
En el entorno de los ingenieros de SRE- / DevOps, no se sorprenderá de que un día aparezca un cliente (o sistema de monitoreo) e informe que "todo está perdido": el sitio no funciona, los pagos no pasan, la vida es decadencia ... No importa cómo me gustaría ayudar en esta situación Puede ser muy difícil hacer esto sin una herramienta simple y comprensible. A menudo, el problema está oculto en el código de la aplicación en sí misma; solo necesita localizarlo.
Y con pena y alegría ...
Dio la casualidad de que siempre hemos sido muy aficionados a New Relic. Ha sido y sigue siendo una excelente herramienta para monitorear el rendimiento de la aplicación, y también le permite instrumentar la arquitectura del microservicio (utilizando su agente) y mucho, mucho más. Y todo podría ser maravilloso, de no ser por los cambios en la política de precios del servicio: su
costo ha aumentado más de 3 veces desde 2013 . Además, desde el año pasado, obtener una cuenta de prueba requiere comunicación con un gerente personal, lo que dificulta la presentación del producto a un cliente potencial.
La situación habitual: New Relic no es necesaria de forma "continua", se recuerda solo en el momento en que comenzaron los problemas. Pero aún debe pagar regularmente (140 USD por servidor por mes), y en la infraestructura de nube escalable automáticamente, las cantidades son bastante grandes. Aunque existe la posibilidad de "Pay-As-You-Go", pero para habilitar New Relic necesitará reiniciar la aplicación, lo que puede conducir a la pérdida de la situación del problema para el que se inició todo. No hace mucho tiempo, New Relic introdujo un nuevo plan de tarifas:
Essentials , que a primera vista parece una alternativa razonable a Professional ... pero después de un examen más detallado resultó que faltan algunas de las funciones importantes (en particular, no tiene
Transacciones clave ,
Seguimiento de aplicaciones cruzadas ,
Seguimiento distribuido ) .
Como resultado, pensamos en encontrar una alternativa más barata, y nuestra elección recayó en los dos servicios Datadog y Atatus. ¿Por qué exactamente en ellos?
Sobre competidores
Debo decir de inmediato que hay otras soluciones en el mercado. Incluso consideramos las opciones de código abierto, pero no todos los clientes tienen capacidad libre para alojar soluciones autohospedadas ... además, requerirán mantenimiento adicional. La pareja que seleccionamos resultó ser la más cercana a
nuestras necesidades :
- soporte integrado y desarrollado para aplicaciones PHP (la pila de nuestros clientes es muy diversa, pero es un líder claro en el contexto de encontrar una alternativa a New Relic);
- costo asequible (menos de 100 USD por mes por host);
- instrumentación automática;
- Integración de Kubernetes
- La similitud con la interfaz New Relic es una ventaja notable (porque nuestros ingenieros están acostumbrados).
Por lo tanto, en la etapa de la selección inicial, eliminamos varias otras soluciones populares, y en particular:
- Tideways, AppDynamics y Dynatrace, por el precio;
- Stackify: está bloqueado en la Federación de Rusia y muestra muy pocos datos.
El artículo posterior está estructurado de tal manera que las soluciones bajo consideración se presentarán brevemente, después de lo cual hablaré sobre nuestra interacción típica con New Relic y la experiencia / impresiones de realizar operaciones similares en otros servicios.
Presentación de competidores seleccionados.

¿Probablemente todos escucharon sobre
New Relic ? Este servicio comenzó a desarrollarse hace más de 10 años, en 2008. Lo utilizamos activamente desde 2012 y no tuvimos problemas de integración con una gran cantidad de aplicaciones en PHP, Ruby y Python, y también tuvimos experiencia en la integración con C # y Go. Los autores del servicio tienen soluciones para monitorear la aplicación, la infraestructura, el rastreo de infraestructuras de microservicios, se han creado aplicaciones convenientes para dispositivos de usuario y mucho más.
Sin embargo, el agente New Relic funciona en protocolos propietarios, no tiene soporte OpenTracing. La instrumentación avanzada requiere ediciones específicas para New Relic. Finalmente, el soporte para Kubernetes tiene un estado experimental hasta ahora.
 Datadog
Datadog ,
que comenzó su desarrollo en 2010, parece notablemente más interesante que New Relic en términos de su uso en entornos Kubernetes. En particular, admite la integración con NGINX Ingress, la recopilación de registros, las estadísticas y los protocolos OpenTracing, lo que le permite rastrear una solicitud del usuario desde el momento en que se conecta al final del trabajo, así como encontrar registros para esta solicitud (tanto en el lado del servidor web como en el lado consumidor).
Cuando usamos Datadog, nos enfrentamos con el hecho de que a veces construía incorrectamente un mapa de microservicio y algunos defectos técnicos. Por ejemplo, determinó incorrectamente el tipo de servicio (tomó Django por un servicio de almacenamiento en caché) y causó los errores número 500 en una aplicación PHP usando la popular biblioteca Predis.
 Atatus
Atatus es el instrumento más joven; servicio lanzado en 2014. Su presupuesto de marketing es claramente inferior a los competidores listados, las menciones son mucho menos comunes. Sin embargo, la herramienta en sí es muy similar a New Relic, y no solo en características (APM, monitoreo del navegador, etc.), sino también en apariencia.
Un inconveniente importante es solo el soporte para Node.js y PHP. Por otro lado, se implementa mucho mejor que Datadog. A diferencia de este último, Atatus no requiere que las aplicaciones modifiquen o establezcan etiquetas adicionales en el código.
Cómo trabajamos con New Relic
Ahora veamos cómo usamos generalmente New Relic. Supongamos que tenemos un problema que necesita ser resuelto:
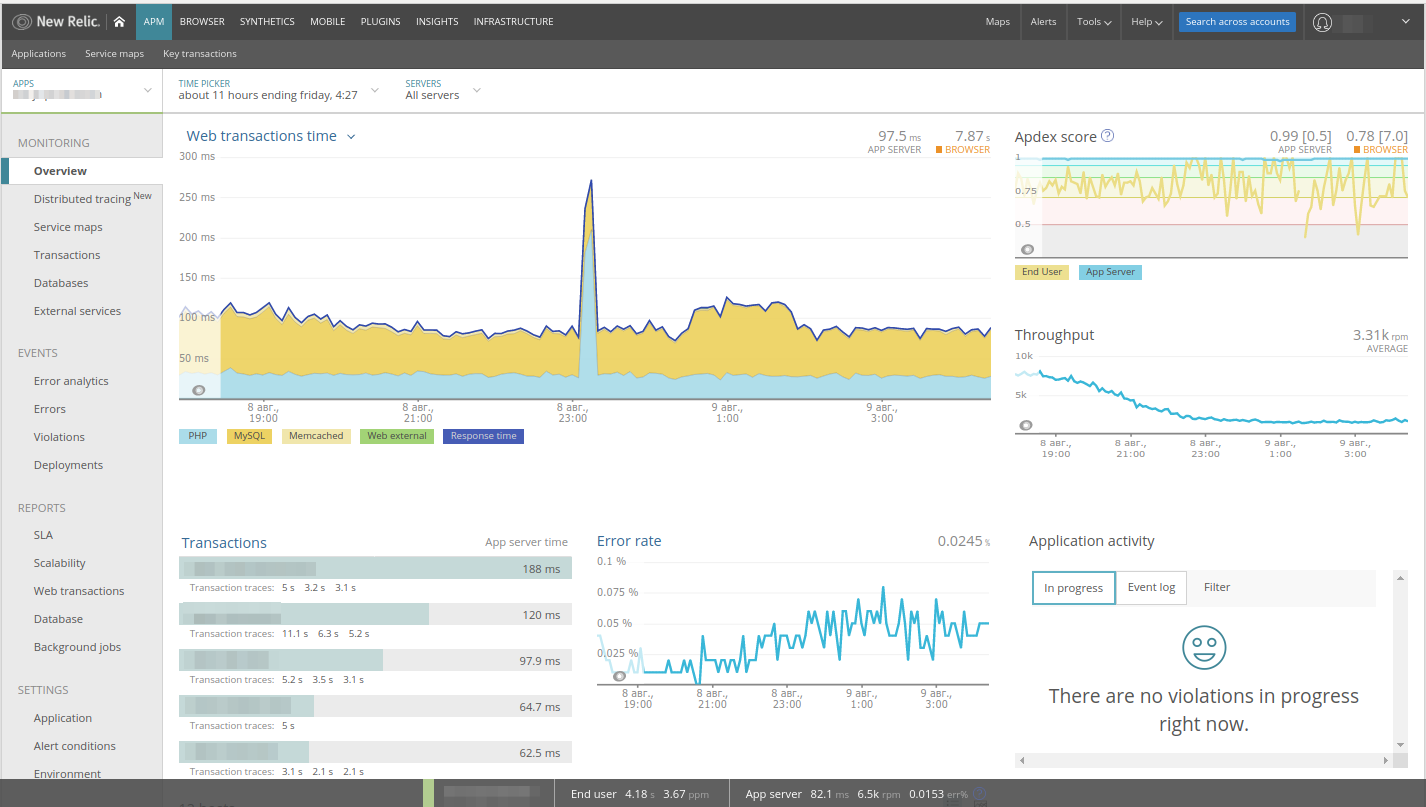
Es fácil notar un
aumento en el gráfico: lo analizamos. En New Relic, las transacciones web se seleccionan inmediatamente para la aplicación web, todos los componentes se indican en el gráfico de rendimiento, hay paneles de tasa de error, tasa de solicitud ... Lo más importante, directamente desde estos paneles puede moverse entre diferentes partes de la aplicación (por ejemplo, haciendo clic en MySQL a la sección de la base de datos).
