En general, el reconocimiento de la cara y la identificación de las personas de acuerdo con sus resultados parece ser sexo adolescente para los ancianos: todos hablan mucho de él, pero pocos practican. Está claro que ya no nos sorprende que después de descargar fotos de reuniones amistosas, Facebook / VK sugiera marcar a las personas que se encuentran en la imagen, pero aquí intuitivamente sabemos que las redes sociales tienen una buena ayuda en forma de gráfico de conexiones de una persona. ¿Y si no hay tal gráfico? Sin embargo, comencemos en orden.

Inicialmente, el reconocimiento facial y la identificación de "amigos / enemigos" con nosotros surgieron de necesidades exclusivamente domésticas: los adictos se metían en la puerta de un colega y vigilaban constantemente la imagen desde la cámara de video instalada, e incluso desensamblaban dónde el vecino y el extraño no deseaban no
Por lo tanto, en solo una semana, se ensambló un prototipo en la rodilla, que constaba de una cámara IP, un dispositivo de placa única, un sensor de movimiento y la biblioteca de reconocimiento de Python de reconocimiento facial. Dado que la biblioteca de Python estaba en un hardware de placa única y bastante potente ... digamos con cuidado, no muy rápido, decidimos construir el proceso de procesamiento de la siguiente manera:
- el sensor de movimiento determina si hay movimiento en el área del espacio que se le confía y señala su presencia;
- un servicio escrito basado en gstreamer, que recibe constantemente una transmisión de una cámara IP, corta 5 segundos antes y 10 segundos después de la detección y lo envía a la biblioteca de reconocimiento para su análisis;
- ella, a su vez, mira el video, encuentra caras allí, las compara con muestras conocidas y, si se encuentra una desconocida, entrega el video al canal Telegram, luego se suponía que debía controlarse en el mismo lugar para cortar inmediatamente los falsos positivos, por ejemplo, cuando un vecino Se volvió hacia la cámara del lado equivocado de las muestras.
Todo nuestro proceso fue pegado por nuestro querido Erlang, y en el proceso de pruebas en colegas demostró su capacidad de trabajo mínima.
Sin embargo, el modelo ensamblado no encontró aplicación en la vida real, no debido a su imperfección técnica, que indudablemente lo fue, como lo demuestra la experiencia, recolectado en la rodilla en condiciones de invernadero tiene una muy mala tendencia a romperse en el campo y al momento de la demostración al cliente. , y debido a las organizaciones, los residentes de la entrada rechazaron la mayoría de cualquier video vigilancia.
El proyecto salió a la venta y periódicamente pinchó con un palo para hacer demostraciones durante las ventas y la necesidad de reencarnar en el hogar personal.
Todo ha cambiado desde el momento en que tuvimos un proyecto más específico y bastante comercial sobre el mismo tema. Dado que no sería posible cortar esquinas usando un sensor de movimiento directamente desde el enunciado del problema, tuve que profundizar en los matices de buscar y reconocer caras en tres cabezas (está bien, dos y media, si cuentas las mías) directamente en la secuencia. Y luego ocurrió una revelación.
El problema es que la mayoría de los hallazgos sobre este tema son bocetos puramente académicos sobre el tema de que "tuve que escribir un artículo en una revista sobre un tema de moda y obtener una marca para publicar". No menosprecio los méritos de los científicos: entre los documentos que encontré que eran muy útiles e interesantes, pero, por desgracia, tengo que admitir que la reproducibilidad del trabajo de su código publicado en Github deja mucho que desear o parece una empresa dudosa con el tiempo perdido al final.
Numerosos marcos para las redes neuronales y el aprendizaje automático a menudo eran difíciles de levantar: el reconocimiento facial era una tarea estrecha y separada para ellos, sin interés en una amplia gama de problemas que resolvieron. En otras palabras, tomar un ejemplo listo y ejecutarlo en el hardware de destino solo para verificar cómo funciona y si funciona, no funcionó. Ese no fue un ejemplo, entonces la necesidad de obtenerlo sugirió una búsqueda agria del ensamblaje de ciertas bibliotecas de ciertas versiones para un SO estrictamente definido. Es decir para tomar y volar en movimiento, literalmente migajas como la face_recognition mencionada anteriormente, que utilizamos para las embarcaciones anteriores.
