Nota perev. : Este material continúa una maravillosa serie de artículos del evangelista de tecnología de AWS Adrian Hornsby, quien se propuso explicar de manera simple y clara la importancia de los experimentos diseñados para mitigar las consecuencias de fallas en los sistemas de TI.
"Si no pudo preparar el plan, entonces planea fallar". - Benjamin Franklin
En la
primera parte de esta serie de artículos, presenté el concepto de ingeniería del caos y expliqué cómo ayuda a encontrar y corregir fallas en el sistema antes de que conduzcan a fallas en la producción. También habló sobre cómo la ingeniería del caos contribuye al cambio cultural positivo dentro de las organizaciones.
Al final de la primera parte, prometí hablar sobre "herramientas y métodos para introducir fallas en los sistemas". Por desgracia, mi cabeza tenía sus propios planes a este respecto, y en este artículo trataré de responder la pregunta más popular que surge de las personas que quieren involucrarse en la ingeniería del caos:
¿qué romper primero? Gran pregunta! Sin embargo, no parece molestarse con este panda ...
 ¡No te metas con el panda del caos!Respuesta corta
¡No te metas con el panda del caos!Respuesta corta : Apunte a servicios críticos en la ruta de solicitud.
Una respuesta larga pero más inteligible : para comprender dónde comenzar los experimentos con el caos, preste atención a tres áreas:
- Mire la historia de fallas e identifique patrones;
- Decidir sobre dependencias críticas ;
- Usa el llamado. Efecto de exceso de confianza .
Es divertido, pero esta parte con el mismo éxito podría llamarse
"Viaje al autoconocimiento y la iluminación" . En él, comenzaremos a "jugar" con algunas herramientas geniales.
1. La respuesta yace en el pasado.
Si recuerdan, en la primera parte introduje el concepto de Corrección de errores (COE), el método por el cual analizamos nuestros errores: fallas en la tecnología, el proceso o la organización, para comprender sus causas y evitar futuras repeticiones. . En general, esto debería comenzar.
"Para entender el presente, necesitas conocer el pasado". - Karl Sagan
Mire el historial de fallas, coloque etiquetas en SOE o postmortem'ah y clasifíquelas. Identifique patrones comunes que a menudo conducen a problemas, y para cada SOE hágase la siguiente pregunta:
"¿Podría esto haberse previsto y, por lo tanto, prevenido mediante la introducción de un mal funcionamiento?"Recuerdo un fracaso al comienzo de mi carrera. Podría haberse evitado fácilmente si tuviéramos un par de simples experimentos de caos:
En condiciones normales, las instancias de fondo responden a las comprobaciones de estado del equilibrador de carga (ELB ). ELB utiliza estas comprobaciones para redirigir las solicitudes a instancias saludables. Cuando resulta que cierta instancia no es “saludable”, el ELB deja de enviarle solicitudes. Una vez, después de una exitosa campaña de marketing, el volumen de tráfico creció y los backends comenzaron a responder a los controles de salud más lentamente de lo habitual. Cabe decir que estos controles de salud fueron profundos , es decir, se verificó el estado de las dependencias.
Sin embargo, por un tiempo todo estuvo en orden.
Luego, ya en condiciones bastante estresantes, una de las instancias comenzó a realizar una tarea cron regular y no crítica de la categoría ETL. La combinación de alto tráfico y cronjob estimuló la utilización de la CPU en casi un 100%. La sobrecarga del procesador ralentizó aún más las respuestas a las comprobaciones de estado, tanto que ELB decidió que la instancia estaba experimentando problemas. Como se esperaba, el equilibrador dejó de distribuirle tráfico, lo que, a su vez, condujo a un aumento de la carga en las instancias restantes en el grupo.
De repente, todas las demás instancias también comenzaron a fallar el control de salud.
Comenzar una nueva instancia requirió descargar e instalar paquetes y tomó mucho más tiempo del que el ELB necesitó para desconectarlos, uno por uno, en el grupo de escalado automático. Está claro que pronto todo el proceso alcanzó un punto crítico y la aplicación cayó.
