
En este artículo, me gustaría proponer una alternativa al estilo de diseño de prueba tradicional utilizando conceptos de programación funcional en Scala. Este enfoque se inspiró en muchos meses de dolor por mantener docenas de exámenes fallidos y un deseo ardiente de hacerlos más directos y más comprensibles.
Aunque el código está en Scala, las ideas propuestas son apropiadas para desarrolladores e ingenieros de control de calidad que usan lenguajes que admiten programación funcional. Puede encontrar un enlace de Github con la solución completa y un ejemplo al final del artículo.
El problema
Si alguna vez tuvo que lidiar con pruebas (no importa cuáles: pruebas unitarias, integrales o funcionales), probablemente se escribieron como un conjunto de instrucciones secuenciales. Por ejemplo:
En mi experiencia, esta forma de escribir pruebas es preferida por la mayoría de los desarrolladores. Nuestro proyecto tiene alrededor de mil pruebas en diferentes niveles de aislamiento, y todas fueron escritas con este estilo hasta hace poco. A medida que el proyecto creció, comenzamos a notar problemas graves y retrasos en el mantenimiento de tales pruebas: solucionarlos tomaría al menos la misma cantidad de tiempo que escribir el código de producción.
Al escribir nuevas pruebas, siempre teníamos que encontrar formas de preparar los datos desde cero, generalmente copiando y pegando los pasos de las pruebas vecinas. Como resultado, cuando el modelo de datos de la aplicación cambiara, el castillo de naipes se derrumbaría y tendríamos que reparar cada prueba fallida: en el peor de los casos, profundizando en cada prueba y reescribiéndola.
Cuando una prueba fallaba "honestamente", es decir, debido a un error real en la lógica empresarial, era imposible comprender qué salió mal sin depurar. Debido a que las pruebas eran tan difíciles de entender, nadie tenía el conocimiento completo sobre cómo se supone que debe comportarse el sistema.
Todo este dolor, en mi opinión, es un síntoma de los dos problemas más profundos de este diseño de prueba:
- No existe una estructura clara y práctica para las pruebas. Cada prueba es un copo de nieve único. La falta de estructura conduce a la verbosidad, que consume mucho tiempo y desmotiva. Detalles insignificantes distraen de lo que es más importante: el requisito que afirma la prueba. Copiar y pegar se convierte en el enfoque principal para escribir nuevos casos de prueba.
- Las pruebas no ayudan a los desarrolladores a localizar defectos; solo indican que hay un problema de algún tipo. Para comprender el estado en el que se ejecuta la prueba, debe trazarla en su cabeza o usar un depurador.
Modelado
¿Podemos hacerlo mejor? (Alerta de spoiler: podemos). Consideremos qué tipo de estructura puede tener esta prueba.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Como regla general, el código bajo prueba espera algunos parámetros explícitos (identificadores, tamaños, cantidades, filtros, por nombrar algunos), así como algunos datos externos (de una base de datos, cola o algún otro servicio del mundo real). Para que nuestra prueba se ejecute de manera confiable, necesita un elemento fijo : un estado para colocar el sistema, los proveedores de datos o ambos.
Con este accesorio, preparamos una dependencia para inicializar el código bajo prueba: llenar una base de datos, crear una cola de un tipo particular, etc.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Después de ejecutar el código bajo prueba en algunos parámetros de entrada, recibimos una salida , tanto explícita (devuelta por el código bajo prueba) como implícita (los cambios en el estado).
result shouldBe 90
Finalmente, verificamos que el resultado es el esperado, terminando la prueba con una o más aserciones .
