El particionamiento ("particionamiento") en SQL Server, con aparente simplicidad ("lo que hay allí: distribuye la tabla y los índices por grupos de archivos, obtiene ganancias en administración y rendimiento") es un tema bastante extenso. A continuación, trataré de describir cómo crear y aplicar una función y un esquema de partición y qué problemas puede encontrar. No hablaré sobre los beneficios, excepto por una cosa: cambiar secciones, cuando eliminas instantáneamente un gran conjunto de datos de una tabla, o viceversa, carga instantáneamente un conjunto no menos grande en una tabla.
Como dice
msdn : “Los datos de tablas e índices particionados se dividen en bloques que pueden distribuirse entre varios grupos de archivos en la base de datos. Los datos se dividen horizontalmente, por lo que los grupos de filas se asignan a secciones individuales. Todas las secciones del mismo índice o tabla deben estar en la misma base de datos. Una tabla o índice se considera una entidad lógica única cuando se ejecutan consultas o actualizaciones de datos ".
Las principales ventajas también se enumeran allí:
- Transfiera y acceda a subconjuntos de datos de manera rápida y eficiente mientras mantiene la integridad del conjunto de datos
- Las operaciones de mantenimiento se pueden realizar más rápido con una o más secciones;
- Puede aumentar la velocidad de ejecución de consultas, dependiendo de las consultas que a menudo se ejecutan en su configuración de hardware.
En otras palabras, la partición se usa para el escalado horizontal. La tabla / los índices están "distribuidos" por diferentes grupos de archivos, que se pueden ubicar en diferentes discos físicos, lo que aumenta significativamente la conveniencia de la administración y, en teoría, le permite mejorar el rendimiento de las consultas a estos datos: puede leer solo la sección deseada (menos datos) o leer todo en paralelo (los dispositivos son diferentes, lea rápidamente). En la práctica, todo es algo más complicado y aumentar el rendimiento de las consultas en tablas particionadas solo puede funcionar si sus consultas usan la selección por el campo por el que particionó. Si aún no tiene experiencia con tablas particionadas, solo tenga en cuenta que el rendimiento de sus consultas puede no cambiar, pero puede deteriorarse después de particionar su tabla.
Hablemos de la ventaja absoluta que definitivamente se lleva bien con la partición (pero que también necesita poder usar): este es un aumento garantizado en la conveniencia de administrar su base de datos. Por ejemplo, tiene una tabla con mil millones de registros, de los cuales 900 millones pertenecen a períodos anteriores ("cerrados") y son de solo lectura. Con la ayuda de la sección, puede transferir estos datos antiguos a un grupo de archivos de solo lectura separado, hacer una copia de seguridad y ya no arrastrarlo a todas sus copias de seguridad diarias: la velocidad de creación de una copia de seguridad aumentará y el tamaño disminuirá. Puede reconstruir el índice no sobre toda la tabla, sino sobre secciones seleccionadas. Además, la disponibilidad de su base de datos está creciendo: si uno de los dispositivos que contiene el grupo de archivos con la sección falla, los demás seguirán estando disponibles.
Para lograr los beneficios restantes (cambiar de sección al instante; aumentar la productividad), debe diseñar específicamente la estructura de datos y escribir consultas.
Supongo que ya he avergonzado al lector lo suficiente y ahora puedo proceder a practicar.
Primero, cree una base de datos con 4 grupos de archivos en los que realizaremos experimentos:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
Crea una tabla que atormentaremos.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
Y llénalo con datos de un año:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
Ahora la tabla pTest contiene un registro por cada hora de 2018.
Ahora necesita crear una función de partición que describa las condiciones de contorno para dividir datos en secciones. SQL Server solo admite particiones de rango.
Vamos a dividir nuestra tabla en la columna dt (fecha y hora) para que cada sección contenga datos durante 4 meses (aquí la arruiné; de hecho, la primera sección contendrá datos para 3, la segunda para 4, la tercera durante 5 meses, pero para fines de demostración, esto no es un problema)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
Todo parece ser normal, pero aquí deliberadamente cometí un "error". Si observa la sintaxis en
msdn , verá que durante la creación puede especificar a qué sección pertenecerá el borde especificado: a la izquierda o a la derecha. Por defecto, por alguna razón desconocida, el borde especificado se refiere a la sección "izquierda", por lo que para mi caso sería correcto crear una función de partición de la siguiente manera:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Si bien en realidad ejecuté:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
Pero volveremos a esto más tarde y recrearemos nuestra función de partición. Mientras tanto, continuamos con lo que sucedió para entender qué sucedió y por qué no es muy bueno para nosotros.
Después de crear la función de partición, debe crear un esquema de partición. Claramente une secciones a grupos de archivos:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Como puede ver, nuestras tres secciones estarán en diferentes grupos de archivos. Ahora es el momento de dividir nuestra mesa. Para hacer esto, necesitamos crear un índice agrupado y, en lugar de especificar el grupo de archivos en el que debe ubicarse, especifique el esquema de partición:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
Y aquí, también, cometí un "error" en el esquema actual: muy bien podría haber creado un índice agrupado único en esta columna, sin embargo, al crear un índice único, la columna utilizada para particionar debería incluirse en el índice. Y quiero mostrar lo que puede encontrar con esta configuración.
Ahora veamos qué obtuvimos en la configuración actual (la
solicitud se toma de aquí ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

Por lo tanto, obtuvimos tres secciones poco exitosas: la primera almacena datos desde el principio del tiempo hasta el 01/04/2018 00:00:00 inclusive, la segunda, desde el 01/01/2018 00:00:01 hasta el 01/08/2018 00:00:00 inclusive, el tercero desde el 01/08/2018 00:00:01 hasta el fin del mundo (deliberadamente perdí la fracción de un segundo, porque no recuerdo en qué gradación SQL Server escribe estas fracciones, pero el significado se transmite correctamente).
Ahora cree un índice no agrupado en el campo dummy_int, "alineado" de acuerdo con el mismo esquema de partición.
¿Por qué necesitamos un índice alineado?necesitamos un índice alineado para poder realizar la operación de cambiar una sección (interruptor), y esta es una de esas operaciones para las cuales, a menudo, se molestan con la partición. Si hay al menos un índice no alineado en la tabla, no puede cambiar la sección
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
Y veamos por qué dije que sus consultas pueden volverse más lentas después de la implementación del seccionamiento. Ejecute la solicitud:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
Y veamos las estadísticas de ejecución:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Y el plan de implementación:

Dado que nuestro índice está "alineado" por secciones, condicionalmente, cada sección tiene su propio índice, que está "desconectado" con los índices de otras secciones. No impusimos condiciones en el campo por el que se divide el índice, por lo que SQL Server se ve obligado a ejecutar Index Seek en cada sección, de hecho, 3 Index Seek en lugar de una.
Intentemos excluir una sección:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
Y veamos las estadísticas de ejecución:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Sí, se excluyó una sección y la búsqueda del valor deseado se realizó en solo dos secciones.
Esto es algo que debe recordarse al decidir la partición. Si tiene consultas que no utilizan una restricción en el campo por el que se divide la tabla, puede tener un problema.
Ya no necesitamos el índice no agrupado, así que lo elimino
drop index nix_pTest_dummyINT on pTest;
¿Y por qué se necesitaba un índice sin clúster?en general, no lo necesitaba, podría mostrar lo mismo con el índice de clúster, no sé por qué lo creé, pero como lo hice y tomé capturas de pantalla, no pierda lo bueno
Ahora considere el siguiente escenario: archivamos los datos de esta tabla cada 4 meses: eliminamos los datos antiguos y agregamos una sección para los próximos cuatro meses (la organización de la "ventana deslizante" se describe en msdn y el montón de blogs).
Dividimos la tarea en subtareas pequeñas y comprensibles:
- Agregar una sección para datos del 01/01/2019 al 01/04/2019
- Crear una mesa de escenario vacía
- Cambie la sección de datos hasta el 01/04/2018 en la tabla de etapas
- Deshazte de la sección vacía
Vamos:
1. Anunciamos que la nueva sección se creará en el grupo de archivos FG1, porque pronto se nos liberará:
alter partition scheme psTest next used [FG1];
Y cambie la función de partición agregando un nuevo borde:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Nos fijamos en las estadísticas:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Hay 8809 páginas en la tabla (índice de clúster), por lo que el número de lecturas, por supuesto, está más allá del bien y del mal. Veamos lo que tenemos ahora en secciones.

En general, todo es como se esperaba: ha aparecido una nueva sección con un límite superior (recuerde que las condiciones de límite para nosotros pertenecen a la sección izquierda) 01/01/2019 y una sección vacía en la que habrá otros datos con una fecha más larga.
Todo parece estar bien, pero ¿por qué hay tantas lecturas? Observamos cuidadosamente la figura anterior y vemos que los datos de la tercera sección que estaban en FG3 terminaron en FG1, pero la siguiente sección, vacía, en FG3.
2. Crear una mesa de escenario.
Para cambiar (cambiar) una sección a una tabla y viceversa, necesitamos una tabla vacía en la que se creen las mismas restricciones e índices que en nuestra tabla particionada. La tabla debe estar en el mismo grupo de archivos que la sección que queremos "cambiar" allí. La primera sección (archivada) se encuentra en FG1, por lo que creamos una tabla y un índice de clúster en el mismo lugar:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
No necesita particionar esta tabla.
3. Ahora estamos listos para cambiar:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Y esto es lo que obtenemos:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Es curioso, veamos qué tenemos en los índices:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
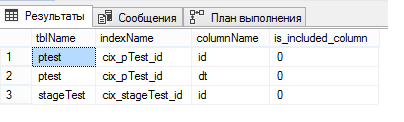
¿Recuerdas que escribí que era necesario hacer un índice agrupado único en una tabla particionada? Eso es precisamente por qué era necesario. Al crear un índice agrupado único, SQL Server requeriría incluir explícitamente la columna por la cual dividimos la tabla en el índice, por lo que lo agregó él mismo y olvidó decirlo. Y realmente no entiendo por qué.
Pero, en general, el problema es comprensible, recreamos el índice del clúster en la tabla del escenario.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
Y ahora, una vez más, intentamos cambiar la sección:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Ta Dam! La sección está cambiada, vea lo que nos costó:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Pero nada Cambiar una sección a una tabla vacía y viceversa (una tabla completa a una sección vacía) es una operación únicamente en metadatos y esta es exactamente la razón por la cual la partición es algo muy, muy bueno.
Veamos qué hay con nuestras secciones:

