Las sugerencias de búsqueda son geniales. ¿Con qué frecuencia escribimos la dirección completa del sitio en la barra de direcciones? ¿Y el nombre del producto en la tienda en línea? Para consultas tan cortas, escribir unos pocos caracteres suele ser suficiente si las sugerencias de búsqueda son buenas. Y si no tiene veinte dedos o una increíble velocidad de escritura, seguramente los usará.
En este artículo, hablaremos sobre nuestro nuevo servicio de sugerencias de búsqueda hh.ru, que hicimos en la edición anterior de la
School of Programmers .
El antiguo servicio tenía varios problemas:
- trabajó en consultas de usuarios populares seleccionadas a mano;
- no pudo adaptarse a las preferencias cambiantes del usuario;
- no se pudieron clasificar las consultas que no están incluidas en la parte superior;
- no corrigió errores tipográficos.
En el nuevo servicio, corregimos estas deficiencias (al tiempo que agregamos otras nuevas).
Diccionario de consultas populares
Cuando no hay pistas, puede seleccionar manualmente las consultas de N principales de los usuarios y generar pistas a partir de estas consultas utilizando la aparición exacta de palabras (con o sin orden). Esta es una buena opción: es fácil de implementar, proporciona una buena precisión de las indicaciones y no experimenta problemas de rendimiento. Durante mucho tiempo, nuestra sugestión funcionó así, pero un inconveniente importante de este enfoque es la insuficiente integridad del problema.
Por ejemplo, la solicitud "desarrollador de JavaScript" no se incluyó en dicha lista, por lo que cuando ingresamos "tiempos de JavaScript" no tenemos nada que mostrar. Si complementamos la solicitud, teniendo en cuenta solo la última palabra, veremos "javascript handyman" en primer lugar. Por la misma razón, no será posible implementar la corrección de errores más difícil que el enfoque estándar con la búsqueda de las palabras más cercanas por la distancia Damerau-Levenshtein.
Modelo de idioma
Otro enfoque es aprender a evaluar las probabilidades de consultas y generar las continuaciones más probables para una consulta de usuario. Para hacer esto, use modelos de lenguaje, una distribución de probabilidad en un conjunto de secuencias de palabras.
Dado que las solicitudes de los usuarios son en su mayoría cortas, ni siquiera probamos modelos de lenguaje de redes neuronales, sino que nos limitamos a n-gram:
Como el modelo más simple, podemos tomar la definición estadística de probabilidad, luego
Sin embargo, dicho modelo no es adecuado para evaluar consultas que no estaban en nuestra muestra: si no observamos el 'desarrollador junior java', entonces resulta que
Para resolver este problema, puede usar varios modelos de suavizado e interpolación. Utilizamos Backoff:
Donde P es la probabilidad suavizada
(Utilizamos el suavizado de Laplace):
donde V es nuestro diccionario.
Generación de opciones
Entonces, podemos evaluar la probabilidad de una solicitud en particular, pero ¿cómo generar estas mismas solicitudes? Es aconsejable hacer lo siguiente: dejar que el usuario ingrese una consulta
, entonces las consultas que son adecuadas para nosotros se pueden encontrar a partir de la condición
Por supuesto, clasificando
No es posible seleccionar las mejores opciones para cada solicitud entrante, por lo que utilizaremos
Beam Search . Para nuestro modelo de lenguaje n-gram, todo se reduce al siguiente algoritmo:
def beam(initial, vocabulary): variants = [initial] for i in range(P): candidates = [] for variant in variants: candidates.extends(generate_candidates(variant, vocabulary)) variants = sorted(candidates)[:N] return candidates def generate_candidates(variant, vocabulary): top_terms = []

Aquí los nodos resaltados en verde son las opciones finales seleccionadas, el número delante del nodo
- probabilidad
, después del nodo -
.
Se ha vuelto mucho mejor, pero en generate_candidates necesitas obtener rápidamente N mejores términos para un contexto dado. En el caso de almacenar solo las probabilidades de n-gramos, necesitamos revisar todo el diccionario, calcular las probabilidades de todas las frases posibles y luego ordenarlas. Obviamente, esto no despegará para consultas en línea.
Boro para probabilidades
Para obtener rápidamente las N mejores variantes de probabilidad condicional de la continuación de la frase, usamos boro en términos. En el nodo
coeficiente almacenado
valor
y ordenado por probabilidad condicional
lista de términos
junto con
. El término especial
eos marca el final de una frase.