Entonces entendimos para siempre los siguientes puntos:
- Para instalar el software al crear una nueva instancia durante mucho tiempo, es mejor dar preferencia al enfoque inmutable y Golden AMI .
- En situaciones difíciles, las respuestas a los controles de salud y los ELB deben tener prioridad, y lo que menos desea es que la vida sea difícil para las instancias restantes.
- El almacenamiento en caché local de los controles de estado (incluso durante unos segundos) ayuda mucho.
- En una situación difícil, no ejecute tareas cron y otros procesos no críticos: ahorre recursos para las tareas más importantes.
- Cuando escale automáticamente, use instancias más pequeñas. Un grupo de 10 copias pequeñas es mejor que 4 grandes; Si una instancia cae, en el primer caso, el 10% del tráfico se distribuirá en 9 puntos, en el segundo, el 25% del tráfico en tres puntos.
Entonces, ¿
podría preverse esto y, por lo tanto, prevenirse introduciendo el problema?Sí , y de varias maneras.
Primero, al simular una alta utilización de la CPU con herramientas como
stress-ng o
cpuburn :
❯ stress-ng --matrix 1 -t 60s
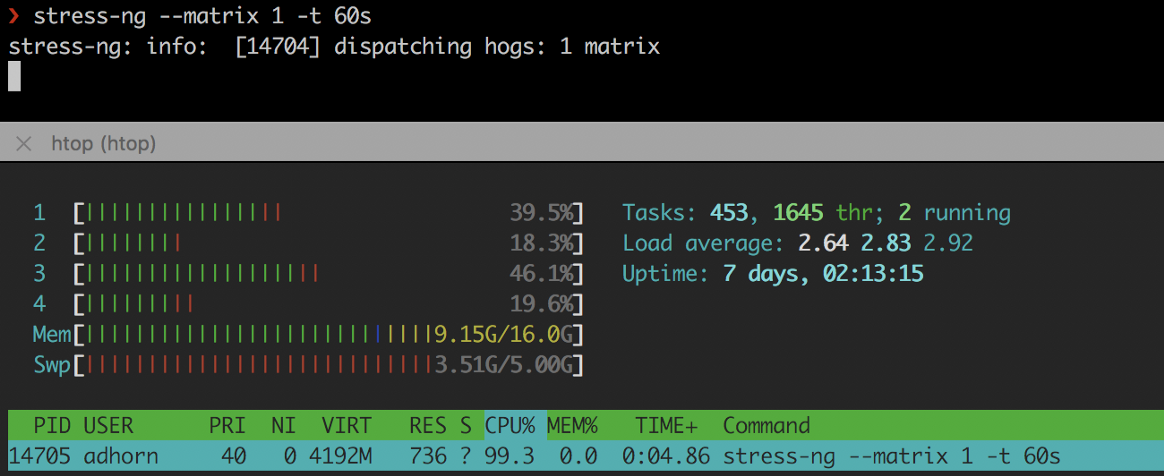 estrés
estrésEn segundo lugar, sobrecargar la instancia usando
wrk y otras utilidades similares:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
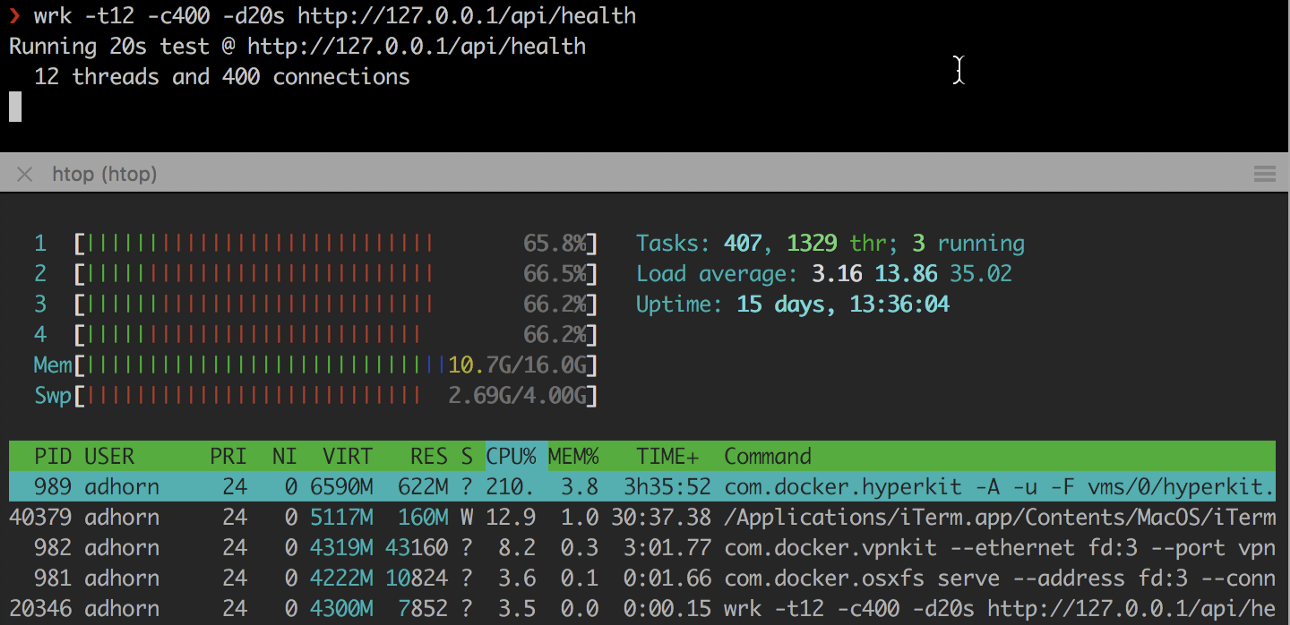
Los experimentos son relativamente simples, pero pueden proporcionar una buena forma de pensar sin tener que experimentar el estrés de un fracaso real.
Sin embargo,
no te detengas ahí . Intente reproducir la falla en un entorno de prueba y verifique su respuesta a la pregunta "
¿Podría haber sido previsto y, por lo tanto, prevenido mediante la introducción de un mal funcionamiento?" ". Este es un mini experimento de caos dentro de un experimento de caos para probar suposiciones, pero comenzando con una falla.