Como en este ejemplo vemos un aumento en la actividad de
PHP , haga clic en este gráfico y vaya automáticamente a
Transacciones :
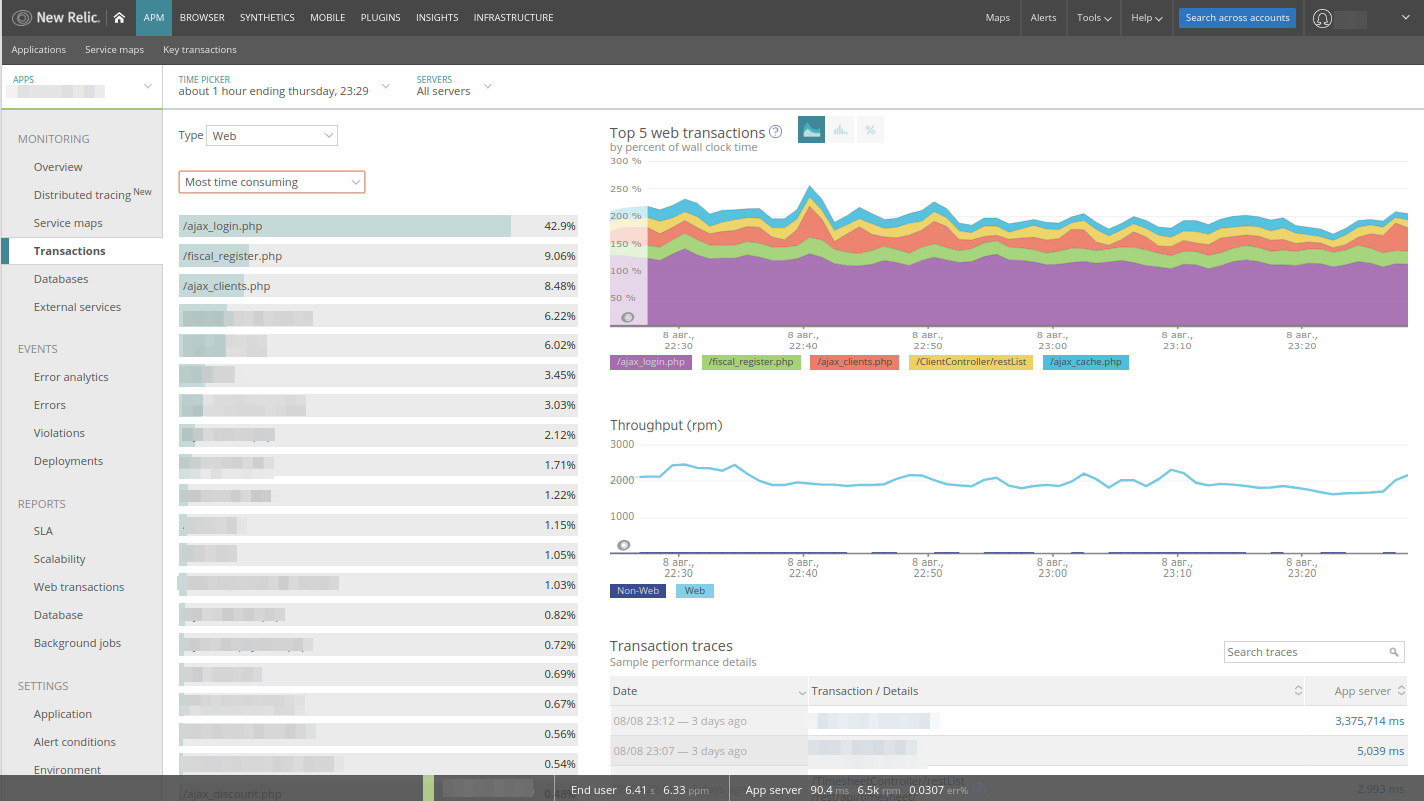
La lista de transacciones, que son esencialmente controladores del modelo MVC, ya está ordenada por la
mayoría de tiempo , lo cual es muy conveniente: vemos de inmediato lo que hace la aplicación. Aquí hay ejemplos de consultas largas que New Relic recopila automáticamente. Cambiar la clasificación es fácil de encontrar:
- el controlador de aplicación más cargado;
- El controlador más solicitado
- El más lento de los controladores.
Además, puede expandir cada transacción y ver qué estaba haciendo la aplicación en el momento de la ejecución del código:
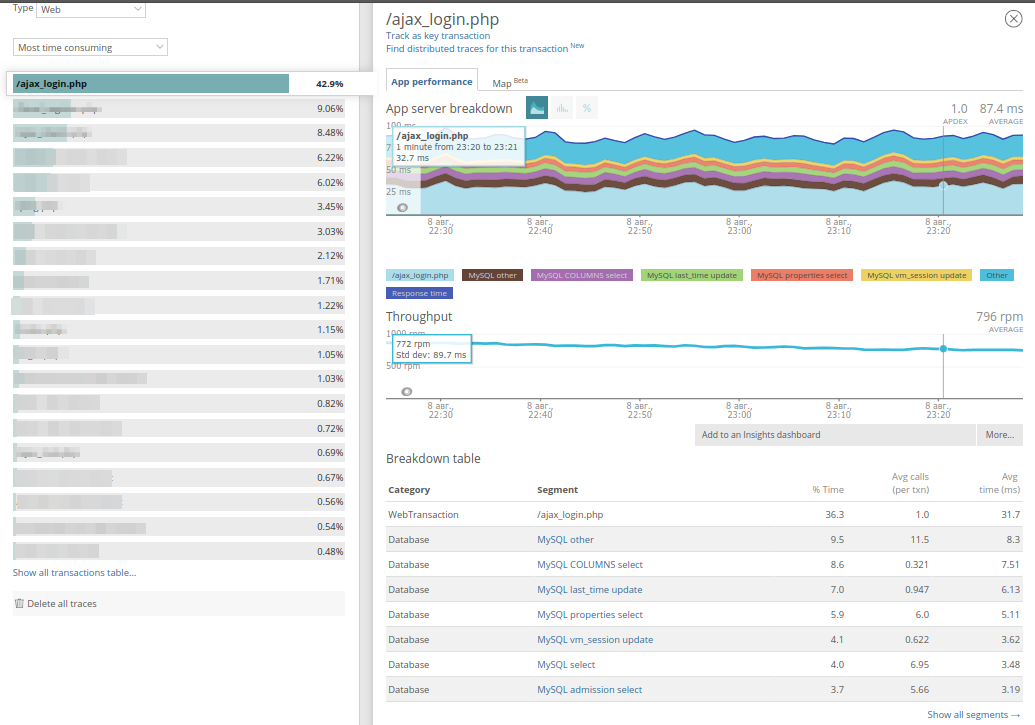
Finalmente, se guardan en la aplicación ejemplos de trazas de consultas largas (que funcionan durante más de 2 segundos). Aquí está el panel para una transacción larga:

Se puede ver que dos métodos toman mucho tiempo y, junto con el momento en que se ejecutó la solicitud, también se muestran su URI y dominio. Muy a menudo esto ayuda a encontrar la consulta en los registros. Al ir a los
detalles de Rastreo , puede ver desde dónde se llaman estos métodos:
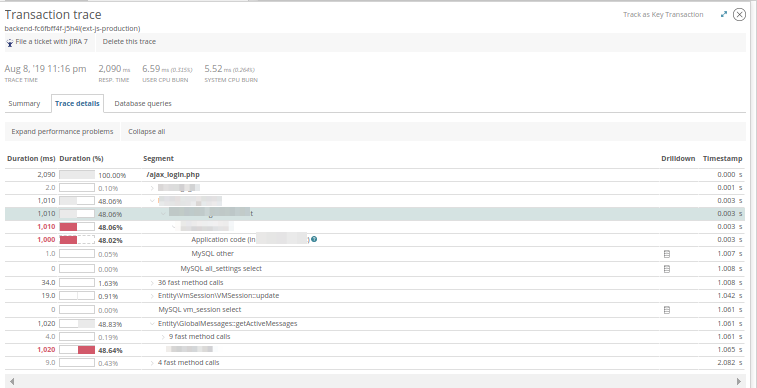
Y en las
consultas de la base de datos : evalúe las consultas de la base de datos que se ejecutaron en el momento de la aplicación:

Con este conocimiento, podemos evaluar la causa de la desaceleración de la aplicación y, junto con el desarrollador, desarrollar una estrategia para resolver el problema. En realidad, New Relic no siempre da una imagen clara, pero ayuda a elegir el vector de investigación:
- el largo
PDO::Construct nos condujo al extraño funcionamiento de pgpoll; - inestabilidad en el tiempo
Memcache::Get una configuración incorrecta sugerida de la máquina virtual; - el tiempo sospechosamente aumentado para procesar la plantilla condujo a un bucle anidado con una verificación de la presencia de 500 avatares en el almacenamiento de objetos;
- y así sucesivamente ...
