AntipovSN y MihhaCF
Segunda parte, en la que Athos tiene todas las reglas, pero al Conde de la Fer le falta algo
UPD Part One está aquí
UPD parte tres aquí
Introducción de los autores:
Buenas tardes Hoy continuamos con la serie de artículos dedicados a la puntuación y al uso de la teoría de grafos en ella. Puede familiarizarse con el primer artículo aquí .
Todas las alegorías cómicas, inserciones, etc. están diseñadas para aliviar ligeramente la narrativa y no permitir que caiga en una tediosa conferencia. Pedimos disculpas a todos los que no entienden nuestro humor
El propósito de este artículo: en no más de 30 minutos, describir las principales formas de almacenar datos de gráficos y describir las reglas y principios para construir nuestro modelo para calificar a un prestatario.
Términos y definiciones:
- Una tabla hash es una estructura de datos que implementa una interfaz de matriz asociativa; le permite almacenar pares (clave, valor) y realizar tres operaciones: la operación de agregar un nuevo par, la operación de búsqueda y la operación de eliminar un par por clave. La búsqueda por tabla hash, en promedio, se lleva a cabo durante el tiempo O (1).
Los auditores contratados por Korol PJSC para evaluar la solvencia de One for All NPO encontraron algunos problemas. Por un lado, es muy sencillo describir el esquema de interacción de 10-15 empresas y realizar una evaluación inicial de la interacción entre empresas, es suficiente tener una hoja de papel y un bolígrafo a mano. Pero, ¿qué pasa si tiene información sobre la interacción de decenas o cientos de miles de empresas? Por ejemplo, si necesitas describir las interacciones de Aramis con todas sus pasiones o D'artagnan con todos con quienes peleó.
¿Cómo almacenar datos sobre estas interacciones?
¿Qué estructuras de datos y enfoques utilizar?
Los auditores tendrían que plantar todo un cuerpo monástico de escritores para este trabajo.
No haremos esto y les daremos a nuestros auditores el conocimiento y las tecnologías del futuro ( les enviaremos Prometheus en forma de T-800, lo que les dará la luz del conocimiento ).
Bueno, bueno, comencemos a responder las preguntas planteadas. ¡Que haya luz!
Como escribimos y dibujamos aquí , un gráfico es una relación de 2 conjuntos: un conjunto de nodos y un conjunto de bordes. ¿Cuál es la mejor manera de almacenar un gráfico?
Antes de responder a la pregunta de cómo almacenar el gráfico, debe decidir qué es exactamente lo que queremos almacenar y de qué forma.
De acuerdo con la teoría de grafos, los nodos de grafos pueden ser cualquier objeto con cualquier conjunto de parámetros (este hecho nos será útil más adelante, para modelos avanzados / adaptativos para calcular una bola de puntuación).
Entonces, ¿qué necesitamos para almacenar?
Como mínimo, el identificador del nodo y los identificadores de sus vecinos (con quienes está asociado). La presencia de estos datos ya le permite buscar en ancho y profundidad.
¿Necesito almacenar datos de borde de gráfico? Sí, si estamos tratando con un gráfico ponderado. En nuestro caso, estamos tratando con un gráfico ponderado y en el primer artículo dibujamos solo un gráfico de este tipo.
¿Es suficiente esta información? No
¿De dónde vienen las costillas? En los libros de texto, esta información simplemente está allí, alguien la ha recopilado y procesado antes que nosotros. A finales de la Edad Media (justo entonces vivían los mosqueteros) nadie se molestó en calcular el peso de los bordes de nuestro conde. Tenemos que hacerlo nosotros mismos. En este y en el próximo artículo, no describiremos la metodología específica para calcular el peso de una arista; esto se hará en el artículo 4. Ahora es importante para nosotros decidir qué información acerca de nuestro gráfico almacenaremos.
Entonces, en nuestro caso, hay tres parámetros clave que necesitamos saber para calcular correctamente el puntaje de puntuación:
- Una evaluación interna de un nodo: consta de indicadores que lo caracterizan (rotación, deuda, multas, etc.). En nuestro ejemplo, estos serán:
- Evaluación: un nudo bueno o malo en relación con NPO "Uno para todos";
- Rango de nodo: el Rey tiene el rango más alto, Bonacieux, el más bajo;
- El volumen de fondos, en otras palabras, solvencia.
