En el mundo de la criptografía, hay muchas formas fáciles de cifrar un mensaje. Cada uno de ellos es bueno a su manera. Uno de ellos será discutido.
Ylchu Schzzkgow
O traducido del "Cifrado del César" al ruso - Cifrado del César .

- ¿Cuál es su esencia?
- Codifica el mensaje, cambiando cada letra por N puntos. El clásico cifrado de César mueve las letras tres pasos hacia adelante. En palabras simples: era "abv", se convirtió en "dónde".
"¿Pero qué pasa con las letras al final del alfabeto?" ¿Qué hay de los espacios?
Están bien. Si cambia la letra, el cifrado va más allá del alcance del alfabeto: comienza a contar de nuevo. Es decir, las letras "Eyuya" se convierten en "abv". Y los espacios siguen siendo espacios.
- ¿Debería N ser necesariamente igual a tres?
En absoluto N puede diferir de tres. Se permite cualquier N entre [1: M-1], donde M es el número de letras en el alfabeto.
Tal cifrado es fácil de descifrar si conoce su existencia. Pero no fue su "fiabilidad" lo que me atrajo, sino algo más.
Empate
Un día de verano quería saber:
- Pero, ¿qué sucede si cifro una palabra con Caesar y obtengo una palabra existente en la salida?
- ¿Cuántas de esas palabras son "cambiaformas"?
- ¿Y habrá un patrón si se cambia N?
Empecé a buscar respuestas a estas preguntas en los mismos minutos.
Tarea: encuentra todas las palabras
Retiro De los conciertos de Mikhail Zadornov y la experiencia personal, entendí dos cosas:
- Los estadounidenses no se ofenden por el discurso de los comediantes rusos.
- El idioma ruso es fuerte y poderoso. Y hay muchas palabras en él.
Por lo tanto, decidí tomar el idioma inglés como base. Además, había una vez que los chicos de habla inglesa pudieron armar un diccionario completo de palabras en inglés. Lo que me impulsó a encontrar ese conjunto de datos.
La primera línea de google lento me trajo a este repositorio . El autor prometió 479K palabras en inglés en formatos convenientes. Me gustó el archivo json, en el que todas las palabras se presentaron en una forma conveniente para cargar en el diccionario Python.
Después de la primera autopsia, resultó que había menos palabras: 370 101 piezas. "Pero esto no importa, porque para un buen ejemplo será suficiente", pensé.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Primero necesitas crear un alfabeto. Decidí hacer una lista de la manera más conveniente para mí. También era necesario recordar la cantidad de letras en el alfabeto:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
Al principio fue interesante hacer la función de traducir una palabra encriptada. Esto es lo que sucedió:
Decidí hacer un gran ciclo de todas las palabras y comenzar a traducirlas una por una. Pero se encontró con un problema. Resultó que algunas palabras contenían un signo "-", que era sorprendente y natural al mismo tiempo.
Sin pensarlo dos veces, conté el número de esas palabras y resultó que solo había dos de ellas. Después de lo cual eliminó ambos, porque difícilmente afectará el resultado. Para ayudarme, nació esta función:
El diccionario se veía así:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Por lo tanto, decidí no ser inteligente y reemplazar las palabras codificadas. Para hacer esto, escribió una función:
Y, por supuesto, necesitábamos un gran ciclo que abarcara todas las palabras, encontrara los cambiadores de palabras y guardara el resultado. Aquí esta:
Es posible que haya notado que en los parámetros de la función está "min_len = 0". Será necesario en el futuro. Por la peculiaridad de este conjunto de datos era un conjunto de palabras "extraño". Tales como: "aa", "aah" y combinaciones similares. Fueron ellos quienes dieron el primer resultado: 660 palabras cambiantes.
Por lo tanto, tuve que poner un límite de cinco al menos cinco caracteres para que las palabras fueran agradables a la vista y similares a las existentes.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Sí, se encontraron diez palabras invertidas gracias al algoritmo. Mi combinación favorita:
primero [Primero] → azufre [Azufre]. La mayoría de los otros pares de traductores de Google no reconoce.
En esta etapa, apagué parcialmente la sed de conocimiento. Pero por delante había preguntas como: "¿Qué pasa con la otra N?"
Y usando esta función, encontré la respuesta:
El ciclo terminó en 10-15 segundos. Solo queda ver los resultados. Pero, como creo, es más interesante cuando hay un horario. Y aquí está la función final, que nos mostrará el resultado:
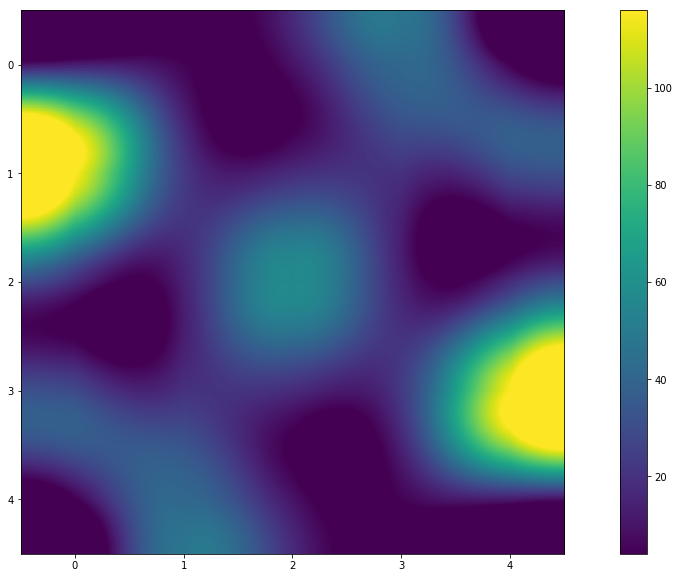
Resumen
Respuestas a preguntas al principio
"¿Qué sucede si cifro una palabra con Caesar y obtengo una palabra existente en la salida?"
- Esto es posible, incluso muy. Algunos N dan muchas más palabras que otros.
- ¿Cuántas de esas palabras "cambiaformas" hay?
- Depende de N, la longitud mínima y, por supuesto, del conjunto de datos. En mi caso, con N = 3, la longitud mínima de palabra de 0 y 5 es el número de palabras: 660 y 10, respectivamente.
- ¿Y habrá un patrón si cambias N?
- ¡Al parecer sí! En el gráfico (o mapa de calor) puede ver que los colores son simétricos. Y los valores en la matriz de resultados lo indican. Y la respuesta a la pregunta "¿Por qué es así?" Lo dejaré al lector.
Contras de este trabajo
- Conjunto de datos no del todo correcto. Muchas palabras no son obvias. Aunque puede ser así. Estas son " todas " palabras del idioma inglés.
- Código
siempre Se puede mejorar. - El "código de César" es un caso especial del "código ateniense", donde la fórmula:
Para "Cifrado del César" A = 1. Por cierto, tiene más matices, lo que significa más interesante.
Mi archivo de trabajo con el resultado y una lista de palabras invertidas se encuentra en este repositorio
Efzp zzhgl!