El nuevo trabajo de Google ofrece una arquitectura de redes neuronales que puede simular los instintos y reflejos innatos de los seres vivos, seguido de más capacitación durante toda la vida.
Y también reduce significativamente el número de conexiones dentro de la red, aumentando así su velocidad.
Las redes neuronales artificiales, aunque son similares en principio a las biológicas, aún son muy diferentes de ellas para ser utilizadas en su forma pura para crear una IA fuerte. Por ejemplo, ahora es imposible crear un modelo de una persona en un simulador (o un ratón, o incluso un insecto), darle un "cerebro" en forma de una red neuronal moderna y entrenarlo. Simplemente no funciona.
Incluso descartando las diferencias en el mecanismo de aprendizaje (en el cerebro no existe un análogo exacto del algoritmo de propagación de error de retroceso, por ejemplo) y la falta de correlaciones temporales de diferente escala, sobre la base de las cuales el cerebro biológico construye su trabajo, las redes neuronales artificiales tienen varios problemas más que no les permiten simular suficientemente cerebro vivo Probablemente debido a estos problemas inherentes al aparato matemático utilizado ahora, el Aprendizaje de refuerzo, diseñado para imitar el entrenamiento de las criaturas vivientes sobre la base de la recompensa, no funciona tan bien como nos gustaría en la práctica. Aunque se basa en ideas realmente buenas y correctas. Los desarrolladores mismos bromean que el cerebro es RNN + A3C (es decir, un algoritmo recurrente de red + actor-crítico para su entrenamiento).
Una de las diferencias más notables entre el cerebro biológico y las redes neuronales artificiales es que la estructura del cerebro vivo está preconfigurada por millones de años de evolución. Aunque la neocorteza, que es responsable de la mayor actividad nerviosa en los mamíferos, tiene una estructura aproximadamente uniforme, la estructura general del cerebro está claramente definida por los genes. Además, los animales que no sean mamíferos (aves, peces) no tienen una neocorteza en absoluto, pero al mismo tiempo exhiben un comportamiento complejo que las redes neuronales modernas no pueden lograr. Una persona también tiene limitaciones físicas en la estructura del cerebro, que son difíciles de explicar. Por ejemplo, la resolución de un ojo es de aproximadamente 100 megapíxeles (~ 100 millones de bastones y conos fotosensibles), lo que significa que desde dos ojos el flujo de video debe ser de aproximadamente 200 megapíxeles con una frecuencia de al menos 15 fotogramas por segundo. Pero en realidad, el nervio óptico puede pasar a través de sí mismo no más de 2-3 megapíxeles. Y sus conexiones se dirigen no a la parte más cercana del cerebro, sino a la parte occipital a la corteza visual.
Por lo tanto, sin restarle importancia a la importancia de la neocorteza (en términos generales, puede considerarse al nacer como un análogo de redes neuronales modernas iniciadas al azar), los hechos sugieren que incluso en los humanos una estructura cerebral predefinida juega un papel muy importante. Por ejemplo, si un bebé tiene solo unos minutos para mostrar su lengua, entonces, gracias a las neuronas espejo, también sacará la lengua. Lo mismo sucede con la risa de los niños. Es bien sabido que los bebés desde el nacimiento han sido "cosidos" con un excelente reconocimiento de los rostros humanos. Pero lo más importante, el sistema nervioso de todos los seres vivos está optimizado para sus condiciones de vida. El bebé no llorará durante horas si tiene hambre. Se cansará O miedo a algo y cállate. El zorro no alcanzará el agotamiento hasta que el hambre alcance las uvas inaccesibles. Hará varios intentos, decidirá que él está amargado (s) y se irá. Y este no es un proceso de aprendizaje, sino un comportamiento predefinido por la biología. Además, las diferentes especies tienen diferentes. Algunos depredadores se apresuran inmediatamente por la presa, mientras que otros se quedan en una emboscada durante mucho tiempo. Y aprendieron esto no a través de prueba y error, sino que tal es su biología, dada por instintos. Del mismo modo, muchos animales tienen programas de evitación de depredadores por cable desde los primeros minutos de vida, aunque físicamente aún no pudieron aprenderlos.
Teóricamente, los métodos modernos de entrenamiento de redes neuronales son capaces de crear una imagen de un cerebro tan pre-entrenado desde una red totalmente conectada, poniendo a cero conexiones innecesarias (de hecho, cortándolas) y dejando solo las necesarias. Pero esto requiere una gran cantidad de ejemplos, no se sabe cómo entrenarlos y, lo que es más importante, por el momento no hay buenas maneras de arreglar esta estructura "inicial" del cerebro. El entrenamiento posterior cambia estos pesos y todo sale mal.
Los investigadores de Google también hicieron esta pregunta. ¿Es posible crear una estructura cerebral inicial similar a la biológica, es decir, que ya esté bien optimizada para resolver el problema y luego volver a entrenarla? Teóricamente, esto reducirá drásticamente el espacio de soluciones y le permitirá entrenar rápidamente redes neuronales.
Desafortunadamente, los algoritmos de optimización de estructura de red existentes, como la Búsqueda de Arquitectura Neural (NAS), operan en bloques enteros. Después de agregar o eliminar cuáles, la red neuronal debe ser entrenada nuevamente desde cero. Este es un proceso que requiere muchos recursos y no resuelve completamente el problema.
Por lo tanto, los investigadores propusieron una versión simplificada, llamada "Redes neuronales agnósticas de peso" (WANN). La idea es reemplazar todos los pesos de una red neuronal con un peso "común". Y en el proceso de aprendizaje, no se trata de seleccionar pesos entre las neuronas, como en las redes neuronales comunes, sino de seleccionar la estructura de la red en sí (el número y la ubicación de las neuronas), que con los mismos pesos muestra los mejores resultados. Y después de eso, optimícelo para que la red funcione bien con todos los valores posibles de este peso total (¡común para todas las conexiones entre neuronas!).
Como resultado, esto da la estructura de una red neuronal, que no depende de pesos específicos, pero funciona bien con todos. Porque funciona debido a la estructura general de la red. Esto es similar al cerebro de un animal que aún no se ha inicializado con escalas específicas al nacer, pero que ya contiene instintos incrustados debido a su estructura general. Y el ajuste posterior de las escalas durante el entrenamiento durante toda la vida, hace que esta red neuronal sea aún mejor.
Un efecto secundario positivo de este enfoque es una disminución significativa en el número de neuronas en la red (ya que solo quedan las conexiones más importantes), lo que aumenta su velocidad. A continuación se muestra una comparación de la complejidad de una red neuronal completamente conectada clásica (izquierda) y una nueva red emparejada (derecha).
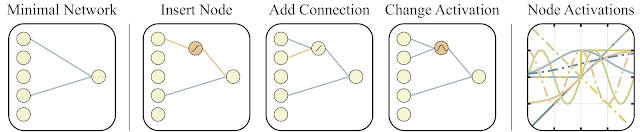
Para buscar dicha arquitectura, los investigadores utilizaron el algoritmo de búsqueda de topología (NEAT). Primero, se crea un conjunto de redes neuronales simples, y luego se realiza una de tres acciones: se agrega una nueva neurona a la conexión existente entre dos neuronas, se agrega una nueva conexión con otras aleatorias a otra neurona o la función de activación en la neurona cambia (ver las figuras a continuación). Y luego, a diferencia del NAS clásico, donde se buscan los pesos óptimos entre las neuronas, aquí todos los pesos se inicializan con un solo número. Y la optimización se lleva a cabo para encontrar la estructura de red que funciona mejor en una amplia gama de valores de este peso total. Por lo tanto, se obtiene una red que no depende del peso específico entre las neuronas, pero que funciona bien en todo el rango (pero todos los pesos siguen siendo iniciados por un número, y no son diferentes como en las redes normales). Además, como un objetivo adicional para la optimización, intentan minimizar la cantidad de neuronas en la red.
A continuación se muestra un esquema general del algoritmo.
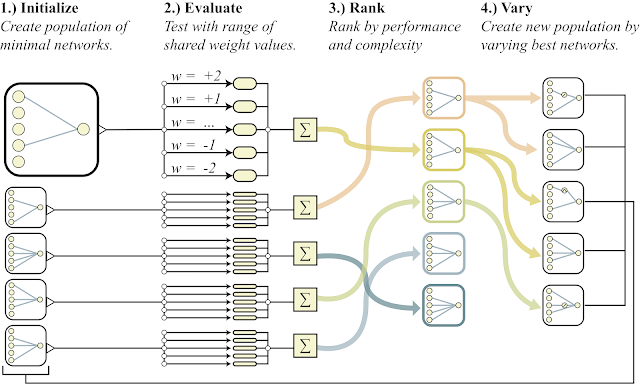
- crea una población de redes neuronales simples
- cada red inicializa todos sus pesos con un número y para un amplio rango de números: w = -2 ... + 2
- Las redes resultantes se ordenan por la calidad de la solución al problema y por el número de neuronas (abajo)
- en la parte de los mejores representantes, se agrega una neurona, una conexión o la función de activación en una neurona cambia
- Estas redes modificadas se utilizan como iniciales en el punto 1)
Todo esto es bueno, pero se han propuesto cientos, si no miles de ideas diferentes para redes neuronales. ¿Funciona esto en la práctica? Si lo hace A continuación se muestra un ejemplo del resultado de búsqueda de dicha arquitectura de red para el problema clásico del carro de péndulo. Como se puede ver en la figura, la red neuronal funciona bien con todas las variantes del peso total (mejor con +1.0, pero también trata de levantar el péndulo de -1.5). Y después de optimizar este peso único, comienza a funcionar perfectamente (opción de pesos ajustados en la figura).
