Hace algún tiempo,
anunciamos un lanzamiento público y abrimos bajo la licencia MIT el código fuente de
LuaVela , una implementación de Lua 5.1, basada en LuaJIT 2.0. Comenzamos a trabajar en él en 2015 y, a principios de 2017, se utilizó en más del 95% de los proyectos de la compañía. Ahora quiero mirar hacia atrás en el camino recorrido. ¿Qué circunstancias nos llevaron a desarrollar nuestra propia implementación de un lenguaje de programación? ¿Qué problemas encontramos y cómo los resolvimos? ¿En qué se diferencia LuaVela de otras horquillas LuaJIT?
Antecedentes
Esta sección se basa en nuestro
informe sobre HighLoad ++. Comenzamos a usar activamente Lua para escribir la lógica comercial de nuestros productos en 2008. Al principio fue Lua de vainilla, y desde 2009 - LuaJIT. El protocolo RTB tiene un marco estricto para procesar la solicitud, por lo que cambiar a una implementación más rápida del lenguaje fue una solución lógica y, desde algún punto, necesaria.
Con el tiempo, nos dimos cuenta de que había ciertas limitaciones en la arquitectura de LuaJIT. Lo más importante para nosotros fue que LuaJIT 2.0 utiliza estrictamente punteros de 32 bits. Esto nos llevó a una situación en la que la ejecución en Linux de 64 bits limitó el tamaño del espacio de direcciones virtuales de la memoria de proceso a un gigabyte (en versiones posteriores del kernel de Linux, este límite se elevó a dos gigabytes):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Esta limitación se convirtió en un gran problema: en 2015, 1-2 gigabytes de memoria dejaron de ser suficientes para que muchos proyectos cargaran los datos con los que funcionaba la lógica. Vale la pena señalar que cada instancia de la máquina virtual Lua es de un solo subproceso y no sabe cómo compartir datos con otras instancias; esto significa que, en la práctica, cada máquina virtual podría reclamar un tamaño de memoria que no exceda los 2 GB / n, donde n es el número de flujos de trabajo de nuestro servidor aplicaciones.
Revisamos varias soluciones al problema: redujimos el número de subprocesos en nuestro servidor de aplicaciones, intentamos organizar el acceso a los datos a través de LuaJIT FFI, probamos la transición a LuaJIT 2.1. Desafortunadamente, todas estas opciones eran económicamente desventajosas o no escalaban bien a largo plazo. Lo único que nos quedaba era arriesgarnos y bifurcar a LuaJIT. En este momento, tomamos decisiones que determinaron en gran medida el destino del proyecto.
Primero, inmediatamente decidimos no hacer ningún cambio en la sintaxis y la semántica del lenguaje, enfocándonos en eliminar las restricciones arquitectónicas de LuaJIT, que resultaron ser un problema para la compañía. Por supuesto, a medida que el proyecto se desarrolló, comenzamos a agregar extensiones (discutiremos esto a continuación), pero aislamos todas las API nuevas de la biblioteca de idiomas estándar.
Además, abandonamos la plataforma cruzada en favor de admitir solo Linux x86-64, nuestra única plataforma de producción. Desafortunadamente, no teníamos suficientes recursos para probar adecuadamente la cantidad gigantesca de cambios que íbamos a hacer a la plataforma.
Un vistazo rápido debajo del capó de la plataforma
Veamos de dónde proviene la restricción en el tamaño de los punteros. Para empezar, el tipo de
número en Lua 5.1 es (con algunas advertencias menores) el tipo C doble, que a su vez corresponde al tipo de precisión doble definido por el estándar IEEE 754. En la codificación de este tipo de 64 bits, el rango de valores se resalta para la presentación NaN. En particular, cómo cualquier valor en el rango [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Por lo tanto, podemos empaquetar en un solo valor de 64 bits, ya sea un número de doble precisión "real", o alguna entidad, que desde el punto de vista del tipo doble se interpretará como NaN, y desde el punto de vista de nuestra plataforma será algo más significativo, por ejemplo, por el tipo de objeto (alto 32 bits) y un puntero a su contenido (bajo 32 bits):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Esta técnica a veces se llama etiquetado NaN (o boxeo NaN), y TValue básicamente describe cómo LuaJIT representa valores variables en Lua. TValue también tiene una tercera hipóstasis utilizada para almacenar un puntero a una función e información para rebobinar la pila Lua, es decir, en el análisis final, la estructura de datos se ve así:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
El campo frame.link en la definición anterior es del tipo uintptr_t, porque en algunos casos almacena un puntero y en otros es un número entero. El resultado es una representación muy compacta de la pila de la máquina virtual; de hecho, es una matriz TValue, y cada elemento de la matriz se interpreta situacionalmente como un número, luego como un puntero escrito a un objeto o como datos sobre el marco de la pila Lua.
Veamos un ejemplo. Imagine que comenzamos con LuaJIT este código Lua y establecimos un punto de interrupción dentro de la función de impresión:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
La pila Lua en este punto se verá así:

Y todo estaría bien, pero esta técnica comienza a fallar tan pronto como intentamos comenzar en x86-64. Si ejecutamos en modo de compatibilidad para aplicaciones de 32 bits, descansamos en contra de la restricción mmap ya mencionada anteriormente. Y los punteros de 64 bits no funcionarán en absoluto. Que hacer Para solucionar el problema tuve que:
- Extienda TValue de 64 a 128 bits: de esta manera obtenemos un vacío * honesto * en una plataforma de 64 bits.
- Corrija el código de la máquina virtual en consecuencia.
- Realice cambios en el compilador JIT.
El volumen total de cambios resultó ser muy significativo y nos alejó bastante del LuaJIT original. Vale la pena señalar que la extensión TValue no es la única forma de resolver el problema. En LuaJIT 2.1, fuimos al revés implementando el modo LJ_GC64. Peter Cawley, quien hizo una enorme contribución al desarrollo de este modo de operación, leyó sobre esto en una reunión en Londres. Bueno, en el caso de LuaVela, la pila para el mismo ejemplo se ve así:
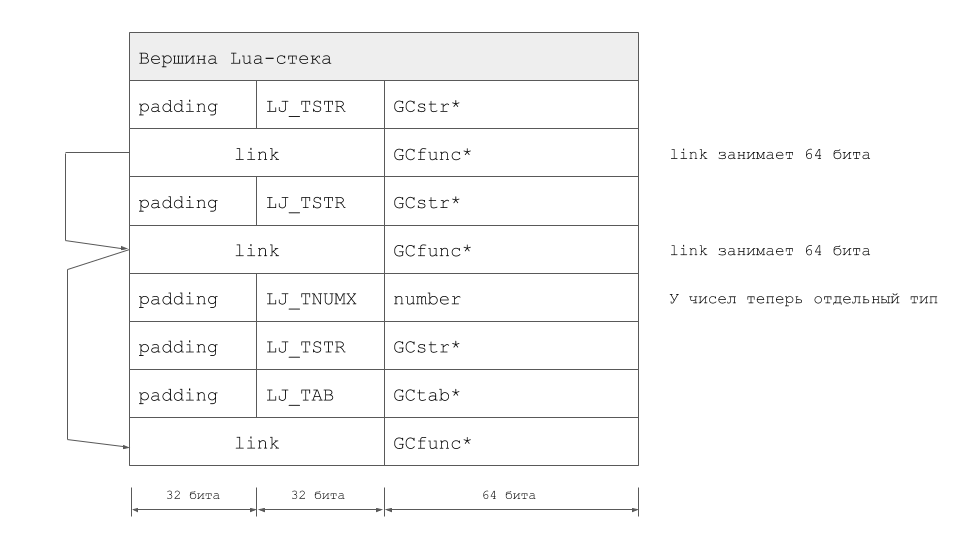
Primeros éxitos y estabilización del proyecto.
Después de meses de desarrollo activo, es hora de probar LuaVela en la batalla. Como experimental, elegimos los proyectos más problemáticos en términos de consumo de memoria: la cantidad de datos con los que tuvieron que trabajar, obviamente excedió 1 gigabyte, por lo que se vieron obligados a usar varias soluciones. Los primeros resultados fueron alentadores: LuaVela fue estable y mostró un mejor rendimiento en comparación con la configuración de LuaJIT utilizada en estos mismos proyectos.
Al mismo tiempo, surgió la cuestión de las pruebas. Afortunadamente, no tuvimos que comenzar desde cero, ya que desde el primer día de desarrollo, además de los servidores provisionales, teníamos a nuestra disposición:
- Pruebas funcionales y de integración de un servidor de aplicaciones que ejecuta la lógica empresarial de todos los proyectos de la empresa.
- Pruebas de proyectos individuales.
Como se ha demostrado en la práctica, estos recursos fueron suficientes para depurar y llevar el proyecto a un estado estable mínimo (hicieron un ensamblaje de desarrollo, implementado para la puesta en escena, funciona y no se bloquea). Por otro lado, tales pruebas a través de otros proyectos fueron completamente inadecuadas a largo plazo: un proyecto de tal nivel de complejidad como la implementación de un lenguaje de programación no puede tener sus propias pruebas. Además, la falta de pruebas directamente en el proyecto complicaba puramente técnicamente la búsqueda y corrección de errores.
En un mundo ideal, queríamos probar no solo nuestra implementación, sino también tener un conjunto de pruebas que nos permitieran validarla contra la
semántica del lenguaje . Lamentablemente, nos esperaba algo de decepción en este asunto. A pesar del hecho de que la comunidad Lua voluntariamente crea tenedores de implementaciones existentes, hasta hace poco, faltaba un conjunto similar de pruebas de validación. La situación mejoró cuando, a finales de 2018, François Perrad
anunció el proyecto lua-Harness.
Al final, cerramos el problema de las pruebas integrando las suites de pruebas más completas y representativas del ecosistema Lua en nuestro repositorio:
- Pruebas escritas por los creadores del lenguaje para su implementación de Lua 5.1.
- Pruebas proporcionadas por la comunidad por el autor de LuaJIT Mike Pall.
- arnés lua
- Un subconjunto de las pruebas del proyecto MAD desarrollado por el CERN.
- Dos conjuntos de pruebas que hemos creado en IPONWEB y que seguimos reponiendo hasta ahora: uno para pruebas funcionales de la plataforma, el otro usando el marco cmocka para probar la API de C y todo lo que carece de pruebas en el nivel de código Lua.
La introducción de cada lote de pruebas nos permitió detectar y corregir 2-3 errores críticos, por lo que es obvio que nuestros esfuerzos dieron resultado. Aunque el tema de probar los tiempos de ejecución y los compiladores del lenguaje (tanto estáticos como dinámicos) es realmente ilimitado, creemos que hemos establecido una base bastante sólida para el desarrollo estable del proyecto. Hablamos sobre los problemas de probar nuestra propia implementación de Lua (incluidos temas como trabajar con bancos de prueba y depuración post mortem) dos veces, en
Lua en Moscú 2017 y en
HighLoad ++ 2018 : todos los que
estén interesados en los detalles pueden ver un video de estos informes. Bueno, mira el directorio de
pruebas en nuestro repositorio, por supuesto.
Nuevas características
Por lo tanto, teníamos a nuestra disposición una implementación estable de Lua 5.1 para Linux x86-64, desarrollada por las fuerzas de un pequeño equipo, que gradualmente "dominó" la herencia de LuaJIT y la experiencia acumulada. En tales condiciones, el deseo de expandir la plataforma y agregar funciones que no están en Vanilla Lua ni en LuaJIT, pero que nos ayudarían a resolver otros problemas apremiantes, se volvió bastante natural.
Se proporciona una descripción detallada de todas las extensiones en la
documentación en formato RST (use cmake. && make docs para crear una copia local en formato HTML). Puede encontrar una descripción completa de las extensiones de la API de Lua
en este enlace , y la API de C
en este . Desafortunadamente, en un artículo de revisión es imposible hablar de todo, así que aquí hay una lista de las funciones más importantes:
- DataState: la capacidad de organizar el acceso compartido a un objeto desde varias instancias independientes de máquinas virtuales Lua.
- La capacidad de establecer un tiempo de espera para la rutina e interrumpir la ejecución de aquellos que corren más tiempo.
- Un conjunto de optimizaciones del compilador JIT diseñado para combatir el aumento exponencial en el número de trazas al copiar datos entre objetos: hablamos de esto en HighLoad ++ 2017, pero hace solo un par de meses teníamos nuevas ideas de trabajo que aún no se han documentado.
- Nuevo kit de herramientas: perfilador de muestreo. analizador de salida de depuración del compilador dumpanalyze , etc.
Cada una de estas características merece un artículo separado: escriba en los comentarios sobre cuál le gustaría leer más.
Aquí quiero hablar un poco más sobre cómo redujimos la carga en el recolector de basura.
El sellado le permite hacer que un objeto sea inaccesible para el recolector de basura. En nuestro proyecto típico, la mayoría de los datos (hasta el 80%) dentro de la máquina virtual Lua ya son reglas comerciales, que son una tabla Lua compleja. La vida útil de esta tabla (minutos) es mucho más larga que la vida útil de las solicitudes procesadas (decenas de milisegundos), y los datos que contiene no cambian durante el procesamiento de la consulta. En tal situación, no tiene sentido obligar al recolector de basura a recurrir alrededor de esta enorme estructura de datos una y otra vez. Para hacer esto, "sellamos" recursivamente el objeto y reordenamos los datos de tal manera que el recolector de basura nunca llegue ni al objeto "sellado" ni a su contenido. En Vanilla Lua 5.4, este problema se
resolverá al admitir generaciones de objetos en la recolección de basura generacional.
Es importante tener en cuenta que los objetos "sellados" no deben poder escribirse. La no observancia de esta invariante conduce a la aparición de punteros colgantes: por ejemplo, un objeto "sellado" se refiere a uno normal, y un recolector de basura, omitiendo un objeto "sellado" cuando va alrededor de un montón, omite uno normal, con la diferencia de que un objeto "sellado" no puede liberarse, y el habitual puede. Habiendo implementado el soporte para este invariante, esencialmente obtenemos soporte de
inmunidad gratuito
para los objetos, cuya ausencia a menudo se lamenta en Lua. Insisto en que los objetos inmutables y "sellados" no son lo mismo. La segunda propiedad implica la primera, pero no al revés.
También noto que en Lua 5.1 la inmunidad se puede implementar usando metatablas: la solución funciona bastante, pero no es la más rentable en términos de rendimiento. En
este informe se puede encontrar más información sobre "sellado", inmunidad y cómo los usamos en la vida cotidiana.
Conclusiones
Por el momento, estamos satisfechos con la estabilidad y el conjunto de oportunidades para nuestra implementación. Y aunque debido a las limitaciones iniciales, nuestra implementación es significativamente inferior a Vanilla Lua y LuaJIT en términos de portabilidad, resuelve muchos de nuestros problemas: esperamos que estas soluciones sean útiles para otra persona.
Además, incluso si LuaVela no es adecuado para la producción, lo invitamos a usarlo como punto de entrada para comprender cómo funciona LuaJIT o su tenedor. Además de resolver problemas y ampliar la funcionalidad, a lo largo de los años hemos refactorizado una parte significativa de la base del código y hemos escrito
artículos de capacitación sobre la estructura interna del proyecto; muchos de ellos son aplicables no solo a LuaVela, sino también a LuaJIT.
Gracias por su atención, estamos esperando solicitudes de extracción.