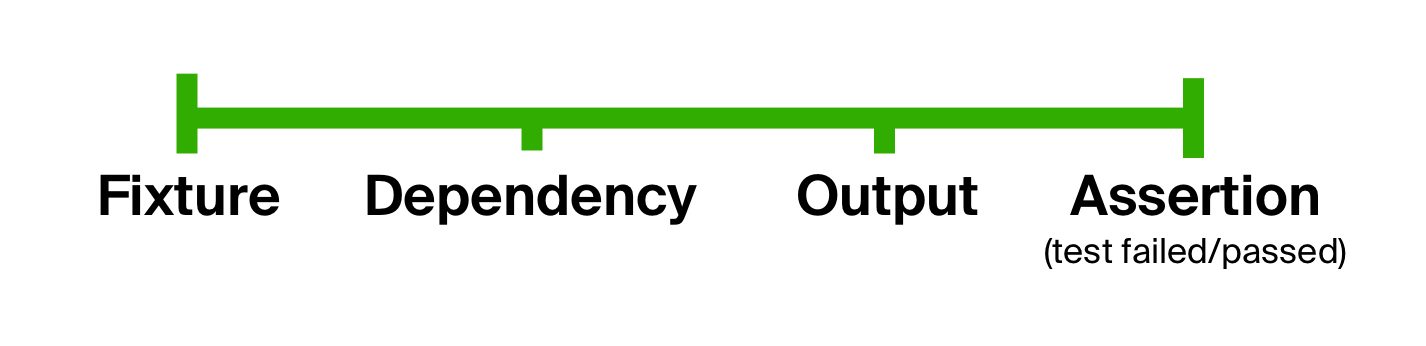
Se puede concluir que las pruebas generalmente consisten en las mismas etapas: preparación de entrada, ejecución de código y afirmación de resultados. Podemos utilizar este hecho para deshacernos del primer problema de nuestras pruebas , es decir, una forma demasiado liberal, dividiendo explícitamente el cuerpo de una prueba en etapas. Tal idea no es nueva, como se puede ver en las pruebas de estilo BDD ( desarrollo basado en el comportamiento ).
¿Qué pasa con la extensibilidad? Cualquier paso del proceso de prueba puede, a su vez, contener cualquier cantidad de intermedios. Por ejemplo, podríamos dar un paso grande y complicado, como construir un accesorio y dividirlo en varios, encadenados uno tras otro. De esta manera, el proceso de prueba puede ser infinitamente extensible, pero en última instancia siempre consta de los mismos pocos pasos generales.

Ejecutando pruebas
Intentemos implementar la idea de dividir la prueba en etapas, pero primero, debemos determinar qué tipo de resultado nos gustaría ver.
En general, nos gustaría escribir y mantener pruebas para que sea menos laborioso y más agradable. Cuantas menos instrucciones explícitas y no únicas tenga una prueba, menos cambios tendrían que realizarse después de cambiar los contratos o la refactorización, y menos tiempo tomaría leer la prueba. El diseño de la prueba debe promover la reutilización de fragmentos de código comunes y desalentar la copia y el pegado sin sentido. También sería bueno que las pruebas tuvieran una forma unificada. La previsibilidad mejora la legibilidad y ahorra tiempo. Por ejemplo, imagine cuánto tiempo más le tomaría a los aspirantes a científicos aprender todas las fórmulas si los libros de texto los escribieran libremente en un lenguaje común en lugar de las matemáticas.
Por lo tanto, nuestro objetivo es ocultar cualquier cosa que distraiga e innecesaria, dejando solo lo que es de importancia crítica para la comprensión: lo que se está probando, cuáles son las entradas y salidas esperadas.
Volvamos a nuestro modelo de la estructura de la prueba.
Técnicamente, cada paso puede representarse mediante un tipo de datos y cada transición, mediante una función. Es posible pasar del tipo de datos inicial al último aplicando cada función al resultado del anterior. En otras palabras, mediante el uso de la composición de funciones de preparación de datos (llamémosla prepare ), ejecución de código ( execute ) y verificación del resultado esperado ( check ). La entrada para esta composición sería el primer paso: el accesorio. Llamemos a la función de orden superior resultante la función de ciclo de vida de prueba .
Prueba de la función del ciclo de vida def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Surge una pregunta, ¿de dónde vienen estas ciertas funciones? Bueno, en cuanto a la preparación de datos, solo hay una cantidad limitada de formas de hacerlo: llenar una base de datos, burlarse, etc. Por lo tanto, es útil escribir variantes especializadas de la función de prepare compartida en todas las pruebas. Como resultado, sería más fácil realizar funciones de ciclo de vida de prueba especializadas para cada caso, lo que ocultaría implementaciones concretas de preparación de datos. Dado que la ejecución de código y las aserciones son más o menos únicas para cada prueba (o grupo de pruebas), la execute y la check deben escribirse explícitamente cada vez.
Función de ciclo de vida de prueba adaptada para pruebas de integración en una base de datos Al delegar todos los matices administrativos a la función del ciclo de vida de la prueba, tenemos la capacidad de extender el proceso de prueba sin tocar ninguna prueba dada. Al utilizar la composición de funciones, podemos interferir en cualquier paso del proceso y extraer o agregar datos.
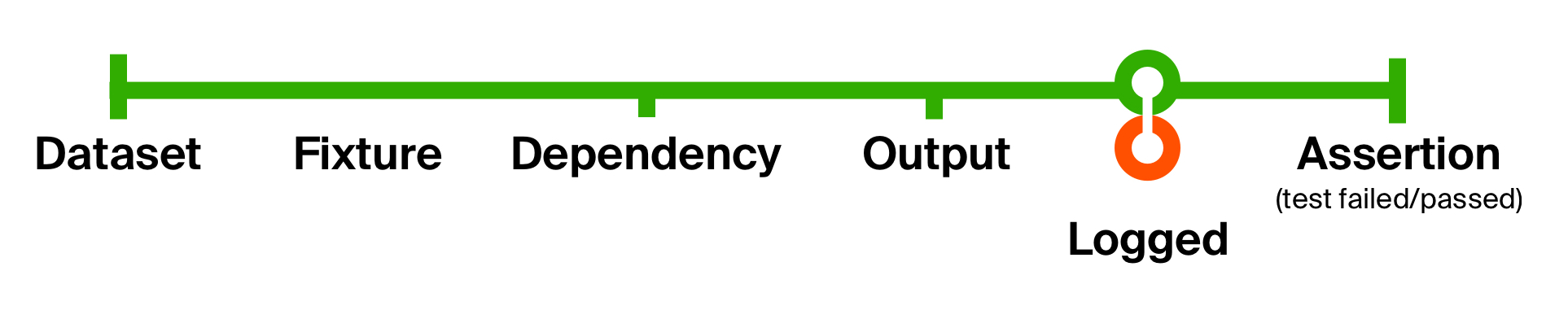
Para ilustrar mejor las capacidades de este enfoque, resuelvamos el segundo problema de nuestra prueba inicial : la falta de información complementaria para detectar problemas. Agreguemos el registro de cualquier ejecución de código que haya devuelto. Nuestro registro no cambiará el tipo de datos; solo produce un efecto secundario : enviar un mensaje a la consola. Después del efecto secundario, lo devolvemos tal como está.
Pruebe la función del ciclo de vida con el registro def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Con este simple cambio, hemos agregado el registro de la salida del código ejecutado en cada prueba . La ventaja de funciones tan pequeñas es que son fáciles de entender, componer y eliminar cuando sea necesario.

Como resultado, nuestra prueba ahora se ve así:
val fixture: SomeMagicalFixture = ???
El cuerpo de la prueba se volvió conciso, el dispositivo y los controles se pueden reutilizar en otras pruebas, y ya no preparamos la base de datos manualmente en ninguna parte. Solo queda un pequeño problema ...
Preparación de accesorios
En el código anterior estábamos trabajando bajo la suposición de que el dispositivo nos sería dado desde algún lugar. Dado que los datos son el ingrediente crítico de las pruebas sencillas y fáciles de mantener, tenemos que tocar cómo hacerlos fácilmente.
Supongamos que nuestra tienda bajo prueba tiene una base de datos relacional típica de tamaño mediano (por simplicidad, en este ejemplo tiene solo 4 tablas, pero en realidad, puede tener cientos). Algunas tablas tienen datos referenciales, algunos datos comerciales, y todo eso puede agruparse lógicamente en una o más entidades complejas. Las relaciones se vinculan con claves externas , para crear un Bonus , se requiere un Package , que a su vez necesita un User , y así sucesivamente.

Las soluciones y los hacks solo conducen a la inconsistencia de los datos y, como resultado, a horas y horas de depuración. Por esta razón, no estamos haciendo cambios en el esquema de ninguna manera.
Podríamos usar algunos métodos de producción para llenarlo, pero incluso bajo un escrutinio superficial, esto plantea muchas preguntas difíciles. ¿Qué preparará los datos en las pruebas para ese código de producción? ¿Tendríamos que reescribir las pruebas si cambia el contrato de ese código? ¿Qué sucede si los datos provienen de otro lugar y no hay métodos para usar? ¿Cuántas solicitudes se necesitarían para crear una entidad que depende de muchas otras?
Base de datos completando la prueba inicial insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Los métodos de ayuda dispersos, como los de nuestro primer ejemplo, son el mismo problema bajo un disfraz diferente. Asumen la responsabilidad de gestionar las dependencias sobre nosotros mismos, lo que estamos tratando de evitar.
Idealmente, nos gustaría tener una estructura de datos que presente todo el estado del sistema de un vistazo. Un candidato adecuado sería una tabla (o un conjunto de datos , como en PHP o Python) que no tendría nada más que campos críticos para la lógica empresarial. Si cambia, mantener las pruebas sería fácil: simplemente cambiamos los campos en el conjunto de datos. Ejemplo:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Desde nuestra tabla, creamos claves - enlaces de entidad por ID. Si una entidad depende de otra, también se crea una clave para esa otra entidad. Puede suceder que dos entidades diferentes creen una dependencia con la misma ID, lo que puede conducir a una violación de la clave principal . Sin embargo, en esta etapa es increíblemente barato deduplicar claves, ya que todo lo que contienen son ID, podemos ponerlas en una colección que nos deduplica, por ejemplo, un Set . Si eso resulta insuficiente, siempre podemos implementar una deduplicación más inteligente como una función separada y componerla en la función de prueba del ciclo de vida.
Claves (ejemplo) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
La generación de datos falsos para campos (por ejemplo, nombres) se delega a una clase separada. Luego, al usar esa clase y las reglas de conversión para las claves, obtenemos los objetos Row destinados a la inserción en la base de datos.
Filas (ejemplo) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Los datos falsos generalmente no son suficientes, por lo que necesitamos una forma de anular campos específicos. Afortunadamente, las lentes son justo lo que necesitamos: podemos usarlas para iterar sobre todas las filas creadas y cambiar solo los campos que necesitamos. Dado que las lentes son funciones disfrazadas, podemos componerlas como de costumbre, que es su punto más fuerte.
Lense (ejemplo) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Gracias a la composición, podemos aplicar diferentes optimizaciones y mejoras dentro del proceso: por ejemplo, podríamos agrupar filas por tabla para insertarlas con un solo INSERT para reducir el tiempo de ejecución de la prueba o registrar todo el estado de la base de datos.
Función de preparación de accesorios def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Finalmente, todo nos proporciona un accesorio. En la prueba en sí, no se muestra nada adicional, excepto el conjunto de datos inicial: todos los detalles están ocultos por la composición de la función.

Nuestro conjunto de pruebas ahora se ve así:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
Y el código de ayuda:
Agregar nuevos casos de prueba a la tabla es una tarea trivial que nos permite concentrarnos en cubrir más casos marginales y no en escribir código repetitivo.
Reutilizando la preparación de accesorios en diferentes proyectos
Bien, escribimos una gran cantidad de código para preparar accesorios en un proyecto específico, pasando bastante tiempo en el proceso. ¿Qué pasa si tenemos varios proyectos? ¿Estamos condenados a reinventar todo desde cero todo el tiempo?
Podemos abstraer la preparación del aparato sobre un modelo de dominio concreto. En el mundo de la programación funcional, existe un concepto de clases de tipos . Sin profundizar en los detalles, no son como clases en OOP, sino más bien como interfaces en el sentido de que definen un cierto comportamiento de algún grupo de tipos. La diferencia fundamental es que no se heredan sino que se instancian como variables. Sin embargo, de manera similar a la herencia, la resolución de instancias de tipo de clase ocurre en tiempo de compilación . En este sentido, las clases de tipos se pueden entender como métodos de extensión de Kotlin y C # .
Para registrar un objeto, no necesitamos saber qué hay dentro, qué campos y métodos tiene. Lo único que nos importa es tener un log() comportamiento log() con una firma particular. Extender cada clase individual con una interfaz Logged sería extremadamente tedioso e incluso, en muchos casos, no sería posible, por ejemplo, para bibliotecas o clases estándar. Con las clases de tipos, esto es mucho más fácil. Podemos crear una instancia de una clase de tipo llamada Logged , por ejemplo, para que un dispositivo lo registre en un formato legible para humanos. Para todo lo demás que no tiene una instancia de Logged , podemos proporcionar una alternativa: una instancia para el tipo Any que utiliza un método estándar toString() para registrar de forma gratuita todos los objetos en su representación interna.
Un ejemplo de la clase de tipo Logged y sus instancias trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Además del registro, podemos usar este enfoque durante todo el proceso de hacer accesorios. Nuestra solución propone una forma abstracta de hacer accesorios de base de datos y un conjunto de clases de tipos para acompañarlo. Es el proyecto que usa la responsabilidad de la solución implementar las instancias de estas clases de tipos para que todo funcione.
Al diseñar esta herramienta de preparación de accesorios, utilicé los principios SÓLIDOS como una brújula para asegurarme de que se pueda mantener y ampliar:
- El Principio de Responsabilidad Única : cada clase de tipo describe uno y solo un comportamiento de un tipo.
- El principio abierto / cerrado : no modificamos ninguna de las clases de producción; en su lugar, los extendemos con instancias de typeclasses.
- El Principio de sustitución de Liskov no se aplica aquí ya que no usamos la herencia.
- El principio de segregación de interfaz : utilizamos muchas clases de tipos especializadas en lugar de una global.
- El principio de inversión de dependencia : la función de preparación de accesorios no depende de tipos concretos, sino de clases de tipos abstractos.
Después de asegurarnos de que se cumplan todos los principios, podemos asumir con seguridad que nuestra solución es mantenible y lo suficientemente extensible como para ser utilizada en diferentes proyectos.
Después de escribir la función del ciclo de vida de la prueba y la solución para la preparación del accesorio, que también es independiente de un modelo de dominio concreto en cualquier aplicación, estamos listos para mejorar todas las pruebas restantes.
Línea inferior
Hemos cambiado del estilo de diseño de prueba tradicional (paso a paso) a funcional. El estilo paso a paso es útil desde el principio y en proyectos de menor tamaño, ya que no restringe a los desarrolladores y no requiere ningún conocimiento especializado. Sin embargo, cuando la cantidad de pruebas se vuelve demasiado grande, ese estilo tiende a caerse. Escribir pruebas en el estilo funcional probablemente no resolverá todos sus problemas de prueba, pero podría mejorar significativamente la escala y el mantenimiento de las pruebas en proyectos, donde hay cientos o miles de ellas. Las pruebas escritas en el estilo funcional resultan ser más concisas y centradas en las cosas esenciales (como los datos, el código bajo prueba y el resultado esperado), no en los pasos intermedios.
Además, hemos explorado cuán poderosas pueden ser la composición de funciones y las clases de tipos en la programación funcional. Con su ayuda, es bastante sencillo diseñar soluciones teniendo en cuenta la capacidad de ampliación y la reutilización.
Desde que adoptamos el estilo hace varios meses, nuestro equipo tuvo que dedicar un poco de esfuerzo para adaptarse, pero al final, disfrutamos del resultado. Las nuevas pruebas se escriben más rápido, los registros hacen la vida mucho más cómoda y los conjuntos de datos son útiles para verificar cada vez que haya preguntas sobre las complejidades de algunas lógicas. Nuestro equipo tiene como objetivo cambiar gradualmente todas las pruebas a este nuevo estilo.
Enlace a la solución y un ejemplo completo se puede encontrar aquí: Github . ¡Diviértete con tus pruebas!