También sucede que, en lugar de ejecutar código en la pantalla principal, crece algo relacionado con el almacenamiento externo de datos, y no importa cuál sea: Redis o PostgreSQL, todos están ocultos en la pestaña
Bases de datos .

Puede seleccionar una base específica para la investigación y ordenar las consultas, de forma similar a cómo se hace en Transacciones. Y yendo a la pestaña de solicitud, puede ver cuánto se encuentra esta solicitud en cada uno de los controladores de la aplicación, así como evaluar con qué frecuencia se llama. Esto es muy conveniente:
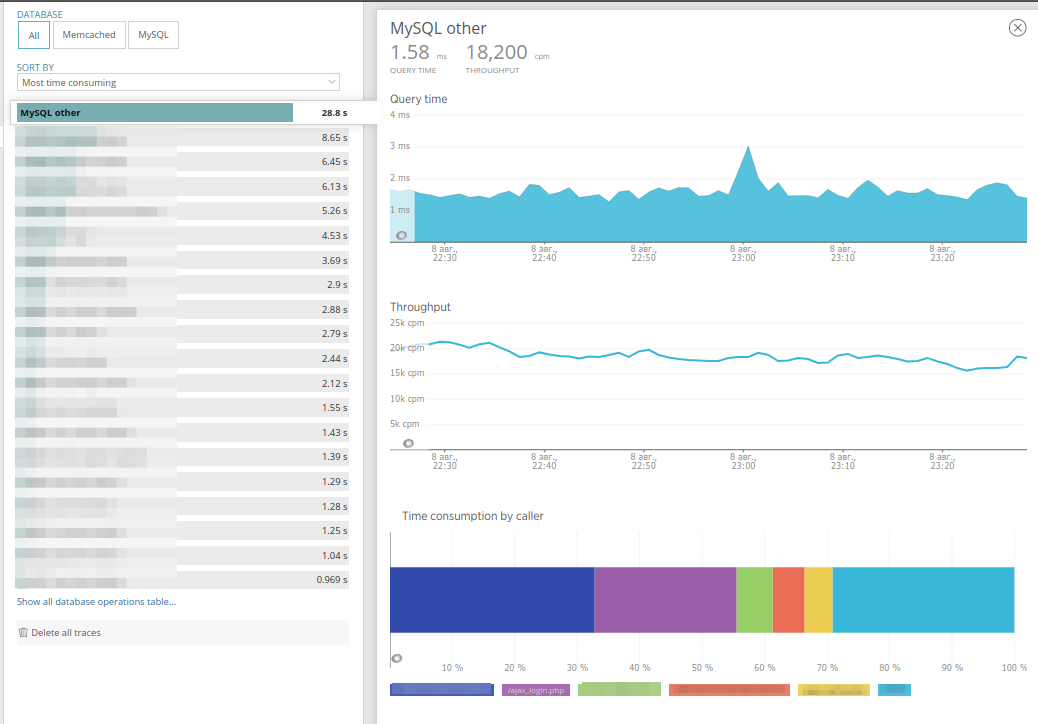
La pestaña
Servicios externos contiene datos similares, que ocultan las solicitudes de servicios HTTP externos, como acceder al almacén de objetos, enviar eventos a centinela o similares. Por su contenido, la pestaña es completamente similar a las Bases de datos:

Competidores: oportunidades e impresiones
Ahora lo más interesante es comparar las capacidades de New Relic con lo que ofrecen los competidores. Desafortunadamente, no pudimos probar las tres herramientas en la misma versión de una aplicación que se ejecuta en producción. Sin embargo, tratamos de comparar las situaciones / configuraciones más idénticas.
1. Datadog
Datadog nos saluda con un panel con un muro de servicios:
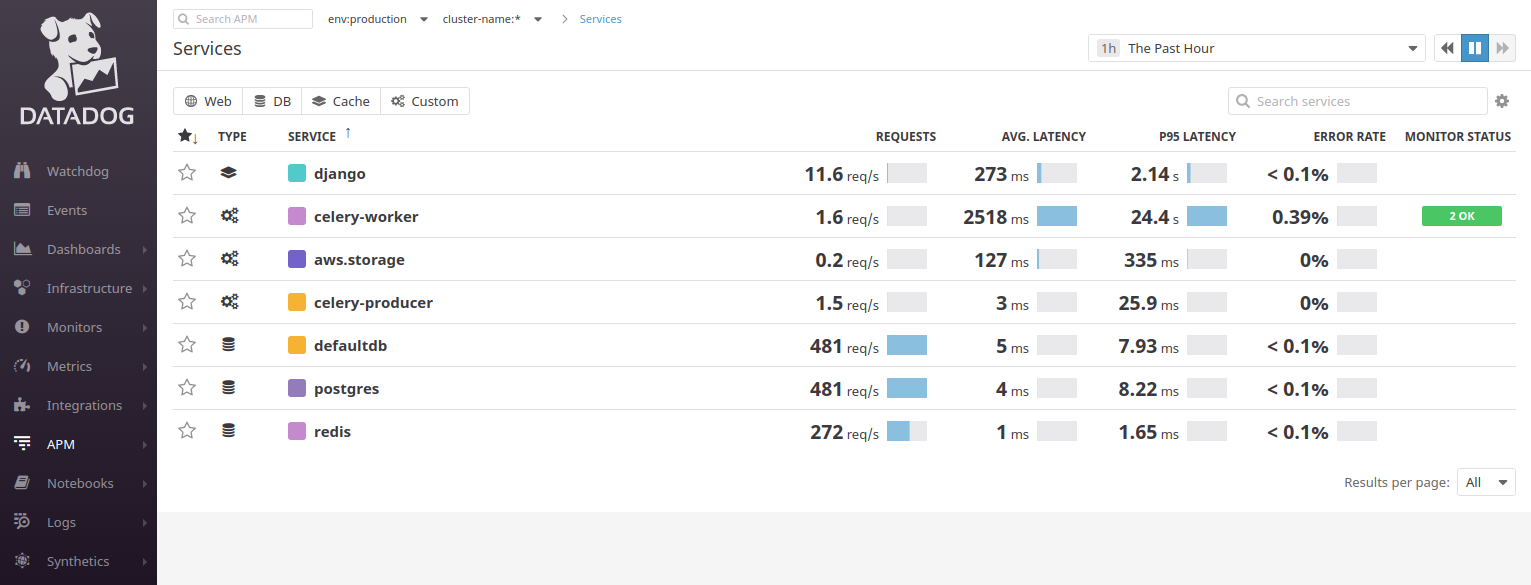
Está tratando de dividir las aplicaciones en componentes / microservicios, por lo que en la aplicación de ejemplo Django vemos 2 conexiones a PostgreSQL (
defaultdb y
postgres ), así como a Celery, Redis. Trabajar con Datadog requiere que tenga un conocimiento mínimo de los principios de MVC: debe comprender de dónde provienen las solicitudes de los usuarios. Por lo general,
un mapa de servicio ayuda con esto:

Por cierto, hay algo similar en New Relic:
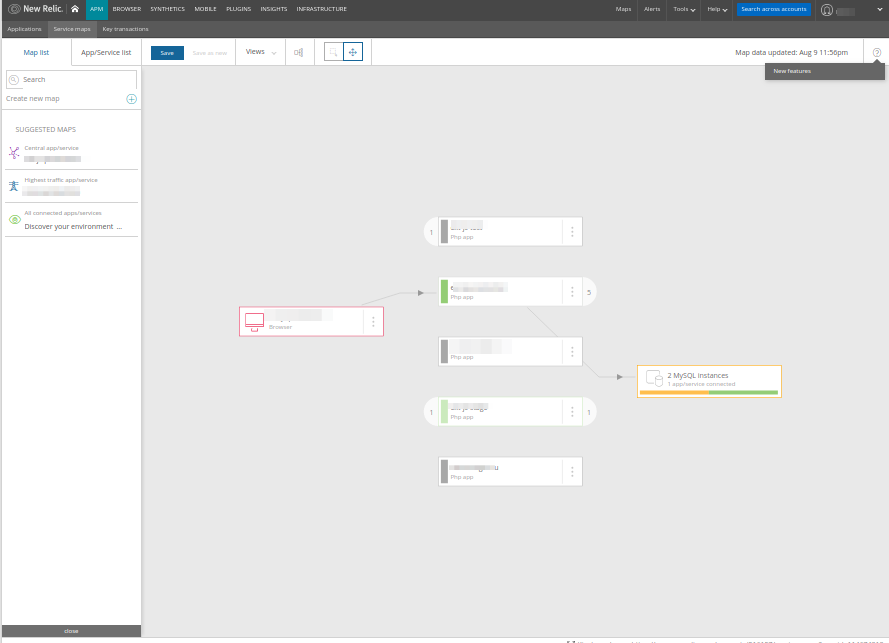
... además, su mapa, en mi opinión, se hace más simple y más comprensible: no muestra los componentes de una aplicación (lo que lo haría innecesariamente detallado, como en el caso de Datadog), sino solo servicios o microservicios específicos.
Regresando a Datadog: del mapa de servicios queda claro que las solicitudes de los usuarios llegan a Django. Vayamos al servicio de Django y finalmente veamos lo que esperábamos:
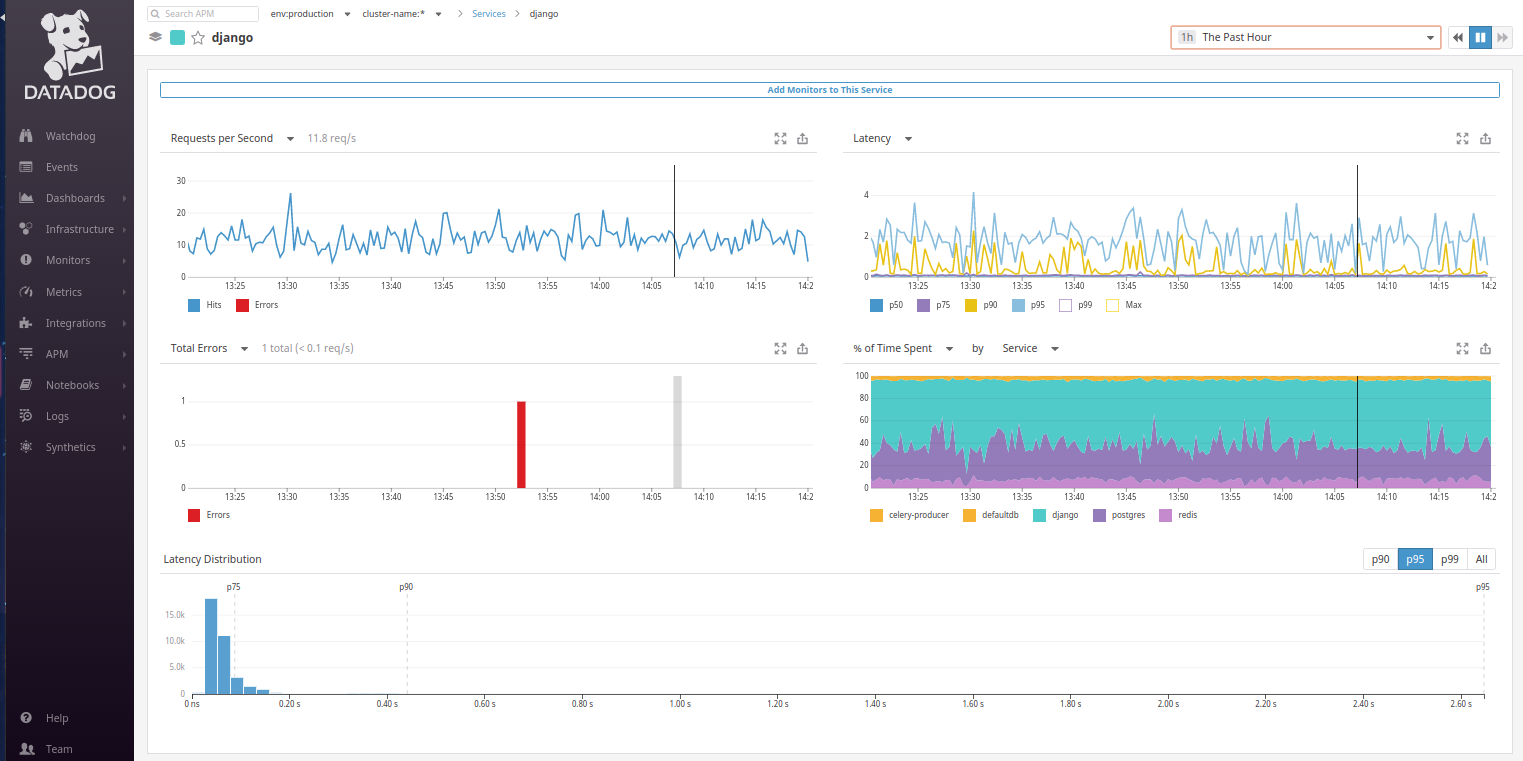
Desafortunadamente, por defecto no hay
un gráfico de
tiempo de transacción web similar a lo que vemos en el panel principal de New Relic. Sin embargo, se puede configurar en lugar del gráfico
de% de tiempo empleado . Es suficiente cambiarlo a
Tiempo promedio por solicitud por tipo ... ¡y ahora el gráfico familiar nos mira!
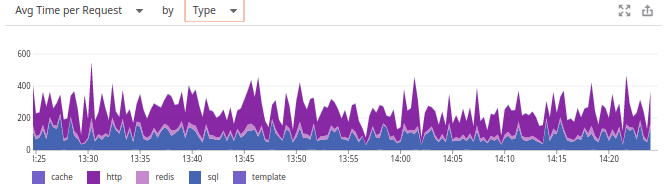
Por qué Datadog optó por un horario diferente es un misterio para nosotros. También fue frustrante que el sistema no recuerde la elección del usuario (a diferencia de ambos competidores) y, por lo tanto, solo se guarda la creación de paneles personalizados.
Pero me complació la oportunidad en Datadog de cambiar de estos gráficos a las métricas de los servidores relacionados, leer los registros y evaluar la carga de los controladores del servidor web (Gunicorn). ¡Todo es casi igual que en New Relic ... e incluso algunos más (registros)!
Debajo de las tablas hay transacciones que son completamente similares a New Relic:
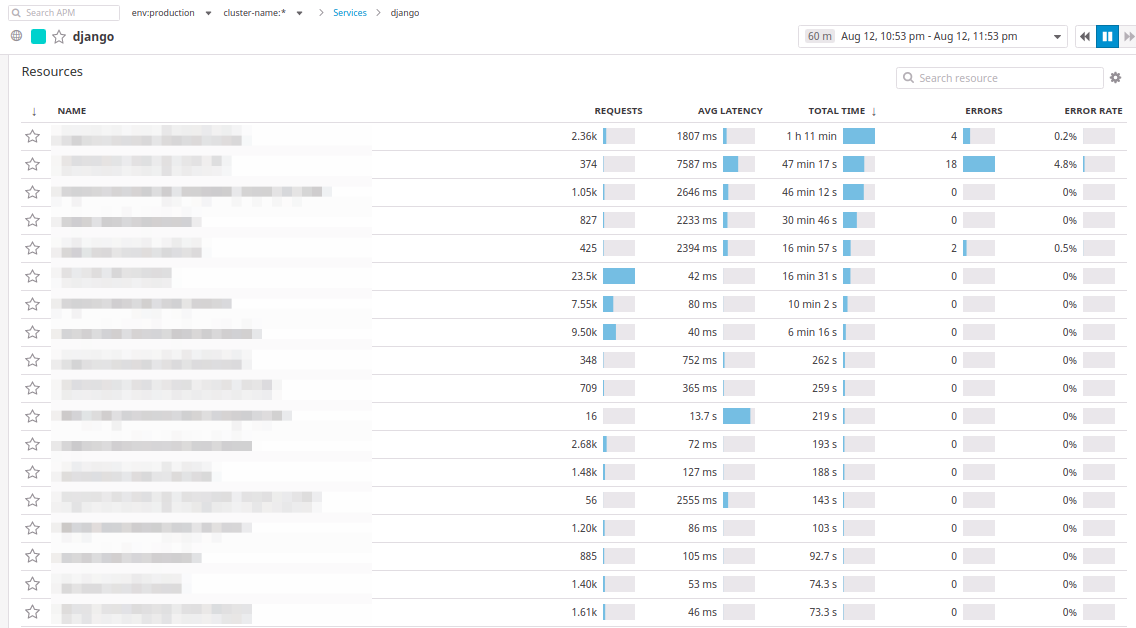
En Datadog, las transacciones se llaman
recursos . Puede ordenar los controladores por el número de solicitudes, por el tiempo de respuesta promedio, por el tiempo máximo transcurrido durante un período de tiempo seleccionado.
