
En un
artículo anterior
, conté una breve historia del desarrollo de productos internos y externos de DublGIS. Hoy nos sumergimos en los detalles del desarrollo de uno de los productos, a saber, la exportación de datos. Hablaré sobre la arquitectura del proyecto y las soluciones técnicas individuales que nos permitieron desarrollar gradualmente el proyecto y adaptarlo a los requisitos cambiantes con el tiempo.
Un breve resumen del último artículo.
Hay varios productos internos que recopilan grandes cantidades de datos de mapas, un directorio de organizaciones, publicidad, comentarios de los usuarios, reseñas, fotos, diversos análisis. Estos productos se comunican entre sí a través del bus de datos o a través de Rest Api. Y hay un proceso de exportación separado que recopila todos estos datos en un montón, los procesa y descompone en el formato deseado, los empaqueta y forma un "paquete" listo para su entrega a sus productos finales. La entrega se realiza a través del servidor de actualización para PC y versiones móviles, o en el backend en línea para, de hecho, la versión en línea de 2GIS.
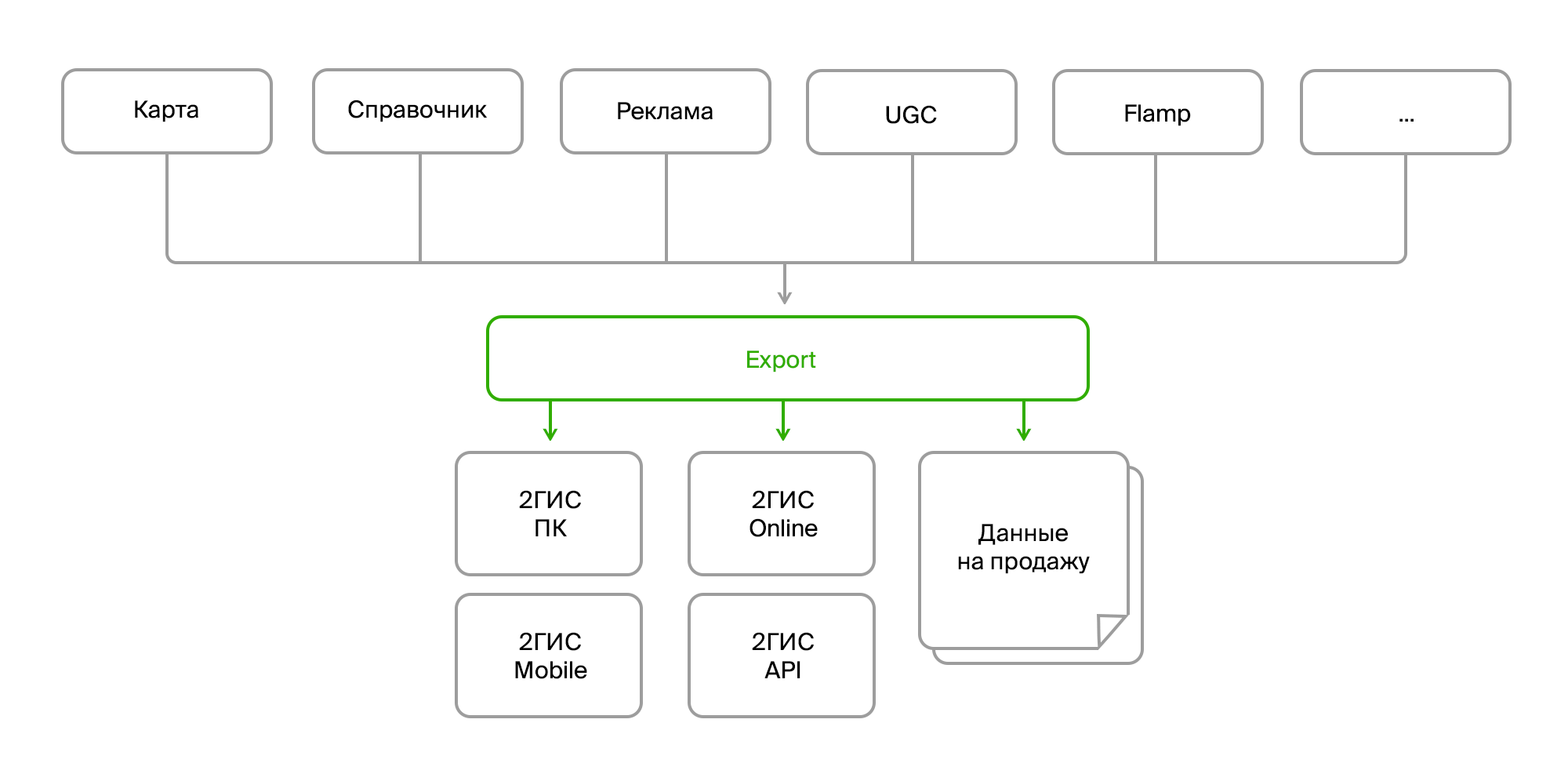
Datos de origen
Entonces, en la entrada tenemos:
- varias fuentes de los mismos datos;
- diferentes métodos de entrega (Firebird, bus, FTP, RestAPI);
- estructura diferente de los mismos objetos;
- cambios constantes en la estructura de datos;
- diferentes formatos (datos en bruto en la base de datos, XML, JSON).
Desde el punto de vista del consumidor:
- nuevamente, diferentes formatos (sus formatos de datos para diferentes versiones del producto, formatos separados para la venta);
- cambios constantes de formato;
- datos agregados (necesita combinar diferentes objetos en uno, recopilar datos sobre la empresa de todas las sucursales, complementarlos con enlaces a fotos, reseñas, paradas más cercanas, etc.);
- preprocesamiento y posprocesamiento complejos (actualizar algunos datos sobre la base de otros, convertir datos, generar datos faltantes, por ejemplo, organizar mini logotipos publicitarios en edificios, eliminar o corregir datos erróneos);
- coherencia de datos y requisitos de validez;
- TODOS los datos son necesarios.
