Este artículo describe el proceso de analizar la oración del idioma ruso utilizando la gramática libre de contexto y el algoritmo de análisis LR.
El procesamiento del lenguaje natural es la dirección general de la inteligencia artificial y la lingüística matemática. Estudia los problemas de análisis informático y síntesis de lenguajes naturales.
En general, el proceso de análisis de oraciones en lenguaje natural es el siguiente: (1) dividir oraciones en unidades sintácticas: palabras y frases; (2) determinación de los parámetros gramaticales de cada unidad; (3) la definición de la relación sintáctica entre unidades. El resultado es un árbol de análisis abstracto.
1. División de oraciones en unidades sintácticas
Una oración en lenguaje natural consiste en formas de palabras y frases fuertes. Una serie de formas de palabras de una palabra dada se llama paradigma.
Por ejemplo
"": [, , , , , ]
Las frases (conjunciones compuestas, predicados o expresiones estables) no cambian y no pueden descomponerse en unidades más pequeñas sin pérdida de significado. Además, por una palabra nos referimos a cualquier unidad sintáctica: una forma de palabra o una frase.
Cada palabra en una oración está determinada por un triple:
- forma de palabra / cadena de palabra ("escribió")
- forma normal de la palabra ("escribir")
- un conjunto de parámetros gramaticales (['VERBO', 'cantar', 'musc', 'tran', 'pasado'])
Por lo tanto, el desglose de la frase "
Claramente, él no asistirá a la reunión " será el siguiente:
[' ', '', '', '', '', ''] ' ' - ,
2. Definición de parámetros gramaticales (grammems)
Un gramo es un elemento de una categoría gramatical; Los diferentes gramos de la misma categoría son mutuamente excluyentes y no se pueden expresar juntos. Para cada forma de palabra, definimos un conjunto de siete gramos:
[ , , , , , , ]
Como fuente, utilizaremos el diccionario
OpenCorpora y su interfaz,
pymorphy2 . Para buscar una regla en la gramática para un conjunto dado de gramos, los presentaremos en forma general:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. Definición de la relación sintáctica entre palabras.
Para determinar la relación sintáctica entre palabras, utilizaremos gramática y análisis LR sin contexto.
Gramática y Análisis LR
La gramática formal es una forma de describir un lenguaje en forma de las llamadas producciones. Por ejemplo:
a -> ab | ac
significa la regla 'a' genera 'ab' O 'ac'.
Los no terminales son objetos que denotan cualquier esencia del lenguaje (oración, fórmula, etc.).
Terminales : objetos directamente presentes en el lenguaje correspondiente a la gramática y que tienen un significado específico e inmutable (letras, palabras, fórmulas, etc.). Las gramáticas sin contexto son gramáticas en las que los lados izquierdos de todos los productos son no terminales individuales.
Para describir el idioma ruso, usaremos la teoría de la gramática de componentes (
gramática de estructura de frases ), que afirma que cualquier unidad gramatical compleja consta de dos unidades más simples y no intersectantes, llamadas sus componentes inmediatos. Se distinguen los siguientes componentes:
(1) Grupo nominal (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
Es decir, una frase nominativa nominativa es un sustantivo en el caso nominativo O un adjetivo en el caso nominativo + una frase nominativa nominativa u otra.
(2) Grupo verbal (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
En otras palabras, un grupo de verbos transitivos es un verbo transitivo + un grupo de sustantivos ablativos O un adjetivo corto + grupo de verbos transitivos O otro.
(3) Grupo preposicional (PP) PP -> PREP NP[case='datv'] | ...
Un grupo preposicional es una preposición + un grupo dativo nominal u otro.
(4) Oferta completa (S) S -> NP[case='nomn'] VP[tran]
Existe una oración completa si y solo si los grupos de sustantivos y verbos coinciden en número, persona y género.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
Una oración incompleta es una oración donde se omite la parte nominal. Como regla, en tales oraciones el grupo de verbos se expresa mediante un verbo impersonal. Por ejemplo, "
Quiero caminar ", "Se está
poniendo ligero ". Una oración elíptica es una oración donde se omite la parte del verbo, se reemplaza por un guión. Por ejemplo, "
Detrás de la espalda hay un bosque. A la derecha y a la izquierda hay pantanos ".
Para determinar si esta oración pertenece al lenguaje gramatical, utilizaremos el algoritmo de análisis LR. Este algoritmo implica la construcción de un árbol de análisis desde abajo hacia arriba (desde las hojas hasta la raíz). El elemento clave del algoritmo es el método de "transferencia-convolución" (inglés
shift-reduce ):
(1) leemos los caracteres de la línea de entrada hasta que haya una cadena que coincida con el lado derecho de cualquiera de las reglas, colocamos la cadena encontrada en la pila (transferencia);
(2) reemplace la cadena encontrada por la regla de la gramática (convolución).
Si se han envuelto todas las cadenas de cadenas, entonces esta oración pertenece al lenguaje gramatical y existe al menos un árbol de análisis.
ArbolPara representar la conexión sintáctica, la oración usa un árbol binario, donde las hojas son palabras (terminales) con un conjunto de gramos, y los nodos son reglas (preterminales). La raíz es la oración (no terminal).
Un nodo de árbol se define de la siguiente manera:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
La construcción de un árbol comienza con las hojas, a las que se les asigna una cadena de palabras o frases, así como un conjunto de sus gramos.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
A continuación, se realiza el análisis LR. Cada convolución corresponde a la unión de dos nodos u hojas bajo un ancestro común. A un nodo ancestro se le asigna una etiqueta preterminal que corresponde a la regla gramatical, además, el ancestro acepta gramáticas del miembro principal del grupo, por ejemplo, en el grupo de verbos V [tran] PRCL (por ejemplo,
"me gustaría" ) los signos se tomarán del verbo transitivo V [tran], y no de una partícula de PRCL; y en el grupo de sustantivos NP [caso = 'nomn'] NP [caso = 'gent'] (por ejemplo,
"padre de niños" ) los signos se tomarán del sustantivo en el nominativo.
Es importante tener en cuenta que la convolución ocurre en el orden establecido:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
Este orden es importante porque excluye la posibilidad de "perder" algunos miembros de la propuesta. Primero, los adjetivos se forman junto con modificadores (por ejemplo,
increíblemente hermosos ), luego grupos nominales, preposicionales y finalmente verbales. Después de eso, hay una búsqueda de oraciones completas / incompletas, si no hay ninguna, entonces el árbol no tiene una raíz y, por lo tanto, la oración no pertenece al lenguaje gramatical.
Considere un ejemplo condicional de construir un árbol:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
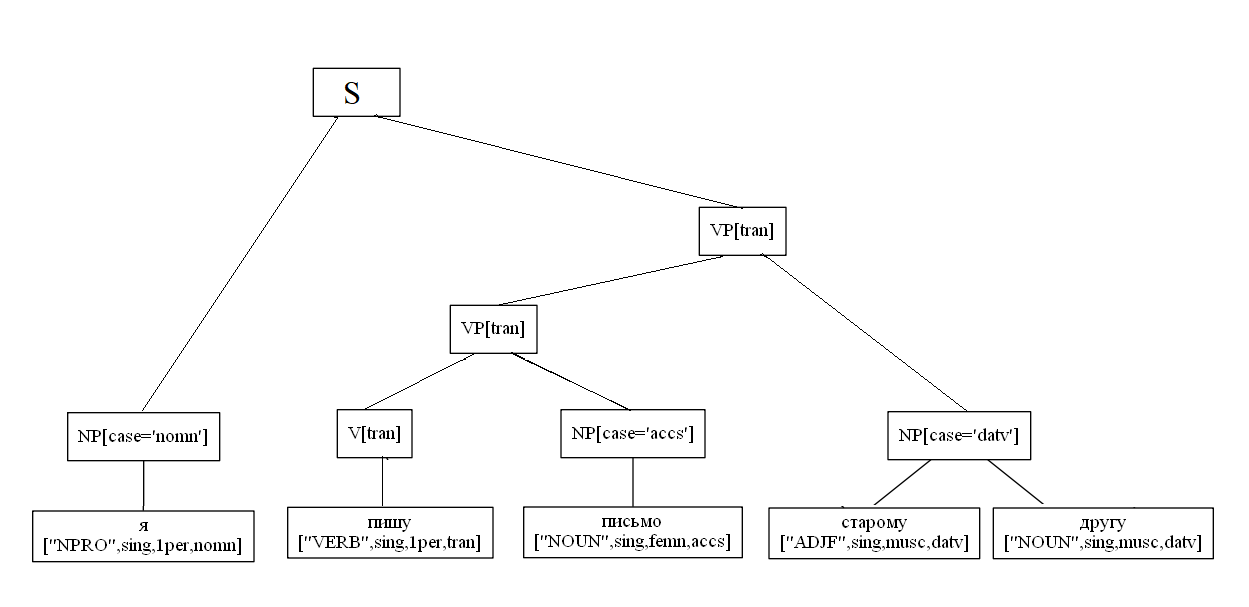
Un ejemplo específico de analizar una oración de dos partes:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
Los problemas
El lenguaje natural es ambiguo, su comprensión depende de una serie de factores: de las características de la estructura gramatical del idioma, de la cultura nacional, del hablante, etc. Enumeramos los principales problemas del procesamiento del lenguaje de máquina.
- Divulgación de anáfora. Una persona viva comprende la anáfora basada en el sentido común y el contexto, pero para una computadora esto obviamente no siempre es fácil.
- La homonimia es una coincidencia en el sonido y la ortografía de las unidades lingüísticas cuyos significados no están relacionados entre sí. Una solución son los métodos probabilísticos. En la oración " Sé esto bien " , la probabilidad de que " esto " sea un pronombre y no una partícula será mayor. Dichos métodos requieren un recinto suficientemente grande.
- El orden libre de las palabras lleva al hecho de que la interpretación de la oración puede ser ambigua. Por ejemplo, "El ser determina la conciencia ", ¿qué determina qué? En ruso, el orden de las palabras libres se compensa con la morfología desarrollada, las palabras de servicio y los signos de puntuación, pero en la mayoría de los casos para la computadora esto presenta un problema adicional.
- No todas las personas escriben correctamente. En la red, las personas tienden a usar abreviaturas, neologismos, elipses y otras cosas que pueden contradecir la norma literaria. Debido a esto, el uso de gramáticas y diccionarios sin contexto no siempre es posible.
Conclusión
El proyecto
está disponible para su uso y edición. Contiene el analizador en sí, el árbol de análisis, así como la gramática rusa y la gramática del idioma ruso y un pequeño diccionario de uniones compuestas y predicados que no están en el diccionario OpenCorpora. Por el momento, para oraciones largas y complejas, el analizador puede encontrar 3 o más árboles, para resolver este problema, se realizan cambios en la gramática y también se planea utilizar métodos probabilísticos.