
En Mail.ru Group, tenemos Tarantool: este es un servidor de aplicaciones en Lua, que también tiene una base de datos (¿o viceversa?). Es rápido y genial, pero las capacidades de un servidor aún no son ilimitadas. El escalado vertical tampoco es una panacea, por lo que Tarantool tiene herramientas para el escalado horizontal: el módulo vshard
[1] . Le permite compartir datos en varios servidores, pero tiene que jugar con ellos para configurarlos y afianzar la lógica empresarial.
Buenas noticias: recolectamos los conos (por ejemplo
[2] ,
[3] ) y recortamos otro marco que simplificará significativamente la solución a este problema.
Tarantool Cartridge es un nuevo marco para desarrollar sistemas distribuidos complejos. Le permite concentrarse en escribir lógica de negocios en lugar de resolver problemas de infraestructura. Debajo del corte, le diré cómo está organizado este marco y cómo escribir servicios distribuidos con él.
¿Y cuál es, de hecho, el problema?
Tenemos una tarántula, hay vshard, ¿qué más se puede pedir?
En primer lugar, el punto es la conveniencia. La configuración de Vshard se configura a través de tablas Lua. Para que un sistema distribuido de varios procesos de Tarantool funcione correctamente, la configuración debe ser la misma en todas partes. Nadie quiere hacer esto manualmente. Por lo tanto, se utilizan todo tipo de scripts, Ansible, sistemas de implementación.
Cartridge gestiona la configuración vshard; lo hace en función de su
propia configuración distribuida . En esencia, este es un archivo YAML simple, una copia del cual se almacena en cada instancia de Tarantool. La simplificación radica en el hecho de que el marco en sí mismo monitorea su configuración y que es igual en todas partes.
En segundo lugar, el punto vuelve a ser conveniente. La configuración no tiene relación con el desarrollo de la lógica empresarial y solo distrae al programador del trabajo. Cuando discutimos la arquitectura de un proyecto, a menudo estamos hablando de componentes individuales y su interacción. Es demasiado pronto para pensar en implementar un clúster en 3 centros de datos.
Resolvimos estos problemas una y otra vez, y en algún momento logramos desarrollar un enfoque para simplificar el trabajo con la aplicación a lo largo de todo su ciclo de vida: creación, desarrollo, pruebas, CI / CD, mantenimiento.
Cartridge presenta el concepto de rol para cada proceso de Tarantool. Los roles son un concepto que permite al desarrollador centrarse en escribir código. Todos los roles disponibles en el proyecto se pueden ejecutar en una instancia de Tarantool, y esto será suficiente para las pruebas.
Características clave del cartucho de Tarantool:
- orquestación automatizada de clústeres;
- expandir la funcionalidad de la aplicación con nuevos roles;
- desarrollo de aplicaciones y plantilla de implementación;
- fragmentación automática incorporada;
- integración con el marco de prueba de Luatest;
- gestión de clústeres utilizando WebUI y API;
- herramientas de empaque y despliegue.
Hola mundo
Estoy ansioso por mostrar el marco en sí mismo, así que dejemos la historia sobre arquitectura para más adelante y comencemos con una simple. Suponiendo que Tarantool ya esté instalado, todo lo que queda por hacer es
$ tarantoolctl rocks install cartridge-cli $ export PATH=$PWD/.rocks/bin/:$PATH
Estos dos comandos instalarán las utilidades de línea de comandos y le permitirán crear su primera aplicación desde la plantilla:
$ cartridge create --name myapp
Y esto es lo que obtenemos:
myapp/ ├── .git/ ├── .gitignore ├── app/roles/custom.lua ├── deps.sh ├── init.lua ├── myapp-scm-1.rockspec ├── test │ ├── helper │ │ ├── integration.lua │ │ └── unit.lua │ ├── helper.lua │ ├── integration/api_test.lua │ └── unit/sample_test.lua └── tmp/
Este es un repositorio de git con el acabado "¡Hola, mundo!" aplicación Intentemos ejecutarlo inmediatamente, preinstalando las dependencias (incluido el propio marco):
$ tarantoolctl rocks make $ ./init.lua --http-port 8080
Por lo tanto, hemos lanzado un nodo de la futura aplicación fragmentada. Un laico inquisitivo puede abrir inmediatamente la interfaz web, usar el mouse para configurar un clúster desde un nodo y disfrutar del resultado, pero es demasiado pronto para alegrarse. Hasta ahora, la aplicación no sabe cómo hacer nada útil, por lo que le contaré sobre la implementación más tarde, y ahora es el momento de escribir el código.
Desarrollo de aplicaciones
Imagínese, diseñaremos un proyecto que debería recibir datos, guardarlo y generar un informe una vez al día.

Comenzamos a dibujar un diagrama y le colocamos tres componentes: puerta de enlace, almacenamiento y programador. Estamos trabajando más en la arquitectura. Como usamos vshard como almacenamiento, agregamos vshard-router y vshard-storage al esquema. Ni la puerta de enlace ni el planificador accederán directamente al repositorio, hay un enrutador para esto, fue creado para eso.

Este esquema aún no refleja con precisión lo que crearemos en el proyecto, porque los componentes se ven abstractos. También tenemos que ver cómo se proyecta esto en un Tarantool real: agruparemos nuestros componentes por proceso.

Mantener vshard-router y gateway en instancias separadas no tiene mucho sentido. ¿Por qué necesitamos ir a través de la red una vez más, si esto ya es responsabilidad del enrutador? Deben estar ejecutándose dentro del mismo proceso. Es decir, en un proceso, tanto la puerta de enlace como vshard.router.cfg se inicializan y les permiten interactuar localmente.
Era conveniente trabajar con tres componentes en la etapa de diseño, pero como desarrollador, mientras escribo código, no quiero pensar en lanzar tres instancias de Tarnatool. Necesito ejecutar pruebas y verificar que escribí la puerta de enlace correctamente. O tal vez quiero demostrar una característica a mis colegas. ¿Por qué debería sufrir con el despliegue de tres copias? Así nació el concepto de roles. Un rol es un módulo de Loach normal cuyo ciclo de vida es administrado por Cartridge. En este ejemplo, hay cuatro de ellos: puerta de enlace, enrutador, almacenamiento, programador. En otro proyecto, puede haber más. Todos los roles pueden iniciarse en un solo proceso, y esto será suficiente.

Y cuando se trata de implementar la puesta en escena o en funcionamiento, asignaremos cada conjunto de roles a cada proceso de Tarantool, dependiendo de las capacidades del hardware:
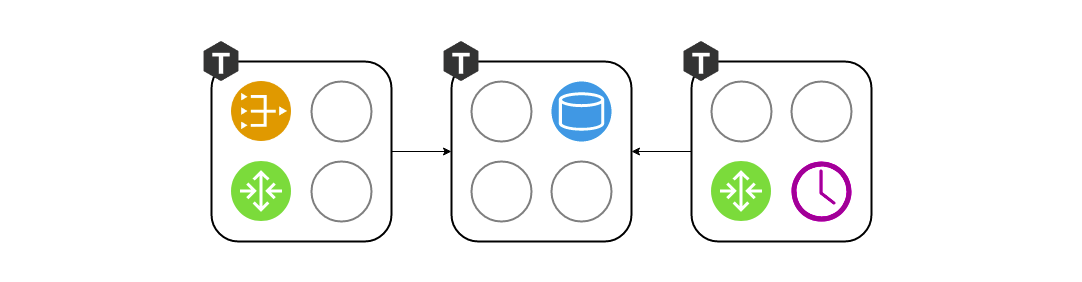
Gestión de topología
La información sobre dónde se lanzan los roles debe almacenarse en algún lugar. Y este "en algún lugar" es la configuración distribuida que mencioné anteriormente. Lo más importante es la topología de clúster. Aquí hay 3 grupos de replicación de 5 procesos de Tarantool:

No queremos perder datos, por lo tanto, tratamos cuidadosamente la información sobre los procesos en ejecución. Cartridge monitorea la configuración con una confirmación de dos fases. Tan pronto como queramos actualizar la configuración, primero verifica la disponibilidad de todas las instancias y su disponibilidad para aceptar la nueva configuración. Después de esto, la segunda fase aplica la configuración. Por lo tanto, incluso si una instancia no estuviera disponible temporalmente, no sucederá nada terrible. La configuración simplemente no se aplicará y verá un error por adelantado.
También en la sección de topología se indica un parámetro tan importante como el líder de cada grupo de replicación. Por lo general, esta es la instancia que se está grabando. El resto suele ser de solo lectura, aunque puede haber excepciones. A veces, los desarrolladores valientes no temen los conflictos y pueden escribir datos en varias réplicas en paralelo, pero hay algunas operaciones que, a pesar de todo, no deberían realizarse dos veces. Hay una señal de un líder para esto.

Vida del papel
Para que exista un rol abstracto en dicha arquitectura, el marco debe de alguna manera administrarlos. Naturalmente, el control ocurre sin reiniciar el proceso de Tarantool. Hay 4 devoluciones de llamada para gestionar roles. El propio cartucho los llamará según lo que diga en una configuración distribuida, aplicando así la configuración a roles específicos.
function init() function validate_config() function apply_config() function stop()
Cada rol tiene una función
init . Se llama una vez, ya sea cuando el rol está habilitado o cuando se reinicia Tarantool. Es conveniente allí, por ejemplo, inicializar box.space.create, o el programador puede ejecutar algo de fibra de fondo, que hará el trabajo a ciertos intervalos.
La función
init puede no ser suficiente. Cartridge permite que los roles aprovechen la configuración distribuida que utiliza para almacenar la topología. En la misma configuración, podemos declarar una nueva sección y almacenar un fragmento de la configuración empresarial en ella. En mi ejemplo, esto puede ser un esquema de datos o configuraciones de programación para el rol de planificador.
El clúster llama a
validate_config y
apply_config cada vez que cambia la configuración distribuida. Cuando una configuración se aplica mediante una confirmación de dos fases, el clúster verifica que cada rol esté listo para aceptar esta nueva configuración y, si es necesario, informa un error al usuario. Cuando todos estuvieron de acuerdo en que la configuración es normal, se
apply_config .
Los roles también tienen un método de
stop , que es necesario para eliminar los signos vitales del rol. Si decimos que el planificador en este servidor ya no es necesario, puede detener las fibras que comenzó con
init .
Los roles pueden interactuar entre sí. Estamos acostumbrados a escribir llamadas a funciones en Lua, pero puede suceder que no tengamos el papel que necesitamos en este proceso. Para facilitar el acceso a la red, utilizamos el módulo auxiliar rpc (llamada a procedimiento remoto), que se basa en el netbox estándar integrado en Tarantool. Esto puede ser útil si, por ejemplo, su puerta de enlace quiere pedirle directamente al programador que haga el trabajo ahora, en lugar de esperar un día.
Otro punto importante es garantizar la tolerancia a fallas. Cartridge utiliza el protocolo SWIM
[4] para controlar el estado. En resumen, los procesos intercambian "rumores" entre sí a través de UDP: cada proceso informa a sus vecinos las últimas noticias y ellos responden. Si la respuesta no llega, Tarantool comienza a sospechar que algo anda mal, y después de un tiempo recita la muerte y comienza a contarle a todos sobre esta noticia.

Según este protocolo, Cartridge organiza la conmutación por error automática. Cada proceso monitorea su entorno, y si el líder deja de responder repentinamente, la réplica puede asumir su rol en sí misma, y Cartridge configurará los roles en ejecución en consecuencia.

Debe tener cuidado aquí porque cambiar de un lado a otro con frecuencia puede generar conflictos de datos durante la replicación. Activar la conmutación por error automática al azar, por supuesto, no vale la pena. Debe comprender claramente lo que está sucediendo y asegurarse de que la replicación no se romperá después de que el líder se recupere y le devuelva la corona.
De todo lo que se ha dicho, puede parecer que los roles son similares a los microservicios. En cierto sentido, lo son, solo como módulos dentro de los procesos de Tarantool. Pero hay una serie de diferencias fundamentales. Primero, todos los roles del proyecto deben vivir en una base de código. Y todos los procesos de Tarantool deben iniciarse desde una base de código, para que no haya sorpresas como esas cuando intentamos inicializar el planificador, pero simplemente no. Además, no permita diferencias en las versiones del código, porque el comportamiento del sistema en tal situación es muy difícil de predecir y depurar.
A diferencia de Docker, no podemos simplemente tomar la "imagen" de un rol, llevarlo a otra máquina y ejecutarlo allí. Nuestros roles no están tan aislados como los contenedores Docker. Además, no podemos ejecutar dos roles idénticos en la misma instancia. El rol está ahí o no, en cierto sentido es singleton. Y en tercer lugar, los roles deberían ser los mismos en todo el grupo de replicación, porque de lo contrario sería ridículo: los datos son los mismos y la configuración es diferente.
Herramientas de implementación
Prometí mostrar cómo Cartridge ayuda a implementar aplicaciones. Para hacer la vida más fácil para otros, el framework incluye paquetes RPM:
$ cartridge pack rpm myapp # ./myapp-0.1.0-1.rpm $ sudo yum install ./myapp-0.1.0-1.rpm
El paquete instalado lleva casi todo lo que necesita: tanto la aplicación como las dependencias de lauch instaladas. Tarantool también llegará al servidor como una dependencia del paquete RPM, y nuestro servicio está listo para lanzarse. Esto se hace a través de systemd, pero primero debe escribir una pequeña configuración. Como mínimo, especifique el URI de cada proceso. Tres por ejemplo es suficiente.
$ sudo tee /etc/tarantool/conf.d/demo.yml <<CONFIG myapp.router: {"advertise_uri": "localhost:3301", "http_port": 8080} myapp.storage_A: {"advertise_uri": "localhost:3302", "http_enabled": False} myapp.storage_B: {"advertise_uri": "localhost:3303", "http_enabled": False} CONFIG
Hay un matiz interesante aquí. En lugar de especificar solo el puerto de protocolo binario, especificamos la dirección pública de todo el proceso, incluido el nombre de host. Esto es necesario para que los nodos del clúster sepan cómo conectarse entre sí. Es una mala idea usar la dirección 0.0.0.0 como publicidad_uri, debe ser una dirección IP externa, no un socket de enlace. Sin él, nada funcionará, por lo que Cartridge simplemente no permitirá que se inicie el nodo con el publicidad errónea.
Ahora que la configuración está lista, puede iniciar los procesos. Dado que una unidad systemd normal no permite iniciar más de un proceso, las aplicaciones en Cartridge instalan el denominado unidades instanciadas que funcionan así:
$ sudo systemctl start myapp@router $ sudo systemctl start myapp@storage_A $ sudo systemctl start myapp@storage_B
En la configuración, especificamos el puerto HTTP en el que Cartridge sirve la interfaz web - 8080. Veamos y veamos:

Vemos que los procesos, aunque se están ejecutando, aún no están configurados. El cartucho aún no sabe quién debe replicarse con quién y no puede decidir por sí mismo, por lo que está esperando nuestra acción. Y nuestra elección no es grande: la vida de un nuevo clúster comienza con la configuración del primer nodo. Luego agregamos el resto al clúster, les asignamos roles, y en esta implementación se puede considerar completada con éxito.
Vierte un vaso de tu bebida favorita y relájate después de una larga semana laboral. La aplicación puede ser explotada.

Resumen
¿Y cuáles son los resultados? Intente, use, deje comentarios, inicie tickets en el github.
Referencias
[1]
Tarantool »2.2» Referencia »Referencia de rocas» Módulo vshard[2]
Cómo implementamos el núcleo del negocio de inversión de Alfa-Bank basado en Tarantool[3]
Arquitectura de facturación de próxima generación: transición a Tarantool[4]
SWIM - protocolo de construcción de clúster[5]
GitHub - tarantool / cartucho-cli[6]
GitHub - tarantool / cartucho