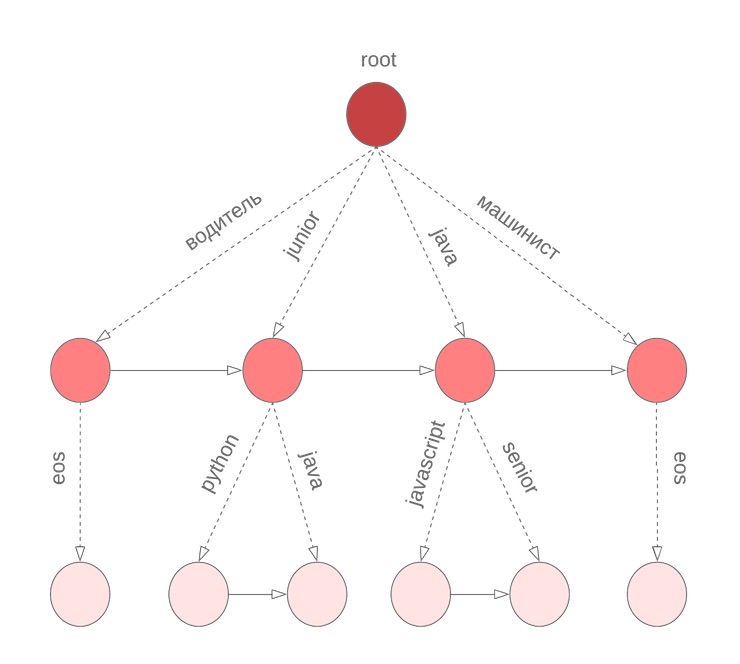
Pero hay un matiz
En el algoritmo descrito anteriormente, asumimos que todas las palabras en la consulta se completaron. Sin embargo, esto no es cierto para la última palabra que el usuario ingresa en este momento. Nuevamente necesitamos revisar todo el diccionario para continuar con la palabra actual que se está ingresando. Para resolver este problema, utilizamos un boro simbólico, en los nodos de los cuales almacenamos M términos ordenados por la probabilidad de unigrama. Por ejemplo, este se verá como nuestro bor para java, junior, jupyter, javascript con M = 3:

Luego, antes de comenzar Beam Search, encontramos los mejores candidatos para continuar con la palabra actual
y selecciona los N mejores candidatos para
.
Errores tipográficos
Bueno, hemos creado un servicio que le permite dar buenos consejos para una solicitud del usuario. Incluso estamos listos para nuevas palabras. Y todo estaría bien ...
Pero los usuarios se cuidan y no cambian los teclados hfcrkflre.¿Cómo resolver esto? Lo primero que viene a la mente es la búsqueda de correcciones mediante la búsqueda de las opciones más cercanas para la distancia Damerau-Levenshtein, que se define como el número mínimo de inserción / eliminación / reemplazo de un carácter o transposición de dos vecinas necesarias para obtener otro de una línea. Desafortunadamente, esta distancia no tiene en cuenta la probabilidad de un reemplazo particular. Entonces, para la palabra ingresada "zapador", entendemos que las opciones "recolector" y "soldador" son equivalentes, aunque intuitivamente parece que tenían en mente la segunda palabra.
El segundo problema es que no tenemos en cuenta el contexto en el que ocurrió el error. Por ejemplo, en la consulta "Order Sapper" aún deberíamos preferir la opción "colector" en lugar de "soldador".
Si aborda la tarea de corregir errores tipográficos desde un punto de vista probabilístico, es bastante natural llegar a un
modelo de canal ruidoso :
- conjunto de alfabeto ;
- conjunto de todas las líneas finales sobre él
- muchas líneas que son palabras correctas ;
- distribuciones dadas donde .
Luego, la tarea de corrección se establece como encontrar la palabra correcta w para la entrada s. Dependiendo de la fuente del error, mida
se puede construir de diferentes maneras, en nuestro caso es aconsejable tratar de estimar la probabilidad de errores tipográficos (llamémoslos reemplazos elementales)
, donde t, r son n-gramos simbólicos, y luego evalúa
como la probabilidad de obtener s de w por los reemplazos elementales más probables.
Dejar
- dividiendo la cadena x en n subcadenas (posiblemente cero). El modelo Brill-Moore implica el cálculo de probabilidad
como sigue:
P (s | w) \ approx \ max_ {R \ en Parte_n (s)} T \ en Parte_n (s)} \ prod_ {i = 1} ^ {n} P_e (T_i | R_i)
Pero necesitamos encontrar
:
Al aprender a evaluar P (w | s), también resolveremos el problema de clasificar las opciones con la misma distancia Damerau-Levenshtein y podremos tener en cuenta el contexto al corregir un error tipográfico.
Calculo
Para calcular las probabilidades de las sustituciones elementales, las consultas de los usuarios nos ayudarán nuevamente: compondremos pares de palabras (s, w) que
- cerrar en Damerau-Levenshtein;
- Una de las palabras es más común que las otras N veces.
Para tales pares, consideramos la alineación óptima según Levenshtein:
Componemos todas las particiones posibles de syw (nos limitamos a longitudes n = 2, 3): n → n, pr → rn, pro → rn, ro → po, m → ``, mm → m, etc. Para cada n-gramo, encontramos
Calculo
Calculo
toma directamente
: necesitamos clasificar todas las particiones posibles de w con todas las particiones posibles de s. Sin embargo, la dinámica en el prefijo puede dar una respuesta para
donde n es la longitud máxima de las sustituciones elementales:
d [i, j] = \ begin {cases} d [0, j] = 0 & j> = k \\ d [i, 0] = 0 & i> = k \\ d [0, j] = P (s [0: j] \ espacio | \ espacio w [0]) & j <k \\ d [i, 0] = P (s [0] \ espacio | \ espacio w [0: i]) & i <k \\ d [i, j] = \ underset {k, l \ le n, k \ lt i, l \ lt j} {max} (P (s [jl: j] \ space | \ space w [ik: i]) \ cdot d [ik-1, jl-1]) \ end {cases}
Aquí P es la probabilidad de la fila correspondiente en el modelo de k-gramos. Si observa de cerca, es muy similar al algoritmo Wagner-Fisher con recorte de Ukkonen. En cada paso que obtenemos
enumerando todas las correcciones
en
sujeto a
y la elección del más probable.
Volver a
Entonces, podemos calcular
. Ahora necesitamos seleccionar varias opciones para maximizar
. Más precisamente, para la solicitud original
debes elegir
donde
máximo Desafortunadamente, una elección honesta de opciones no se ajustaba a nuestros requisitos de tiempo de respuesta (y el plazo del proyecto estaba llegando a su fin), por lo que decidimos centrarnos en el siguiente enfoque:
- de la consulta original obtenemos varias opciones cambiando las últimas k palabras:
- corregimos la distribución del teclado si el término resultante tiene una probabilidad varias veces mayor que el original;
- encontramos palabras cuya distancia Damerau-Levenshtein no excede d;
- elija entre ellas las mejores opciones para ;
- envíe BeamSearch a la entrada junto con la solicitud original;
- al clasificar los resultados, descontamos las opciones obtenidas en .
Para la Cláusula 1.2, utilizamos el algoritmo FB-Trie (trie hacia adelante y hacia atrás), basado en la búsqueda difusa en los árboles de prefijos hacia adelante y hacia atrás. Esto resultó ser más rápido que evaluar P (s | w) en todo el diccionario.
Estadísticas de consulta
Con la construcción del modelo de lenguaje, todo es simple: recopilamos estadísticas sobre las consultas de los usuarios (cuántas veces hemos realizado una consulta para una frase determinada, cuántos usuarios, cuántos usuarios registrados), dividimos las solicitudes en n-gramas y creamos burs. Más complicado con el modelo de error: como mínimo, se necesita un diccionario de las palabras correctas para construirlo. Como se mencionó anteriormente, para seleccionar los pares de entrenamiento, utilizamos el supuesto de que dichos pares deberían estar cerca en la distancia Damerau-Levenshtein, y uno debería ocurrir con más frecuencia que el otro varias veces.
Pero los datos siguen siendo demasiado ruidosos: intentos de inyección xss, diseño incorrecto, texto aleatorio del portapapeles, usuarios experimentados con solicitudes "programador c no 1c",
solicitudes del gato que pasó por el teclado .
Por ejemplo, ¿qué trató de encontrar con tal solicitud? Por lo tanto, para borrar los datos de origen, excluimos:
- términos de baja frecuencia;
- Contiene operadores de lenguaje de consulta
- vocabulario obsceno
También corrigieron la distribución del teclado, verificaron las palabras de los textos de vacantes y diccionarios abiertos. Por supuesto, no fue posible arreglarlo todo, pero tales opciones generalmente están completamente cortadas o ubicadas al final de la lista.
En prod
Justo antes de la protección del proyecto, lanzaron un servicio en producción para pruebas internas y, después de un par de días, para el 20% de los usuarios. En hh.ru, todos los cambios que son significativos para los usuarios pasan por un
sistema de pruebas AB , que nos permite no solo estar seguros de la importancia y la calidad de los cambios, sino también
encontrar errores .
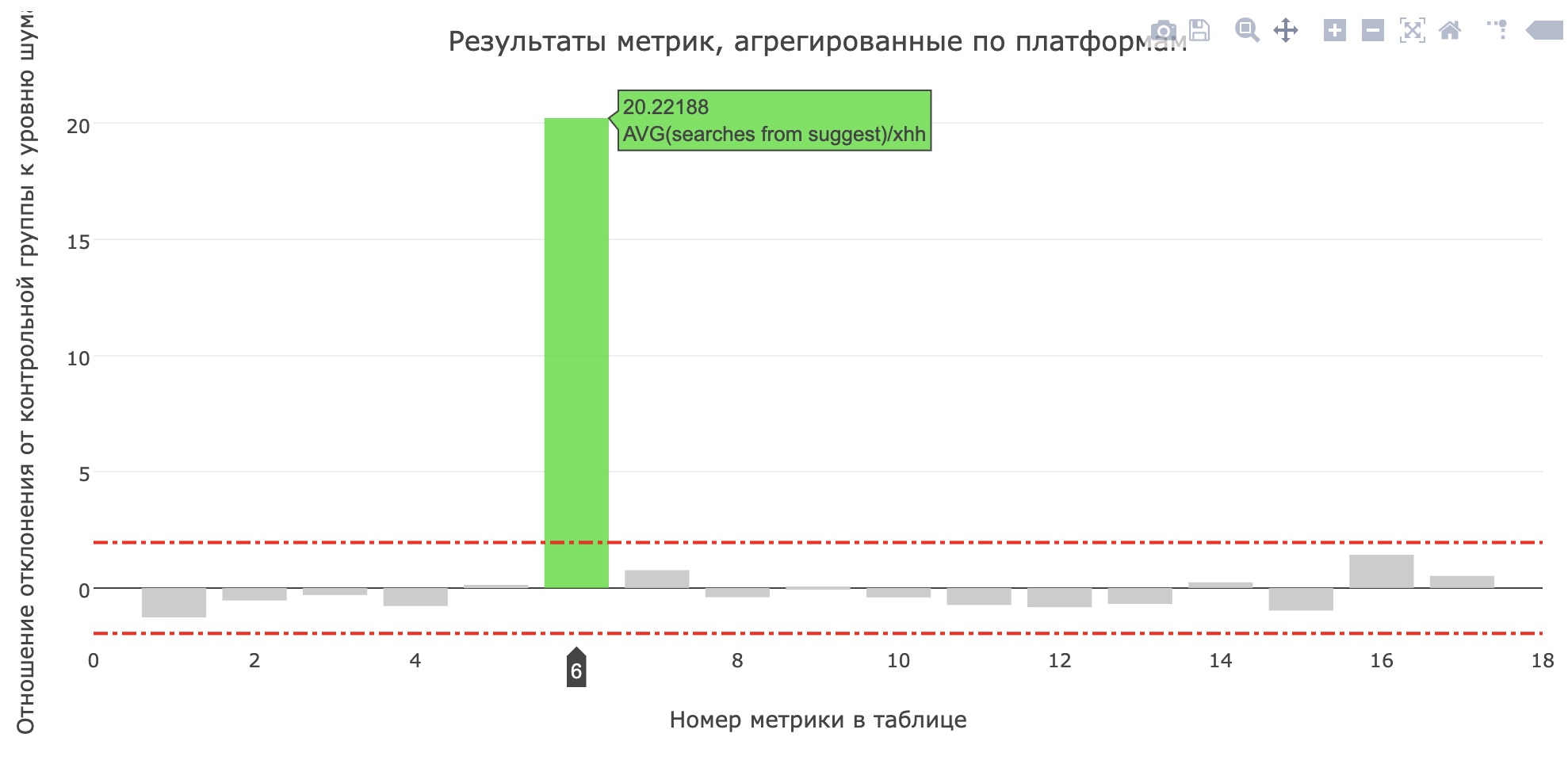
La métrica del número promedio de búsquedas del sujest para solicitantes se ha mejorado (aumentó de 0.959 a 1.1355), y la proporción de búsquedas del sujest de todas las consultas de búsqueda aumentó del 12.78% al 15.04%. Desafortunadamente, las principales métricas del producto no crecieron, pero los usuarios definitivamente comenzaron a usar más consejos.
Al final
No había lugar para una historia sobre los procesos de la escuela, otros modelos probados, las herramientas que escribimos para las comparaciones de modelos y las reuniones donde decidimos qué características desarrollar para obtener una demostración intermedia. Mire los
registros de la escuela anterior , deje una solicitud en
https://school.hh.ru , complete tareas interesantes y venga a estudiar. Por cierto, el servicio para verificar tareas también fue realizado por los graduados del conjunto anterior.
Que leer
- Introducción al modelo de lenguaje
- Modelo Brill-Moore
- Fb-trie
- ¿Qué sucede con su consulta de búsqueda?