Hola a todos En este artículo, le diré por qué elegimos Kafka hace nueve meses en Avito, y qué es. Compartiré uno de los casos de uso: un agente de mensajes. Y finalmente, hablemos sobre las ventajas que obtuvimos al aplicar el enfoque Kafka como servicio.
El problema

Primero, un pequeño contexto. Hace algún tiempo, comenzamos a alejarnos de la arquitectura monolítica, y ahora en Avito ya hay varios cientos de servicios diferentes. Tienen sus propios repositorios, su propia pila de tecnología y son responsables de su parte de la lógica empresarial.
Uno de los problemas con una gran cantidad de servicios es la comunicación. El servicio A a menudo quiere saber la información que tiene el servicio B. En este caso, el servicio A accede al servicio B a través de una API síncrona. El servicio B quiere saber qué sucede con los servicios G y D, y aquellos, a su vez, están interesados en los servicios A y B. Cuando hay muchos servicios tan "curiosos", las conexiones entre ellos se convierten en una bola enredada.
Además, en cualquier momento, el servicio A puede no estar disponible. ¿Y qué hacer en este caso, el servicio B y todos los demás servicios vinculados a él? Y si necesita hacer una cadena de llamadas síncronas consecutivas para completar una operación comercial, la probabilidad de falla de toda la operación se vuelve aún mayor (y es mayor, cuanto más larga sea esta cadena).
Selección de tecnología

OK, los problemas son claros. Puede eliminarlos creando un sistema de mensajería centralizado entre servicios. Ahora, cada uno de los servicios es suficiente para saber solo sobre este sistema de mensajería. Además, el sistema en sí mismo debe ser tolerante a fallas y escalable horizontalmente, así como en caso de accidentes, acumular un búfer de llamadas para su procesamiento posterior.
Elija ahora la tecnología en la que se implementará la entrega de mensajes. Para hacer esto, primero entienda lo que esperamos de ella:
- Los mensajes entre servicios no deben perderse;
- Los mensajes pueden estar duplicados
- los mensajes se pueden almacenar y leer a una profundidad de varios días (búfer persistente);
- los servicios pueden suscribirse a datos de interés para ellos;
- varios servicios pueden leer los mismos datos;
- Los mensajes pueden contener una carga útil detallada y masiva (transferencia de estado transmitida por evento);
- a veces necesita una garantía de pedido de mensaje.
También fue crítico para nosotros elegir el sistema más escalable y confiable con alto rendimiento (al menos 100k mensajes a unos pocos kilobytes por segundo).
En esta etapa, nos despedimos de RabbitMQ (difícil de mantener estable a altas rps), PGT de SkyTools (no lo suficientemente rápido y poco escalable) y NSQ (no persistente). Todas estas tecnologías se utilizan en nuestra empresa, pero no se ajustaban a la tarea en cuestión.
Luego comenzamos a buscar nuevas tecnologías para nosotros: Apache Kafka, Apache Pulsar y NATS Streaming.
El primero en soltar Pulsar. Decidimos que Kafka y Pulsar son soluciones bastante similares. Y a pesar de que Pulsar es probado por grandes empresas, es más nuevo y ofrece una latencia más baja (en teoría), decidimos dejar a Kafka fuera de los dos, como el estándar de facto para tales tareas. Probablemente volveremos a Apache Pulsar en el futuro.
Y quedaban dos candidatos: NATS Streaming y Apache Kafka. Estudiamos ambas soluciones con cierto detalle, y ambas estuvieron a la altura. Pero al final, teníamos miedo de la relativa juventud de NATS Streaming (y el hecho de que uno de los principales desarrolladores, Tyler Treat, decidió abandonar el proyecto y comenzar el suyo: Liftbridge). Al mismo tiempo, el modo Clustering de NATS Streaming no permitía una escala horizontal fuerte (esto probablemente ya no sea un problema después de agregar el modo de partición en 2017).
Sin embargo, NATS Streaming es una tecnología genial escrita en Go y respaldada por la Cloud Native Computing Foundation. A diferencia de Apache Kafka, no necesita Zookeeper para funcionar ( puede ser posible decir lo mismo sobre Kafka pronto ), ya que en su interior implementa RAFT. Al mismo tiempo, NATS Streaming es más fácil de administrar. No excluimos que en el futuro volveremos a esta tecnología.
