A menudo sucede que vienes a la máquina y encuentras algún tipo de script que se ejecuta bajo el usuario del sistema hace una semana. ¿Quién lo lanzó? ¿Dónde buscar este run.php? O agrega una entrada a / etc / crontab, y el script falla allí con el error "comando no encontrado". Por qué Y que hacer
Tengo las respuestas a estas preguntas.

Variables de entorno
En casi todos los sistemas operativos modernos, los procesos tienen variables de entorno. Técnicamente, son una colección de cadenas con nombre. Si se inicia un subproceso, automáticamente hereda una copia del entorno del padre.
Entre otros, está la variable PATH, que indica las rutas para buscar archivos ejecutables, la variable HOME, que apunta al directorio de inicio del usuario, las variables responsables de las preferencias de idioma del usuario y muchos otros.
Hay muchas revisiones que describen el significado de estas variables, pero prácticamente no hay artículos sobre cómo investigar problemas. Llena este vacío.
¿Quién comenzó el proceso?
Entonces, encontramos una secuencia de comandos que se ejecuta bajo el usuario del sistema hace una semana. ¿Quién lo lanzó? Por qué ¿Quizás se olvidaron de él? Potencialmente 10-15 personas podrían lanzarlo, no entrevistará a todos. ¿Cómo encontrar quién era? ¿Y dónde está esto run.php mentir?
$ ps x | grep run.php 10684 ? Ss 472:25 /local/php/bin/php run.php
Las variables de entorno del proceso y la función sudo vienen al rescate. Existe una variable PWD en la que el shell almacena el directorio de trabajo actual; este valor, de hecho, guarda información sobre el directorio actual en el momento en que se ejecuta el comando. Además, la utilidad sudo por defecto deja información en la variable de entorno del proceso sobre el usuario desde el que se inició.
Las variables de entorno (y mucho más) para cualquier proceso en ejecución se pueden encontrar en / proc. Voila
$ cat /proc/10684/environ | tr '\0' '\n' | grep SUDO_USER SUDO_USER=alexxz $ cat /proc/10684/environ | tr '\0' '\n' | grep PWD PWD=/home/etlmaster
Ejem, lo lancé yo mismo. Bueno, ¿a quién no le pasa?
En general, utilizando un método tan simple en situaciones simples, puede encontrar información sobre el proceso, que generalmente no está disponible.
El script funciona desde la línea de comando, pero no funciona desde cron
Uno de los casos en los que debe pensar en las variables de entorno es cuando un script agregado a / etc / crontab se bloquea con un error. Vas al servidor a través de SSH, ejecutas el comando, todo parece funcionar como debería. Y cuando se inicia automáticamente, muestra algo como "colmena: comando no encontrado".
En general, es una buena práctica escribir la ruta completa a los comandos ejecutables, pero esto no siempre es posible. En tales casos, los desarrolladores salen como cualquiera puede. Alguien agrega la ruta deseada en PATH como parte del equipo en crontab. Los más experimentados envuelven su comando en bash -l. Y las bombas de cuervo enseñadas por la amarga experiencia aún no se olvidan de acudir en masa. Todo es así: hecho, agregado a la supervisión y olvidado.
Después de tales manipulaciones, queda un sedimento en el alma de un verdadero ingeniero. Sí, el problema está resuelto. ¡Pero no entendí lo que estaba pasando! ¿Cómo es un enfoque mejor que otro? ¿Dónde se almacenan todas estas configuraciones y por quién se cambian?
Comparemos las variables de entorno que tiene el proceso cuando se inicia desde la corona y las variables de entorno que tenemos en la línea de comando. Registramos la salida del comando env desde la corona y nuestro entorno actual:
$ echo "* * * * * env > ~/crontab.env" | crontab; sleep 60; echo "" | crontab; $ env > my.env
Mira lo que hay en la variable PATH:
> grep ^PATH= crontab.env my.env Crontab.env: PATH=/usr/bin:/bin My.env: PATH=/local/hive/bin:/local/python/bin:/local/hadoop/bin:/local/hadoop/bin:/local/hive/bin:/local/hadoop/bin:/usr/local/bin:/usr/bin:/bin
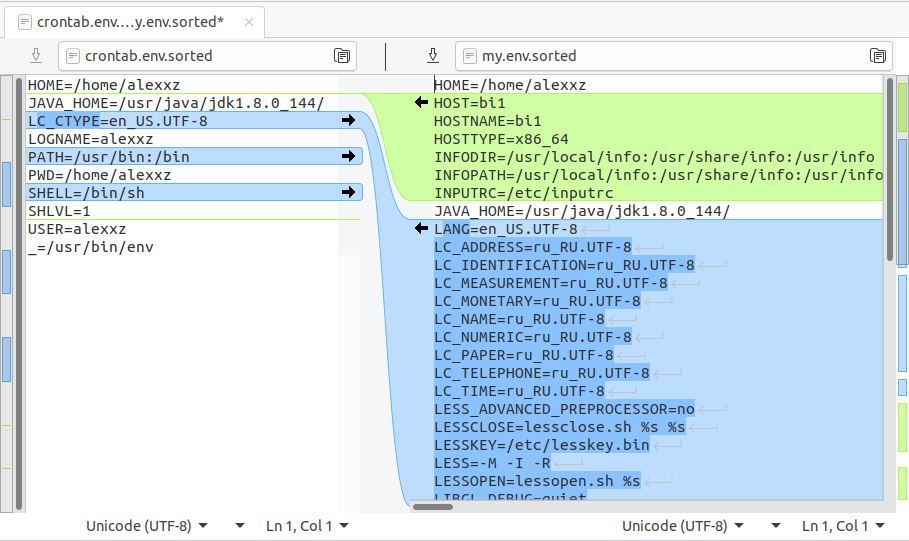
Mama Mia! ¡Así que debajo de la corona solo el mínimo! Por supuesto, debe cargar las variables de entorno normales.
Veamos cuál será el entorno si agregamos bash -l:
$ echo "* * * * * bash -l env > ~/crontab.env" | crontab; sleep 60; echo "" | crontab; alexxz@bi1.mlan:~> grep ^PATH= crontab.env my.env Crontab.env: PATH=/local/hive/bin:/local/python/bin:/local/hadoop/bin:/local/hadoop/bin:/local/hadoop/bin:/local/hive/bin:/usr/local/bin:/usr/bin:/bin My.env: PATH=/local/hive/bin:/local/python/bin:/local/hadoop/bin:/local/hadoop/bin:/local/hive/bin:/local/hadoop/bin:/usr/local/bin:/usr/bin:/bin
La diferencia no es tan notable. Todos los caminos se presentan. Algunos en un orden diferente, algunos se repiten, pero esto ya es mucho mejor de lo que era. El resto de las variables también están bien ajustadas. Existe, por supuesto, una ligera diferencia en la configuración regional, en las variables de SSH, pero esto ya no debería afectar drásticamente el funcionamiento del script.
Ahora está claro por qué se necesita bash -l en las entradas de crontab. Y, por supuesto, no te olvides del rebaño.
Inicialización de depuración de scripts de inicio de sesión
El problema parece estar resuelto, todo, desde la corona, funciona. Pero, ¿cómo es que algunas rutas están duplicadas en la variable PATH? Entonces, hay algún tipo de desorden en la configuración del servidor. Tratemos de resolverlo.
Abrimos a un hombre para inicializar el entorno, leemos qué guiones y en qué orden se ejecutan, con entusiasmo comenzamos a pasar por sus ojos, y después de unos minutos llega un sentimiento de desesperación. Un sinfín de condiciones sobre algunos casos especiales de arquitecturas, terminales y configuraciones de color increíblemente importantes para el comando ls. ¡Dolor, desesperación, odio! ¡Estamos interesados en una maldita RUTA variable!
De hecho, todo es algo más simple. Cumplir:
env -i bash -x -l -c 'echo 123' > login.log 2>&1
¿Qué hace este equipo? Crea un nuevo proceso bash con un entorno impecable, indica que es necesario ejecutar scripts de inicialización y asegurar todo en detalle en el archivo login.log. Ahora tenemos la oportunidad de no ejecutar todos los scripts en nuestras mentes, sino simplemente leer qué, dónde y cuándo se ejecutó y de dónde proviene este o aquel entorno.
No analizaré en detalle cómo leer el registro resultante. Todo es casi trivial allí. Solo menciono que un hit vino de / etc / profile y dos de /etc/bash.bashrc. Sí, en algún lugar eran demasiado inteligentes al configurar paquetes en una marioneta. Bueno, nada, no me molesta trabajar.
Pero ahora lo sé y puedo!
PD: en casos muy difíciles y para comprenderlo todo, puede ajustar el comando en orden:
strace -f env -i bash -x -l -c 'echo 123' > login.log 2>&1