Hola a todos! Estamos publicando una traducción del artículo preparado para los estudiantes del nuevo grupo del curso de Ingeniero de datos . Si está interesado en aprender cómo construir un sistema de procesamiento de datos eficiente y escalable con costos mínimos, ¡vea la grabación de la clase magistral por Yegor Mateshuk!

Hace unas semanas escribí un artículo sobre Hadoop, que cubría varios
partes y descubrió qué papel juega en el campo de la ingeniería de datos. En este artículo, yo
Daré una breve descripción de los diversos formatos de archivo en Hadoop. Es rapido y facil
tema Si está tratando de entender cómo funciona Hadoop y qué lugar ocupa en el trabajo
Ingeniero de datos, mira mi artículo sobre Hadoop aquí .
Los formatos de archivo Hadoop se dividen en dos categorías: orientados a filas y columnas.
orientado
Orientado a la fila:
Las filas de datos de un tipo se almacenan juntas, formando un continuo
almacenamiento: SequenceFile, MapFile, Avro Datafile. Por lo tanto, si es necesario
acceder solo a una pequeña cantidad de datos de una fila, de todos modos la fila completa
será leído en la memoria. Los retrasos en la serialización pueden, hasta cierto punto
aliviar el problema, pero completamente desde la sobrecarga de leer toda la fila de datos con
la unidad no podrá deshacerse. Almacenamiento orientado a filas
adecuado en casos donde es necesario procesar toda la línea al mismo tiempo
datos
Orientado a columnas:
El archivo completo se divide en varias columnas de datos y todas las columnas de datos.
almacenados juntos: Parquet, RCFile, ORCFile. Formato orientado a columna (columna-
orientado), le permite omitir columnas innecesarias al leer datos, lo cual es adecuado para
situaciones en las que se necesita una pequeña cantidad de líneas. Pero este formato de lectura y escritura
requiere más espacio de memoria ya que toda la línea de caché debe estar en la memoria
(para obtener una columna de varias filas). Al mismo tiempo, no es adecuado para
grabación en tiempo real, porque después de una falla de grabación, el archivo actual no puede
Los datos restaurados y orientados linealmente pueden reutilizarse
sincronizado desde el último punto de sincronización en caso de un error de escritura, por lo tanto,
por ejemplo, Flume usa un formato de almacenamiento orientado a líneas.

Figura 1 (izquierda). Tabla lógica mostrada
Figura 2 (derecha). Ubicación orientada a filas (archivo de secuencia)

Figura 3. Diseño orientado a columnas
Si aún no ha entendido completamente qué es la orientación de columna o fila,
no te preocupes Puede seguir este enlace para comprender la diferencia entre los dos.
Aquí hay algunos formatos de archivo que se usan ampliamente en el sistema Hadoop:
Archivo de secuencia
El formato de almacenamiento cambia dependiendo de si el almacenamiento está comprimido,
¿Utiliza compresión de escritura o compresión de bloque?

Figura 4. La estructura interna del archivo de secuencia sin compresión y con compresión de registros.
Sin compresión:
Almacenar en el orden correspondiente a la longitud del registro, longitud de la clave, valor del grado,
Valor clave y valor del valor. El rango es el número de bytes. Serialización
realizado utilizando el especificado.
Compresión de registro:
Solo se comprime el valor y el códec comprimido se almacena en el encabezado.
Compresión de bloque:
Se comprimen varios registros para que pueda usar
Aproveche las similitudes entre las dos entradas y ahorre espacio. Banderas
Las sincronizaciones se agregan al principio y al final del bloque. Valor de bloque mínimo
establecido por el atributo o.seqfile.compress.blocksizeset.

Figura 4. La estructura interna del archivo de secuencia con compresión de bloque.
Archivo de mapa
Un archivo de mapa es un tipo de archivo de secuencia. Después de agregar el índice a
el archivo de secuencia y su clasificación dan como resultado un archivo de mapa. El índice se almacena como un archivo separado.
archivo, que generalmente contiene los índices de cada una de las 128 entradas. Los índices pueden ser
cargado en la memoria para una recuperación rápida, porque los archivos en los que se almacenan los datos,
organizado en el orden especificado por la clave.
Las entradas del archivo de mapa deben estar en orden. De lo contrario nosotros
obtener una IOException.
Tipos de archivo de mapa derivados:
- SetFile: un archivo de mapa especial para almacenar una secuencia de teclas del tipo
Escribible Las claves se escriben en un orden específico. - ArrayFile: la clave es un número entero que indica la posición en la matriz, valor
escriba escribible. - BloomMapFile: optimizado para el método get () de un archivo de mapa usando
filtros dinámicos Bloom. El filtro se almacena en la memoria y el método habitual.
Se llama a get () para leer solo si el valor clave
existe
Los archivos enumerados a continuación en el sistema Hadoop incluyen RCFile, ORCFile y Parquet.
La versión orientada a columnas de Avro es Trevni.
Archivo RC
Archivo de columnas de registro de Hive : este tipo de archivo primero divide los datos en grupos de filas,
y dentro de un grupo de filas, los datos se almacenan en columnas. Su estructura es la siguiente
manera:

Figura 5. Ubicación de los datos del archivo RC en un bloque HDFS.
Compare con puro orientado a filas y columnas:
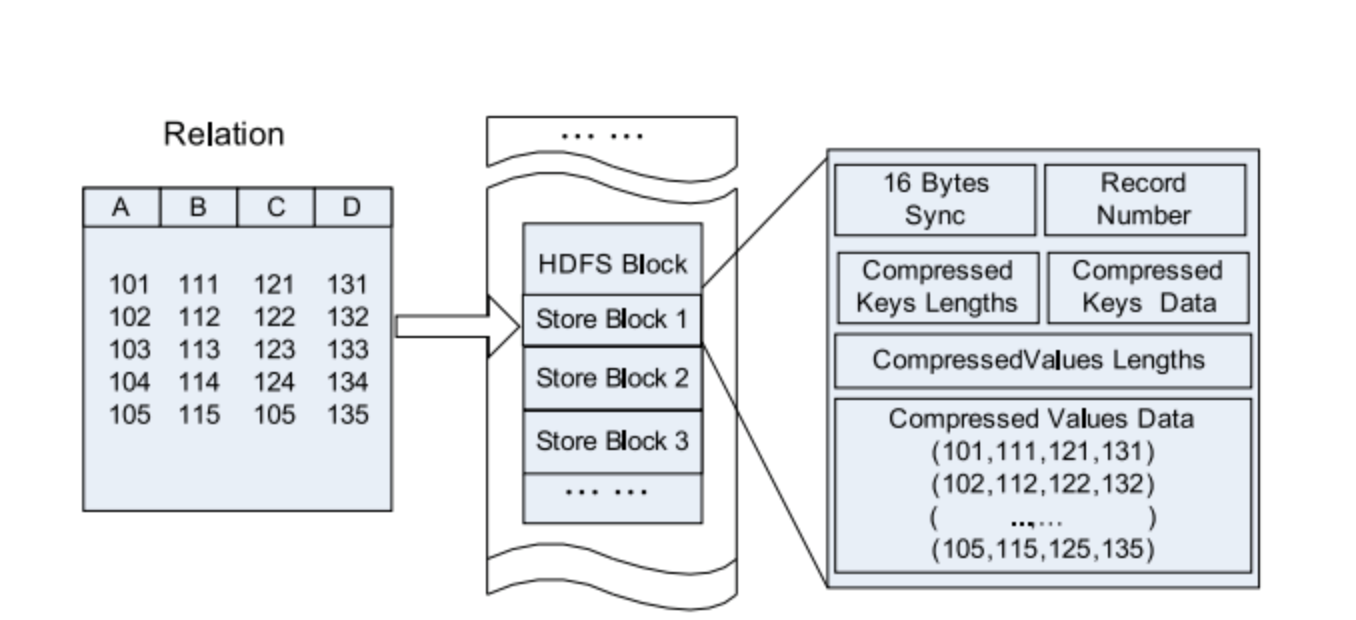
Figura 6. Almacenamiento fila por fila en el bloque HDFS.

Figura 7. Agrupación por columnas en un bloque HDFS.
Archivo ORC
ORCFile (archivo de columnas de registro optimizado): es un formato más eficiente
archivo que rcfile. Divide internamente los datos en tiras de 250M cada uno.
Cada carril tiene un índice, datos y pie de página. El índice almacena el mínimo y
el valor máximo de cada columna, así como la posición de cada fila en la columna.

