Hace un año, comencé a trabajar a tiempo completo en Bloomberg. Y luego decidí escribir este artículo. Pensé que estaría lleno de ideas que podría tirar en papel cuando llegue el momento. Pero dentro de un mes me di cuenta de que todo no será tan simple: ya he comenzado a olvidar lo que aprendí. O el conocimiento fue tan bien adquirido que mi mente me hizo creer que siempre lo supe, o simplemente se me escaparon de la cabeza.
1Esta es una de las razones por las que empecé a llevar un diario. Todos los días, entrando en situaciones interesantes, las describía. Y todo gracias al hecho de que estaba sentado al lado de un programador líder. Pude observar de cerca su trabajo, y vi cuán diferente era de lo que haría. Programamos mucho juntos, lo que facilitó aún más mis observaciones. Además, nuestro equipo no condena el "espionaje" a las personas que escriben código. Cuando me pareció que algo interesante estaba sucediendo, me di vuelta y miré. Gracias al constante aumento, siempre fui consciente de lo que estaba sucediendo.
Pasé un año al lado de un programador líder. Esto es lo que aprendí.
Contenido
Escritura de código
Cómo nombrar cosas en código
Una de mis primeras tareas fue trabajar en React UI. Teníamos un componente principal que contenía todos los demás componentes. Me gusta agregar un poco de humor al código, y quería nombrar el componente principal de
GodComponent . Ha llegado el momento de revisar el código, y entendí por qué es tan difícil dar nombres.
Cada pieza de código que bauticé ha adquirido un propósito implícito. ¿
GodComponent ? Este es el componente que obtiene toda la basura que no quiero poner en el lugar correcto. Contiene todo
LayoutComponent , y en el futuro decidiría que este componente asigna un diseño. Que no contiene un estado.
Otra lección importante que aprendí fue que si algo parece demasiado grande, como un
LayoutComponent con un montón de lógica empresarial, entonces es hora de refactorizarlo, porque aquí no debería haber lógica empresarial. Y en el caso del nombre
GodComponent presencia de la lógica empresarial no importará.
¿Necesita nombrar los grupos? Llamarlos después de los servicios que se ejecutan en ellos será una gran idea hasta que ejecute algo más en estos clústeres. Les dimos un nombre en honor a nuestro equipo.
Lo mismo se aplica a las funciones.
doEverything() es un nombre terrible con muchas consecuencias. Si la función hace todo, será muy difícil probar sus partes individuales. No importa cuán grande pueda llegar a ser esta función, nunca te parecerá demasiado extraña, porque debería hacer todo. Entonces cambia el nombre. Refact.
Un nombre significativo tiene un inconveniente. ¿De repente el nombre será demasiado significativo y esconderá algún tipo de matiz? Por ejemplo,
cerrar sesiones no cierra la conexión de la base de datos cuando
session.close() llama a session.close
session.close() en SQLAlchemy. Debería haber leído la documentación y haber evitado este error, más sobre esto en la sección de
bicicletas .
Desde este punto de vista, nombrar funciones como
x ,
y ,
z lugar de
count() ,
close() ,
insertIntoDB() no nos permite ponerles un cierto significado y me hace monitorear cuidadosamente lo que hacen estas funciones.
2Nunca pensé que escribiría sobre los principios de nombrar más de una línea de texto.
Código heredado y el próximo desarrollador
¿Alguna vez has mirado el código y te parece extraño? ¿Por qué escribiste eso? Esto no tiene sentido.
Tuve la oportunidad de trabajar con una base de código heredada. Esto, ya sabes, con comentarios como "Descomenta el código cuando Muhammad comprenda la situación". Que haces aqui Quien es Muhammad?
Puedo cambiar de roles y pensar en la persona que recibirá mi código, ¿le parecerá extraño? La revisión parcial de su código ayuda a sus colegas a revisar su código. Esto me llevó a pensar en el contexto: necesito recordar el contexto en el que trabaja mi equipo.
Si olvido este código, vuelvo a él más tarde y no puedo restaurar el contexto, diré: “¿Qué demonios hicieron? Esto es estúpido ... Ah, espera, lo hice.
Y aquí entran en juego la documentación y los comentarios del código.
Documentación y comentarios en código
Ayudan a mantener el contexto y a transmitir el conocimiento. Como Lee dijo en
Cómo construir un buen software :
El valor principal del software no está en el código creado, sino en el conocimiento acumulado por las personas que crearon este software.