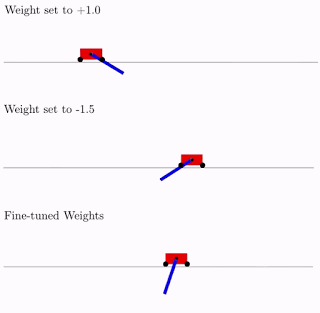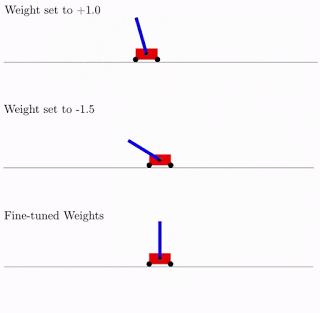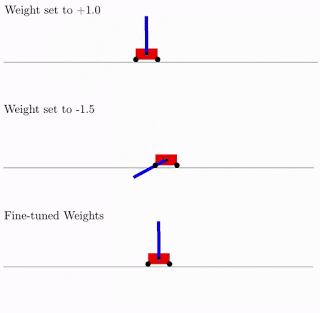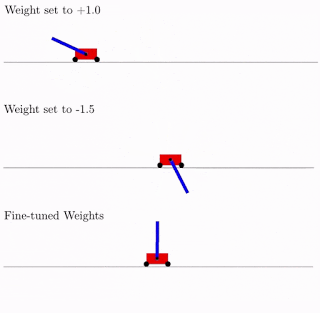
Por lo general, puede volver a entrenar como este peso total único, ya que la selección de la arquitectura se realiza en un número discreto limitado de parámetros (en el ejemplo anterior -2, -1,1,2). Y puede obtener un parámetro óptimo más preciso, digamos, 1.5. Y puede utilizar el mejor peso total como punto de partida para el reentrenamiento de todos los pesos, como en el entrenamiento clásico de redes neuronales.
Esto es similar a cómo se entrenan los animales. Teniendo instintos que son casi óptimos al nacer, y usando esta estructura cerebral dada por los genes como la inicial, durante el curso de su vida, los animales entrenan su cerebro en condiciones externas específicas. Más detalles en un artículo reciente en la revista Nature .
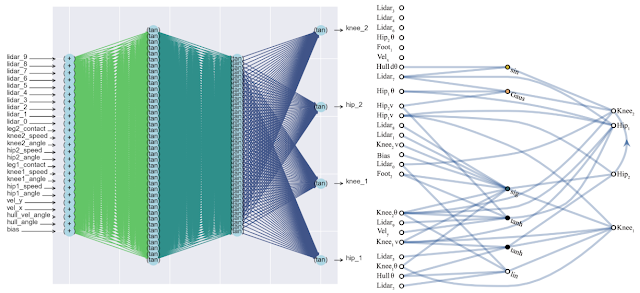
A continuación se muestra un ejemplo de una red encontrada por WANN para una tarea de control de máquina basada en píxeles. Tenga en cuenta que este es un paseo basado en los "instintos pelados", con el mismo peso total en todas las articulaciones, sin el ajuste clásico de todos los pesos. Al mismo tiempo, la red neuronal es extremadamente simple en estructura.
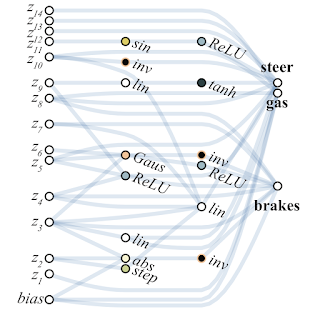

Los investigadores sugieren crear conjuntos de redes WANN como otro caso de uso para WANN. Por lo tanto, la red neuronal inicializada aleatoriamente habitual en MNIST muestra una precisión de aproximadamente el 10%. Una única red neuronal WANN seleccionada produce aproximadamente el 80%, pero un conjunto de WANN con diferentes pesos totales muestra ya> 90%.
Como resultado, el método propuesto por los investigadores de Google para buscar la arquitectura inicial de una red neuronal óptima no solo imita el aprendizaje animal (nacimiento con instintos óptimos incorporados y reentrenamiento durante la vida), sino que también evita la simulación de la vida animal completa con el aprendizaje completo de toda la red en algoritmos evolutivos clásicos, creando Redes simples y rápidas a la vez. Lo cual es suficiente para entrenar un poco y obtener una red neuronal completamente óptima.
Referencias
- Entrada de blog de Google AI
- Un artículo interactivo en el que puede cambiar el peso total y controlar el resultado.
- Artículo de Nature sobre la importancia de los instintos incrustados al nacer