El tema Captcha no es nuevo, incluso para Habr. Sin embargo, los algoritmos de captcha están cambiando, al igual que los algoritmos para resolverlos. Por lo tanto, se propone recordar la versión anterior y operar la siguiente versión de captcha:

En el camino, entienda el trabajo de una red neuronal simple en la práctica, y también mejore sus resultados.
Inmediatamente haga una reserva de que no nos sumergiremos en pensamientos sobre cómo funciona la neurona y qué hacer con todo esto, el artículo no pretende ser científico, sino que solo proporciona un pequeño tutorial.
Bailar desde la estufa. En lugar de unirse
Tal vez las palabras de alguien se repitan, pero la mayoría de los libros sobre Deep Learning realmente comienzan con el hecho de que al lector se le ofrecen datos previamente preparados con los que comienza a trabajar. De alguna manera MNIST: 60,000 dígitos escritos a mano, CIFAR-10, etc. Después de leer, una persona sale preparada ... para estos conjuntos de datos. No está completamente claro cómo usar sus datos y, lo más importante, cómo mejorar algo al construir su propia red neuronal.
Es por eso que el artículo en
pyimagesearch.com sobre cómo trabajar con sus propios datos, así como su
traducción, fue muy útil.
Pero como dicen, el rábano picante no es más dulce: incluso con la traducción del artículo masticado sobre keras, hay muchos puntos ciegos. Una vez más, se ofrece un conjunto de datos preparado previamente, solo con gatos, perros y pandas. Tienes que llenar los vacíos tú mismo.
Sin embargo, este artículo y código se tomarán como base.
Recopilamos datos en captcha
No hay nada nuevo aquí. Necesitamos muestras de captcha, como la red aprenderá de ellos bajo nuestra guía. Puede extraer el captcha usted mismo, o puede tomar un poco aquí:
29,000 captchas . Ahora necesitas cortar los números de cada captcha. No es necesario cortar los 29,000 captcha, especialmente porque 1 captcha da 5 dígitos. 500 captcha serán más que suficientes.
¿Cómo cortar? Es posible en Photoshop, pero es mejor tener un cuchillo mejor.
Así que aquí está el código del cuchillo de pitón -
descargar . (para Windows. Primero cree las carpetas C: \ 1 \ test y C: \ 1 \ test-out).
La salida será un volcado de números del 1 al 9 (no hay ceros en el captcha).
A continuación, debe analizar este bloqueo de los números en carpetas del 1 al 9 y colocar en cada carpeta el número correspondiente. Más o menos la ocupación. Pero en un día puedes distinguir hasta 1000 números.
Si, al elegir un número, es dudoso cuál de los números, es mejor eliminar esta muestra. Y está bien si los números son ruidosos o ingresan de manera incompleta el "marco":


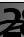
Necesita recolectar 200 muestras de cada dígito en cada carpeta. Puede delegar este trabajo a servicios de terceros, pero es mejor hacer todo usted mismo para no buscar números que coincidan incorrectamente más adelante.
Red neuronal. Prueba
Tyat, tyat, nuestras redes arrastraron al hombre muertoAntes de comenzar a trabajar con sus propios datos, es mejor leer el artículo anterior y ejecutar el código para comprender que todos los componentes (keras, tensorflow, etc.) están instalados y funcionan correctamente.
Usaremos una red simple cuya sintaxis de inicio es del comando (!) Line:
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* Tensorflow puede escribir cuando trabaja sobre errores en sus propios archivos y métodos obsoletos, puede solucionarlo a mano o simplemente ignorarlo.
Lo principal es que después de que el programa se haya resuelto, aparecen dos archivos en la carpeta del proyecto: simple_nn_lb.pickle y simple_nn.model, y se muestra la imagen del animal con una tasa de inscripción y reconocimiento, por ejemplo:

Red neuronal - datos propios
Ahora que se ha verificado la prueba de estado de la red, puede conectar sus propios datos y comenzar a entrenar la red.
Coloque en las carpetas de la carpeta de datos con números que contengan muestras seleccionadas para cada dígito.
Para mayor comodidad, colocaremos la carpeta dat en la carpeta del proyecto (por ejemplo, al lado de la carpeta animales).
Ahora la sintaxis para comenzar el aprendizaje en red será:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Sin embargo, es demasiado temprano para comenzar a entrenar.
Necesita arreglar el archivo train_simple_nn.py.
1. Al final del archivo:
Esto agregará información.
2)
image = cv2.resize(image, (32, 32)).flatten()
cambiar a
image = cv2.resize(image, (16, 37)).flatten()
Aquí redimensionamos la imagen de entrada. ¿Por qué exactamente este tamaño? Porque la mayoría de los dígitos cortados son de este tamaño o se reducen a él. Si escala a 32x32 píxeles, la imagen se distorsionará. Si, y por que hacerlo?
Además, llevamos este cambio a la prueba:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
Porque el programa no puede digerir algunas imágenes y problemas Ninguno, por lo tanto, se omiten.
3. Ahora lo más importante. Donde hay un comentario en el código
definir arquitectura 3072-1024-512-3 con Keras
La arquitectura de red en el artículo se define como 3072-1024-512-3. Esto significa que la red recibe 3072 (32 píxeles * 32 píxeles * 3) en la entrada, luego la capa 1024, la capa 512 y las opciones de salida 3: un gato, un perro o un panda.
En nuestro caso, la entrada es 1776 (16 píxeles * 37 píxeles * 3), luego la capa 1024, la capa 512, a la salida de 9 variantes de números.
Por lo tanto nuestro código:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9 salidas no necesitan ser indicadas adicionalmente, porque el programa mismo determina la cantidad de salidas por la cantidad de carpetas en el conjunto de datos.
Lanzamos
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Dado que las imágenes con números son pequeñas, la red aprende muy rápidamente (5-10 minutos) incluso en hardware débil, utilizando solo la CPU.
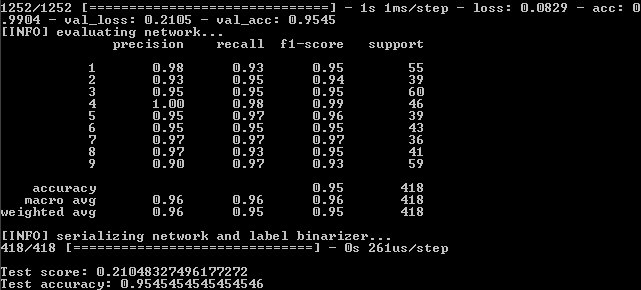
Después de ejecutar el programa en la línea de comando, vea los resultados:
Esto significa que en el conjunto de entrenamiento, se logró la fidelidad - 82.19%, en el control - 75.6% y en la prueba - 75.59%.
Necesitamos centrarnos en el último indicador en su mayor parte. Por qué los otros también son importantes se explicará más adelante.
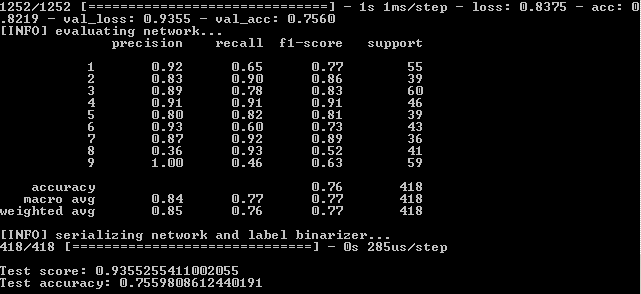
Veamos también la parte gráfica del trabajo de la red neuronal. Está en la carpeta de salida del proyecto simple_nn_plot.png:
Más rápido, más alto, más fuerte. Mejorando resultados
Bastante sobre la configuración de una red neuronal, mira
aquí .
La opción auténtica es la siguiente.
Agregar eras.
En el código cambiamos
EPOCHS = 75
en
EPOCHS = 200
Aumente el "número de veces" que la red recibirá capacitación.
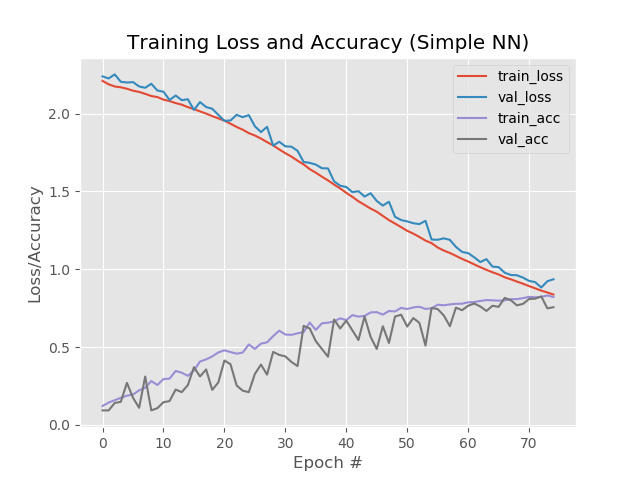
Resultado:
Así, 93.5%, 92.6%, 92.6%.
En imágenes:
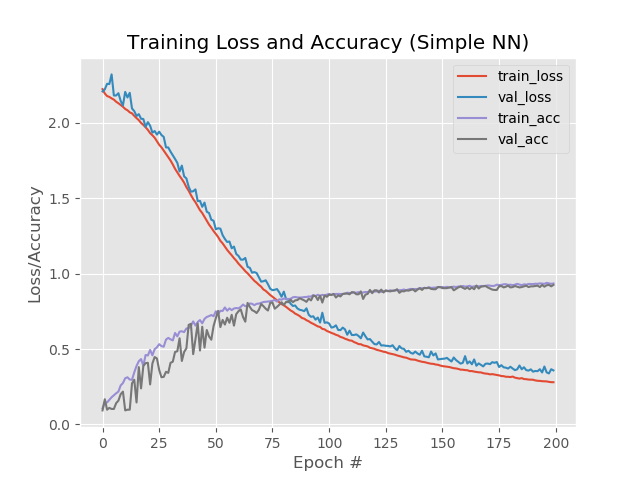
Aquí es notable que las líneas azules y rojas después de la era 130 comienzan a dispersarse entre sí y esto dice que un aumento adicional en el número de épocas no funcionará. Mira esto.
En el código cambiamos
EPOCHS = 200
en
EPOCHS = 500
y huir de nuevo.
Resultado:
Entonces tenemos:
99%, 95.5%, 95.5%.
Y en el gráfico:
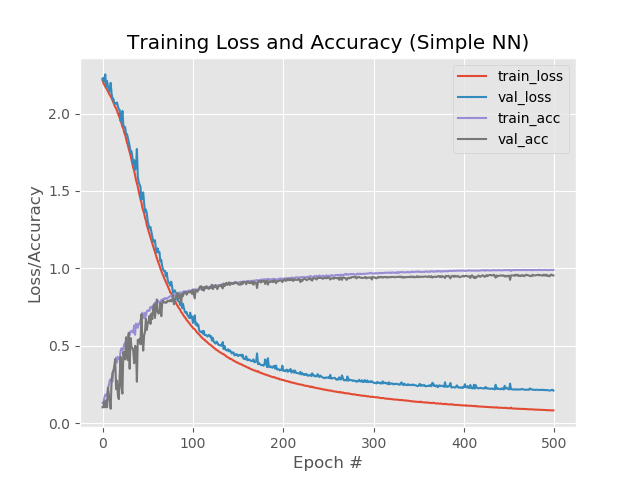
Bueno, el aumento en el número de eras claramente se ha ido a la red. Sin embargo, este resultado es engañoso.
Verifiquemos el funcionamiento de la red con un ejemplo real.
Para estos fines, el script predict.py está en la carpeta del proyecto. Antes de comenzar, prepárate.
En la carpeta de imágenes del proyecto, colocamos los archivos con las imágenes de los números de captcha, que la red no había encontrado previamente en el proceso de aprendizaje. Es decir es necesario tomar dígitos no del conjunto de datos de datos.
En el archivo mismo, arreglamos dos líneas para el tamaño de imagen predeterminado:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
Ejecutar desde la línea de comando:
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
Y vemos el resultado:
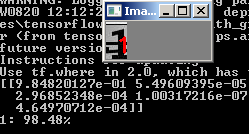
Otra foto:
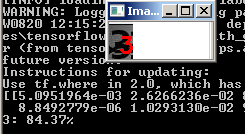
Sin embargo, no funciona con todos los números ruidosos:
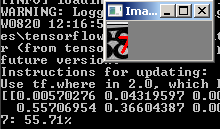
¿Qué se puede hacer aquí?
- Aumente el número de copias de números en las carpetas para capacitación.
- Prueba otros métodos.
Probemos otros métodos.
Como puede ver en el último gráfico, las líneas azul y roja divergen alrededor de la era 130. Esto significa que el aprendizaje después de la era 130 no es efectivo. Arreglamos el resultado en la época 130: 89.3%, 88%, 88% y vemos si funcionan otros métodos para mejorar la red.
Reduce la velocidad de aprendizaje. INIT_LR = 0.01
en
INIT_LR = 0.001
Resultado:
41%, 39%, 39%
Bueno por.
Agrega una capa oculta adicional. model.add(Dense(512, activation="sigmoid"))
en
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
Resultado:
56%, 62%, 62%
Mejor pero no.
Sin embargo, si aumenta el número de eras a 250:
84%, 83%, 83%
Al mismo tiempo, las líneas rojas y azules no se separan después de la era 130:
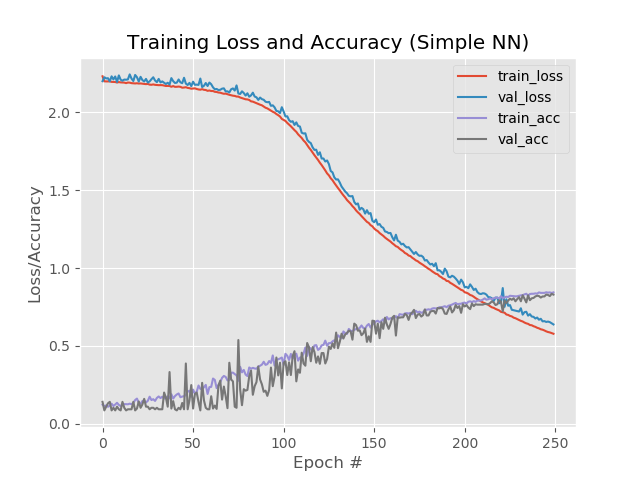 Ahorre 250 eras y aplique adelgazamiento
Ahorre 250 eras y aplique adelgazamiento :
from keras.layers.core import Dropout
Insertar adelgazamiento entre las capas:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
Resultado:
53%, 65%, 65%
El primer valor es más bajo que el resto, esto indica que la red no está aprendiendo. Para hacer esto, se recomienda aumentar el número de eras.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
Resultado:
88%, 92%, 92%
Con 1 capa adicional, adelgazamiento y 500 eras:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
Resultado:
92.4%, 92.6%, 92.58%
A pesar de un porcentaje más bajo en comparación con un simple aumento de eras a 500, el gráfico se ve más parejo:
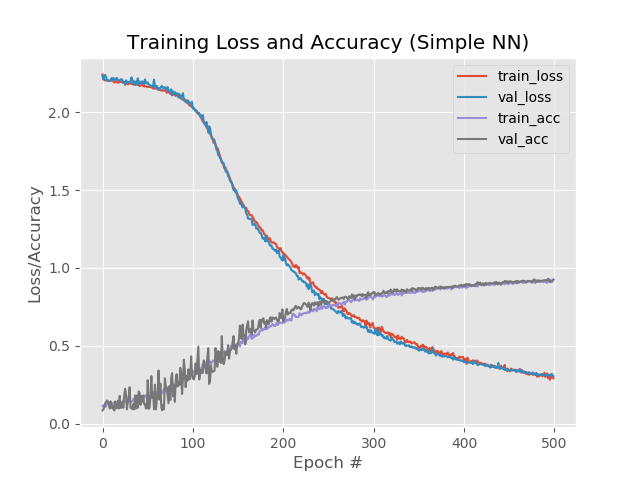
Y la red procesa imágenes que anteriormente se caían:
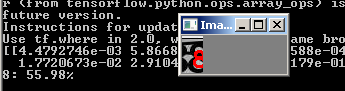
Ahora recopilaremos todo en un archivo, que cortará la imagen con el captcha en la entrada en 5 dígitos, ejecutaremos cada dígito a través de la red neuronal y enviaremos el resultado al intérprete de Python.
Es más simple aquí. En el archivo que nos corta los números del captcha, agregue el archivo que se ocupa de las predicciones.
Ahora el programa no solo corta el captcha en 5 partes, sino que también muestra todos los números reconocidos en el intérprete:

Nuevamente, debe tenerse en cuenta que el programa no proporciona el 100% del resultado y, a menudo, uno de los 5 dígitos es incorrecto. Pero este es un buen resultado, considerando que en el conjunto de entrenamiento solo hay 170-200 copias para cada número.
El reconocimiento de captcha dura de 3 a 5 segundos en una computadora de potencia media.
¿De qué otra forma puede intentar mejorar la red? Puede leer en el libro "Biblioteca de Keras: una herramienta de aprendizaje profundo" A. Dzhulli, S. Pala.
El guión final que corta el captcha y reconoce está
aquí .
Comienza sin parámetros.
Guiones reciclados para
entrenar y
probar la red.
Captcha para la prueba, incluso con falsos positivos,
aquí .
El modelo para el trabajo está
aquí .
Los números en las carpetas están
aquí .