Decidí compartirlo, pero yo mismo no olvidaría cómo se pueden usar herramientas estadísticas simples para analizar datos. Se utilizó una encuesta anónima como ejemplo con respecto a los salarios, la duración del servicio y los puestos de programadores ucranianos para 2014 y 2019. (1)
Pasos de análisis
- Preprocesamiento de datos y análisis preliminar ( cualquier persona interesada en el código aquí )
- Una representación gráfica de los datos. Función de densidad de distribución.
- Formulamos la hipótesis nula (H0) (2)
- Elija una métrica para el análisis.
- Usamos el método de arranque para formar una nueva matriz de datos.
- Calculamos el valor p (3) para confirmar o refutar la hipótesis
Preprocesamiento de datos
Después de algunas manipulaciones (el
código está aquí ), presentamos los datos de la siguiente forma:
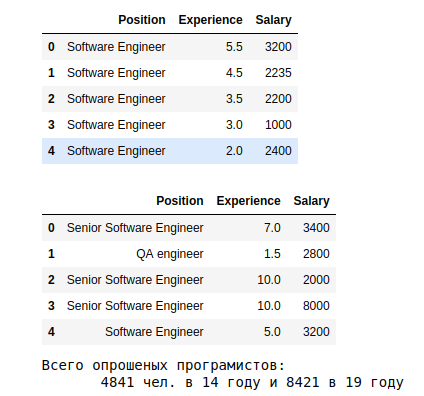
Un poco más de agrupaciones durante un año (deja el 19):

Las primeras estimaciones son las siguientes.
a. Los resultados muestran que, en promedio, en 19, aquellos que han estado trabajando durante más de 10 años reciben más de 3.5k. La dependencia de la experiencia -> zp
c. Promedio s.p. en 19, dependiendo de la especialización, muestran una extensión de 10 veces, desde 5k para System Architect, hasta 575 para Junior QA.
s La última placa muestra la distribución por profesión. La mayoría de los datos sobre el ingeniero de software, sin calificación.
Llamamos la atención sobre las características del año 19: Algo está mal con el noveno año de experiencia y no hay clasificación según los niveles de junior, middle, senior. Puede comprender mejor los motivos del valor atípico del noveno año. Pero para este análisis, lo tomamos como es.
Pero con las categorías, vale la pena resolverlas. en 19, el ingeniero de software 2739 personas (35% de todos) sin indicar el nivel de calificación. Calculemos el promedio y las desviaciones para quienes lo indicaron.
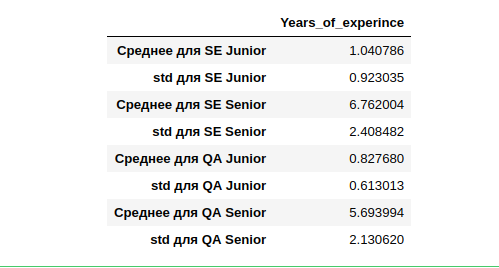
Resulta que la experiencia laboral promedio (que lo indicó) para SE Junior es de un año, con una desviación bastante amplia de un año. SE Senior tiene la mayor experiencia con una desviación similar de 2.4 años.
Si tratamos de calcular Middle y usar la experiencia promedio de quienes lo indicaron, entonces para clasificar al que no lo indicó, es posible que no agrupemos correctamente toda la muestra. Cometeremos errores especialmente en otras especialidades (no SE y QA), es decir Muy pocos datos. Además, hay pocos de ellos en comparación con el decimocuarto año.
¿Qué más puedo usar?
¡Tomemos solo el nivel salarial como un indicador confiable del nivel de habilidad! (Creo que habrá disidencia).
Primero, construimos cómo se ve la distribución de salarios para el año 19.
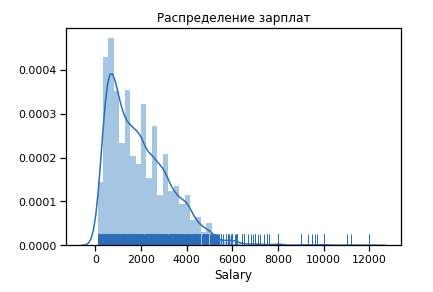
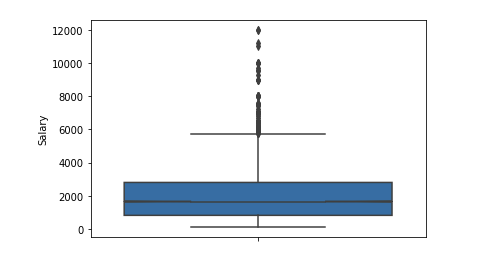
Número significativo de valores atípicos después de 6 $ k. Dejamos el rango de limitaciones [400 - 4000]. Cualquier programador debería obtener más de 400 :)
df_new = data_19_1[(data_19_1['Salary'] > 400) & (data_19_1['Salary'] < 4000)] sns.distplot(df_new['Salary'], rug=True, norm_hist=True)
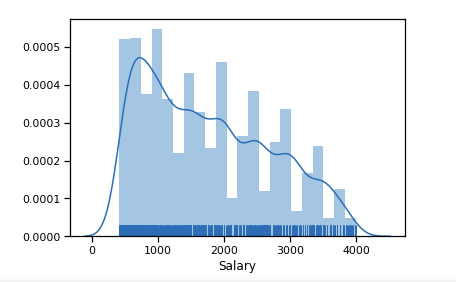
Ya un poco más cerca de la distribución normal.
Compusimos durante 19 años, niveles de habilidad dependiendo de la RFP. El rango de $ 3600 nos da un buen divisor en 3 categorías: $ 1200
df_new.reset_index() df_new.loc['level'] = 0 df_new.loc[df_new.Salary <= 1200, 'level'] = 'Junior' df_new.loc[(df_new.Salary > 1200) & (df_new.Salary <= 2400), 'level'] = 'Middle' df_new.loc[df_new.Salary > 2401, 'level'] = 'Senior'
Empate - densidad de categoría por 19 años.
sns.set(style="whitegrid") fig, ax = plt.subplots() fig.set_size_inches(11.7, 8.27) plt.title(' 19 ') sns.barplot(x='level', y='Salary', hue='Experience', hue_order=[1,3,5,7,10], palette='Blues', \ data=df_new, ci='sd')

Al agregar la cantidad de experiencia especificada (esquina izquierda), puede ver diferentes matices. Por ejemplo, que en promedio Junior obtiene hasta 1k y su experiencia laboral es de 5 años. La dispersión más grande en sn en Senior (una línea corta negra en la parte superior de cada columna) y muchos otros detalles interesantes.
Aquí es donde terminan las dos primeras etapas, procedemos a la prueba de hipótesis utilizando bootstraping.
Formulamos la hipótesis nula (H0)
En las primeras etapas, descubrimos que la experiencia laboral especificada no significa con mucha precisión el nivel de calificación. Luego formamos la hipótesis nula (la que necesita ser refutada)
Hay muchas opciones (por ejemplo):
- La dependencia del salario en la antigüedad en el año 14 es la misma que en el 19.
- Los sueldos juveniles no han cambiado desde hace 14 años.
Sin embargo, dado que la experiencia indicada es un mal indicador, y el cálculo para ciertas categorías puede ser confuso, entonces tomamos una opción simple y más sustantiva: el
nivel promedio de sn en 14, el mismo que en 19, es nuestra hipótesis nula H0 (2).
Es decir, suponemos que los salarios durante 5 años no han cambiado.
NO la fidelidad de la hipótesis, a pesar de toda su evidencia, podemos verificar con precisión calculando el valor P para la hipótesis nula.
El salario promedio en el año 14 es de $ 1797, donde el intervalo de confianza es del 95% [300.0 4000.0]
El salario promedio en 19 es $ 1949, donde el intervalo de confianza es 95% [300.0 5000.0]
La diferencia en los salarios promedio en los años 14 y 19: $ 152
Métrica para análisis
Es lógico elegir los valores promedio como nuestra métrica. Son posibles otras opciones, por ejemplo, la mediana, que a menudo se realiza en caso de un número significativo de valores atípicos. Sin embargo, el promedio como estimación es fácil de entender y también da una buena idea.
Escribir una función de arranque.
Calculamos nuestras estadísticas.
valor p = 0.0
Los valores P de hasta 0.05 se consideran insignificantes, y en nuestro caso es igual a 0. Lo que significa que la hipótesis nula es
refutada : los valores salariales promedio en los años 14 y 19 son diferentes y esto no es un resultado accidental o un número significativo de valores atípicos.
Generamos 10 mil de tales matrices, en promedio, no se pudo obtener un total de más separaciones que los datos en sí.
Aunque dedicamos mucha atención a las dos primeras etapas, formulamos la hipótesis correcta y elegimos la métrica correcta. En tareas más complejas, con una gran cantidad de variables, sin estos pasos preliminares, los análisis pueden conducir a una interpretación incorrecta. No te los saltes.
Como resultado de nuestro estudio del nivel de salarios de 14 y 19 años, llegamos a las siguientes conclusiones:
- Según los datos de la encuesta, la experiencia especificada no es un criterio totalmente adecuado para determinar el nivel de salarios y calificaciones.
- La división en el nivel de habilidad probablemente se basará en el nivel de los salarios.
- Los salarios de los programadores aumentaron de 14 a 19 (un promedio de 8.5%) y esto no es un resultado accidental.
Gracias por su atencion Estaré encantado de comentarios y críticas.
Fuentes
- https://jobs.dou.ua/salaries/ (resultados de la encuesta)
- https://en.wikipedia.org/wiki/Null_hypothesis
- https://en.wikipedia.org/wiki/P-value