Las pruebas unitarias son geniales, pero una no es suficiente. A menudo, desea asegurarse adicionalmente de que la aplicación en ejecución funcionará. Las pruebas de integración vienen al rescate. Se utiliza cada vez más para probar servicios, y Docker le permite administrar convenientemente su entorno de prueba. Pero, como siempre, las cosas no son tan simples cuando hay muchos más microservicios y dependencias.
Yuri Badalyants en RIT ++ contó cómo en 2GIS están probando una gran cantidad de servicios y un zoológico tecnológico completo. Bajo el corte, la versión de este informe, complementada y actualizada bajo la cuidadosa supervisión del orador: qué opciones probaste, qué se te ocurrió, qué problemas no tienes que resolver ahora. Será sobre Docker, Testcontainers y también sobre Scala.
Sobre el orador: Yuri Badalyants (@
LMnet ) comenzó su carrera en 2011 como desarrollador web, trabajó con PHP, JavaScript y Java. Ahora escribe sobre Scala en 2GIS.
Casino
2GIS ha estado proporcionando mapas de ciudades convenientes y directorios de empresas durante 20 años, y recientemente tenemos una
nueva versión con un mapa ilimitado de Rusia. Te contaré sobre la experiencia adquirida mientras trabajaba en el equipo de Casino. Este equipo está involucrado en tres áreas principales:
- Publicidad: qué anunciantes mostrar, qué ocultar, qué aumentar y cómo reducir la calificación.
- BigData está relacionado con la publicidad y su personalización, así como con la creación de análisis y métricas.
- Crawler es un programa que busca organizaciones en Internet para agregarlas automáticamente a la base de datos.
Estas tres áreas son las tareas principales, que, a su vez, tienen una gran cantidad de subtareas. Actualmente, hay más de 25 microservicios escritos en Scala. Este es nuestro código exclusivamente, sin embargo, también utilizamos sistemas de terceros, por ejemplo, PostgreSQL, Cassandra y Kafka. Almacenamos los datos en Hadoop y los procesamos en Spark. Además, utilizamos los métodos de aprendizaje automático proporcionados por el equipo de Data Science.
Como resultado, tenemos una gran cantidad de servicios y microservicios, una gran cantidad de dependencias y, por supuesto, todo esto necesita ser probado de alguna manera.
Por supuesto, escribimos pruebas unitarias. Sin embargo, incluso si todas las pruebas son verdes, esto no significa que todo funcione. Algo puede salir mal durante la fase de integración de componentes o microservicios. Por lo tanto, escribimos pruebas de integración.
Pruebas de integración
Cada microservicio desarrollado por el equipo de Casino resuelve su problema comercial y se encuentra en un repositorio separado en GitLab. Este artículo se centrará en las pruebas de integración dentro de uno de estos repositorios (microservicio) con dependencias bloqueadas, que es responsabilidad de los propios desarrolladores. El equipo de control de calidad está probando la interacción de los microservicios, y no hablaré sobre este tema.
Cuando me uní al equipo por primera vez, a finales de 2016, había aproximadamente el siguiente esquema de prueba de integración:
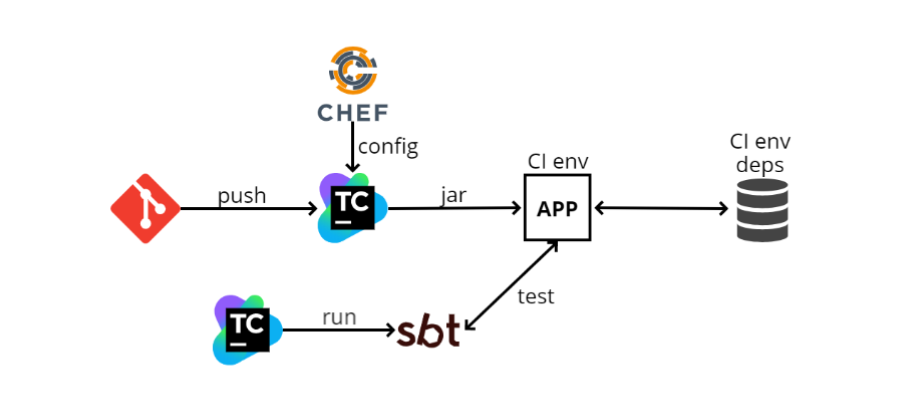
- El desarrollador introduce su código en GIT, después de lo cual el código del microservicio ingresa a TeamCity. TeamCity comienza a construir código y ejecutar pruebas.