Puedes expandir el recurso y ver todo lo que ya hemos observado en New Relic:
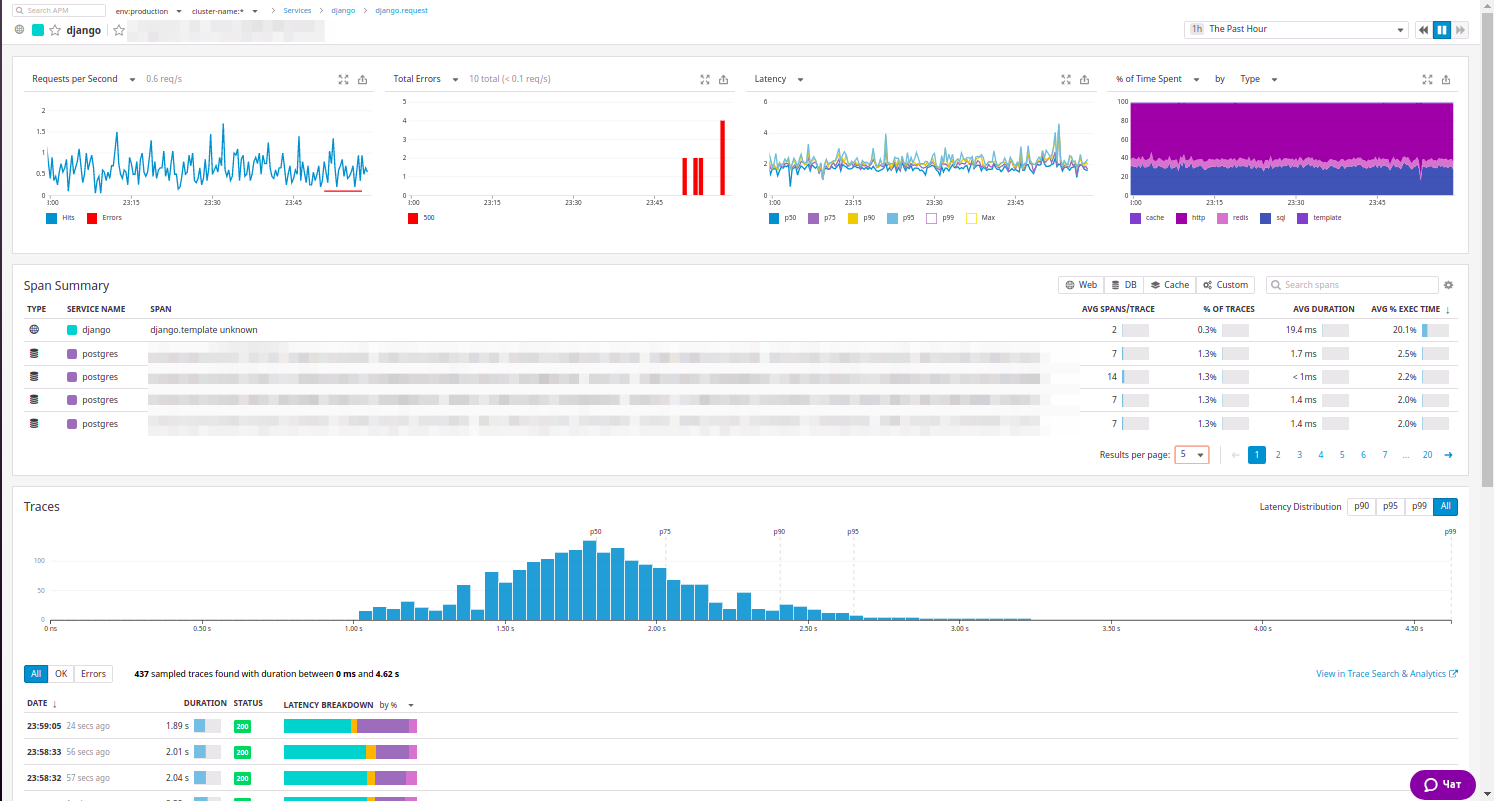
Hay estadísticas sobre el recurso, y una lista generalizada de llamadas internas, y ejemplos de solicitudes que se pueden ordenar por el código de respuesta ... Por cierto, a nuestros ingenieros realmente les gustó esta clasificación.
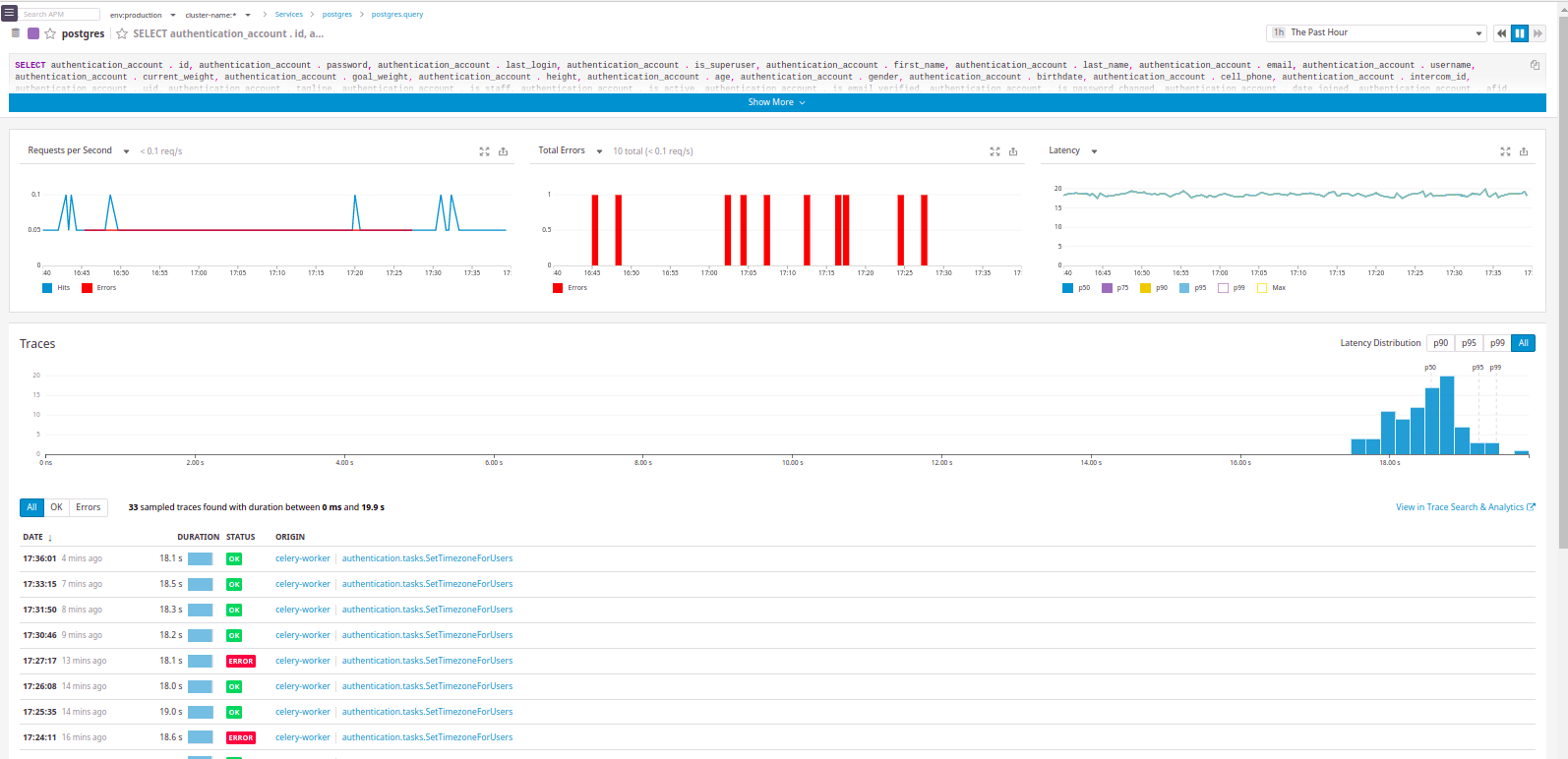
Cualquier recurso de ejemplo en Datadog se puede expandir y explorar:

Se presentan los parámetros de consulta, un diagrama de resumen del tiempo transcurrido para cada uno de los componentes y un diagrama en cascada en el que se muestra la secuencia de llamadas. Además, también está disponible el cambio a la vista de árbol del diagrama de cascada:

Y lo más interesante es ver la carga del host en el que se ejecutó la solicitud y ver los registros de la solicitud.