 ¿Fue un sueño o realmente sucedió?
¿Fue un sueño o realmente sucedió?Por lo tanto, estudie el historial de fallas, analice
COE , etiquételas y clasifíquelas de acuerdo con el "radio de daño", o, más precisamente, de acuerdo con el número de clientes afectados, y luego busque patrones. Pregúntese si esto podría haberse previsto y evitado al presentar el problema. Comprueba tu respuesta.
Luego cambie a los patrones más comunes con el rango más grande.
2. Construye un mapa de dependencia
Tómese un momento para pensar en su aplicación. ¿Hay un mapa claro de sus dependencias? ¿Sabes qué impacto tendrán en caso de falla?
Si no está muy familiarizado con el código de su aplicación o si se ha vuelto demasiado grande, puede ser difícil entender qué hace el código y cuáles son sus dependencias. Comprender estas dependencias y su posible impacto en la aplicación y los usuarios es fundamental para comprender dónde comenzar la ingeniería del caos: el componente con el mayor radio de destrucción será el punto de partida.
Identificar y documentar dependencias se denomina "
mapeo de dependencias ". Por lo general, se lleva a cabo para aplicaciones con una amplia base de código utilizando herramientas para la creación de perfiles de código
(creación de perfiles de código) y la instrumentación
(instrumentación) . También puede crear mapas monitoreando el tráfico de red.
Sin embargo, no todas las dependencias son iguales (lo que complica aún más el proceso). Algunos son
críticos , otros son
secundarios (al menos en teoría, porque los bloqueos a menudo resultan de problemas de dependencia que se consideraron no críticos) .