- TeamCity toma el archivo de configuración (config) de Chef (un sistema de gestión de configuración similar a Ansible, solo escrito en Ruby). Chef también sirve para automatizar la implementación. Cuando tengo 100 máquinas, no quiero ir a cada una de ellas e instalar lo que necesito en SSH, y Chef me permite automatizar esto.
- TeamCity recopila el archivo jar (dado que escribimos en Scala, el artefacto que publicamos es el jar), luego el programa lo carga en el entorno de CI. Nuestra aplicación se implementa allí, también hay algunas dependencias. En el diagrama, una de las dependencias se representa como una base de datos. Puede haber tantas dependencias como sea posible, y gracias a Chef, nuestra aplicación las conoce y comienza a interactuar con ellas.
- A continuación, TeamCity lanza SBT (este es nuestro sistema de compilación, donde se ejecutan la compilación y las pruebas) y ejecuta las pruebas en sí. Son relativamente similares a las pruebas unitarias, pero funcionan principalmente en este principio: vaya a través de http a una dirección específica, verifique algún método y vea qué devuelve; o hacer algo de preparación, y luego ver si lo que se necesita ha regresado.
¿Qué se puede decir sobre tal esquema? Lo más importante, funciona. Cuando todo está configurado, ejecutar pruebas es fácil, ya que parecen pruebas unitarias. Pero las ventajas terminan ahí.
Y los contras comienzan.
El entorno de CI siempre está activado , y esto es un desperdicio adicional de recursos. Dado que Chef es una configuración estática, siempre debe tener algún tipo de máquina donde se configuren todas las dependencias, donde las aplicaciones se implementarán de forma independiente. Tal máquina consumirá recursos adicionales, ya que las pruebas se ejecutan de vez en cuando, y la máquina debe estar lista todo el tiempo. Además, el entorno de CI se incluye con todas las dependencias.
No es posible ejecutar pruebas en dos ramas al mismo tiempo . Esto se desprende del párrafo anterior: dado que tenemos un entorno, simplemente no podemos ejecutarlos en paralelo.
No es posible probar el inicio, detener y reiniciar . Explicaré por qué esto es necesario: todas nuestras aplicaciones obedecen la lógica del llamado
apagado elegante , es decir, cuando obtenemos SIGTERM, no detenemos el proceso en el medio, sino que interceptamos esta señal y entendemos que necesitamos apagar el programa. En este punto, se activa cierta lógica, por ejemplo, se procesan las solicitudes HTTP que están "en vuelo", o si trabajamos con Kafka, comprometemos todas las compensaciones; en otras palabras, realizamos ciertas acciones para que podamos completar el trabajo de forma segura, y luego, cuando todo esté listo, apáguelo.
Esta lógica no siempre es simple, y puede probarla con dicho esquema solo manualmente, porque a partir de las pruebas no controlamos el ciclo de vida de la aplicación. Resulta que TeamCity de alguna manera ha implementado algo a través de Chef, mientras que las pruebas están en una etapa diferente y no saben cómo se implementa la aplicación.
El siguiente
inconveniente es que es muy
difícil configurar todo esto localmente . Es decir, hay muchas dependencias, tienen sus propias configuraciones, necesitan ser generadas en la máquina local. La aplicación en sí también tiene su propio archivo de configuración, en el que hay muchos valores. Las pruebas en sí tienen una configuración que debe coincidir con la configuración de la aplicación, y también puede haber más de un valor de configuración. Parece que todo esto no suena tan aterrador, como "ve y arregla las configuraciones en tres lugares", pero en realidad puede tomar horas para que los nuevos empleados hagan esto.
Docker GitLab CI +
Con el tiempo, este esquema se ha transformado en otro:
GitLab CI y
Docker . Esto no sucedió porque el esquema anterior no era ideal, sino porque la compañía cambió ligeramente el rumbo en términos de organización administrativa.
Anteriormente, cada equipo, y tenemos muchos de ellos, como queríamos o cómo podíamos, y desarrollamos su trabajo. Por ejemplo, teníamos que TeamCity, Chef y otros equipos podían usar Jenkins o Ansible.
Ahora nos estamos moviendo hacia la nube local y Kubernetes, y hay un equipo separado que gestiona todo esto, tanto GitLab CI como Kubernetes. Otros equipos solo usan esto como un servicio. Esto es mucho más conveniente ya que no necesita administrar todo esto manualmente.
Usando Kubernetes, implementamos el siguiente esquema:

- En lugar de TeamCity, ahora se usa Gitlab CI.
- GitLab CI crea una imagen acoplable y la implementa en Kubernetes. La configuración ahora se almacena directamente en el repositorio, y no por separado en Chef, por lo que para la implementación no necesita trabajar con un servicio de configuración de terceros.
- Las dependencias se plantean de antemano, también en Kubernetes.
- Luego, GitLab CI lanza SBT y las pruebas en un paso separado.
Todo es bastante similar al esquema anterior y no es fundamentalmente diferente de él, es decir, incluso los pros y los contras serán exactamente los mismos, pero aparece Docker.
Con Docker, puedes hacer diferentes cosas más divertidas y una de ellas es Docker-compose.
Docker-compose
Este es un tipo de "superposición" en Docker, que le permite ejecutar múltiples imágenes de docker como una sola entidad.
Un buen ejemplo donde Docker-compose realmente ayuda es Kafka. Ella necesita ZooKeeper para correr. Si levanta Kafka y ZooKeeper sin el docker-compose, entonces necesita levantar ZooKeeper por separado en el docker, por separado, Kafka, y mantener estos dos contenedores de docker consistentes. Esto no es muy conveniente, y docker-compose le permite describir ambos contenedores en un archivo docker-compose.yml y usar el simple
docker-compose run Kafka Docker
docker-compose run Kafka aumentar Kafka y ZooKeeper.
Puede crear pruebas de integración en docker-compose. Veamos cómo se verá.

- Nuevamente, empuje todo en GitLab.
- GitLab CI lanza docker-compose.
- En docker-compose, la aplicación sube, todas las dependencias y SBT suben, y SBT dirige las pruebas para esta aplicación; todo sucede dentro de docker-compose.
Gracias a este esquema, no hay necesidad de mantener un entorno y dependencias separados, porque todo va directamente al corredor de GitLab CI, donde solo deben estar docker y docker-compose. Durante el inicio, bombeará las imágenes necesarias y las ejecutará.
Además, puede probar diferentes ramas al mismo tiempo, porque todo sucede en el corredor.
Ahora
es más fácil configurar el entorno
localmente , pero aún necesita coordinar varios lugares. La cuestión es que ahora, cuando hacemos la configuración local, no necesitamos poner todo en la máquina local, todo está escrito en el archivo docker-compose.yml. Por lo tanto, debe configurar en dos lugares diferentes: esto es docker-compose.yml y la configuración de nuestras pruebas.
En cuanto a las desventajas,
todavía es imposible probar el inicio, detener y reiniciar , porque desde SBT, desde las pruebas, no controlamos el ciclo de vida de la aplicación. Lo ejecuta docker-compose, ejecuta SBT y las pruebas se ejecutan dentro de SBT. Por lo tanto, no hay una gestión completa del ciclo de vida de la aplicación. También hay dificultades con el lanzamiento, sobre las cuales me gustaría hablar más.
docker-compose 2
En los días de docker-compose 2, docker-compose.yml el archivo se veía así:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
Los servicios se registran aquí, es decir, lo que recaudaremos como parte de este docker-compose. En este caso, acabo de tomar un ejemplo de la documentación de docker-compose. Hay tres servicios: web, redis y db (base de datos).
Web es nuestra aplicación, y redis y db son algún tipo de dependencias.
Hay un elemento en el bloque web llamado
depends_on . Esto sugiere que la aplicación web depende de algunos otros contenedores, y se describe a continuación en los cuales: de la base de datos y redis.
Además, hay una cláusula de
condition . Para redis, esto es
service_started , lo que significa que hasta que se inicie redis, el contenedor no intentará iniciar la aplicación web.
En cuanto a la base de datos, su condición es
service_healthy , y la comprobación de salud se describe a continuación. Es decir, no solo necesitamos lanzar el contenedor docker, sino también ejecutar un cierto chequeo de salud. Puede ser cualquier lógica personalizada.
Por ejemplo, usamos PostgreSQL, que usa la extensión PostGIS, y necesita algo de tiempo para inicializarse. Cuando lanzamos el contenedor docker, no podemos trabajar de inmediato con la extensión postgis; debemos esperar a que la extensión se inicialice. Por lo tanto, solo
SELECT PostGIS_Version(); consultas
SELECT PostGIS_Version(); a
SELECT PostGIS_Version(); . Hasta que se inicialice la extensión, la solicitud arrojará un error, y cuando la extensión se inicialice, comenzará a devolver la versión. Esto es muy conveniente y lógico:
primero elevaremos todas las dependencias y luego la aplicación .
docker-compose 3
Cuando salió Docker-compose 3, comenzamos a usarlo.
Pero en la documentación para ello, apareció un elemento al cambiar la lógica depend_on. Los desarrolladores de Docker decidieron que una descripción del gráfico de dependencia era suficiente. Esto significa que cuando inicia el
docker-compose run web , tanto la aplicación como la base de datos de la que depende se iniciarán simultáneamente.

El siguiente párrafo de la documentación dice que depende_on ya no es condición.
Por lo tanto, si aún desea obtener la funcionalidad que se utilizó en la segunda versión, tendrá que tener todo en sus manos.
La página de
pedidos de inicio de Controlling ofrece varias soluciones. La primera opción es usar
wait-for-it.sh .
Ahora docker-compose.yml se ve un poco diferente:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on es solo una matriz, no hay condiciones.
En nuestras dependencias, redefinimos el comando, es decir, en docker-compose puede adjuntar un comando con el que se inicia el contenedor de docker.
Allí deberíamos escribir wait-for-it.sh, y algo más. En lugar de los tres puntos en el ejemplo anterior, deberíamos escribir lo que necesitamos esperar, así como el comando original que inicia el contenedor docker.
Para hacer esto, debe encontrar el archivo acoplable, copiar el comando para redis desde allí y pegarlo, lo mismo ocurre con la base de datos. Un gran inconveniente es que la
abstracción se descompone : no quiero saber qué comando inicia el contenedor acoplable. Estos comandos pueden ser no triviales, bastante complejos, pero no quiero molestarme, solo quiero ingresar el
docker run y eso es todo.
Personalmente no me gusta esta solución, pero teníamos un par de servicios que funcionan así.
Script en la parte superior de docker-compose
Entonces decidí que había llegado el momento de "
construir bicicletas", y tuve
docker-compose-run.sh :
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
Permíteme darte un ejemplo semi-realista: hay postgres en docker-compose.yml, hay una aplicación my_service, que depende de postgres, y SBT, en la que se ejecutan las pruebas y que depende de mi servicio.
Ejecuto el programa no a través de
docker run , sino a través del script docker-compose-run.sh.
Primero, comienza la dependencia más profunda primero, en mi caso es postgres. El script inicia la dependencia en el modo "daemon", es decir, no bloquea el terminal:
docker-compose up -d postgres
Luego espero a que la función wait_until satisfaga la condición. Esto es casi lo mismo que wait-for-it.sh, solo, por así decirlo, en un estilo imperativo. Mientras PostGIS se está inicializando, el terminal está bloqueado, es decir, el programa también espera, y si no espera, se produce un error y las pruebas dejan de funcionar.
wait_until 10 2 docker-compose exec -T postgres psql
Cuando PostGIS se inicializa, continúe con el siguiente paso y haga lo mismo con el servicio. Para él, la prueba es un poco más simple: el puerto 80 debería estar vinculado.
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
El último paso es ejecutar SBT a través del comando de ejecución, en el que se ejecutan las pruebas.
docker-compose run sbt down $?
Por lo tanto, todo se plantea en el orden correcto, pero manualmente.
Al final, se llama
down función
down , que acepta el resultado del comando anterior. Si es "0", las pruebas han pasado y simplemente desactivamos docker-compose; de lo contrario, primero "escupimos" los registros para descubrir qué salió mal, y solo luego apagamos la compilación de la ventana acoplable.
function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
Tal esquema funciona, pero no escala bien. Cada servicio tendrá que describir su docker-compose-run.sh con su propia lógica. Además, la configuración de inicio se extiende entre docker-compose-run.sh y docker-compose.yml. Bueno, en general, parece que no estamos usando docker-compose, pero estamos luchando con sus deficiencias.
