertidores y agregados para el procesamiento de flujos. También está
integrado en el planificador de consultas y el ejecutor de consultas permite implementar el concepto de informática de flujo en una base de datos relacional.
Al igual que TimescaleDB, la extensión PipelineDB
no impone restricciones de SQL en PostgreSQL . Hay varias características, por ejemplo, no puede combinar dos secuencias, pero esto no es necesario.
Soporte para estructuras de datos probabilísticos y algoritmos . La extensión utiliza el filtro Bloom para SELECT DISTINCT, HyperLogLog para COUNT (DISTINCT) y T-Digest para percentile_count () directamente en SQL. Esto mejora la productividad.
Ecosistema La extensión le permite trabajar con las soluciones habituales de alta disponibilidad, herramientas de monitoreo y todo lo demás que es familiar en PostgreSQL.
Dados los detalles de la informática de transmisión, PipelineDB tiene
integraciones con Apache Kafka y con Amazon Kinesis, un servicio de análisis en tiempo real. Dado que PipelineDB ya no es una bifurcación, sino una extensión, la integración con el resto del zoológico también debería estar lista para usar. Una visita obligada, pero no vivimos en un mundo ideal, y todo vale la pena comprobarlo.
Licencias y noticias
Todo el código tiene licencia bajo Apache 2.0. Hay una suscripción paga al soporte de diferentes galerías de tiro, así como una versión en clúster con licencia comercial. Basado en PipelineDB, la compañía proporciona el servicio de análisis Stride.
Antes de comenzar a hablar sobre la extensión, dije que hay un "pero". Es hora de hablar de él. El 1 de mayo de 2019, el equipo de PipelineDB anunció que ahora es parte de Confluent. Esta es la compañía que desarrolla KSQL, un motor para transmitir datos en Kafka con sintaxis SQL. Ahora Victor Gamov, cofundador del podcast Debriefing, está trabajando allí.
¿Qué se sigue de esto? PipelineDB se congeló en la versión 1.0.0. Además de corregir errores críticos, no hay nada planeado en él. Debido a la adquisición, esperamos la integración de Uber de Kafka con PostgreSQL. Quizás sea Confluent basado en almacenamiento conectable que hará algo genial.
Que hacer Vaya a TimescaleDB. En la última versión hicieron su "VISTA CONTINUA" con el blackjack. Por supuesto, ahora la funcionalidad no es tan buena como en PipelineDB, pero es cuestión de tiempo.
Para resumir
PipelineDB está diseñado para el procesamiento de datos de transmisión de alto rendimiento. Le permite realizar cálculos en grandes conjuntos de datos sin tener que guardar los datos en sí.
Con PipelineDB, cuando enviamos un flujo de datos a PostgreSQL en un flujo, los consideramos virtuales. No guardamos datos, sino que agregamos, calculamos y descartamos. Puede crear un servidor de 200 gigabytes y extraer terabytes de datos a través de flujos. Obtendremos el resultado, pero los datos en sí serán descartados.
Si por alguna razón la "VISTA CONTINUA" de TimescaleDB no es suficiente para usted, pruebe PipelineDB. Este es un proyecto de código abierto bajo la licencia Apache. No irá a ninguna parte, aunque ya no se está desarrollando activamente. Pero las cosas pueden cambiar, Confluent aún no ha escrito sobre planes de expansión.
Usando TimescaleDB y PipelineDB
Con PostgreSQL y dos extensiones,
podemos almacenar y procesar grandes matrices de datos de series temporales . Puedes pensar en muchas aplicaciones. Veamos un ejemplo de mi área temática: monitoreo de vehículos.

El equipo de navegación envía continuamente grabaciones de telemetría a nuestros servidores. Analizan varios protocolos de texto y binarios en un formato común y envían datos a Kafka en un tema especial. A partir de ahí, se integran con PipelineDB en el flujo de datos de telemetría dentro de PostgreSQL. Este flujo actualiza la vista del estado actual de los vehículos y el análisis general de la flota, y sobre la base del desencadenante provoca la grabación de registros de telemetría en el hiperestable TimescaleDB.
Con extensiones, tenemos tres ventajas.
- Análisis en tiempo real.
- Almacenamiento de datos de series temporales.
- Disminución del volumen de telemetría almacenada. Usando el mutador PipelineDB, agregamos datos, por ejemplo, en un minuto, calculando valores promedio.
Grafana tiene soporte incorporado para las funciones de TimescaleDB. Por lo tanto, es posible construir gráficos según las métricas comerciales directamente desde el cuadro, hasta las pistas en el mapa por coordenadas. El departamento de análisis estará encantado.
Para "tocar" todo usted mismo, mire
la demostración en GitHub y ejecute la
imagen Docker , dentro del ensamblaje de los últimos PostgreSQL, TimescaleDB y PipelineDB.
Total
PostgreSQL le permite combinar varias extensiones, así como agregar sus propios tipos de datos y funciones para resolver problemas específicos. En nuestro caso, el uso de las extensiones TimescaleDB y PostGIS cubre casi por completo las necesidades de almacenamiento de datos de series temporales y cálculos geoespaciales. Con la extensión PipelineDB, podemos realizar cálculos continuos para diversos análisis y estadísticas, y el uso de columnas JSONB nos permite almacenar datos débilmente estructurados en una base de datos relacional. Las soluciones de código abierto son suficientes con la cabeza: no utilizamos soluciones comerciales.
Estas extensiones prácticamente no imponen restricciones al ecosistema en torno a PostgreSQL, como soluciones de alta disponibilidad, sistemas de respaldo, herramientas de monitoreo y análisis de registros. No necesitamos MongoDB si hay columnas JSONB, y no necesitamos InfluxDB si hay TimescaleDB.
¿Te gusta la historia de Ivan y quieres compartir algo similar? Solicite antes del 7 de septiembre en HighLoad ++ en Moscú. El programa se está llenando gradualmente. , , , , . , !