Sin dependencias críticas, un servicio no puede funcionar. Las dependencias no críticas "
no deberían " tener un efecto en el servicio en caso de una caída. Para lidiar con las dependencias, debe tener una comprensión clara de las API utilizadas por la aplicación. Puede ser mucho más complicado de lo que parece, al menos para aplicaciones grandes.
Comience clasificando todas las API. Destacar los más
significativos y críticos . Tome las
dependencias del repositorio de código, examine los
registros de conexión , luego mire la
documentación (por supuesto, si existe; de lo contrario, todavía tiene más problemas). Use las herramientas para
perfilar y rastrear , filtrar llamadas externas.
Puede usar programas como
netstat , una utilidad de línea de comandos que muestra una lista de todas las conexiones de red (sockets activos) en el sistema. Por ejemplo, para mostrar todas las conexiones actuales, escriba:
❯ netstat -a | more

En AWS, puede usar los registros de flujo VPC, un método que le permite recopilar información sobre el tráfico IP que va hacia o desde las interfaces de red en las VPC. Dichos registros pueden ayudar con otras tareas, por ejemplo, encontrar una respuesta a la pregunta de por qué cierto tráfico no llega a la instancia.
También puede usar
AWS X-Ray . X-Ray le permite obtener una visión general detallada de "final"
(de extremo a extremo) de las solicitudes a medida que avanzan a través de la aplicación, y también crea un mapa de los componentes básicos de la aplicación. Es muy conveniente si necesita identificar dependencias.
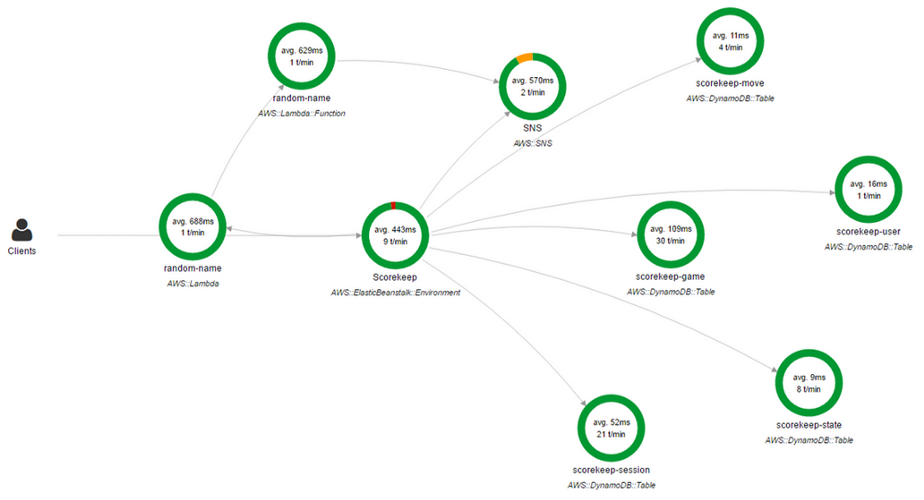 Consola de rayos X AWS
Consola de rayos X AWSUn mapa de dependencia de red es solo una solución parcial. Sí, muestra qué aplicación está asociada a qué, pero hay otras dependencias.
Muchas aplicaciones usan DNS para conectarse a dependencias, mientras que otras pueden usar el mecanismo de descubrimiento de servicios o incluso direcciones IP codificadas en archivos de configuración (por ejemplo, en
/etc/hosts ).
Por ejemplo, puede crear un
DNS de agujero negro usando
iptables y ver qué se rompe. Para hacer esto, ingrese el siguiente comando:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
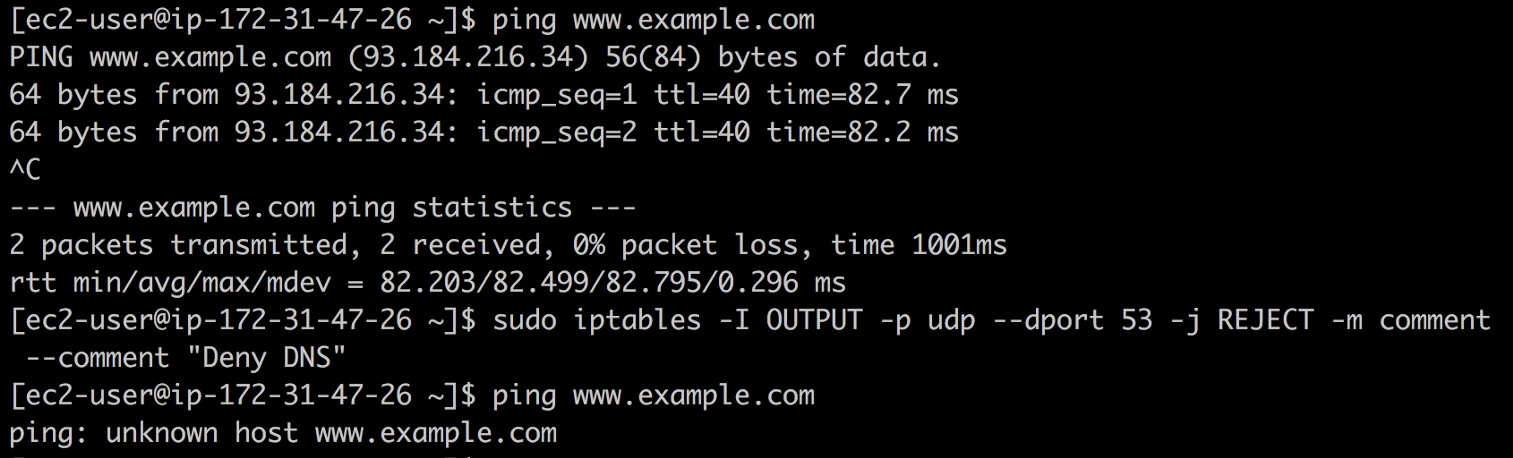 DNS de agujero negro
DNS de agujero negroSi encuentra direcciones IP en
/etc/hosts u otros archivos de configuración de los que no sabe nada (sí, desafortunadamente, eso sucede),
iptables puede acudir al rescate nuevamente. Digamos que encuentra
8.8.8.8 y no sabe que esta es la dirección del servidor DNS público de Google. Con
iptables puede cerrar el tráfico entrante y saliente a esta dirección con los siguientes comandos:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
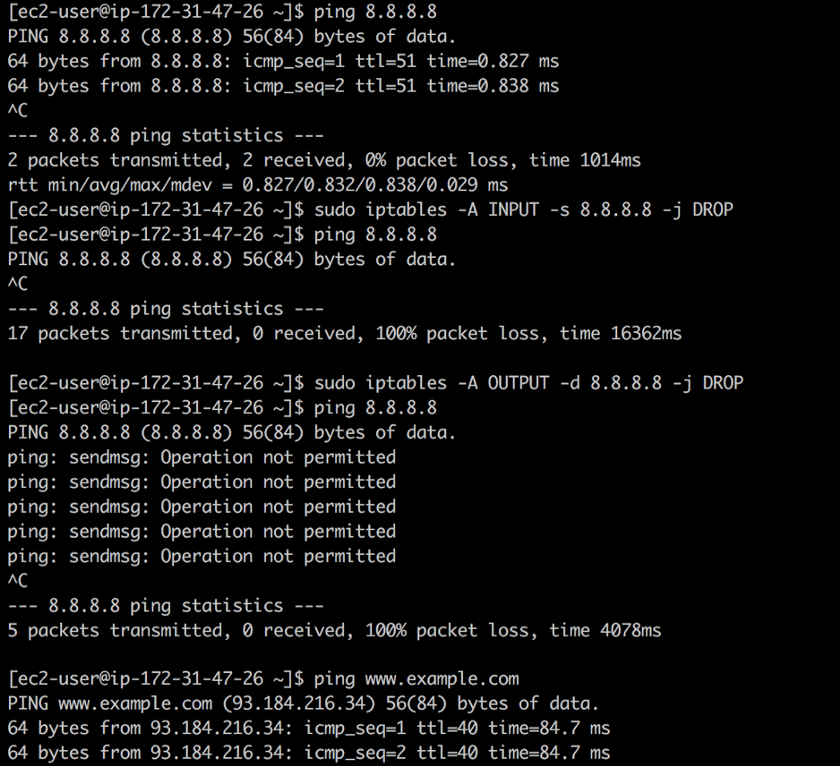 Cerrar acceso
Cerrar accesoLa primera regla descarta todos los paquetes del DNS público de Google: el
ping funciona, pero los paquetes no se devuelven. La segunda regla descarta todos los paquetes que provienen de su sistema en la dirección del DNS público de Google; en respuesta al
ping , obtenemos la
Operación no permitida .
Nota: en este caso particular, sería mejor usar whois 8.8.8.8 , pero esto es solo un ejemplo.Puede profundizar aún más en el agujero del conejo, ya que todo lo que usa TCP y UDP en realidad depende de IP. En la mayoría de los casos, la IP está vinculada a ARP. No te olvides de los firewalls ...
 Si eliges una pastilla roja, permanecerás en el País de las Maravillas y te mostraré cuán profundo es el agujero del conejo
Si eliges una pastilla roja, permanecerás en el País de las Maravillas y te mostraré cuán profundo es el agujero del conejoUn enfoque más radical es
apagar los autos uno por uno y ver qué se rompe ... convertirse en un "mono del caos". Por supuesto, muchos sistemas de producción no están diseñados para un ataque tan crudo, pero al menos se puede probar en un entorno de prueba.
Construir un mapa de dependencia es a menudo un ejercicio muy largo. Hace poco hablé con un cliente que pasé casi 2 años desarrollando una herramienta que, en modo semiautomático, genera mapas de dependencia para cientos de microservicios y equipos.
El resultado, sin embargo, es extremadamente interesante y útil. Aprenderá mucho sobre su sistema, sus dependencias y operaciones. Nuevamente, sea paciente: el viaje en sí es de suma importancia.
3. Cuidado con la arrogancia
"Quien sueña con qué, cree en eso". - Demóstenes
¿Alguna vez has oído hablar del
efecto del exceso de confianza ?
Según Wikipedia, el efecto del exceso de confianza es "una distorsión cognitiva en la que la confianza de una persona en sus acciones y decisiones es mucho más alta que la precisión objetiva de estos juicios, especialmente cuando el nivel de confianza es relativamente alto".
 Basado en el instinto y la experiencia ...
Basado en el instinto y la experiencia ...Desde mi propia experiencia, puedo decir que esta distorsión es una gran pista sobre dónde comenzar la ingeniería del caos.
Cuidado con el operador seguro de sí mismo:
Charlie: "Esta cosa no ha caído en unos cinco años, ¡todo está bien!"
Fracaso: "Espera ... ¡lo estaré pronto!"
El sesgo como consecuencia de la confianza en uno mismo es algo insidioso e incluso peligroso debido a varios factores que lo afectan. Esto es especialmente cierto cuando los miembros del equipo ponen su alma en cierta tecnología o pasan mucho tiempo en "arreglos".
Para resumir
La búsqueda de un punto de partida para la ingeniería del caos siempre produce más resultados de lo esperado, y los equipos que comienzan a romper todo demasiado rápido pierden de vista la esencia más global e interesante de la
ingeniería (del caos): la aplicación creativa de
métodos científicos y
evidencia empírica para el diseño, el desarrollo , operación, mantenimiento y mejora de sistemas (software).
Sobre esto, la segunda parte llega a su fin. Escribe comentarios, comparte opiniones o simplemente aplaude a
Medium .
En la siguiente parte, realmente analizaré las herramientas y técnicas para introducir fallas en el sistema. Hasta que ... ¡chao! ACTUALIZADO (19 de diciembre): La
traducción de la tercera parte está disponible.
PD del traductor
Lea también en nuestro blog: