La web moderna es casi impensable sin contenido de medios: casi todas nuestras abuelas tienen teléfonos inteligentes, todos se sientan en las redes sociales y el tiempo de inactividad del servicio es costoso para las empresas. Para su atención, hay una transcripción de la historia de Badoo sobre cómo organizó la entrega de fotos usando una solución de hardware, qué problemas de rendimiento encontró en el proceso, qué los causó y cómo se resolvieron estos problemas usando una solución de software basada en Nginx, al tiempo que garantiza tolerancia a fallas en todos los niveles ( video ). Agradecemos a los autores de la historia Oleg Sannis Efimov y Alexander Dymov, quienes compartieron su experiencia en la conferencia del día 4 de tiempo de actividad .
La web moderna es casi impensable sin contenido de medios: casi todas nuestras abuelas tienen teléfonos inteligentes, todos se sientan en las redes sociales y el tiempo de inactividad del servicio es costoso para las empresas. Para su atención, hay una transcripción de la historia de Badoo sobre cómo organizó la entrega de fotos usando una solución de hardware, qué problemas de rendimiento encontró en el proceso, qué los causó y cómo se resolvieron estos problemas usando una solución de software basada en Nginx, al tiempo que garantiza tolerancia a fallas en todos los niveles ( video ). Agradecemos a los autores de la historia Oleg Sannis Efimov y Alexander Dymov, quienes compartieron su experiencia en la conferencia del día 4 de tiempo de actividad .- Comencemos con una breve introducción sobre cómo almacenamos y almacenamos en caché las fotos. Tenemos una capa en la que los almacenamos, y una capa donde almacenamos las fotos en caché. Al mismo tiempo, si queremos lograr un gran éxito y reducir la carga en cientos, es importante para nosotros que cada foto de un usuario individual se encuentre en un servidor de almacenamiento en caché. De lo contrario, tendríamos que poner tantas veces más discos, cuántos servidores más tenemos. Tenemos una tasa de éxito de alrededor del 99%, es decir, reducimos la carga en nuestro almacenamiento 100 veces, y para hacer esto, incluso hace 10 años, cuando todo esto se construyó, teníamos 50 servidores. En consecuencia, para dar estas fotos, necesitábamos esencialmente 50 dominios externos a los que sirven estos servidores.
Naturalmente, la pregunta surgió de inmediato: si un servidor cae, no estará disponible, ¿qué parte del tráfico estamos perdiendo? Analizamos lo que hay en el mercado y decidimos comprar una pieza de hierro para resolver todos nuestros problemas. La elección recayó en la decisión de la compañía de la red F5 (que, por cierto, recientemente compró NGINX, Inc): BIG-IP Local Traffic Manager.

Lo que hace esta pieza de hardware (LTM): es un enrutador de hierro que hace la redundancia de hierro de sus puertos externos y le permite enrutar el tráfico en función de la topología de la red, en algunas configuraciones, y realiza comprobaciones de estado. Para nosotros era importante que esta pieza de hierro se pueda programar. En consecuencia, podríamos describir la lógica de cómo se proporcionaron las fotografías de un usuario específico desde un caché en particular. ¿Cómo se ve? Hay una pieza de hierro que se ve en Internet en un dominio, una ip, descarga ssl, analiza las solicitudes http, desde IRule selecciona el número de caché a dónde ir y deja que el tráfico vaya allí. Al mismo tiempo, realiza comprobaciones de estado y, si alguna máquina no está disponible, la realizamos en ese momento para que el tráfico fuera a un servidor de respaldo. Desde el punto de vista de la configuración, hay, por supuesto, algunos matices, pero en general todo es bastante simple: prescribimos una tarjeta, hacemos coincidir algún número con nuestra IP en la red, decimos que escucharemos en los puertos 80 y 443, decimos, que si el servidor no está disponible, debe iniciar el tráfico en la copia de seguridad, en este caso el 35, y describimos un montón de lógica sobre cómo se debe desmontar esta arquitectura. El único problema era que el lenguaje que programaba la pieza de hardware era Tcl. Si alguien recuerda esto ... este lenguaje es más de solo escritura que un lenguaje conveniente para la programación:

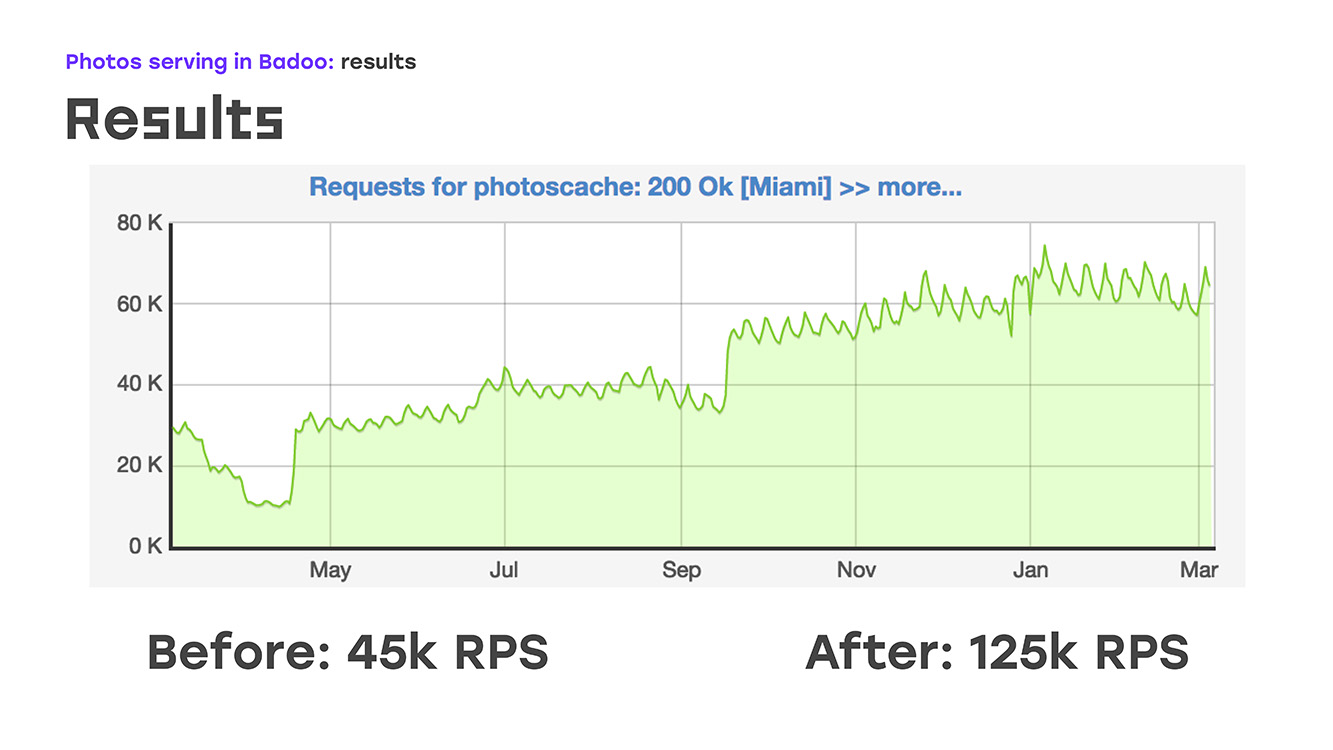
Que conseguimos Obtuvimos un hardware que brinda alta disponibilidad de nuestra infraestructura, enruta todo nuestro tráfico, brinda cuidados de salud y simplemente funciona. Además, ha estado funcionando durante bastante tiempo: en los últimos 10 años no ha habido quejas al respecto. A principios de 2018, ya estábamos entregando unas 80k fotos por segundo. Esto es alrededor de 80 gigabits de tráfico de nuestros dos centros de datos.
Sin embargo ...
A principios de 2018, vimos una imagen fea en las listas: el tiempo de respuesta de las fotos aumentó claramente. Y ha dejado de satisfacernos. El problema es que este comportamiento solo era visible en el pico del tráfico; para nuestra compañía, esta es la noche de domingo a lunes. Pero el resto del tiempo, el sistema se comportó como de costumbre, sin signos de daño.

Sin embargo, el problema tuvo que ser resuelto. Identificamos posibles cuellos de botella y comenzamos a eliminarlos. En primer lugar, por supuesto, ampliamos los enlaces ascendentes externos, realizamos una auditoría completa de los enlaces ascendentes internos, encontramos todos los posibles cuellos de botella. Pero todo esto no dio un resultado obvio, el problema no desapareció.
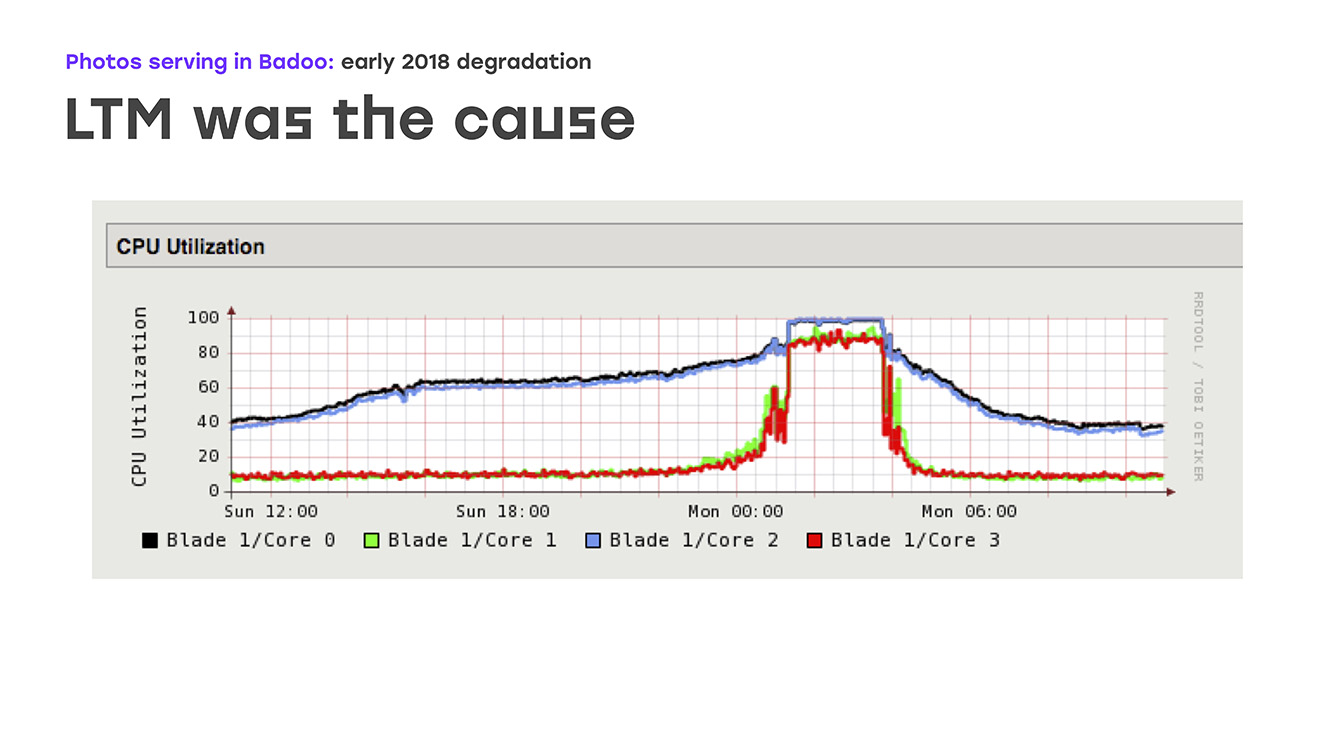
Otro posible cuello de botella fue el rendimiento de las fotos en caché. Y decidimos que quizás el problema descansa en ellos. Bueno, ampliamos el rendimiento, principalmente puertos de red en cachés de fotos. Pero, de nuevo, no se observó una mejora aparente. Al final, prestamos mucha atención al rendimiento de LTM en sí, y aquí vimos una imagen triste en los gráficos: la carga de todas las CPU comienza a funcionar sin problemas, pero luego se apoya bruscamente en el estante. Al mismo tiempo, LTM deja de responder adecuadamente a las comprobaciones de estado y enlaces ascendentes y comienza a apagarlos al azar, lo que conduce a una grave degradación del rendimiento.
Es decir, identificamos la fuente del problema, identificamos el cuello de botella. Queda por decidir qué haremos.
Lo primero que sugiere que podríamos tomar es actualizar de alguna manera LTM. Pero hay algunos matices, porque este hierro es bastante único, no irás al supermercado más cercano y no lo comprarás. Este es un contrato por separado, un contrato de licencia por separado, y tomará mucho tiempo. La segunda opción es comenzar a pensar en usted mismo, idear su propia solución en sus componentes, preferiblemente utilizando un programa de acceso abierto. Solo queda decidir qué elegiremos exactamente para esto y cuánto tiempo dedicaremos a resolver este problema, porque los usuarios no han recibido fotos. Por lo tanto, todo esto debe hacerse muy, muy rápido, se podría decir, ayer.
Dado que la tarea sonaba como "hacer algo lo más rápido posible y usar el hardware que tenemos", lo primero que pensamos fue simplemente eliminar algunas de las máquinas que no son las más potentes del frente, poner Nginx con el que sabemos cómo trabajar e intentamos implementar toda la lógica que solía hacer la pieza de hierro. De hecho, dejamos nuestro hardware, configuramos 4 servidores más que tuvimos que configurar, creamos dominios externos para ellos, de forma similar a como era hace 10 años ... Perdimos un poco de disponibilidad si estas máquinas fallaban, pero menos resuelto el problema de nuestros usuarios a nivel local.
En consecuencia, la lógica sigue siendo la misma: ponemos Nginx, puede hacer una descarga SSL, de alguna manera podemos programar la lógica de enrutamiento, verificar el estado de las configuraciones y simplemente duplicar la lógica que teníamos antes.
Nos sentamos a escribir configuraciones. Al principio parecía que todo era muy simple, pero, desafortunadamente, es muy difícil encontrar manuales para cada tarea. Por lo tanto, no recomendamos solo google "cómo configurar Nginx para fotos": es mejor consultar la documentación oficial, que mostrará qué configuraciones vale la pena tocar. Pero es mejor elegir un parámetro específico usted mismo. Bueno, entonces todo es simple: describimos los servidores que tenemos, describimos los certificados ... Pero lo más interesante es, de hecho, la lógica del enrutamiento en sí.
Al principio, nos pareció que simplemente describimos nuestra ubicación, igualamos el número de nuestro caché de fotos, describimos con nuestras manos o el generador cuántos aguas arriba necesitamos, en cada flujo ascendente indicamos el servidor al que debe ir el tráfico y un servidor de respaldo en caso de que el servidor principal no disponible:

Pero, probablemente, si todo fuera tan simple, simplemente iríamos a casa y no diríamos nada. Desafortunadamente, con la configuración predeterminada de Nginx, que, en general, se realizó durante muchos años de desarrollo y no del todo para este caso ... la configuración se ve así: si algún servidor ascendente tiene un error de solicitud o tiempo de espera, Nginx siempre cambia el tráfico al siguiente. Al mismo tiempo, después del primer archivo, el servidor también se apagará durante 10 segundos, tanto por error como por tiempo de espera; esto ni siquiera se puede configurar. Es decir, si eliminamos o restablecemos la opción de tiempo de espera en la directiva ascendente, aunque Nginx no procesará esta solicitud y responderá con algún error no tan bueno, el servidor se cerrará.

Para evitar esto, hicimos dos cosas:
a) le prohibieron a Nginx hacer esto a mano, y desafortunadamente, la única forma de hacerlo es simplemente establecer la configuración máxima de fallas.
b) recordó que en otros proyectos usamos un módulo que le permite realizar verificaciones de antecedentes; en consecuencia, realizamos verificaciones de salud con bastante frecuencia para tener un mínimo en caso de accidente.
Desafortunadamente, esto no es todo, porque literalmente las primeras dos semanas de este esquema mostraron que la comprobación de estado de TCP también es algo poco confiable: ni Nginx ni Nginx en el estado D se pueden generar en el servidor ascendente, en este caso el núcleo aceptará la conexión, pasará la comprobación de estado, pero no funcionará. Por lo tanto, de inmediato lo reemplazamos con el estado de comprobación http'shny, hicimos uno específico, que si devuelve 200, entonces todo funciona en este script. Puede hacer una lógica adicional; por ejemplo, en el caso de servidores de almacenamiento en caché, verifique que el sistema de archivos esté montado correctamente:

Y nos convendría, excepto que en este momento el circuito repitió por completo lo que hizo la pieza de hierro. Pero queríamos hacerlo mejor. Anteriormente, teníamos un servidor de respaldo, y probablemente esto no sea muy bueno, porque si tiene cien servidores, entonces, cuando varios bloqueos a la vez, es poco probable que un servidor de respaldo haga frente a la carga. Por lo tanto, decidimos distribuir la reserva en todos los servidores: acabamos de hacer otro flujo ascendente separado, escribimos todos los servidores con ciertos parámetros allí de acuerdo con el tipo de carga que pueden manejar, agregamos las mismas comprobaciones de estado que teníamos antes :

Dado que es imposible ir a otro flujo ascendente dentro de un flujo ascendente, fue necesario asegurarse de que, en caso de que el flujo ascendente principal no estuviera disponible, en el que simplemente se escribió el caché de fotos correcto, simplemente fuimos a fallback vía error_page, desde donde fuimos a la copia de seguridad de abril:

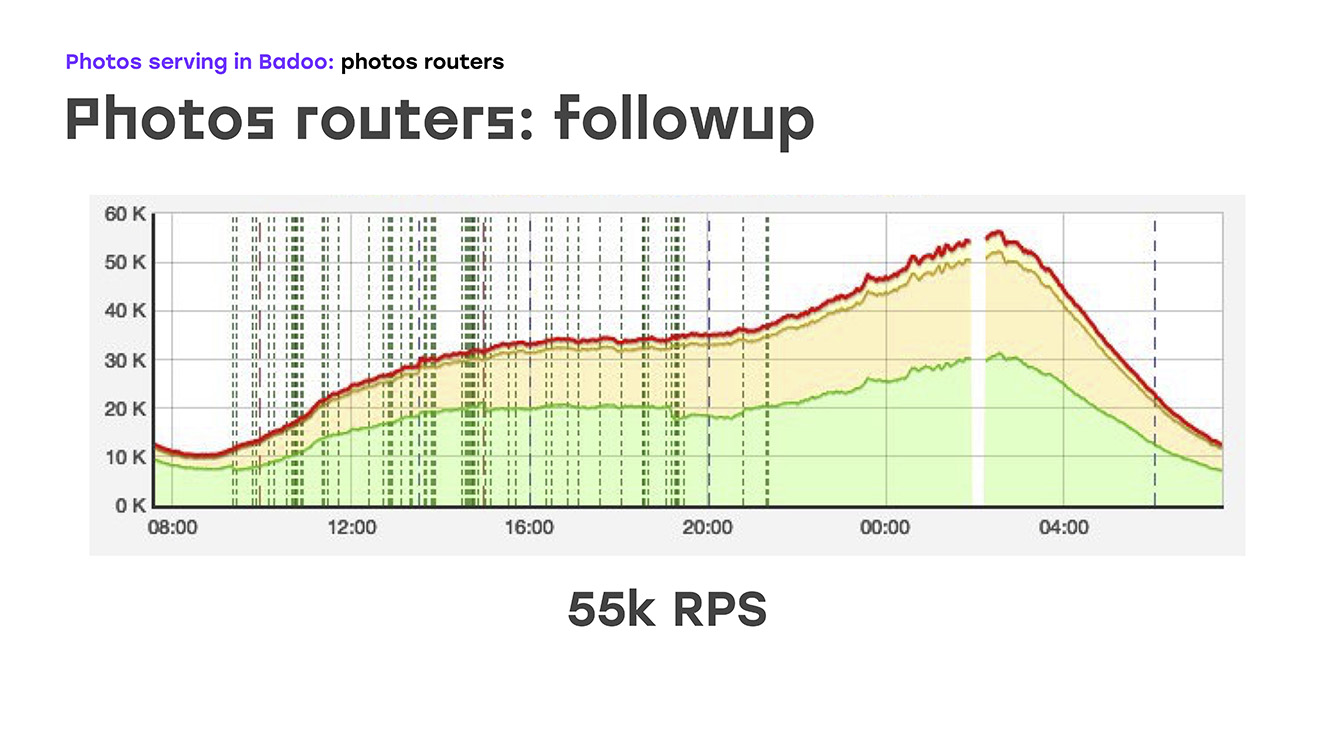
Y, literalmente, agregando cuatro servidores, obtuvimos esto: reemplazamos parte de la carga, se eliminó de LTM a estos servidores, implementamos la misma lógica allí usando hardware y software estándar, e inmediatamente obtuvimos la ventaja de que estos servidores se pueden escalar porque pueden ser simplemente pon todo lo que necesites. Bueno, lo único negativo es que hemos perdido alta disponibilidad para usuarios externos. Pero en ese momento tuve que sacrificar esto, porque tenía que resolver el problema de inmediato. Entonces, eliminamos una parte de la carga, esto es alrededor del 40% en ese momento, LTM se sintió bien y, literalmente, dos semanas después del inicio del problema, comenzamos a enviar no 45 mil solicitudes por segundo, sino 55 mil. De hecho, crecimos en un 20%, este es claramente el tráfico que no le dimos al usuario. Y después de eso comenzaron a pensar cómo resolver el problema restante: proporcionar una alta accesibilidad externa.
Tuvimos una pausa durante la cual discutimos qué solución usaremos para esto. Hubo sugerencias para garantizar la confiabilidad usando DNS, usando algunos scripts auto-escritos, protocolos de enrutamiento dinámico ... había muchas opciones, pero quedó claro que para una salida de fotos verdaderamente confiable necesitas introducir otra capa que monitoreará esto. Llamamos a estas máquinas directores de fotografía. Como el software en el que confiamos, elegí Keepalived:

Para empezar, en qué consiste Keepalived. El primero es el protocolo VRRP, ampliamente conocido por los networkers, ubicado en equipos de red que proporciona tolerancia a fallas para la dirección IP externa a la que se conectan los clientes. La segunda parte es IPVS, servidor virtual IP, para equilibrar entre enrutadores de fotos y garantizar la tolerancia a fallas en este nivel. Y el tercero son los controles de salud.
Comencemos con la primera parte: VRRP: ¿cómo se ve? Hay una cierta IP virtual en la que hay una entrada en dns badoocdn.com donde los clientes están conectados. En algún momento, tenemos una dirección IP en un servidor. Los paquetes de Keepalived se ejecutan entre los servidores usando el protocolo VRRP, y si el asistente desaparece del radar (el servidor se reinicia o algo más, el servidor de respaldo automáticamente levanta esta dirección IP de sí mismo), no son necesarios pasos manuales. El maestro y la copia de seguridad difieren, principalmente la prioridad: cuanto más alto sea, más probable es que la máquina se convierta en un maestro. Una gran ventaja es que no es necesario configurar las direcciones IP en el servidor, es suficiente describirlas en la configuración, y si al mismo tiempo las direcciones IP necesitan algunas reglas de enrutamiento personalizadas, esto se describe directamente en la configuración, la misma sintaxis como se describe en paquete VRRP. No encontrarás cosas desconocidas.
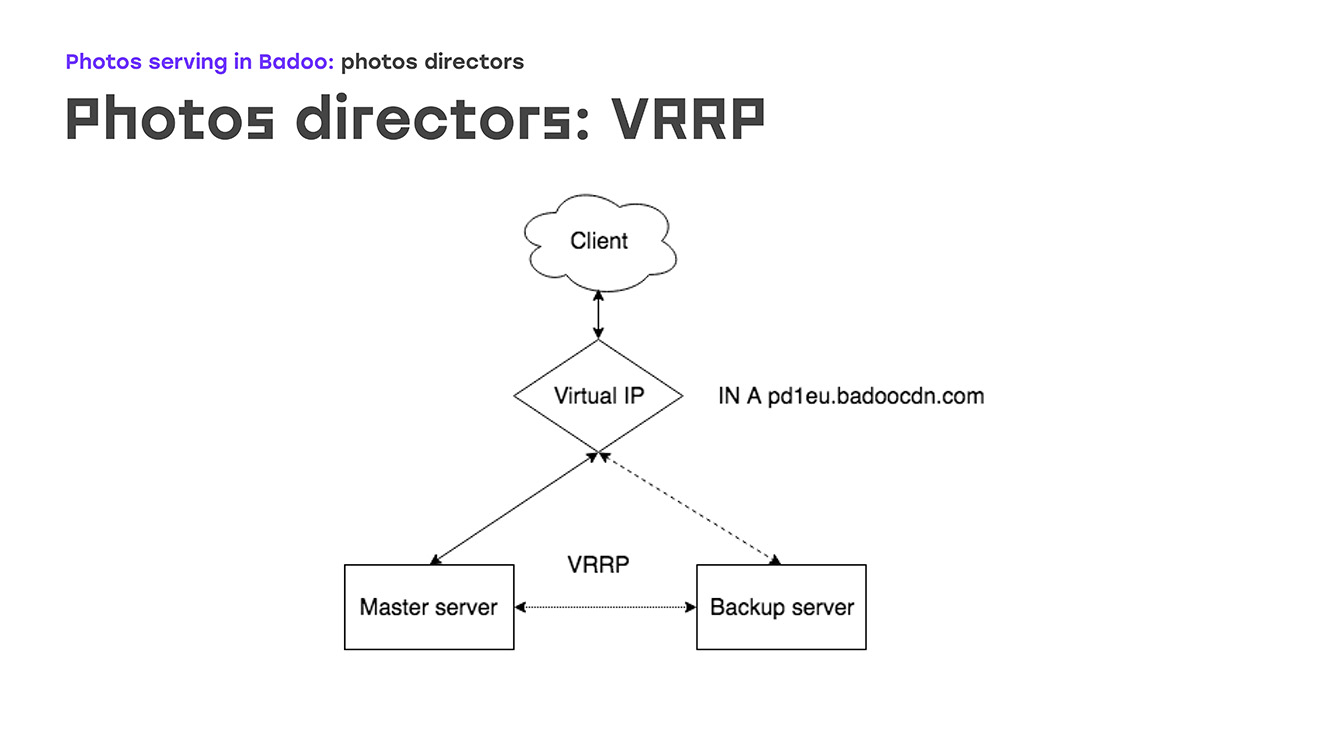
¿Cómo se ve en la práctica? ¿Qué sucede si uno de los servidores se cae? Tan pronto como el maestro desaparece, nuestro respaldo deja de recibir anuncios y automáticamente se convierte en maestro. Después de un tiempo, arreglamos el Keepalived maestro, reiniciado y levantado: las aventuras tienen una prioridad más alta que la copia de seguridad, y la copia de seguridad vuelve automáticamente, elimina las direcciones IP, no se requieren acciones manuales.

Por lo tanto, garantizamos la tolerancia a fallos de la dirección IP externa. La siguiente parte es equilibrar de alguna manera el tráfico a los enrutadores de fotos que ya lo terminan desde una dirección IP externa. Con los protocolos de equilibrio, todo está bastante claro. Este es un simple round-robin, o cosas un poco más complejas, wrr, conexión de lista, etc. Esto se describe en principio en la documentación, no hay nada especial. Pero el método de entrega ... Aquí nos detenemos en más detalles: por qué eligieron uno de ellos. Estos son NAT, enrutamiento directo y TUN. El hecho es que inmediatamente establecimos el retorno de 100 gigabits de tráfico de los sitios. Si esto se estima, necesita tarjetas de 10 gigabits, ¿verdad? Tarjetas de 10 gigabits en un servidor: esto ya está fuera del alcance de al menos nuestro concepto de "equipo estándar". Y luego recordamos que no solo estamos regalando algo de tráfico, estamos dando fotos.
¿Cuál es la característica? - La gran diferencia entre el tráfico entrante y saliente. El tráfico entrante es muy pequeño, el saliente es muy grande:
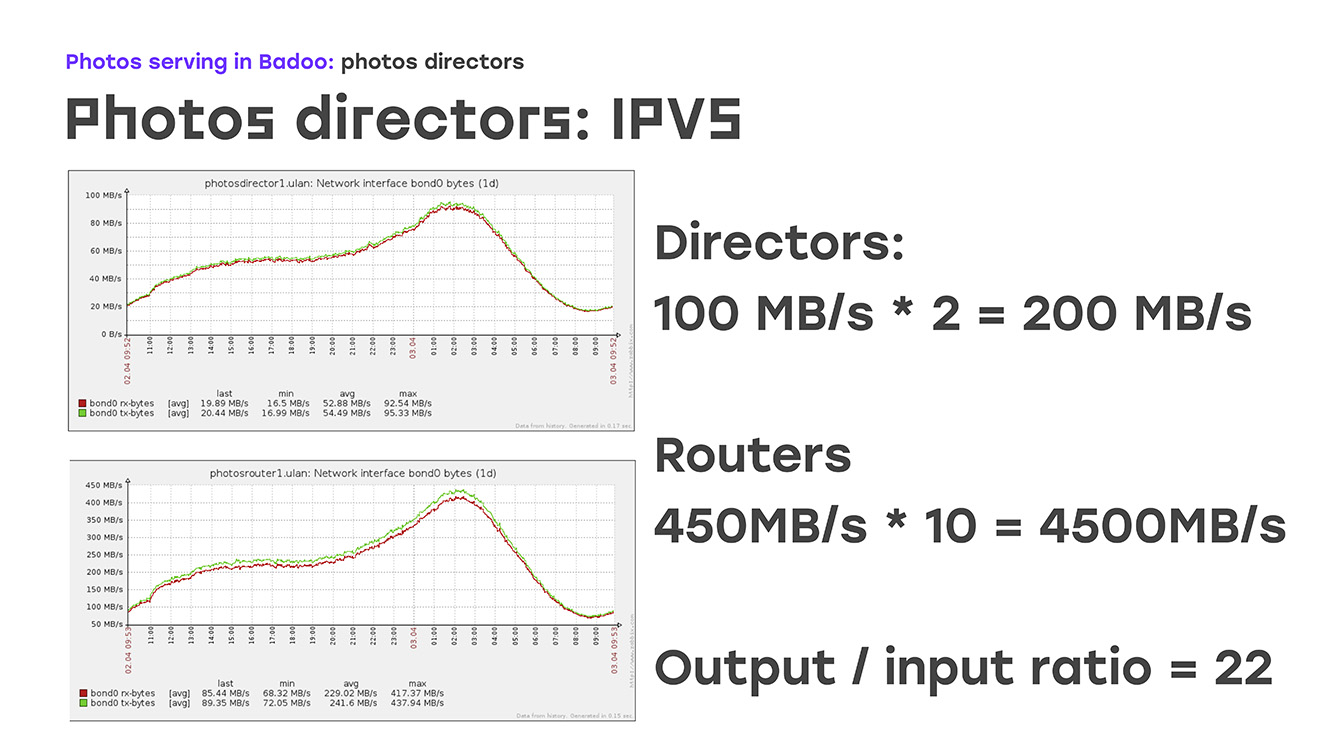
Si observa estos gráficos, puede ver que en este momento le llegan al director unos 200 MB por segundo, este es el día más común. Estamos devolviendo 4.500 MB por segundo, la relación es de aproximadamente 1/22. Ya está claro que para garantizar completamente el tráfico saliente a 22 servidores en funcionamiento, uno que acepte esta conexión es suficiente. Aquí el algoritmo de enrutamiento directo, el algoritmo de enrutamiento, viene en nuestra ayuda.
¿Cómo se ve? Según nuestra tabla, el director de fotos transfiere las conexiones a los enrutadores de fotos. Pero los enrutadores de fotos envían el tráfico de retorno directamente a Internet, lo envían al cliente, no regresa a través del director de fotografía, por lo tanto, con el número mínimo de máquinas, brindamos tolerancia completa a fallas y bombeamos todo el tráfico. En las configuraciones se ve así: especificamos el algoritmo, en nuestro caso es un simple rr, proporcionamos un método de enrutamiento directo y luego comenzamos a enumerar todos los servidores reales, cuántos tenemos. Lo que determinará este tráfico. En caso de que tengamos uno o dos servidores más allí, surge tal necesidad: solo agregamos esta sección en la configuración y no nos preocupamos realmente. Por parte de los servidores reales, por parte del enrutador de fotos, este método requiere una configuración muy mínima, se describe perfectamente en la documentación y no hay trampas allí.
Lo que es especialmente bueno: tal solución no implica una alteración radical de la red local, fue importante para nosotros, tuvimos que resolverla con gastos mínimos. Si observa el
resultado del comando de administración IPVS , veremos cómo se ve. Aquí tenemos un servidor virtual, en el puerto 443, escucha, acepta la conexión, se enumeran todos los servidores de trabajo y está claro que la conexión es la misma, más o menos. Si miramos las estadísticas en el mismo servidor virtual, tenemos paquetes entrantes, conexiones entrantes, pero absolutamente ninguna saliente. Las conexiones salientes van directamente al cliente. Bueno, pudimos desequilibrarnos. Ahora, ¿qué sucede si uno de los enrutadores de fotos falla? Después de todo, el hierro es hierro. Puede ir al pánico del núcleo, puede romperse, la fuente de alimentación puede quemarse. Cualquier cosa Para esto, se necesitan controles de salud. Pueden ser los más simples, verificando cómo se abre el puerto con nosotros, o algunos más complejos, hasta algunos scripts autoescritos que incluso verificarán la lógica comercial.
Nos detuvimos en algún punto intermedio: tenemos una solicitud https para una ubicación específica, se llama a un script si responde con la respuesta número 200, creemos que todo es normal con este servidor, que está en vivo y que puede encenderlo con bastante calma.
Cómo, de nuevo, se ve en la práctica. Apague el servidor, digamos para el servicio: BIOS parpadeante, por ejemplo. En los registros, inmediatamente tenemos un tiempo de espera, vemos la primera línea, luego, después de tres intentos, se marca como "invertida", y simplemente se elimina de la lista.

Hay un segundo comportamiento posible cuando simplemente VS se establece en cero, pero si se devuelve la foto, no funciona bien. El servidor se eleva, Nginx comienza allí, allí mismo, las comprobaciones de estado comprenden que la conexión pasa, que todo está bien, que el servidor aparece en nuestra lista y que la carga comienza a aplicarse automáticamente. Al mismo tiempo, no se requieren acciones manuales del administrador de turno. Por la noche, el servidor se reinició; el departamento de monitoreo no nos llama sobre esto por la noche. Informan que tal fue, todo es normal.
Entonces, de una manera bastante simple, utilizando una pequeña cantidad de servidores, resolvimos el problema de la tolerancia a fallas externas., , , . , Keepalivede, , , DBus, SMTP, SNMP, Zabbix'. , , , - , , , IP- . , , . nginx -, . , , : -, health-check' , , , , - - . - , amazon -, , , anomaly detection, , machine learning, , , , , , . .
: , , , - , , , HTTPS health-check'. , , , , , .
? 2018-. , , LTM, - 40 60 , 2018- .