Y todo es genial con ellos. En la primera sección, quedan cero registros, se dejaron de forma segura para la tabla stageTest. Podemos seguir adelante
4. Todo lo que nos queda es eliminar nuestra primera sección vacía. Hagámoslo y veamos qué sucede:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Y esto también es una operación solo en metadatos, en nuestro caso. Nos fijamos en las secciones:

Tenemos, como era, solo 3 secciones, cada una en su propio grupo de archivos. Misión cumplida ¿Qué podría mejorarse aquí? Bueno, en primer lugar, me gustaría que los valores límite se refieran a las secciones "correctas", de modo que las secciones contengan todos los datos durante 4 meses. Y me gustaría ver que la creación de una nueva sección cuesta menos. Lea los datos diez veces más que la tabla misma: busto.
No podemos hacer nada con el primero ahora, pero con el segundo lo intentaremos. Creemos una nueva sección que contendrá datos del 01/01/2019 al 01/04/2019, y no hasta el final de los tiempos:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
Y vemos:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Ja! Entonces, ¿ahora esta operación solo está en metadatos? Sí, si "divide" una sección vacía: esta es una operación solo en metadatos, por lo tanto, será la decisión correcta mantener las secciones vacías garantizadas tanto a la izquierda como a la derecha y, si es necesario, seleccionar una nueva: "cortarlas" desde allí.
Ahora veamos qué sucede si quiero devolver los datos de la tabla de escenario a la tabla particionada. Para hacer esto, necesitaré:
- Crear una nueva sección a la izquierda para datos
- Cambie la tabla a esta sección.
Intentamos (y recordamos que stageTest en FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
Vemos:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Bueno, no está mal, es decir lee solo la sección izquierda (que dividimos) y eso es todo. Esta bien Para cambiar una tabla no vacía no particionada en una sección de tabla particionada, la tabla fuente debe tener restricciones para que SQL Server sepa que todo estará bien y que el cambio se puede realizar como una operación en metadatos (en lugar de leer todo en una fila y verificar si la sección cumple o no las condiciones) ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
Intentando cambiar:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
Estadísticas:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
Nuevamente, la operación es solo en metadatos. Vemos qué hay con nuestras secciones:

Esta bien Parece resuelto. Y ahora intentaremos recrear la función y el esquema de particionamiento (eliminé el esquema y la función de particionamiento, recreé y rellené la tabla y volví a crear el índice del clúster utilizando el nuevo esquema de particionamiento):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Veamos qué secciones tenemos ahora:

Bueno, ahora tenemos tres secciones "lógicas": desde el principio hasta el 01/04/2018 00:00:00 (no incluido), desde el 01/04/2018 00:00:00 (incluido) hasta el 01/08/2018 00:00:00 ( no incluido) y el tercero, todo lo que es mayor o igual a 01/01/2018 00:00:00.
Ahora intentemos realizar la misma tarea de archivar datos que realizamos con la función de partición anterior.
1. Agregar una nueva sección:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Nos fijamos en las estadísticas:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
No está mal, al menos razonablemente, lea solo la última sección. Nos fijamos en lo que tenemos en las secciones:

Tenga en cuenta que ahora, la tercera sección completa se ha mantenido en su lugar en FG3, y se ha creado una nueva sección vacía en FG1.
2. Creamos una tabla de escenario y el índice de clúster CORRECTO en ella
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Cambiar sección
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Las estadísticas dicen que la operación de metadatos es:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
Ahora, todo sin sorpresas.
4. Eliminar la sección innecesaria
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Y aquí tenemos una sorpresa:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Nos fijamos en lo que tenemos con las secciones:

Y aquí queda claro: nuestra sección # 2 se movió del grupo de archivos fg2 al grupo de archivos fg1. Clase. ¿Podemos hacer algo al respecto?
Tal vez solo necesitemos tener siempre una sección vacía y "destruir" el borde entre la sección izquierda "siempre vacía" y la sección que "cambiamos" a otra tabla.
En conclusión:- Utilice la sintaxis completa para crear la función de partición, no confíe en los valores predeterminados; es posible que no obtenga lo que desea.
- Manténgase a la izquierda y a la derecha en la sección vacía: serán muy útiles para organizar una "ventana deslizante".
- Dividir y fusionar secciones no vacías: siempre duele, evítelo si es posible.
- Verifique sus consultas: si no usan el filtro por la columna en la que planea dividir la tabla y necesita la capacidad de cambiar de sección, su rendimiento puede disminuir significativamente.
- Si quieres hacer algo, primero prueba que no esté en producción.
Espero que el material haya sido útil. Tal vez resultó ser arrugado, si crees que algo de lo declarado no se revela, escribe, intentaré terminarlo. Gracias por su atencion