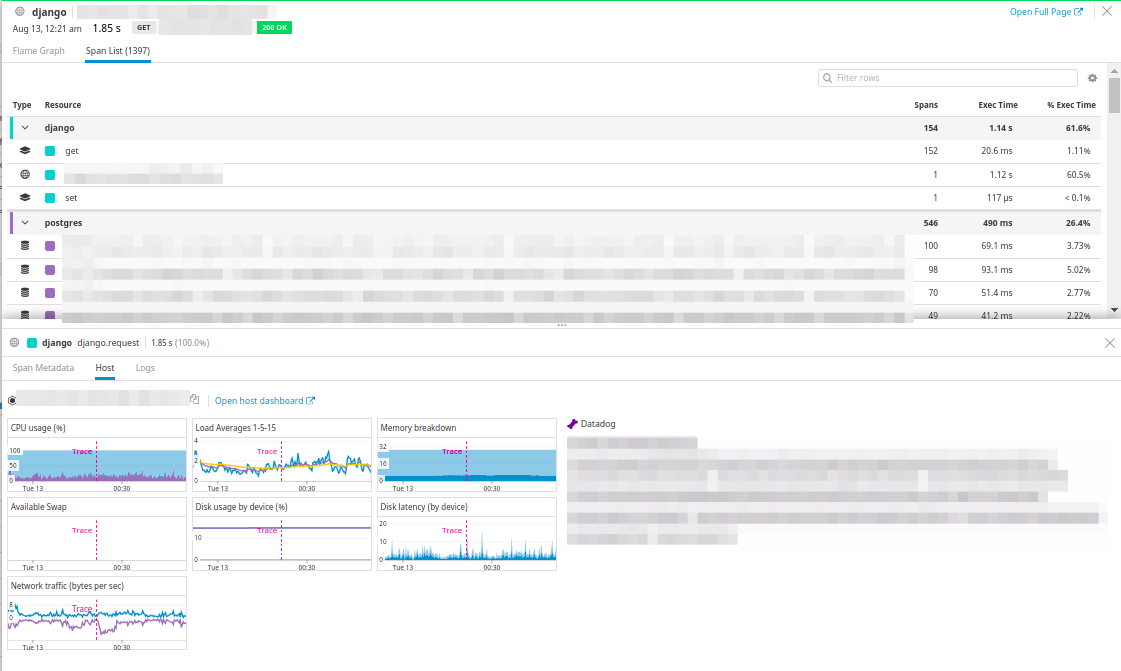
¡Gran integración!
Quizás se pregunte dónde están las pestañas
Bases de datos y
Servicios externos , como en New Relic. No están aquí: dado que Datadog analiza la aplicación en componentes, PostgreSQL se considerará un
servicio separado y, en lugar de Servicios externos, vale la pena buscar
aws.storage (será lo mismo para todos los demás servicios externos a los que la aplicación pueda acceder).

Y aquí hay un ejemplo con
postgres :
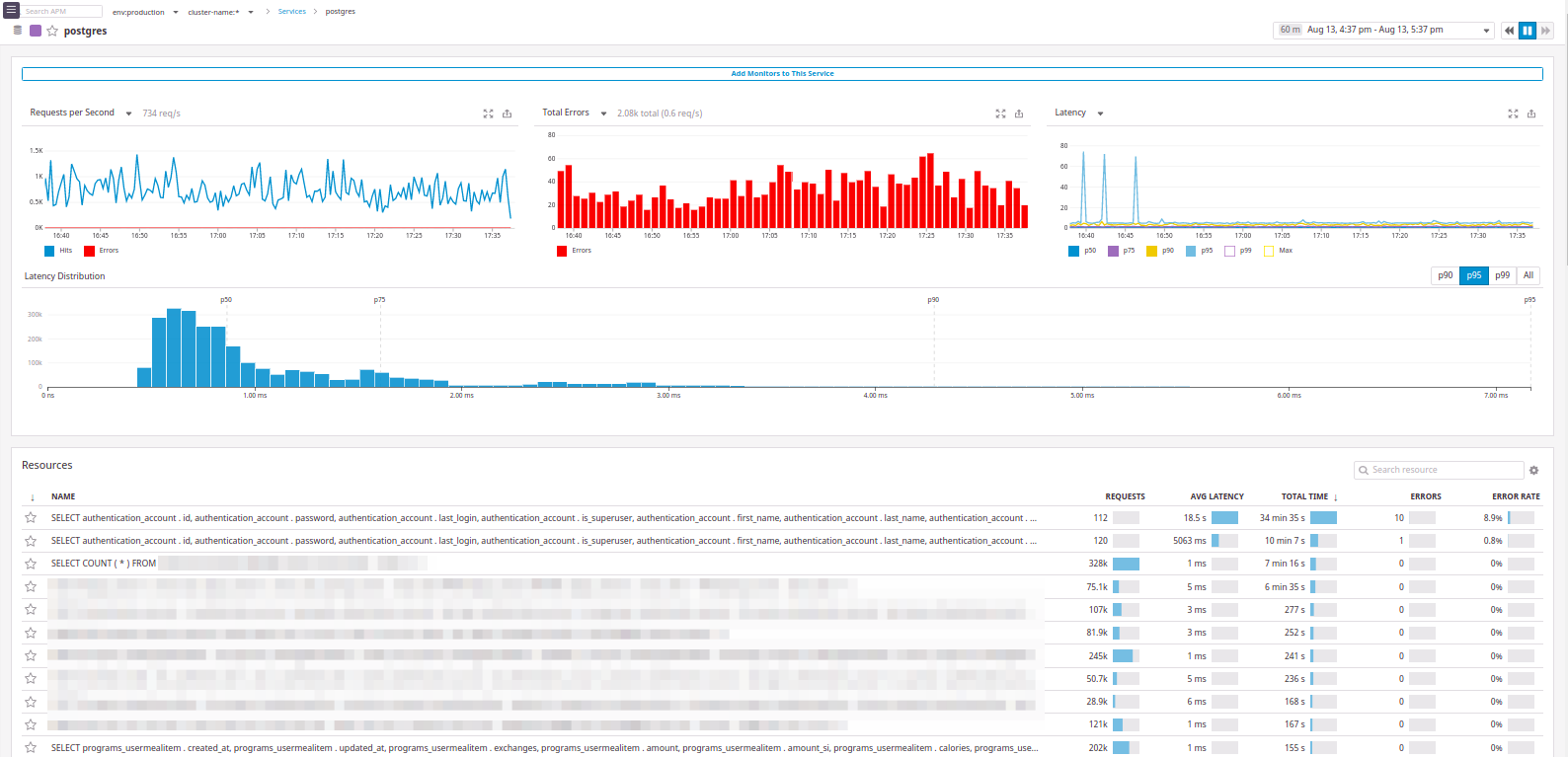
De hecho, hay todo lo que queríamos:
Se puede ver de qué "servicio" vino la solicitud.
No será superfluo recordar que Datadog se integra perfectamente con NGINX Ingress y permite el rastreo de extremo a extremo desde el momento en que llega una solicitud al clúster, y también le permite aceptar métricas estadísticas, recopilar registros y métricas de host.
Una gran ventaja de Datadog es que su precio
consiste en la infraestructura de monitoreo, APM, gestión de registros y pruebas sintéticas, es decir. Puede elegir un plan de manera flexible.
2. Atatus
El equipo de Atatus afirma que su servicio es "igual que New Relic, pero mejor". Veamos si esto es realmente así.
La barra de título realmente se ve igual, pero no fue posible determinar el Redis y la memoria caché utilizada en la aplicación.
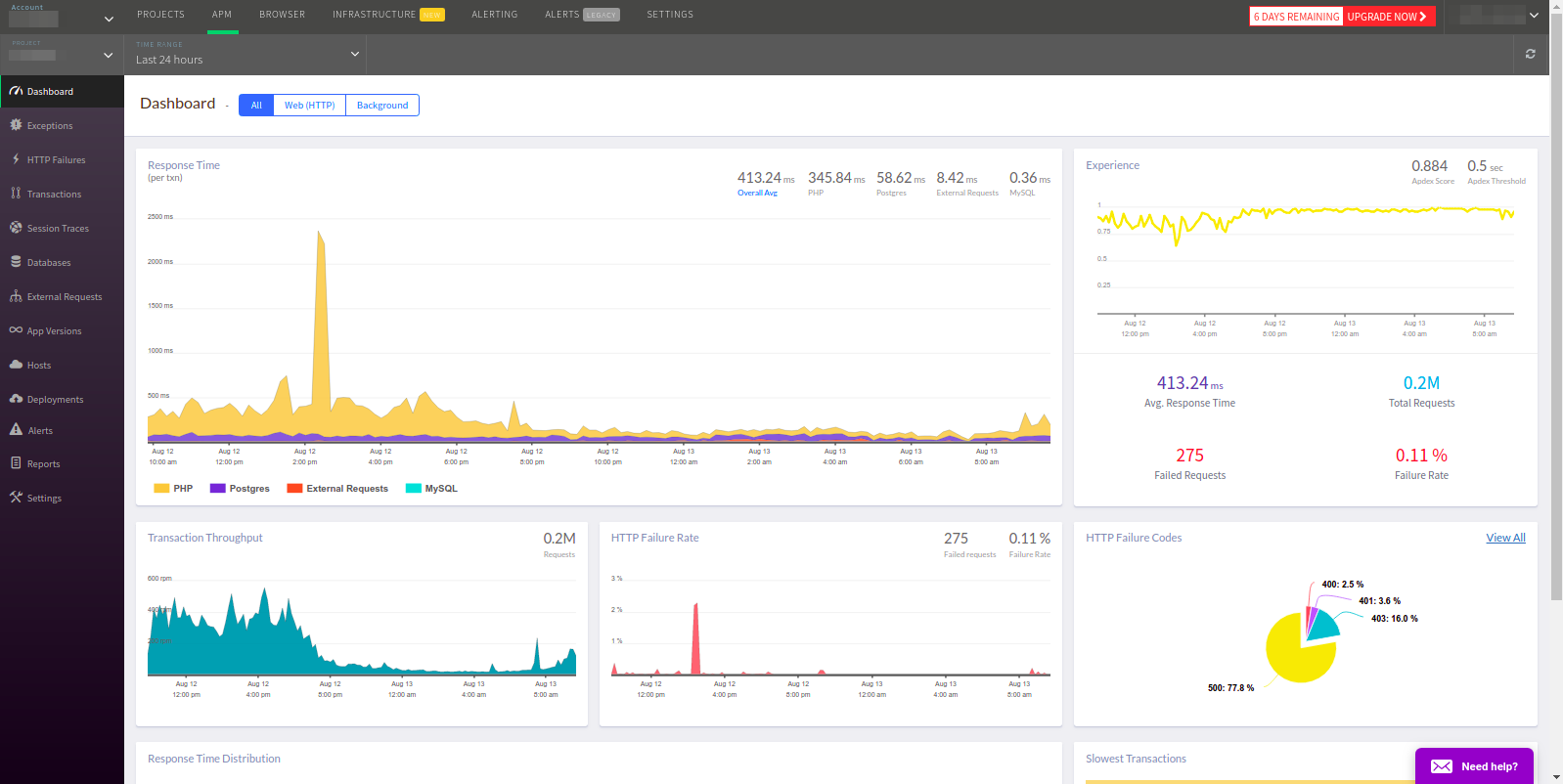
APM selecciona todas las transacciones de forma predeterminada, aunque normalmente solo se necesita la Web. Como en Datadog, no hay forma de acceder al servicio deseado desde el panel principal. Además, las transacciones se enumeran después de los errores, lo que para APM no parece muy lógico.
En las transacciones de Atatus, todo es lo más similar posible a New Relic. Menos: no puede ver de inmediato la dinámica de cada uno de los controladores. Debe buscarlo en la tabla del controlador, ordenando por
Consumo de tiempo más :

La lista habitual de controladores está disponible en la pestaña
Explorar :
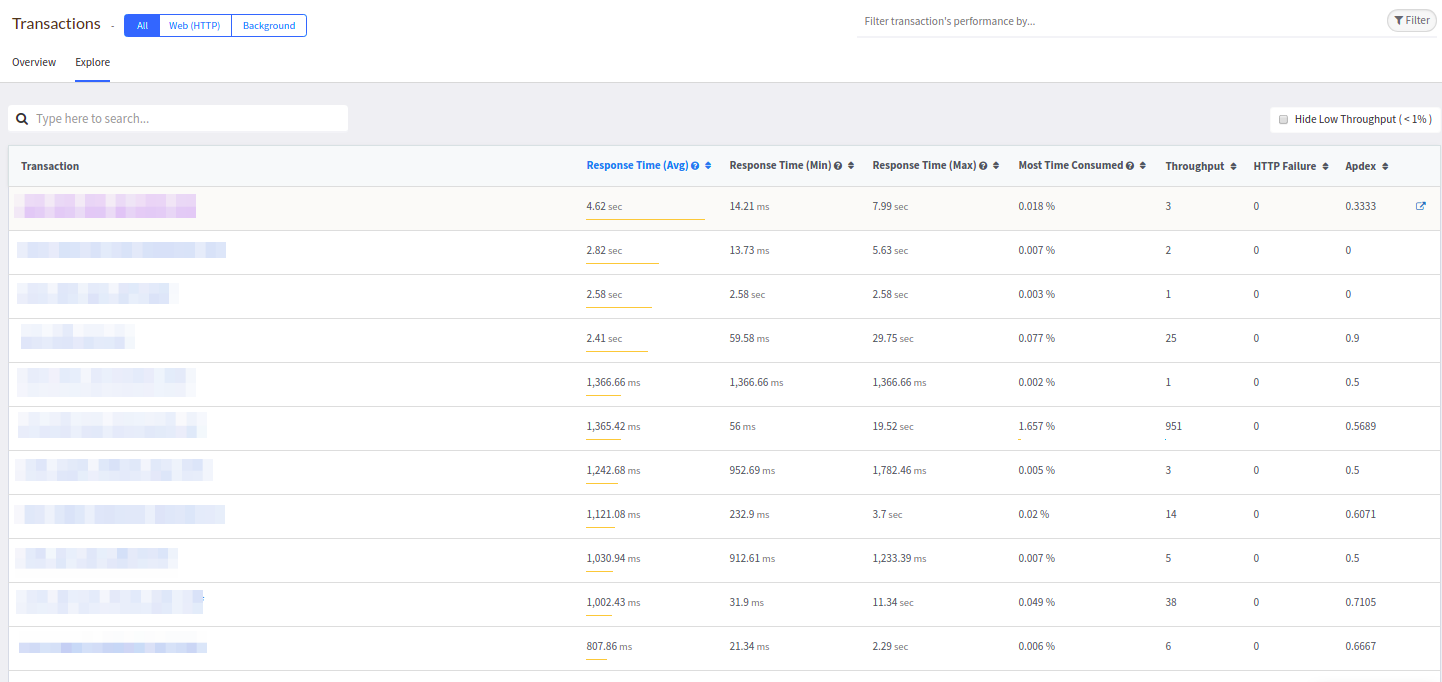
De alguna manera, esta tabla se parece a Datadog y se parece más a la de New Relic.
Cada transacción se puede implementar y ver qué hizo la aplicación:

El panel también se parece más a Datadog: hay una serie de solicitudes, una imagen general de las llamadas. El panel superior proporciona una pestaña con errores de
Fallos HTTP y ejemplos de solicitudes lentas de Rastreo de
sesiones :

Si entra en una transacción, ve un ejemplo de rastreo, puede obtener una lista de consultas a la base de datos y ver los encabezados de las solicitudes. Todo es similar a New Relic:

En general, Atatus está satisfecho con los rastros detallados, sin el típico pegado de llamadas New Relic en un bloque recordatorio:
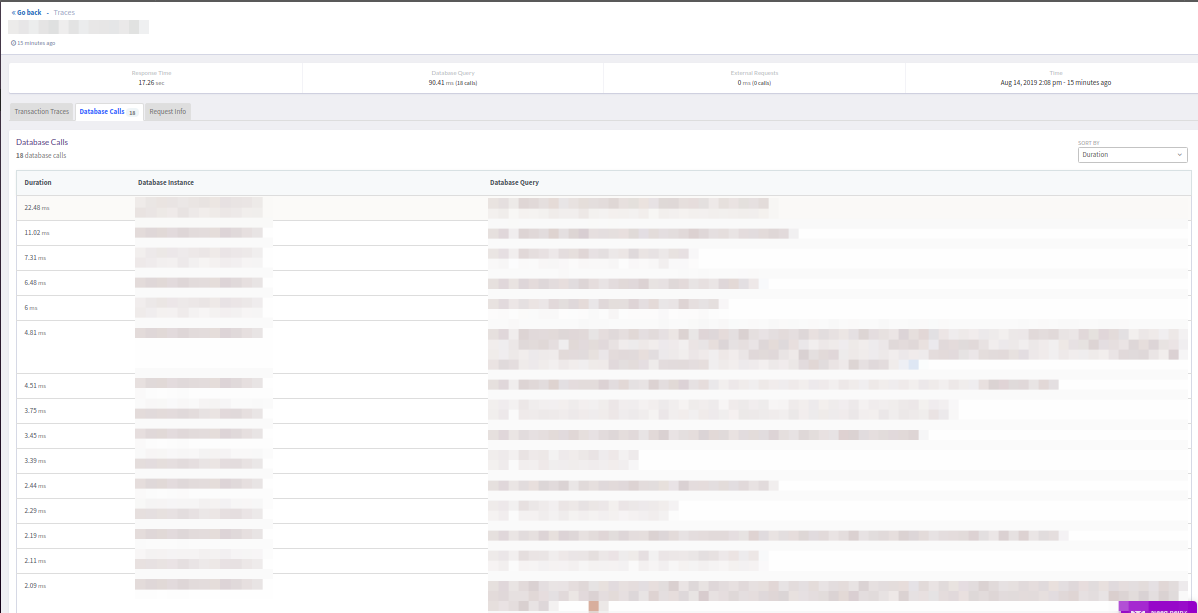
Sin embargo, no hay suficiente filtro que pueda (como en New Relic) cortar las solicitudes ultrarrápidas (<5 ms). Por otro lado, mostrar la respuesta final de la transacción (exitoso o error) fue agradable.
