
En los días en que Kubernetes todavía era v1.0.0, existían complementos de volumen. Fueron necesarios para conectarse a los sistemas Kubernetes para almacenar datos de contenedor persistentes (permanentes). Su número era pequeño, y entre los primeros había proveedores de almacenamiento como GCE PD, Ceph, AWS EBS y otros.
Los complementos se entregaron junto con Kubernetes, por lo que obtuvieron su nombre: en el árbol. Sin embargo, muchos de los conjuntos existentes de tales complementos no eran suficientes. Los artesanos agregaron complementos simples al núcleo de Kubernetes utilizando parches, después de lo cual construyeron sus propios Kubernetes y los pusieron en sus servidores. Pero con el tiempo, los desarrolladores de Kubernetes se dieron cuenta de que el
pescado no podía resolverse. La gente necesita una
caña de pescar . Y en el lanzamiento de Kubernetes v1.2.0, apareció ...
Complemento Flexvolume: caña de pescar mínima
Los desarrolladores de Kubernetes crearon el complemento FlexVolume, que era un enlace lógico de variables y métodos para trabajar con controladores Flexvolume de terceros.
Detengámonos y echemos un vistazo más de cerca a lo que es el controlador FlexVolume. Este es un cierto
archivo ejecutable (
archivo binario, secuencia de comandos Python, secuencia de comandos Bash, etc.) que, cuando se ejecuta, toma argumentos de línea de comando y devuelve un mensaje con campos previamente conocidos en formato JSON. Por convención, el primer argumento de la línea de comando es siempre el método, y el resto de los argumentos son sus parámetros.
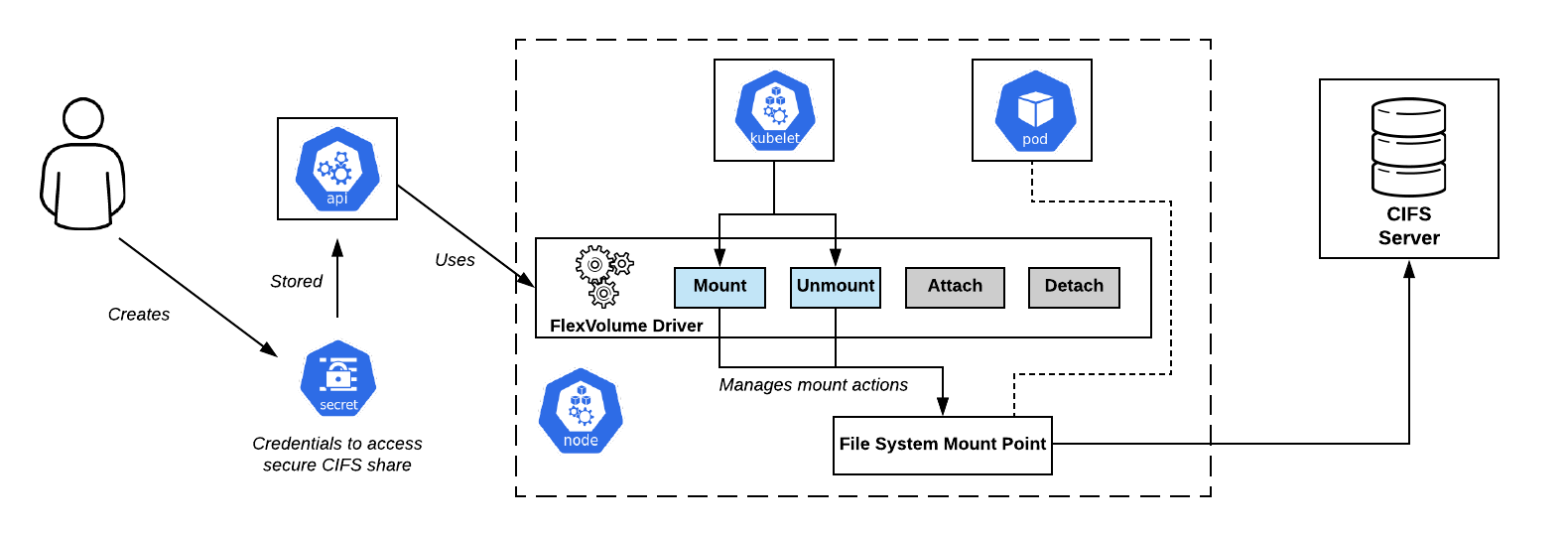 Esquema de conexión de CIFS Shares en OpenShift. Controlador Flexvolume - Justo en el centroEl conjunto mínimo de métodos se
Esquema de conexión de CIFS Shares en OpenShift. Controlador Flexvolume - Justo en el centroEl conjunto mínimo de métodos se ve así:
flexvolume_driver mount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver unmount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver init # # : { "status": "Success"/"Failure"/"Not supported", "message": " ", // , attach/deatach "capabilities":{"attach": True/False} }
El uso de los métodos de conexión y desconexión determinará el escenario según el cual en el futuro actuará Kubelet cuando se llame al controlador. También hay
expandfs especiales
expandvolume y
expandfs que son responsables de cambiar el tamaño dinámicamente de un volumen.
Como ejemplo de los cambios que
expandvolume método
expandvolume , y con la capacidad de cambiar el tamaño del volumen en tiempo real, puede consultar
nuestra solicitud de extracción en el Rook Ceph Operator.
Aquí hay un ejemplo de implementación del controlador Flexvolume para trabajar con NFS:
usage() { err "Invalid usage. Usage: " err "\t$0 init" err "\t$0 mount <mount dir> <json params>" err "\t$0 unmount <mount dir>" exit 1 } err() { echo -ne $* 1>&2 } log() { echo -ne $* >&1 } ismounted() { MOUNT=`findmnt -n ${MNTPATH} 2>/dev/null | cut -d' ' -f1` if [ "${MOUNT}" == "${MNTPATH}" ]; then echo "1" else echo "0" fi } domount() { MNTPATH=$1 NFS_SERVER=$(echo $2 | jq -r '.server') SHARE=$(echo $2 | jq -r '.share') if [ $(ismounted) -eq 1 ] ; then log '{"status": "Success"}' exit 0 fi mkdir -p ${MNTPATH} &> /dev/null mount -t nfs ${NFS_SERVER}:/${SHARE} ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failure\", \"message\": \"Failed to mount ${NFS_SERVER}:${SHARE} at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } unmount() { MNTPATH=$1 if [ $(ismounted) -eq 0 ] ; then log '{"status": "Success"}' exit 0 fi umount ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failed\", \"message\": \"Failed to unmount volume at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } op=$1 if [ "$op" = "init" ]; then log '{"status": "Success", "capabilities": {"attach": false}}' exit 0 fi if [ $# -lt 2 ]; then usage fi shift case "$op" in mount) domount $* ;; unmount) unmount $* ;; *) log '{"status": "Not supported"}' exit 0 esac exit 1
Entonces, después de preparar el archivo ejecutable real, debe
diseñar el controlador en el clúster de Kubernetes . El controlador debe estar ubicado en cada nodo del clúster de acuerdo con una ruta predefinida. Por defecto fue seleccionado:
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/__~_/... pero usando diferentes distribuciones de Kubernetes (OpenShift, Rancher ...) la ruta puede ser diferente.
Problemas de flexvolumen: ¿cómo lanzar una caña de pescar?
Poner el controlador Flexvolume en los nodos del clúster resultó ser una tarea no trivial. Una vez realizada la operación manualmente, es fácil encontrar una situación en la que aparecen nuevos nodos en el clúster: debido a la adición de un nuevo nodo, escala horizontal automática o, peor aún, al reemplazo del nodo debido a un mal funcionamiento. En este caso, es
imposible trabajar con el almacenamiento en estos nodos hasta que agregue manualmente el controlador Flexvolume de la misma manera.
La solución a este problema fue una de las primitivas de Kubernetes:
DaemonSet . Cuando aparece un nuevo nodo en el clúster, obtiene automáticamente un pod de nuestro DaemonSet, al que se adjunta un volumen local en el camino para encontrar controladores Flexvolume. Tras la creación exitosa, el pod copia los archivos necesarios para que el controlador funcione en el disco.
Aquí hay un ejemplo de tal DaemonSet para diseñar el complemento Flexvolume:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: flex-set spec: template: metadata: name: flex-deploy labels: app: flex-deploy spec: containers: - image: <deployment_image> name: flex-deploy securityContext: privileged: true volumeMounts: - mountPath: /flexmnt name: flexvolume-mount volumes: - name: flexvolume-mount hostPath: path: <host_driver_directory>
... y un ejemplo de un script Bash para diseñar un controlador Flexvolume:
Es importante no olvidar que la operación de copia
no es
atómica . Es muy probable que Kubelet comience a usar el controlador antes de que se complete el proceso de preparación, lo que provocará un error en el sistema. El enfoque correcto sería copiar primero los archivos del controlador con un nombre diferente y luego usar la operación de cambio de nombre atómico.
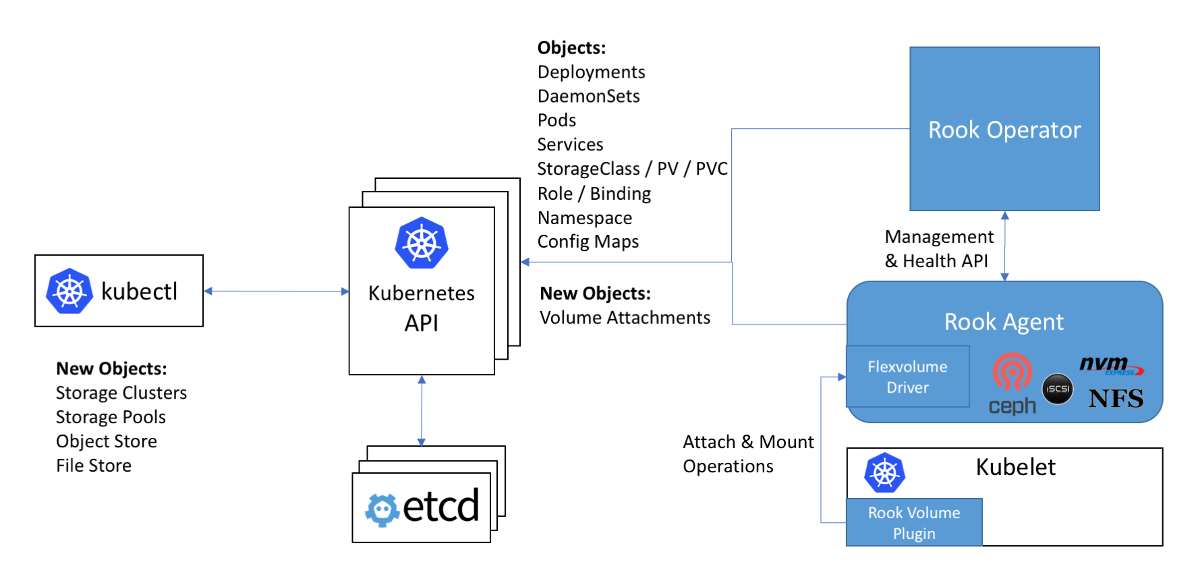 Esquema de trabajo con Ceph en la declaración Rook: el controlador Flexvolume en el diagrama está dentro del agente Rook
Esquema de trabajo con Ceph en la declaración Rook: el controlador Flexvolume en el diagrama está dentro del agente RookEl siguiente problema cuando se utilizan controladores Flexvolume es que para la mayoría de los almacenamientos
, el software necesario para esto debe instalarse en el nodo del clúster (por ejemplo, el paquete ceph-common para Ceph). Inicialmente, el complemento Flexvolume no fue diseñado para implementar sistemas tan complejos.
Se puede ver una solución original a este problema en la implementación del controlador Flexvolume del operador Rook:
El controlador en sí está diseñado como un cliente RPC. El socket IPC para la comunicación se encuentra en el mismo directorio que el controlador mismo. Recordamos que para copiar archivos de controlador sería bueno usar DaemonSet, que conecta un directorio con el controlador como un volumen. Después de copiar los archivos necesarios del controlador de torre, este pod no muere, sino que se conecta al zócalo IPC a través del volumen adjunto como un servidor RPC completo. El paquete ceph-common ya está instalado dentro del contenedor del módulo. El socket IPC confía en que kubelet se comunicará con el pod particular ubicado en el mismo nodo. ¡Todo lo ingenioso es simple! ..
¡Adiós, nuestros afectuosos ... complementos en el árbol!
Los desarrolladores de Kubernetes han descubierto que la cantidad de complementos de almacenamiento dentro del núcleo es veinte. Y el cambio en cada uno de ellos de alguna manera pasa por el ciclo completo de lanzamiento de Kubernetes.
Resulta que para usar la nueva versión del complemento para el almacenamiento,
debe actualizar todo el clúster . Además de esto, puede sorprenderse de que la nueva versión de Kubernetes de repente se vuelva incompatible con el kernel de Linux utilizado ... Y, por lo tanto, limpie las lágrimas y apriete los dientes y coordine con las autoridades y los usuarios el tiempo para actualizar el kernel de Linux y el clúster de Kubernetes. Con posible tiempo de inactividad en la prestación de servicios.
La situación es más que cómica, ¿no? Se hizo evidente para toda la comunidad que el enfoque no funcionó. Con una decisión decidida, los desarrolladores de Kubernetes anuncian que ya no se aceptarán nuevos complementos de almacenamiento en el núcleo. Para todo lo demás, como ya sabemos, en la implementación del complemento Flexvolume se revelaron una serie de deficiencias ...
De una vez por todas, se convocó al último complemento agregado para volúmenes en Kubernetes, CSI, para cerrar el problema con los almacenes de datos persistentes. Su versión alfa, más comúnmente conocida como Complementos de volumen CSI fuera del árbol, se anunció en
Kubernetes 1.9 .
Interfaz de almacenamiento de contenedores, o CSI 3000 girando!
En primer lugar, me gustaría señalar que CSI no es solo un complemento de volumen, sino un
estándar real
para crear componentes personalizados para trabajar con almacenes de datos . Se supuso que los sistemas de orquestación de contenedores, como Kubernetes y Mesos, deberían "aprender" cómo trabajar con componentes implementados de acuerdo con este estándar. Y ahora Kubernetes ya ha aprendido.
¿Cuál es el dispositivo del complemento CSI en Kubernetes? El complemento CSI funciona con controladores especiales (
controladores CSI ) escritos por desarrolladores externos. El controlador CSI en Kubernetes debe constar al menos de dos componentes (pods):
- Controlador : administra el almacenamiento externo persistente. Se implementa como un servidor gRPC para el que se usa la primitiva
StatefulSet . - Nodo : es responsable de montar almacenes persistentes en los nodos del clúster. También se implementa como un servidor gRPC, pero se
DaemonSet primitiva DaemonSet para ello.
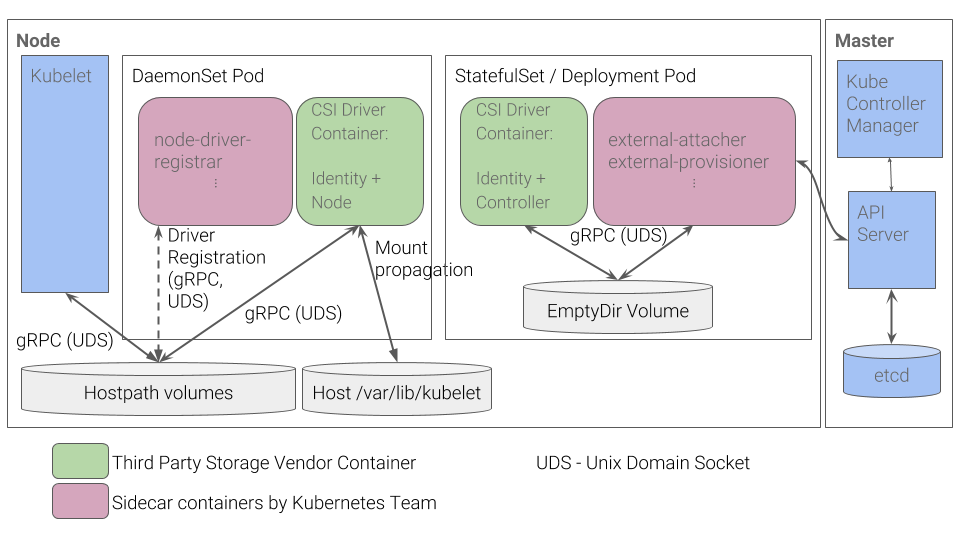 Kubernetes CSI Plugin Workflow
Kubernetes CSI Plugin WorkflowPuede obtener información sobre otros detalles de CSI, por ejemplo, del artículo "
Comprender el CSI ", una
traducción que publicamos hace un año.
Las ventajas de tal implementación
- Para cosas básicas, por ejemplo, para registrar un controlador para un nodo, los desarrolladores de Kubernetes han implementado un conjunto de contenedores. Ya no necesita crear una respuesta JSON con capacidades, como se hizo para el complemento Flexvolume.
- En lugar de "deslizar" los nodos de los archivos ejecutables, ahora colocamos pods en el clúster. Esto es lo que originalmente esperábamos de Kubernetes: todos los procesos ocurren dentro de contenedores desplegados usando primitivas de Kubernetes.
- Para implementar controladores complejos, ya no necesita desarrollar un servidor RPC y un cliente RPC. El cliente para nosotros fue implementado por los desarrolladores de Kubernetes.
- Pasar argumentos para trabajar con el protocolo gRPC es mucho más conveniente, flexible y más confiable que pasarlos a través de argumentos de línea de comandos. Para comprender cómo agregar soporte para las métricas de uso de volumen a CSI agregando un método gRPC estandarizado, consulte nuestra solicitud de extracción para el controlador vsphere-csi.
- La comunicación se realiza a través de sockets IPC para no confundirse si el pod Kubelet envió o no una solicitud.
¿Esta lista te recuerda algo? Las ventajas de CSI son la
solución a los problemas que no se tuvieron en cuenta al desarrollar el complemento Flexvolume.
Conclusiones
CSI como estándar para implementar complementos personalizados para interactuar con los almacenes de datos ha sido muy aceptado por la comunidad. Además, debido a sus ventajas y versatilidad, los controladores CSI se crean incluso para repositorios como Ceph o AWS EBS, complementos para trabajar que se agregaron en la primera versión de Kubernetes.
A principios de 2019, los complementos en árbol
quedaron en desuso . Se planea continuar admitiendo el complemento Flexvolume, pero no habrá desarrollo de nuevas funcionalidades para él.
¡Nosotros mismos ya tenemos experiencia en el uso de ceph-csi, vsphere-csi y estamos listos para agregar a esta lista! Hasta ahora, CSI hace frente a las tareas que se le asignaron con una explosión, y allí esperamos y vemos.
¡No olvides que todo lo nuevo es bien pensado!
PS
Lea también en nuestro blog: