En este artículo describiré nuestra experiencia de migrar Preply a Kubernetes, cómo y por qué lo hicimos, qué dificultades encontramos y qué ventajas obtuvimos.

Kubernetes para Kubernetes? No, requisitos comerciales!
Alrededor de Kubernetes hay mucha publicidad y por buenas razones. Mucha gente dice que resolverá todos los problemas, algunos dicen que lo más probable es que no necesite Kubernetes . La verdad, por supuesto, está en algún punto intermedio.

Sin embargo, todas estas discusiones sobre dónde y cuándo se necesita Kubernetes merecen un artículo separado. Ahora hablaré un poco sobre nuestros requisitos comerciales y cómo funcionó Preply antes de la migración a Kubernetes:
- Cuando utilizamos el flujo Skullcandy , teníamos muchas ramas, todas ellas fusionadas en una rama común llamada
stage-rc , desplegada en el escenario. El equipo de control de calidad probó este entorno, después de probar que la rama estaba feliz en el maestro y el maestro desplegado en el prod. Todo el procedimiento tomó alrededor de 3-4 horas y pudimos implementar de 0 a 2 veces al día - Cuando implementamos el código roto en el producto, tuvimos que revertir todos los cambios incluidos en la última versión. También fue difícil encontrar qué cambio rompió nuestro producto
- Utilizamos AWS Elastic Beanstalk para alojar nuestra aplicación. Cada implementación de Beanstalk en nuestro caso tomó 45 minutos (toda la tubería junto con las pruebas funcionaron en 90 minutos ). Volver a la versión anterior de la aplicación tomó 45 minutos
Para mejorar nuestros productos y procesos en la empresa, queríamos:
- Romper un monolito en microservicios
- Implemente más rápido y con más frecuencia
- Retroceda más rápido
- Cambiamos nuestro proceso de desarrollo porque pensamos que ya no era efectivo
Nuestras necesidades
Cambiamos el proceso de desarrollo.
Para implementar nuestras innovaciones con el flujo Skullcandy, necesitábamos crear un entorno dinámico para cada sucursal. En nuestro enfoque con la configuración de la aplicación en Elastic Beanstalk, fue difícil y costoso hacerlo. Queríamos crear entornos que pudieran:
- Implementado rápida y fácilmente (preferiblemente contenedores)
- Trabajó en instancias puntuales
- Eran tan similares a los productos
Decidimos pasar al desarrollo basado en troncales. Con su ayuda, cada característica tiene una rama separada que, independientemente del resto, puede fusionarse en un maestro. Se puede implementar una rama maestra en cualquier momento.
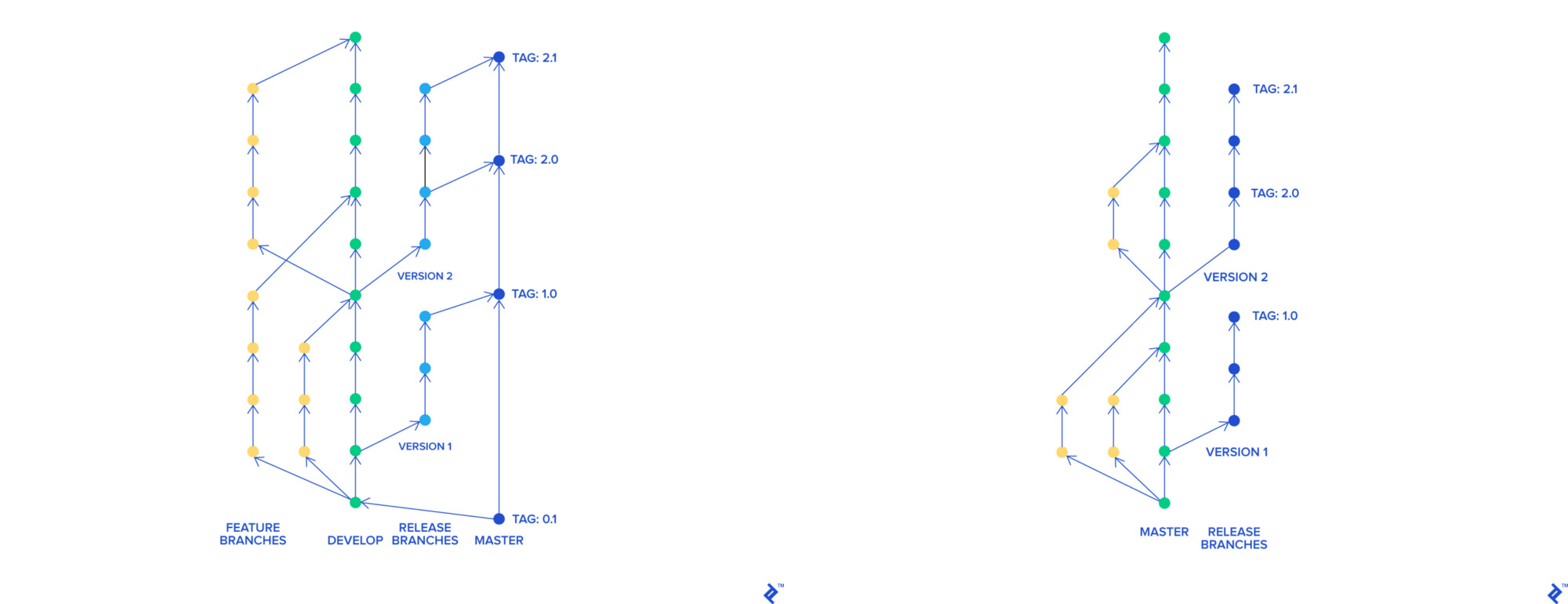
git-flow y desarrollo basado en troncales
Implemente más rápido y con más frecuencia
El nuevo proceso basado en troncales nos permitió entregar innovaciones a la rama maestra más rápido una tras otra. Esto nos ayudó mucho en el proceso de encontrar código roto en el producto y revertirlo. Sin embargo, el tiempo de implementación aún era de 90 minutos, y el tiempo de reversión era de 45 minutos, debido a esto no pudimos implementar más a menudo 4-5 veces al día.
También encontramos dificultades al usar la arquitectura de servicio en Elastic Beanstalk. La solución más obvia era usar contenedores e instrumentos para orquestarlos. Además, ya teníamos experiencia usando Docker y docker-compose para el desarrollo local.
Nuestro siguiente paso fue investigar los populares orquestadores de contenedores:
- AWS ECS
- Enjambre
- Apache mesos
- Nómada
- Kubernetes
Decidimos quedarnos en Kubernetes, y por eso. Entre los orquestadores en cuestión, cada uno tenía una falla importante: ECS es una solución dependiente del proveedor, Swarm ya perdió los laureles de Kubernetes, Apache Mesos parecía una nave espacial con sus cuidadores del zoológico para nosotros. Nomad parecía interesante, pero se reveló completamente solo en integración con otros productos de Hashicorp, también nos decepcionó que se pagaran los espacios de nombres en Nomad.
A pesar de su alto umbral de entrada, Kubernetes es el estándar de facto en la orquestación de contenedores. Kubernetes as a Service está disponible en la mayoría de los principales proveedores de la nube. La orquesta está en desarrollo activo, tiene una gran comunidad de usuarios y desarrolladores, y una buena documentación.
Esperábamos migrar completamente nuestra plataforma a Kubernetes en 1 año. Dos ingenieros de plataforma sin experiencia en Kubernetes participaron en la migración de arranque parcial.
Usando Kubernetes
Comenzamos con una prueba de concepto, creamos un grupo de prueba y documentamos todo lo que hicimos en detalle. Decidimos usar kops , ya que en nuestra región en ese momento EKS todavía no estaba disponible (en Irlanda se anunció en septiembre de 2018 ).
Mientras trabajábamos con el clúster, probamos el autoescalador de clúster, el gestor de certificados , Prometheus, las integraciones con Hashicorp Vault, Jenkins y mucho más. "Jugamos" con estrategias de actualización continua, enfrentamos varios problemas de red, en particular con DNS , y fortalecimos nuestro conocimiento en clustering de clúster.
Utilizaron instancias puntuales para optimizar los costos de infraestructura. Para recibir notificaciones sobre problemas puntuales , utilizaron kube-spot-termination-notice-handler , el Asesor de instancias puntuales puede ayudarlo a elegir el tipo de instancia puntual.
Comenzamos la migración del flujo de Skullcandy al desarrollo basado en Trunk, donde lanzamos una etapa dinámica para cada solicitud de extracción, esto nos permitió reducir el tiempo de entrega de nuevas funciones de 4 a 6 a 1 a 2 horas .
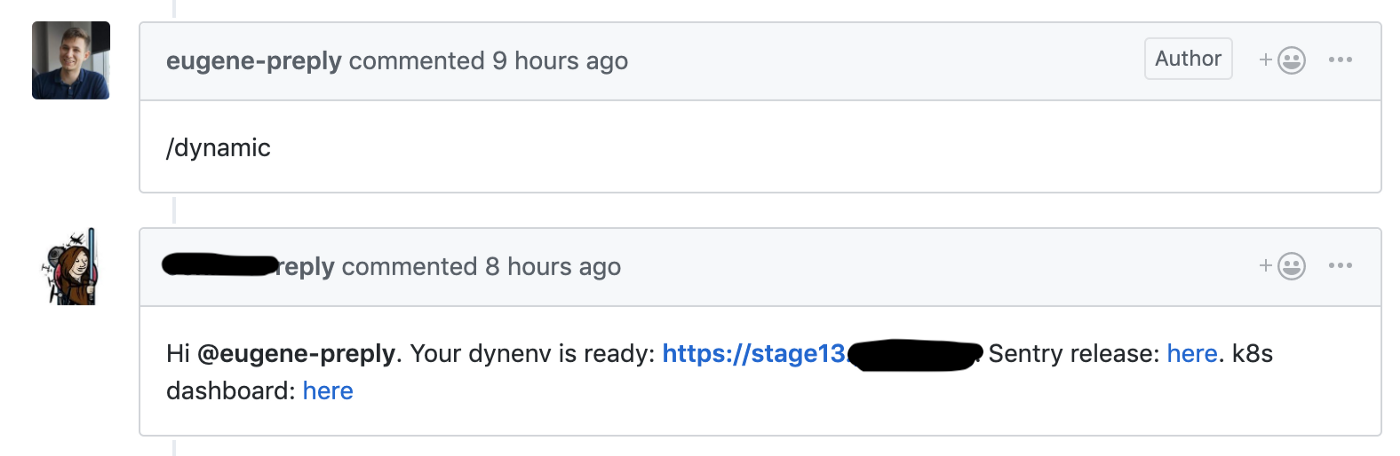
Github hook lanza la creación de un entorno dinámico para la solicitud de extracción
Utilizamos un clúster de prueba para estos entornos dinámicos, cada entorno estaba en un espacio de nombres separado. Los desarrolladores tuvieron acceso al Panel de Kubernetes para depurar su código.
Estamos contentos de haber comenzado a beneficiarnos de Kubernetes después de solo 1-2 meses desde el comienzo de su uso.
Etapa y grupos de venta
Nuestra configuración para grupos de escenarios y productos:
- kops y Kubernetes 1.11 (la última versión en el momento de la creación del clúster)
- Tres nodos maestros en diferentes zonas de acceso.
- Topología de red privada con bastión dedicado, Calico CNI
- Prometheus para recopilar métricas se implementa en el mismo clúster con PVC (vale la pena considerar que no almacenamos métricas durante mucho tiempo)
- Agente Datadog para APM
- Dex + dex-k8s-authenticator para proporcionar acceso al clúster a los desarrolladores
- Los nodos para el clúster de etapas funcionan en instancias puntuales
Mientras trabajábamos con clústeres, encontramos varios problemas. Por ejemplo, las versiones del agente Nginx Ingress y Datadog diferían en los clústeres, en relación con esto, algunas cosas funcionaron en el clúster del escenario, pero no funcionaron en el producto. Por lo tanto, decidimos cumplir totalmente las versiones de software en los clústeres para evitar tales casos.
Migración de productos a Kubernetes
Los grupos de escenarios y alimentos están listos, y estamos listos para comenzar la migración. Utilizamos monorepa con la siguiente estructura:
. ├── microservice1 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microservice2 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microserviceN │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── helm │ ├── microservice1 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microservice2 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microserviceN │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml └── Jenkinsfile
El Jenkinsfile raíz Jenkinsfile contiene una tabla de correspondencia entre el nombre del microservicio y el directorio en el que se encuentra su código. Cuando el desarrollador retiene la solicitud de extracción al maestro, se crea una etiqueta en GitHub, esta etiqueta se implementa en el producto utilizando Jenkins de acuerdo con el archivo Jenkins.
El directorio helm/ contiene gráficos HELM con dos archivos de valores separados para el escenario y la venta. Usamos Skaffold para desplegar muchas cartas HELM en el escenario. Intentamos usar el gráfico general, pero nos enfrentamos al hecho de que es difícil de escalar.
De acuerdo con la aplicación de doce factores, cada nuevo microservicio en el producto escribe registros en stdout, lee secretos de Vault y tiene un conjunto básico de alertas (que verifica el número de hogares en funcionamiento, quinientos errores y retrasos en el ingreso).
Independientemente de si importamos nuevas características en microservicios o no, en nuestro caso toda la funcionalidad principal está en el monolito Django y este monolito todavía funciona en Elastic Beanstalk.

Divide el monolito en microservicios // El Parque Vigeland en Oslo
Utilizamos AWS Cloudfront como CDN y con él utilizamos una implementación canaria durante toda nuestra migración. Comenzamos a migrar el monolito a Kubernetes y a probarlo en algunas versiones de idiomas y en las páginas internas del sitio (como el panel de administración). Un proceso de migración similar nos permitió detectar errores en la producción y pulir nuestras implementaciones en solo unas pocas iteraciones. En el transcurso de un par de semanas, monitoreamos el estado de la plataforma, la carga y el monitoreo, y al final, el 100% del tráfico de ventas se cambió a Kubernetes.
Después de eso, pudimos negarnos a usar Elastic Beanstalk.
Resumen
La migración completa nos llevó 11 meses, como mencioné anteriormente, planeamos cumplir con la fecha límite de 1 año.
En realidad, los resultados son obvios:
- El tiempo de implementación disminuyó de 90 min a 40 min.
- El número de implementaciones aumentó de 0-2 a 10-15 por día (¡y sigue creciendo!)
- El tiempo de reversión disminuyó de 45 a 1-2 minutos.
- Podemos entregar fácilmente nuevos microservicios al producto
- Arreglamos nuestro monitoreo, registro, gestión de secretos, los centralizamos y los describimos como código
Fue una experiencia de migración muy interesante y todavía estamos trabajando en muchas mejoras de plataforma. Asegúrese de leer el interesante artículo sobre la experiencia con Kubernetes de Jura, fue uno de esos ingenieros de YAML que participaron en la implementación de Kubernetes en Preply.