Las grandes empresas, como siempre, nos salvaron. Tanto Intel como Nvidia han sentido durante mucho tiempo el creciente impulso y el atractivo comercial de esta clase de tareas, pero como proveedores de equipos en primer lugar, distribuyen sus marcos para resolver problemas de aplicaciones específicas de forma gratuita.
Nuestro proyecto probablemente no era de investigación, sino de naturaleza experimental, por lo que no analizamos ni comparamos las soluciones de proveedores individuales, sino que simplemente tomamos el primero con el objetivo de recolectar un prototipo listo y probarlo en la batalla, mientras recibíamos la respuesta más rápida posible. Por lo tanto, la elección recayó rápidamente en
Intel OpenVINO , una biblioteca para la aplicación práctica del aprendizaje automático en tareas aplicadas.
Para comenzar, armamos un soporte, que tradicionalmente es un conjunto de nettop con un procesador Intel Core i3 y cámaras IP de proveedores chinos en el mercado. La cámara se conectó directamente al nettop y se le suministró una transmisión RTSP con un FPS no muy grande, basado en el supuesto de que la gente todavía no correría delante de ella como en las competiciones. La velocidad de procesamiento de un cuadro (búsqueda y reconocimiento de caras) fluctuó en la región de decenas a cientos de milisegundos, lo que fue suficiente para integrar el mecanismo de búsqueda de personas que usan muestras existentes. Además, también teníamos un plan de respaldo: Intel tiene un coprocesador especial para acelerar los cálculos de las redes neuronales
Neural Compute Stick 2 , que podríamos usar si no tuviéramos un procesador de uso general. Pero hasta ahora no ha pasado nada.
Después de completar el ensamblaje y verificar la funcionalidad de los ejemplos básicos, una característica distintiva del SDK de Intel estaba en una guía de ejemplos paso a paso y muy detallada, comenzamos a construir el software.
La tarea principal a la que nos enfrentamos era buscar a una persona en el campo de visión de la cámara, su identificación y notificación oportuna de su presencia. En consecuencia, además de reconocer caras y compararlas con patrones (cómo hacer esto, en ese momento, no causó menos preguntas que todo lo demás), necesitábamos proporcionar elementos secundarios del plan de interfaz. Es decir, debemos recibir marcos con las caras de las personas necesarias de la misma cámara para su posterior identificación. Por qué, desde la misma cámara, creo que también es bastante obvio: el punto de instalación de la cámara en el objeto y la óptica del objetivo introducen ciertas distorsiones que, presumiblemente, pueden afectar la calidad del reconocimiento, utilizamos una fuente de datos de origen diferente a una herramienta de seguimiento.
Es decir Además del controlador de flujo en sí, necesitamos al menos un archivo de video y un analizador de archivos de video que aislarán todas las caras detectadas de la grabación y guardarán las más adecuadas como referencias.
Como siempre, tomamos el conocido Erlang y PostgreSQL como pegamento entre ffmpeg, aplicaciones en OpenVINO y Telegram Bot API para alertas. Además, necesitábamos una interfaz de usuario web para proporcionar el conjunto mínimo de procedimientos para administrar el complejo, que nuestro interlocutor colega había subido a VueJS.