Figura 8. Ubicación de los datos en el archivo ORC
Hive usa los siguientes comandos para usar el archivo .orc:
Parquet
Formato de almacenamiento genérico orientado a columnas basado en Google Dremel.
Especialmente bueno para procesar datos con un alto grado de anidamiento.
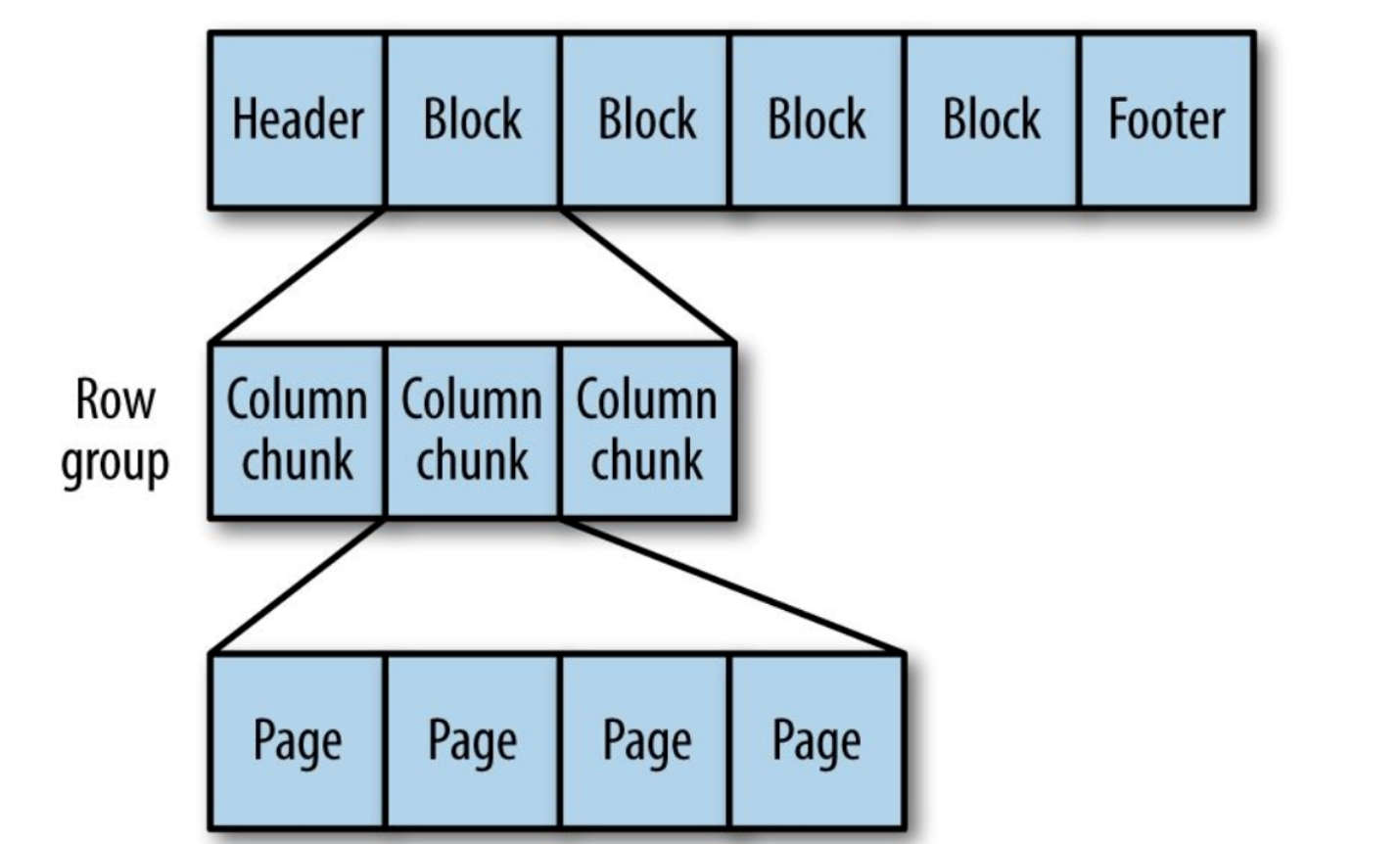
Figura 9. La estructura interna del archivo Parquet.
El parquet transforma las estructuras anidadas en almacenamiento de columna plana,
que está representado por el nivel de repetición y el nivel de definición (R y D) y utiliza
metadatos para restaurar registros mientras lee datos para recuperar todos
archivo. A continuación verá un ejemplo de R y D:
AddressBook { contacts: { phoneNumber: “555 987 6543” } contacts: { } } AddressBook { }

Eso es todo Ahora ya conoce las diferencias en los formatos de archivo en Hadoop. Si
encuentra cualquier error o inexactitud, no dudes en contactar
a mi Puedes contactarme en LinkedIn .