Tiene un punto final de API de cliente abierto que nadie parece haber usado nunca. ¿Solo necesita ser eliminado? En términos generales, es un deber técnico. ¿Y si te digo que en uno de los países 10 periodistas envían sus informes a este punto final una vez al año? ¿Cómo verificarlo? Si esto no se menciona en la documentación (lo fue), entonces no hay forma de verificarlo. No hemos verificado. Lo quitaron, y unos meses más tarde llegó ese momento muy anual. Diez periodistas no pudieron enviar sus informes importantes porque el punto final ya no existía. Y las personas con conocimiento del producto ya han abandonado el equipo. Por supuesto, ahora en el código hay comentarios que explican por qué esto es necesario.
Que yo sepa, cada equipo está luchando con la documentación. Y con la documentación, no solo por código, sino también por los procesos asociados con él.
Todavía no hemos encontrado la solución perfecta. Personalmente, me gusta la forma en que Antirez dividió los comentarios en código
en diferentes tipos de valores .
Comisiones atómicas
Si necesita retroceder (y lo necesita. Consulte el capítulo
Pruebas ), ¿tendrá este compromiso sentido como un solo módulo?
Cómo eliminar con confianza el código pésimo
Fui muy desagradable para eliminar el código pésimo u obsoleto. Me pareció que todo lo escrito hace siglos es sagrado. Pensé: "Tenían algo en mente cuando escribieron así". Esta es una confrontación entre tradición y cultura, por un lado, y pensar en el estilo del "principio primario" por el otro. Esto es lo mismo que la eliminación del punto final anual. Aprendí una lección especial.
3Intentaría sortear el código, y los desarrolladores líderes intentarían superarlo. Bórralo. ¿Una expresión if a la que no se puede acceder? Sí, borramos Que he hecho Acabo de escribir mi función encima. No he reducido la deuda técnica. De todos modos, acabo de aumentar la complejidad del código y el reenvío. Será aún más difícil para la próxima persona juntar las piezas de la imagen.
Empíricamente, llegué a la conclusión: hay un código que no entiendes, pero hay un código que definitivamente nunca contactarás. Borra el código con el que no contactas y ten cuidado con el código que no entiendes.
Revisión de código
Una revisión de código es una gran herramienta para la autoeducación. Este es un ciclo de retroalimentación externo que muestra cómo escribirían el código y cómo lo escribió. Cual es la diferencia ¿Una forma mejor que otra? Me pregunté sobre esto con cada crítica: "¿Por qué escribieron de esa manera?" Y si no pudo encontrar una respuesta adecuada, fue y preguntó.
Después del primer mes, comencé a encontrar errores en el código de mis colegas (como encontraron en el mío). Fue una especie de locura. La revisión se ha vuelto mucho más interesante para mí, se convirtió en un juego que me faltaba, un juego que mejoró mi "sentido del código".
En mi experiencia, no tiene que aprobar el código hasta que entienda cómo funciona.
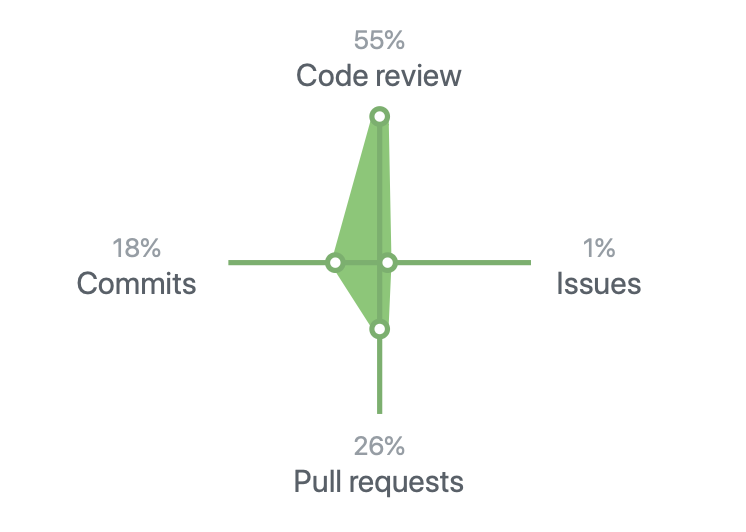 Mis estadísticas de github.
Mis estadísticas de github.Prueba
Me enamoré tanto de las pruebas que es desagradable para mí escribir código en una base de código sin pruebas.
Si su aplicación solo hace una cosa (como todos los proyectos de mi escuela), aún puede realizar la prueba manualmente.
4 Eso es exactamente lo que hice. Pero, ¿qué sucede si una aplicación realiza 100 tareas diferentes? No quiero pasar media hora probando, y a veces pierdo de vista algo. Una pesadilla
Las pruebas y la automatización de pruebas ayudan aquí.
Trato las pruebas como documentación. Esta es la documentación de mis ideas sobre el código. Las pruebas me dicen cómo yo (o cualquier otra persona antes que yo) imagino que el código funciona y dónde algo debería salir mal.
Hoy, cuando escribo pruebas, intento:
- Muestra cómo usar la clase, función o sistema de prueba.
- Mostrar lo que, en mi opinión, podría salir mal.
Como resultado, la mayoría de las veces pruebo el comportamiento, pero no la implementación (
aquí hay un ejemplo que elegí durante los descansos en Google).
En el párrafo 2, no mencioné las fuentes de errores.
Cuando noto un error, me aseguro de que la solución tenga una prueba adecuada (esto se llama prueba de regresión) para documentar la información. Esta es otra razón por la cual algo puede salir mal.
5 5Por supuesto, la calidad de mi código mejora no porque escribo pruebas, sino porque escribo código. Pero leer las pruebas me ayuda a comprender mejor las situaciones y escribir mejor código.
Esta es la situación general con las pruebas.
Pero este no es el único tipo de prueba que aplico. Estoy hablando de entornos de implementación. Es posible que tenga pruebas unitarias ideales, pero si no tiene pruebas del sistema, puede ocurrir algo como esto:

Esto también se aplica al código bien probado: si no tiene las bibliotecas necesarias en su computadora, entonces todo se bloqueará.
- Hay máquinas en las que está desarrollando (la fuente de todos los memes como "¡Funcionó en mi computadora!").
- Hay máquinas en las que está probando (pueden coincidir con las anteriores).
- Finalmente, hay máquinas en las que está implementando (no deben coincidir con las máquinas en las que desarrolló).
Si los entornos de prueba e implementación no coinciden en las máquinas, tendrá problemas. Los entornos de implementación ayudarán a evitar esto.
Estamos haciendo desarrollo local en Docker en nuestra computadora.
Tenemos un entorno de desarrollo, estas computadoras están equipadas con un conjunto de bibliotecas (y herramientas de desarrollo), y aquí instalamos el código escrito. Aquí se puede probar con todos los sistemas necesarios. También tenemos un entorno beta / provisional que repite completamente el entorno operativo. Finalmente, tenemos un entorno operativo: máquinas que ejecutan código para nuestros clientes.
La idea es detectar errores que no han aparecido durante las pruebas de la unidad y el sistema. Por ejemplo, la diferencia en API entre los sistemas solicitantes y de respuesta. Creo que en el caso de un proyecto personal o una pequeña empresa, la situación puede ser completamente diferente. No todos tienen la oportunidad de crear su propia infraestructura. Sin embargo, puede recurrir a servicios en la nube como AWS y Azure.
Puede configurar clústeres individuales para el desarrollo y la operación. AWS ECS utiliza imágenes de Docker para la implementación, por lo que los procesos en diferentes entornos serán relativamente consistentes. Existen matices en términos de integración entre diferentes servicios de AWS. ¿Está llamando al punto final correcto desde el entorno correcto?
Puede ir aún más lejos: descargue imágenes alternativas de contenedores para otros servicios de AWS y configure un entorno local totalmente funcional basado en Docker-Compose. Esto acelera el ciclo de retroalimentación.
6 Quizás gane más experiencia cuando cree y lance mi proyecto paralelo.
Reducción de riesgos
¿Qué pasos puede tomar para reducir su riesgo de desastre? Si estamos hablando de un nuevo cambio radical, ¿cómo podemos verificar la duración mínima del tiempo de inactividad, si algo sale mal? "No necesitamos implementar completamente el sistema debido a todos estos nuevos cambios". Que realmente ¡Y por qué no lo pensé!
Arquitectura
¿Por qué estoy hablando de arquitectura después de escribir código y probar? Se puede instalar primero, pero si no hubiera programado y probado en el entorno que utilicé, probablemente no habría logrado crear una arquitectura que tenga en cuenta las características de este entorno.
7 7
Debes pensar mucho al crear una arquitectura.
- ¿Cómo se usarán los números?
- ¿Cuántos usuarios habrá? ¿Cuánto puede aumentar su número (el número de filas en la base de datos depende de esto)?
- ¿Qué arrecifes pueden encontrarse?
Necesito convertir esto en una lista de verificación llamada "Colección de reclamos". Todavía no tengo suficiente experiencia, intentaré hacerlo el próximo año en Bloomberg. Este proceso es en gran medida contrario a Agile: ¿cuánto puede diseñar la arquitectura antes de pasar a la implementación? Se trata de equilibrio, debe elegir cuándo y qué hará. ¿Cuándo tiene sentido apresurarse y cuándo retroceder? Por supuesto, la recopilación de requisitos no equivale a considerar todas las cuestiones. Creo que vale la pena si incluimos los procesos de desarrollo en el diseño. Por ejemplo:
- ¿Cómo procederá el desarrollo local?
- ¿Cómo empacaremos y desplegaremos?
- ¿Cómo llevaremos a cabo las pruebas de extremo a extremo?
- ¿Cómo realizaremos pruebas de estrés del nuevo servicio?
- ¿Cómo guardaremos secretos?
- Integración CI / CD?
Recientemente desarrollamos un nuevo motor de búsqueda para
BNEF . Fue maravilloso trabajar en ello, organicé un desarrollo local y descubrí DPG (paquetes y su despliegue), recabando el despliegue de secretos.
¿Quién hubiera pensado que desplegar secretos en un producto podría ser tan trivial?
- No se pueden colocar en el código, porque alguien puede notarlos
- ¿Para almacenarlos como una variable de entorno como la especificación ofrece 12 factores de aplicación? No es una mala idea, pero ¿cómo ponerlos allí? (Ir al producto para completar las variables de entorno cada vez que el auto arranca es un fastidio)
- ¿Desplegarlos como archivos? ¿Pero de dónde vendrán y cómo llenarlos?
No queremos hacer todo manualmente.
Como resultado, llegamos a una base de datos con control de acceso basado en roles (solo nosotros y nuestras computadoras podemos comunicarnos con la base de datos). Nuestro código recibe secretos de la base de datos al inicio. Este enfoque está bien replicado en el marco de los entornos de desarrollo, preparación y operación; los secretos se almacenan en bases de datos apropiadas.
Nuevamente, con servicios en la nube como AWS, la situación puede ser completamente diferente. No necesita cuidar los secretos de alguna manera. Obtenga una cuenta para su rol, ingrese los secretos en la interfaz y su código los encontrará cuando sean necesarios. Esto simplifica enormemente todo, pero me alegro de haber adquirido experiencia, gracias a lo cual puedo apreciar esta simplicidad.
Creamos arquitectura, sin olvidar el mantenimiento.
El diseño del sistema es inspirador. ¿Y la escolta? No demasiado Mi viaje por el mundo de las escorts me llevó a la pregunta: ¿por qué y cómo se degradan los sistemas? La primera parte de la respuesta no está relacionada con el desmantelamiento de todos los obsoletos, sino solo con la adición de uno nuevo. La tendencia a agregar en lugar de eliminar (¿no recuerda nada?). La segunda parte es diseñar con el objetivo final en mente. Un sistema que, con el tiempo, comienza a hacer lo que no estaba destinado, no necesariamente funcionará tan bien como un sistema originalmente diseñado para las mismas tareas. Este es un enfoque de estilo paso atrás, no trucos y trucos.
Conozco al menos tres formas de reducir la tasa de degradación.
- Lógica e infraestructura empresarial separadas: la infraestructura generalmente se degrada: la carga aumenta, los marcos se vuelven obsoletos, aparecen vulnerabilidades de día cero, etc.
- Crear procesos para soporte futuro. Aplique las mismas actualizaciones para bits antiguos y nuevos. Esto evitará las diferencias entre lo antiguo y lo nuevo y mantendrá todo el código en un estado "moderno".
- Asegúrese de tirar todo lo innecesario y viejo.
Despliegue
¿Combinaré características o las desplegaré una a la vez? Dependiendo del proceso actual, si los empaqueta, espere problemas. Pregúntese por qué quiere agrupar características juntas.
- ¿La implementación lleva mucho tiempo?
- ¿La revisión de código no es demasiado divertida?
Cualquiera sea la razón, esta situación necesita ser corregida. Conozco al menos dos problemas asociados con el embalaje:
- Usted mismo bloquea todas las funciones si una de ellas tiene un error.
- Aumenta el riesgo de problemas.
Independientemente del proceso de implementación que elija, siempre querrá que sus autos sean como ganado, no como mascotas. No son únicos Sabes exactamente qué se ejecuta en cada máquina, cómo recrearlos en caso de muerte. No se enojará si algún automóvil muere, simplemente elija uno nuevo. Los pastan, no crecen.
Cuando algo sale mal
En caso de que algo salga mal, y lo hace, hay una regla de oro: minimizar el impacto en los clientes. En caso de fallas, mi primer deseo siempre fue arreglarlo. Esto no parece ser la solución óptima. En lugar de arreglarlo, incluso si se puede hacer en una línea, primero debe retroceder. Regresar al estado operativo anterior. Esta es la forma más rápida de devolver a los clientes a una versión que funcione. Solo entonces descubro cuál es el problema y lo soluciono.
Lo mismo se aplica a la máquina "dañada" en su clúster: apáguela, márquela como inaccesible, antes de descubrir qué le sucedió. Me resulta extraño cuánto mis deseos e instintos naturales contradicen la solución óptima.
Creo que este instinto también condujo al hecho de que solucioné errores más tiempo. A veces me di cuenta de que algo no funcionaba, porque el código que escribí estaba de alguna manera equivocado, y me metí en la naturaleza, mirando cada línea. Algo así como una búsqueda "primero en profundidad". Y cuando resultó que el problema surgió debido a un cambio de configuración, es decir, no lo revisé en primer lugar, esta situación me inquietó. Perdí mucho tiempo buscando un error.
Desde entonces, he aprendido a buscar "primero en amplitud" y, por lo tanto, ya "primero en profundidad" para excluir razones de nivel superior. ¿Qué puedo confirmar exactamente con los recursos actuales?
- ¿Funciona el auto?
- ¿El código está instalado correctamente?
- ¿Hay una configuración?
- <Configuración específica del código>, como si el enrutamiento se explica correctamente.
- ¿Es correcta la versión del esquema?
- Y luego me sumerjo en el código.
Pensamos que nginx se instaló incorrectamente, pero resultó que solo la configuración estaba deshabilitada
Por supuesto, no necesito hacer esto todo el tiempo. A veces, solo un mensaje de error es suficiente para llegar inmediatamente al código. Cuando no puedo determinar la causa, trato de minimizar el número de cambios en el código para encontrar el motivo. Cuantos menos cambios, más rápido puedo encontrar la verdadera raíz del problema. Además, ahora tengo un memo para los errores que me ahorraron más de una hora pensando "¿qué me perdí?" A veces me olvido de las comprobaciones más simples, como la configuración de enrutamiento, el esquema de coincidencia y las versiones de servicio, etc. Este es otro paso en el desarrollo de la pila de tecnología que uso, y lo que obtienes solo con experiencia es la intuición para determinar qué es exactamente lo que no funciona.
Bicicleta
Este artículo no puede estar completo sin una historia. , . SQLAlchemy. BNEF , . . SQLAlchemy, , Solr. - .
«MYSQL server has gone away.» . , , . , . , . , ?
, ? , , . , ,
__exit__() session.close() .
, , . . . . .
Session.close() MySQL- SQLAlchemy , NullPool. . , , . : StackOverflow (, !) , , SQL- . , . , , (), .
«» , 1 8. , , — .
, .
, . , , . , .
, , , . , . , . «
?! , ? ».
, : , . , , . , , . , . — ? , , . . , -, , , , , .. .
. , , ? (, AWS CloudWatch Grafana). .
. , , 50 %, — . ? . , — (, ?).
. , , , , ? ? , ?
, . , . — - .
Conclusión
. , , , . , - !
. , !
, . , — How to Build Good Software .
. : ! , .
- ?
- ? , ? , ?
- . , ? ?
- (utils) (, , , ) , « »?
- ?
- , , - ?
- — API , ?
- ? , .
- , , . , , .
- PR: « , , 52 , , , , , ». ?
- . ?
- ?
- ?
Notas
- . , ? - ? , ?
- ,
x() , y() z(), x() , y() z() . , WYSIATI .
- .
- . , ?
- , - , , . , .
- , , Docker- AWS.
- .