La lógica del trabajo fue la siguiente:
- bajo el control de un plano de control (en Erlang) ffmpeg escribe un flujo de la cámara al video en segmentos de cinco minutos, un proceso separado asegura que los registros se almacenan en un volumen estrictamente especificado y limpia el más antiguo cuando se alcanza este umbral;
- a través de la interfaz de usuario web puede ver cualquier registro, están ordenados cronológicamente, lo que, aunque no sin dificultad, le permite aislar el fragmento deseado y enviarlo para su procesamiento;
- el procesamiento consiste en analizar el video y extraer cuadros con caras detectadas, solo hace el software basado en OpenVINO (debo decir, aquí logramos cortar un poco el ángulo; el software para analizar el flujo y analizar archivos es casi idéntico, por lo que la mayor parte fue a una biblioteca compartida, y las utilidades en sí mismas difieren solo en la cadena de procesamiento a la modular gstreamer). El procesamiento se realiza en video, aislando las caras encontradas utilizando una red neuronal especialmente entrenada. Los fragmentos resultantes del marco que contiene caras caen en otra red neuronal, que forma un vector de 256 elementos, que es, de hecho, las coordenadas de los puntos de referencia de la cara de una persona. Este vector, el marco detectado y las coordenadas del rectángulo de la cara encontrada se almacenan en la base de datos;