Aquí vale la pena centrarse en el último párrafo. Como sabes, la característica principal de 2GIS es el trabajo fuera de línea. Es decir, la mayoría de los datos que ve en nuestra PC y versiones móviles se encuentran en su dispositivo. Pero esta es una gran variedad: cientos de miles de objetos geográficos (mares, bosques, ríos, carreteras, edificios, entradas, porches, firmas, planos de planta, modelos 3D), decenas y cientos de miles de empresas y sus sucursales con contactos, horas de trabajo, atributos adicionales como la factura promedio y la disponibilidad de Wi-Fi. Y, por supuesto, textos publicitarios y fotos.
Y todo cambia constantemente, se agrega, se elimina.
Y para no ahogarnos en este flujo interminable de cambios, al desarrollar la arquitectura de exportación, tuvimos que centrarnos en varias áreas principales:
- fuentes de datos;
- métodos de entrega;
- algoritmos de procesamiento;
- formatos de datos del consumidor.
Extraemos de diferentes fuentes y formatos de datos.
Diferentes fuentes presentan las siguientes dificultades:
- dan los mismos datos en diferentes formatos;
- tener un conjunto diferente de entidades o atributos que deben reducirse a un solo objeto de dominio.
Este es un problema bastante estándar y se resuelve como estándar. Solo necesitamos crear una interfaz para recibir datos, y una implementación específica ya está yendo a donde se necesita y obtendrá los datos en la forma que necesitamos.

Ejemplo de interfaz:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
Un ejemplo de la implementación de la obtención de empresas:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
Esta abstracción en parte nos permite resolver el problema con diferencias en el modelo de dominio, pero no completamente. Una limitación importante es la necesidad de recibir datos de forma incremental, es decir, recibir solo sus actualizaciones y no absorber todo el proceso cada vez. En este caso, es bastante inconveniente rastrear la relación entre los datos para recopilar algunos agregados. Y es relativamente difícil hacer todo sin errores. Por lo tanto, decidimos que en esta etapa extraeremos los datos de las fuentes uno a uno y resolveremos el problema con el modelo de dominio a un nivel diferente.
Modelo de dominio
Para no depender de los cambios en el conjunto de datos y su estructura en las fuentes de datos, la base de datos de exportación se realizó con una lista relativamente estable de tablas, que finalmente cayeron en nuestro dominio. Si la fuente 1 carecía de algunos atributos para la entidad A (Objeto de datos en la siguiente imagen), entonces recibieron un valor predeterminado o fueron opcionales. Y si la entidad B era algún tipo de agregado de datos fuente o incluso fuentes diferentes, entonces cada parte podría obtenerse por separado y luego ensamblarse como un todo en la siguiente etapa.

Hacemos un resumen del método de entrega de datos.
De hecho, tener su propia base de datos en la exportación y la apariencia de la interfaz
ISourceReader ya resuelve este problema. Pero hay un punto sin resolver: modelos de adquisición de datos ligeramente diferentes. En un caso, extraemos y obtenemos una instantánea en el momento actual, en el otro, deltas de cambios en el bus, en el tercero, también el estado actual en el momento de la solicitud, pero con información sobre los objetos eliminados desde el momento de la solicitud anterior.
Para brindar uniformidad a este zoológico, agregaremos una base de datos más a la que fusionaremos todos los datos de todas las fuentes.
Tienes una foto así.
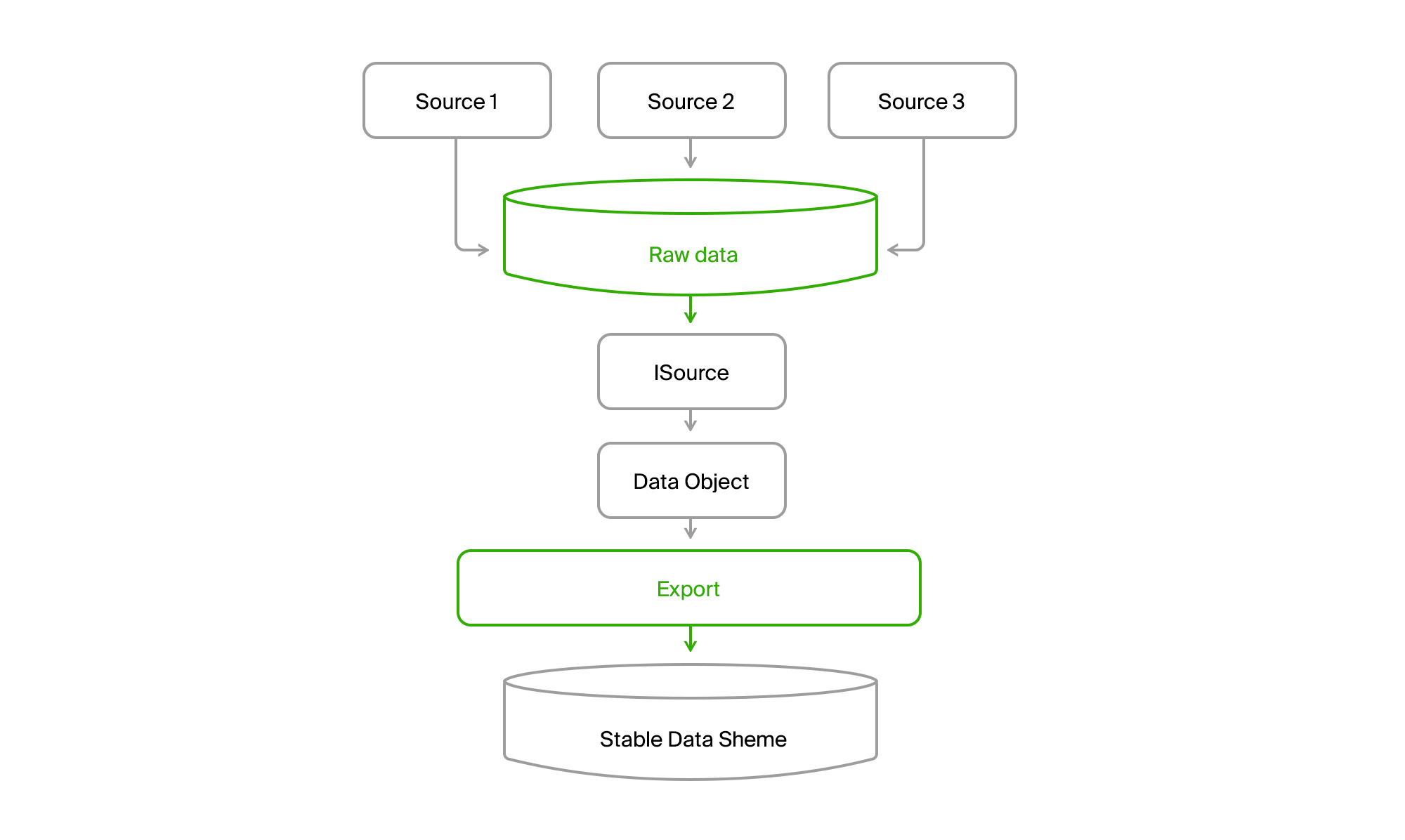
Como resultado, leemos todos los datos de cualquier canal en todas las ciudades a la base de datos central. Casi siempre la entrega es incremental, es decir, solo se producen cambios. El viejo DGPP, mientras estaba vivo, seguía siendo una fuente alternativa. Pude bombear datos de un DBMS a otro no había ninguno.
Además, la exportación a través de ISource extrajo los datos de la ciudad de DGPP o EMDB a su base de datos de sincronización estable y los convirtió en su modelo de dominio.
Entonces solo queda procesarlos y subirlos en formatos de consumidor.
Resumen de algoritmos de preparación de datos
Y aquí surge una dificultad más. En primer lugar, diferentes consumidores quieren datos en sus formatos. Además, quieren diferentes conjuntos de datos. Y en el apéndice, los datos fuera de línea deben ser lo más compactos y estructurados posible para que puedan leerse rápidamente. Como resultado, obtenemos formatos binarios que son desarrollados por los equipos de productos finales. Y estos son tipos que trabajan en una pila de tecnología completamente diferente. Tenemos los conocidos y amados para desarrollar el backend .NET y, a veces, Java, principalmente tienen C ++ y python.
En general, un zoológico de tecnología.
En los albores del rápido desarrollo, cuando solo teníamos DGPP (ver el
artículo anterior) y la versión para PC de 2GIS, el formato de los datos finales era un binario, que fue preparado por una biblioteca especial escrita en C ++ y envuelta en un objeto COM. Parecería que no la integración de código heterogéneo. Conectamos la referencia, se genera la interfaz .NET y la manejamos. Y la primera vez que lo hicimos.
Pero, como de costumbre, aparecieron un par de problemas.
- Nuestros datos comenzaron a crecer rápidamente. Aparecieron nuevos tipos de datos, nuevas grandes ciudades como Moscú.
- Los sistemas operativos X64-bit comenzaron a extenderse activamente.
- Los problemas en COM necesitaban ser depurados de alguna manera.
Veamos los puntos.
El crecimiento de los datos que nuestros productos necesitan por completo ha llevado al hecho de que su procesamiento comenzó a consumir una gran cantidad de RAM. Y después de haber conectado la biblioteca COM a nuestro proceso .NET x86, recibimos automáticamente el proceso x86, es decir, un máximo de operativos de 3Gb con mayor espacio de direcciones. Los equipos no tenían soporte de biblioteca para recursos x64, pero la biblioteca en sí tenía la capacidad de usar el disco en lugar de la memoria, lo que mitigaba el problema.
Pero la depuración seguía siendo muy difícil. Era necesario comenzar la exportación, esperar a que prepare los datos, comenzar a agregar estos datos a la biblioteca. Y después de que aparezca el error, debe comprender en los registros qué salió mal y repetir el proceso nuevamente. No bien, muy mal.
La solución es la habitual en la superficie. Es suficiente llevar todo el código externo a un proceso separado y establecer la comunicación a través de archivos intermedios en un formato binario o de texto simple.
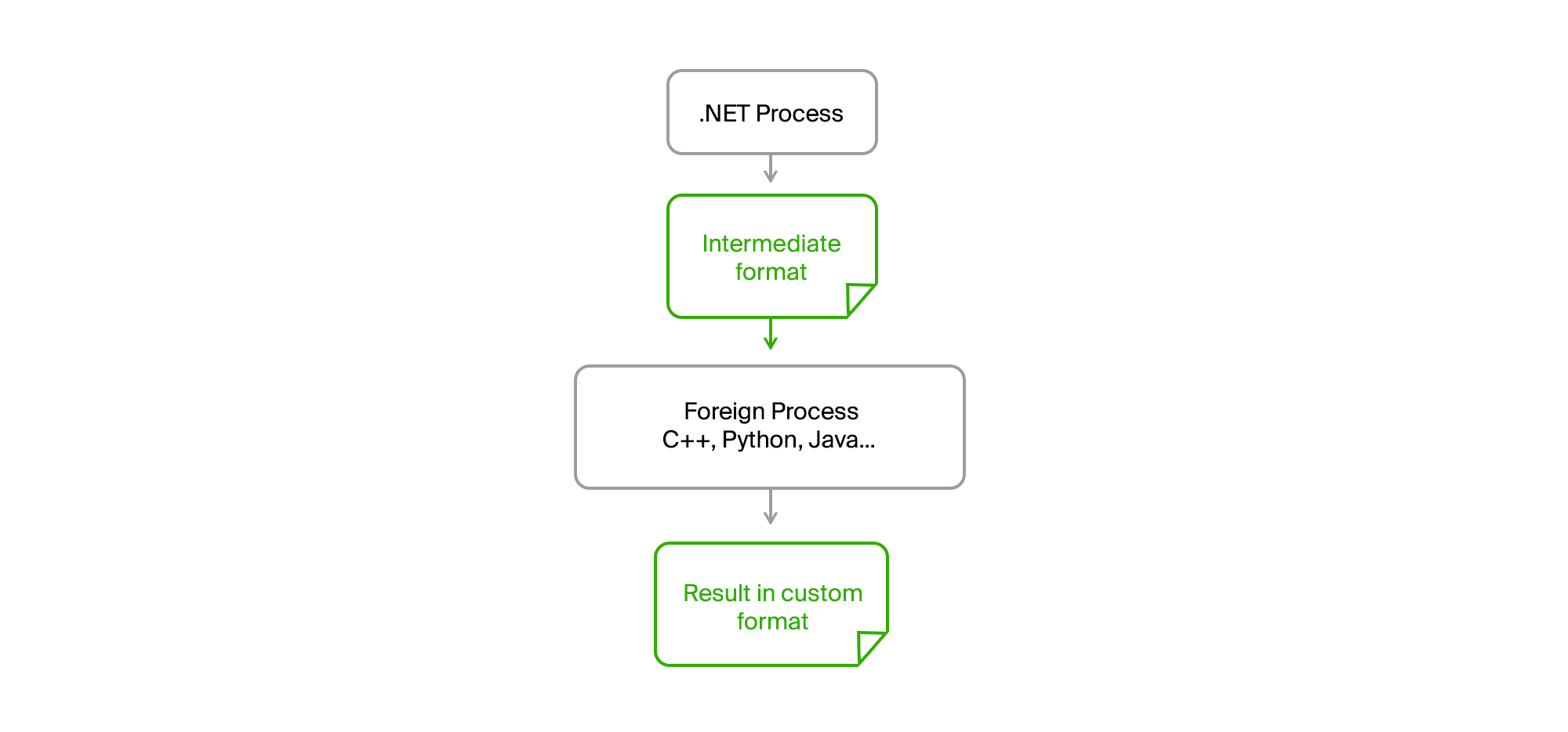
Como resultado, nuestro proceso original .NET se convirtió completamente en cualquier CPU. No hay fugas de memoria o errores críticos en el código de terceros que ya no lo afectan. La exportación preparó los datos, los cargó en un archivo intermedio, los alimentó a la utilidad y recibió el resultado de ellos también en forma de archivo. Los chicos de equipos de terceros escribieron sus algoritmos en sus propios lenguajes (C ++ o Python) y pudieron depurarlos en datos reales en caso de errores en su máquina sin la necesidad de comenzar a exportar.
Solo teníamos que formar acuerdos en la interfaz de la utilidad, que se proporcionaba con el tiempo de ejecución, tenía una lista acordada de los parámetros requeridos y mostraba mensajes informativos y errores en stdout en el formato requerido.
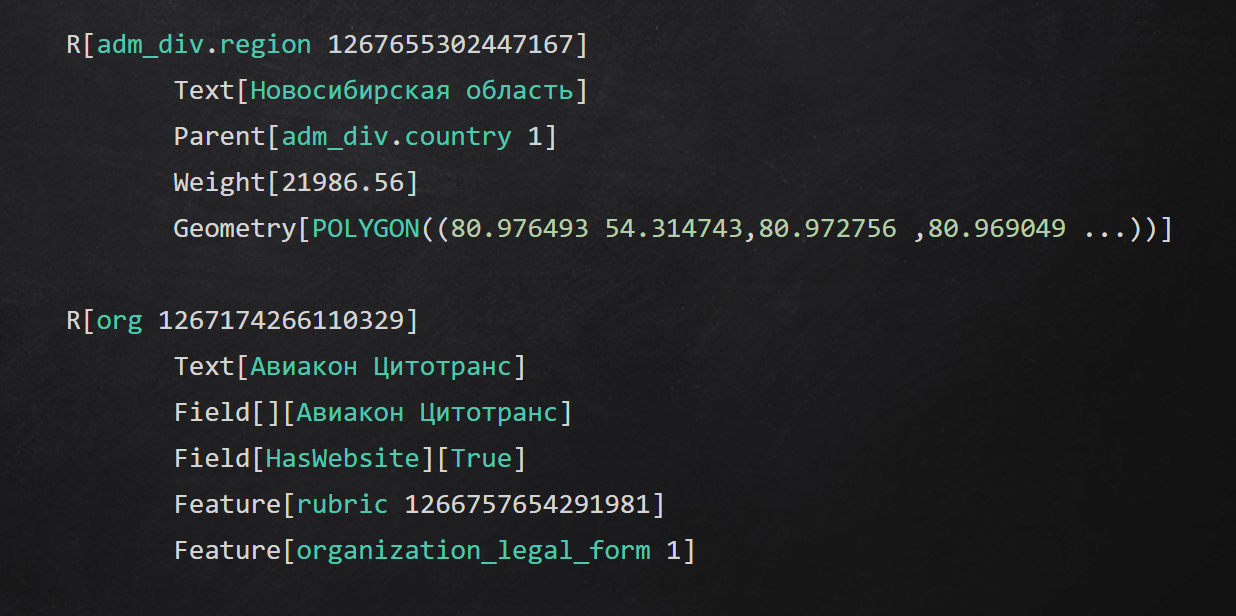 Ejemplo de formato de texto intermedio
Ejemplo de formato de texto intermedioResumen
En el artículo, hablé sobre algunos enfoques que utilizamos en diferentes niveles de la aplicación para aislar el proceso de preparación de datos:
- ocultó detalles de acceso a fuentes de datos detrás de interfaces;
- abstraído de los canales de entrega de datos utilizando almacenamiento intermedio;
- crea tu dominio estable y convierte los datos originales en él;
- llevó a cabo etapas individuales de procesamiento de datos en procesos y utilizó código en otros idiomas.
Gracias por llegar al final. Contestaré todas las preguntas en los comentarios, asegúrese de preguntar.