Ejecutando Docker desde el código
Cuando se creó el esquema anterior, pensé: si ya tengo todo en la ventana acoplable, ¿por qué no ejecutarlo desde el código? Empecé a buscar una solución y encontré varias opciones.
La primera opción es simplemente
usar el cliente docker . Hay dos clientes principales de docker en el mundo JVM:
docker-java y
spotify docker-client .
El cliente docker le permite ejecutar comandos docker directamente desde el código utilizando la API. Es decir, en lugar de concatenar cadenas para construir comandos como
`docker run ...` , simplemente puede formar dicho comando en el código y ejecutarlo. Es mucho mas conveniente.
Este método funciona bien y, con seguridad, pueden hacer todo, sin embargo, este es un nivel muy bajo. Tendría que crear mi propio análogo compuesto por docker, que es una tarea muy grande.
La siguiente opción es la
biblioteca docker-it-scala , que envuelve a ambos clientes y le permite elegir qué back-end usar. Ella puede ejecutar los contenedores que necesita.
Pero el inconveniente de esta biblioteca es que no tiene una API muy flexible y no hay control del ciclo de vida.
Tampoco me gustó esta opción, continué buscando y encontré
Testcontainers . Me gustaría contarles más sobre esto.
Contenedores de prueba
Este es un tipo de biblioteca java para iniciar y probar contenedores docker. Hay una fachada Scala, testcontainers-scala. Fuera de la caja, hay una serie de servicios populares, por ejemplo, PostgreSQL, MySQL, Nginx, Kafka, Selenium. Puede ejecutar cualquier otro contenedor. La biblioteca tiene una API bastante simple y flexible, en la que me detendré con más detalle.
Contenedores predefinidos
Entonces, cómo trabajar con contenedores predefinidos, que están en la biblioteca: de hecho, todo es bastante simple, ya que los contenedores se representan como objetos:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
En este caso, creamos
PostgreSQLContainer , podemos iniciarlo y comenzar a trabajar con él. A continuación, obtenemos
jbdcUrl , con el que puede conectarse a PostgreSQL. Después de eso obtenemos
mappedPort .
Esto significa que PostgreSQL sobresale del puerto de acoplamiento 5432, y Testcontainers ve este puerto y lo asigna automáticamente a algún puerto aleatorio. Es decir, de las pruebas que vemos, por ejemplo, 32422. La asignación se realiza automáticamente.
Contenedor personalizado
La siguiente vista, el llamado contenedor personalizado, también es bastante simple:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
Hay un
GenericContainer del que debe heredar y anular varios campos. Asegúrese de establecer solo
imageName : este es el nombre del contenedor que queremos crear.
Puede configurar los puertos
exposedPorts : los puertos que el contenedor sobresaldrá. En env, puede establecer variables de entorno; también puede establecer el
command para ejecutar.
classpathResourceMapping permite lanzar recursos de classpath al contenedor acoplable. Esto es muy conveniente, por ejemplo, si la configuración de la aplicación está directamente en los recursos de prueba. Simplemente asigna dentro, y la aplicación dentro de Docker obtiene acceso a esta configuración.
waitStrategy es algo muy conveniente que faltaba en docker-compose 3, de hecho es HealthCheck. Hay varios
waitStrategy predefinidos, por ejemplo, puede esperar hasta que se produzca un enlace de puerto, o un método http específico devolverá 200. Pero puede escribir cualquiera de sus HealthCheck.
Como escribe HealthCheck simplemente en su código, puede usar, en primer lugar, un idioma normal, no bash, y, en segundo lugar, cualquier biblioteca que esté disponible a partir de su código: si desea hacer HealthCheck personalizado en Cassandra, tome el controlador y escriba cualquier HealthCheck.
Ejecutando pruebas
Y ahora un poco sobre cómo ejecutar pruebas:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
Hablaré sobre
ScalaTest , el estándar de facto para pruebas en el mundo Scala.
Por ejemplo, queremos escribir pruebas para Postgres. Cree una prueba
PostgresqlSpec y herede de
ForAllTestContainer . Este es un rasgo proporcionado por la biblioteca. Comenzará los contenedores necesarios antes de todas las pruebas y los detendrá después de todas las pruebas. O puede usar
ForeachTestContainer , luego los contenedores comienzan antes de cada prueba y se detienen después de cada uno de ellos.
Entonces necesitas redefinir el contenedor. Esto puede hacerse anulando la propiedad del
container . En mi caso, estoy usando
PostgreSQLContainer .
Luego escribimos pruebas. En el ejemplo, creo una conexión, tomo jdbcUrl, nombre de usuario, contraseña, escribo pruebas específicas, envío de solicitudes.
Por lo general, las pruebas de integración requieren varios contenedores. Puedo crearlos usando
MultipleContainers :
val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
Es decir, creo contenedores, los agrego a
MultipleContainers y los uso como
container .
El esquema para ejecutar pruebas con Testcontainers es el siguiente:

- Empuje el código en GitLa.
- El corredor de GitLab CI lanza SBT.
- SBT ejecuta pruebas. Dentro de las pruebas, se lanzan nuestra aplicación y dependencias.
Las ventajas de este esquema:
- No es necesario mantener un entorno y dependencias separados, todo sucede en el corredor.
- Puede probar diferentes ramas al mismo tiempo.
- Puede probar iniciar, detener y reiniciar, porque podemos controlar el ciclo de vida de la aplicación (todo comienza en el código de prueba).
- Hay HealthChecks flexibles que faltaban mucho.
- No hay archivos * .sh en el repositorio, puede configurar las pruebas en la aplicación de la manera más flexible que desee.
- Gracias a la asignación de classpathResource, puede usar la misma configuración con ambas pruebas y la aplicación.
- Puede configurar pruebas desde el código.
- Todo esto se ejecuta igualmente fácilmente tanto en CI como localmente, ya que estas son solo pruebas que se ven y se ejecutan como pruebas unitarias, solo todo sube en el contenedor de la ventana acoplable.
Resulta que todo es sospechosamente suave y bueno, pero esto es solo a primera vista, de hecho, encontramos una serie de problemas.
Contenedores dependientes
El primer problema que encontramos son
los contenedores dependientes . Digamos que hay algún tipo de prueba:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
Ejecuta postgres y AppContainer. El appContainer de postgres se pasa jdbcUrl, el nombre de usuario y la contraseña para la conexión. A continuación, se crea MultipleContainers y se describe la prueba en sí.
Ejecuto el programa y veo un error:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
El punto es que el puerto asignado no se puede tomar hasta que se inicia el contenedor. ¿Por qué está pasando esto?
El hecho es que
ForAllTestContainer o
ForEachTestContainer inician contenedores justo antes de las pruebas, y no en el momento en que creo instancias de contenedor. Resulta que en el momento en que creo el AppContainer, todavía no tengo
PostgreSQLContainer activado, lo que significa que no puedo obtener el puerto asignado de él, y es necesario para formar
jdbcUrl .
El problema es que la esencia del contenedor es mutable: tiene varios estados. Por ejemplo, se puede apagar y encender.
¿Cómo resolver este problema? El primer método que llamaría "vago".
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
La idea principal es crear contenedores utilizando
vago val . Entonces no se inicializarán inmediatamente en el constructor de prueba, sino que esperarán la primera llamada. Inicializaremos en los
afterAll beforeAll y
afterAll , que proporciona el
BeforeAndAfterAll BeforeAndAfterAll de ScalaTest. En
beforeAll contenedores comienzan y en
afterAll se apagan. Dado que los contenedores se declaran vagos, en el momento en que se llama al método de inicio antes de All, se crearán, inicializarán e iniciarán.
Sin embargo, todavía se produce un error que no puedo unir localhost: 32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
Parece que usamos jdbcUrl, ¿por qué aparece localhost? Veamos cómo funciona jdbcUrl:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
Es solo una concatenación de cadenas. Todo está claro con constantes; no pueden romperse.
getMappedPort debería funcionar, porque ya lo hemos solucionado.
databaseName es una constante codificada. Pero con
getContainerIpAddress más interesante. Por nombre, podemos suponer que debe devolver la dirección IP del contenedor. Pero si ejecuta este código, resulta que siempre devuelve localhost. Al final resultó que, este método no está destinado a la interacción entre contenedores:
getContainerIpAddress proporciona la interacción de las pruebas dentro del contenedor .
Recomendación del desarrollador de Testcontainers:
cree una red personalizada para la comunicación entre contenedores . Docker-compose funciona de esta manera: crea una red y resuelve todo por sí solo.
Entonces necesitas crear una red.
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
Ahora tenemos que configurar manualmente nuestro jdbcUrl. También necesitamos habilitar nuestros contenedores en la red y establecer un alias para PostgreSQLContainer para que sea accesible dentro de la red mediante algún nombre de dominio. Al final, debe recordar "matar" la red.
Finalmente, dicho programa funcionará.
En versiones recientes de testcontainers-scala, la inicialización de contenedor diferido es compatible de forma inmediata:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
Puede usar
ForAllTestContainer y
MultipleContainers nuevamente. En
beforeAll ya no necesita
beforeAll manualmente
beforeAll orden de inicio. Ahora
MultipleContainers puede trabajar con val diferido y ejecutarlos en el orden correcto, y no realiza una inicialización estricta inmediatamente después de la creación. Al mismo tiempo, las manipulaciones con la red personalizada y jdbcUrl también deben realizarse manualmente.
Simulacros
Sin embargo, todavía hay problemas. Por ejemplo moki. A veces no es muy conveniente crear algún tipo de dependencia en un contenedor acoplable. Utilizamos Spark JobServer, que crea trabajos de Spark y controla su ciclo de vida en Spark. Utilizamos dos de sus métodos: "crear" y "dar estado".
Para ejecutar Spark JobServer dentro de la ventana acoplable. Es necesario criar Spark, y hasta hace poco, no tenía un contenedor acoplable y era necesario ensamblarlo usted mismo. Además, Spark JobServer usa PostgreSQL para almacenar estados. Como resultado, debe realizar un trabajo difícil cuando realmente solo necesita dos métodos con una API simple.
Pero puede echar un vistazo a la implementación del Spark JobServer y crear un simulacro que se comporte de la misma manera, pero que no requiera las dependencias del Spark JobServer original.
Se ve así (en el ejemplo, un pseudocódigo simplificado):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
http- API Spark JobServer. - , . , , , mock.
- , . : «» config; , host.
SparkJobServerMock , host-, docker-, , , docker-.
? docker-, , gateway , docker-.
, Testcontainers API. , Testcontainers docker-java-, . «» docker-:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
-,
DockerClient . Testcontainers
DockerClientFactory . c
inspectNetworkCmd . , info, gateway.
, , .
— . Docker : Windows, Mac, . Linux. , , Linux .
, Testcontainers . , docker-. :
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
,
. docker-.
`host.testcontainers.internal` .
, :
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Testcontainers
, , Testcontainers , . Java-, Scala-. :
- . , testcontainers-java JUnit, testcontainers-scala ScalaTest, testcontainers-java . Scala- .
- Scala . . , . , predefined Java-. , .
- API . API, . , . , , .
Resumen
. Docker , , , , network gateway.
Testcontainers — , . API , .
Java-, . — . .
, docker-, .
— , , , . .?, .
— - ?Kubernetes, . end-to-end , , , , .
, , unit-, .
— Kubernetes ?-, , -, , , , Spark Kubernetes ; , .
, , unit-, , , break point , , .
, , , CI , .
, minicube — Mac, . , , , , .
— ? : master? , - , , 2.1, 2.2, ?ImageName, Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
9.6, 10. [ ], .
Image tag — , — , . , latest .
— , ?, CI , GitLab CI , , Branch Name.
— , , , ? - , ? 20- , ?-, , . , , , , , .
- , , full-time , , , .
commit', , , , Android, iOS . . , , , , — .
, , -: - , - . , - .
Desea más detalles sobre los microservicios en sí y no solo sobre Scala: nuestro programa ScalaConf tiene respuestas a varias preguntas. Más interesado en la arquitectura y las interconexiones de sus diversas partes: visite HighLoad ++ del 7 al 8 de noviembre.
Todo es tan sabroso y no está claro qué elegir, luego suscríbase al boletín en el que hablamos sobre informes y recopilamos materiales útiles sobre el tema.