Sin embargo, Apache Kafka se ha convertido en nuestro ganador hoy. En nuestras pruebas, demostró ser bastante rápido (más de un millón de mensajes por segundo para leer y escribir con un volumen de mensajes de 1 kilobyte), experiencia suficientemente confiable, bien escalable y probada en ventas por parte de grandes empresas. Además, Kafka admite al menos varias grandes empresas comerciales (por ejemplo, usamos la versión Confluent), y Kafka tiene un ecosistema desarrollado.
Revisión Kafka
Antes de comenzar, recomiendo inmediatamente un excelente libro: "Kafka: la guía definitiva" (también está en la traducción al ruso, pero los términos rompen un poco el cerebro). En él puede encontrar la información necesaria para una comprensión básica de Kafka e incluso un poco más. La documentación de Apache y el blog Confluent también están bien escritos y son fáciles de leer.
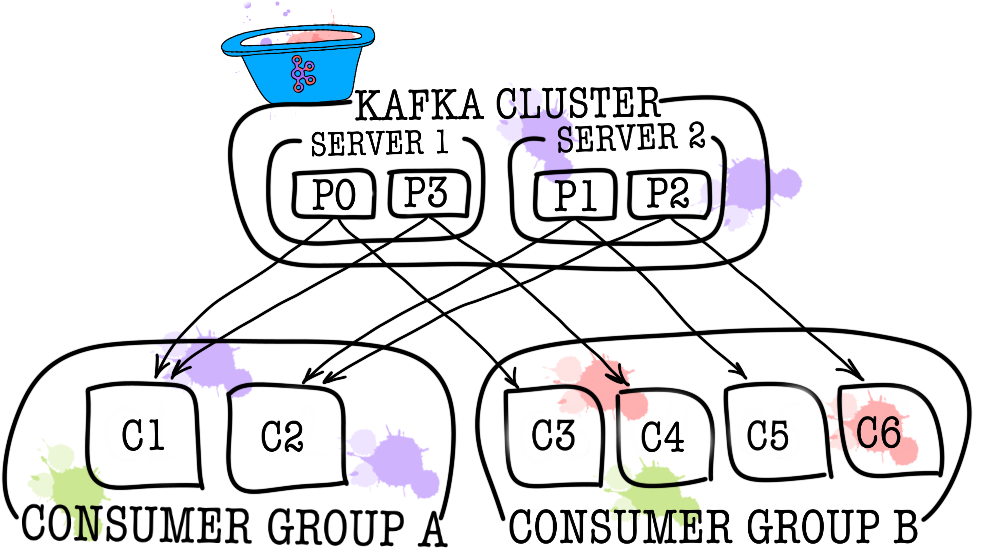
Entonces, echemos un vistazo a cómo Kafka es una vista de pájaro. La topología básica de Kafka consiste en productor, consumidor, corredor y cuidador del zoológico.
Corredor

Un corredor es responsable de almacenar sus datos. Todos los datos se almacenan en forma binaria, y el corredor sabe poco acerca de qué son y cuál es su estructura.
Cada tipo lógico de evento generalmente se encuentra en su propio tema separado (tema). Por ejemplo, un evento de creación de anuncios puede caer en el tema item.created y un evento de su cambio puede caer en item.changed. Los temas pueden considerarse como clasificadores de eventos. A nivel de tema, puede establecer parámetros de configuración como:
- volumen de datos almacenados y / o su antigüedad (retención.bytes, retención.ms);
- factor de redundancia de datos (factor de replicación);
- tamaño máximo de un mensaje (max.message.bytes);
- el número mínimo de réplicas consistentes en las que se pueden escribir datos en el tema (min.insync.replicas);
- la capacidad de conmutación por error a una réplica de retraso no síncrono con pérdida potencial de datos (unclean.leader.election.enable);
- y muchos más ( https://kafka.apache.org/documentation/#topicconfigs ).
A su vez, cada tema se divide en una o más particiones (partición). Es en la partición donde los eventos finalmente caen. Si hay más de un intermediario en el clúster, las particiones se distribuirán por igual entre todos los intermediarios (tanto como sea posible), lo que le permitirá escalar la carga en la escritura y la lectura de un tema a varios intermediarios a la vez.