- Además, una vez que se completa el procesamiento, el operador abre la variedad de cuadros dibujados, se horroriza por su número y procede a buscar a las personas objetivo. Las muestras seleccionadas se pueden agregar a una persona existente o crear una nueva. Una vez que se completa el procesamiento de la tarea, los resultados del análisis se eliminan, con la excepción de los vectores almacenados asignados a los registros de observables;
- en consecuencia, podemos ver tanto los cuadros como los vectores de detección en cualquier momento y editarlos, eliminando muestras que no tuvieron éxito;
- Paralelamente al ciclo de detección en segundo plano, el servicio de análisis de flujo siempre funciona, lo que hace lo mismo, pero con el flujo de la cámara. Selecciona caras en el flujo observado y las compara con muestras de la base de datos, que se basa en la simple suposición de que los vectores de una persona estarán más cerca uno del otro que de todos los demás vectores. Se produce un cálculo por pares de la distancia entre los vectores, cuando se alcanza el umbral, un registro de detección y un marco se colocan en la base de datos. Además, una persona se agrega a la lista de paradas en un futuro cercano, lo que evita múltiples notificaciones sobre la misma persona;
- el plano de control verifica periódicamente el registro de detección y, en caso de nuevas entradas, notifica con un mensaje con la foto adjunta y destacando la cara a través del bot a aquellos que están autorizados de acuerdo con la configuración.
