"Consultor +": un sistema de referencia para abogados, contadores, etc. Funciona establemente como un reloj. En esta publicación, se sugiere que ajuste este reloj un poco a sus necesidades en términos de salida de texto, a saber: vea cómo puede procesar la información de texto que el sistema proporciona con python. En el camino, trabaje con los elementos de texto declarados en el título.
Sombra en la valla
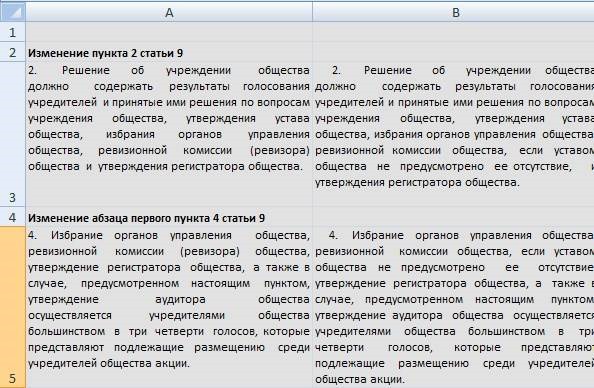
Como abogado, que trabajó durante mucho tiempo con el programa de ayuda "Consultor +", siempre me faltó una función ordinaria en este sistema. Esta función fue la siguiente. Cuando aparece algún cambio en la ley reguladora, los empleados de K + publican una descripción general de los cambios en forma de dos columnas de texto:

La columna de la izquierda es lo que era antes, la columna de la derecha es la norma que ahora está vigente. Ahora (hace algunos años), la funcionalidad se ha actualizado y los cambios se resaltan
en negrita e inmediatamente visibles. Todo esto es muy conveniente. Pero hay cosas incómodas.
En primer lugar, algunas normas no se dan porque su volumen es demasiado grande para los empleados de K + y debe ir a los enlaces del sistema, y en segundo lugar, no puede simplemente tomar y copiar estas dos columnas pegándolas en una tabla de Excel o Word normal.
Quizás esto se hizo intencionalmente para que los usuarios trabajen más activamente con el sistema, incluida la no transferencia de nada desde allí.
Bueno, tengo que arreglarlo.
La tarea : difundir el texto en dos columnas, donde sea posible y donde no, simplemente elimine la norma y coloque todo esto en una hoja de cálculo de Excel. Al mismo tiempo, veamos cómo puede cambiar la fuente, la alineación y otras pequeñeces en el texto usando Python.
Para un ejemplo que alimenta nuestro programa futuro, tomamos de K + los cambios a la Ley "Sobre JSC". Esta ley a menudo se cambia, por lo que habrá trabajo que hacer.
Guarde los cambios en un archivo txt normal (por ejemplo, la edición de .txt). Obtienes algo como lo siguiente:

Por lo tanto, está claro que cada cambio está separado del otro por una línea continua, que después de guardar tomó la forma de numerosos "???". También hay un cambio de rumbo a tener en cuenta. Todo parece simple excepto ciertos puntos.
Entonces, encuentre cambios que tengan la siguiente forma:

Además, el asunto se agrava por el hecho de que los cambios individuales difieren significativamente en longitud.
Procedemos a K +.
Cree un nuevo archivo consult.py y agregue las primeras líneas:
from __future__ import unicode_literals import codecs import openpyxl
El módulo openpyxl ya es familiar, le permite trabajar con Excel, pero otros dos son nuevos. Su función es procesar correctamente los caracteres rusos, que a menudo los programas leen incorrectamente.
De antemano, cree un nuevo archivo de Excel vacío fuera del programa, nombrándolo por ejemplo revision2.xlsx. Abriremos este archivo con nuestro programa y escribiremos los datos allí. Este será nuestro archivo final.
Entonces, el programa abre el archivo de Excel, lo ingresa:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
También arriba creamos 3 listas vacías donde recopilaremos datos: test, test2, test3.
A continuación, en la variable 'a' colocaremos todo lo que pueda caer en la forma del nombre del cambio. En y, habrá una línea divisoria. Es igual en longitud:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
Ahora la parte divertida.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
Abrimos el archivo .txt codificado cp1251. Cada línea se limpió de espacios desde el final y el principio por el método de la tira.
Si la línea comienza con la palabra "viejo", la omitimos. ¿Por qué necesitamos mantener lo "viejo" y lo "nuevo"? Esto ya está claro. A continuación, dividimos la línea: del principio a 35 caracteres y de 39 caracteres al final. Es decir, eliminamos la brecha en el medio:

Ponemos el contenido del espacio en el medio de la línea en col3, porque puede no ser un espacio si el cambio se escribe en una línea en una fila:

Además, si la línea comienza con el encabezado de cambio (escribimos estos encabezados en la variable a), inmediatamente escribimos esta línea para sobresalir sin división y agregamos la línea - x + = 1 (o x = x + 1). que nos encontramos, lo extrañamos.
Considere el siguiente fragmento de código:
if len(col2)==0:
Si la longitud de 2 partes de la cadena es 0, es decir, no existe, entonces test2 obtiene la primera parte de la cadena. Si hay un espacio en la línea, pero la segunda parte de la línea está ausente, entonces la primera y la segunda parte de la línea, respectivamente, caen en prueba y prueba2.
Si hay un espacio en la línea, y la línea no está vacía y su longitud es superior a 60 caracteres, se agrega a test3.
Si la línea está vacía, es decir, pasamos por todo el cambio, luego escribimos todo lo que recolectamos en las celdas de Excel, verificando simultáneamente el vacío en la prueba (para que no esté vacío) y la duración de la prueba3.
Finalmente, guarde el archivo de Excel:
wb.save('2.xlsx')
Estilos, fuente y alineación de texto en python
Agregue un poco de belleza a nuestra mesa.
En particular, lo haremos para que, al generar datos, los encabezados de cambio se resalten en negrita, y el texto en sí sea más pequeño y esté formateado para facilitar la lectura.
Python te permite hacer esto. Para hacer esto, necesitamos agregar y cambiar el código en los lugares donde registramos los resultados en un archivo de Excel:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
Es decir, de hecho, solo agregamos los métodos aplicables .font y .alignment.
Todo el programa tomó la forma:
Código from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
Entonces, al final, después de procesar el archivo por el programa, tenemos una tabla bastante decente con cambios en la ley:
El programa se puede descargar desde el enlace
aquí .
Aquí hay un archivo de ejemplo para que el programa lo procese.