En el disco, los datos para cada partición se almacenan como archivos de segmento, por defecto igual a un gigabyte (controlado a través de log.segment.bytes). Una característica importante es que los datos se eliminan de las particiones (cuando se activa la retención) solo por segmentos (no puede eliminar un evento de una partición, puede eliminar solo el segmento completo y solo inactivo).
Zookeeper
Zookeeper actúa como un repositorio y coordinador de metadatos. Es él quien puede decir si los corredores están vivos (puede mirarlo a través de los ojos de un cuidador del zoológico a través del comando ls /brokers/ids ), cuál de los corredores es el controlador ( get /controller ), si las particiones están en estado sincronizado con sus réplicas ( get /brokers/topics/topic_name/partitions/partition_number/state ). Además, el productor y el consumidor irán primero al cuidador del zoológico para averiguar en qué agente se almacenan los temas y las particiones. En los casos en que se especifique un factor de replicación mayor que 1 para el tema, el cuidador del zoológico indicará qué particiones son líderes (se escribirán y se leerán). En el caso de un accidente de corredor, es en el cuidador del zoológico donde se registrará la información sobre las nuevas particiones líderes (a partir de la versión 1.1.0 de forma asíncrona, y esto es importante ).
En versiones anteriores de Kafka, Zookeeper también era responsable del almacenamiento de las compensaciones, pero ahora se almacenan en un tema especial __consumer_offsets en el corredor (aunque aún puede usar Zookeeper para estos fines).
La forma más fácil de convertir sus datos en una calabaza es simplemente la pérdida de información con Zookeeper. En tal escenario, será muy difícil entender de qué y dónde leer.
Productor
El productor suele ser un servicio que escribe datos directamente en Apache Kafka. El productor selecciona un tema, en el que se almacenarán sus mensajes temáticos, y comienza a escribirle información. Por ejemplo, un productor podría ser un servicio de publicidad. En este caso, enviará eventos como "anuncio creado", "anuncio actualizado", "anuncio eliminado", etc. a temas temáticos. Cada evento es un par clave-valor.
Por defecto, todos los eventos son distribuidos por las particiones de partición con round-robin si la clave no está configurada (perdiendo el orden), y a través de MurmurHash (clave) si la clave está presente (ordenando dentro de la misma partición).
Vale la pena señalar aquí de inmediato que Kafka garantiza el orden de los eventos dentro de una sola partición. Pero, de hecho, a menudo esto no es un problema. Por ejemplo, seguramente puede agregar todos los cambios del mismo anuncio a una partición (preservando así el orden de estos cambios dentro del anuncio). También puede pasar un número de secuencia en uno de los campos del evento.
Consumidor
El consumidor es responsable de recuperar los datos de Apache Kafka. Si vuelve al ejemplo anterior, el consumidor puede ser un servicio de moderación. Este servicio se suscribirá al tema del servicio de anuncios, y cuando aparezca un nuevo anuncio, lo recibirá y analizará para cumplir con algunas políticas específicas.
Apache Kafka recuerda los eventos recientes que recibió el consumidor (el tema del servicio __consumer__offsets se utiliza para esto), asegurando así que, después de una lectura exitosa, el consumidor no recibirá el mismo mensaje dos veces. Sin embargo, si usa la opción enable.auto.commit = true y le da el trabajo completo de rastrear la posición del consumidor en el tema a Kafka, puede perder datos . En el código de producción, la posición del consumidor suele controlarse manualmente (el desarrollador controla el momento en que debe producirse la confirmación del evento de lectura).
En los casos en que un consumidor no es suficiente (por ejemplo, el flujo de nuevos eventos es muy grande), puede agregar algunos consumidores más al vincularlos en el grupo de consumidores. El grupo de consumidores lógicamente es exactamente el mismo consumidor, pero con la distribución de datos entre los miembros del grupo. Esto permite que cada uno de los participantes tome su parte de los mensajes, lo que aumenta la velocidad de lectura.
Resultados de la prueba

Aquí no escribiré mucho texto explicativo, solo comparto los resultados. Las pruebas se llevaron a cabo en 3 máquinas físicas (12 CPU, 384 GB de RAM, 15K SAS DISK, 10 GBit / s Net), corredores y zookeeper se implementaron en lxc.
Pruebas de rendimiento
Durante las pruebas, se obtuvieron los siguientes resultados.
- La velocidad de grabación de mensajes de 1 KB de tamaño simultáneamente por 9 productores: 1300000 eventos por segundo.
- Velocidad de lectura de mensajes de 1 KB al mismo tiempo por 9 consumidores: 1,500,000 eventos por segundo.
Prueba de tolerancia a fallas
Durante las pruebas, se obtuvieron los siguientes resultados (3 corredores, 3 cuidadores del zoológico).
- Una terminación anormal de uno de los corredores no conduce a la suspensión o inaccesibilidad del grupo. El trabajo continúa como de costumbre, pero los corredores restantes tienen una gran carga.
- La terminación anormal de dos corredores en el caso de un grupo de tres corredores y min.isr = 2 conduce a la inaccesibilidad del grupo para escribir, pero legibilidad. En el caso de min.isr = 1, el clúster sigue estando disponible para lectura y escritura. Sin embargo, este modo contradice el requisito de alta seguridad de datos.
- La terminación anormal de uno de los servidores de Zookeeper no conduce a un apagado del clúster o inaccesibilidad. El trabajo continúa como de costumbre.
- Una terminación anormal de dos servidores Zookeeper lleva a una inaccesibilidad del clúster hasta que se restaure al menos uno de los servidores Zookeeper. Esta afirmación es cierta para un clúster Zookeeper de 3 servidores. Como resultado, después de la investigación, se decidió aumentar el clúster Zookeeper a 5 servidores para aumentar la tolerancia a fallas.
Kafka como servicio

Nos aseguramos de que Kafka sea una tecnología excelente que nos permita resolver la tarea establecida para nosotros (implementar un intermediario de mensajes). Sin embargo, decidimos prohibir que los servicios accedan directamente a Kafka y cerrarlo en la parte superior con el servicio de bus de datos. ¿Por qué hicimos esto? En realidad hay varias razones.
Data-bus se hizo cargo de todas las tareas relacionadas con la integración con Kafka (implementación y configuración de consumidores y productores, monitoreo, alerta, registro, escalado, etc.). Por lo tanto, la integración con el intermediario de mensajes es lo más simple posible.
El bus de datos permite abstraer de un idioma o biblioteca específicos para trabajar con Kafka.
El bus de datos permitió que otros servicios se abstrajeran de la capa de almacenamiento. Quizás en algún momento cambiemos Kafka a Pulsar, y nadie notará nada (todos los servicios solo conocen la API del bus de datos).
El bus de datos se hizo cargo de la validación de los esquemas de eventos.
Se implementa el uso de autenticación de bus de datos.
Bajo la cobertura del bus de datos, podemos, sin tiempo de inactividad, actualizar discretamente las versiones de Kafka, realizar configuraciones centrales de productores, consumidores, corredores, etc.
El bus de datos nos permitió agregar características que necesitamos que no están en Kafka (como auditoría de temas, monitoreo de anomalías en el clúster, creación de DLQ, etc.).
El bus de datos permite que la conmutación por error se implemente de manera centralizada para todos los servicios.
En este momento, para comenzar a enviar eventos al intermediario de mensajes, simplemente conecte una pequeña biblioteca a su código de servicio. Eso es todo Tiene la oportunidad de escribir, leer y escalar con una sola línea de código. Toda la implementación está oculta para usted, solo quedan unos pocos palos como el tamaño del lote. Bajo el capó, el servicio de bus de datos aumenta la cantidad necesaria de instancias de productores y consumidores en Kubernetes y les agrega la configuración necesaria, pero todo esto es transparente para su servicio.
Por supuesto, no hay una bala de plata, y este enfoque tiene sus limitaciones.
- El bus de datos debe ser compatible solo, a diferencia de las bibliotecas de terceros.
- El bus de datos aumenta el número de interacciones entre los servicios y el intermediario de mensajes, lo que conduce a un menor rendimiento en comparación con Kafka.
- No todo puede estar tan simplemente oculto de los servicios, no queremos duplicar la funcionalidad de KSQL o Kafka Streams en el bus de datos, por lo que a veces hay que permitir que los servicios vayan directamente.
En nuestro caso, los profesionales superaron a los contras, y la decisión de cubrir el agente de mensajes con un servicio separado estaba justificada. Durante el año de operación, no tuvimos accidentes y problemas serios.
PD: Gracias a mi novia, Ekaterina Oblyalyaeva, por las fotos geniales de este artículo. Si te gustaron, hay aún más ilustraciones.