Hola a todos Antes del comienzo del curso de Machine Learning, queda poco más de una semana. En previsión del comienzo de las clases, hemos preparado una traducción útil que será de interés tanto para nuestros estudiantes como para todos los lectores del blog. Empecemos

¡Es hora de deshacerse de las cajas negras y construir fe en el aprendizaje automático!En su libro
"Interpretable Machine Learning", Christoph Molnar destaca perfectamente la esencia de la interpretabilidad del Machine Learning con el siguiente ejemplo: Imagina que eres un experto en Data Science y en tu tiempo libre tratando de predecir a dónde irán tus amigos en vacaciones de verano según sus datos de Facebook y Twitter Entonces, si el pronóstico es correcto, tus amigos te considerarán un mago que puede ver el futuro. Si las predicciones son erróneas, no dañará nada más que su reputación como analista. Ahora imagine que no fue solo un proyecto divertido, sino que también atrajo inversiones. Supongamos que desea invertir en bienes raíces donde es probable que sus amigos se relajen. ¿Qué sucede si las predicciones del modelo fallan? Perderás dinero. Mientras el modelo no tenga un impacto significativo, su capacidad de interpretación no importa mucho, pero cuando hay consecuencias financieras o sociales asociadas con las predicciones del modelo, su capacidad de interpretación adquiere un significado completamente diferente.
Explicación automática de aprendizaje
Interpretar es explicar o mostrar en términos comprensibles. En el contexto de un sistema ML, la interpretabilidad es la capacidad de explicar su acción o mostrarla en una
forma legible para los humanos .
Muchas personas han denominado modelos de aprendizaje automático "cajas negras". Esto significa que a pesar del hecho de que podemos obtener un pronóstico preciso de ellos, no podemos explicar o entender claramente la lógica de su compilación. Pero, ¿cómo puedes extraer ideas del modelo? ¿Qué cosas deben tenerse en cuenta y qué herramientas necesitamos para hacer esto? Estas son preguntas importantes que vienen a la mente cuando se trata de la interpretabilidad del modelo.
Importancia de la interpretabilidad
La pregunta que algunas personas hacen es,
¿por qué no solo estar contentos de que estamos obteniendo un resultado concreto del trabajo del modelo, por qué es tan importante saber cómo se tomó esta o aquella decisión? La respuesta radica en el hecho de que el modelo puede tener un cierto impacto en eventos posteriores en el mundo real. La interpretabilidad será mucho menos importante para los modelos diseñados para recomendar películas que para los modelos que se usan para predecir los efectos de un medicamento.
"El problema es que solo una métrica, como la precisión de la clasificación, es una descripción inadecuada de la mayoría de las tareas del mundo real". (
Doshi Veles y Kim 2017 )
Aquí hay un panorama general sobre el aprendizaje automático explicable. En cierto sentido, capturamos el mundo (o más bien, información de él), recolectamos datos sin procesar y los usamos para pronósticos adicionales. En esencia, la interpretabilidad es solo otra capa del modelo que ayuda a las personas a comprender todo el proceso.
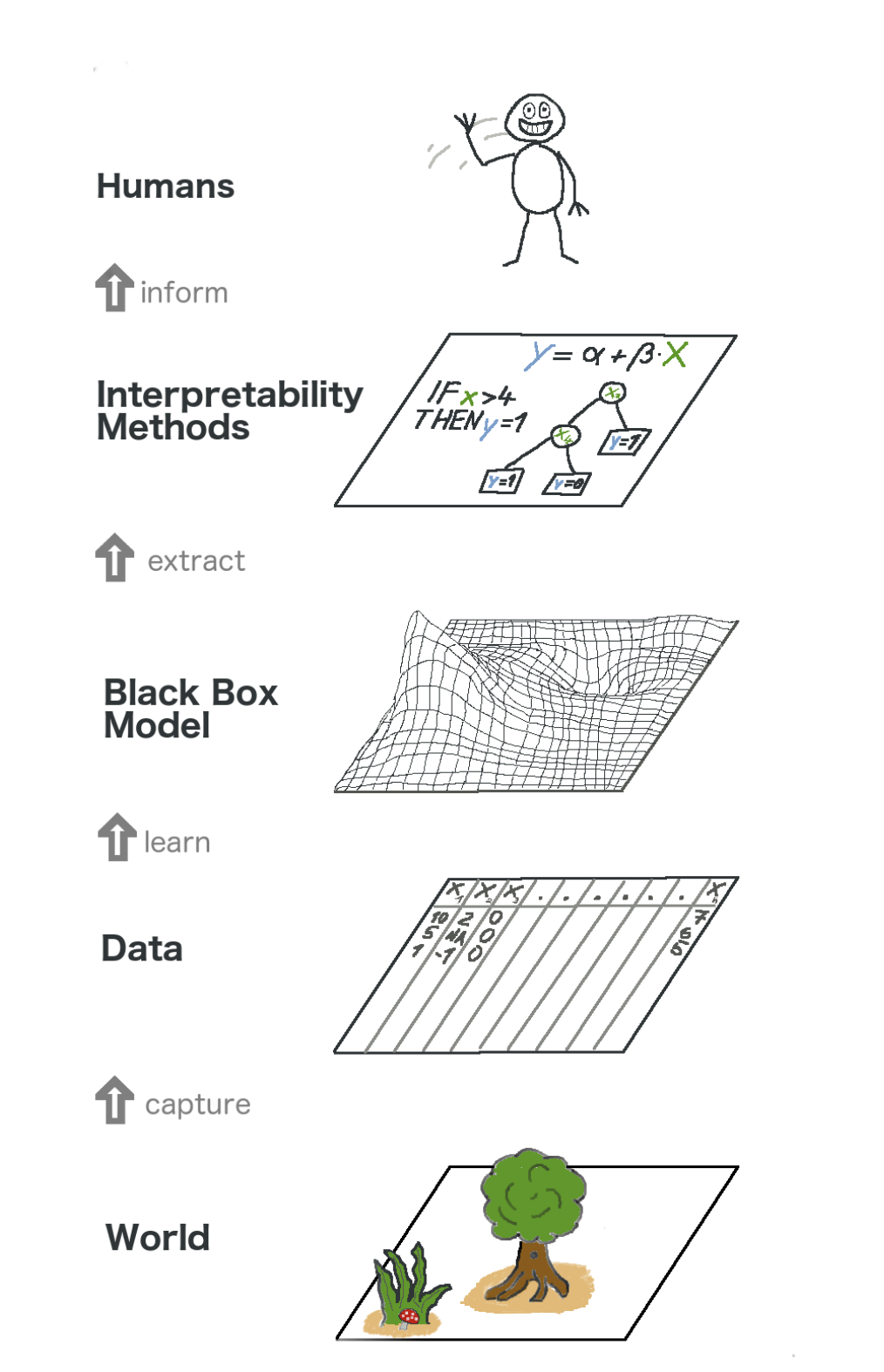 El texto en la imagen de abajo hacia arriba: Mundo -> Obtener información -> Datos -> Capacitación -> Modelo de caja negra -> Extracto -> Métodos de interpretación -> Personas
El texto en la imagen de abajo hacia arriba: Mundo -> Obtener información -> Datos -> Capacitación -> Modelo de caja negra -> Extracto -> Métodos de interpretación -> PersonasAlgunos de los
beneficios que trae la interpretabilidad son:
- Fiabilidad
- Conveniencia de depuración;
- Información sobre características de ingeniería;
- Gestión de la recopilación de datos para las características.
- Información sobre la toma de decisiones;
- Construyendo confianza.
Métodos de interpretación del modelo
Una teoría tiene sentido solo mientras podamos ponerla en práctica. En caso de que realmente quiera abordar este tema, puede intentar tomar el curso de Explicabilidad de Machine Learning de Kaggle. En él encontrará la correlación correcta de la teoría y el código con el fin de comprender los conceptos y poder poner en práctica los conceptos de interpretabilidad (explicabilidad) de modelos a casos reales.
Haga clic en la captura de pantalla a continuación para ir directamente a la página del curso. Si desea obtener una visión general del tema primero, continúe leyendo.
Información que se puede extraer de los modelos.
Para comprender el modelo, necesitamos las siguientes ideas:
- Las características más importantes en el modelo;
- Para cualquier pronóstico específico del modelo, el efecto de cada atributo individual en un pronóstico específico.
- La influencia de cada característica en una gran cantidad de pronósticos posibles.
Analicemos algunos métodos que ayudan a extraer las ideas anteriores del modelo:
Importancia de permutación
¿Qué características considera importantes el modelo? ¿Qué síntomas tienen el mayor impacto? Este concepto se denomina importancia de la característica, y la Importancia de permutación es un método ampliamente utilizado para calcular la importancia de las características. Nos ayuda a ver en qué punto el modelo produce resultados inesperados, nos ayuda a mostrar a los demás que nuestro modelo funciona exactamente como debería.
La importancia de la permutación funciona para muchas evaluaciones de scikit-learn. La idea es simple: reorganizar o mezclar arbitrariamente una columna en el conjunto de datos de validación, dejando intactas las demás columnas. Un signo se considera "importante" si la precisión del modelo cae y su cambio provoca un aumento de errores. Por otro lado, una característica se considera "sin importancia" si mezclar sus valores no afecta la precisión del modelo.
Como funciona
Considere un modelo que predice si un equipo de fútbol recibirá el premio "El hombre del juego" o no, según ciertos parámetros. Este premio se otorga al jugador que demuestre las mejores habilidades del juego.
La importancia de la permutación se calcula después de entrenar el modelo. Entonces,
RandomForestClassifier y preparemos el modelo
RandomForestClassifier , designado como
my_model , en los datos de entrenamiento.
La importancia de la permutación se calcula utilizando la biblioteca
ELI5 . ELI5 es una biblioteca en Python que le permite visualizar y depurar varios modelos de aprendizaje automático utilizando una API unificada. Tiene soporte incorporado para varios marcos de ML y proporciona formas de interpretar el modelo de caja negra.
Cálculo y visualización de importancia utilizando la biblioteca ELI5:
(Aquí
val_X ,
val_y denotan conjuntos de validación, respectivamente)
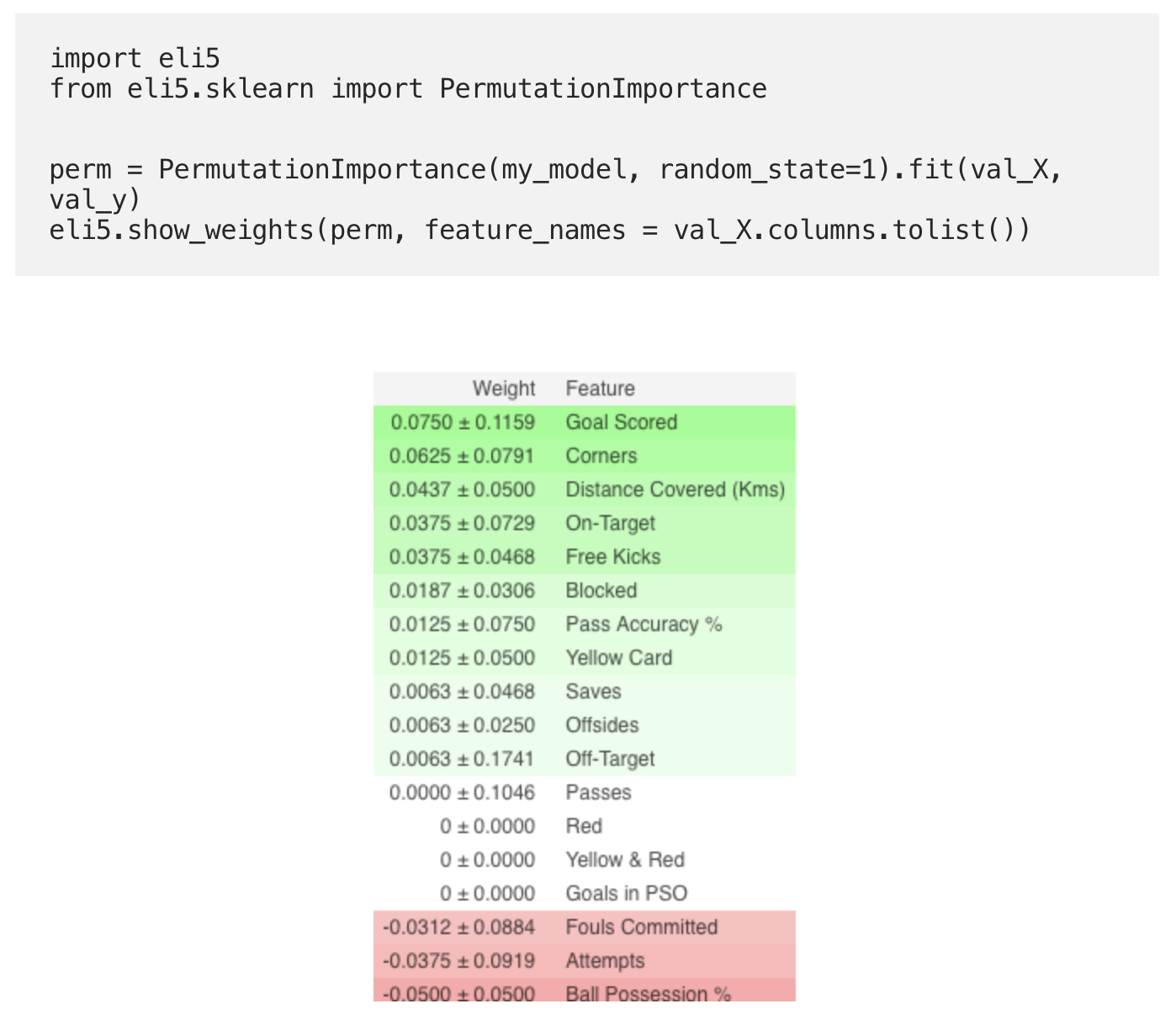
Interpretación
- Los signos de arriba son los más importantes, los de abajo son los menos importantes. Para este ejemplo, el signo más importante fueron los goles marcados.
- El número después de ± refleja cómo la productividad ha cambiado de una permutación a otra.
- Algunos pesos son negativos. Esto se debe al hecho de que en estos casos las previsiones de los datos barajados resultaron ser más precisas que los datos reales.
Practica
Y ahora, para ver el ejemplo completo y verificar si entendió todo correctamente, vaya a la página de Kaggle usando el
enlace .
Así que la primera parte de la traducción llegó a su fin. ¡Escribe tus comentarios y conoce el curso!
Lee la segunda parte .