Se parece a esto:
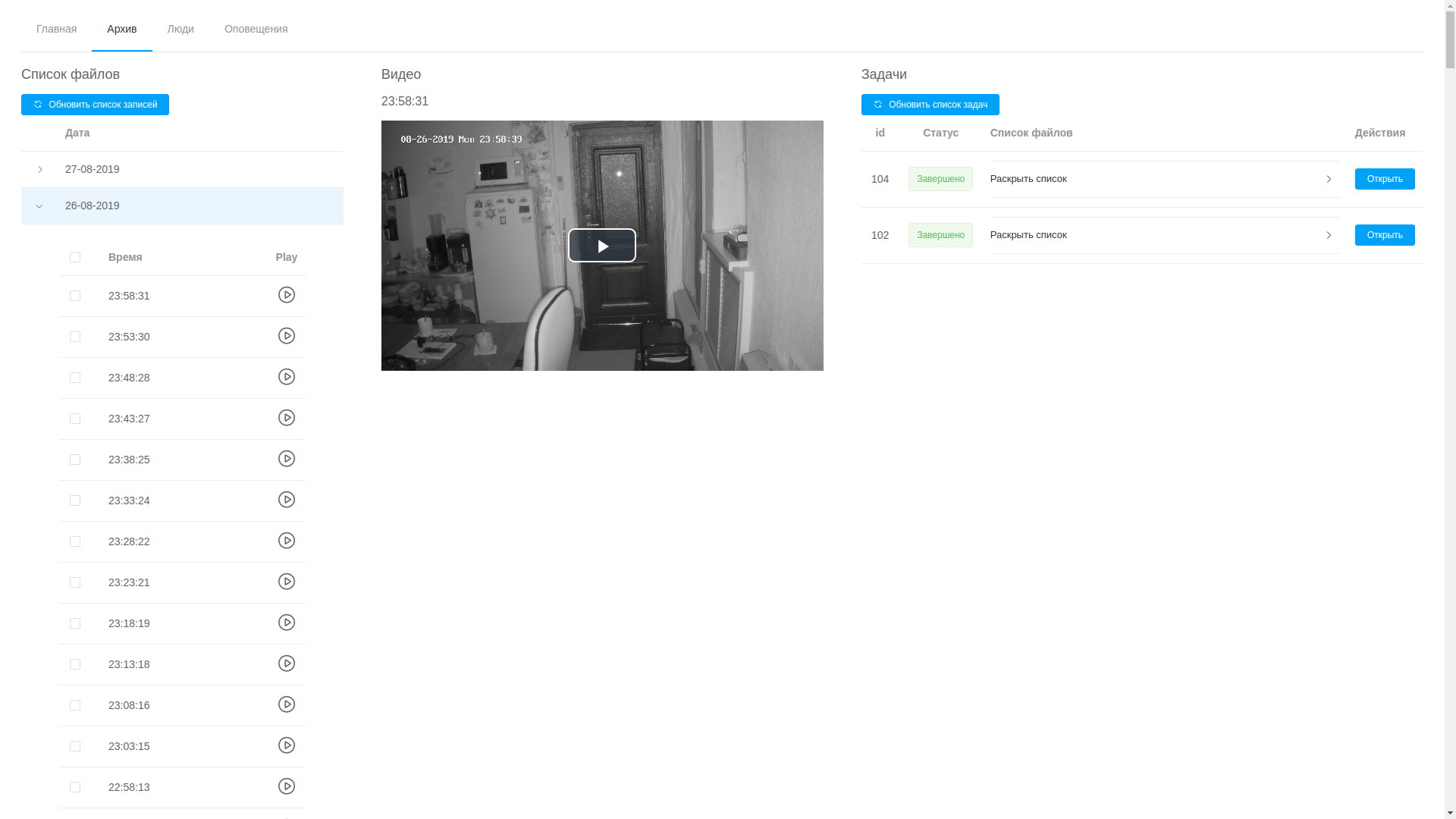 Ver archivo
Ver archivo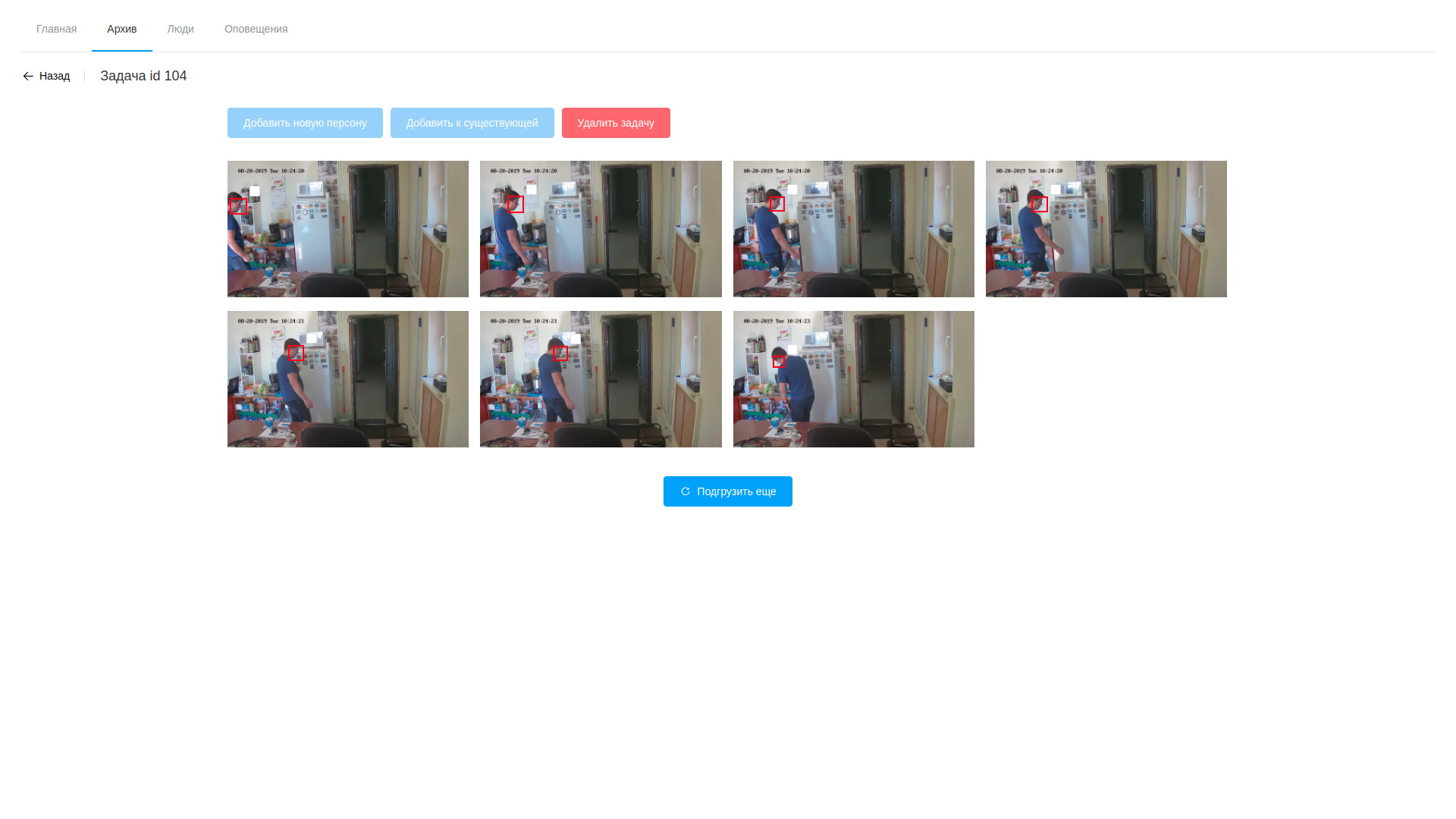 Resultados de análisis de video
Resultados de análisis de video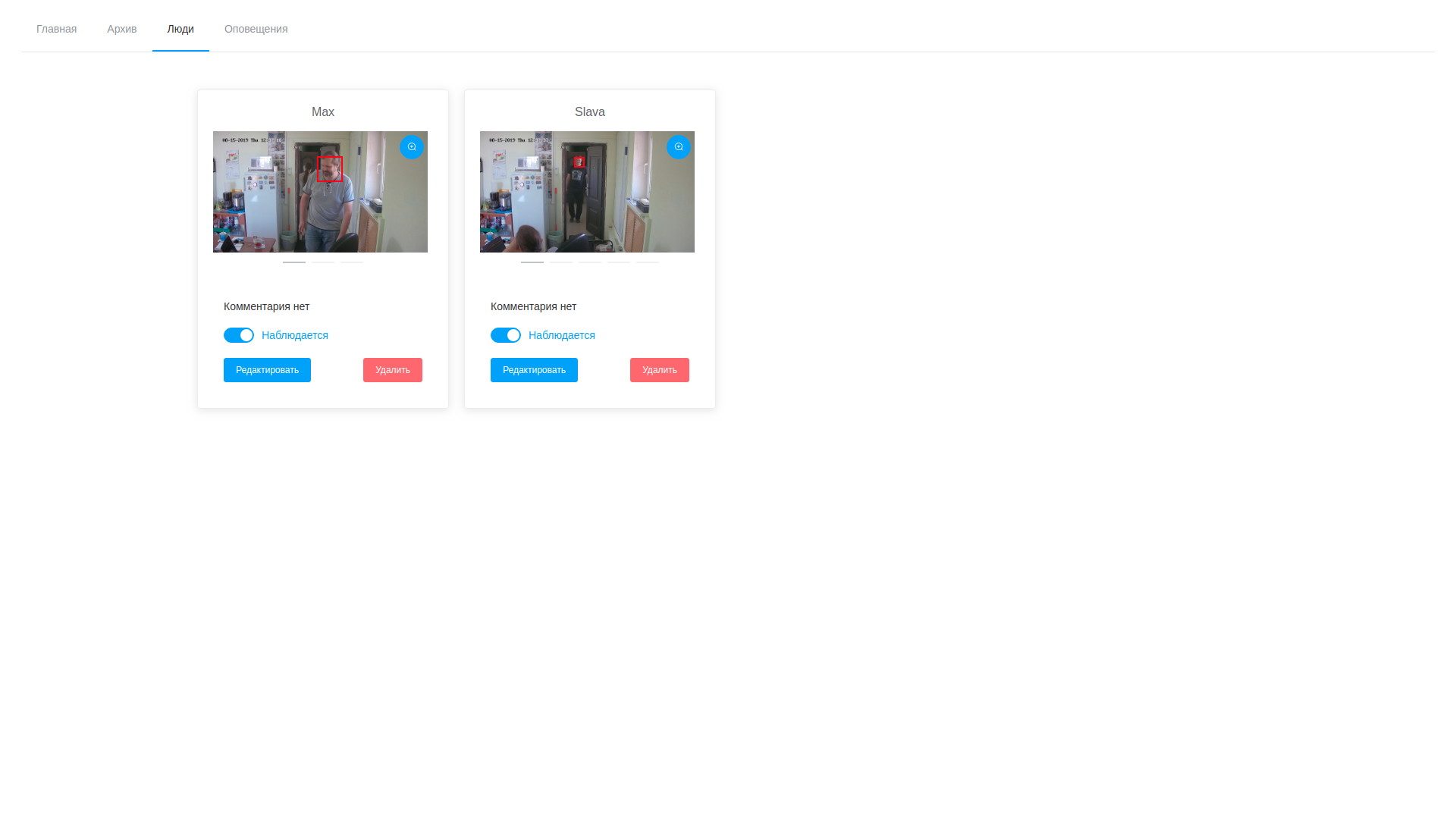 Lista de personalidades observadas
Lista de personalidades observadasLa solución resultante es, en muchos sentidos, controvertida y, a veces, incluso no óptima, tanto en términos de productividad como en términos de reducción del tiempo de reacción. Pero, repito, no teníamos el objetivo de obtener un sistema efectivo de inmediato, sino simplemente seguir esta ruta y llenar el número máximo de conos, identificar caminos estrechos y posibles problemas no obvios.
El sistema ensamblado se probó en condiciones de invernadero durante una semana. Durante este tiempo, se observaron las siguientes observaciones:
- Existe una clara dependencia de la calidad de reconocimiento de la calidad de las muestras originales. Si la persona observada atraviesa la zona de observación demasiado rápido, con un alto grado de probabilidad no dejará datos para el muestreo y no será reconocida. Sin embargo, creo que se trata de ajustar el sistema, incluidos los parámetros de iluminación y transmisión de video;
- Dado que el sistema funciona con el reconocimiento de elementos de caras (ojos, nariz, boca, cejas, etc.), es fácil engañar al colocar un obstáculo visual entre la cara y la cámara (cabello, anteojos oscuros, usar una capucha, etc.): la cara, lo más probable es que se encuentre, pero la comparación con las muestras no funcionará debido a la fuerte discrepancia entre los vectores de detección y las muestras;
- los anteojos comunes no afectan demasiado: tuvimos ejemplos de respuestas positivas en personas con anteojos y respuestas falsas negativas en personas que se pusieron anteojos para la prueba;
- si la barba estaba en las muestras originales, y luego desapareció, entonces el número de operaciones se reduce (el autor de estas líneas recortó su barba a 2 mm y el número de operaciones en ella se redujo a la mitad);
- También se produjeron falsos positivos, esta es una ocasión para una mayor inmersión en las matemáticas del problema y, posiblemente, una solución a la cuestión de la correspondencia parcial de los vectores y el método óptimo para calcular la distancia entre ellos. Sin embargo, las pruebas de campo deberían revelar aún más problemas a este respecto.
Lo que está por venir? Verificando el sistema en batalla, optimizando el ciclo de procesamiento de detección, simplificando el procedimiento para buscar eventos en el archivo de video, agregando más datos al análisis (edad, género, emociones) y otras 100,500 tareas pequeñas y no tan importantes que aún deben hacerse. Pero el primer paso en el camino de mil pasos ya hemos dado. Si alguien comparte su experiencia en la solución de tales problemas o da enlaces interesantes sobre este tema, le agradeceré mucho.