- Evaluación de las costillas. En nuestro caso, la evaluación de la conexión será para cada nodo, esto significa que la relación Bonacieux - Constance puede no ser igual a la conexión Constance - Bonacieux, porque tienen diferentes posibilidades de influirse mutuamente.
- Nivel de nodo: no se almacenará, pero es un indicador importante.
No pregunte de dónde vienen todos estos números en el modelo, D'artanyan lo ve. En la vida real, tampoco calcularemos estos indicadores (comercio, deudas, multas, etc., tomamos de fuentes existentes, no estamos en la Edad Media, más o menos).
De todo lo anterior, resulta que, además de los identificadores de los nodos, debemos almacenar los parámetros de cada nodo y los pesos de los bordes que obtenemos en función de la agregación de los parámetros de los nodos.
Total, la siguiente información está sujeta a almacenamiento:
- Nombre de nodo;
- Parámetros de nodo
- Vecinos nodo;
- Peso de costilla para cada vecino.
Genial Descubrimos lo que necesitamos almacenar. Ahora, cómo almacenar.
Y de nuevo una pequeña digresión.
Cómo se verá nuestro proceso de puntuación de forma simplificada:
- Recogida de datos de objetos;
- Formación de un objeto que describirá el modelo gráfico. Es en esta instalación donde llevaremos a cabo todas nuestras operaciones de puntuación.
En base a estos dos pasos, tenemos tres opciones:
- Almacenamos datos sobre el objeto de puntuación en el servidor SQL / NoSQL. Todas las operaciones relacionadas con cálculos, algoritmos, etc. se llevan a cabo directamente en el servidor;
- Almacenamos datos sobre el objeto de puntuación en el servidor SQL / NoSQL. En base a estos datos, creamos un objeto separado (por ejemplo, una tabla hash) con el que realizamos todos los cálculos básicos;
- Los datos sobre el objeto de puntuación se almacenan en la RAM. En base a estos datos, creamos un objeto separado (por ejemplo, una tabla hash) con el que realizamos todos los cálculos básicos.
Requisitos básicos para este proceso:
- Velocidad de trabajo;
- Fiabilidad
- Verificabilidad
Ahora hablemos. Nos sentaremos, como nuestros mosqueteros sobre una taza de lo que bebieron allí, té, por ejemplo. Lo principal es que no interferimos con todo tipo de pollas con los guardias.
Si se necesita almacenamiento a largo plazo, puede seleccionar una tabla con los campos significativos correspondientes. En NoSQL o RAM, es mejor almacenar datos en forma de una lista o un directorio (tabla hash) de objetos.
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
Con los picos más o menos claros. ¿Cómo representar mejor los arcos / aristas de un gráfico? Para hacer esto, debe comprender el principio básico de cualquier operación analítica en el gráfico: el acceso a cualquier arco / borde debe ocurrir muy rápidamente, es deseable que el tiempo de acceso sea igual a O (1). Una matriz o matriz viene inmediatamente a la mente, una estructura en la que se puede acceder rápidamente a cualquier elemento por índice.
[i, j]: el elemento de matriz denota el arco del gráfico, donde i es el identificador del vértice inicial, j es el identificador del vértice final, el acceso y la selección del vértice inicial se produce directamente por el identificador del vértice inicial. La intersección de i y j almacena el peso del borde.
Hay varios inconvenientes en esta vista:
- A menudo, la estructura es redundante, especialmente si el gráfico es escaso (un pequeño número de bordes), hay muchos valores vacíos que indican que no hay conexión.
- Para encontrar todos los vecinos del vértice, es necesario ordenar la matriz de todos los elementos de la i-ésima fila de la matriz de relación.
- Una matriz con muchas columnas no se puede almacenar en la base de datos.
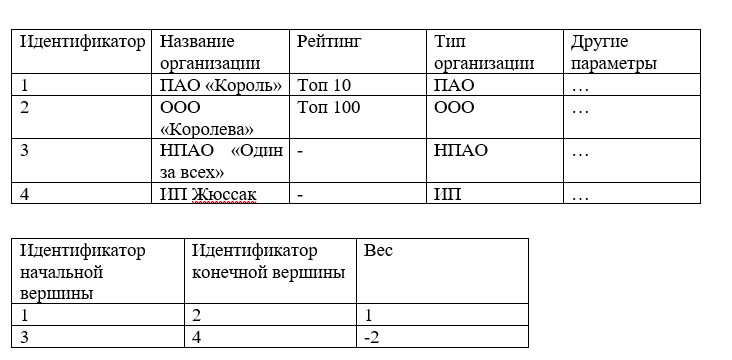
La siguiente opción para almacenar arcos / aristas es una tabla, es decir, un conjunto de columnas y filas.
Por ejemplo:

Dicha estructura se puede almacenar fácilmente en una base de datos relacional y, al ejecutar consultas SQL, puede seleccionar los valores necesarios, pero cuando se trata de RAM, la complejidad de encontrar todos los bordes del vértice aumenta y, en el caso general, toma O (n) donde n es el número de todos los bordes del gráfico.
Existe otro muy buen método de almacenamiento de gráficos para usar en casi todos los sistemas, sin los inconvenientes descritos anteriormente: esta es una referencia de valor clave o tabla hash. La obtención de todos los bordes del vértice deseado ocurre con la velocidad O (1).
Una desventaja significativa es que no todos los lenguajes de programación admiten este diseño.
¿Cómo se puede imaginar una estructura similar en diferentes sistemas?
En la base de datos relacional, puede implementar la relación de las tablas de objetos y aristas (párrafo anterior)
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
Al acceder a un objeto por su clave, obtenemos inmediatamente un conjunto de sus conexiones. Si tenemos un gráfico no ponderado, en lugar de una matriz de objetos, puede pasar una matriz de identificadores de vecinos Relaciones: [3,4, ... n]. En forma de referencia, la clave es el valor, esta opción es similar a la anterior. En el directorio, el valor clave, puede almacenar el mismo objeto que en el ejemplo anterior, la clave, por supuesto, será el identificador del vértice (puede haber un número, puede haber una cadena, etc., que permite un sistema de desarrollo particular). También en el directorio solo puede almacenar matrices de enlaces e información sobre los vértices en otro directorio.
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
o
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
Para nuestro ejemplo, elegimos la opción de almacenar datos en RAM con la creación de una tabla hash para puntuar datos. Los resultados intermedios se escribirán en un archivo en el servidor.
Tenemos estructuras de almacenamiento mal y mal definidas, ahora es el momento de averiguar dónde comenzar a construir nuestro modelo analítico. Comencemos con uno simple: definimos la interacción con los vecinos más cercanos y con los vecinos de los vecinos (amigos de amigos).
Por lo tanto, es posible determinar la interacción con todos los vértices interconectados. Según nuestras observaciones, la interacción con vecinos más profundos que el nivel 2 es de interés solo en casos especiales y se calcula por otros métodos. La complejidad de este cálculo es bastante grande 0 (2 ^ n).
Para calcular la pelota, utilizaremos un algoritmo de búsqueda de profundidad ligeramente modificado.
El refinamiento será el siguiente:
- Necesitamos encontrar no un vértice específico, sino clasificar todos los vértices a una profundidad de n, para nuestra tarea n = 2.
- No debemos almacenar información innecesaria y debemos suponer que el cálculo puede hacerse para cualquier nodo en el gráfico, por lo que el nivel del nodo no se almacenará en el gráfico.
- Si 2 o más rutas conducen a la parte superior, entonces todas las rutas se evalúan, porque Estamos tratando con comunicaciones bidireccionales y es necesario evaluar completamente la interacción de los nodos.
- Debe poder determinar el nivel de anidamiento de cualquier vértice para un cálculo específico.
Bueno, bueno, los cálculos teóricos básicos se han hecho, incluso si a alguien le parecen algo simple y banal. Pero para nosotros, los Gascons, todo esto es importante e interesante, casi lo mismo que ingresar a los Royal Mosqueteros.
Pasamos a la implementación práctica. ¡Uno para todos y todos para uno!
Nos vemos! Definitivamente nos encontraremos! ¡Quizás en 10 años o 20! Pero conoce!
¡El próximo artículo está cerca!