El panel
Bases de datos lo ayudará a examinar las solicitudes a bases de datos externas que realiza la aplicación. Permítame recordarle que Atatus solo encontró PostgreSQL y MySQL, aunque Redis y memcached también están involucrados en el proyecto.
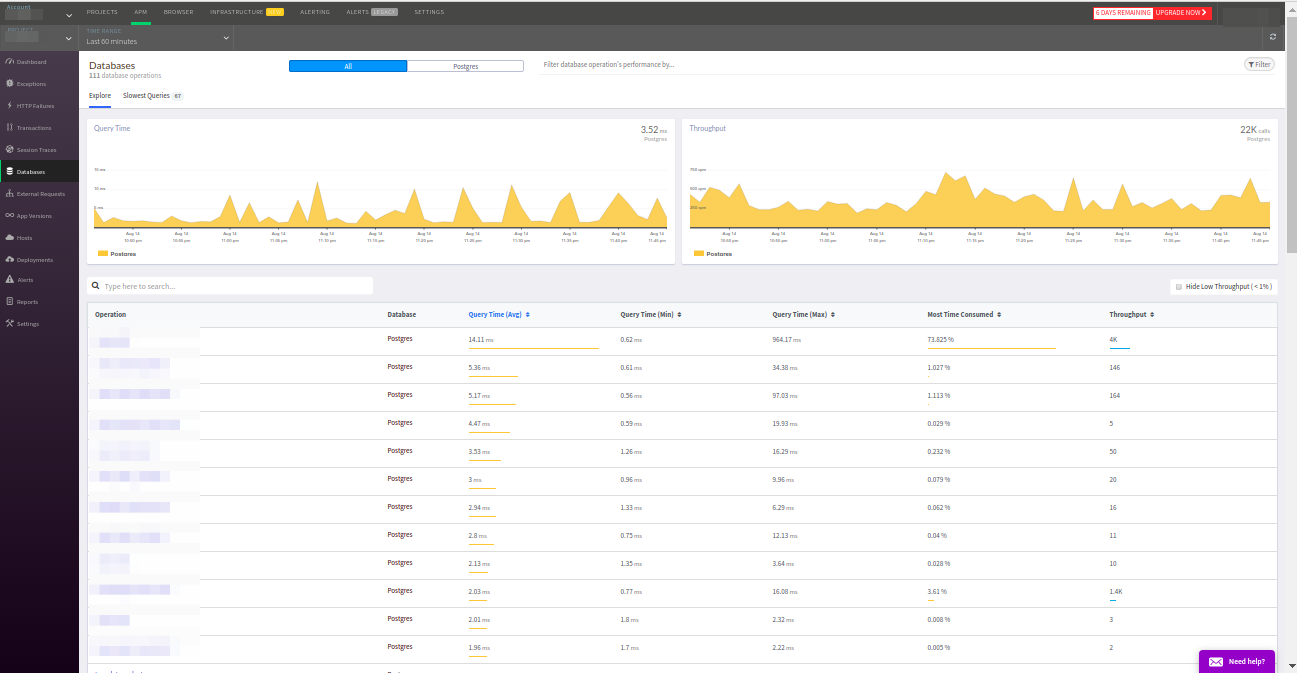
Las solicitudes se ordenan según los criterios habituales: frecuencia de respuesta, tiempo de respuesta promedio, etc. También me gustaría señalar la pestaña con las consultas más lentas, esto es muy conveniente. Además, los datos en esta pestaña para PostgreSQL coincidieron con los datos de la extensión
pg_stat_statements , ¡un resultado excelente!
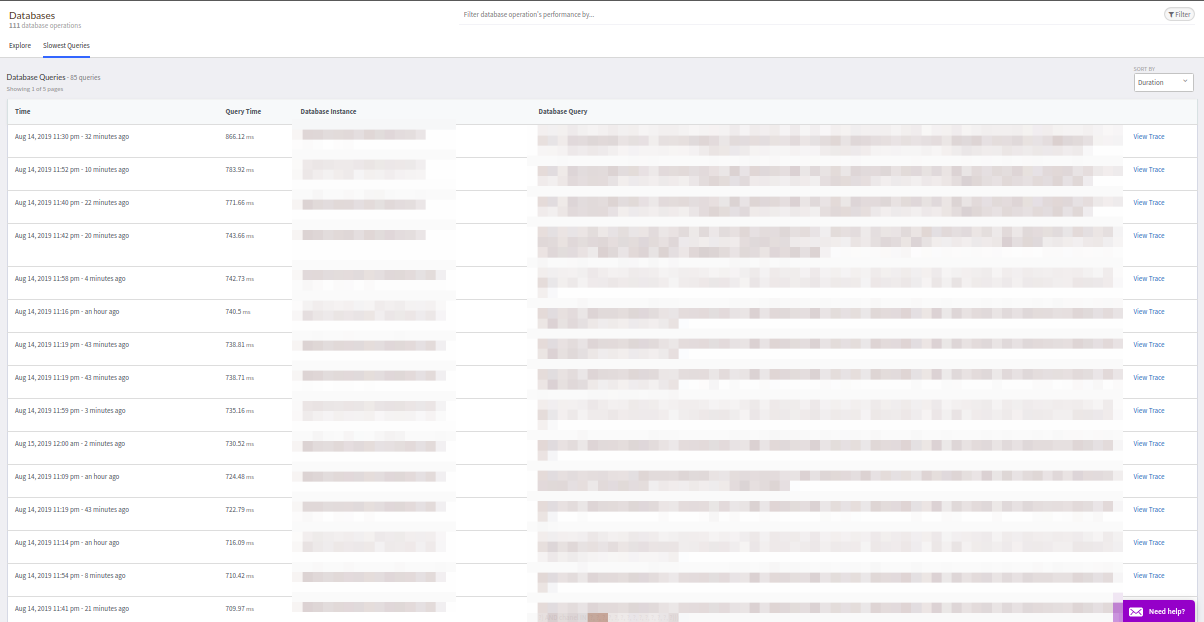
La pestaña
Solicitudes externas es idéntica a las Bases de datos.
Conclusiones
Las dos herramientas presentadas se desempeñaron bien en el papel de APM. Cualquiera de ellos puede ofrecer el mínimo necesario. Resuma brevemente nuestras impresiones de la siguiente manera:
Datadog
Pros:
- conveniente programa de tarifas (APM cuesta 31 USD por host);
- funcionó bien con Python;
- capacidad de integrarse con OpenTracing
- Integración de Kubernetes
- Integración con NGINX Ingress.
Contras:
- El único APM que causó la inaccesibilidad de la aplicación debido a un error del módulo (predis)
- herramientas automáticas PHP débiles;
- Definición en parte extraña de los servicios y su propósito.
Estado
Pros:
- instrumentación profunda de PHP;
- Nueva interfaz de usuario tipo reliquia.
Contras:
- no funciona en sistemas operativos más antiguos (Ubuntu 12.05, CentOS 5);
- herramientas automáticas débiles;
- soporte para solo dos idiomas (Node.js y PHP);
- Operación lenta de la interfaz.
Dado el precio de Atatus de 69 USD por mes por servidor, preferimos usar Datadog, que se integra perfectamente para nuestras necesidades (aplicaciones web en K8) y tiene muchas características útiles.
PS
Lea también en nuestro blog: