Muchos usan herramientas especializadas para crear procedimientos para extraer, transformar y cargar datos en bases de datos relacionales. Se registra el proceso de las herramientas de trabajo, se registran los errores.
En caso de error, el registro contiene información de que la herramienta no pudo completar la tarea y qué módulos (a menudo Java) se detuvieron. En las últimas líneas puede encontrar un error en la base de datos, por ejemplo, una violación de una clave de tabla única.
Para responder a la pregunta, ¿qué papel juega la información de error ETL? Clasifiqué todos los problemas que han ocurrido en el repositorio bastante grande en los últimos dos años.

Características del almacenamiento donde se realizó la clasificación:
- 20 fuentes de datos conectadas
- 10.5 mil millones de filas se procesan diariamente
- que se agregan hasta 50 millones de filas,
- los datos procesan 140 paquetes en 700 pasos (un paso es una solicitud de sql)
- servidor - base de datos X5 de 4 nodos
Los errores de la base de datos incluyen, por ejemplo, quedarse sin espacio, una conexión desconectada, una sesión suspendida, etc.
Los errores lógicos incluyen violaciones de claves de tabla, objetos no válidos, falta de acceso a objetos, etc.
Es posible que el programador no se inicie en el momento adecuado, puede que se bloquee, etc.
Los errores simples no requieren mucho tiempo para solucionarlos. Con la mayoría de ellos, un buen ETL puede hacer frente por sí solo.
Los errores complicados hacen que sea necesario abrir y verificar los procedimientos para trabajar con datos, para investigar fuentes de datos. A menudo conducen a la necesidad de probar cambios e implementación.
Entonces, la mitad de todos los problemas están relacionados con la base de datos. El 48% de todos los errores son errores simples.
La tercera parte de todos los problemas está asociada con un cambio en la lógica o el modelo del repositorio; más de la mitad de estos errores son complejos.
Y menos de una cuarta parte de todos los problemas están relacionados con el programador de tareas, el 18% de los cuales son errores simples.
En general, el 22% de todos los errores que han ocurrido son complejos; su reparación requiere la mayor atención y tiempo. Ocurren aproximadamente una vez a la semana. Mientras que los errores simples ocurren casi todos los días.
Obviamente, el monitoreo de los procesos ETL será efectivo cuando la ubicación del error se indique con la mayor precisión posible en el registro y se requiera un tiempo mínimo para encontrar la fuente del problema.
Monitoreo efectivo
¿Qué quería ver en el proceso de monitoreo de ETL?
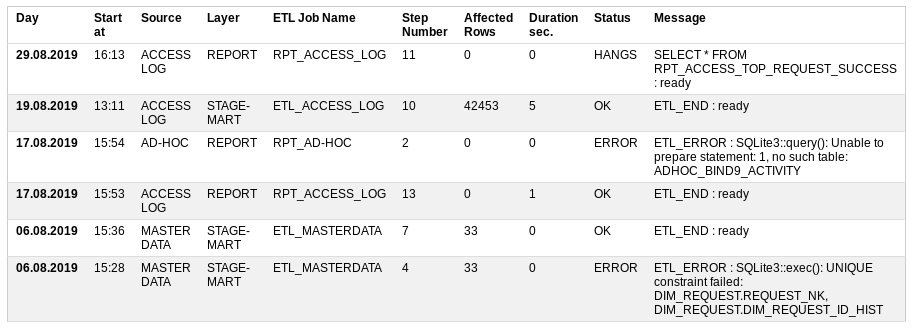
Comience a las - cuando comenzó
Fuente: una fuente de datos
Capa: qué nivel de almacenamiento se está cargando,
ETL Job Name es un procedimiento de carga que consta de muchos pasos pequeños,
Número de paso: el número del paso a realizar,
Filas afectadas: cuántos datos ya se han procesado,
Duración sec: cuánto tiempo lleva ejecutar,
Estado: si todo está bien o no: OK, ERROR, RUNNING, HANGS
Mensaje: el último mensaje exitoso o descripción del error.
Según el estado de las entradas, puede enviar un correo electrónico. carta a otros participantes. Si no hay errores, entonces la carta no es necesaria.
Por lo tanto, en caso de error, la ubicación del incidente está claramente indicada.
A veces sucede que la herramienta de monitoreo en sí misma no funciona. En este caso, es posible llamar directamente una vista (vista) en la base de datos sobre la base de la cual se construye el informe.
Tabla de monitoreo de ETL
Para implementar el monitoreo de procesos ETL, una tabla y una vista son suficientes.
Para hacer esto, puede volver a
su pequeño repositorio y crear un prototipo en la base de datos sqlite.
Tablas DDLCREATE TABLE UTL_JOB_STATUS ( UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, SID INTEGER NOT NULL DEFAULT -1, LOG_DT INTEGER NOT NULL DEFAULT 0, LOG_D INTEGER NOT NULL DEFAULT 0, JOB_NAME TEXT NOT NULL DEFAULT 'N/A', STEP_NAME TEXT NOT NULL DEFAULT 'N/A', STEP_DESCR TEXT, UNIQUE (SID, JOB_NAME, STEP_NAME) ); INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);
Envío / informe DDL CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V AS WITH SRC AS ( SELECT LOG_D, LOG_DT, UTL_JOB_STATUS_ID, SID, CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' ELSE 'N/A' END AS LAYER, CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' ELSE 'N/A' END AS SOURCE, JOB_NAME, STEP_NAME, CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG, CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG, CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG, STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG, SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS FROM UTL_JOB_STATUS WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month') ) SELECT JB.SID, JB.MIN_LOG_DT AS START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT, JB.SOURCE, JB.LAYER, JB.JOB_NAME, CASE WHEN JB.ERROR_FLAG = 1 THEN 'ERROR' WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING' ELSE 'OK' END AS STATUS, ERR.STEP_LOG AS STEP_LOG, JB.CNT AS STEP_CNT, JB.AFFECTED_ROWS AS AFFECTED_ROWS, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT, JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC FROM ( SELECT SID, SOURCE, LAYER, JOB_NAME, MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID, MAX(START_FLAG) AS START_FLAG, MAX(END_FLAG) AS END_FLAG, MAX(ERROR_FLAG) AS ERROR_FLAG, MIN(LOG_DT) AS MIN_LOG_DT, MAX(LOG_DT) AS MAX_LOG_DT, SUM(1) AS CNT, SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS FROM SRC GROUP BY SID, SOURCE, LAYER, JOB_NAME ) JB, ( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG FROM SRC WHERE 1 = 1 ) ERR WHERE 1 = 1 AND JB.SID = ERR.SID AND JB.JOB_NAME = ERR.JOB_NAME AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;
Comprobación de SQL para obtener un nuevo número de sesión SELECT SUM ( CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL AND NOT ( 'y' = 'n' ) THEN 1 ELSE 0 END ) AS IS_RUNNING FROM ( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job LEFT OUTER JOIN ( SELECT JOB_NAME, SID, 1 AS dummy FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' AND STEP_NAME = 'ETL_START' GROUP BY JOB_NAME, SID ) start_job ON d_job.dummy = start_job.dummy LEFT OUTER JOIN ( SELECT JOB_NAME, SID FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' AND STEP_NAME in ('ETL_END', 'ETL_ERROR') GROUP BY JOB_NAME, SID ) end_job ON start_job.JOB_NAME = end_job.JOB_NAME AND start_job.SID = end_job.SID
Características de la mesa:
- Al comienzo y al final del proceso de procesamiento de datos, debe seguir los pasos ETL_START y ETL_END
- en caso de error, se debe crear el paso ETL_ERROR con su descripción
- la cantidad de datos procesados debe resaltarse, por ejemplo, con asteriscos
- al mismo tiempo, se puede iniciar el mismo procedimiento con el parámetro force_restart = y; sin él, el número de sesión se emite solo para el procedimiento completado
- en modo normal, no puede ejecutar el mismo procedimiento de procesamiento de datos en paralelo
Las operaciones necesarias para trabajar con la tabla son las siguientes:
- obtener el número de sesión del procedimiento ETL para comenzar
- inserte una entrada de registro en una tabla
- obtener el último registro exitoso de procedimiento ETL
En bases de datos como Oracle o Postgres, estas operaciones se pueden implementar con funciones integradas. Sqlite necesita un mecanismo externo, y en este caso está
prototipado en PHP .
Conclusión
Por lo tanto, los mensajes de error en las herramientas de procesamiento de datos juegan un papel muy importante. Pero es difícil llamarlos óptimos para una búsqueda rápida de las causas del problema. Cuando el número de procedimientos se acerca a cien, el monitoreo de los procesos se convierte en un proyecto complejo.
El artículo proporciona un ejemplo de una posible solución al problema en forma de prototipo. El prototipo completo del repositorio pequeño está disponible en gitlab
SQLite PHP ETL Utilities .